基于改进图节点的图神经网络多跳阅读理解研究
2022-01-14欧阳智杜逆索
舒 冲,欧阳智,杜逆索,,何 庆,魏 琴
(1.贵州大学计算机科学与技术学院,贵阳 550025;2.贵州大学贵州省大数据产业发展应用研究院,贵阳 550025)
0 概述
随着深度学习技术的不断发展,机器阅读理解(Machine Reading Comprehension,MRC)成为自然语言处理领域的热门研究课题,受到了越来越多的关注。机器阅读理解需要根据给定的上下文来回答与其相关联的问题,因此要求模型既要理解上下文的语义语境等信息,又要能够识别出哪些信息与问题相关,从而进行最终的问题推断。早期的机器阅读理解工作[1-3]主要针对的问题是答案在单个段落的单个句子或多个句子中。然而,在实际应用中大量问题的答案不能仅由单个段落进行推断,而应由多个段落进行整合后回答。因此,多段落阅读理解的研究开始受到广泛关注。
多段落推理的传统方法主要是单独对每个段落进行答案抽取,最终输出可能性最大的答案。CHEN 等[4]基于Wikipedia,采用文章检索模块提取与问题相关的文章并切分成为段落,再利用文章阅读模块从提取文章的每个段落中进行答案搜索。CLARK 等[5]从文档中抽取多个段落,分别计算每一个段落的置信度分数,选择置信度分数最高的段落,从中进行答案提取,在多个数据集中取得了不错的效果。万静等[6]提出多段落排序BiDAF(PR-BiDAF)模型,通过对多个段落与问题之间进行相关度匹配,选取相关度最高的段落进行答案提取。然而,这些方法都只是将段落看成单独的个体,忽视了段落与段落间的关联,无法得到段落间更复杂的信息。
针对多段落之间的信息交互问题,还需要一种可以更好地获取段落与段落之间交互信息的方法,以实现多跳信息连接。吴睿智等[7-8]通过实验证明图神经网络可以很好地运用在自然语言处理任务中,并且能够有效提升网络性能。针对多跳问题,基于图神经网络的相关研究[9-11]主要通过构建实体图来聚合信息实现多跳阅读理解。实体图一般由多个节点以及节点之间相连的边所构成,而节点的选取则是模型取得优良效果的关键。CHEN 等[12]通过抽取支撑文档中的句子构建多条推理链,将支撑文档中的句子作为图中的节点,通过聚合句子中的相关信息进行问题推理回答。TU 等[13]抽取问题中的实体与候选词在文章中对应的实体以及每个支撑文档作为图的节点,构建包含多种节点与边关系的异质文档实体图(HDE),在实体图中聚合多粒度信息实现节点信息传递进行答案推理。然而,聚合多种信息往往会导致实体图中信息量过多,使得模型容易受到不相关信息的干扰。DE CAO 等[10]仅将在支撑文档中出现过的候选词作为实体,建立实体关系图并通过候选词节点之间的信息传递进行问题推理。CAO 等[14]在文献[10]的基础上引入双向注意力机制用于问题与候选词节点之间的双向信息交互,生成问题感知节点表示用于最终结果推断。这些方法相对提取的实体种类更少,虽然效率较高,但也会导致实体图在初始阶段缺乏关键信息,或是所得到的信息量不足,使得模型在推理过程中无法得到正确的结果。
现有研究在实体提取方面大多数基于简单的字符串匹配来查找文中的相关实体,这样会使不少隐含在文中的实体无法被提取出来,导致相关信息的缺失。此外,已有模型很少关注疑问实体与候选词实体之间的信息交互,而通常疑问实体所在的支撑文档包含的信息量会远远大于其他文档,提取该支撑文档中出现的所有疑问实体作为新的节点类型加入到实体图中,可以使得实体图中包含更多与问题相关联的信息,从而使得模型可以更加准确有效地得到最终的推断结果。
本文提出基于改进图节点的图神经网络多跳阅读理解模型。首先,采用基于指代词的实体提取方法进行实体提取,增加更多的相关节点参与到实体图中进行信息传递。然后,将疑问实体作为实体图中新的节点类型,参与到图卷积操作中丰富节点的种类。对于不能直接与候选词节点相连的疑问实体,提取出疑问实体所在支撑文档中的所有实体,将这些实体经过筛选后,作为疑问实体关联实体参与到实体图中进行信息传递。通过将疑问实体、关联实体与候选词实体相连使得疑问实体间接与候选词实体相连。最后,对实体图中的节点进行图卷积操作,计算图卷积网络(Graph Convolutional Network,GCN)输出结果与问题的双向注意力,并通过与其他模型的对比实验验证本文模型的有效性。
1 本文模型
本文提出的基于改进图节点的图神经网络多跳阅读理解模型如图1 所示,主要包括实体图构建模块、上下文语义信息嵌入模块、GCN 推理模块、信息交互模块、预测模块等5 个模块。

图1 基于改进图节点的图神经网络多跳阅读理解模型框架Fig.1 Framework of multi-hop reading comprehension model based on graph neural network with improved graph nodes
1.1 实体图构建模块
1.1.1 基于指代词的实体提取方法
传统字符串匹配提取实体的方法在实际提取实体的过程中,会导致大量相关实体的缺失。例如,英文人名中可能将名称简写或者是使用别名等,如问题句“participant of juan rossell”,其 中“juan rossell”为疑问实体,但是在支撑文档中,“juan rossell”对应的全名是“Juan Miguel Rossell Milanes”,如果此时采用传统的字符串匹配方法直接进行字符串匹配,那么将无法提取到这些实体或者遗失掉某些实体其他支撑文档中的对应实体。因此本文针对这一问题,提出基于指代词的实体提取方法,该方法从支撑文档中提取出更多的相关实体,增加更多相关实体节点参与实体图中进行信息交互,使得实体图可以包含更多的信息量,有利于最终的问题推断。
1.1.2 基于问题关联实体的实体图构建
通过基于指代词的实体提取方法获得在文章中所出现的候选词节点与疑问实体节点,再用提取出的节点构建实体图,如图2 所示。然而,在实际构建实体图的过程中,由于不是每个疑问实体都能与候选词实体相连,导致疑问实体不能参与到最终的图卷积网络中,使得实体图中缺乏包含问题的关键信息。对于不能与候选词实体相连的疑问实体,提取出该疑问实体所在支撑文档中的所有实体,经过筛选后作为疑问实体关联实体参与实体图的构建。通过加入新的节点类型使得疑问实体节点与候选词节点间接相连,从而使疑问实体节点中的信息在实体图中进行信息传递,最终得到的实体图如图3 所示。
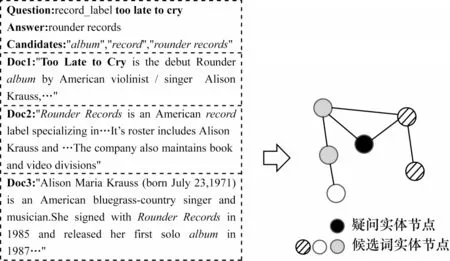
图2 WikiHop 样本实体图构建Fig.2 Construction of WikiHop sample entity graph

图3 基于问题关联实体的实体图构建Fig.3 Construction of entity graph based on problem-related entities
实体图中边的定义如下:1)出现在同一支撑文档中的实体相连;2)出现在不同文档中,属于同一个实体的节点相连。值得注意的是,这些边都是无向边,没有在边上赋予特殊的权值。通过构建实体关系图,将支撑文档的上下文语义信息转换成图关系节点。最终得到N个节点{Ni},1≤i≤N,这些节点都是通过上述边的定义方式来进行连接。
1.2 上下文语义信息嵌入模块
通过使用ELMO 词嵌入预处理模型[15]对提取到的候选词实体、疑问实体、疑问实体关联实体进行编码,得到这些实体节点与上下文语义相关的信息,从而将支撑文档中所包含的信息转化成文档中各个实体节点的信息。此外,ELMO 模型还可以根据上下文特征动态地调整词嵌入,能够有效地解决大规模文本数据集下一词多义的现象。由于每个实体节点中可能包含的单词数量不止一个,因此对每个节点中所包含的单词向量都进行最大池化与平均池化操作,再将获得的特征向量进行拼接,得到最终的每个节点信息表示向量,如式(1)所示:

其中:dnode表示节点最终的特征向量;dmax-pool表示经过最大池化操作后的节点特征向量;dmean-pool表示经过平均池化操作后的节点特征向量。
1.3 GCN 推理模块
通过将经过上下文语义信息嵌入模块编码后的特征向量输入至图神经网络中,得到图中节点的原始向量。由于每个节点都会与多个节点相连,因此要求节点有选择性地获取相邻节点的信息,在进行信息传递时可以在实体图中传递最为相关的信息,模型采用门机制的图卷积网络(G-GCN)来进行推理操作。
在图神经网络中,节点之间的信息按照式(2)进行传递:

在各个节点进行信息传递后,使用Sigmoid 激活函数对各个节点进行激活,如式(3)所示:

门机制使得节点在获取其邻居信息时更有选择性,通过式(4)计算得到门更新单元,再把门更新单元代入式(5)可以得到使用门机制后的关系权重矩阵:

其中:flinear表示向量经过一层全连接层后进行线性转换;表示门更新单元,用于更新同一个节点在图神经网络中下一层隐藏层的权重矩阵。
基于门机制的GCN 节点信息传递如式(6)所示,因此在经过门更新单元处理后,得到最终的节点隐藏层状态。

其中:⊙表示矩阵对应元素相乘。
在L层的图卷积网络中所有的参数都是共享的,每个节点的信息都会经过L个节点的传播,从而使节点完成L次跳跃的推理过程,并获得这L次跳跃后的节点信息关系表示。
1.4 信息交互模块
模型通过在问题与节点的信息交互上使用双向注意力机制,可以更好地获取节点与问题之间更多相互有关联的信息,最大限度地丰富模型最终输出向量的信息量。CAO 等[14]在BAG 模型中引入了双向注意力机制,取得了不错的实验效果,证明了双向注意力机制可以很好地运用在图神经网络中节点与问题之间的信息交互。因此图神经网络最终的输出向量为Hl∈RM×d,初始节点特征向量为fl∈RM×d,M为节点数量,d为隐藏层维度,通过ELMO 编码的问题输入向量为fq∈RN×d,N为问题数量。通过式(7)求得相似度矩阵S∈RM×N:
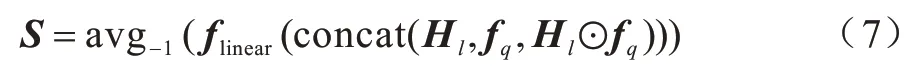
其中:avg-1表示对flinear最后一维求平均值。
通过对问题与图神经网络中的节点进行一次反向注意力运算,得到节点-问题的注意力表示,如式(8)所示:

其中:·表示矩阵相乘。
在得到节点-问题的注意力表示后,计算问题-节点的注意力表示,如式(9)所示:

其中:maxcol表示取相似度矩阵S中每一列的最大值,从而将相似度矩阵维度转换为R1×N;dup(·)表示经过M次复制后将S的维度转换为RM×N。
最终将经过这一模块处理后的输出向量输入至预测模块,进行最后的答案预测,如式(10)所示:

1.5 预测模块
通过将最终信息交互模块的输出经过两层全连接层的转换之后,得到每个节点作为答案的概率值,每个节点都对应一个候选词,将每个候选词所对应的所有节点的概率相加,就是该候选词作为答案的概率。由于答案选择实际是一个多分类问题,因此选择多分类交叉熵损失函数作为模型的损失函数,即:

当答案预测正确时yi为1,否则为0,pi为预测候选词所对应的概率,如式(12)所示:

值得注意的是,由于在构建实体图时加入了很多非候选词节点,因此在实际计算答案概率时只会计算相关候选词实体节点作为答案的概率,而不会计算疑问实体节点与疑问实体关联实体节点作为答案的概率。
2 实验结果与分析
为验证本文模型的有效性,在WikiHop 数据集的unmasked 版本中对其进行验证测试。WikiHop 数据集是一个需要跨越多个文档进行多跳推理的阅读理解数据库。每一个WikiHop 的样本有一个问题Q,多个支撑文档S={s1,s2,…,sn}和一个候选答案集C={c1,c2,…,cn},候选答案可以是单个单词,也可以是多个单词组成的名词短语,需要模型根据给定的问题从中选出正确的答案。其中,训练集有43 738 条数据,验证集有5 129 条数据,测试集有2 451 条数据,支撑文档来自WikiReading[16]。
实验环境设置如下:操作系统为Ubuntu16.04,采用2 块GTX Titan Xp 进行数据并行处理,服务器运行内存为96 GB。在参数选择上:ELMO 模型默认选择1 024 维;本文模型除了最终的输出层神经网络维度为256 维外,其余的隐藏层维度均为512 维,图卷积网络层数L为5;训练集batch_size 设置为32,验证集batch_size 设置为16;初始学习率设置为2×10-4,为了防止模型过拟合,Dropout 设置为0.2。本文模型所需的实体图数据与ELMO 词向量嵌入均已在线下提前训练好,可以有效减少实际模型的训练时间。如表1 所示,实体图中节点数量主要集中于小于500 这一区间,因此每个实体图设置最大节点数为500。

表1 实体图节点数量统计Table 1 Statistics of node number in entity graph
为验证本文模型的效能,分别通过在验证集和测试集上与基于图神经网络的多跳阅读理解模型(Entity-GCN[10]、MHQA-GRN[11]、HDE[13]、BAG[14]、Path-based GCN[17])、基于循环神经网络(Recurrent Neural Network,RNN)的多跳阅读理解模型(Coref-GRU[9]、EPAr18])、基于注意力机制的多跳阅读理解模型(BiDAF[1]、CFC[19]、DynSAN[20])进行比较,结果如表2 所示。由于本文模型是单模型,因此仅与已有单模型进行比较,而不与融合模型进行比较,评价指标为准确率。

表2 多跳阅读理解模型准确率比较Table 2 Comparison of accuracy of multi-hop reading comprehension models %
从表2 中的结果可以看出,与基于图神经网络的多跳阅读理解模型相比,本文模型在验证集中仅低于Path-based GCN 模型,但是在测试集上优于所有基于GCN 的多跳阅读理解模型,与其中准确率最高的Path-based GCN 模型相比在验证集上提高了0.6 个百分点,这表明了本文模型的可泛化性较强。在与其他非图神经网络模型进行比较时,本文模型在验证集上准确率仅低于DynSAN 模型,但在测试集上准确率高出DynSAN 模型1.7 个百分点。以上比较结果表明:使用基于指代词的实体提取方法提取出实体以构建新型实体关系的实体图可以有效地增加实体图中所含的关键信息量,最终提升模型性能。
为验证本文模型中各模块的有效性,在验证集上进行模型消融实验来验证基于指代词的实体提取方法与基于问题关联实体的实体图构建对于模型效果的影响,结果如表3 所示。由表3 中的结果可以看出:去除基于指代词的实体提取模块后,准确率下降了1.9 个百分点,说明使用传统方法在提取实体时会造成部分相关实体的缺失,导致模型推理效果下降;去除基于问题关联实体的实体图模块后,准确率下降了1.5 个百分点,证明了实体图内缺乏关键问题信息会影响多跳推理的结果;去除GCN 模块后,准确率下降达到了4.8 个百分点,说明了图卷积网络能够有效地促进实体图内各个节点之间的信息交互;去除双向注意力模块后,准确率下降了3.5 个百分点,这证明了双向注意力机制可以有效提升模型性能。

表3 多跳阅读理解模型消融实验结果Table 3 Results of ablation experiment for multi-hop reading comprehension models %
3 结束语
为解决实体图内缺乏关键问题信息以及信息量冗余的问题,本文提出基于改进图节点的图神经网络多跳阅读理解模型。采用基于指代词的实体提取方法从支撑文档中提取与问题相关的实体,并将提取到的相关实体基于问题关联实体构建实体图。通过对图节点进行ELMO 编码后使用G-GCN 模拟推理,最终计算推理信息与问题信息的双向注意力并进行最终答案预测。实验结果表明,该模型相比现有多跳阅读理解模型准确率更高、泛化性能更强。后续将添加更多类型的节点和边到实体关系图中,使得实体关系图可以包含更多的相关信息,进一步增强模型推理能力。
