基于孪生区域建议网络的无人机目标跟踪算法
2022-01-14杨帅东谌海云徐钒诚赵书朵袁杰敏
杨帅东,谌海云,徐钒诚,赵书朵,袁杰敏
(西南石油大学电气信息学院,成都 610500)
0 概述
在智能化时代,无人机被广泛应用在无人驾驶、航空拍摄、交通监控[1]、农药喷洒、目标跟随、人机交互[2]、自动驾驶等领域。无人机目标跟踪是基于视频图像对感兴趣区域进行筛选和定位的技术。在复杂场景下,无人机图像跟踪受光照、遮挡、小目标迅速移动等影响,导致跟踪效果不佳,因此,提高其稳定性及可靠性成为当前的研究热点。
无人机跟踪目标移动迅速且跟踪目标通常较小,存在目标遮挡的问题。视觉跟踪是根据当前视频图像第一帧[3]给出的边界框,准确估计目标对象在后续帧中视频图像位置的过程。目标跟踪算法有均值漂移算法[4]、光流法等。基于相关滤波的目标跟踪算法起源于MOSS[5]算法,其将相关滤波引入目标跟踪算法中,CSK[6]算法引入核循环矩阵,通过计算高斯核相关矩阵判断相邻两帧之间的相似度,进而实现目标跟踪。KCF[7]算法引入核技巧以及多通道特征处理方式进行目标跟踪,大大简化了在跟踪过程中的计算量,奠定了相关滤波目标跟踪算法的理论与实践基础,例如SAMF[8]、DSST[9]、SRDCF[10]、BACF[11]、STRCF[12]等。文献[13]提出的AlexNet 网络,是深度学习发展的重要阶段,深度学习中以SiamFC[14]为代表的相关目标跟踪算法在精度和速度取得很好的平衡,采用全卷积神经网络结构,通过模板帧与测试帧匹配进行相似性度量,对目标进行后续定位。SiamRPN[15]在SiamFC 的基础上通过加入区域候选网络(Region Proposal Network,RPN)解决原始的多尺度问题。很多工作都是基于SiamRPN完成,以提高模型的泛化和判别能力,DaSiamPRN[16]在训练阶段不仅扩大训练数据,而且加入不同类别和相同类别的困难负样本以提升跟踪性能。SiamDW[17]对特征提取主干网络进行加深,如ResNet[18]、VGG[19]、ResNeXt[20]等,使得VGG 等网络可以提取更深层次的语义信息。文献[21]提出SiamRPN++网络以解决绝对平移不变性的问题,采用空间感知采样策略打破空间不变性。SiamC-RPN[22]级联多个RPN 网络,加深网络结构以充分利用深层与浅层特征信息,使得对目标的定位和检测框的回归更精确。但是这些孪生网络都是在加深网络的基础上进行特征提取,没有充分考虑到网络本身的空间特征信息和上下文联系,跟踪精度的提高主要依赖网络深度和模型复杂度,导致网络更为复杂,大辐降低模型的跟踪速度。
本文考虑空间语义信息对网络的影响,基于SiamRPN 算法提出一种新的目标跟踪算法DAPSiamRPN。通过加入通道注意力机制和条带空间池以提升跟踪的精确率和成功率,并优化原始算法中交并比计算方法,运用距离交并比机制解决目标预测框训练发散问题。
1 相关工作
1.1 孪生网络目标跟踪算法
在目标跟踪中,孪生网络目标跟踪算法通过模板帧与测试帧的相似性匹配,完成最终目标跟踪任务。因卷积神经网络(Convolutional Neural Network,CNN)对视频图像特征提取表现较优,推动计算机视觉对各类任务的发展。近年来,CNN 被广泛应用在目标识别、检测和视频分割中,CNN 预训练一个模型,将训练好的模型应用在图像处理中。
AlexNet 网络推动了深度学习的发展,SiamFC的出现推动了目标跟踪领域从相关滤波到深度学习的蔓延。将ImageNet[23]作为训练数据完成模型训练,通过全卷积神经网络对图像进行目标特征提取以完成后续跟踪任务。首先,对第一帧视频图像进行剪裁作为模板的提取,提供目标准确位置;其次,在后续视频帧中进行候选区域搜索,匹配响应最大的目标框得分;最终,孪生网络利用相似性学习函数进行模板匹配,得出最终目标的真实位置,完成跟踪任务。相似性学习函数如式(1)所示:

其中:x、z分别为目标模板图像和目标搜索区域图像;*为图像卷积操作;bI为图像中每个位置的值;φ为由神经网络进行特征提取。函数的输出并不是一个纯向量,而是有空间信息的特征映射。由于在训练过程中正样本较少,不可避免会出现过拟合现象,边界框并没有进行回归调整。因此,在跟踪过程中易发生目标的漂移。
虽然在训练阶段孪生网络会进行大量计算,消耗较多时间,但训练出的模型在跟踪过程中具有较高的快速性和准确性,是研究者未来重点研究方向。因加入边界框的回归,SiamRPN 的出现取得了良好的跟踪效果,但并没有考虑网络本身对空间信息的利用。因此,在目标发生光照变化、背景干扰、遮挡等问题时,模型会发生目标漂移情况。
1.2 通道注意力和空间池化网络
注意力机制主要分为通道注意力机制和空间注意力机制。通道注意力机制是在不同任务中找到不同功能间的相关性,并突出一些重要功能。在跟踪过程中,高层卷积可以将每个通道视为一种分类任务,各通道间存在相互依赖关系,通过调节各通道间所占比重,使其相互建立依赖关系进而加强对目标特征的提取。空间注意力机制主要对特征图中每个位置的特征信息进行加权,然后将输入特征信息与加权后的位置信息进行相乘或相加,进一步加强目标特征的提取能力。传统孪生网络并没有考虑网络中通道信息和空间位置信息对目标特征提取能力的影响,常采用更深层次的卷积结构增强目标特征的提取。在跟踪过程中,因图像需要进行填充操作,在特征提取时会导致网络平移不变性[21]被破坏。同时,加深网络结构和提升模型的复杂度将大辐降低模型的跟踪速度。
注意力机制能够捕捉时空上下文的依赖关系,对空间维度信息与特征维度上的信息进行融合,以提取视觉场景中的局部或全局信息,广泛应用在目标检测、目标分割、语义分割等领域[24-26],在图像中对每个像素点分配语义标签,扩大网络的感受野。但是,传统的注意力网络很难对各种场景进行优化,自注意力机制[27]优化传统注意力网络中远程上下文依赖关系,会引入大量的计算和内存消耗。用于远程上下文建模的方法[28]主要通过扩张卷积扩大网络的感受野。
因此,在网络中加入条带池[29]和全局上下文模块,在减少计算量的情况下,有效建立远程上下文关系,扩大主干网络感受野,完成区域建议网络前景与背景的分类和边界框的回归。
1.3 基于交并比边界框计算
交并比主要计算预测边界框与真实边界框之间交集与并集的比值,也是在边界框的回归任务中,判断边界框与真实边界框距离最直接的指标,常用于目标检测中。泛化交并比[30]优化传统交并比的计算方法,考虑重叠框对结果的影响,但是会出现在训练过程中发散的情况。距离交并比[31]可以有效缓解交并比出现在目标检测中训练发散的问题,将最小的预测框与真实边界框进行归一化计算,使回归的边界框更精准。本文通过改进交并比的计算方法,在训练跟踪阶段能够有效缓解对边界框选择的问题,在训练过程中,可以得到精准的交并比计算,使得网络在非极大化抑制过程中筛选出精准的预测框。
2 基于SiamRPN 的UAV 跟踪算法
2.1 DAPSiamRPN 网络结构
单目标跟踪DAPSiamRPN 网络结构如图1 所示。网络中2 个输入图像尺寸分别为127×127×3 和255×255×3,网络中包含孪生网络进行特征提取和区域建议网络进行边界框的预测,区域建议网络包含2 个子网络:1)进行前景和背景的分类网络;2)进行边界框的回归网络。整个网络结构可以进行端到端的训练。在搜索分支上通过加入轻量级的全局上下文网络块提取全局上下文信息,用于边界框的回归。在模板分支中,加入轻量级条带池化捕捉上下文空间信息,用于区域建议网络目标与背景的分类和边界框的回归,使得主干网络能够长期依赖目标模板提取出特征。因此,本文对交并比计算策略做出改进,运用距离交并比方法,针对重叠面积、中心点距离以及长宽比3 种度量方式进行优化选择,选取更精准的预测框,完成无人机的跟踪任务。

图1 DAPSiamRPN 网络结构Fig.1 Structure of DAPSiamRPN network
2.2 注意力机制
注意力机制利用CNN 进行场景解析或语义分割,但是通过堆叠局部卷积或池化操作使得CNN 感受野增长缓慢[29],因此网络中不能考虑足够有用的上下文信息。本文引入条带池化操作,针对目标特征提取进行空间维度加权,使得网络对目标位置自动分配较大比例的权重,增强网络对目标的判别能力,使网络进一步解析跟踪场景。
首先在标准的平均池化中,x∈RH×W表示输入的二维张量;H和W分别表示空间的高度和宽度;然后进入平均池化层,h×w表示池化窗口大小,得到输出y,其高和宽为H0=H/h,W0=W/w,平均池化操作如式(2)所示:
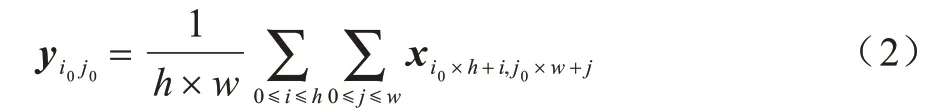
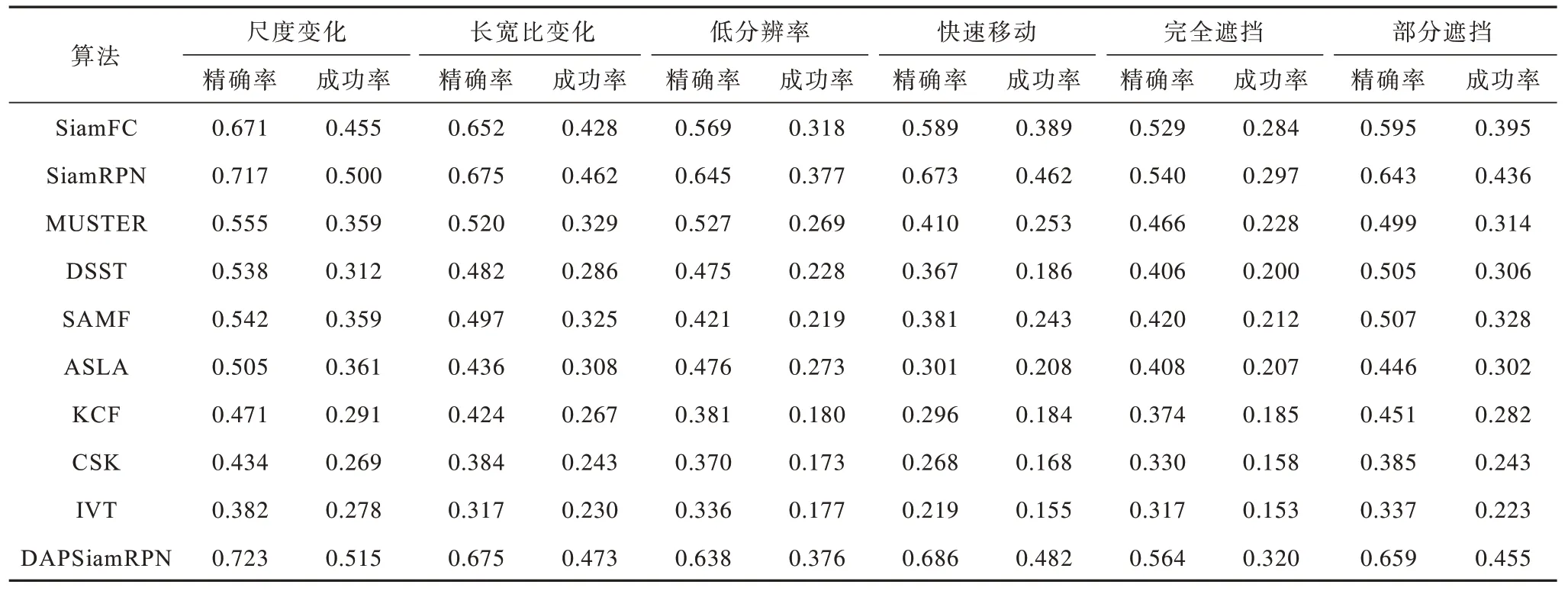
其中:0 ≤i0 同样的,条带池化在水平方向如式(4)所示: 通过长且窄的内核建立远程上下文关系,扩大主干网络的感受野并利于跟踪过程中目标和背景的分类,因此,条带池化使得孪生网络在跟踪过程中捕捉上下文关系,条带池模块结构如图2所示。 图2 条带池模块结构Fig.2 Structure of strip pooling module 输入x∈RC×H×W,其中C表示通道数。首先,将x输出到水平和垂直路径上内核大小为3 的一维卷积,用来调制当前位置和相邻位置信息,得到有用的全局先验信息,在水平和竖直方向上得到yh∈RC×H以 及yV∈RC×W,扩大感受野之后,最终输出ZV∈RC×H×W,然后将yh和yV合并在一起,得 到y∈RC×H×W,即: 最终得到输出z,如式(6)所示: 其中:Sc函数为逐元素相乘,是一个sigmoid 激活函数;f为1*1 卷积,在条带池的池化窗口中分别设置池化尺寸为16×16 和12×12。在每个卷积层的过程后,条带池都通过批标准[32](Batch Normalization,BN)进行归一化处理,ReLu 非线性激活函数在最后一层。 在检测模板中,为了更好地建立网络远程上下文的依赖关系,在当前无人机跟踪场景中加深网络的全局理解能力,在检测模板的孪生网络中将全局上下文网络块加入到区域建议网络中,能自动提升与目标特征相关的通道比重,同时降低与目标特征无关的通道比重,改变不同通道间的依赖性,使得边界框回归更精准。全局上下文模块结构如图3所示。 图3 中C为网络通道数,H和W分别为输入特征图的高和宽,×为矩阵相乘,+为矩阵相加,r为通道压缩比。在实验中,C表示通道数256,高和宽分别为22 和22,r表示4。 图3 全局上下文模块结构Fig.3 Structure of global context module 首先,在上下文建模部分,在网络中将C×H×W特征图进行1×1 的卷积,将通道压缩为1,将一个通道上整个空间特征编码为一个全局特征,得到1×H×W特征图;然后将此特征图进行重新调整为HW×1×1,通过softmax 全连接层,得到HW×1×1 注意力权重;最后与调整过的原始特征图进行全连接层后注意力权重的矩阵相乘,得到上下文模板的输出。在下面的通道转化部分类似于文献[25]中所述,完成信息转换,并且给各个通道分配相应的上下文信息,建立通道之间的依赖关系,通过1×1 卷积在通道之间建立联系,C通道数压缩到C/r,经过归一化和非线性激活层(ReLu),可以提升模型的泛化能力和增强模型的非线性,有利于网络的训练和优化,然后在进行1×1 的卷积层,将通道数重新转换为C,在此过程中,计算量和参数量被减少,最终C×1×1 以广播的形式发送,与原始特征图进行元素之间的相加,如式(7)所示: 通过上下文模块后得到一个权重向量α,经过卷积层与非线性激活函数得到最终分配的通道集合,如式(9)所示: 边界框预测直接影响视频跟踪的性能,交并比(IOU)是目标检测常用的指标,不仅可以区分正负样本,而且还可以评估输出边界预测框和目标真实边界框的距离,如式(10)所示: 其 中:B=(x,y,w,h) 为输出的预测框;Bgt=(xgt,ygt,wgt,hgt)为真实的边界框;x和y分别为边界框的中心坐标;h和w分别为边界框的高和宽。由于将区域建议网络加入到跟踪网络中,因此交并比的计算可以很好反映跟踪过程中预测框和真实框的效果,并进行后续跟踪指标的评估。 本文算法将交并比改进为距离交并比计算,使预测出的边界框更符合网络回归机制,距离交并比示意图如图4 所示。 图4 距离交并比示意图Fig.4 Schematic diagram of distance and intersection over union 考虑到目标和边界框之间的距离、重叠率以及尺度变换,使得回归框更稳定,在训练过程中避免原始交并比出现发散问题,距离交并比(DIOU)如式(11)所示: 其中:ρ为预测框和真实框之间的中心点距离;b和bgt分别为预测框和真实框的中心点;c为预测框和真实框相交后的区域对角线距离。 本文算法区域建议网络分类分支的损失函数中交叉熵损失和回归分支的损失函数为L1 范数损失,将Ax、Ay、Aw、Ah分别表示预测边界框的中心坐标和宽高,Tx、Ty、Tw、Th表示真实边界框的中心点坐标和宽高,进行正则化处理,如式(12)所示: 因此,平滑(so)L1 损失函数如式(13)所示,回归的总损失函数如式(14)所示,在训练过程中总的损失函数如式(15)所示: 无人机跟踪流程如图5 所示,主要步骤如下:1)加载DAPsiamRPN 预训练网络,判断网络是否为第一帧图像,在输入图像中提取视频第一帧图像大小为127×127×3 作为模板分支的输入,将图像大小为255×255×3 作为搜索分支的输入;2)将输入的模板分支图像和检测分支图像经过DAPSiamRPN 网络中,在区域建议网络的分类分支和回归分支中进行互相关运算,生成最后的响应2k个特征图和4k个回归的边界框,实验中k值为5,得到目标和背景的分类得分,通过边界框的回归,优化边界框的大小,得到目标的位置;3)在后续的视频图像中,扩大搜索区域,通过检测分支找到与上一帧视频图像响应最大的特征图,进行后续跟踪。如果跟踪模板需要更新,则重复上述步骤。最终判断是否为最后一帧图像,如果是,则跟踪结束。 图5 无人机跟踪流程Fig.5 Tracking procedure of UAV 实验平台为ubuntu16.04 LTS 系统,运用pytorch1.4版本的深度学习框架,设备为Inter Core i7-9700F CPU 3.00 GHz×8,采用单GPUGeForce GTX 2060Super 8 GB。 本文实验的训练数据是从ILSVRC2017_VID[23]数据集和Youtube-BB[33]数据集中提取符合跟踪场景的视频数据,在ILSVRC2017_VID 数据集中提取44 976 个视频序列,从Youtube-BB 数据集中提取904 个视频序列,共有一百多万张带有真实标签的视频图像,训练过程中采用Alexnet 网络作为预训练模型,并且作为主干网络进行视频图像的特征提取,然后进行20 轮训练,每轮进行12 000 次迭代,训练总时长为13 h,采用随机梯度下降法,动量设置为0.9,为防止训练过程中出现梯度爆炸,梯度裁剪设置为10,设置动态学习率从0.03 下降到0.00 001,候选框采用5 种比例分别为0.33、0.5、1、2、3。在视频第一帧时送入模板分支进行模板采集,后续帧都是经过搜索分支送入区域建议网络进行分类和回归,得到响应最大的位置及所在的边界框,为后续帧的跟踪做准备,最终完成整个跟踪任务。 为验证本文算法的有效性,本次实验测试数据选取UAV123[34]数据集,UAV123 数据集是无人机在低空状态下所采集的数据,具有123 个视频序列,总量超过1.1×105frame,包含各种各样的跟踪场景,例如人、船只、汽车、建筑等。涉及到多种属性的变化,例如光照变化、尺度变化、快速移动、背景模糊、背景遮挡等12 种不同类型。在跟踪过程中无人机常出现相机抖动、尺度多变以及跟踪场景和相机拍摄角度不一致的情况,导致跟踪困难,具有很大难度的挑战性。跟踪性能主要有成功率和精确率两个评价标准,成功率是指边界框与真实标注的边界框的重叠面积大于所设定的阈值占当前视频图像总边界框数量的比例,精确率是指边界框距离真实边界框的中心误差小于所设定阈值占当前视频图像总边界框数量的比例。 本次实验中当交并比设定大于0.6 时,视为正样本,小于0.3 时视为负样本,在一个视频图像中计算从边界框选出的候选边界框有1 805 个,由于数量过大,因此在一组训练过程中限制总样本数量共为256 个,正样本数量与负样本数量比例为1∶3。本文算法在无人机数据集测试时长为1 064 s,帧率约106 frame/s,原始SiamRPN 测试时长为1 066 s,帧率约为106 frame/s,本文算法比原始算法快2 s。 为验证本文算法(DSPSiamRPN)在背景模糊、光照变化等情况下的有效性,将本文算法与当前9 种目标跟踪算法进行结果对比,包含SiamRPN、SiamFC、KCF、CSK、SAMF、DSST、SAMF、ASLA[35]、MUSTER[36]、IVT[37]算法。实验测试数据为UAV123 数据集,不同算法的实验结果如表1 所示。 表1 在光照变化和背景模糊场景下不同算法的实验结果对比Table 1 Experimental results comparison among different algorithms on lighting changes and blurred background scenes 相比原始单目标跟踪算法SiamRPN,本文算法在背景模糊下精确率提升6.45%,成功率提升11.63%,在光照变化情况下,精确率提升5.87%、成功率提升10.09%,本文算法同样优于其他目标跟踪算法。在模板分支中加入条带池模块,可以加强空间语义对主干网络的依赖性,以适应光照的变化。同时在搜索分支中加入上下文网络块输入区域建议网络的回归,加强网络对全局上下文的理解能力,使回归的边界框更精准,因此在背景模糊和光照变化较大的情况下,本文算法具有很好的跟踪效果。 本文与所有算法的对比均在UAV123 数据集上进行测试,测试数据有123 个视频序列,共有12 个不同场景的属性,实现跟踪的成功率和精确率对跟踪结果进行定量分析,本文算法的成功率达到0.542,精确率达到0.754。因此,在不同场景下本文算法相比SiamRPN算法的处理能力较高,与SiamRPN 算法均有较好的泛化能力,在其他测试数据集上也同样适用。在各场景不同算法的实验结果对比如表2 和表3 所示,本文算法在尺度变化、目标快速移动、部分和完全遮挡、相机抖动等场景下均表现出较好的性能,尤其是在背景干扰和光照变化场景下体现出较大的优异性。 表2 在尺度变化、长宽比变化等场景下不同算法的实验结果对比Table 2 Experimental results comparison among different algorithms on scale variatio,aspect ratio change and other scenes 表3 在超出视野、视野变化等场景下不同算法的实验结果对比Table 3 Experimental results comparison among different algorithms on out of view,viewpoint change and other scenes 从表2 和表3 可以看出,在11 种不同属性的场景下,本文算法具有良好的精确性、稳定性和鲁棒性。在算法中加入轻量级条带池和全局上下文模块进行网络建模,能够较好地适应跟踪场景的变化,并不影响网络训练时长和跟踪效果。条带池沿着水平和竖直两个方向部署长而窄的内核,能够捕捉到狭小区域的远程关系,有利于建立局部上下文信息,而且可以防止在跟踪过程中无关区域对前景和背景分类以及边界预测框的干扰,使网络能够同时聚合全局上下文关系。在区域建议网络回归分支,通过加入全局上下文网络块对回归边界框的预测有良好的稳定性和精确性。区域建议网络广泛应用在目标检测,因此,在跟踪中优化交并比的计算也同样重要。在网络训练过程中,运用距离交并比计算预测边界框和真实边界框之间的距离,重叠率以及尺度都考虑,使边界框的预测更准确,实现无人机目标跟踪效果达到良好的性能。 针对无人机视频目标跟踪过程易受光照变化和背景干扰的问题,本文提出一种基于SiamRPN 算法的无人机视频目标跟踪算法DAPSiamRPN,通过降低无人机跟踪场景中多变性对网络输出性能的影响并优化回归边界框提升跟踪器的性能。实验结果表明,相比SiamFC、SiamRPN、MUSTER 等目标跟踪算法,DAPSiamRPN 具有较高的精确率和成功率。后续将在不影响跟踪速度的前提下加入全局检测或局部检测过程,使算法在长时间遮挡和尺度变化大的情况下不易发生跟踪目标漂移的现象。





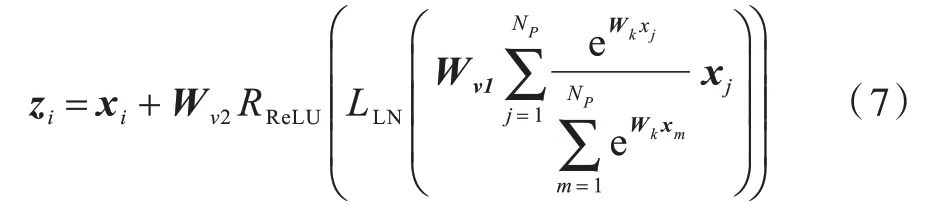

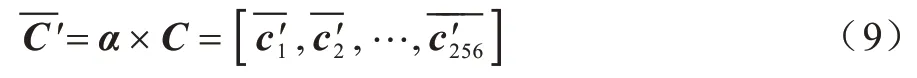
2.3 边界框预测优化





2.4 无人机跟踪步骤
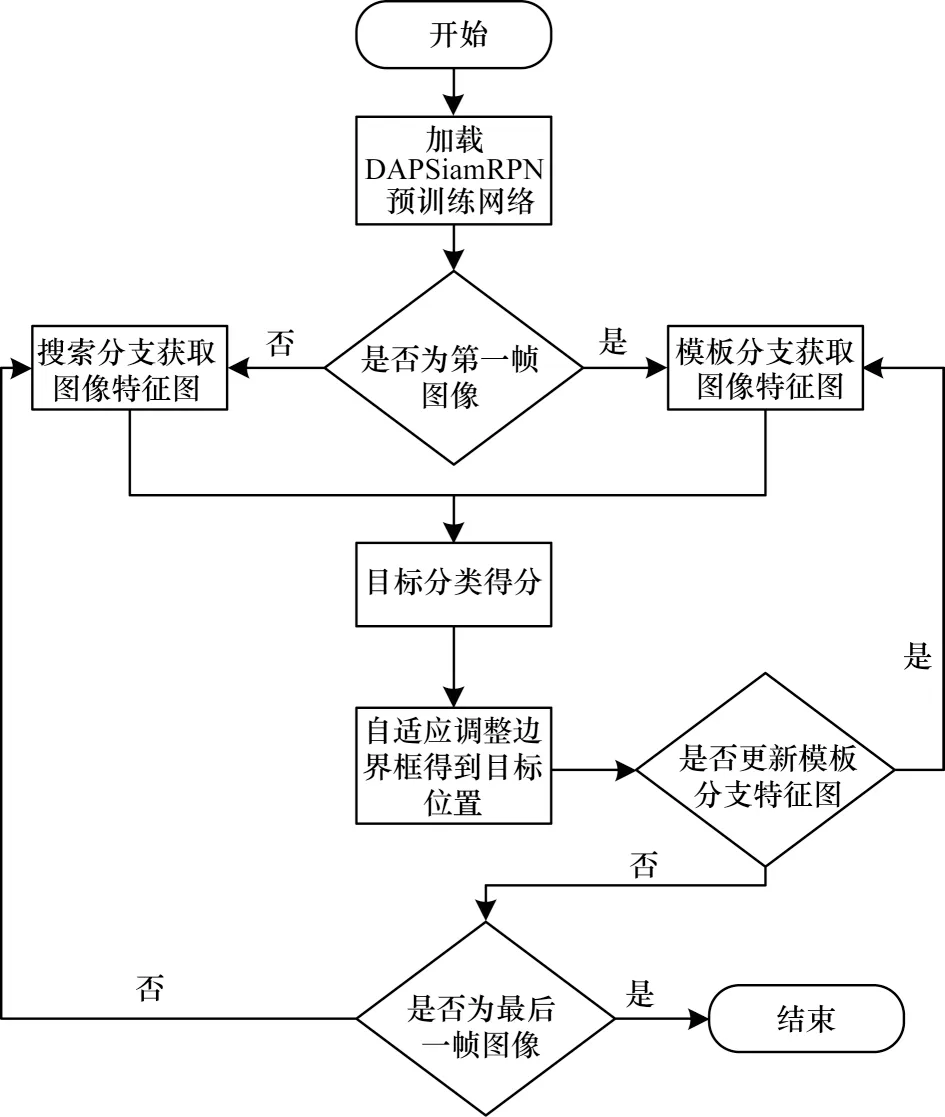
3 仿真实验
3.1 实验数据
3.2 实验结果分析


4 结束语
