基于一维卷积神经网络的岩石物理相识别
2022-01-14李盼池李文杰
李盼池,李文杰
(东北石油大学 计算机与信息技术学院,黑龙江 大庆163318)
0 引 言
近年来,随着油气勘探工作的深入发展,致密砂岩储层成为目前勘探工作的重中之重。但由于复杂的地质成因作用使致密砂岩储层表现出孔隙关系复杂、物性不好以及非均质性等现象。这使常规储层预测方法(如油气测试法、含油产状法和经验统计法等)在识别致密砂岩储层时的准确率并不理想。虽然该类方法相对简单,在油田实际工作中应用较广,但对储层质量的表征不够全面,而且每种方法都有其适用性和局限性[1]。
储层岩石物理相的概念由熊琦华等[2]提出,它是一个含有地质相概念的成因单元,不是单因素控制的结果,而是多种地质因素耦合的结果,这些地质因素包括沉积、成岩和后期的构造作用,可以通过岩石岩性、成分和结构体现出所划分的各岩石物理相之间的性质差异预测出物性好的致密砂岩储层。因此,岩石物理相是多种地质作用形成的成因单元,它既能通过观测反映当前储层宏观或微观的岩石物理特征,同时又能指示岩石物理特征形成时的地质成因机理,因而具备地质“相”的预测功能[3-6]。从岩石物理相入手可从储层的形成机制上评价储层,从而能进一步对勘探区域优质储层及含油气进行预测。不同岩石物理相对应的沉积微相特征及成岩作用类型均有所不同,且通过电阻率等测井技术所得到的地层信息内容主要为物理性质。而测井参数是对地层沉积、成岩、储集空间及其所含储层特征的综合响应,不同的测井参数能反应地层的岩性、储集性、渗透性和含油气特征等,尽管在敏感性上存在差异,但基于对同一地层探测的不同测井参数之间必然存在一定的联系。不同测井参数是从不同机理、特征或角度对地层的响应,包含了丰富多样的信息,这是利用测井参数进行岩石物理相识别数据基础[7-12]。
常规的点对点的机器学习方法无法有效表达测井参数的空间特征,对岩石物理相与其他测井参数之间的内在关系的表征不够充分。目前卷积神经网络(CNN:Convolutional Neural Networks)已经是成熟技术,该方法的准确率相对较高,但其在处理文中问题时接收的是测井曲线图片,这既增加了工作成本,又降低了工作效率。因此,笔者选择采用一种可解释的一维卷积神经网络(1D-CNN:One-Dimensional Convolutional Neural Networks)实现岩石物理相识别,通过不同尺度卷积提取测井参数在测井深度空间上的结构性特征,学习岩石物理相与测井参数深度特征之间的关系[13-15]。模型中引入的全局平均池化层(GAP:Global Average Pooling layer)代替了传统的全连接层(FC:Fully Connected layer),它能将测井曲线波形的动态变化部分可视化,并且通过分类激活映射(CAM:Class Activation Map)解释分类结果[16-18],从而增强了模型的可解释性。此外,由于GAP的引入减少了1D-CNN模型中参数的数量,这在一定程度上降低了模型的分类能力。为此笔者加入了扩张卷积(DC:Dilated Convolution)和批量归一化(BN:Batch normalization),并且减少了最大池化层的个数弥补GAP引起的性能下降问题。
1 可解释一维卷积神经网络
1.1 卷积神经网络概述
卷积神经网络在上世纪九十年代初被引入,专门用于图像识别。典型的CNN由一系列具有非线性激活的卷积层和池化层组成。卷积层通常由几个并行通道组成,这些通道在信号处理中应用标准卷积核的卷积操作,其中卷积核是可以训练的。此外,与标准的全连接网络相比,CNN采用权重共享的方式处理由图像或多变量序列数据提供的高维输入空间。因此,从图像处理、自然语言处理到序列数据分析,CNN被证明是各种机器学习任务中最先进的架构[19]。

其中hij是输入图像中(i,j)th个感受野的输出,Xi+f,j+h是输入图像或序列的感受野中的元素,Ki+f,j+h是卷积核,b是卷积核的偏差,每个卷积核的大小是K∈Rnr×nr。
二维卷积假设关系在图像的输入域中可用,然而,在传感器通道且没有任何空间关系的序列数据中,情况并非如此,因为二维卷积无法确保任意堆叠传感器通道之间的空间关系。一维卷积可以应用于多元序列分析。在一维卷积中,卷积核覆盖整个传感器通道,卷积核大小是nr×m。其定义为

其中hi是输入序列中(i)th个感受野的输出。本质上,卷积核跨越整个列空间,其大小是K∈Rnr×m。显然,如果传感器通道的数量很多,卷积核的大小将急剧增加,这将严重削弱CNN的权重共享能力。此外,由于nr通常选择很小,导致卷积核只能提取局部信息,即短时间范围内的特征。为解决这一难题,可通过增加CNN的深度增加卷积核的感受野,但这将导致参数过多。还有一种方式是通过增加固定膨胀率,即一维扩张卷积解决上述问题。
1.2 可解释一维卷积神经网络模型
笔者研究属于模式识别问题,其研究对象为一维的测井采样数据,是一种多元序列数据,因此可以采用一维卷积神经网络(1D-CNN),通过对目标储层各维输入的序列数据做一维卷积运算,提取该层的特征信息,进而实现目标储层的岩石物理相类型。提出的可解释一维卷积神经网络模型,与传统卷积神经网络的不同之处在于:首先,对卷积操作,采用了具有较大感受野的一维扩张卷积;其次,为提升网络性能在每个卷积层都配置了批量归一化操作;最后,为增强网络的可解释性,用GAP代替了传统的FC,在网络的输出端增加了CAM模块。下面首先给出这3个子模块的基本原理,然后给出模型的总体框架。
1.2.1 一维扩张卷积
搭建的网络需要具有多尺度聚合能力,而扩张卷积(DC)可以实现在不丢失分辨率或重新缩放图像的前提下,聚合多尺度上下文信息[20-22]。扩张卷积的特点是在卷积核中添加了空洞,这些空洞可以使用不同的扩张因子在不同的范围内应用相同的卷积核,进而增加了卷积核的感受野。
一维扩张卷积定义为
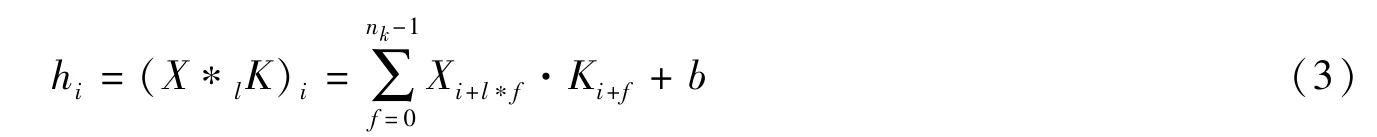
其中l是扩张因子并定义*l为扩张l倍的卷积,常见的卷积操作是扩张1倍的卷积,即l=1;Xi+l*f是扩张了l倍的输入序列,nk是感受野的大小。不同扩张率对卷积核感受野的影响如图1所示。从图1可以看出,随扩张因子的增加,卷积核尺寸的变化规律。

图1 不同扩张率对卷积核感受野的影响Fig.1 The influence of different dilation rates on the receptive field of convolution kernel
通过改变扩张因子,扩张卷积运算可以在不同范围内应用相同的卷积核(即具有相同数量的参数),从而实现更好的多尺度上下文信息聚合。该卷积可高效率实现对一维序列数据的特征抽取。
1.2.2 批量归一化
对深层神经网络,即使输入数据已做标准化,训练中模型参数的更新依然很容易造成靠近输出层的输出存在剧烈变化,这种计算数值的不稳定性将给训练有效的深度学习模型造成困难。批量归一化(BN)利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定[23],原理如下:
设一个由m个样本组成的小批量β={X1,X2,…,Xm},它们是BN层的输入。对小批量β中任意样本X(i)∈Rd,1≤i≤m,BN层的输出y同样是d维向量

并由以下几步得到。首先,对小批量β求均值和方差

其中ε>0是一个很小的常数,其作用是保证分母大于0。在上述标准化的基础上,BN层引入了两个可以学习的模型参数,拉伸参数γ和偏移参数ω。这两个参数和X(i)的形状相同,皆为d维向量。它们与分别按元素乘法和加法计算

1.2.3 分类激活映射
在训练学习阶段,GAP作用于1D-CNN模型的最终输出层,用于产生分类激活映射。GAP计算最后一个卷积层每个内核特征图的空间平均值,因此可以通过将输出层的权重应用于卷积特征图关注测井曲线波形的动态变化部分。具体过程为对在深度d处的测井曲线信号fk(d)由最后一个卷积层在样本层深度d处的卷积核k激活,然后将其作为GAP的输入。对单位卷积核k,GAP将深度层的维度降为1,它是通过

1.2.4 模型总体框架
笔者设计的1D-CNN的网络体系结构如图2所示。网络中各层的含义解释如下。

图2 1D-CNN模型架构Fig.2 The structure of 1D-CNN
1)输入层。让输入层接收与岩石物理相类别密切相关的测井曲线对应的特征向量,从而进行下一步的特征提取。
2)全局平均池化层(GAP)。用GAP代替传统FC,在处理测井曲线信息时,GAP的优点是:首先,GAP能为最后一个卷积层中分类任务的每个对应类别生成一个特征图;其次,GAP总结了空间信息,与传统FC相比,它可以解释模型的分类结果;最后,GAP减少了模型训练参数的数量,可使该模型不易过拟合。
3)Block块。由于GAP大大减小了参数的数量,这将导致模型的分类能力可能会受到影响,所以在Block块中引入了扩张卷积(DC)、批量归一化(BN)优化模型,从而弥补GAP的短板。DC可增加卷积核的感受野,这使卷积层输出包含更多范围信息的特征图,使网络具有多尺度聚合能力。BN可利用小批量上的均值和标准差不断调整神经网络中间输出,从而随着网络的深入训练,它可以使非线性输入的分布保持稳定,进而增强了网络的表达能力。并在DC和BN后采用ReLU激活函数和丢弃策略(Dropout)。采用ReLU激活函数代替传统Sigmoid激活函数的优点是:首先,它克服了Sigmoid激活函数存在的梯度消失问题;其次,它可以加快训练速度。使用Dropout可以减少网络隐藏层的节点数,能有效抑制过拟合现象的发生。
4)最大池化层。这里仅在第1个和最后1个卷积层后添加了最大池化层,因为已经有GAP减小特征图的大小并减少训练参数,它间接地代替了最大池化层的作用,所以加入过多的最大池化层只会使训练参数少之又少,进而造成测井曲线特征图的分辨率丢失。
5)输出层。在输出层中不同的神经元对应不同的岩石物理相类型。
2 基于1D-CNN的岩石物理相识别方法
2.1 指标敏感性分析方法
笔者提出通过深度学习模型连接权重运算方法,表征测井识别深度学习模型对输入测井曲线的敏感性。连接权重方法计算已建立深度神经网络模型的每个输入变量与所有隐含层和输出层的权重之和[24]。输入变量在进入模型前,所有输入变量都归一化为[0,1]

其中sj是输入变量xj的标准偏差,用于标准化输入变量的尺度。I越大,神经模型对相应的输入变量就越敏感。指标敏感性分析方法同时还可以为模型变量选择提供定量依据。
2.2 处理样本不均衡的上采样方法
通常,训练样本的类不平衡会导致分类模型偏向于多数类,这会大大影响模型的识别准确率[25]。笔者提出的处理样本不均衡的上采样方法,模拟了遗传学中的繁殖过程,并通过遗传和突变产生了新的少数样本实例。对训练集中的每个少数类别,都执行以下步骤。
1)计算出少数类别中每两个实例(xi,xj)之间的上采样距离

其中S-1是协方差矩阵。之后根据距离以降序重新排列实例。
2)将重新排列的实例分为两组,分别表示为b1和b2,它们将作为下一代的双亲。
3)依次选择两个实例xm∈b1,xn∈b2,之后将这两个实例的平均值作为一个综合实例xnew添加到少数类中。重复此步骤,直到选择b1和b2中的每个实例。
4)完成上述步骤后,如果少数类的样本数量仍然少于多数类,则综合实例xnew将作为下一代的双亲,并再次执行步骤3)。这种继承将代代相传,直到数据平衡为止。
5)最后,可以将新训练样本描述为

2.3 样本数据插值
为解决样本层厚度不相等问题,统计各样本层数据点个数,根据统计结果,统一数据点个数为L,对少于此长度的测井曲线片段进行数据插值,多于此长度的测井曲线片段采用相同原理进行数据抽稀。其中样本数据插值的方法有很多,例如分段阶梯插值、分段线性插值和分段样条插值等。其中插值节点越多,插值多项式的次数也随之增加,为避免高次插值在插值区间边界产生剧烈动荡,笔者采用分段线性插值法进行插值与抽稀,它的运算量和插值误差都较小,并且插值函数具有连续性,不会影响测井曲线形态[26-27]。原理如下。
设已知节点a=x0<x1<…<xn=b上的函数值为y0,y1,…,yn,插值函数为

满足φ(xi)=yi(i=0,1,2,…,n)且在每个小区间[xi,xi+1]上φ(x)是线性函数。
2.4 数据标准化
如果直接使用原始数据的指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱了数值水平较低指标的作用。经过标准化处理后,原始数据转化为无量纲化指标测评值,使各指标值处于同一数量级别,可进行综合测评分析。此外,数据标准化还可以满足笔者1D-CNN模型求解的需要,加快了梯度下降求最优解的速度。笔者采取Z-score的数据标准化方法,处理后的数据符合标准正态分布,原理如下

2.5 模型训练与评估
笔者将预处理后的数据分为3类:训练集、验证集和测试集。其中训练集用于训练模型,验证集用于调整模型的超参数并初步评估模型的能力,测试集用于评估最终模型的泛化能力。
笔者使用k折交叉验证的方法进行评估,目的是确定模型是否已达到足够的准确性。具体做法是将训练数据集随机划分为k个不重合的子数据集,在每次训练中,使用1个子数据集用于验证,其余(k-1)个子数据集用于训练,重复k次,每次选择不同的子数据集作为训练集和验证集。最后,对这k次模型训练的表现性能求平均。
评估指标是一种基于人工神经网络的可视化、组织和选择分类器的技术,一般几个常见的指标是:精度、召回率和F1分数,如下

其中TP,FN,TN和FP分别是真正例,假反例,真反例和假正例样本的数量,这些值可以通过表1的分类结果混淆矩阵得出。对多分类问题可以转化为二分类问题,正例为对应的某一类别,其余的其他类别均为负例。式(20)中的精度反映了模型预测负样本的能力,精度越高,模型预测负样本的能力越强。式(21)中的召回率反映了分类模型预测正样本的能力,召回率越高,模型预测正样本的能力就越强。式(22)中的F1分数是召回率和精度这两者的调和,F1分数越高,分类模型综合性能越好、越稳健,所以F1分数在模型评估中被广泛使用[28]。

表1 分类结果混淆矩阵Tab.1 Confusion matrix of the classification result
此外,笔者还进行了消融实验,以表明在GAP代替FC后模型F1分数的变化。首先,以1D-CNN的基本架构和标准的卷积核为基础,比较模型使用GAP和FC的性能差异。然后,在GAP的基础上,通过添加BN层,并将标准卷积核替换为DC评估模型分类性能的改进。
3 实际应用结果及分析
3.1 矿场资料数据
笔者研究的数据来自三肇地区的扶余油层储层,三肇凹陷位于松辽盆地中心地带,总面积大约是5 743 km2,西为大庆长垣、东南接朝阳沟阶地、北为安达向斜。它是在古中央隆起解体后,由大庆长垣和朝阳沟阶地抬升形成的,如图3所示。据大庆油田第八采油厂2009年统计结果,该区域始于1989年,共含井796口,其平均井距在2 000 m以上。笔者最终在这里收集了三肇凹陷内钻遇扶余油层的54口钻井资料,主要包括各口井内对应深度点的岩心图片、铸体薄片、扫描电镜和测井参数。

图3 数据来源地Fig.3 The source of data
3.2 指标集构造
结合专家经验、岩石物理相描述等地质专业相关知识,储层的品质主要受控于粒度、钾长石含量和方解石含量的影响。通过2.1节的指标敏感性分析方法选取对粒度、钾长石含量和方解石含量较为敏感的自然伽马(GR:natural Gamma Ray)、自然电位(SP:Spontaneous Potential)、声波时差(AC:Acoustic)、补偿中子(CNL:Neutron)与密度(DEN:Density)5条测井曲线,以岩心分析数据为标定,确定了三肇凹陷扶余层的4种岩石物理相类型(PF1相、PF2相、PF3相和PF4相)。其中PF1相主要为有利的沉积微相(水下分流河道及河口坝微相),经历建设性成岩相(主要为溶蚀相)改造后,储集层物性特征较好,多为常规储层,对应常规油层及水层;PF2相主要为有利的沉积微相,经历一定成岩作用(溶蚀相及黏土矿物充填相)而形成,储集层物性相对较好,多为产能较低油层;PF3相为有利的沉积微相背景下,经历破坏性成岩作用(压实致密相及碳酸盐胶结相)而形成,储集物性特征较差,为产能较低油层及油水层;PF4相在不利的沉积微相(水下分流间湾)下,经过破坏性成岩相叠加,储集物性特征差,多为非储层与干层。表2给出了某单井的部分样本数据,图4为该井的测井解释成果图,包含测井数据和对应的岩石物理相类型。

表2 三肇凹陷扶余层某单井的部分样本数据Tab.2 The partly sample data of a single well in Fuyu Formation,Sanzhao Sag

图4 三肇凹陷扶余层某单井的测井解释Fig.4 The logging interpretation of a single well
3.3 模型参数设置
笔者收集到的54口井的测井段大约在1 700~2 100 m范围内,采样间隔为0.05 m。通过分段线性插值,最终得到了11 547个长为292,宽为5的样本层张量。将训练集和测试集按照7∶1的比例划分,得到10 167个训练集样本(PF1相:722个,PF2相:5 044个,PF3相:4 310个,PF4相:91个)和1 380个测试集样本,可以看出训练集样本类别不均衡,其中PF1相和PF4相属于少数类,PF2相和PF3相属于多数类。笔者通过处理样本不均衡的上采样方法最终得到20 133个训练集样本,并且最后通过10折交叉验证对这些训练集样本进行训练和验证。
实验对岩石物理相进行分类的1D-CNN模型使用Windows 10操作系统,以Python3.7编程语言实现,使用的学习框架为Keras,后端为Tensorflow,实验在GPU上运行,GPU的具体规格是NVIDIA GeForce GTX 1050Ti,内存4 GByte。
详细的网络配置参数如表3所示。

表3 1D-CNN模型中的网络配置和参数Tab.3 The networks configuration and parameters in 1D-CNN model
笔者采用的小批量大小为30,表4给出了不同迭代次数对训练集准确率的影响,可以看出当训练迭代次数为200时实验效果最好。

表4 不同迭代次数对实验准确率的影响Tab.4 The influence of different iteration times on experimental accuracy
笔者使用Adam优化算法,初始学习率设为0.001,动量为0.9,权重衰减为1×10-8,学习率衰减系数为0.000 5并且随着迭代次数的增加逐渐减小。
3.4 实验结果对比
图5是笔者模型训练过程中对应的训练集和验证集的准确率上升曲线和损失函数下降曲线(以10折交叉验证中的第8次训练验证为例)。其中对于准确率,训练集最高为0.97,验证集最高为0.93;对于损失函数,训练集最低为0.65,验证集最低为0.64。图6是测试集的分类结果对应的混淆矩阵,可直观地看出模型在不同岩石物理相类别上的分类效果。其中模型对PF4相的识别没有误差,而在PF1相和PF2相,PF2相和PF3相之间的识别存在误判。图7显示了某测试井的测井解释及1D-CNN模型在该井上的预测结果,观察到真实岩石物理相与模型预测的岩石物理相几乎一致,表明该模型准确性较高,泛化能力比较强,可以达到实际应用效果。

图5 训练过程中的准确率上升和损失函数下降曲线图Fig.5 The curve of increasing accuracy rate and decreasing loss function in the process of training

图6 混淆矩阵Fig.6 The confusion matrix
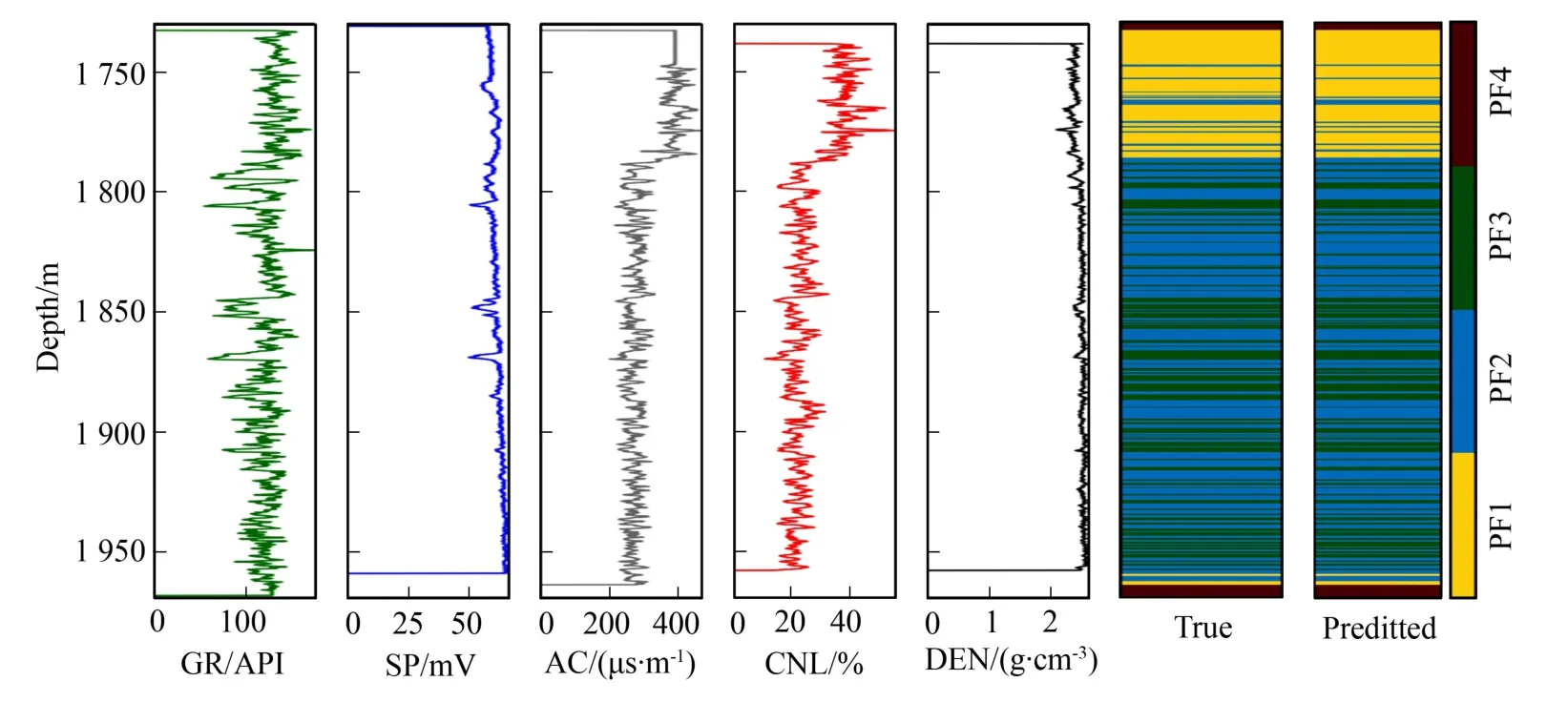
图7 某测试井的测井解释和模型识别结果Fig.7 The logging interpretation and model identification results of a test well
表5给出了消融实验结果。可以看出当模型输出端采用FC时,模型表现一般,F1分数仅为0.84。当模型采用GAP代替FC(没有加入DC和BN)时性能反而下降了,F1分数为0.67。当将DC,BN和GAP一起使用时,分类效果提高并且达到了最佳,F1分数上升到0.97。

表5 1D-CNN在消融实验下的表现差异Tab.5 The difference of performance of 1D-CNN in ablation experiment
为验证笔者方法相比现有同类方法的优势,将BP神经网络,双向LSTM和笔者的1D-CNN进行全面对比分析。其中,BP神经网络的网络层数为4,优化器为Adam,学习率为0.001,隐藏层使用ReLU激活函数,丢弃率为0.2,输出层使用Softmax激活函数。双向LSTM的网络层数为5,优化器为Adam,初始学习率为0.01且衰减系数为0.001,动量为0.9,LSTM层的丢弃率为0.3并采用ReLU激活函数,输出层为Softmax激活函数。对比实验结果如表6所示,可以得出,1D-CNN的F1分数比BP神经网络提升了0.24,比双向LSTM提升了0.05,其参数量相对较少,训练时间也相对较短。

表6 同类方法实验效果对比Tab.6 The comparison of experimental results of similar methods
3.5 实验结果分析
对3.4节中给出的实验结果,理论分析如下。由图5b可知,训练集和验证集的损失函数在大约第25个迭代周期时就开始逐渐趋于平缓,这是由于数据标准化加快了梯度下降求最优解的速度,导致笔者模型收敛较快。且图5a中验证集的准确率与训练集的准确率相差不多,说明笔者模型不存在过拟合现象。图6给出了测试集中4种岩石物理相的误识别主要出现在PF1相和PF2相、PF2相和PF3相之间,而对PF4相没有误识别。原因在于PF1相和PF2相、PF2相和PF3相属于储层中的相邻相,导致模型会产生一定的混淆。而PF4相为非储层或干层,它与储层差异明显,所以具有较高的识别精度。由于GAP会减少模型中参数的数量,如果仅仅将FC替换为GAP会导致模型训练不足,从而造成模型的分类性能下降。在GAP的基础上,通过将普通卷积替换为DC,卷积核的参数保持不变,卷积核的感受野随着扩张率的增加呈指数增长,同时保证输出的特征映射大小保持不变,再加上BN可以使非线性输入的分布保持稳定,既能弥补GAP的不足,又能保持GAP将测井曲线波形的动态变化部分可视化的优势,从而有效地提高网络的学习与泛化能力。这与表3给出的结果是一致的。表4中BP神经网络的分类效果最差,原因是它采用常规点对点的深度学习方法,导致对测井曲线的空间特征利用不充分。尽管双向LSTM可以自动提取序列化数据的空间动态信息,模型的分类性能也较高,但其固有的递归结构和繁重的网络参数会导致模型收敛缓慢,训练时间较长。相对BP神经网络和双向LSTM,笔者提出的1D-CNN模型既没有过多的网络训练参数,训练时间相对较短,拥有较低的空间和时间复杂度,又能有效利用一维测井数据的空间特征,从而有效提升了网络的分类预测能力。
4 结 语
笔者在1D-CNN模型中引入了GAP,可以将测井曲线波形的动态变化部分以一种可视化的方式展现,并通过CAM解释模型的分类结果,用于确定深度学习模型的决策是否可信,进而提高了模型分类器的性能。由于GAP减少了模型中可训练参数的数量,在模型中加入了DC和BN,以及减少最大池化层的数量弥补GAP的不足。笔者提出的可解释1D-CNN网络模型既有效利用了测井曲线的空间特征、充分表征了岩石物理相与测井参数之间的内在联系,又对1D-CNN如何做出分类决策加深了认识。笔者模型具有可重复性和高度准确性,相对人工预测岩石物理相节省了大量时间,其应用可以大大缓减储层勘探专家的许多繁琐且费力的工作,实现岩石物理相的有效分类。
