基于机器学习的大学生简历数据分析
2022-01-14汤英洹王佳玟
李 俊,郑 阳,汤英洹,王佳玟
(湖南工程学院 电气与信息工程学院,湖南 湘潭411104)
就业是最大的民生,而高校毕业生是国家的重点人才资源,因此促进毕业生高质量就业成为高校的重要任务[1]。据统计,2021 届毕业生人数达到909 万[2],比2020届毕业生人数多出35 万,大学生就业形势日益严峻。对此,有针对性地提高大学生就业率是有必要的。作者通过日常工作和研究各类文献发现大学生从制作简历到就业,时间间隔短,一些学生没来得及等到教师指导就已经找到工作,签订三方协议。这样会导致部分学生走弯路,签了并不适合自己的工作岗位,不利于学生的高质量就业。本文提出一种新的方式,辅助教师对毕业生进行就业指导,提高工作效率。总体流程为,首先收集大学毕业生就业指导课提交的电子简历,再建立数据提取模型将简历数据以结构化的形式保存在数据库中,最后建立工作推荐模型,为每个毕业生推荐适合自己的工作,促进大学生高质量就业。
1 基于机器学习的简历数据分析总体框架
基于机器学习的简历数据分析总体包括三大部分,首先是电子简历信息的抽取,其次是简历信息的数据挖掘,最后是工作推荐模型的评估。如图1 所示收集电子简历后,利用Python 编写程序建立简历信息抽取模型,将单个简历中的个人基本信息(姓名、性别、电话、出生日期、毕业时间等)、求职意向、实习经历、组织活动经历、获奖证书等信息提取出来,放入MongoDB 数据库中进行储存。将学生的简历数据都存入数据库后,编写Python 程序依次读取每份简历的信息,进行特征选择和预处理后,实现基于内容的互惠就业推荐算法[3],将简历中的信息与企业招聘需求信息进行相似度计算[4],再进行个人和企业的匹配推荐。如学生简历中的实习信息能够展现出学生的工作能力和相关企业的胜任力。企业招聘信息展示工作内容的部分是招聘职位信息中的“职位描述”。企业在进行人才选拔时,通常会考虑到学生的实习经历是否与工作职位所匹配,如果在同一条件下,那匹配度高的简历必定会受到企业人力资源部门的重视。建立工作推荐模型后,需要对模型进行评估,将数据集分为两部分,一部分占总数的80%为训练集,另一部分占总数的20%为测试集,模型先通过训练集的数据进行训练学习,再通过测试集来测试模型的预测准确率。评估完成后可以将模型应用于大学生就业指导中。

图1 简历数据分析总体流程图
2 建立数据抽取模型提取电子简历数据
提取电子简历的数据主要有两种方法,一种是基于规则的提取方法[5],通过编写正则表达式确定规则进行提取,这种方法提取信息的准确率高,适合简历中的个人基本信息提取;另一种是基于统计的提取方法[6],这种方法会结合全文的词语关系,提取信息的准确率也较高,适合简历中的实习经历、组织及活动经历、获奖证书等信息提取。针对电子简历中不同区域的数据不同,选择不同的提取方法,作者通过Python 调用pandas、numpy、re 等库将两种自然语言抽取方法结合起来,用于抽取电子简历中的数据。
2.1 大学生电子简历信息特征分析
为了建立完善的简历抽取模型,首先需要对大学生的简历数据类型进行分析。通过查阅相关资料和审阅大量学生简历,发现大学生简历的内容主要有个人基本信息、教育经历、求职意向、实习经历、项目经验、组织及活动经历、获奖证书和其他信息八个模块。如表1 所示,每个模块都包含了不同的属性信息,如个人基本信息模块包括学生姓名、性别、电话、出生日期、毕业时间等属性信息,组织及活动经历模块包括组织名称、担任职务、时间、组织活动内容等属性信息。分析得出八个简历模块中有个人基本信息、教育经历、获奖证书三个模块的规则性比较强,利用基于规则的数据提取方法比较合适,而实习经历、组织及活动经历、项目经验等模块用基于统计的数据提取方法更合适。

表1 简历模块和属性信息定义
2.2 大学生电子简历数据信息预处理
在对简历信息特征进行分析后,还需要对电子简历数据信息进行预处理。第一步,利用Python 编写程序,将电子简历上的数据信息转化为文本信息的形式,保存到CSV 文件中,这样减少了不同简历带来的不同格式影响;第二步,利用Python 的pandas 库函数的read_csv 方法读取CSV 文件信息,导入re 库编写正则表达式将空格、感叹号等标点符号去除;第三步,利用Python 的segment 方法来实现NLP 分词,对去除了标点符号的文本数据进行进一步处理,这里NLP 分词还会同步执行命名实体识别和词性标注,命名实体识别能将文本数据中的命名实体识别出来,如简历中的专业、姓名、地址名等,而词性标注可以给句子里的词语进行词性标注;第四步,由于简历文本信息中也会存在形容词、助词等没有意义的词,所以对其进行去停用词操作是有必要的,作者编写Python 程序依次遍历NLP 分词后的词语,与哈工大停用词表进行比对,如果出现了停用词则去除。
2.3 大学生电子简历信息抽取模型建立
建立简历信息抽取模型前,还需要对文本信息进行分块,将同一模块属性信息归为一类,作者使用的是SVM 算法[7],利用Python 编写程序,从sklearn 机器学习库导入SVM 支持向量机模块,设置SVM 分类器中的decision_function_shape 参数为ovo 实现一对一分类,即对任意两个类别之间进行划分,这样提高分块的准确性,最后通过调用accuracy_score 方法计算准确率。
利用SVM 算法分完块后,根据特征分析的结果,作者采取基于规则和基于统计模型相结合的方法建立简历信息抽取模型。首先,作者将利用正则表达式构建抽取规则,对简历模块中的个人基本信息、教育经历、获奖证书和求职意向四个模块中的属性信息进行提取,如姓名、专业、学校和GPA 等属性。提取完规则性强的模块后,作者将利用HMM 算法模型[8]抽取实习经历、活动经历和项目经验等模块的属性信息,由于Python 的机器学习库里面包含的HMM 算法模型已不能使用,所以作者从hmmlearn 库中导入hmm 方法,实现对规则性弱的文本信息的提取,如实习经历中的实习内容、实习成果等。
大学生电子简历信息抽取模型建立后,作者收集300 份大四毕业生简历用于检测模型的准确率,如图2所示,简历数据抽取准确率测试情况,从表中可以看出个人基本信息和教育经历模块的平均准确率、平均召回率和平均F1 值,明显比实习经历的三个值高,说明正则表达式提取的信息较为准确,而实习经历、组织及活动经历等文本信息因为含有实习内容、活动内容、组织及活动取得的成果等复杂信息,提取的信息准确率较低,有待改进HMM 算法模型。简历数据抽取模型中各个简历模块的平均准确率、平均召回率和平均F1 值在80%以上,说明模型整体上准确率较高。
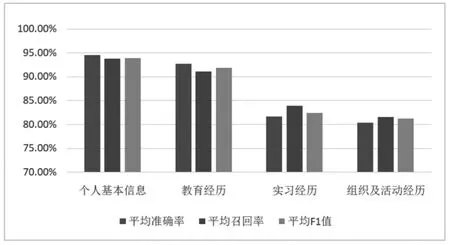
图2 简历数据抽取准确率测试情况
3 建立大学生工作推荐模型
大学生工作推荐模型的建立能给大学就业指导相关教师提供辅助决策,有利于教师更好地因材施教,针对每个学生的特点提出适合该学生的职业发展路线,进行全方位的就业指导。作者通过简历数据抽取模型将学生简历的数据提取到MongoDB 数据库中,为后续模型的建立提供数据源。
3.1 建立用人单位招聘信息库
为了让每份简历数据与用人单位匹配,还需要建立用人单位招聘信息库。作者利用网络爬虫从学校就业网站、智联招聘等平台上爬取企业招聘信息,主要爬取的字段有公司名、岗位名、薪资待遇、工作内容和地点等。经研究发现大多数网站上的招聘信息都保存在网页的json 字符串中,这样首先通过调用Python 的requiests、beautifulsoup4 库,编写网络爬虫程序提取数据,再利用json 模块的loads 方法对json 字符串进行解析。最后将爬取完的数据保存至MongoDB 数据库。
3.2 基于内容的互惠就业推荐算法
由于传统的推荐算法并没有综合应聘者和岗位之间的关系,而是单纯地用传统推荐算法导致匹配准确率很低[9],如有些学习成绩一般、项目经验少、能力较弱的学生匹配到工作岗位要求高、实力强的企业,这样会导致学生投递简历后,收不到企业的回复,而造成一定程度上的心理压力。对此,作者使用随机森林算法[10]构建互惠就业推荐模型,互惠就业推荐是综合了学生和企业的需求来进行匹配的[11]。
如表2 所示,学生意向对应招聘岗位信息的不同属性值,将学生满意度设置为X1,选择企业地点、岗位名称、企业类型和岗位薪资水平四个特征属性作为学生满意度属性,利用Python 调用sklearn 机器学习库的RandomForestClassifier 方法,利用随机森林算法计算学生的满意度,并设置权重为W1。同理,作者选取政治面貌、学历、专业和薪资水平作为企业满意度属性,设置为X2,利用随机森林算法计算出X2值,设置权重为W2。总满意度X 的计算公式为:

表2 招聘岗位信息和学生意向属性值对应图

计算完一份简历数据与一条招聘信息的X 值后,作者编写for 循环遍历每条招聘信息,计算出该份简历与每条招聘信息的X 值,再将X 值从大到小排列后输出前五个值,这五条招聘信息更适合这份简历的学生。通过观察发现匹配度高的几条招聘信息都有共同的特征,如求职意向为电气工程师、意向工作地点为浙江、意向工作性质为民营企业、意向薪资区间为4K-7K 的学生匹配出的五条招聘信息都是浙江当地电气类的名企,招聘岗位、薪资待遇都比较符合学生简历所写。
3.3 大学生工作推荐模型评估
基于随机森林算法的互惠就业推荐模型建立后,还需要进行测试评估。作者通过计算MAE 平均绝对误差,RMSE 方均根误差来评估推荐模型的准确率[12]。为了进行对比,作者用传统推荐算法实现了基于内容的推荐就业模型。在数据方面,由于目前没有标准的简历推荐数据集,因此作者针对200 名大四学生做了问卷调查,收集简历电子版和投递的岗位信息,以这些数据信息作为实验数据集,其中160 份数据作为训练集,40 份作为测试集。
运行简历数据抽取模型提取简历数据到MongoDB数据库Data1 中,编写程序从Data1 库中读取电子简历训练集数据,再运行基于随机森林算法的互惠就业推荐模型和传统推荐算法模型,两个模型训练完成后,使用测试集数据分别进行测试,并计算MAE 平均绝对误差值和RMSE 方均根误差值。如图3 所示,从图中可以明显看出互惠就业推荐模型和传统推荐模型的MAE 值都是先下降后上升最后趋于稳定状态的,而经过实验两种模型的RMSE 值趋势也和MAE 值一样,并且互惠就业推荐模型的RMSE 值更低,相比传统推荐模型有一定的优势。

图3 MAE 值对比折线图
4 结论
在本文中,作者建立了简历数据抽取模型,能够快速地提取学生的电子简历数据,并以结构化的形式保存在数据库中,为教师查阅简历节省了大量时间,教师能清晰地看到每个学生的简历关键点,有更多的时间用来指导学生就业。而后续作者建立的基于随机森林算法的互惠就业推荐模型能有效地为学生提供合适的就业方向。两种模型结合使用,能让教师更全面地了解学生就业需求,有针对性地进行就业指导。
