结合感知哈希与空间约束的室内连续视觉定位方法
2022-01-11李清泉方志祥
张 星,林 静,李清泉,刘 涛,方志祥
1. 深圳大学广东省城市空间信息工程重点实验室,广东 深圳 518060; 2. 深圳大学自然资源部大湾区地理环境监测重点实验室,广东 深圳 518060; 3. 深圳大学空间信息智能感知与服务深圳市重点实验室,广东 深圳 518060; 4. 河南财经政法大学资源与环境学院,河南 郑州 450002; 5. 武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079
作为位置服务(location-based service, LBS)的关键技术之一,室内定位在近年来引起了工业界和企业界的关注[1-2]。由于遮挡和反射效应的影响,卫星定位系统,如北斗和GPS,在室内或地下环境难以获取准确、连续的定位结果。在过去的10年中,各种室内定位技术得到了快速发展,如Wi-Fi[3-4]、蓝牙[5]、超声波[6]、射频识别(radio frequency identification,RFID)[7]、超宽带(ultra wide band,UWB)[8]和地磁[9]等。其中,Wi-Fi、RFID等定位技术由于信号容易受到室内复杂环境的干扰,定位精度和稳定性存在不足。UWB和蓝牙的定位精度较高,但对信号发射设备的布设要求同样很高,限制了这些技术的应用场景和范围。
近年来,随着视觉感知技术、图像处理技术和机器学习理论的发展,基于图像视觉信息的位置计算和场景认知技术受到广泛关注[10-12]。视觉定位技术的主要原理是利用视觉传感器(如智能手机的相机)获取当前场景的图像帧,将图像帧与带有地理标签(即具有位置信息)的数据库图像进行图像匹配,在匹配结果中查找匹配程度最高的数据库图像(即视觉相似),将其位置信息作为当前图像帧的视觉定位结果[13-19]。在两幅图像的匹配过程中通常采用图像特征描述子,例如SIFT(scale-invariant feature transform)[20]、SURF(speeded up robust features)[21]或GIST(generalized search tree)[22],直观地描述每张图像的视觉特征,对这些图像的描述参数进行匹配,利用匹配结果评价两幅图像之间的相似程度。视觉定位的结果即是相机当前的空间位置或轨迹。文献[14]通过衡量当前视觉输入与数据库图像匹配的置信度确定最佳匹配结果。文献[15—16]利用图像匹配算法来识别照片中的参考对象,利用环境参考对象匹配进行室内定位。文献[17—19]构建了室内图像数据库或场景视觉模型,通过相机探测到的视觉特征与室内图像数据库或视觉模型的匹配进行室内定位。此外,也有研究通过SfM(structure from motion)方法实现相机轨迹的几何恢复和相机位置的相对定位[23-24],结合其他方法确定轨迹的起点位置并消除累积定位误差。对于数据库图像采集,文献[24]提出了一种利用众包轨迹进行快速图像采集及位置标注的方法,能够显著提高数据库图像采集效率。室内视觉定位具有定位精度相对较高、不依赖于额外设备、成本低等优势。然而,由于视觉匹配计算的时间较长,现有大部分方法只能实现定点的位置查询或离线条件下的轨迹计算,难以实现高效率的在线视觉连续定位。如何实现连续定位条件下的高效率视觉匹配计算仍然是一个重要瓶颈问题。
图像检索技术是提高视觉匹配效率的有效方法,常用的图像检索技术包括词袋模型 (bag of words)、指数权重(vector of locally aggregated descriptor)、感知哈希方法等。其中,词袋模型通过统计单词直方图的相似性来度量图像相似性,结合倒排索引等方法能有效减少图像搜索过程中的计算量,但采用无序的单词直方图也会导致丢失大量图像信息。指数权重方法需要手动提取特征,且在向量量化的过程中会损失图像特征的精度。感知哈希方法利用一段变换生成的哈希序列表示原图像,通过度量两幅不同图像生成的哈希序列,能够快速判断出这两幅图像内容的相似性[25-27],且图像尺寸、亮度、颜色等特征的变化对相似性度量结果的影响较小。因此,感知哈希方法被广泛应用于视频篡改检测[28]、目标跟踪[29-30]、遥感影像认证[31]、图像场景主题分类[32]等问题。本文采用感知哈希方法提高视觉定位的图像搜索效率。相似性度量是图像检索技术的组成部分,主要通过计算特征向量之间的距离来实现。常见的距离计算方法包括欧氏距离、曼哈顿距离、切比雪夫距离、余弦距离和汉明距离等。其中汉明距离常用于信号处理问题,在距离计算过程中通过比较向量每一位是否相同来计算,可以用于哈希指纹的快速匹配。
感知哈希方法能一定程度上减少图像检索耗时,但仍然无法适用于对实时性和连续性要求较高的视觉定位场景。因此,本文提出一种结合感知哈希与空间约束的室内连续视觉定位方法,建立了一种双层次的图像搜索策略:在全局层次上,构建基于感知哈希方法的室内场景图像相似性度量和图像搜索方法,从全局上减少图像匹配计算量;在局部层次上,通过相机运动的空间连续性约束图像搜索范围,提高图像匹配效率。在此基础上,结合图像匹配定位和SfM方法,提出一种室内连续视觉定位算法。该算法利用双层次图像搜索和匹配确定行人全局位置,结合PDR(pedestrian dead reckoning)方法进行连续的行人航向和位置推算,从而提高室内视觉定位的连续性。由于PDR方法易受漂移误差的影响,航向角估计误差会快速累积,本文算法利用SfM方法进行行人航向角的连续估计,并利用全局图像匹配持续减少航位推算方法的累积误差,提高室内视觉定位精度。最后,本文建立了一个带有位置标签的室内影像数据集,通过多组室内定位试验对所提出方法的定位精度和计算效率进行验证。
1 感知哈希与空间约束结合的双层次图像检索策略
图像匹配方法是本文室内视觉定位的基础,通过相机图像帧和数据库图像的匹配确定相机全局位置。本节首先介绍一种基于多约束条件的图像匹配方法,然后提出双层次图像检索策略:基于感知哈希方法的全局搜索策略和顾及运动连续性的局部搜索策略。
1.1 基于多约束条件的图像匹配
图像的视觉特征提取和相似性匹配是图像视觉定位方法的基础,相似性最高的数据库图像会作为相机查询图像的匹配结果。图像匹配中常用的图像特征描述子包含SIFT、SURF和GIST等。其中GIST使用全局特征描述图像,算法稳健性较弱,常用于目标检测和场景分类问题。SIFT和SURF使用局部特征描述图像。相较于SURF算子,SIFT在图像尺度和旋转变换的情况下效果更好,稳定性更高。在视觉匹配定位过程中,查询图像和数据库图像常存在尺度不一致、旋转等问题,且匹配结果的准确性对定位精度有较大影响。因此本文利用SIFT[33]算子提取图像特征点。在查询图像和数据库图像匹配时,找到两幅图像的所有对应的特征点对,利用成功匹配的特征点对数量评价两者的相似程度。然而仅采用SIFT算法会存在大量错误匹配结果(图1(a))。因此,本文利用多种约束条件来减少错误匹配的特征点对,包括比率约束、对称性约束和随机抽样一致性算法(random sample consensus,RANSAC)[34]。
(1) 比率约束。图像a中的特征点P0与其在图像b最佳匹配点的距离可以定义为
(1)
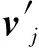
(2) 对称性约束。对称性约束是指对两幅图像的特征点进行双向特征匹配,只有两次计算过程中都匹配成功的特征点对才会被保留。
(3) RANSAC约束:该方法首先随机从样本数据集中抽选一个随机样本,即4个匹配点对;根据4个匹配点对计算单应性矩阵M
(2)
用于描述坐标变换信息,计算过程为
(3)
然后利用矩阵和匹配点坐标,迭代计算直至得到内点数最多的单应矩阵M,得到坐标转换误差和异常值,剔除异常值从而提高匹配效率,计算过程为
(4)
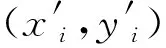
为了分析多约束匹配方法的结果,采集了20组室内场景测试图像,将每组中的2幅图像分别利用无约束匹配(SIFT)、比率约束匹配、比率约束及对称性约束匹配、多约束匹配(包含3种约束策略)4种方法进行图像匹配。其中无约束匹配方法存在大量错误匹配的特征点对(如图1(a)所示)。比率约束匹配、比率约束及对称性约束、多约束匹配的特征点对平均匹配正确率分别为88.09%、89.68%和95.80%。可以发现,在使用多种匹配策略后,室内场景图像匹配正确率逐渐提高。图1显示了不同约束策略下的图像匹配结果,错误匹配的特征点对数量随着约束策略的增加不断降低,多约束图像匹配方法能很好地剔除错误的匹配点对,保留的特征点对将用于下文的视觉定位及基于SfM的航向角估计。

图1 不同约束条件下的图像匹配结果示例Fig.1 An example of image matching under different constraint condition
1.2 双层次图像检索策略
1.2.1 基于感知哈希方法的全局搜索策略
全局图像搜索在视觉定位开始时(初始位置未知)或局部搜索匹配失败时执行。由于全图像搜索的计算量较大,本文方法在全局搜索过程中利用感知哈希方法计算视频帧与数据库图像的哈希指纹相似度,相似度低的图像不进行匹配,从而提高全局搜索效率。感知哈希方法的基本原理是从图像中提取特征内容,生成一串精简的数字或字符序列,通过度量两幅不同图像的哈希序列来度量图像相似性,度量结果具有稳健特性,可以有效快速地对两幅图像的相似度进行判断。在计算过程中,感知哈希方法利用离散余弦变换(discrete cosine transform,DCT)获取图片的低频成分,生成图像的指纹(finger print)字符串,比较不同图像的指纹信息来判断图像相似度,具体过程如下:
(1) 图像简化。缩小图像尺寸,并转化为灰度图像,只保留结构、明暗等基本信息。
(2) 计算DCT。计算图像的DCT变换,得到DCT系数矩阵,将图像从像素域变换为频率域。变换过程如式(5)、式(6)所示
(5)
(6)
式中,f(i)为原始信号;F(u)是DCT变换后的系数;N为原始信号的点数;c(u)是补偿系数,使DCT变换矩阵转化为正交矩阵。在此基础上缩小DCT矩阵,只保留其中的最低频率。计算DCT图像像素点的均值。
(3) 计算哈希值。将每个DCT值与平均值进行比较。大于或等于平均值则记为1,否则记为0,将生成的二进制数组作为图像指纹。图2是4幅不同室内图像的哈希值计算示例。

图2 4幅图像的哈希值计算Fig.2 Hash calculation result of four images
(4) 指纹匹配。使用两幅图像哈希值的汉明距离进行匹配。对于两个哈希值k1和k2,其中k1∈{0,1}l、k2∈{0,1}l,其匹配方法为
(7)
式中,d(k1,k2)的取值范围为[0,l],l是哈希指纹长度。如果d(k1,k2)小于阈值H0,则两幅图像的哈希指纹判定为相似。
在图像全局搜索过程中,首先将当前图像与数据库图像进行哈希指纹匹配,将哈希指纹判定为相似的数据库图像列入候选图像集合,利用1.1节介绍的多约束图像匹配方法进行进一步匹配,得到相似性最高的匹配结果。由于哈希指纹匹配的时间少于图像匹配,全局搜索策略能显著提高全局匹配效率。
1.2.2 顾及运动连续性的局部搜索策略
由于全局搜索的计算量总体偏大,在连续定位过程中优先使用局部搜索策略,其执行判定条件为当前位置和上一次成功图像匹配位置的距离小于阈值D0。局部搜索策略的思路是利用行人运动的空间连续性特征,在图像搜索时仅将当前位置周围局部范围内(搜索半径为D0)的图像列入候选图像集合,从而显著减少图像匹配次数。定位算法中阈值D0的设置会影响到图像匹配定位的精度和计算量:较大的D0值会导致待匹配的数据库图像数量过多,显著增加计算时间;较小的D0值会使得数据库图像搜索域变小,可能会丢失最佳匹配图像,从而影响定位精度。因此,对于阈值D0需要分析图像匹配的距离因素和匹配结果(即图像相似性)之间的关系。在室内局部环境中,图像的相似性在正常条件下会随着空间距离的增加而逐渐降低。这里将两幅图像在局部搜索过程中的相似性定义为图像匹配成功的特征点对数量。根据图像匹配测试结果的分析,当特征匹配点对数量大于20时,两幅图像的匹配结果更可靠,视觉相似程度更高。为了分析图像匹配结果和空间距离的关系,在房间、走廊和开放空间这些不同类型的室内场景中各采集了5组图像序列,每组图像序列包含试验者手持智能手机沿着相同方向行走时采集的图像帧序列。在数据采集后,将每组图像序列中的每张图像依次和序列的第1幅图像进行匹配,从而分析随着距离的增加,图像相似程度的变化情况。如图3所示,试验发现:空间距离相距越近,图像匹配特征点对的数量越多;空间距离越远,图像匹配特征点对的数量越少,并且当距离高于6~10 m时,图像匹配点对数量会变得非常少。因此,当空间距离很远的两幅图像之间匹配点对数量很高时,其可能的原因主要是室内场景布局类似,导致视觉特征高度相似。但此种情况下,如果判定两幅图像是同一位置,会导致定位误差显著增加,是视觉定位的一个重要误差来源。
图3 不同类型场景中序列图像相似性与距离的关系Fig.3 The relationship between distance and similarity of image sequences in three scenes
综合以上因素,在本文试验中(数据库图像平均采样间距约2 m),阈值D0的经验值设置为5 m,从而在兼顾视觉定位计算效率的同时,避免当前图像在局部搜索过程中被错误匹配到相距很远的数据库图像位置,减少定位误差。当局部搜索失败后,发现在当前定位位置的周围无法搜索到相似的数据库图像,再转为全局搜索策略进行全局匹配定位。对于图像采样间隔更大的室内区域(例如3~4 m),阈值D0经验值可适当增加(如7~10 m),避免因为当前位置周围搜索到的候选数据库图像数量过少而丢失最佳匹配结果。
在候选图像集合生成后,可以对集合中候选图像的匹配优先级进行排序,与行人当前位置及方向相近的数据库图像具有更高的优先级,其计算方法为
(8)
式中,C(i)表示当前图像与数据库图像i之间的空间邻近性;Ac表示当前图像的方位角;Ai表示数据库图像i的方位角;Di表示行人当前位置与数据库图像i的位置之间的距离。在局部检索过程中,具有较低C(i)值的图像将被给予较高的匹配优先级。
1.3 室内连续视觉定位算法
通过图像搜索和匹配能够得到准确的室内定位结果。然而考虑到室内数据库图像的空间分布密度,单纯依靠图像匹配难以实现连续的行人轨迹定位。因此,本文结合图像匹配和航位推算方法进行连续视觉定位。由于惯性航向角估计的偏移误差较大,因此利用SfM方法提高航向估计精度,结合PDR方法实现连续轨迹定位。最后建立了一种室内连续视觉定位算法,利用视觉定位结果持续修正航位推算误差。
1.3.1 基于SfM的航向角估计
基于SfM的航向角估计过程如图4所示,其中灰色和白色图像分别表示成功匹配的数据库图像和相机视频帧。利用张正友标定法对智能手机摄像头进行标定,估算出相机内参数矩阵。相邻帧的基本矩阵F可通过匹配的关键点对进行计算
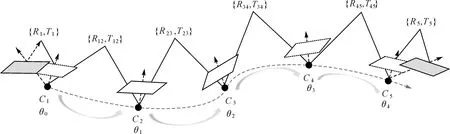
图4 基于SfM的航向角估计Fig.4 SfM-based heading angle estimation
(9)
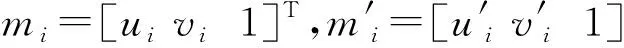

(10)
式中,Δθ为相机在t时的航向角变化,为俯仰角变化。若初始航向角为θ0,则相机在t时的航向角可计算为
(11)
式中,θt为智能手机在t时刻的航向角。SfM方法能够提高航向计算性能,然而航向误差仍然会逐渐累积。本文方法进一步利用成功匹配的数据库图像减少航向角累积误差
(12)
式中,Δθ(t-1,t)为t-1到t时刻的航向角变化;θg(t)为t时刻成功匹配数据库图像的方位角;Δθg(t)为t时刻的图像与数据库图像的方位角差,通过计算两者的旋转矩阵R进行估计。
1.3.2 室内连续视觉定位算法
在航向角估计的基础上,结合PDR方法可以实现室内连续定位。本文算法假设智能手机初始位置未知,通过航位推算进行相对坐标估计。当智能手机视频帧与数据库图像成功匹配后,即可为定位算法提供绝对坐标,如式(13)所示
(13)
式中,(xt,yt)为t时刻智能手机的坐标;(xg(t),yg(t))为t时刻之前最近匹配的数据库图像的坐标;θi为i时刻的航向角;di为智能手机在t-1时刻与t时刻之间的距离。因此,当视频帧与数据库图像成功匹配时,定位结果可以得到校正,减小航位推算的累积误差。同时,当前定位结果可以为图像局部搜索提供空间约束信息,提高视觉定位效率。
结合以上介绍的方法,提出一种室内连续视觉定位算法。算法的输入包括数据库图像数据集D、智能手机视频帧和惯性数据,输出为当前定位结果,算法过程如图5所示。
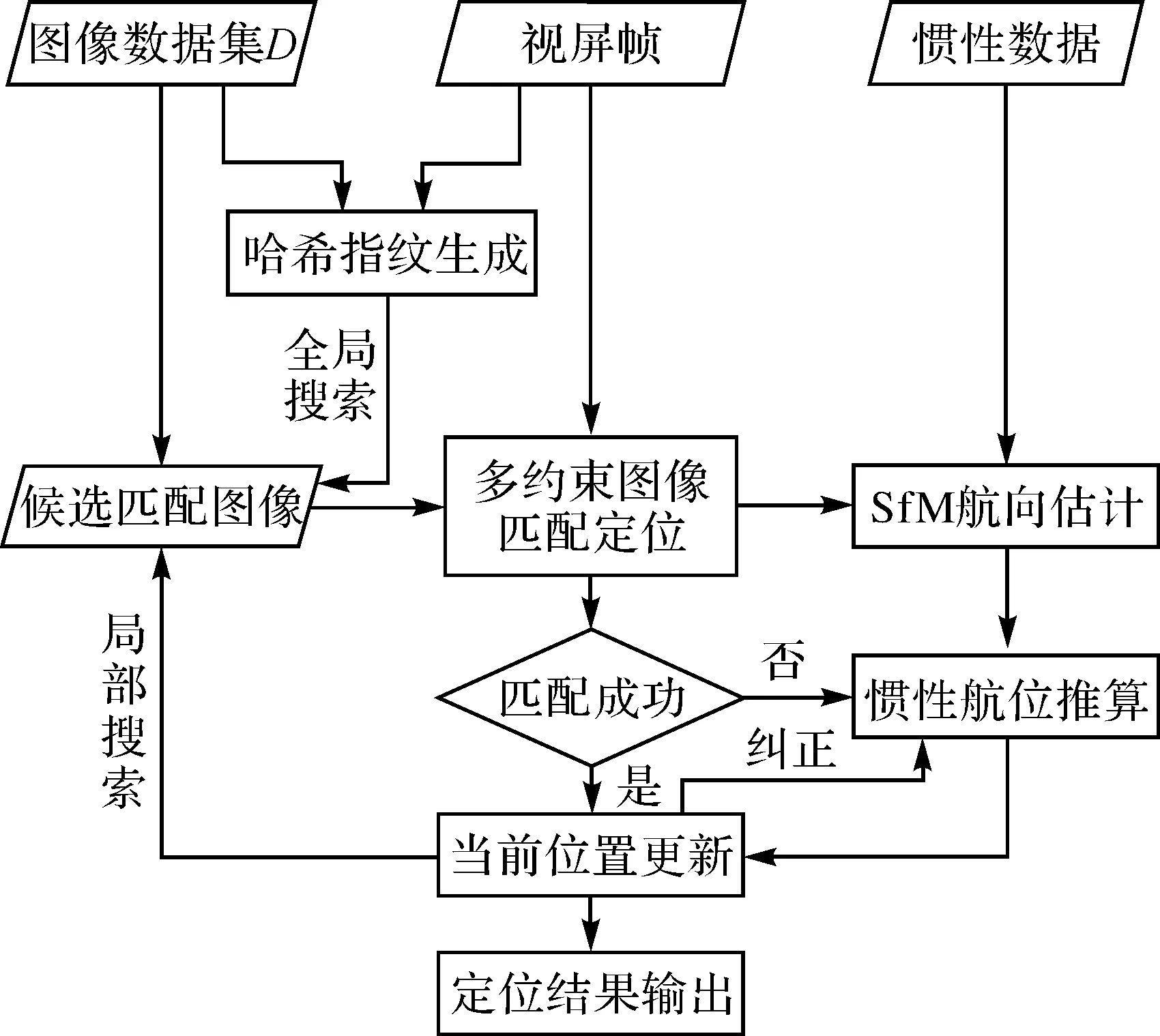
图5 室内连续视觉定位算法Fig.5 The indoor continuous visual localization algorithm
2 试验分析
2.1 试验区域
为验证所提出视觉定位方法,在深圳大学科技楼14层进行了定位试验,试验区域面积为52.5 m×40 m(图6)。试验区域各采样点(平均间距约为2 m)采集不同方向(间隔90°)的多幅图像,构建数据库图像数据集,属性包含图像、坐标和方向,共484幅图像。将所有图像的分辨率调整为640×480,计算图像的SIFT特征和哈希值。
在试验过程中,试验人员沿着3条测试轨迹正常行走,路径长度分别为55、79和80 m,具体轨迹见图7,平均行进速度分别为0.56、0.58和0.59 m/s。行走过程中使用智能手机(小米8)收集视频帧和惯性数据(保持摄像头朝前),两者的采样频率分别为30 FPS和100 Hz。路径沿途已知坐标处设置了标记点以估计试验误差。算法测试平台为一台i7 9750H CPU(2.6 GHz)的笔记本电脑。根据试验区域的图像采样点平均间距(2 m),试验中将D0的经验值设置为5 m。在图像采样间距更大的室内区域, 可以适当设置更高的阈值D0。每条路径的初始位置均设置为未知。以下共包括2组不同的试验,分别是基于双层次图像搜索策略的室内视觉匹配定位试验和室内连续视觉定位试验。
2.2 基于双层次图像搜索策略的室内视觉匹配定位试验结果与分析
本文利用3条轨迹采集的视频帧作为试验数据,通过视频帧和数据库图像的匹配进行定位,主要测试双层次图像搜索策略的定位精度与效率。视频帧中每30帧(1 s)提取1帧图像作为当前图像,利用双层次图像搜索策略将其与数据库图像进行匹配,成功匹配的数据库图像的位置作为当前定位结果。图8显示了分别利用常规匹配策略(将图像帧与所有数据库图像进行匹配)、全局搜索策略、双层次搜索策略(即全局策略加上局部策略)的计算效率对比结果。当采用常规匹配策略时,3条轨迹的平均计算时间(即所有查询影像的计算时间均值)分别为32.60、36.65和42.54 s。采用全局搜索策略时,3条轨迹的平均计算时间降低到8.91、8.84和7.90 s。采用双层次搜索策略时,平均计算时间进一步减少到1.89、1.65和1.27 s。可见,利用双层次搜索策略可以优化匹配图像搜索的范围和优先级,显著提高匹配效率。
除了计算效率外,本文利用匹配准确率和平均定位误差两个指标来评估方法的精度。匹配准确率是指轨迹上所有查询图像的总体匹配正确率;平均定位误差是轨迹上所有查询图像定位误差的均值。表1为3条轨迹平均视觉定位误差对比,在利用双层次图像搜索策略时,3条轨迹的匹配精度分别为73.33%、82.92%和64.44%,平均定位误差分别为0.77、0.62和0.73 m,均高于常规匹配策略和单独的全局搜索策略的匹配精度和平均定位误差。结果表明,双层次搜索策略的图像搜索和匹配总体精度较高,错误匹配的图像大部分是匹配到了真实图像的空间相邻图像,总体定位精度达到了亚米级。

表1 3条轨迹平均视觉定位误差对比
2.3 室内连续视觉定位试验结果与分析
2.2节试验仅利用视频帧数据,其定位结果的空间连续性取决于数据库图像的空间密度,因此,当数据库图像空间密度较低时,定位结果并非是连续的。因此,本文结合视频帧和惯性数据,利用第1.3节提出的算法进行连续定位试验,分别在离线模式(offline)和在线模式(online)两种条件下对上述3条轨迹进行定位测试。其中,离线模式是利用所有成功匹配的视频帧对轨迹的位置进行恢复。在线模式是在轨迹定位过程中,仅利用成功匹配的视频帧定位当前位置,而不用于纠正已行走轨迹部分的定位误差,即更偏向实际导航过程。
离线定位结果如图7所示,3条轨迹的平均离线定位误差分别为0.97、0.71和0.91 m,利用视觉定位结果的校正次数分别为23、31和26次(校正点位置为图中红色圆点),总体平均误差为0.86 m。该误差略高于表1(图像匹配方法)的结果。其原因是采用连续定位算法能够得到连续性更好的定位结果,虽然精度略有降低,但轨迹中定位点的平均间距由2 m减小到0.5 m。如图8所示,各轨迹的估计位置均接近于真实轨迹。

图7 离线定位结果Fig.7 Offline localization results
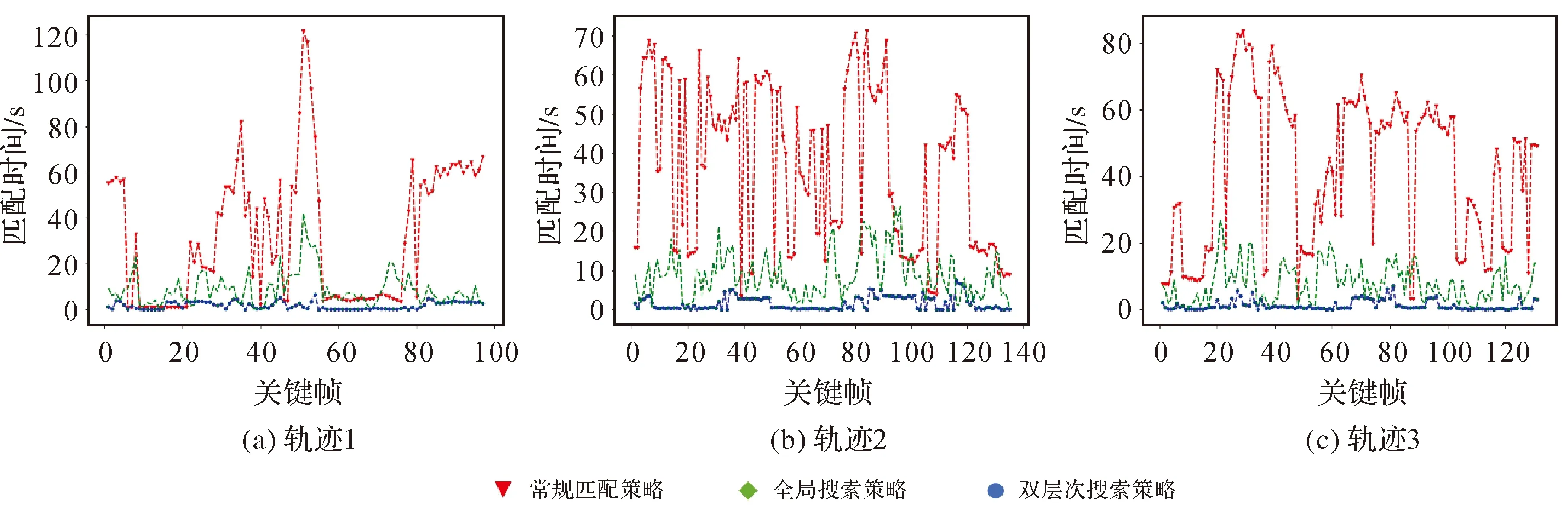
图8 3条轨迹的图像匹配时间Fig.8 The computation time of each query image from three trajectories
在线定位试验中采用了不同的方法进行对比,包括:①地图约束修正的PDR方法;②基于PDR的连续视觉定位方法;③结合SfM和PDR的连续视觉定位方法;④相机随机开启条件下的方法3。其中,方法2和方法3均采用本文连续视觉定位方法,区别在于方法2仅利用惯性信息估计航向角。方法4用于模拟实际情况,即行人的智能手机相机不一定连续打开,用于测试相机随机开启条件下的定位精度,当相机关闭时仅使用PDR定位结果直到相机再次打开。图9显示了不同方法的在线定位结果,4种方法的平均定位误差依次为12.05、1.10、0.93和1.31 m。可见,采用视觉定位条件下(方法2—方法4)的定位误差明显小于方法1,能够达到较好的定位精度。方法3的定位误差小于方法2,表明利用SfM方法能够减小航向角估计误差。此外,即使在相机随机开启条件下(图9下方黑色块表示相机开启,白色块表示相机关闭),本文方法也能实现较好的定位精度。
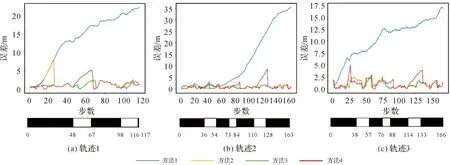
图9 不同方法条件下的在线定位误差Fig.9 Average online localization error using four different methods
在上述在线定位试验中,本文方法(即方法3)对3条轨迹的总计算时间分别为67.17、45.15和54.80 s,少于对应的轨迹行走时间(98、136和132 s)。为了进一步评估该算法的效率,本文计算了在轨迹行走期间提供每个位置估计(即每一步)所需的平均计算时间:3条轨迹的总体平均计算时间为0.42 s。从时间角度分析,定位算法每秒能平均得到约2次定位反馈,满足大众化导航应用的连续定位需求;从距离角度分析,轨迹的行进速度在0.5~0.6 m/s之间,即测试者每行进1 m可以得到约4次定位结果反馈,能够支持连续视觉定位。
3 结 语
本文提出了一种结合感知哈希与空间约束的室内连续视觉定位方法,构建了一种双层次的图像搜索和匹配策略,包括基于感知哈希方法的全局搜索策略和顾及运动连续性的局部搜索策略,通过全局与局部策略的结合提高视觉定位效率。在此基础上,提出了一种室内连续视觉定位算法,将图像匹配定位和航位推算相结合,利用SfM方法提高航位推算的航向角估计精度,并提高视觉定位的空间连续性。试验结果表明,本文方法在图像匹配定位、连续离线定位、连续在线定位模式下的平均定位误差分别为0.70、0.86和0.93 m,能够达到亚米级定位精度。在线定位模式下的平均计算时间为0.42 s,能够支持连续的视觉定位。可见,结合感知哈希方法和空间约束策略对提高视觉定位的精度和效率有显著意义。
