短语后验证的无监督领域适应电商机器翻译
2022-01-09宁秋怡史小静段湘煜
宁秋怡,史小静,段湘煜
(苏州大学,江苏 苏州 215006)
0 引 言
机器翻译(machine translation,MT)[1-2]是基于自然语言数据研究的项目,近年来,机器翻译的发展已经达到一个较高的水平,特别是基于编码器和解码器结构的神经机器翻译系统(neural machine translation,NMT)[3-5]。但在现阶段,不论是统计机器翻译(statistical machine translation,SMT)[6]模型还是神经机器翻译模型,它们的性能取决于语料库的规模和质量。高质量的机器翻译系统训练都依赖于大规模的平行数据,这些数据一般在通用领域中大量存在,如新闻领域。然而在一些不常用的低资源领域,往往只有小规模的平行语料,甚至在一些领域中不存在平行数据,如电子商务领域。如今电子商务活动日益频繁,随之而来的电子商务平台产品信息翻译成为了一个突出的问题。通过人工进行产品信息翻译将消耗大量的时间和资金,因此希望通过机器翻译来辅助电商产品信息翻译,构建电子商务翻译系统。
通过利用其他通用领域训练的翻译系统进行稀缺领域资源的翻译,但是两个领域数据差异较大,翻译效果不佳。可以利用资源丰富的领域语料来帮助语料稀少的领域提升翻译质量,称为机器翻译的领域适应(machine translation adaptation)[7]。在领域适应机器翻译中,资源丰富的领域被称为外领域(out-domain),资源稀缺的领域被称为内领域(in-domain)。
在机器翻译领域适应中,有监督的领域适应要求内领域和外领域都具有平行语料,然而在电子商务领域,不存在公开的大规模平行数据,并且构建电子商务平行语料是十分困难的,所以采用无监督领域适应的方法,避免了对内领域平行语料的需求。目前无监督领域适应中,提升模型翻译效果主要有两种方式。第一种方法是生成内领域的伪平行数据。最为显著的方法是2015年Sennrich等人[8]通过将内领域目标语言反向翻译来构建伪平行数据。反向翻译(back-translation)是给定目标语言句子y,用训练好的目标语言到源语言的翻译模型得到伪句子对(x',y),训练过程始终保持目标端的真实性。此外,2017年Anna Currey等人[9]复制内领域目标语言文本的方法都是不断更新扩充领域内的数据。2019年Hu等人[10]通过词库归纳构建域内伪平行语料库,大大提高了翻译质量。第二种方法是在现有的网络基础上设计出新的网络模型,Xia等人[11]在利用伪平行的数据的基础上,提出双向学习的方法提升模型的性能。2018年Zhen Yang等人[12]在翻译模型中引入对抗分类器的方法实现无监督的领域适应。2019年Dou等人[13]提出将领域特征嵌入到网络中编码端的无监督领域适应方法,并通过多任务学习训练了整个网络。
为了解决内领域平行资源稀缺的问题,该文使用无监督领域适应,并在迭代训练的过程中,通过数据逐步混合训练策略提升翻译性能,充分利用单语数据。同时针对于无监督领域适应过程中词对匹配不佳的问题,提出短语后验证的方法进一步强化。通过大量实验对比,在电子商务领域上该方法超于现有的方法,较最强基线系统高出约1.5 Bleu点。
该文的贡献包含以下几点:
(1)获取电子商务单语数据,以无监督领域适应方法搭建电子商务机器翻译平台;
(2)无监督领域适应电商机器翻译系统采用混合策略为主体框架,充分利用内领域数据,探索内外领域混合比例,提升翻译性能;
(3)提出短语后验证的方法解决无监督领域适应机器翻译中词对匹配不佳问题,同时最大化利用内领域数据。
首先介绍了近年在领域适应机器翻译方面的相关研究以及工作,其次详细描述无监督领域适应电商机器翻译的主体框架以及短语后验证方法,再次介绍实验设置和实验结果,并对相关实验进行详细的分析,最后给出结论与未来工作计划。
1 短语后验证的无监督领域适应
1.1 混合策略的主体框架
短语后验证的无监督领域适应电商机器翻译是在混合策略基础上实现的,它是训练双向翻译过程,整个框架见图1。从源端到目标端系统,目标端到源端系统,记做src→tgt和tgt→src。

图1 基于混合策略的无监督领域适应框架结构
首先由外领域翻译模型获得内领域的初始伪平行数据,如图1中的{src',tgt}和{tgt',src}。该过程是神经机器翻译模型,它是一种非线性结构,其经典的架构是编码器—解码器(encoder—decoder)。编码器首先将源端语句X={x1,x2,…,xn}输入转换成Eencoder={e1,e2,…,en}编码,然后将其编码成隐藏状态h,并发送到解码器decoder。解码器类似,将目标端语言输入Y={y1,y2,…,ym}转换成Edecoder={e1,e2,…,em},然后给定输入历史和隐藏状态h,生成Z,具体公式如下:
(1)
其中,θ是神经模型参数,z≤i是历史输入。训练过程的损失如公式(2):
(2)
1.2 短语后验证
混合策略的无监督领域适应在训练过程中通过数据混合充分利用了内领域单语数据以及外领域的平行语料,大大地提升了翻译效果。但反向翻译产生的伪平行语料质量难以保证,所以在混合策略训练的前期始终保持目标语言的数据是真实的,避免因使用低质量的伪数据作为目标端,导致在神经网络训练过程中翻译模型的偏离。但由外领域训练产生的词对存在匹配不佳的问题,通过引入短语后验证方法解决该问题。
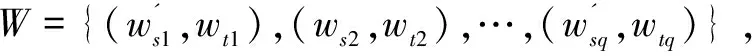

图2 前向翻译验证示意图
1.3 综合训练
在混合训练策略的无监督领域适应框架结构基础上加入前向翻译验证的方法,由于训练开始产生的前向翻译数据质量较低,为了保证训练的新验证短语质量, 每次迭代训练后,增加c*i数量前向翻译与反向翻译学习校验原句中源端数据的词进行替换,从而产生新的伪语料继续训练,重复迭代训练与前向翻译验证过程直至收敛。
2 实验设置及过程
2.1 实验设置
该文所有实验采用开源代码Fairseq[15],将模型设置为Transformer[16],dropout设置为0.3,编码器和解码器层数均为6层,其他基本的超参数设置为Fairseq中的默认参数选项。解码时,采用集束搜索(beam search),其中beam_size设置为5,其余参数采用默认设置。训练和测试均基于GTX1080Ti。采用双语互译评估(bilingual evaluation understudy,BLEU)[17],它已经被广泛应用于自然语言处理和机器翻译任务。该文采用BLEU自动化脚本multi-bleu.perl。
2.2 实验数据集及预处理
在新闻领域,平行数据非常丰富,因此通常被用作域外领域数据。选择linguistic data consortium (LDC)作为领域外的数据集,这是一个中英新闻语料,大约有125万个平行句。领域内的数据是本节中获取的电子商务领域数据。
目前,电子商务领域不存在公开的语料,为了构建电子商务翻译系统,在此之前首先构建一份电子商务语料。这是一份包含英文和中文的单语电商语料库,分别通过中英电商平台获取产品文本信息。数据包含四类:男士服装、女士服装、食物和玩具。笔者构建了训练集为单语数据,平行数据分别为测试集和验证集,数据的详细数量见表1。表中数字为数据集的句子数量,其中训练集是以百万(M)为单位。

表1 电商领域数据统计
对训练数据进行了预处理,去掉网络中特殊字符,并且针对中文,由于字符之间没有明显的分割符号,一般采用中文分词工具进行分词,这里使用jieba分词工具;针对英文,可以依据单词之间的空格进行切分,同时进行词串识别(tokenization)处理。为了去除分词工具在模型评估中的影响,在测试过程中,在英文到中文方向上,以字级别文本文件作为参考译文。
2.2.1 数据bpe设置
在神经机器翻译的训练中,使用了(byte pair encoder,BPE)[18]技术处理所有的数据,进行了词表的压缩。使用所有的数据训练得到bpe编码,并且分别对不同大小的bpe进行了实验,对源端与目标端分别做bpe和联合源端与目标端做bpe进行了实验。在外领域数据上训练得到的内领域四类测试数据结果如表2所示,英—中和中—英方向均是64K bpe效果最佳,最终决定中英分别使用64K bpe编码。

表2 不同bpe设置实验对比
2.2.2 数据比例设置
为了探寻基于混合策略的无监督训练过程中,内领域和外领域数据在不同混合比例下的效果,在整个训练前进行了不同比例的多组实验。通过外领域平行句与内领域伪平行句不同比例组合,该伪语料是获取的反向翻译。实验结果如表3所示。表中的混合比率表示域内数据和域外数据的比率。根据结果,当外部数据和内部数据以1∶1混合时,与Sennrich等人[19]得到的结论一致。

表3 不同的数据比例实验结果
2.3 实验过程
基于上述的实验设置,采用中英分别64K bpe,内领域与外领域数据1∶1的设置,并且数据总量保持不变。分别训练了混合策略的无监督领域适应电商机器翻译以及短语后验证方法,此外在电子商务领域数据上分别采用了下面基准实验进行性能的对比,实验具体结果见表4。

表4 电子商务产品翻译测试BLEU值
2.3.1 基准系统
为了更好地探索短语后验证的无监督在电商上的效果,利用以下多个无监督基准系统:
外领域nmt:在外领域平行语料上使用fairseq训练神经网络机器翻译系统。
nmt反向翻译:由外领域nmt系统进行反向翻译,联合外领域数据构成伪平行语料,训练神经翻译模型。
nmt反向翻译+前向翻译:在nmt反向翻译的基础上,前期融合前向翻译数据,联合外领域数据构成伪平行语料,训练神经翻译模型。
目标端复制:在内领域,目标语言句子被直接复制到源语言,以构建伪平行语料。联合外领域平行数据,训练新的神经翻译模型。
DAFE反向翻译:在内领域伪平行语料库和外领域平行数据的组合上训练神经翻译系统,在编码器的每一层添加领域感知函数嵌入和任务特定函数嵌入。
无监督词归纳领域适应:通过所有领域单语数据训练一个词嵌入,使用最近邻搜索获得归纳词,根据该词表构建内领域伪平行数据。然后,将内领域伪数据和真实外领域数据结合起来训练新模型。
监督词归纳领域适应:在无监督词归纳的基础上用外领域词典作为种子词典来进行有监督的词汇归纳。
2.3.2 短语后验证的无监督领域适应
混合训练:根据混合策略,先由外领域nmt模型获得初始数据,在迭代中逐步混合内领域和外领域数据,其中常数c为50k,迭代训练i经过6轮,最后混合前向翻译训练更新得到最佳模型,m∶n∶k=1∶1∶1,整个训练过程数据总量保持不变。
混合训练+短语后验证:在混合训练的每轮更新模型后,加上短语后验证从而产生新的伪平行句对,代入继续训练。重复这个过程直至收敛。
3 实验分析
3.1 基准系统
通过基准实验系统结果表明,nmt反向翻译以及DAFE反向翻译高于外领域nmt系统,这表明内领域数据构建伪平行数据能够提升翻译性能。此外nmt反向翻译+前向翻译较外领域nmt系统有提升,但由于前向翻译质量影响,在效果上低于反向翻译方法。
词归纳通过归纳词构建初始数据进行训练和通过目标端复制构建伪平行语料进行训练,结果表现出较强的基准,这是因为电商数据包含大量的低频词,并且在相关产品的描述时,会存在短语的堆叠现象。例如:“尺码:m x xl xxl”,“品牌:adidas”, 这体现了词匹配优化在电子商务中是具有一定效果。
3.2 短语后验证 vs. 基准系统
混合训练充分利用内领域与外领域数据,采用渐进增加方法,避开了前期的前向翻译质量较低问题,从而使得训练能够达到基准系统。通过加入短语的后验证,在此基础上,不仅最大化利用了内领域数据,同时解决了无监督领域适应的词匹配问题,在中—英和英—中方向超过最强基线分别为1.54 Bleu点和1.78 Bleu点。
此外为了更好地验证混合训练与短语后验证方法对数据质量的提升,在测试集进行单词匹配验证。通过fasttext[14]对测试集及参考译文构建出内领域词对,在构建内领域词对过程中,若抽取的该领域内的词对在外领域中存在则去除该词对,剩余的对齐词集合构成新词对的参考集合。
根据该参考集合,在验证集上分别测出其精确率、召回率和F值。其过程与构建内领域过程相同,分别对最强的基线系统、混合训练+短语后验证方法进行新词对集合提取。
表5中显示各方法验证集的单词配对三个值。其中混合训练、混合训练+短语后验证方法在中—英和英—中两个方向的召回率远超于基准系统的召回率。而在精确率上英—中的基准系统偏高,中—英几种模型之间差距较小。根据精确率以及召回率,综合指标F值三者参考各方法产生的词对质量,表明文中方法能够改善词对质量,提升翻译性能。

表5 验证集的单词配对评分 %
4 结束语
在电子商务机器翻译中,资源十分稀缺。获取大量电子商务数据,通过一系列预处理构建了电子商务中英单语语料库。在此语料库上构建短语后验证的无监督领域适应电商机器翻译,通过无监督领域适应避开了对电商平行资源的需求。并且该方法在混合策略的无监督领域基础上,充分利用内领域与外领域数据,将短语后验证方法融入该训练,解决无监督领域适应的词对匹配不佳问题,使得电商产品信息翻译模型性能够得到进一步的提升。在未来将拓展更多的语言的电商产品数据信息,进行进一步的研究与创新。
