面向洪水预警预报的水文数据自动化整合与系统集成
2022-01-14梁宁
梁宁
(玉林水文中心,广西玉林537000)


1 区域概况
玉林市位于广西东南部,境内3大水系主要是独流入海的南流江、九洲江与珠江流域西江水系的北流河,均发源于玉林境内;小部分属郁江水系武思江的支流和广东鉴江水系的支流,都属于中小河流。南流江流入北海合浦县,在玉林辖区内集水面积5395 km2,干流长197.1 km,多年平均径流深为775.8 mm;北流河流入梧州藤县,在玉林辖区内集水面积3643 km2,干流长161 km,多年平均径流深954.7 mm;九洲江汇入广东鹤地水库,在广西境内集水面积1092 km2,干流长85.5 km,多年平均径流深为996.6 mm。
全市50 km2以上集水面积的河流104条,建有水文(位)站62个,均测定防洪警戒水位,其中集水面积最大为3610 km2,最小为17 km2,200 km2以下的有40个站点,汇流时间小于3 h的有24个,洪水期间暴涨暴落,属于典型的暴雨主导型流域,受汇流影响较小;建有雨量站221个。从流域水系、集水面积、站网分布和洪水影响等方面考虑,都比较适合构建洪水预警预报一体化体系。
区域水系及水文站网分布见图1。
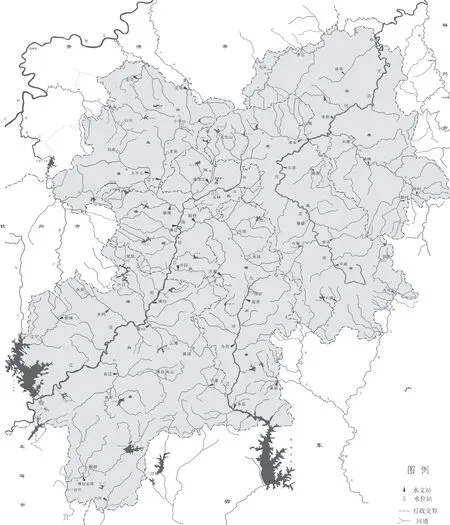
图1 玉林市江河水系及水文站网分布图
2 模型构建
2.1 多元线性回归
回归分析是研究变量之间相关关系的一种数理统计方法,也是水文学中的重要研究工具。本系统主要采用多元回归方法建立经验预报模型。
如果因变量y与m个自变量x1,x2,…,xm之间存在线性函数关系,有n组观测数据(n>m),则有:
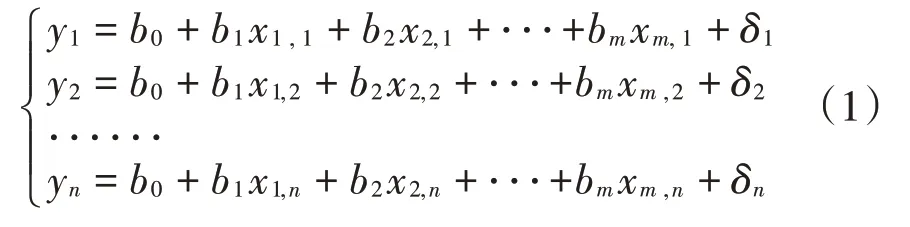
式中:y0、y1、y2、…、ym为观测值;b0、b1、b2、…、bm为经验回归系数。

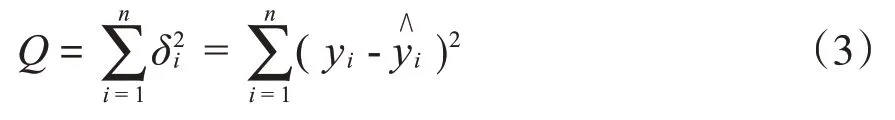
2.2 显著性检验
2.2.1 F检验
对任意一组观测数据,需要确定自变量与因变量之间是否存在线性关系,即进行F分布显著性检验。显著性原假设是:在总体中,因变量与所有自变量都不存在线性回归关系,即
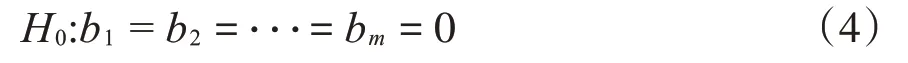
当原假设H0成立时,统计量F:
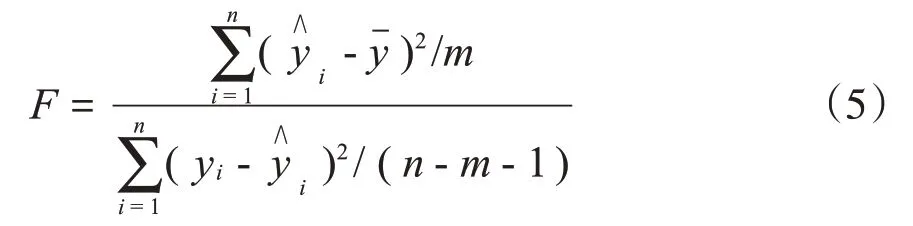
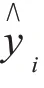

根据式(5),当用样本得到的F值大于Fα时,拒绝原假设H0,即线性回归方程是显著的;否则所得方程无意义,因变量与自变量之间不存在线性回归关系。
2.2.2 T检验
通过了F检验,只能说明回归方程中的m个回归系数不全为0,而不能排除其中某个回归系数为0。如果某个bk(k=1,2,…,m)为0,说明xk与y不存在线性关系,应从方程剔除。
双侧检验:H0:bk=0;H1:bk≠0。
选择统计量T:

当H0成立时,T服从自由度为(n-m-1)的t分布。对给定的α和自由度(n-m-1),由t分布表查出临界值tα2,其满足

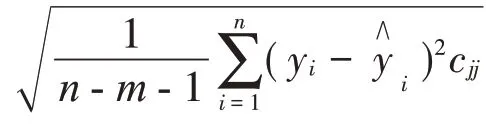
当|T |>tα2,则拒绝假设H0,接受H1,即因子xk与y存在显著线性关系,应予保留;否则剔除xk,重新计算经验回归系数,再重复显著性检验。
在洪水经验预报模型中,将洪峰水位(流量)作为观测值y,将流域面平均雨量、有效降雨历时、起涨水位、同时水位、涨幅,以及上游站(如存在)的洪峰、涨幅、历时、同时水位等多个因子作为x1,x2,⋅⋅⋅,xm,对辖区每一个水文站(断面),摘录历史洪水场次,构建多元回归预报模型。对于各个水文站(断面),由于气象水文特性和下垫面条件不同,各自适用的回归因子也可能有所不同,因此,最后采用F检验和T检验,筛选出显著相关的因子,剔除不敏感因子,最终得到适应该站(断面)特性的多元回归方程,提高预测精度。
3 系统集成
3.1 系统结构
本研究基于玉林市辖区各江河水文站特性,构建了面向洪水预警预报的水文数据自动化整合体系。
系统采用B/S(浏览器/服务器)3层体系结构搭建,采用HTML、Javascript作为主要前端语言,以PHP为服务器端技术支撑,使用关系型数据库MySQL作数据存储,良好实现跨平台兼容,电脑、手机、平板均可使用,同时便于版本升级、后期维护。面向洪水预警预报的水文数据自动化模型体系结构图见图2。
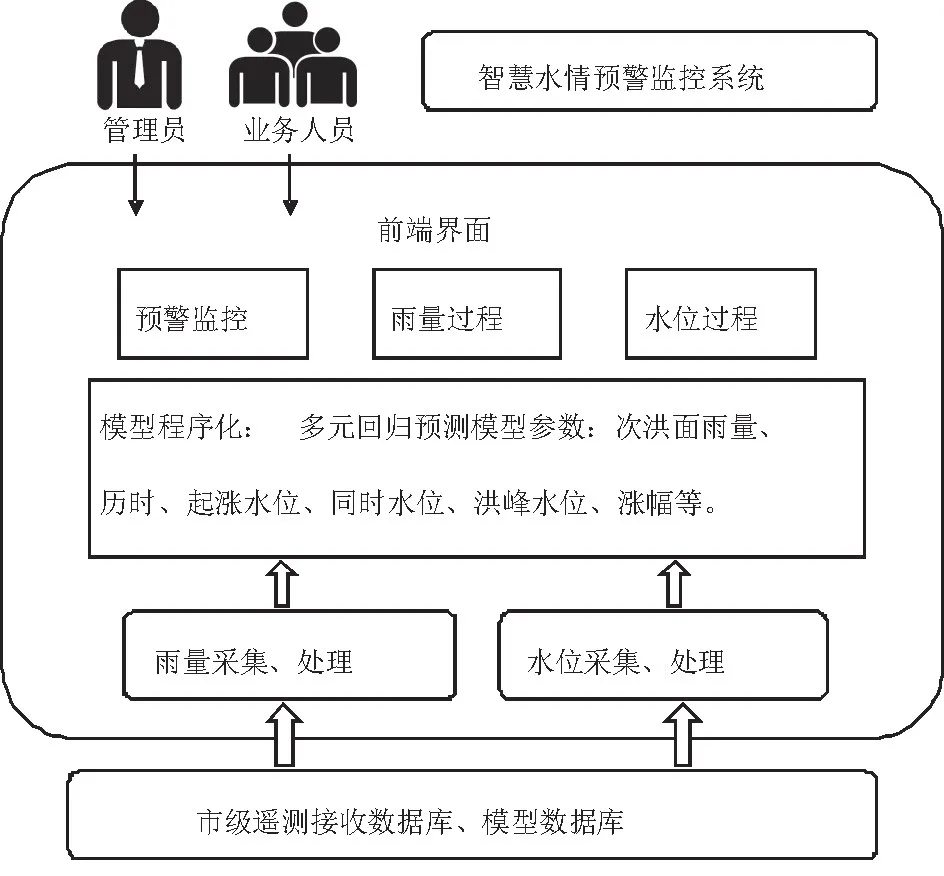
图2 面向洪水预警预报的水文数据自动化模型体系结构图
(1)数据采集层:衔接各市级水文系统的雨水情遥测接收数据库,直接读取遥测雨水情、站点基础信息等,避免与遥测终端通讯、数据传输、报文解析等重复工作量;部分基础信息从交换数据库读取。
(2)功能逻辑层:水文模型参数计算机程序化,将采集的雨、水情遥测数据进行模块化处理,生成多元回归模型涉及的因子:次洪面雨量、历时、起涨水位、洪峰水位、涨幅等。进行洪峰计算及超警判断,生成雨量过程线和水位过程线。
(3)业务表现层:前端界面主要包括预警监控、雨量过程线、水位过程线(含涨率)展示3部分。预警监控主页主要通过表格形式展示雨水情实时监控信息和洪峰预测结果,专业性强而成果简明,适用于一线水文人员;雨量、水位过程线以图表形式供工作人员查看过程信息,较为直观,同时便于进行模型结果调整。
(4)适用对象:提供管理员账户和普通业务账户,分级管理。管理员账户默认查询市级所有水文站点,普通业务账户依据登录用户分别查询各县(市、区)水文中心站;两类账户均可手工指定县域查询范围,既减少数据干扰,又兼顾流域上下游信息互通。
3.2 主界面展示
主界面主要综合了实时监控模块、预警研判模块、报警提示模块、定时更新模块、历史查询模块等。从页面展示信息划分,又可以分为系统菜单栏、系统状态栏、输入参数栏、搜索栏、预测成果表(见图3)。
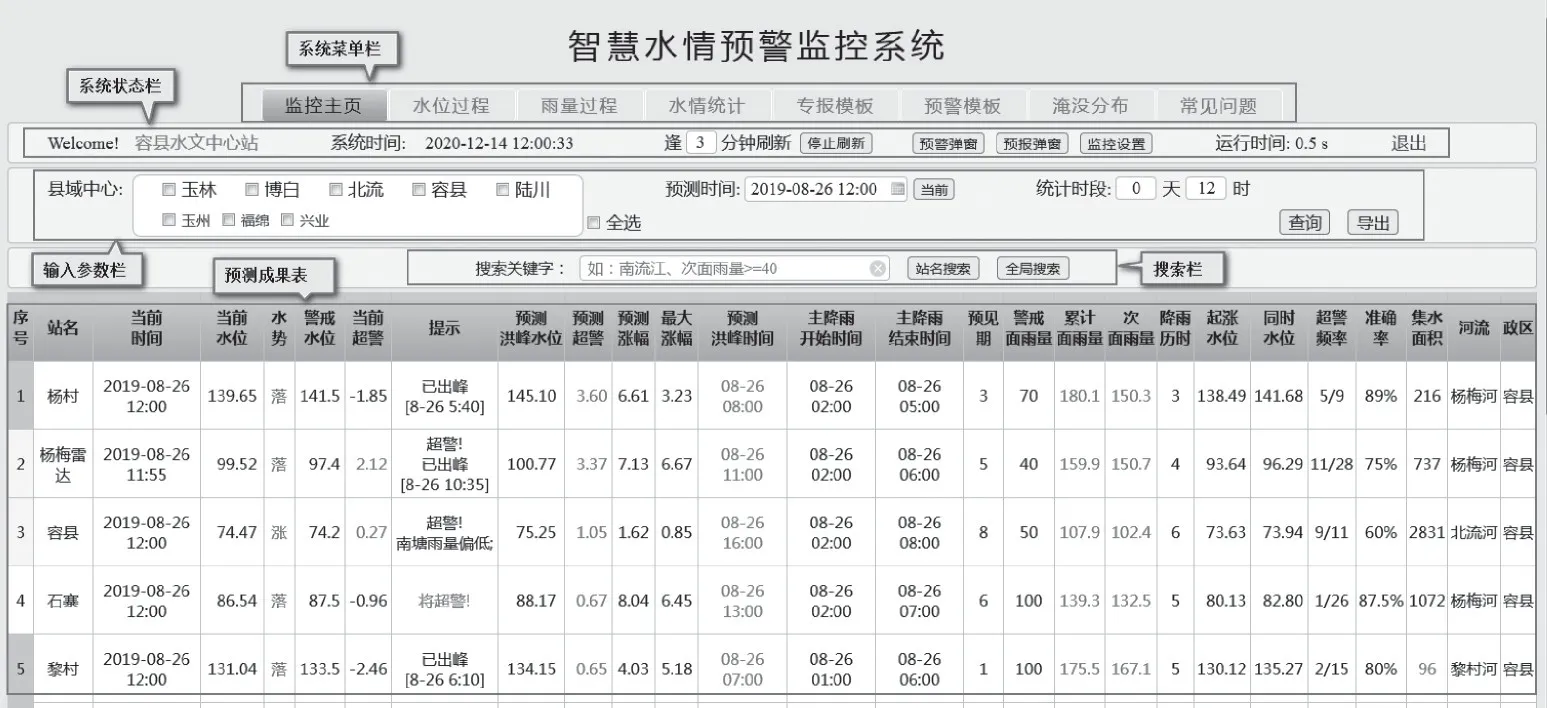
图3 系统主界面展示
(1)预测成果表主要分为6大类。①站点信息:站名、警戒水位、集水面积、河流、政区;②实时信息:当前时间、当前水位、水势、当前超警;③预测信息:预测洪峰水位~预见期等连续8列;④临界雨量信息:警戒面雨量、累计面雨量、次面雨量;⑤多元回归模型信息:次面雨量~准确率等连续6列;⑥提示信息:对当前和未来水情作出的评价。
(2)自动刷新。当前系统设定每10 min自动刷新一次,进行数据更新、研判,并判断是否发出相应提示和报警。用户可以根据需要修改刷新时间值。
(3)预警弹窗。当系统自动刷新或人工查询时,出现以下任意一种情况系统会弹出报警提示框并自动播放音乐:①预测将有1个或多个站点出现超警洪水(此时,显示“预测超警表”);②当前已有1个或多个站点出现超警洪水(此时,显示“当前超警表”)。当①②同时发生,则2种提示表格同时显示(见图4)。
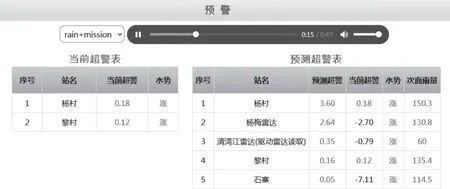
图4 预警提示框
3.3 系统特色
(1)智能模式:针对基层水文用户,提供了操作简易的“智能模式”,只需保持主界面不关闭即可。系统会自动监控、分析研判、预警提示、定时轮询,并将结果展示在成果表中,根据需要作出报警提示,全程无须人工干预。这大大降低了使用门槛。
(2)人机交互:系统同时提供了丰富的交互功能,用户可以根据需求自定义站点查询范围、过去历史洪水、洪水历时、轮询时间、报警音乐等。
(3)定时轮询:系统基于遥测数据(一般每5 min加报一次),每10 min轮询一次,一旦研判超警,会弹出相应文字提示框与声音报警。
(4)拓展功能:系统增加了当前水位超警信息、站点警戒面雨量、最大涨幅、出峰提示,与实测洪峰水位误差对比等功能,便于专业水文人员获取更多洪水信息,对预测结果进一步校准。
4 结论
本研究针对当前水文数据的利用方式缺乏业务逻辑,通过以洪水预警预报为目标,开展水文数据自动化整合,并以广西玉林市为研究区域,构建了集数据处理、预测预报和分析评价等功能于一体的智能化水文信息处理服务体系。系统采用B/S架构,通过实时采集遥测雨水情数据,采用多元回归经验预报模型,实现辖区所有水文站洪水“一键式”自动化、批量化预警研判;并根据江河防洪指标开展超警评价,以文字和声音方式报警提示。通过面向目标的自动化数据整合,打通了水文数据与目标产品的自动化通道,大大减少了预报人员的工作量,同时最大限度延长辖区洪水预见期。
