建筑物图形形状相似性计算的序列分析法
2022-01-11魏智威郭庆胜
魏智威,郭庆胜,程 璐,刘 洋,童 莹
1. 中国科学院网络信息体系技术重点实验室,北京 100830; 2. 中国科学院空天信息创新研究院,北京 100830; 3. 武汉大学资源与环境科学学院,湖北 武汉 430079; 4. 武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079
矢量图形之间的形状相似性计算是矢量图形匹配、分类和查询的基础[1],已广泛应用于GIS领域,如基于图形相似性的同名实体匹配[2]、基于模板的居民地化简[3]和基于图形形状的空间查询[4-5]等。建筑物是矢量地图的基础地理要素之一,其形状相似性计算对建筑物图形数据处理具有重要意义。
图形形状相似性计算有赖于对图形形状的定量描述,如基于图形轮廓,可以用傅里叶级数拟合图形轮廓[6-7]、用曲率尺度空间表达图形轮廓的曲率变化[8]、用序列编码图形轮廓的局部特征[1,9]等;基于图形区域,有基于矩的形状描述方法[10],也可以描述图形的面积、延展度[11]等;基于图形结构,可以用骨架线作为图形的结构化表达[12]。其中,用序列编码图形轮廓的局部特征,能较好地分析图形的轮廓形态;同时,匹配序列中基础元素度量图形间形状相似性较为形象直观,是矢量图形形状相似性计算常采用的方法[1]。用序列编码图形需确定编码的基础元素,并描述基础元素的特征。如基于特征点编码图形,可以描述特征点的角度、相对于邻近点的可变形势、邻近点相对于该点的切线距离函数等[13-15];基于边编码图形,可以描述边的方向、长度等[16];基于弧段编码图形,可以描述弧段的弓高弦长比、弧长弦长比等[17]。但是,建筑物图形通常相对简单,节点较少,基于特征点或边编码的图形相似结果离散程度高、区分度小。另外,建筑物多具有直角表达的形态特征,即几何转折明显且无连续弯曲,不适宜用弧段编码建筑物图形。
DNA序列是生物信息学研究的重要对象,有成熟的计算DNA序列间相似性的方法,如经典的NW算法和SW算法[18]。因此,本文充分考虑建筑物图形多直角表达的形态特征,将建筑物图形编码成类似DNA的序列,利用NW算法和SW算法计算建筑物图形编码序列间相似程度。
1 DNA序列比对的NW算法和SW算法
DNA序列比对是生物信息学中基因组测序的关键技术之一,通过匹配DNA序列中碱基获取不同DNA序列间相似程度[18]。其中,NW算法和SW算法是DNA序列比对时常用的两种基于动态规划原理的优化方法:NW算法旨在找到两序列在全局上的最佳匹配,可获取两序列比对的全局最大相似性(GsF);SW算法旨在找到两序列相似性最大的片段,可获取两序列比对的局部最大相似性(LsF)[18]。
首先,DNA序列比对需匹配DNA序列中碱基。依据DNA在自然界的复制规律,DNA中碱基存在匹配(match)、误匹配(mismatch)和空缺(gap)3种匹配关系[18],定义见表1。例如,给定DNA序列Qm={A,G,C,A,C,T},Qn={A,G,T,A,T},比对序列Qm、Qn可能存在如表1的匹配关系;其中,匹配对(A,A)、(G,G)、(A,A)、(T,T)为match关系,(C,T)为mismatch关系,(C,-)为gap关系。

表1 DNA序列比对举例
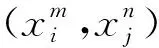

(1)
式中,xi表示序列Qm第i个位置碱基;xj表示序列Qn第j个位置碱基;“-”表示对应位置为空,即存在gap关系。
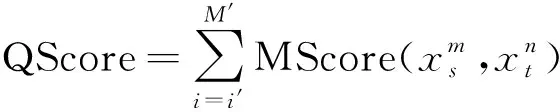
2 基于NW算法和SW算法的建筑物图形形状相似性计算
本文建筑物图形形状相似性计算过程为:首先,将建筑物图形编码成类似DNA的序列;其次,定义序列中基础元素的匹配关系与匹配对得分;最后,利用NW算法与SW算法计算相应建筑物图形编码序列间全局相似性(GsF)与局部相似性(LsF)表达对应建筑物图形间形状相似性。
2.1 建筑物图形的序列编码
考虑到建筑物图形上节点和边的关联关系,可以将节点与节点关联边构成的转折作为建筑物图形序列编码的基础元素[19]。同时,邻近转折可能会构成特殊的结构,需将邻近的转折联合起来表达。其中,考虑到数据采集、存储误差可能导致的异常节点,如重复点、共线点、尖锐点等需在编码前删除[20]。

表2 以转折为基础元素的建筑物图形序列编码
同时,邻近转折可能会构成特殊结构,特别是邻近的直角转折,往往被认为具有较强的视觉含义,常作为建筑物图形数据处理的基础单元[21]。文献[22]将凹部作为建筑物化简的基础结构;文献[23]则依据邻近转折的角度差异将建筑物外轮廓划分为凸部(凹部)和阶梯状结构等。其中,凸部则可以认为是邻近的两个凸角转折构成,如图1(b)中结构ABCD和结构EFGH;凹部可认为是邻近的两个凹角转折构成,如图1(c)中结构CDEF;另外,邻近的凸角转折与凹角转折则会组合形成阶梯状结构,如图1(d)中结构DEFG和结构HIJK。出于不同需要,也可以定义其他特殊结构,如连续的阶梯状结构等,这些结构都可以看成是凸部、凹部和阶梯状结构等的组合[22]。因此,考虑到建筑物图形中邻近转折可能会构成的基础结构,本文将邻近的两个转折联合起来作为基础元素对建筑物图形进行编码,可表示成Sm={Cm,Cm+1}。因此,图1(a)所示的建筑物若以转折ABC为起点进行编码,可以表示成以邻近转折为基础元素的有序序列:S32S25S55S52S22S22S23S34S42S23(图1(f))。对前文数据集中建筑物基础结构特征进行统计分析显示,邻近转折均为直角构成的凸部(S22)、凹部(S55)和阶梯状结构(S25和S52)占比分别为89.22%、0.57%和4.77%,是其中的主要基础结构。

图1 建筑物图形序列编码Fig.1 Building sequence coding
2.2 基础元素匹配关系与匹配对得分
2.2.1 基础元素特征描述
本文将邻近的两个转折联合起来作为基础元素对建筑物图形进行编码,即Sm={Cm,Cm+1}。其中,构成Sm的转折Cm和Cm+1因角度的凹、凸性会组合形成不同基础结构,如凹部、凸部等(图1)。另外,需记录基础元素的几何特征,如构成Sm转折的角度、边的长度等。
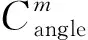

表3 基础元素类型划分
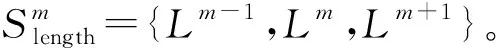
2.2.2 匹配关系与匹配对得分
建筑物图形编码基础元素(Sm)存在不同类型(SType),不同类型Sm在视觉上存在明显差异;同一类型Sm在视觉上表现出一定相似性。因此,给定匹配对(S1m,S2n),其匹配关系定义如下。
(1) match:若S1m.SType=S2n.SType,则(S1m,S2n)构成match关系。
(2) mismatch:若S1m.SType≠S2n.SType,则(S1m,S2n)构成mismatch关系。
(3) gap:若(S1m=null)∨(S2n=null)为真,则(S1m,S2n)构成gap关系。
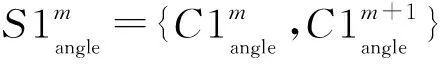
(2)

(3)
基础元素的相似性(Ss)需综合考虑基础元素的As和Ls。其中,角度和长度分别独立描述基础元素的不同侧面,相关性较弱,故Ss可以表示成As和Ls的线性组合[24]
Ss=As×w1+Ls×w2
(4)
式中,w1和w2表示权重,w1+w2=1。
若匹配对(S1m,S2n)为mismatch或gap关系,均需要罚分,表示两图形对应位置在视觉感知上不相似。参考DNA序列匹配针对gap关系的罚分,需考虑gap关系的连续性,即随着gap关系的延续,可能会加强或减弱对应匹配对的相似性[18]。因此,本文针对mismatch或gap关系的罚分见式(5)
Ps=d+(n-1)×e
(5)
式中,d表示开启一个mismatch或gap关系的罚分;n表示延续mismatch或gap关系的个数;e表示延续一个mismatch或gap关系的罚分。
同时,不同基础元素在建筑物图形中重要性不一样,匹配对(S1m,S2n)的得分或罚分需考虑相应基础元素的重要性,如文献[25]认为,人对图形进行视觉感知时,倾向于抓住主要结构而忽略次要细节。因此,重要基础元素构成的匹配对(S1m,S2n)得分或罚分往往相对高,基础元素的重要性可以用其总长度表示。假设存在匹配对(S1m,S2n),构成基础元素S1m和S2n3条边的总长度分别为sumL1m和sumL2n;若匹配对为gap关系,表示其中一个基础元素不存在,其总长度记为0。假设依据式(4)和式(5)计算出匹配对(S1m,S2n)的得分或罚分为Ss,则匹配对(S1m,S2n)的最终得分或罚分(MScore)计算见式(6)
(6)
2.3 建筑物序列相似性计算
建筑物间形状相似性(GLs)需综合考虑两建筑物的GsF与LsF。其中,指标GsF与LsF具有较大的相关性,且LsF≥0,GLs适宜表示成GsF与LsF的乘数组合,见式(7)[24]
(7)
3 试验与讨论
3.1 试验
选择OSM地图中北京地区建筑物作为源数据制作检验本文方法有效性的形状数据库,源数据见图2(a),局部区域放大见图2(b)(下载地址为https:∥www.openstreetmap.org/)。选择方形(T1)、L形(T2)、T形(T3)、C形(T4)、阶梯形(T5)、十字形(T6)共6种较常见的建筑物图形作为典型建筑物[3],从源数据中选择与对应典型建筑物(T1—T6)形状相似的194个建筑物目标构成形状数据库(图2(c)),形状数据库的统计结果见表4。其中,形状数据库中与典型建筑物(T1—T6)形状相似的建筑物是依据多名从事地图学研究的硕士生或博士生的视觉感知试验结果投票选出的,本文形状数据库已开源,下载地址为https:∥data.mendeley.com/datasets/pfmf4y344h/1。
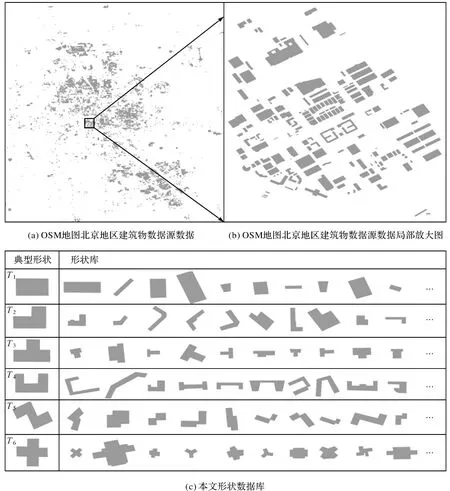
图2 形状数据库Fig.2 Shape database

表4 形状数据库统计结果
在AE10.2基础上利用C#语言二次开发实现本文方法,试验平台为一台CPU为Intel(R) Core(TM) i5-8265U CPU @1.60 GHz、内存为8 GB、操作系统为Windows 10(64位)的计算机。试验参数设置如下:式(5)中取w1=0.8、w2=0.2;式(6)中取d=-0.8,取e=-0.5。
依据形状数据库中建筑物(Bi)与典型建筑物图形(T1—T6)的形状相似性(GLs),确定Bi最相似的典型建筑物(GLs越大表示图形间形状越相似),并与人的视觉认知进行比对,结果统计见表5。其中,tp表示结果中与人视觉感知一致的建筑物数目,fp表示结果中不被认为是视觉感知相似的建筑物数目,fn表示结果中遗漏的与人视觉感知相似的建筑物数目。由表5可知,依据GLs正确识别177个,错误识别17个,识别准确率为91.2%。其中,针对不同类型的典型建筑物图形,识别准确率均达到80.8%以上,且对于阶梯形(T5)和十字形(T6)两类典型建筑物,准确率均达到100%。试验结果一定程度上说明,本文方法在基于形状的建筑物图形检索与匹配上具有较好的性能。

表5 基于形状的建筑物空间查询结果
3.2 讨 论
3.2.1 方法对比
为验证本文方法的有效性,分别基于转角函数(Ts)[9]和多级弦长函数的傅里叶形状描述子(Fs)[7]计算了建筑物间形状相似性,并与本文方法进行对比,结果见表6。其中,基于转角函数计算图形间形状相似性对于起始点的选择较为敏感,本文基于转角函数(Ts)计算建筑物间形状相似性时也参考了文献[3]的策略。不同方法的试验耗时为:基于GLs耗时为9.73 s,基于Ts耗时为3.31 s,基于Fs耗时为0.48 s。
对比表5和表6可知,基于本文方法(GLs)耗时最大,但是其准确率也最高,均明显高于基于Ts的识别准确率(59.8%)和基于Fs的识别准确率(51.5%);基于Fs的耗时最小,但是其识别准确率(51.5%)也最低。同时,基于Ts在识别阶梯形(T5)和十字形(T6)建筑物的准确率为13.8%和46.7%;基于Fs在识别L形(T2)和十字形(T6)建筑物的准确率为15.4%和33.3%;均低于50%,准确率较低。
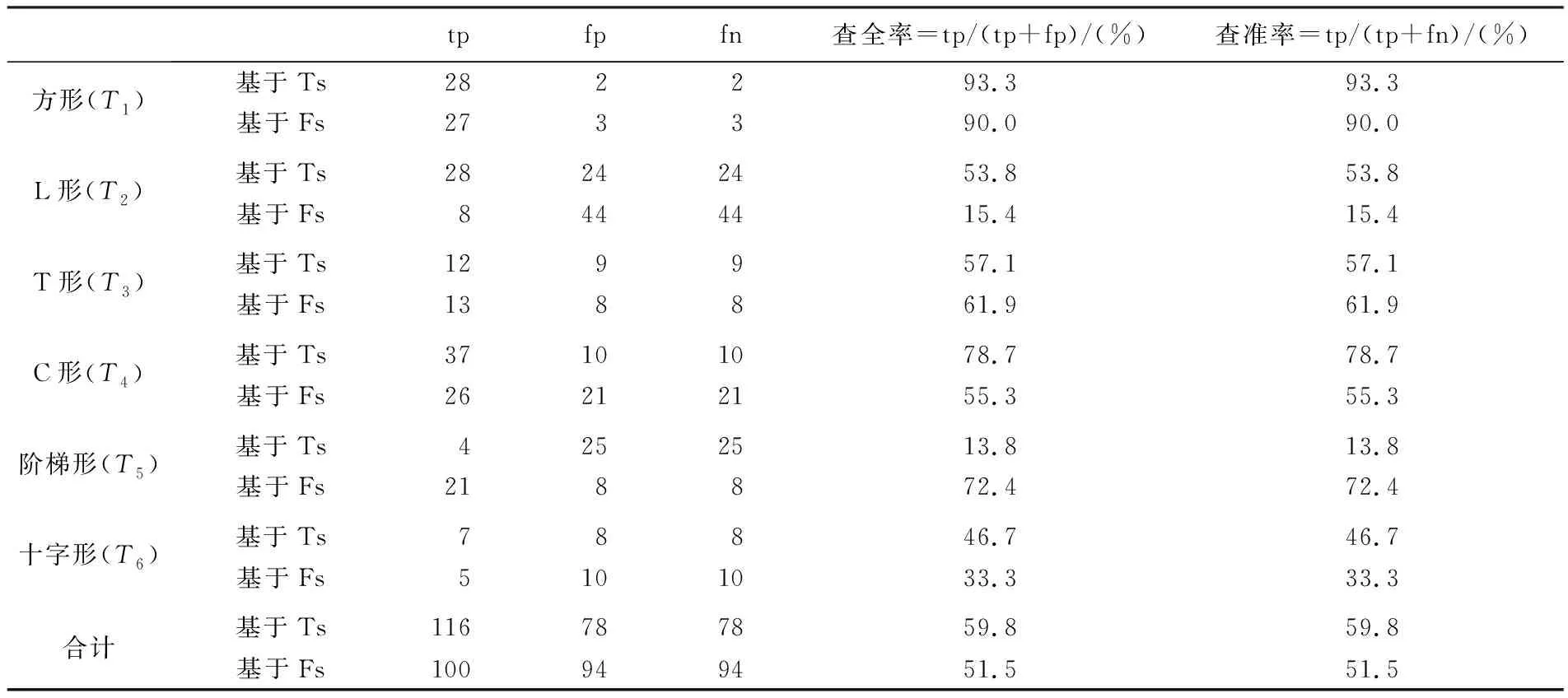
表6 基于Ts和Fs的建筑物空间查询结果
同时,选择3个典型建筑物图形对比分析3种不同方法,结果见表7。对于建筑物1,基于GLs和Fs均获得了与视觉认知一致的结果,而基于Ts获得的结果与视觉认知不一致,这是因为Ts相对于GLs没有有效考虑到连续直角构成的特殊结构,这些特殊结构在识别建筑物图形时具有较明显的视觉含义[23]。对于建筑物2,基于GLs获得了与视觉认知一致的结果,而基于Ts和Fs获得的结果均与视觉认知不一致,这是因为Ts相对于GLs在对比局部结构时,没有有效考虑到局部结构比对时可能存在的gap情况。Fs由于是基于图形轮廓从整体上利用傅里叶描述子表达图形形状,当图形间复杂程度接近时Fs相对不敏感,即表7中建筑物2与各模板相似程度均较大。同时,Fs无法有效顾及建筑物图形多直角表达的形态特征[3]。对于建筑物3,基于Fs获得了与视觉认知一致的结果,而基于Ts和GLs获得的结果均与视觉认知不一致,这是因为基于GLs的识别是以比对连续直角构成的特殊结构组成的序列为基础,若建筑物不具备多直角表达的形态特征,且两建筑物复杂程度差异过大时,GLs往往取值较低,见表7。因此,GLs相比于Fs更适宜多直角表达的简单图形间的形状相似性计算。其中,前文对Ordnance Survey开源提供的制图比例尺1∶10 000的街道层次地图中765 961个建筑物图形外轮廓角度特征进行统计分析显示,其中直角占比为96.06%,呈现出明显的多直角表达形态特征,因而,建筑物形状相似性计算较适宜使用GLs。而Fs则相对更适宜非多直角表达的复杂图形间的形状相似性计算,如面状湖泊、河流等。
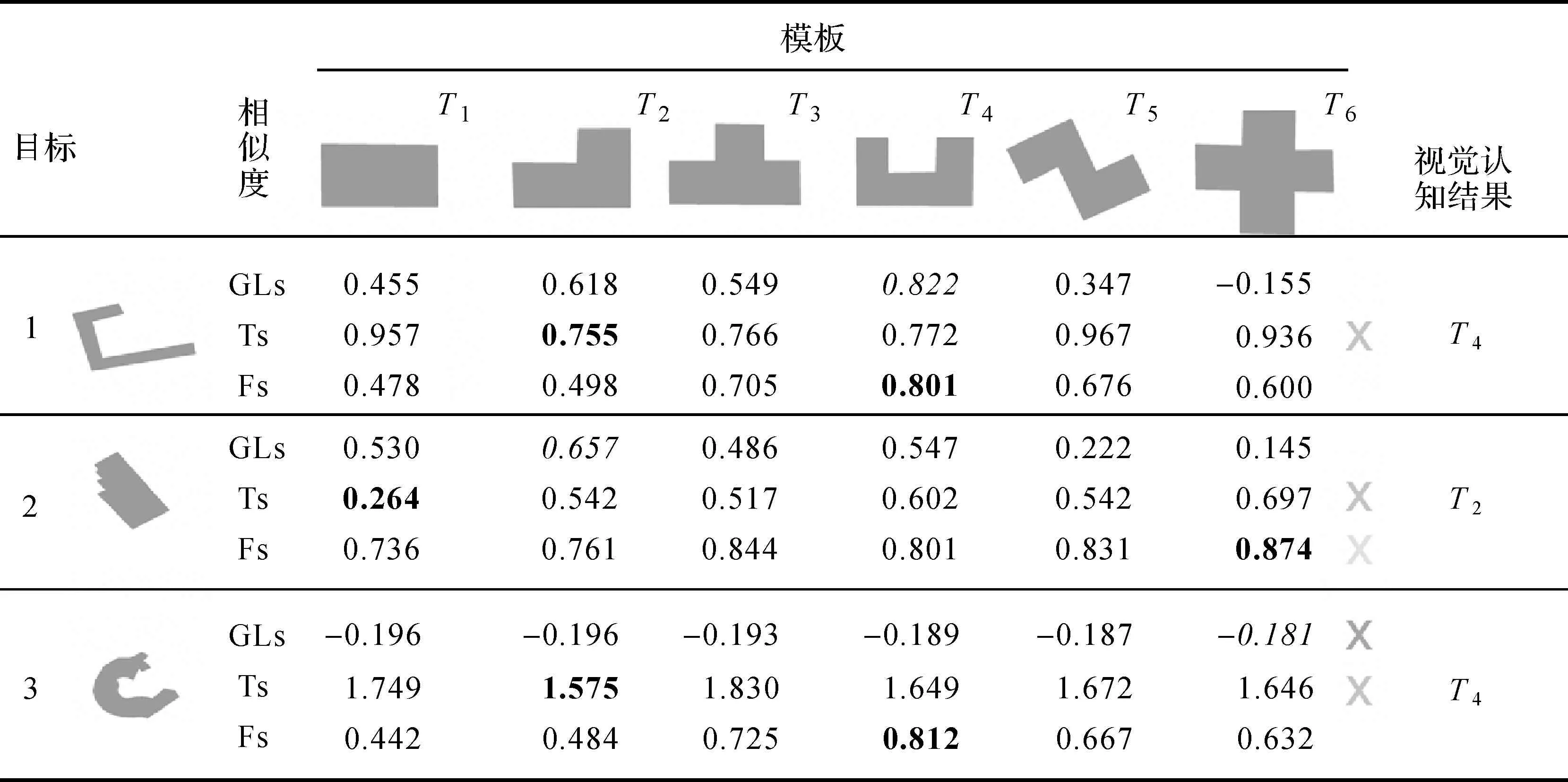
表7 典型建筑物分析
3.2.2 参数敏感性分析
式(5)和式(6)中的参数需要设置,本文依据建筑物图形特征设置了经验阈值。式(5)中,考虑到人对于形状感知时,角度较长度的视觉感知往往更明显[25-26],因此,试验中w1取值大于w2。分析参数w1、w2的影响时,固定式(6)中参数d=-0.8、e=-0.5;分别设置w1=0.0、0.1、…、0.9、1.0,对应设置w2=1.0、0.9、…、0.1、0.0。基于不同参数设置,前文试验中基于GLs的建筑物图形识别准确率(PR)变化见图3(a)。由图3(a)可知,当w1取值适当大于w2时,即w1=0.8、w2=0.2或w1=0.7、w2=0.3时,PR最高,为91.2%;当w1取值较大或w1取值小于w2时,PR均有所下降。
同时,统计参数w1、w2取不同值时建筑物图形间形状相似性(GLs)变化。图3(b)表示参数设置为w1=1.0、w2=0.0和w1=0.0、w2=1.0时,形状数据库中任选的23个建筑物与典型建筑物T3的GLs。由图可知,当w1取值减小时,GLs会减小,这是由于建筑物多直角表达的形态特征所致,即若前文中定义的基础结构构成match关系,则角度特征相似性往往较大,大于对应的长度特征相似性。另外,若w1=0.0、w2=1.0,即只考虑基础结构的长度特征相似性时,GLs均小于0.5,而基于本文的定义,理论上GLs∈[-1,1],故实际应用中w1取值需适当大于w2。
式(6)中,参考DNA序列匹配时罚分权重的设置,若用于匹配的DNA序列发生碱基对替换的可能性较高,即可能存在较多mismatch或gap关系时,罚分通常设置较高,即对于差异大的序列,可设置较大的罚分[18]。考虑到建筑物图形相对简单,若两图形存在mismatch或gap关系,则该匹配关系就可能在序列中占比较大,因此,试验中设置了较大的d和e。
固定式(5)中参数w1=0.8、w2=0.2,分别取值d=-0.8、e=-0.5和d=-0.4、e=-0.25,分析参数d与e变化对试验结果的影响。图4(a)表示参数d与e取不同值时,形状数据库中任选的23个建筑物与典型建筑物T3的GLs,由图可知,随着参数d与e取值变大,GLs会变小。图5(b)表示形状数据库中任选的23个建筑物分别与6个典型建筑物(T1—T6)GLs的标准差(STD),由图可知,当参数d与e取值较大时,STD会更大,这意味着此时GLs的区分性更强。
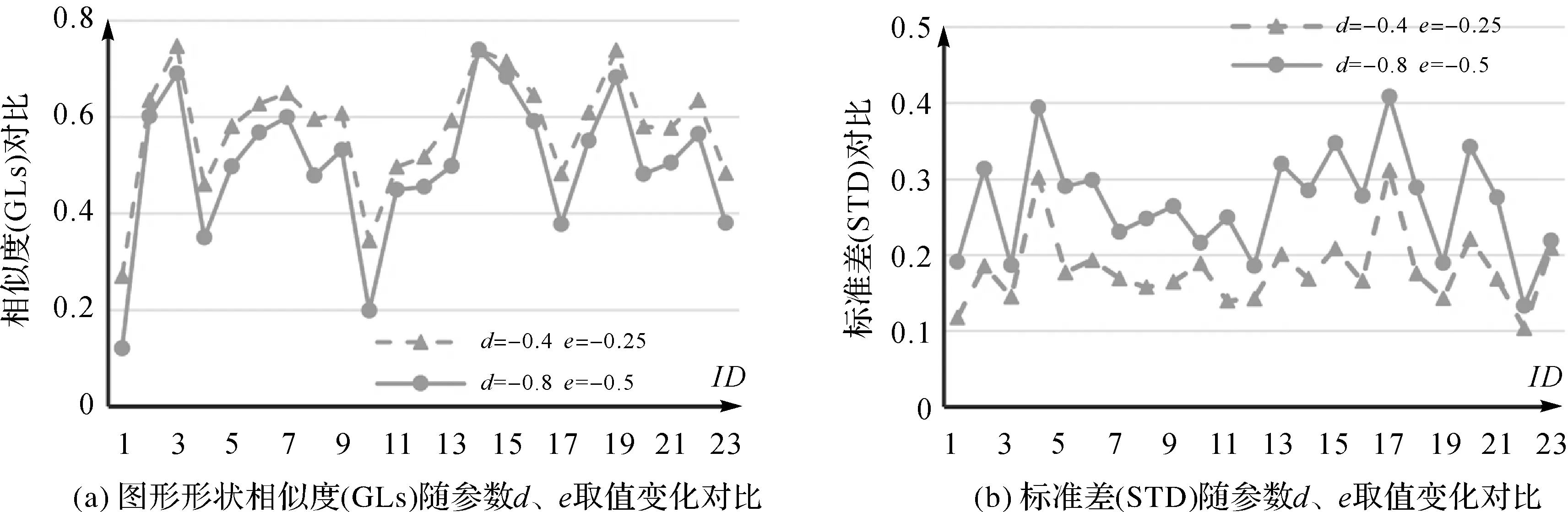
图4 参数d、e影响分析Fig.4 Influences analysis for parameters d and e
依据上文分析可知,实际应用时式(5)中w1取值需适当大于w2;式(6)中若用于计算GLs的建筑物图形复杂程度相近时,参数d与e可取较大值,因为此时GLs区分性更好;若用于计算GLs的建筑物图形复杂程度差异大时,参数d与e可取较小值。因此,本文算法针对复杂程度差异不同的建筑物图形分别设置两组参数缺省值:①w1=0.8、w2=0.2,d=-0.8、e=-0.5;②w1=0.8、w2=0.2,d=-0.4、e=-0.35。依据文献[26],建筑物图形的边数比(Er)可作为建筑物图形复杂程度差异的近似度量:若数据集中建筑物间平均边数比aEr>0.6,表示数据集中建筑物间复杂程度相近,取参数组①;否则,取参数组②。另外,本文算法参数均为可选项,实际应用过程中用户也可依据需要进行设置。
4 结 论
为了计算建筑物图形间形状相似性,本文将建筑物图形编码成序列,应用DNA序列比对的NW算法和SW算法,计算序列间相似性。建筑物图形序列编码时充分顾及了建筑物图形多直角表达的形态特征。试验证明本文方法计算的建筑物图形间形状相似性符合人的视觉空间认知。但是,实际应用中建筑物图形形状复杂多样,未来将结合机器学习方法等动态调整算法参数和基础元素匹配关系,提高算法的智能化程度。
