结合注意力机制的车型检测算法
2022-01-09谢斌红赵金朋张英俊
谢斌红,赵金朋,张英俊
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
随着社会的发展,国内的汽车数量不断增加,种类也日益丰富,使用计算机技术对交通图像中的车型进行识别检测已经成为计算机视觉领域的一项重要应用。在不同的场景中检测不同的车型具有广阔的应用前景,例如:在无人驾驶领域,通过识别图像中的车辆类型和位置,可以规避车辆的碰撞;在智能交通管理中,可以用于市区车辆的限行,也可以进行更精准的车流检测等。
近年来,由于深度卷积神经网络(DCNNs)的发展和计算机计算能力的提升,基于深度学习的车型检测技术引起了人们的广泛研究。Sengar[1]等人采用一种基于双向光流块的运动目标检测算法,该算法实验效果较好,但是需要对比前后两帧图像,需要输入视频,不适用于静态检测。孙皓泽等人[2]提出使用MobileNet网络对装甲车进行检测识别,该方法适用于计算资源受限场景,但在检测精度上仍有待提高。为了能够直接检测图像中的车辆类型,提高实时检测准确率,该文提出将深度学习的目标检测方法用于实时车型检测任务中,解决实际场景应用中车型的检测精度和速度问题。
目前,基于深度学习的目标检测方法主要分为两类:基于候选区域的双阶段检测器和基于回归框的单阶段检测器。其中,双阶段检测器的检测过程分为两个步骤,第一步从图像中生成候选区域(可能存在目标的区域),然后将候选区域作为输入,输入神经网络提取特征,进行目标的类别和回归框位置的检测,典型的网络有R-CNN[3]、Fast R-CNN[4]、Mask R-CNN[5]、PANet[6]、TridentNet[7]。而单阶段检测器省去了候选区域的生成过程,将目标检测任务视为回归任务,直接对输入的图像进行回归预测并输出结果,典型的网络有SSD[8]、YOLO[9-11]、ConerNet[12]、FSAF[13]、FCOS[14]。
两种方法相比较,双阶段检测方法的精度略高于单阶段检测方法的精度,但是其在检测速度方面表现不如单阶段检测方法,不足以满足车型检测的实时要求;而单阶段检测方法在检测速度方面有着很好的表现,故采用单阶段的检测方法进行车型检测。
现在主流的基于单阶段的车型检测方法在检测速度和精度方面都有着较好的表现,但大多数方法是基于Anchor框的,需要人为预先设置Anchor的一些大小和比例等超参数。
该方法存在以下不足:
(1)算法对预先设定的图像的大小、Anchor框的长宽比和数量比较敏感;
(2)由于与Anchor相关的超参数是预先设定的,使得算法无法自适应检测目标的大小,且对变形较大的目标检测效果不太理想;
(3)该类方法计算量和内存开销较大,因为需要和真实结果多次地计算IOU(intersection over union);
(4)该方法会使得数据集的正负样本不平衡,为了获得较高的召回率,需要在特征图上密集地部署Anchor,而其中大部分是负样本,会加剧正负样本的不平衡。
针对上述不足,该文提出基于Anchor-Free的车型检测方法。该方法减少了车型检测模型的设计复杂度和超参数的设置难度,从而简化训练过程,提升模型检测速度;取消了Anchor的设置,在减少计算量的同时可以更好地适应不同尺寸的车辆特征。同时,为了解决车型检测过程中对车辆关键特征提取能力不足的问题,在CenterNet[15]的基础上引入了混合注意力机制;此外为了更好地提取不同尺寸的车型特征,将不同尺度的特征图进行了融合。在增加了极少参数量的同时提升了检测精度。
1 相关工作
1.1 注意力机制
注意力机制(attention mechanism)源于人们对视觉的研究。人类视觉系统的一个重要特性是人们不会一次尝试处理整个场景的信息,而是有选择地聚焦于有重要特征信息的区域。Jaderberg等人[16]在Spatial Transformer Networks中提出了用于分类任务的空间注意力模块,该模块允许对特征数据进行空间变换。Wang等[17]使用编码器式注意模块的残差注意网络,通过细化特征图,使得网络在提升性能的同时增加了对噪声的鲁棒性。注意力机制已被广泛地应用于序列化标注、图像识别和目标检测等场景。使用注意力机制来提升卷积神经网络在大规模图像分类、检测任务中的效果,故该文使用注意力机制提升车型检测效果。
1.2 网络结构
该方法是一种基于Anchor-Free的单阶段目标检测算法,在速度和精度方面都有很好的表现,并且在摒弃Anchor后,减少了人为设置超参的影响。本研究采用ResNet-34作为主干网,其网络结构如表1所示,该网络很好地解决了深度神经网络的退化问题。

表1 主干网的结构

模型训练时,首先使用ResNet-34进行特征提取,然后对提取出来的特征经过多层可变形卷积(deformable convolutional networks),将特征图尺寸进行四次下采样,由512×512缩小到128×128,最后形成三个并行分支,分别预测车辆的类别损失Lk、边框损失Lsize以及车辆中心偏移损失Loff。损失函数的计算公式如式(1)所示,其中λsize为0.1,λoff为1。
Ldet=Lk+λsizeLsize+λoffLoff
(1)

Lk=

(2)
在分类损失中,α为2,β为4,N为关键点个数,该超参的选择依据Law[18]等人的实验。

(3)
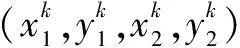
(4)
2 改进网络
2.1 注意力模块
目前常见的注意力机制划分方式有三种,按照关注区域可以分为软注意力和硬注意力;按照输入形式可以分为基于项的注意力和基于位置的注意力;如果按照注意力域(attention domain)分类,则包含三种注意力域:空间域(spatial domain)、通道域(channel domain)和混合域(mixed domain)。
通道注意力的作用是通过对特征图的各个通道之间的依赖性进行建模以提高对于重要特征的表征能力。目前生成通道注意力的方式有以下几种:平均池化、最大池化、结合平局池化和最大池化、方差池化。其生成过程类似,首先通过在各层特征图上的池化获得各个通道的全局信息,然后使用全连接层进行特征提取,ReLU进行非线性激活,最后使用Sigmoid进行权重归一化,通过该过程自适应地对各通道特征的相关程度进行建模,最后再将原特征通道的信息与自适应学习建模后的权重进行加权处理,实现特征响应及特征重校准的效果。
使用注意力机制的网络在前向传播的过程中,重要的特征通道将会占有更大的比重,在最终所呈现的输出图像中也能更加明显地表征车型检测网络所重点关注的部分,更加关注图像的内容特征,更好地分辨出车辆的类别。
空间注意力需要为特征图生成一个空间注意力图,用于增强或抑制不同位置的特征。空间注意力的方式有两种:最大池化和平均池化结合、标准卷积(1*1,S=1,不同卷积核大小)。通过空间注意力,能够更好地展示网络所要关注的重点位置,更加关注图像的位置特征,更好地对车辆进行定位。
混合注意力,顾名思义就是将图像的通道特征和空间特征引入到特征提取的过程。Convolutional Block Attention Module (CBAM)[19]就是使用了混合注意力机制,同时关注通道和空间的特征,以此来提高神经网络在类别以及位置的表征能力。
本研究在ResNet[17]的残差模块中融入混合注意力机制,用于提升车型类别以及车辆位置的表征能力。图1为引入注意力之后的残差模块结构图。从图1可知,输入图像经过卷积之后,首先将特征图输入到通道注意力模块,经过全局平均池化和全局最大池化操作后依次通过两次全连接和Sigmoid;将通道注意力模块输出的特征图输入到空间注意力模块中,经过通道最大池化和通道平均池化后输入到全连接和Sigmoid;最后再和残差连接结合一并输出。

图1 引入注意力的残差模块
通道注意力输入特征图F∈Rc×h×w(c为通道数,h、w为图像的高宽),会生成一个一维的通道注意力图Mc∈Rc×1×1。生成过程如图2所示(图中S代表Sigmoid)。具体注意力特征图计算公式如式(5)所示。

图2 通道注意力结构

(5)
其中,全局平均池化输出为Avgout,全局最大池化输出为Maxout,Fc为全连接,ReLU为激活函数。
空间注意力将通道注意力的输出作为输入,输入到网络,运算后生成一个二维的空间注意力图Ms∈R1×h×w。具体注意力特征图计算公式如式(6)所示,Avg为平均池化操作,Max为最大池化操作,Cat为张量拼接运算。生成过程如图3所示。

图3 空间注意力结构
F''=Ms(F')⊗F'
Ms(F')=Sigmoid(conv(Cat(Avg(F')+
Max(F'))))
(6)
2.2 特征融合
在特征提取过程中,ResNet-34进行了四次下采样,将图像原始尺寸进行了四次缩放,因此,图像中的一些小目标在进行特征提取时,其分辨率逐渐下降,在网络的末端小目标的特征信息可能就会丢失,从而影响小目标的检测精度。所以为了提高车辆目标检测效果,更好地提取图像中车型的细粒度特征,通过引入特征融合,将可以更好地保留上层的特征,减少特征信息的损失,从而提升识别精度,具体过程如下。
首先,将残差网络中C3层的特征进行下采样操作,并通过1×1卷积改变通道数,与C5层的特征进行融合,然后将融合之后的特征一并进行后续运算。图4为引入特征融合的整体网络结构,加粗连接线为引入的特征融合。

图4 网络结构
2.3 图像增强
数据增强也称为数据增广,目的是增加数据集的规模,更好地训练模型,让模型有更好的检测能力,防止模型过拟合。为了提升车型检测模型的泛化能力,提升检测性能,从而更好地进行车型检测,该文首先对实验数据集进行了翻转增强,然后再使用增强后数据集进行训练。
3 实验结果与分析
3.1 数据集
文中使用的数据集为KITTI车型数据集和BIT-Vehicle数据集。其中,KITTI数据集是由丰田美国技术研究院同德国卡尔斯鲁厄理工学院联合创建,该数据集是目前国际上最大的数据集,主要用于自动驾驶场景下的计算机视觉算法评测。
KITTI车型数据集一共有7 481张图像,包含小汽车(Car)、厢式货车(Van)、卡车(Truck)和电车(Tram)四种车型。实验中将数据集划分为两部分,其中5 000张作为训练集,2 481作为测试集,训练标签总共有17 637个,测试标签有15 627个,具体每类车型标签数如图5所示。

图5 KITTI数据集
另一个数据集是BIT-Vehicle车型数据集,它包含了公共汽车(Bus)、越野车(SUV)、轿车(Sedan)、小货车(Minivan)、中巴(Microbus)和卡车(Truck)6种车型,共9 850张图像。本次实验将数据集划分为两部分,6 000张用于训练,3 850张用于测试,详细类别的标签数如图6所示,该数据集中的图像均采自于实际的交通高清摄像头。

图6 BIT-Vehicle数据集
实验中的数据集格式为COCO,所以需要对原始标签进行数据格式的转化。具体步骤如下:
(1)将KITTI转化为txt格式;
(2)从txt中筛选车辆类别;
(3)txt格式标签转化为XML格式;
(4)将XML格式标签转化为Json格式用于训练和测试。
3.2 评价指标
实验使用各车型类别AP的平均值(mean average precision,mAP)和每秒检测帧数(frames per second,fps)作为评价指标。mAP通过计算IOU=0.5时的精度precision和召回率recall得到每类车型的PR(precision-recall)曲线,然后计算PR曲线与其下的面积得到该类别的平均精度AP,最后,计算所有类别AP的平均值得到mAP。而fps则是首先通过计算出检测一张图片所消耗的时间,然后计算每秒可以检测多少张图计算而来。
3.3 实验设置
本研究中使用的实验配置如下:CPU:Inteli7 8700K;RAM:16 G;GPU加速库:CUDA 10.0,CUDNN 7.5.0;GPU:Nvidia GTX1080Ti;实验平台的操作系统为Ubuntu16.04,实验程序开发使用了基于Python机器学习库的Pytorch框架。
网络训练过程中,首先在ImageNet数据集上进行预训练,然后在车型数据集上进行微调。训练参数设置如下:batch_size为32,epoch为120,初始学习率0.000 125,并在第75个和100个epoch时分别下调学习率,每次下调为原来的1/10。
3.4 实验结果及分析
为验证文中方法的有效性,与现有的方法进行对比,在BIT-Vehicle数据集上的实验结果如图7所示。
由图7可知,文中方法与Yolov3相比,在Truck、SUV、Microbus三种车型数据集上识别精度有比较明显的提升,同时速度也由35 fps提升至43 fps,能够更好地应用于实时车型检测。

图7 BIT-Vehicle数据集实验结果
文中方法与其他方法在KITTI数据集上的实验结果如表2所示。分析表中数据可知,文中方法与原CenterNet[15]方法相比mAP提升了2.3%,而检测速度基本不受影响。这就说明混合注意力的引入能够很好地提升车型检测的精度;并且与现在主流的方法相比,能够在速度与精度之间达到了一个很好的平衡。和DF-YOLOv3[22]相比,虽然速度慢了2 fps,但精度提升接近1%。

表2 KITTI数据集实验结果
通过对上述实验结果的分析,证明了通过融入注意力模块,对车辆的空间信息以及通道信息进行权重划分,同时进一步融合了不同尺度的车型特征,虽然增加了模型参数,但检测速度不受较大影响,同时提升了车辆检测的精度,从而验证了文中方法的有效性。
此外,为了更好地分析文中方法,对车型中心点检测结果进行可视化展示。图8为该方法在BIT-Vehicle数据集上的检测结果,其中第一行为原始输入图像,第二行为预测的关键点效果图,最后一行为检测结果图。从图中可以看出该方法能够很好地预测车辆的中心位置。此外,通过观察检测结果发现,在光照充足的情况下,图像中会有车的阴影,这会一定程度上影响检测效果。

图8 检测结果
4 结束语
针对当前车型检测方法存在精度、速度较低和数据集少的问题,首先使用图像增强对车型数据集进行数据增强,为车型检测模型提供了规模更大的数据集。同时为了适应不同尺寸的车型以及多目标检测等情况,通过使用混合注意力模块和特征融合对Centernet[15]进行改进,最终得到混合注意力卷积神经网络,提高了车型检测精度。在KITTI数据集和BIT-Vehicle数据集上分别进行实验,其在测试集上的平均检测精度分别达到了94.6%、95.5%,与现有的一些车型检测算法对比结果显示,该方法更适用于车型检测任务,能够直接对图像进行车型检测,并且能够在速度和精确率上实现了一个很好的平衡。
在未来工作中,将探索更优的注意力模块,同时使用更好的图像处理方法,来适应复杂的应用环境,促进深度学习在车型检测、自动驾驶等任务上的应用。
