基于轻量化YOLOv4的生猪目标检测算法
2022-01-10余秋冬
余秋冬 杨 明 袁 红 梁 坤
(1.天津城建大学 计算机与信息工程学院,天津 300384;2.天津职业技术师范大学 信息技术工程学院,天津 300350;3.天津农学院 计算机与信息工程学院,天津 300384)
群养猪环境下实现生猪快速准确的检测,对行为分析,生猪计数以及猪舍智能巡检投料机器人的开发至关重要。近年来受到非洲猪瘟的影响,实现养殖过程智能化,尽量减少人与生猪之间的接触势在必行。准确有效的目标检测算法能够实现目标的自动计数,同时也是生猪行为分析和养殖决策的基础。
随着人工智能技术的发展,基于图像和视频的生猪目标检测算法成为研究热点。Yu利用颜色特征及纹理特征对生猪进行个体检测。谢双云等提出了一种融合高斯混合模型(GMM)和图像粒化的运动生猪目标检测算法,克服了GMM在提取缓慢运动及静止目标效果不佳的缺陷,但检测精度较依赖粒化阈值的大小,采用人工选定参数很难满足不同时刻的猪舍环境条件。上述方法虽能完成生猪目标提取,但准确性和稳健性不足,同时特征提取方法依赖于人工观察设计和高精度图像分割,难以满足实时性的要求。
目前深度学习相关技术在生猪养殖中应用广泛,在生猪目标检测领域,Zheng等首次将深度学习模型用于提取生猪目标,Zhang等发现SSD在多只生猪检测中表现出最佳的精度与速度平衡。宋伟先提出了改进ResNet模型,有效提高了生猪个体检测的准确率。刘岩等首先利用生猪图像的二值化规范梯度特征训练SVM模型得到高质量候选区域,再对CNN模型进行分类训练。已有研究将改进的Faster R-CNN目标检测算法应用在多个生猪目标的检测中,其中文献[14]中对生猪目标检测的准确率达到96.7%,文献[16]中对生猪目标检测的均值平均精度达到90%。但上述研究均需要在猪舍顶部架设图像采集设备,检测结果较依赖于高性能的图像采集和处理设备,对养殖环境的要求较高。目前我国仍存在大量散养户,养殖环境与养殖户条件并不能支撑高性能设备的应用。同时上述算法存在以下问题:1)模型较大,参数较多,从而导致实时性不足,限制了模型在嵌入式移动终端上的部署和应用;2)在实际养殖环境下准确率难以保证;3)实验数据的问题,由于实验环境下与实际养殖环境下采集的数据集有一定差距,模型泛化能力无法保证。因此研究适合移动端设备的轻量化目标检测模型,实现群养猪环境下个体的准确检测,对智能化养殖技术的研发和推广起到促进作用。目前在农业方面,轻量化网络已经应用到果园障碍物检测,群体种鸭蛋授精信息,苹果以及苹果花的检测中,但尚未有针对生猪检测的研究。
为了解决模型大,耗时长的问题,基于轻量化模型思想,结合YOLOv4目标检测算法速度快,精度高的优点,本研究拟采用MobileNetV3作为主干特征提取网络,以期在保证检测准确率的情况下提高检测速度,为模型在嵌入式移动终端上的部署和应用提供条件。
1 材料与方法
1.1 数据集采集
为了符合实际生产需求,本研究所采用的图像均在实际养殖场环境下拍摄。图像采集自正邦集团江西省吉安市某代养场,该养殖场共32个大舍,平均每舍包含12栏,于2021年3月5日—3月11日,分别在上午、下午以及夜间拍摄。通过对图像筛选,去除模糊、拍摄不全等图像,最终从获取的图像中选取其中15个栏位内中的1 000张图片作为原始数据集。为了保证模型的泛化能力,以不同视角和不同遮挡程度拍摄图像,增加数据集的普适性。
1.2 数据集制作
本研究训练模型采用PASCAL VOC数据集格式,使用LabelImg标注工具对每张图片中生猪目标所在区域进行手工标注矩形框,标注区域为生猪在任意姿态下最小的外接矩形,得到XML文件用于训练。标注图像后,随机挑选图像进行数据增强扩充数据集,扩充后数据集为2 272张,数据增强方式见表1。数据集划分训练集、验证集和测试集,其中训练集1 900张,验证集144张,测试集228张。
表1 数据增强方法
Table 1 Data enhancement methods
方法Method选取图片数量或具体操作Thenumberofpicturesorconcreteoperations垂直翻转Verticalflip随机选取50%的图片。镜像翻转Mirrorflip随机选取50%的图片。调整亮度Adjustbrightness随机选取20%的图片,将像素值乘0.5~1.5。高斯模糊Gaussianblur随机选取20%的图片,σ=(0,3),σ为正态分布的标准偏差。仿射变换Affine随机选取10%的图片,将图像尺寸放缩率设置为80%~90%。
2 轻量化生猪目标检测算法
2.1 YOLOv4目标检测算法
YOLOv4算法将目标检测看作一个端到端的回归问题,输入图像直接计算分类结果和对象的位置坐标,得到最终结果,检测精度和速度较其他算法有了一定提高,其结构见图1(a)。该算法包括用于提取特征的主干网络(Backbone)、用于特征融合的颈部网络(Neck)和用于分类和回归的检测头(Head)3部分。YOLOv4算法是在YOLOv3的基础上,对主干特征提取网络,特征融合网络、激活函数,损失函数等进行了优化,使YOLOv4算法在速度和精度之间达到了最优的平衡。YOLOv4将特征提取网络替换为CSPDarknet53,激活函数替换为Mish激活函数,在降低计算量的同时保证了算法的准确率。在颈部网络中,将YOLOv3采用的特征金字塔网络(Feature pyramid network,FPN)改为包含空间金字塔池化(Spatial pyramid pooling,SPP)模块(图1(b))的路径增强网络(Path aggregation network,PANet)模块。SPP模块通过最大池化的方式,将输入特征图转化为不同尺度的特征图,然后将不同尺度的特征图与原特征图进行Concat操作拼接并输出,有利于扩大卷积的感受野。检测部分延用了YOLOv3中的检测头。并在训练过程中使用了Mosaic数据增强、Label smoothing平滑,CIOU损失函数,学习率余弦退火衰减等训练技巧,提高了模型的准确率。

图1 YOLOv4网络结构图
2.2 改进的YOLOv4生猪目标检测算法
虽然YOLOv4目标检测算法在精度和速度已经达到了较优平衡,但其主干特征提取网络CSPDarknet53使用了大量堆叠的残差结构,导致其在提取特征过程中需计算的参数量巨大,耗时较长,难以嵌入到移动端设备,限制了其在农业中的进一步应用。因此研究轻量化模型对其在农业中的应用和发展有着重要的意义。本研究在YOLOv4目标检测算法的基础上,使用去掉分类以及输出层的MobileNetV3网络替换原有的特征提取网络CSPDarknet53网络。为进一步减少参数量,使用深度可分离卷积替换颈部网络中的部分普通卷积。改进后的整体网络结构如图2所示。

图2 轻量化生猪目标检测算法整体结构
MobileNetV3包括MobileNetV3-Large和MobileNetV3-Small这2种结构,在检测任务中由于MobileNetV3-Large与MobileNetV3-Small在精度相同的情况下,速度提升了25%,因此本研究选取MobileNetV3-Large作为基础网络。由去掉分类和输出层的MobileNetV3网络组成改进后的主干特征提取网络,包括7个逆残差模块(Inverse residual block,IRB)和8个引入注意力机制的逆残差模块(SE inverted residual convolution blocks,SEIRB),具体结构参数见表2。颈部网络和预测头仍采用YOLOv4原结构中的SPP+PAN+YOLO Head结构,使用深度可分离卷积替代原有PANet结构中的普通卷积。
表2 特征提取网络参数
Table 2 Feature extraction network parameters
输入Input具体操作Operator通道数/个No.ofchannels激活函数Activationfunction步长Stride输出Output416×416×3Conv2d16H-Swish2416×416×3208×208×16IRB,3×316ReLU1208×208×16208×208×16IRB,3×324ReLU2104×104×24104×104×24IRB,3×324ReLU1104×104×24104×104×24SEIRB,5×540ReLU252×52×4052×52×40SEIRB,5×540ReLU152×52×4052×52×40SEIRB,5×540ReLU152×52×4052×52×40IRB,3×380H-Swish226×26×8026×26×80IRB,3×380H-Swish126×26×8026×26×80IRB,3×380H-Swish126×26×8026×26×80IRB,3×380H-Swish126×26×8026×26×80SEIRB,3×380H-Swish126×26×11226×26×112SEIRB,3×3112H-Swish126×26×11226×26×112SEIRB,5×5112H-Swish113×13×16013×13×160SEIRB,5×5160H-Swish113×13×16013×13×160SEIRB,5×5160H-Swish213×13×16013×13×160Conv2d,1×1960H-Swish113×13×960
注:输入和输出为图片尺寸乘通道数,其中图片尺寸单位为像素,通道数单位为个;IRB为逆残差模块,SEIRB 为引入注意力机制的逆残差模块,Conv2D为卷积操作,1×1、3×3、5×5为卷积核大小。
Note: Input and Output are the sizes of the picture multiplied by the number of channels.The unit of the size of picture is pixel, and the unit of channels is the number.IRB is inverse residual block.SEIRB is SE inverted residual convolution blocks,Conv2D is the convolution operation.1×1, 3×3 and 5×5 are the sizes of convolution kernel.
2
.2
.1
K-
means++
目标框优化YOLOv4算法预设了9个目标框(Anchor box),分别用于76×76、38×38、19×19这3个不同尺度的 YOLO 检测头预测出目标的边界框(Bounding box)。这些 Anchor box 是在PASCAL VOC 数据集上通过边框聚类得到,包含了人、飞机、牛羊,鸟类等尺度差别较大的目标,针对本研究的生猪目标检测数据集,使用预设的Anchor box 会使得检测头计算交并比(IOU)时筛选不出合适的Bounding box,严重影响模型的性能。因此为提高Bounding box 的检出率,本研究首先使用K-means++算法针对数据集中目标大小进行边界框聚类分析。在本研究的数据集上得到的Anchor box宽和高为(42,40),(51,102),(80,59),(82,141),(104,232),(129,84),(171,146),(196,294),(334,226),单位为像素。
2
.2
.2
深度可分离卷积Howard等在2017 年提出了专门用于嵌入式移动设备的轻量化模型 MobileNetV1,使用深度可分离卷积(Depthwise separable convolution,Conv-dw)代替标准卷积(图3),并将激活函数替换为ReLU6,可以让模型更早地学到稀疏特征。ReLU6函数公式为:

M和N分别为输入和输出的通道数;Dw和Dh为输入数据的长和宽;D′w和D′h为输出数据的长和宽;Dk为卷积核大小。
Y
=min(max(feature,0),6)(1)
式中:Y
为ReLU6函数输出;feature为输入特征。标准卷积的过程(图3(a))是将各通道的输入特征图与相应的卷积核做卷积操作后相加再输出特征。传统标准卷积操作的计算量n
为:n
=D
·D
·M
·N
·D
·D
(2)
深度可分离卷积(图3(b))把传统卷积中的一步卷积操作分为1个 3×3 的深度卷积(Depthwise convolution,Dw)和1个 1×1 的逐点卷积(Pointwise convolution,Pw)2步操作,其卷积操作计算量n
为:n
=D
·D
·M
·D
·D
+M
·N
·D
·D
(3)
二者之间的计算量比值为:
(4)
利用深度可分离卷积后,计算量和参数会减少为原来的 1/4 左右,显著地减少模型大小,提高检测速度。
2
.2
.3
逆残差模块MobileNetV1中引入了宽度因子和分辨率因子,容易导致丢失大量特征,同时网络前向传播过程中由于 ReLU 激活函数的存在,在提取低维特征时会破坏其非线性,导致网络在训练过程中存在线性瓶颈。因此Sandler等结合深度可分离卷积,通过先使用1×1的卷积升维,再通过深度卷积后使用一个逐点卷积降维的操作有效地丰富了特征数量,同时使用 ReLU6 代替 ReLU激活,提升了网络的稳健性。为进一步缩减网络模型大小,提升检测速度,Howard等在MobileNetV3 网络中引入了注意力机制模块改进逆残差模块(Inverted residual blocks with SE, SEIRB),并使用 H-Swish 函数作为激活函数。H-Swish函数的计算公式为:
(5)
式中:x
为H-Swish函数输入。本研究模型的主干网络由具有SE模块和不具有SE模块的逆残差模块(图4)组成。
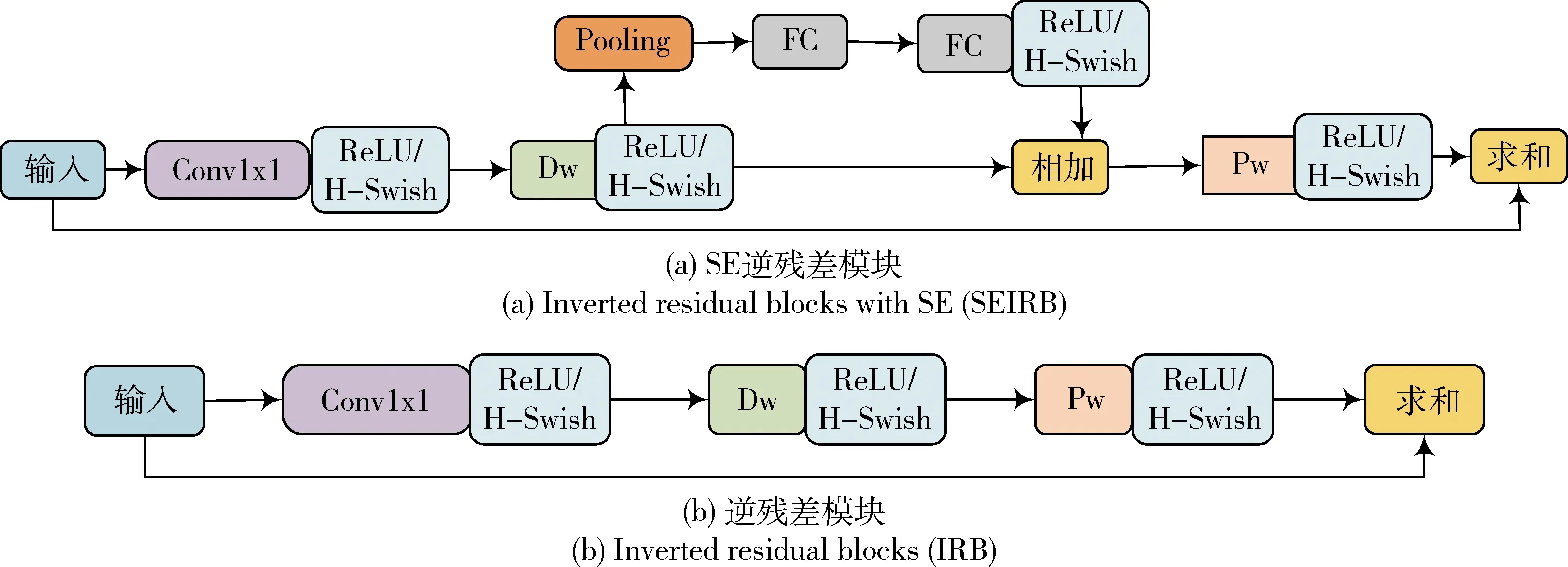
图4 逆残差模块
3 模型训练与结果分析
3.1 试验环境
生猪目标检测模型实验使用PyTorch框架搭建网络,并在工作站中训练。工作站配置为intel(R)Xeon(R)Gold 5222型号 CPU,显存11GB的GeForce RTX 2080 TI型号GPU,搭载Centos8.2系统,python版本3.6.8,深度学习平台PyTorch-gpu=1.7,安装CUDA10.1版本和Cudnn 7.6.0版本的深度学习加速库。
3.2 模型训练
模型输入图像尺寸为416像素×416像素。训练参数为:批处理大小为16,共迭代训练350次,动量0.9,初始学习率0.001,衰减系数为0.9。
3.3 结果分析
3
.3
.1
评价指标本研究中检测评价的指标包括平均精度(Average precision,AP)、准确率(Precision,P
)、召回率(Recall,R
)、调和均值F
、检测速度和占用内存。P
、R
和F
的计算式分别为:(6)
(7)
(8)
式中:TP(True positive)为将猪只正确检测为生猪目标的数量;FP(False positive)为将其他目标错检为生猪目标的数量;FN(False negative)为生猪目标漏检的数量;F
为准确率与召回率之间的调和均值,该值越逼近于1表示模型优化的越好。根据准确率P
和召回率R
绘制P
-R
曲线,与坐标轴间的面积即为AP值。3
.3
.2
测试结果及分析迭代训练300次后,每一代保存一次模型参数。图5为本研究算法的loss曲线,可以看出,模型在第10代迅速收敛,并在第200代维持在较低水平。
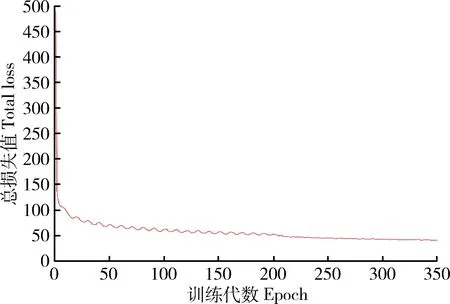
图5 本研究算法损失值曲线
将本研究算法与近些年具有优势的算法进行对比,包括YOLOv4算法,YOLOv4-tiny算法,CenterNet算法以及RetinaNet算法。上述算法用相同的数据集和训练参数进行训练,5种模型检测结果见表3。可见,本研究算法在进行生猪目标检测时与YOLOv4算法相比在准确率上提高了0.06%,召回率提高了2.94%,调和均值提高了0.01,平均精度提高了3.67%;由于改进过后结构中使用了大量深度可分离卷积结构,使得模型大小以及检测速度有了大幅度提升,大小压缩为YOLOv4算法的1/5,检测速度提高11帧/s。与CenterNet和RetinaNet相比,在准确率、召回率、调和均值和平均精度方面分别提高了1.92%,10.01%;25.43%,0.26%;0.16,0.05;9.87%,0.29%。模型大小压缩为CenterNet和RetinaNet的约2/5。与YOLOv4-tiny相比,虽然在模型大小以及检测速度上并不优于YOLOv4-tiny,但在准确率、召回率、调和均值、平均精度方面均有了较大的提升,分别提高了3.26%、16.6%、0.11、10.21%。试验表明本研究改进后的算法在准确率和检测速度具有更优的平衡;虽然模型大小是YOLOv4-tiny的2倍,但53.7MB仍可以满足实际生产需求。在检测速度方面,本研究算法检测一张图片在CPU环境下需要0.4 s,在GPU环境下仅需要0.01 s,足以满足实际生产需求。
表3 5种模型对生猪目标检测数据集的检测结果
Table 3 The results of five models detected on pigs object detection dataset
模型Model准确率/%Precision召回率/%Recall调和均值Harmonicmean平均精度/%Averageprecision检测速度/(帧/s)Detectionspeed占用内存/MBConsumememory改进的YOLOv4ImprovedYOLOv496.8591.750.9494.676253.7YOLOv496.7988.810.9391.0051244.0YOLOv4-tiny93.5975.150.8384.4620122.4CenterNet94.9366.320.7884.8092124.0RetinaNet86.8491.490.8994.3843138.0
分别用5种模型对测试集中的图片进行测试,结果表明在密度较低数量较少的情况下,与本研究算法相比,YOLOv4算法的检测结果在部分检测框的准确性略低,而YOLOv4-tiny,CenterNet和RetinaNet算法均会出现漏检以及误检的情况。在高密度、堆叠严重等情况下,本研究算法仍然有较好的检测结果,这是由于本研究算法中使用了注意力机制,提高了对生猪目标的检测性能。图6示出随机选取1张图片的测试结果。

图6 5种模型对生猪目标检测数据集的检测结果
为了验证不同密度下改进后模型的检测能力,额外准备150张不同于数据集的图片,其中包括50张低密度平视拍摄的图片,50张低密度俯视拍摄的图片,50张高密度的图片,结果表明在低密度以及在高密度但遮挡不严重条件下,检测效果较好,可以准确的检测出生猪目标,实现对生猪目标的计数。图7示出随机选取1张图片的测试结果。

图7 3种不同视角和密度情况对对生猪目标检测数据集的检测结果
4 结 论
本研究将改进的轻量化YOLOv4目标检测算法用于群养猪环境下生猪目标的检测,将去除分类层和输出层MobileNetV3网络作为特征提取网络,并在网络中使用深度可分离卷积替代PANet中的普通卷积。改进后模型大小和计算量仅为YOLOv4算法的1/5,模型更加轻量化,利于农业嵌入式设备的部署。在处理速度上,检测1张图片在CPU环境下需要0.4 s,在GPU环境下仅需要0.01 s,足以满足实际生产需求。
根据实际养殖环境与条件,制作了生猪目标检测数据集用于改进前后YOLOv4目标检测算法的训练和测试,并分别选取了目前在速度与精度达到较优水平的YOLOv4-tiny,CenterNet以及RetinaNet算法进行对比实验。结果表明,改进后的模型具有较高的准确率和实时性,准确率、召回率、调和均值和平均精度分别达到了96.85%、91.75%、0.94和94.67%,检测速度达到了62帧/s,模型大小为53.7 MB。本研究算法与YOLOv4算法相比在保证精度的前提下,大大减少了模型参数量,增强了实时性。本研究算法适用于实际猪场环境下的生猪目标检测,满足智能饲养机器人的实际应用场景。
