基于POD和BPNN的流场快速计算方法
2022-01-11贾续毅龚春林李春娜
贾续毅, 龚春林, 李春娜
(西北工业大学 航天学院, 陕西 西安 710072)
在流场分析和飞行器设计优化等领域中,获取气动数据主要有3种途径:经验公式或半工程化的经验方法;计算流体力学(computational fluid dyna-mics,CFD)方法;风洞等物理实验和试飞的方法。其中,由于CFD相比于前者求解精度更高,相比于后者成本大大降低并且安全,成为了当前获取高精度气动数据的主要手段。但是针对复杂外形或复杂流场,CFD计算十分耗时,并且收敛较慢。当需要对大量外形和状态进行CFD求解时,计算量相当可观。如何提高CFD的分析效率,加快流场分析的收敛过程,是研究人员一直以来关注的重点之一[1-2]。
提高CFD分析效率的途径可以归为两类:①从数值求解技术上对网格、格式等方面进行改进[3];②通过构建流场的近似模型,对未知状态流场进行预测。流场数据一方面由于网格单元/节点数目多,具有数据量大的特点,另一方面具有特征冗余的特点。神经网络(neural network,NN)模型适合于大数据量的建模,但是如果样本数据存在大量冗余特征,会导致模型学习困难,泛化能力弱等问题[4-5]。
降阶模型是一种将高维空间映射到低维空间的方法。采用降阶模型,可以有效地去除数据的冗余特征,提高样本量/特征数比。本征正交分解作为降阶模型的一种,在流体力学中得到广泛应用,例如,构建非结构网格有限元流体流动模型[6],Navier-Stokes方程降阶[7]等。在流场分析中,POD可以把高维流场数据降阶,映射到低维的正交基模态空间,从而分析出流场的主要特征及其对应的基模态系数。但是,单独基于POD无法实现流场预测,而代理模型可以建立从设计变量到气动数据的近似模型,并在气动优化等领域得到广泛应用。已有研究表明:将POD与代理模型结合使用,可以对流场进行预测[8-9]。邱亚松等[8]基于POD与RBF(radial basis function)、Kriging代理模型实现了变几何翼型的定常流场预测;王晨等[9]使用POD-Kriging方法实现了双圆柱非定常流场的预测。但是,传统的Kriging、RBF代理模型对于流场预测这种多输入多输出问题的建模效率较低。
NN模型可以通过隐藏层、神经元个数的设置来建立多输入参数到多输出参数的模型,并且可以保证一定的预测精度和泛化能力,因此在流场分析领域得到广泛应用[10-11]。Saleem等[12]采用了反向传播神经网络和RBF神经网络,建立了翼型表面压力系数分布到升力系数、阻力系数和力矩系数的神经网络,并应用于翼型反设计优化。Zhu等[13]使用RBF神经网络,利用NACA0012翼型的3个亚声速流场样本数据,实现了数据驱动的湍流模型建立。利用NN直接对高维流场数据(数据量与网格单元/节点数量有关)建模,会出现计算内存消耗大,训练耗时长,建模复杂等问题。
本文结合降阶模型与NN模型的特点,提出了一种基于POD和BPNN的流场快速计算方法。其创新点在于,通过引入BPNN,实现对POD基模态系数多输入多输出模型的构建。采用流场分区策略,降低POD建模难度,提高建模效率;采用聚类方法筛选建模样本,降低模型训练耗时,提高模型泛化能力。该方法被应用于亚/跨声速下变几何翼型的定常流场预测,使流场计算效率有了明显提升。
1 建模方法
1.1 POD模型
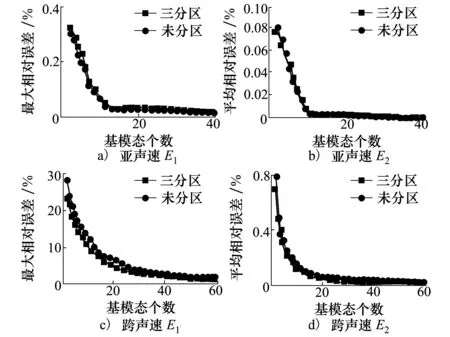
POD是一种使降阶后各维度上样本方差最大化的线性降维方法,可以通过求解样本协方差矩阵的特征值寻求方差最大轴[14]。设原始数据为X(i)(i=1,2,…,r),其中X(i)为n维向量,r为样本数目。样本的均值为

(1)
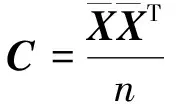
(2)
该协方差矩阵的大小为n×n,其前m阶特征值从大到小依次为λ(1),λ(2),…,λ(m),对应的特征向量为q(1),q(2),…,q(m),即POD基。这m个特征向量构成m×n阶的样本线性映射矩阵U=[q(1),q(2),…,q(m)]T,则得到降阶后的样本向量矩阵为
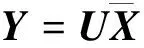
(3)
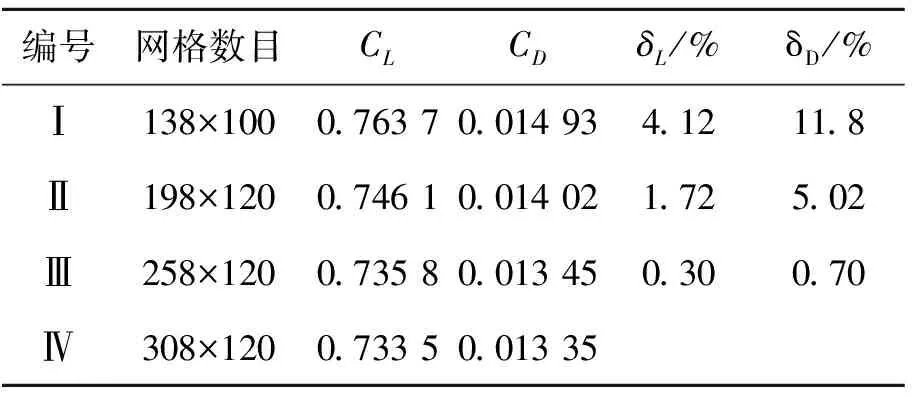
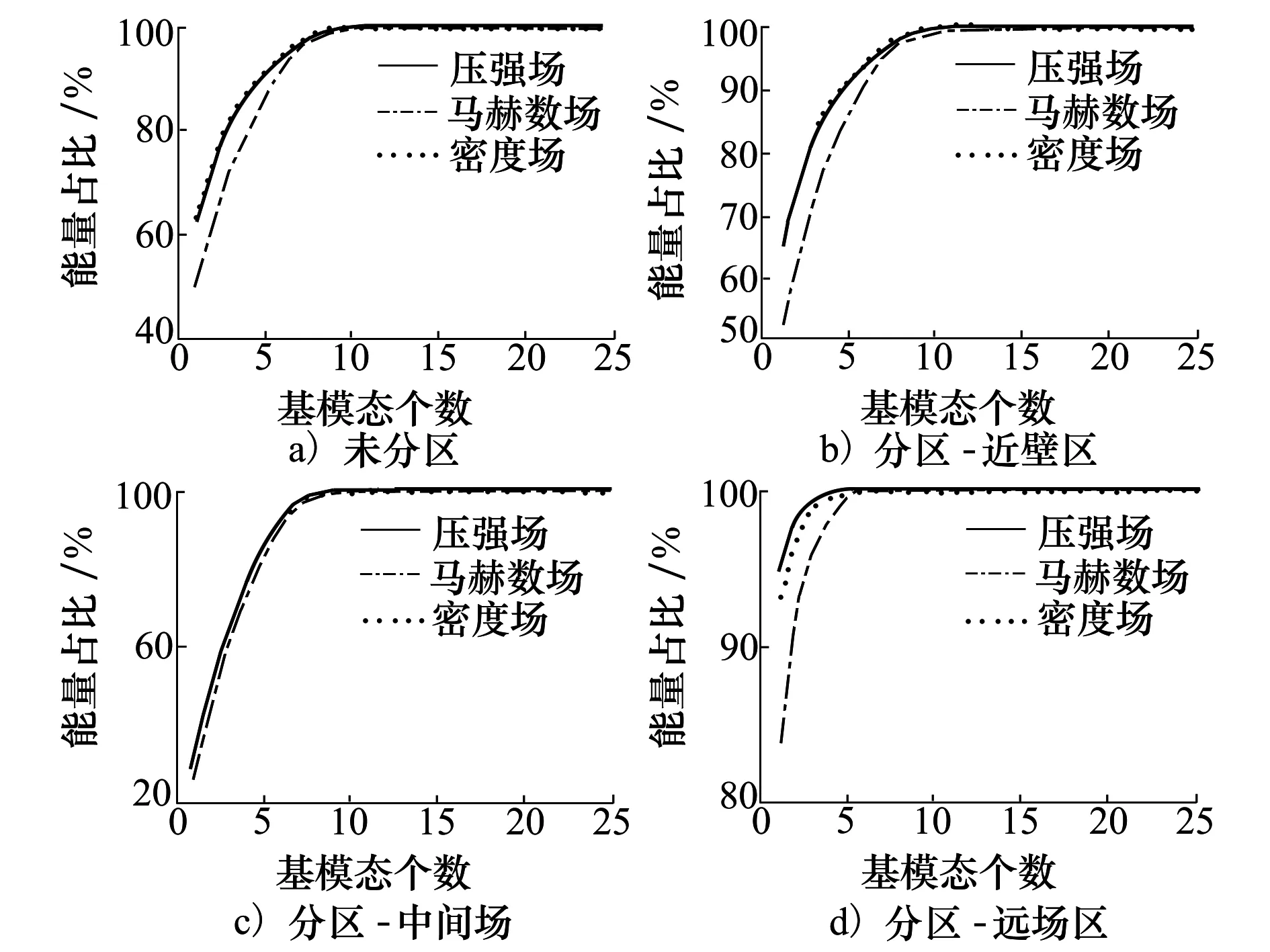
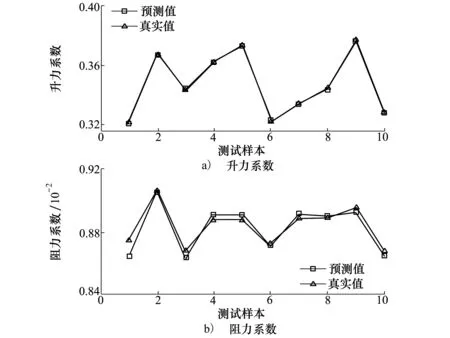
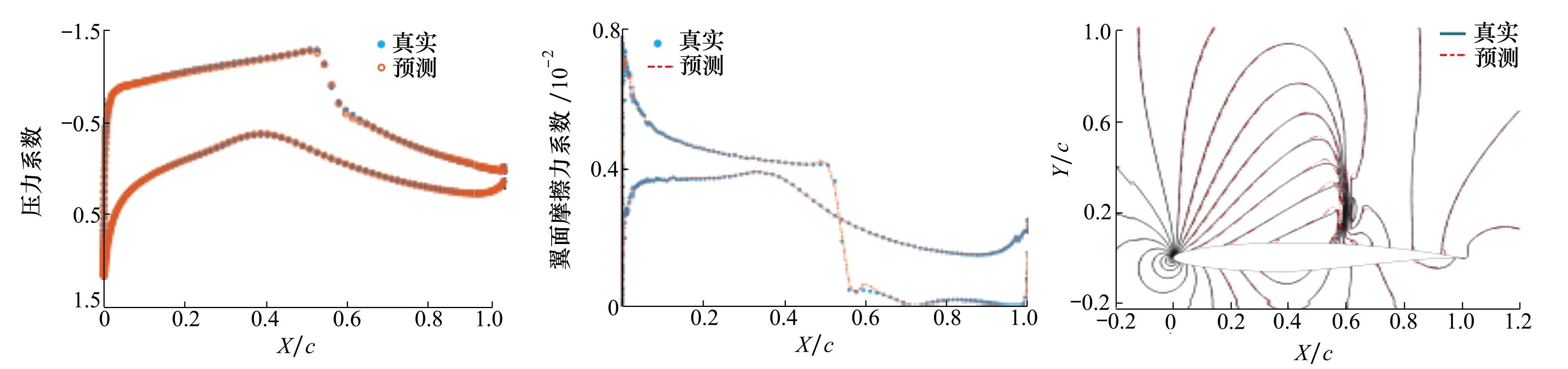
Y为m×r阶矩阵,实现了原始数据维度从n维到m维的降阶。需要注意的是,为了使降阶后的样本数据在空间中是线性无关的,应保证降维后的数据特征数小于样本数,即m BPNN由于具有较强的非线性映射能力和高度自学习和自适应能力,在分类、回归等问题中得到广泛应用。一个典型的BPNN包括输入层、隐藏层和输出层[15]。本文针对少量流场样本建模,当训练样本相对较少时,浅层神经网络在训练以及预测中往往具有更强的稳定性[16],因此本文选取单隐层神经网络,如图1所示。 图1 单隐层BPNN 该神经网络建立了从m维输入到n维输出的映射,其中输入为x=[x1,x2,…,xm]T, 隐藏层神经元个数为q,输出为y=[y1,y2,…,yn]T。ω1,ω2为权值矩阵,其大小分别为q×m、n×q。 BPNN通过反向传播误差来更新连接权值,从而完成模型的训练,具体训练步骤如下: 1) 初始化权值,一般通过设定权值范围随机给出。 2) 计算隐藏层和输出层的输出值。 3) 计算各层反向误差。 4) 判断是否满足训练要求,若满足,则表明模型训练完毕,输出模型;若不满足,更新权值,重复第2)~3)步。该网络的训练流程如图2所示。 图2 BPNN训练流程 结合POD与BPNN模型,本文提出了一种流场快速计算方法,其流程如图3所示。具体流程分为4步。 图3 基于POD & BPNN模型的流场计算流程图 1) 样本流场生成 2) 对样本流场数据降阶 以压强场数据Xp为例,其压强场均值为 (4) 标准化后的样本数据为 (5) (6) 式中,每个特征向量表示压强场的一个基模态,进而得到降阶后的m×r阶矩阵Yp (7) 当取合适值时,可以保证 (8) 由于BPNN对于多输出问题仍然适用,因此无需像传统的Kriging和RBF代理模型那样对m个基模态系数输出建立m个映射模型。这m阶基模态系数之间的量级差距较大,如果m取值较大,直接建立的BPNN难以对所有的基模态系数做出精准预测。因此,可以根据m的具体数值,例如每5~6个输出建立一个BPNN模型,即可实现较好的模型拟合效果。 4) 预测流场 对于一个新的任意输入参数Cs,通过BPNN模型可以预测出基模态系数Ys,然后对Ys进行POD重构,得到预测压强场数据 (9) 在飞行器设计和优化中,需要对大量计算状态或者几何外形进行CFD分析。针对翼型优化过程中几何外形不断变化,需要在优化迭代过程中进行大量CFD分析的问题,研究基于POD & BPNN的流场快速预测方法的效率和精度。 在对流场建模过程中,输入参数取样对应的是在变几何翼型的翼型库中选择翼型样本。本文的翼型库通过Hicks-Henne参数化方法获得。以典型的NACA、RAE系列翼型为基准翼型,在它的上下翼面各施加5个扰动,扰动的位置分别为0.10c,0.25c,0.45c,0.65c,0.80c,c为弦长,本文取1。10个扰动的大小取值范围为[-0.005,0.005],是无量纲化的系数。因此,这10个无量纲化系数可以确定出一个新翼型的几何形状。本文通过拉丁超立方采样方式在亚、跨声速下分别获取200和500组外形的系数,从而得到新翼型样本库。 以跨声速为例,对网格收敛性和流场求解精度进行验证。对RAE2822进行O型网格划分,壁面第一层网格高度为1×10-5c,计算工况为:Ma=0.729,α=2.31°,Re=6.5×106,网格数目及相应的气动计算结果如表1所示。δL,δD分别表示与网格Ⅳ的升阻力系数的相对误差。可见网格Ⅲ(见图4)可以满足收敛性的要求。因此,本文算例采用网格Ⅲ设置生成其他样本翼型网格。 图4 RAE2822网格局部图 表1 网格收敛性分析 流场数据属于高维数据。要减少建模数据的维度:①通过网格收敛性验证可以在保证计算收敛的前提下有效减少网格数目;②可以通过基于输入参数和局部流场信息对流场数据进行分区,实现区域内的降维[13]。在本文工作中,考虑到流场中不同区域的特性沿着附面层法向连续变化,将流场数据分为近壁区数据(包含全部附面层)、中间场数据和远场区数据,每个区对应网格层数均为40(跨声速下的压强场数据分布见图5)。这样,流场的某一个物理量,需要利用POD&BPNN建立3个模型,来对流场信息进行预测。数据维度降低,但是模型数目增加,因此需要对模型的训练时间和模型的泛化能力进行评估。 图5 压强场分区后的数据分布 首先对生成的样本翼型的流场数据进行POD分析,可以得到基模态流场及对应的特征值。定义前q阶基模态对应的特征值之和与所有特征值之和的比值为前q阶基模态的能量占比,能量占比表征了前q阶基模态所包含的流场信息量。图6为亚声速下分区后近壁区、中间场和远场区以及未分区情况下压强、马赫数、密度3个物理量对应场数据的基模态的能量占比。 图6 亚声速分区与未分区情况下的基模态能量占比 从数值大小上看,亚声速下前10阶基模态的能量占比超过99.6%,同样计算得到跨声速下前30阶基模态的能量占比超过99.7%,说明流场特征主要集中在前数阶POD基模态中。 分别对亚声速和跨声速的样本随机抽取90%作为训练样本进行POD降阶,将剩余10%的样本作为测试样本,进行POD重构。为了定量分析重构效果,定义测试样本的重构(或预测)误差为 (10) 对于T个测试样本的整体误差定义如下 (11) 图7为亚/跨声速下,选择不同基模态个数对测试样本压强场进行重构的误差。可以发现,亚声速状态的流场特征主要集中在前10阶,与图6的能量占比信息相吻合;跨声速状态的流场特征主要集中在前30阶。此后,基模态数目的继续增加对流场重构精度的提升不再有显著影响。从是否分区上看,分区对亚声速下模型精度的影响不大;对跨声速情况影响会大一点,但是并不显著,分区后最大误差会变小,而平均误差变化不大。 图7 亚/跨声速的压强场重构误差 POD建模的主要计算耗时来源于协方差矩阵特征值的求解。矩阵的特征值计算仅从浮点运算次数而言,其复杂度为O(n3),其中n为协方差矩阵的阶数,即流场数据的维度。因此,矩阵阶数的减少可以大幅降低计算耗时[17]。 本文所涉及的计算均在Inteli5-8500CPU、16G运行内存的PC上进行。以跨声速算例为例,图8为未分区和三分区下对单个物理量场数据的POD降阶计算时间。其中,三分区的计算时间为建立3个分区POD模型的总时间。可见,对于POD模型,3个分区建模的效率约为未分区建模的3倍。此外,由于协方差矩阵的储存空间与其阶数n的平方成正比,单个分区建模的内存消耗仅为未分区建模的1/9。 因此,针对本文算例使用分区策略可以基本保持未分区模型的精度,有效缩短POD建模耗时,降低内存占用量。通过POD重构的误差分析,可以确定亚、跨声速状态下建模的基模态个数分别为10,30以上。本文亚/跨声速下选取的基模态个数为13和35。 训练样本的数目以及选取方式对模型的训练有较大影响。首先,训练样本应保证在设计空间中均匀分布,这样模型才能较好地捕捉到空间中的全部特征。其次,训练样本量应适中,样本量过少会导致训练信息不足,容易发生欠拟合情况;样本量过多会增加训练难度,使模型训练缓慢。因此,对于不确定合适训练样本数目的问题,可以首先生成一定数目的均匀分布的训练样本,再通过样本量压缩来减少训练样本数目。 样本量压缩的方式有多种,主要采用以下3种方式:①简单删减,即直接删掉一部分样本量;②逐次删减,即逐次增加删减个数或逐次减少删减个数;③聚类分析,即将相似的样本归为一类,每类只保留一个样本。考虑压缩样本量的同时不能降低模型精度,因此本文采用了聚类分析。 在POD&BPNN模型中,输入参数是通过拉丁超立方采样获得的,其在空间中已经处于一种随机均匀分布的状态,因此不适用于聚类。而样本流场通过POD分析得到的基模态系数,针对不同的流场特征会存在差异,相似的流场其基模态系数也相似,流场差异大基模态系数差异也大。因此,对基模态系数进行聚类分析,可以将流场信息相似的样本归为相同类。这样在每个类中只取一个或少量样本作为训练样本,可以在保持模型精度的前提下,实现训练样本量的压缩。 下面对聚类取样策略的效果进行分析。亚/跨声速下聚类个数设置的范围分别为[20,190]和[20,490],亚/跨声速下训练所得模型对10个测试样本的预测误差随聚类个数的变化曲线如图9所示。 图9 聚类数目对模型预测误差的影响分析 在亚声速算例中,当聚类数目超过90时,预测误差不再有明显变化,说明在亚声速状态下通过聚类取样获得的90个训练样本可以基本表征出全部样本的特征,从而有效地避免重复样本对训练时间的消耗。同样,在跨声速算例中,当聚类数目超过200时,预测误差不再有明显变化,说明在跨声速状态下通过聚类取样获得的200个训练样本可以基本表征出全部样本的特征。因此在本文的亚声速算例中,使用聚类取样得到的90个样本作为训练集,跨声速算例中,使用聚类取样得到的200个样本作为训练集。 本文亚声速算例计算工况为:Ma=0.35,α=3°,Re=6.5×106,基准翼型为NACA0012翼型。根据2.3与2.4节的误差分析,选择分区建模的POD&BPNN模型的基模态个数为13,聚类个数为90。因此,训练样本个数为90,随机抽取10个测试样本。测试样本的升阻力系数的预测值与真实值的对比如图10所示。10个测试样本的升力系数的平均相对预测误差为0.14%,阻力系数的平均相对预测误差为0.37%。 图10 亚声速下测试样本的气动性能预测效果 取图10中第4个样本,对比预测和真实的翼面压力系数、翼面摩擦力系数分布、等压线分布,如图11~13所示。可见,亚声速下翼面压力系数和摩擦力系数的预测值与真实值无明显差异,流场等压线重合的很好,说明模型能够准确预测流场信息。 图11 亚声速下翼面压力系数分布对比 图12 亚声速下翼面摩擦力系数分布对比 图13 亚声速下等压线分布对比 表2中给出了亚声速状态下在相同的训练和测试样本条件下,是否使用分区策略的模型训练效率与预测精度指标。其中,POD单次建模耗时是指对一个物理量(如压强场)的单个区的数据完成POD降阶的耗时;BPNN单次建模耗是指对一个物理场的单个区完成所需基模态个数的训练耗时。可以看出,相比未分区,使用分区建模策略的模型总耗时有所减少,模型的精度略有提升。这种分区建模效率上的优势对于3D构型的大规模网格更为突出。使用分区建模策略在亚声速算例中是可行的。 表2 亚声速下的模型训练效率与预测精度指标对比 本文中,跨声速算例的计算工况为:Ma=0.75,α=2.79°,Re=5.7×106。根据2.3与2.4节的误差分析,POD&BPNN建模的基模态个数为35,聚类个数为200。因此,训练样本个数为200,随机抽取10个测试样本。测试样本的升阻力系数的预测值与真实值的对比如图14所示。10个测试样本的升力系数的平均相对预测误差为0.40%,阻力系数的平均相对预测误差为1.31%。以升阻力系数预测效果较差的第4个测试样本为例,对比预测和真实的翼面压力系数、摩擦力系数分布、等压线分布,如图15~17所示。可见,跨声速工况中,下翼面压力系数的预测值与真实值重合很好,上翼面的前缘与激波位置的预测与真实值稍有差异。翼面摩擦力系数在前缘和激波处的预测略有偏差。对于等压线,激波位置预测很好,但是激波前后的流场预测精度略有下降。 图14 跨声速下测试样本的气动性能预测效果 图15 跨声速下翼面压力系数分布对比 图16 跨声速下翼面摩擦力系数分布对比 图17 跨声速下等压线分布对比 本文模型对激波诱导分离泡现象可以实现较好的预测,图18为第4个测试样本的真实和预测的激波诱导分离泡,通过对比发现,预测的激波诱导分离泡的位置和形态与真实情况相吻合。 图18 激波诱导分离泡的真实与预测对比 表3中给出了跨声速状态下在相同的训练和测试样本条件下,是否使用分区策略的模型训练效率与预测精度指标。可以看出,相比未分区,使用分区建模策略的模型总耗时有所减少,模型的最大相对误差和平均相对误差均值有所降低。同样,这种分区建模效率上的优势会在3D构型中体现出来,使用分区建模策略在跨声速算例中是可行的。 表3 跨声速下的模型训练效率与预测精度指标对比 1) 本文提出了基于POD&BPNN模型的流场快速预测方法,相比于传统的代理模型,BPNN可以更好地实现对多个基模态系数的同时建模。但当几何外形的网格及其拓扑结构发生变化时,方法会失效。 2) 在POD建模中引入分区策略,可以在保证模型精度的前提下有效地缩短POD建模的时间。当流场数据量很大时(例如,百万级的网格),分区策略的优势会更加明显。 3) 针对亚/跨声速算例,通过对基模态系数进行聚类分析来确定训练样本集,可以有效地降低训练样本量,提高模型训练效率。 4) 亚声速和跨声速算例表明,基于POD&BPNN模型预测流场的升阻力系数,其预测相对误差不超过1.4%。对于跨声速流场,所建模型能很好地预测激波位置和激波诱导分离泡等复杂流动特征。1.2 BPNN模型


2 流场快速计算方法
2.1 POD & BPNN

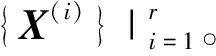


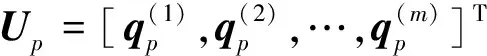

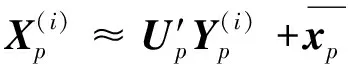

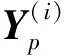


2.2 建模问题

2.3 分区策略

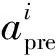

2.4 聚类取样策略
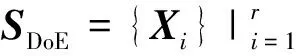
3 案例分析
3.1 亚声速变几何翼型


3.2 跨声速变几何翼型



4 结 论
