基于Dask并行加速的射电干涉成像网格化方法实现*
2022-01-10李姗姗骆开达卫守林
李姗姗,骆开达,卫守林,2,戴 伟,2,梁 波,2
(1. 昆明理工大学信息工程与自动化学院,云南 昆明 650500; 2. 云南省计算机应用技术重点实验室,云南 昆明 650500)
射电干涉阵列得到的是非均匀采样的可见度数据,在应用快速傅里叶变换对可见度数据进行成像前,需使用网格化方法将采样数据重采样到一个均匀划分的网格上。当前网格化主要使用基于卷积的方法,卷积网格化过程的实质是矩阵相乘,当数据量较大时,网格化计算非常耗时。
近年来,天文学家在提高可见度数据网格化算法性能方面做了很多研究。其中W-projection算法是目前广泛使用的网格化方法,由于该算法仅校准W项,没有校准方向相关效应的A项,当天线彼此相距较远,W项的尺寸可能变得很大,算法效率低下且内存占用率高[1]。通过将每个可见度数据的w值投影到邻近w平面的W-stacking算法,可以显著提高网格化性能,但是需要耗费额外的内存[2]。如果考虑方向相关效应,网格化的计算难度将进一步增加,同时修正方向相关效应A项和W项被称为AW-projection网格化算法[3]。在数值分析领域,文[4]提出基于 “半圆指数” 卷积核的非均匀快速傅里叶变换库(Non-uniform Fast Fourier Transform, NUFFT),将快速傅里叶变换推广到离散化的网格数据中。首次将非均匀傅里叶变换应用到射电天文中的Nifty-gridder算法,采用共享内存和多线程技术,进一步优化W-stacking算法。
综上所述,网格化算法的改进和细化都需要计算更多的卷积核,卷积计算占据网格化算法开销的主要部分。虽然采用多核中央处理器和图形处理器[5-7]可以实现并行计算,提高算法性能,但基于Python实现的上述网格化方法主要局限于NumPy多维数组计算,难以适应海量数据和实时处理的需求。近年来数组Dask.Array的提出,为超大矩阵的数值计算开辟了新途径。文[8]采用Dask并行框架,配合Pipeline技术测试LOFAR(Low Frequency Analysis Recording)数据集[9],使得原本需要11 h才能完成整个成像流程的串行化代码缩短至8 min,大大减少了干涉成像时间。本文提出基于Dask并行加速的射电干涉可见度数据卷积网格化方法,在并行计算的基础上兼顾系统的弹性缩放,主要特点是以Dask.Array矩阵分块存储和计算为核心,封装Nifty-gridder卷积网格化算法提供的Python接口,采取数据分块和延迟计算,提高了数值计算效率,配合Dask的分布式调度策略,实现了网格化算法从单机到集群的迁移。
1 网格化
射电干涉测量方程阐明了可见度数据V是天空亮度分布B的傅里叶变换,数学表达式为
Kpq=e-2πi[upql+vpqm+wpq(n-1)],
(1)
(2)
其中,(l,m,n)为观测方向的余弦坐标;(upq,vpq,wpq)为天线p和q组成的基线坐标;G和A项分别是琼斯矩阵参数化的方向无关和方向相关效应。在小场近似的条件下,指数中的wpq(n-1)趋向于0,可见度和天空亮度近似为二维傅里叶变换关系。由于基线uv轨迹的不规则性,可见度数据并非等间隔离散采样,直接对干涉测量方程进行傅里叶反演的计算代价是非常昂贵的。为了应用快速傅里叶变换算法成像,可见度数据必须重新采样到规则化的笛卡尔网格中。
射电干涉成像流程如图1。不同的光谱频率(即图像通道)测量所得的可见度数据可以独立处理。一个图像通道对应一个或多个数据通道。成像通常从空白的天空模型开始迭代,经过网格化和傅里叶逆变换运算,一个或多个明亮的源可能掩盖周围微弱的光源,使用CLEAN算法提取明亮点源到天空模型中。与网格化相反的过程是对天空模型进行快速傅里叶变换,即从天空模型中计算可见度,称为去网格化(Degridding)。测量可见度减去模型可见度数据是为了进一步提取微弱光源。重复网格化和去网格化,直到天空模型收敛。

图1 射电干涉成像流程Fig.1 The imaging pipeline of radio interferometry
干涉成像是射电天文数据处理的关键步骤。简单地将可见度数据插值到邻近的网格会导致严重的伪影,特别是图像混叠。为了抑制图像伪影的副作用,通常采用可见度数据与网格化函数(卷积核)进行卷积,然后再重采样到网格中,这一过程可以产生抗重叠效果。由于卷积核的窗函数特性,边界处的图像裁剪误差比中心位置高出几个数量级,产生较大的脏图。脏图与修正函数相乘抵消卷积核产生的误差,从而获得正确的光通量,该修正函数通常是卷积核的傅里叶逆变换的倒数。相比W-stacking算法,Nifty-gridder为提高卷积核的计算精度做了以下改进:(1)沿着w轴,对所有的可见度数据网格化到三维空间,而不是将每个可见度数据的w值投影到邻近的w平面;(2)改进后的修正函数使脏图的快速傅里叶变换和离散傅里叶变换之间的差异最小化,因此获得更高精度的脏图[10]。
2 卷积网格化实现
2.1 测量集的并行读取和分块
相比于NumPy.ndarray数组,Dask.Array具有如下优势:(1)支持将超大数组分割成许多个NumPy.ndarray小数组;(2)采用阻塞算法能对大于内存的数组进行多核并行计算。此外我们利用Xarray实现矩阵的一致性分块(chunksize),相关字段的数据可以轻易转化为Dask.Array类型。对于单(多)个测量集文件,统一将路径信息放入列表对象,使用Dask.Bag分布式加载,然后按照测量集中的FIELD_ID和DATA_DESC_ID字段分组,实现并行加载。在本实验中整个数据集划为4个子数据集(0_0, 0_1, 0_2和0_3)。以子集0_1为例,Xarray数据集定义的部分相关实验数据如表1。

表1 Xarray数据集定义的部分相关实验数据Table 1 Xarray dataset definitions for some related experiment data
2.2 网格化方法的并行实现
分布式计算是海量数据处理的有效途径,Dask并行计算框架提供了灵活多变的分布式调度方式。由于Dask任务调度方式和用户自定义的算法相解耦,用户只需切换调度方式,便可以使算法在单(多)机以多进程的方式弹性扩展,但需要根据算法的特点,选择合理的任务调度方式,以获取最佳的计算性能。本文使用最为复杂的dask.distributed调度方式在两台机器节点执行Nifty-gridder网格化算法。任务的调度算法(图2(a))采用多进程的执行方式:多个测量集文件的物理分离有利于使用多进程并行读取数据集。测量集文件通常包含多个射电源(即多个Sub-dataset),基于子数据集的任务调度更进一步细粒度化整个Nifty-gridder网格化的并行流程。算法使用高阶函数Dask.Array.blockwise封装和调用Nifty-gridder的Python接口,实现了基于子块的并行计算以及协调子块的缩聚和拼接操作(图2(b))。为降低Dask.Array在进程之间的传输成本,数值计算采用多线程的执行方式计算脏图。Nifty-gridder算法的执行过程如下:
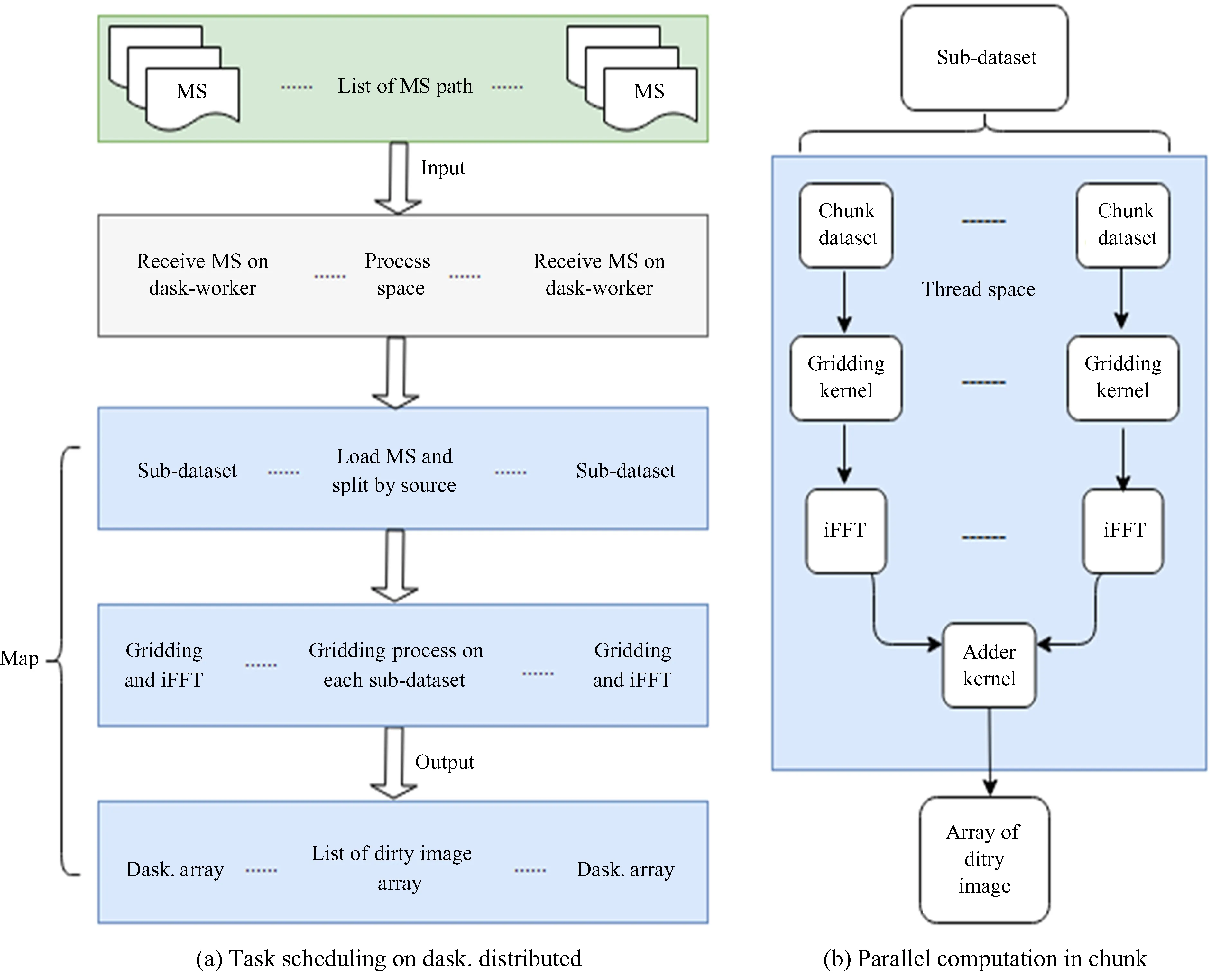
图2 (a)分布式任务调度;(b)Nifty-gridder网格化算法Fig.2 (a) Distributed task scheduling; (b) the Nifty-gridder algorithm
(1)沿w轴确定Nw个采样平面,并均匀分布到w轴(从w0~wNw-1)。
(2)沿w轴将可见度数据网格化到w平面。
(3)初始化Nx×Ny的零矩阵I,对每一个w=wi平面有:
①将每个w平面再进行uv网格化,然后执行二维傅里叶逆变换;
③将上述结果累加到矩阵I中。
(4)修正函数乘以矩阵I,得到最终的脏图。
3 实验结果和分析
3.1 实验环境
实验的数据集来源于2010年8月23日甚大型Karl G. Jansky干涉阵列对超新星遗迹G055.7 + 3.4长达8 h的观测。该阵列采用D型配置,观测频率范围为1~2 GHz,覆盖所有可用的L波段。实验的硬件环境为两台高性能服务器Intel Xeon CPU E5-2660 v4CPU@3.4 GHz处理器(56核),512 GB随机存取存储器(Random Access Memory, RAM)。本文使用CASA 5.6.2(Common Astronomy Software Applications)进行数据结果的验证。
3.2 Dask并行加速和实验结果
以4个子数据集为例,chunksize设置为20 000行,经网格化处理生成脏图,使用可见度数据的行数度量数据集的体积。在同一软硬件环境下,比较Dask.Array和NumPy版本Nifty-gridder算法的运行时间(单位: s),实验结果如表2。
由表2可知,基于Dask.Array改进的Nifty-gridder算法,其中央处理器的时间均大于进程实际占用时间,说明对于计算密集型问题,使用多核计算并行效果显著,可以明显降低程序的运行时间。以0_0和0_1数据集的对比分析为例:即使将可见度数据体积增大10.5倍(≈413 696/39 274),相应的执行时间仅增加1.85倍(≈4.95/2.68),且加速比进一步提高。然而Dask.Array是在NumPy的基础上增加了一层复杂的设计,对于较小的数据体积(0_1数据集约占40MB),NumPy可能是正确的选择,这恰恰说明Dask.Array适宜处理超大型矩阵的数值计算。
Dask允许跨集群提交Python函数,以实现并行任务,从而生成大量可以监视、控制和计算的异步调用对象。对于复杂的程序处理流程,动态的可视化监控有助于了解算法的性能瓶颈,实验执行过程中的实时性能监控如图3。

图3 网格化流程中任务流的实时状态Fig.3 The real-time state of task stream in the gridding process
为了说明Dask并行框架的优越性,通过增加测量集的输入量和限定每台机器内存占有量并保持实验环境一致。从系统资源利用率角度分析并比较基于Dask.Array和NumPy的Nifty-gridder算法性能。由图4可知,资源利用率的峰值和平均值相比NumPy版本,Dask.Array类型的网格化算法中央处理器利用率和内存占有率更低,却能获得更快的网格化执行时间(见表2)。主要因为Dask.Array数组采取分块加载和延迟计算,尚不具备计算条件的子块会驻留磁盘,以节约系统资源,而满足计算条件的子块送入内存并行执行,相反,NumPy数组必须全部加载到内存,导致较高内存的持有率。

图4 网格化流程中中央处理器和内存的使用情况对比(Dask. Array vs. NumPy)Fig.4 CPU and memory usage in the gridding process compared Dask. Array to NumPy
为了进一步验证代码的正确性,我们使用标准的CASA软件对该数据集成像,生成的脏图(图5(a))与实验结果(图5(b))进行对比,两幅灰度图中的灰白色点代表观测源。由图5可以发现,算法能正确识别射电源的分布位置。

图5 CASA和实验结果的脏图对比Fig.5 Comparison of dirty image from CASA and experimental result
4 总 结
高性能分布式并行计算已经成为射电干涉成像过程中应对高分辨率和大视场干涉阵列产生的海量数据的必要方法。可见度数据的网格化和去网格化是成像的重要组成部分,网格化并行加速无疑对提高整个成像速度有重要意义。本文使用开源的Dask分布式计算框架,结合Nifty-gridder实现了测量集的分布式加载和并行网格化加速过程,充分发挥集群的规模化优势,提高了多核中央处理器的利用率。干涉成像过程包含多个复杂的处理流程,都涉及矩阵的数值计算,而Dask.Array可以高效地处理多维超大矩阵的数值计算,因此,下一步的工作考虑基于Dask实现去网格化、校准、成像等算法的并行加速。
