基于联邦学习的无线网络节点能量与信息管理策略
2022-01-14杨文琦聂江天杨和林康嘉文熊泽辉
杨文琦,章 阳,2,聂江天,杨和林,康嘉文,熊泽辉
(1.武汉理工大学计算机科学与技术学院,武汉 430063;2.武汉理工大学交通物联网技术湖北省重点实验室,武汉 430063;3.南洋理工大学计算机科学与工程学院,新加坡 639798;4.新加坡科技设计大学信息系统技术与设计学院,新加坡 487372)
0 概述
无线通信网络的许多新兴智能应用都是基于机器学习技术,机器学习模型的训练通常需要大量数据集,而数据的收集在很大程度上依赖于分布分散的边缘用户节点[1]。由于传统的机器学习技术需要集中储存大量原始数据,因此数据持有用户会有隐私泄露的风险。随着大数据的日益发展,重视数据隐私和信息安全已成为了全球性趋势[2-4],数据的隐私问题已影响到无线通信系统中数据的有效收集,大多数行业数据已出现数据孤岛现象[5],如何在保护隐私的前提下高效收集分布式的数据成为研究热点[6]。
联邦学习是一种通过聚集局部计算的梯度来训练共享模型的分布式学习方法,这种新的机器学习范式使资源受限的客户端节点可在中央服务器的协调下训练数据并分享梯度信息,同时保持训练数据分散在本地,避免上传原始数据以致隐私泄露[7]。目前,研究人员对联邦学习的探究主要集中在提高差分隐私[8]、安全多方计算[9]等隐私保护技术[10]和降低通信开销[11-13]方面。文献[14]提出一种联邦强化技术,通过联邦学习减少移动边缘用户个性化的时间。文献[15]在仿真通信网络中部署联邦学习系统,说明联邦学习参与者的模型训练进度和贡献率。传统的联邦学习框架严格禁止原始数据共享,一般使用安全级别较高的差分隐私等方法进行加密,但联邦学习对于隐私保护的过分严苛也降低了训练数据的可用性,从而降低模型的部分准确率[16]。文献[17]指出,在部署联邦学习框架的无线通信网络中,数据隐私性与可用性的平衡是亟待解决的问题。除此之外,能量供给是客户端节点在信息感知和数据处理方面完成高质量服务的关键[18],如果选择节点作为联邦学习的参与者,则需消耗自身大量的能量以确保采集到合适的数据并在本地顺利训练模型[7]。随着无线能量收集和传输技术的发展,客户端节点可以通过无线能量源充电[19],但同时也需向能量源支付相关费用。随着互联网的高速发展,节约能源并使之可持续性发展早已成为主要问题[20]。因此,联邦学习虽然减轻了传统机器学习集中式训练方法带来的隐私风险和开销[21],但对客户端节点的能量、计算能力以及模型训练效果提出了挑战,在一定程度上影响了无线通信系统数据收集与使用的效率。
分布式数据的收集与训练除了需要满足保护隐私和降低能耗的要求,还面临着无线网络中的不确定性。在下一代5G 通信网络[22]不断发展的背景下,分布式系统训练模型借助移动信息采集设备对较为偏僻的数据持有用户进行数据收集与训练已经成为主要方式。类似无人机[23]、无线传感车辆[24]的高移动性新型网络成员,在辅助无线通信网络收集信息和训练数据的同时,它们移动灵活的特性也给无线通信网络的信息收集和机器学习训练带来了不确定性和安全隐患,例如,客户端节点一般只有当信息采集设备在其通信范围内才能传送数据,当信息采集设备有其他任务离开后,该节点则无法传送数据[25],这给通信网络的管理增加了一定的难度。此外,移动信息采集设备在无线传输中的消息可能会被攻击者窃听,从而导致敏感信息泄露[26]和自身信誉下降,影响其与边缘用户节点的合作。如果无线通信网络无法应对移动信息采集设备带来的不确定性和隐私安全挑战,就无法吸引拥有高质量和大型数据集的边缘用户传输自身的数据,使某些边缘用户的数据处入孤岛状态。因此,在无线通信网络中,资源受限的客户端节点亟需一种可克服无线网络信息传输带来的不确定性、兼顾数据可用性和隐私性的能量与信息管理策略。
本文针对移动信息采集设备辅助的无线通信网络场景,提出一种基于联邦学习的信息传输与能量管理组合优化策略。将通用性较高的移动信息采集设备作为学习服务器,将客户端节点作为学习参与者,并为客户端节点构建马尔科夫决策模型,通过平衡数据可用性、用户隐私以及能量消耗之间的关系,得出客户端节点的信息传输与能量管理组合优化策略。
1 问题描述
1.1 系统模型
联邦学习因其严格的隐私保护机制成为解决无线分布式系统数据无法有效收集问题的有效框架。针对基于传统联邦学习框架工作的客户端节点存在数据可用性较低以及能耗较大的问题,本文在无线通信网络场景下提出一种将联邦学习与传统集中式学习相结合的优化架构,如图1 所示。
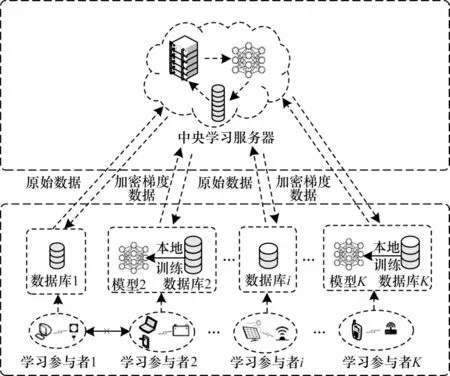
图1 基于联邦学习的优化架构Fig.1 Optimization framework based on federated learning
传统的联邦学习和集中式学习架构都是由上层的中央学习服务器和下层的学习参与者两个类型的实体组成。在传统的联邦学习架构中,每个学习参与者在本地模型训练后仅向学习服务器发送训练后得到的加密梯度数据,再由服务器解密聚合后统一将梯度数据回传给学习参与者。在此过程中服务器不接触原始数据,因此,联邦学习架构起到了保护用户隐私的作用。本文所提架构通过保留联邦学习的基础分布式架构和工作原理以保护客户端节点的隐私。但联邦学习需要能量有限的客户端节点消耗自身算力训练数据,数据加密压缩的过程对于数据的可用性也有一定的损耗。在传统的集中式学习中,学习参与者将自身的原始数据直接交由服务器训练。此过程中学习参与者需要承担泄露隐私的风险,并且传输大量原始的数据对信道的要求较高,数据最终传输成功概率受外部环境的影响,但这种学习方式仅在传送数据时消耗自身能量,且原始数据的可用性较高,因此,传统的集中式学习起到了降低能耗、保证数据可用性的作用。
本文为探究无线网络场景下信息采集的随机性对客户端节点的信息传输以及学习选择的影响,为联邦学习架构中的学习服务器加入了移动属性,将移动信息采集设备作为学习服务器。对于客户端节点,在移动服务器随机的信息采集场景下得到可平衡自身能耗、数据可用性和隐私性的信息传输与能量管理策略,但最终所得的策略也更具通用性,传统的云服务器稳定的信息收集过程可作为其中的一种特例处理。本文围绕一个移动信息采集设备(学习服务器)及与其可能发生交易的K个客户端节点(学习参与者)进行研究并建立系统架构,如图2 所示。

图2 本文系统架构Fig.2 Framework of the proposed system
移动信息采集设备在本文系统中作为一个可移动的学习服务器,不仅可以在不同的客户端节点处收集数据,还可以将收集的数据进行训练以构建模型。本文假设移动信息采集设备在一个时隙内仅停留在一个区域收集与处理该区域中客户端节点的数据或梯度。每个节点可以不断地产生原始数据,拥有的电量和原始数据量都不完全相同,根据自身情况选择参与到移动信息采集设备组织的联邦学习或者传统的机器学习中。
若客户端节点选择参与分布式的联邦学习,则先在本地训练模型,局部计算梯度参数,再将加密过的梯度参数发送给移动信息采集设备。移动信息采集设备得到所有客户端节点的数据之后,在不了解任何节点信息的情况下执行安全聚合,并计算总梯度。最后将结果分别传送给参与的客户端节点,节点再使用解密的梯度参数更新各自的模型。
客户端节点还可以选择传统的集中式机器学习,其仅作为数据提供者,直接发送原始数据给移动信息采集设备。在这种情况下,客户端节点选择放弃保护隐私并完全信任移动信息采集设备,以节省训练过程中的计算开销。移动信息采集设备得到所有客户端节点的数据之后,在了解节点信息的情况下执行数据聚合和训练。
从保护隐私的角度分析,客户端节点更倾向于在本地训练数据,以避免发送大量的原始数据带来隐私泄露的风险。但从提高模型训练效果和减少能源消耗的角度分析,客户端节点传送原始数据有助于最大程度地保留数据的可用性,有利于对模型进行训练,同时也可避免因在本地进行模型训练而消耗较多的能量。因此,本文基于联邦学习中的用户合作训练模型,设计一种客户端节点的信息传输机制。该机制基于马尔科夫决策过程(Markov Decision Process,MDP)构建随机优化模型,并通过求解MDP 模型得到客户端节点的最优信息传输与能量管理组合优化策略。
1.2 马尔科夫决策模型
为确定无线网络场景下客户端节点的信息传输与能量管理组合优化策略,本节将客户端节点的信息传输与能量管理问题建模为一个MDP 模型,以描述与分析节点在移动信息采集设备带有不确定性的信息采集过程中的状态变化与行为模式。
1.2.1 状态空间
状态S是一个复合状态变量,由数据状态、能量状态和移动信息采集设备区域状态这3 组离散状态表示,如式(1)所示:
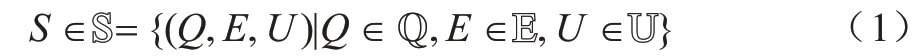
其中:数据状态Q∈Q={0,1,…,Q}为客户端节点在其数据缓存池中当前滞留的数据量;Q为最大数据量。本文假设每个客户端节点训练和发送数据所需要的能量是由外部设备提供的,单个客户端节点配备储能设备和无线充电设备,从可访问的能源中充电并储存在自身的储能设备中。能量状态E∈E={0,1,…,E}为客户端节点储能设备中的剩余电量,E为最大电量。移动信息采集设备区域状态U∈U={0,1}表示移动信息采集设备是否处于该客户端节点的数据可传送区域范围中,U=0 表示移动信息采集设备不在节点传送区域中,即移动信息采集设备未到该节点处,该节点无法与移动信息采集设备产生任何交易,U=1 则表示移动信息采集设备在该节点处。
1.2.2 动作空间
客户端节点在每个时隙中根据所观测到的当前状态做出相应的动作决策。动作空间A 为节点在每个时隙内可选择执行的动作集合,如式(2)所示:

其中:A=0 为节点决定不执行任何操作;A=1 为节点决定参与联邦学习,仅向移动信息采集设备传送在本地训练后的加密数据,消耗自身算力,并保护数据隐私;A=2 为节点决定直接向移动信息采集设备传送原始数据,以避免由于本地训练计算量过大而可能产生的能源中断等问题。
1.2.3 状态转移矩阵
状态转移矩阵H为节点在一个时隙内,从当前状态S转移到下一个状态S'的整体状态转移矩阵,矩阵横坐标代表节点当前状态S,纵坐标代表下一状态S'。该矩阵描述客户端节点所观测系统状态的变化过程。该矩阵由3 个状态分量的转移矩阵通过Kronecker 乘积⊗推导得出,如式(3)所示:

状态转移矩阵包括数据状态转移矩阵、能量状态转移矩阵、区域状态转移矩阵。
1)数据状态转移矩阵Q(A)
为节点从当前数据状态Q转移到下一个状态Q'的分量转移矩阵。为方便解释,本文将数据的流动模式分为消耗和产生两步推导:在一个时隙开始时,根据节点所做出的不同决策,节点消耗对应的数据量;在一个时隙结束前,节点会重新收集k个单位的数据,若当前数据缓存池的数据存储已经达到最大容量,则其数据量不变。当A=0 时,节点的数据状态转移矩阵如式(4)所示:
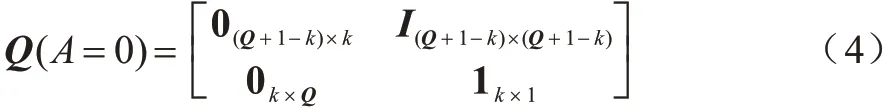
其中:0 为全0 矩阵;I为单位矩阵;1 为全1 矩阵。当A=1 时,即节点在本地训练模型更新梯度参数并传送给移动信息采集设备。在能量充足的情况下,节点可以在一个时隙内向移动信息采集设备传送v个单位的数据,若数据缓存池中当前的数据量大于等于v,则上传v个单位的数据;小于v则上传当前所有数据。本文假设在上传梯度数据过程中不会发生数据丢失的情况,且上传过程中数据的损耗忽略不计,则此时节点的数据状态转移矩阵如式(5)所示:
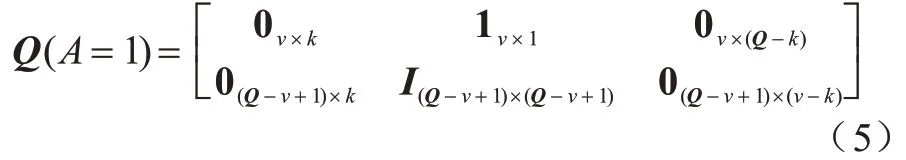
当A=2 时,即节点直接将原始数据传送给移动信息采集设备,在能量充足的情况下,节点可以在一个时隙内向移动信息采集设备传送v个单位的数据,但庞大的数据量对信道的要求较高,信道的不稳定性导致数据包有一定传送失败的概率。本文假设传送成功的概率为q,如果数据第一次传送失败,可重复尝试传输直到当前时隙结束。如果当前时隙结束时传送仍然失败,数据会继续滞留在数据缓冲池中,造成数据延迟。客户端节点当前选择参与集中式学习时,其数据状态的转移过程如图3 所示。

图3 客户端节点数据状态转移过程Fig.3 State transfer process of client node data
此时数据状态转移矩阵如式(6)所示:

矩阵中q所在位置表示在当前时隙开始时,节点数据量为Q,选择传送原始数据后数据传送成功,则数据量先减少v个单位(若当前节点数据量小于v个单位,则上传当前所有数据,当前数据量暂时为0),增加新收集的k个单位数据之后,节点在当前时隙结束时拥有的数据量变为Q'。矩阵中1-q所在位置表示节点当前数据量为Q,选择传送原始数据后数据传送失败,则数据量不会发生变化,节点数据量仅增加新收集的k个单位后变为Q'。
2)能量状态转移矩阵E(A)
为节点从当前能量状态转移E到下一个状态E'的分量转移矩阵。假设能量的补充和传输消耗不会同时进行,且在一个时隙内最多只能消耗节点当前已有的能量储备。本文也将能量的流动模式分为消耗和补充两步推导,在一个时隙开始时,根据节点做出不同的决策,节点消耗对应的能量;在一个时隙结束前,外部设备会给客户端节点提供w个单位的能量,补充的能量可供节点下一个时隙使用。若当前储能已经达到最大容量,则其能量水平不变。当A=0 时,即节点不执行任何操作,节点的能量状态转移矩阵如式(7)所示:

当A=1 时,在一个时隙内,节点训练模型消耗m个单位的电量,上传的梯度数据消耗的能量忽略不计,当客户端节点存储的能量小于m个单位时,即无法完成模型训练,当前存储能量不会被消耗,节点的能量状态转移矩阵如式(8)所示:
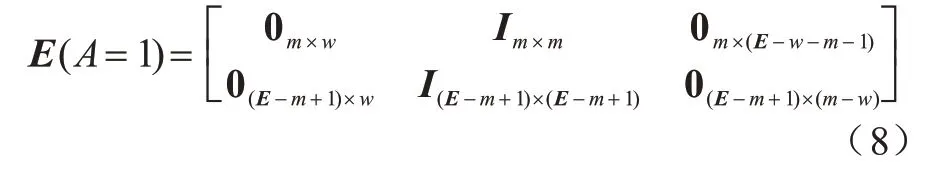
当A=2 时,传送成功的概率为q,上传过程消耗n个单位能量,当存储的能量小于n个单位时,即无法完成数据包的传送,当前存储能量也不会被消耗,节点的能量状态转移矩阵如式(9)所示:

矩阵中q所在位置表示当前时隙开始时,节点能量为E,选择传送原始数据后数据传送成功,则节点能量先减少n个单位(若当前节点拥有的能量小于n个单位,则无法传送数据,能量也不会被消耗,即节点能量保持不变),外部设备提供w个单位能量后,节点能量变为E'。矩阵中1-q所在位置表示节点当前能量为E,选择传送原始数据后数据传送失败,能量未因此发生变化,节点能量仅增加新收集的w个单位后变为E'。
3)区域状态转移矩阵U
为移动信息采集设备覆盖区域状态转移的概率矩阵。移动信息采集设备当前是否在节点的数据传送范围内,直接决定了节点是否可以将数据传送给移动信息采集设备。只有作为数据接收方的移动信息采集设备停留在节点处时,节点才能够参与到移动信息采集设备组织的联邦学习或集中式学习中。因此,移动信息采集设备在节点处的概率越大,节点越有可能获得训练局部模型或上传原始数据所带来的收益。若移动信息采集设备当前时隙不在节点处,则下一个时隙移动信息采集设备进入区域的概率为p;若移动信息采集设备当前时隙在节点处,则下一个时隙移动信息采集设备继续停留在传送区域的概率为P(A),节点的区域状态转移矩阵如式(10)所示:
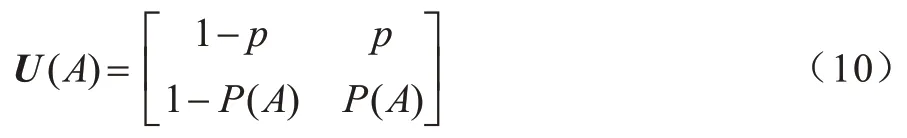
设式中P(A=0) 1.2.4 回报函数 客户端节点在工作过程中会在不同状态之间转换,并相应地采取不同的行动,节点在当前状态做出动作后,其作为学习参与者将获得即时奖励,记为即时效用函数F(S|A),该函数仅与当前状态有关。本文假设F(S|A)由3 个分量组成,分别为模型收益函数FT(S|A)、数据延迟函数FD(S|A) 和隐私泄露函数FL(S|A),如式(11)所示: 其中:ρT、ρD、ρL为权重系数;FT(S|A)为节点训练模型所得的收益。机器学习训练模型的好坏很大程度上取决于训练集所用数据的质量和数量,一般而言,训练样本越多,越有可能通过学习获得具有强泛化能力的模型。最终所得模型的准确度越高,收益也越大[27],则FT(S|A)如式(12)所示: 其中:ΔQ为节点最终传送给移动信息采集设备的数据量,训练模型的最终效果与ΔQ成正相关。但若节点没有足够的能量或者移动信息采集设备不在传送范围内,节点则无法在本地更新梯度数据或上传原始数据给移动信息采集设备,因此节点模型收益为0。由于联邦学习对于隐私保护的严苛性,可能会导致数据的可用性降低,因此传送原始数据可以得到更好的模型训练效果,即T1(ΔQ) FD(S|A)为数据在节点数据缓存池中滞留的开销,数据在数据缓存池中滞留的时间越长,传送给移动信息采集设备的时效性就越低,对总体效用的损耗也越大,则FD(S|A)如式(13)所示: 其中:Q'为当前时隙结束时仍滞留在节点数据缓存池的数据量,滞留开销仅与Q'成负相关,与节点当前的能量级和移动信息采集设备的区域状态都无关。 FL(S|A)为隐私泄露的风险开销,通过分析数据量得出信息量的关系为:当数据量从无到有增加时,可得出的信息量会随之快速增加。随着数据量继续增加,同样数据量可得的有效信息则逐渐减少,该数量关系符合对数变化规律[28],则FL(S|A)如式(14)所示: 当A=1 时,由于数据是加密上传的,隐私泄露的风险较小,隐私开销可忽略不计。当A=2 时,移动信息采集设备得到大量的节点原始数据,从而导致节点隐私有泄露的风险,此时隐私开销L(ΔQ)与上传的真实数据量ΔQ呈负相关。如果节点没有足够的能量或者移动信息采集设备不在传送范围内,即不产生任何信息传输,则隐私开销为0。 在建立MDP 模型的基础上,本文分别采用值迭代算法以及深度强化学习算法求解MDP,以获取客户端节点的优化策略。 在已知完整的系统和环境信息的前提下,值迭代算法根据MDP 模型计算最佳的策略。系统优化的具体目标是在当前系统状态下,选择每个决策阶段的最佳动作,使节点长期预期效用最大化,从而得到最优策略。由于MDP 模型是由所提出的状态空间、动作空间、状态转移矩阵H(S,S'|A)和即时效用函数F(S|A)实现,因此MDP 优化公式可通过贝尔曼方程迭代求得,如式(15)~式(17)所示: 其中:γ∈(0,1]为折扣因子,公式的解可通过值迭代算法得到。值迭代算法首先初始化所有状态值函数V(S),分别计算节点在每一个状态下执行不同动作时所有可能未来状态的预期效用和,选择使节点长期预期效用最大化的动作,并将当前状态的值函数更新为长期预期效用的最大值。当状态空间里的所有状态遍历完毕后,则完成了一次迭代过程,重复上述迭代过程直至前后两次迭代所得的所有状态值函数之间的差值均小于设定的某一阈值,所有状态值函数收敛,此时节点在每个状态下对应执行的动作即为客户端节点信息传输与能量管理的组合优化策略φ*(A|S)。 传统的值迭代算法需要完整的系统和环境信息,适用的状态和动作空间较小,且没有泛化能力。随着系统规模的增加,值迭代的复杂度呈指数级增长。与值迭代算法相比,深度强化学习(Deep Reinforcement Learning,DRL)显著降低了模型的复杂性,在问题规模增大的情况下算法复杂度也没有提升。DRL 是强化学习和深度学习的结合,在具有决策能力强化学习基础上借助深度神经网络使智能体拥有对复杂环境的理解能力和泛化能力,为智能体动态地提供不断适应环境变化的决策方案。 深度Q 网络(Deep Q Network,DQN)是DRL 算法的典型代表。与值迭代算法相比,DQN 利用深度神经网络逼近值函数,将当前系统观察到的状态作为神经网络的输入,通过经验回放打破数据之间的相关性。DQN 通过两个结构相同但参数不同的神经网络,从历史经验中学习回报和动作之间的关系,优化神经网络的权重,从环境中最大化获得累计回报值,最终输出一组动作的估计Q值。此外,DQN的输入数量仅由状态本身性质决定,即使输入数量改变,DQN 的结构也无需改变,具有一定通用性[29]。因此,本文采用基于DQN 的算法为客户端节点提供实时决策,以寻找节点信息传输与能量管理组合优化策略。具体过程见算法1。 算法1基于DQN 算法的客户端节点信息传输与能量管理组合优化策略 本文通过仿真构建系统模型,并定义了相关性能指标评价所提MDP 策略。 本文设置客户端节点的最大数据容量Q=10,最大储能容量E=10。在一个时隙内节点可向移动信息采集设备传送v=3 个单位数据,新收集k=2 个单位数据。节点在本地训练消耗m=3 个单元能量,传送原始数据给移动信息采集设备消耗n=1 个单位能量,每个时隙外部设备给节点补充w=1 个单位能量。移动信息采集设备进入节点传送范围的概率p=0.5;节点执行不同动作后,移动信息采集设备继续停留在节点处的概率P(A=0)=0.5,P(A=1)=0.7,P(A=2)=0.9。节点成功传送原始数据的概率为q=0.9。对于1.2.4 节中给出的回报函数,本文设置T1(ΔQ)=3ΔQ,T2(ΔQ)=4ΔQ,设置数据滞留开销D(Q')=Q',隐私泄露开销L(ΔQ)=lb(ΔQ+1),设置权重系数ρT、ρD、ρL分别为1、-0.5、-2。 对于DQN 算法中的初始参数,本文设置参数θ为0~0.3 的随机数,该参数随着每次迭代实时更新,每隔300 步目标值神经网络的参数θ-更新一次。记忆回放池D=500,学习率α=0.001,ε-贪心策略中的探索率ε=0.95。 为验证所提策略的性能,本文设置4 种对比策略:1)贪心策略(GRE),节点不考虑未来的长期收益,每次都选择使即时效用F(S|A)最大化的动作;2)随机策略(RAN),节点每次在动作空间中随机选择一个动作,所有动作被选中的概率相等;3)传统联邦学习策略(FED),节点在任何状态下仅选择参与联邦学习,即在本地训练并上传梯度数据;4)传统集中式学习策略(TRA),节点在任何状态下仅选择参与集中式机器学习,即上传原始数据。 为评估所提出策略性能,本文定义相关性能评价指标如表1 所示。 表1 客户端节点性能评价指标Table 1 Performance evaluation indexs of client node 本文首先基于所提出的值迭代算法进行仿真实验,通过比较长期效用对客户端节点的性能进行验证。本文研究客户端节点的最大数据容量Q对其长期效用的影响,改变Q为0~10,在不同策略下长期效用随节点最大数据容量的变化如图4 所示。随着数据容量增加,所有策略的效用都呈先增后减的趋势。这是由于在Q较小时,节点最大数据存储容量的增加使得节点可以存储更多的数据以供未来训练模型使用,从而减少节点参与联邦学习或集中式学习,数据缓存池中可供训练的数据短缺问题发生的概率减少。随着Q增加,训练模型所带来的收益逐渐不足以抵消巨大的数据量,滞留在缓存池中的数据延迟开销,因此长期效用逐渐减少。在最大数据容量较小时表现较优的GRE 策略,随着数据容量的增加逐渐体现出了劣势。由于GRE 策略是短视的,节点在决策时仅选择当前时隙能得到最高回报的动作,而忽略了当前所选择动作对未来的影响。FED 策略的能耗成本始终较大,TRA 策略的隐私泄露成本较大,无法获得优于MDP 策略的长期效用。在这种情况下,本文提出的MDP 策略相较于其他基准策略的优势逐渐扩大。MDP 策略在已知全局环境信息的情况下,在尽量保护用户隐私和保持模型训练精度基础上,降低能量开销的策略,实现性能平衡。 图4 在不同策略下长期效用随节点最大数据容量的变化Fig.4 Long-term utility changes with maximum data capacity of client node under different strategies 在不同策略下长期效用随节点最大储能容量的变化如图5 所示,改变节点最大储能容量E从0~10,随着E增加,所有策略的效用都呈现增加趋势后逐渐平缓。当E从0~1 时,MDP、GRE 和TRA 策略的长期效用都有一个较大幅度增加,由于节点上传原始数据需要n=1 个单位能量,此时最大储能容量的增加使节点在做决策时有足够的能量使用,可以减少由于储能能力不足而造成能量短缺。当E>1 时,上述3 种策略的边际效用减小,此时最大储能容量已超过节点执行任何操作所需的能量,因此,最大储能容量的增加带来的优势也逐渐减少。而FED 策略在E=3 时长期效用才有一个较大的提升,但仍低于其他策略的长期效用。在不同的储能容量E下,由于本文提出的MDP 策略考虑了未来可能会产生的能量短缺,提前做出了有利于提高长期效用的决策,因此MDP 策略的表现优于其他基准策略。在实际系统中可以依照相应的仿真结果设置客户端节点的最大数据容量和最大储能容量,以节省成本,例如,在本实验参数设置条件下,将客户端节点的最大数据容量设置为3,最大储能容量设置为1 是较为合适的选择。 图5 在不同策略下长期效用随节点最大储能容量的变化Fig.5 Long-term utility changes with maximum energy capacity of node under different strategies 本文还研究了节点传送原始数据的成功率q对长期效用的影响,如图6 所示。随着q的增加,除了在任何状态下都选择上传梯度数据的FED 策略的总体效用不受原始数据发送成功率的影响,其他所有策略的效用都呈先增后减的趋势。在q较小时,若节点选择了传送原始数据,随着q的增大,更多原始数据可直接用于模型训练,节点所得的训练收益也随之增大,且大于节点在其他方面的成本消耗。当q=0.8 时,节点在隐私开销、模型收益和能量消耗之间达到了最佳平衡。而当q>0.8 时,虽然此时数据传送成功概率更高,所获得的模型收益可能更大,但随着原始数据传送成功率的提高,当节点选择传送原始数据时,隐私泄露的风险开销也随之变大,此时三者之间的最优决策所达到的平衡被打破,因此长期效用反而降低。实际系统可以依照相应的仿真结果设置客户端节点的数据发送成功率。在本实验参数设置条件下,维持客户端节点的数据发送成功率约为0.8 较合适。从图6 可以看出,本文考虑了未来长期效用的MDP 策略优于其他基准策略。 图6 在不同策略下长期效用随节点原始数据发送成功率的变化Fig.6 Long-term utility changes with transmission success rate of node original data under different strategies 为验证部署DQN 策略的客户端节点在未知信息的高维环境中探索学习的性能,本文进行了仿真实验。在不同策略下长期效用随训练周期的变化如图7 所示。在经过约300 轮训练后,DQN 的仿真结果收敛于MDP 的仿真结果并逐渐趋于稳定,原因是DQN 策略对先前训练周期的系统状态、状态转换和即时回报都进行了采样,并将这些历史数据放入记忆回放池中,之后通过训练历史数据不断调整深度神经网络中的权重因子,最终调整到趋于稳定且较高的水平,得出节点最优的信息传输与能量管理策略。该结果表明DQN 策略在高维复杂的无线通信网络环境中,仍表现出较强的探索学习能力。 图7 在不同策略下长期效用随训练周期的变化Fig.7 Long-term utility changes with training period under different strategies 在不同策略下节点平均数据延迟随训练周期的变化如图8 所示。基于历史数据训练的DQN 策略的平均数据延迟初期随着训练周期的增加逐渐降低,可以有效地处理数据传输任务,DQN 策略在训练约300 轮时收敛于MDP 策略,相较于其他基准策略产生的数据延迟最少。由于数据长时间累积存储在队列中会导致较大的延迟开销和较少的长期收益,DQN 策略通过训练学习过程快速调整策略进行平衡,因此更好地完成了移动信息采集设备和客户端节点间的信息传输。 图8 在不同策略下平均数据延迟随训练周期的变化Fig.8 Average data delay changes with training period under different strategies 在不同策略下节点掉电率随训练周期的变化如图9 所示。基于DQN 策略的掉电率在训练约300 轮向下收敛于MDP 策略的基准值且远低于其他策略,相比其他基准策略,对于回报的短视,DQN 策略在学习历史经验的过程中已逐渐学会如何规避可能对后续能量造成短缺的选择,不断调整策略以最大程度地减少能量短缺。 图9 在不同策略下掉电率随训练周期的变化Fig.9 Energy shortage probability changes with training period under different strategies 本文设计一种基于联邦学习的信息传输与能量管理策略。通过构建马尔科夫决策模型分析客户端节点在系统中的行为模式,采用值迭代算法和深度强化学习算法求解马尔科夫决策模型,得到客户端节点的能量与信息管理优化策略。仿真结果表明,本文策略能够实现节点在数据隐私保护、模型收益和能量消耗之间的最优平衡。由于无线通信网络的实际应用场景通常是层次复杂的网络拓扑结构,而本文仅研究联邦学习框架下无线网络中一对多通信的问题,因此后续将对多层次无线网络结构下多对多信息传输的动态变化进行研究,使信息传输与能量管理策略适用于无线通信网络的实际应用场景。



2 无线通信网络场景下的优化策略
2.1 值迭代算法

2.2 深度强化学习

3 仿真与结果分析
3.1 仿真环境与参数
3.2 评价指标

3.3 仿真结果分析






4 结束语
