基于Transformer 的野生动物关键点检测
2022-01-08王旭罗铁坚杨林
王旭 罗铁坚 杨林
1.北京信息科技大学,北京 100096;2.中国科学院大学计算机科学与技术学院,北京 100854;3.北京计算机技术及应用研究所,北京 100039
0 前言
野生动物是生态系统的重要组成部分,不能很好地保护濒危野生动物会导致生态系统不平衡,并影响环境[1]。对野生动物进行保护这一任务依赖于对野生动物的地理空间分布和健康状况的准确监测,特别是在野生动物栖息地逐渐减少的情况下。传统的将发射器连接到野生动物身上的方法容易出现传感器故障并且很难扩展到大型种群中。传统的野生动物监测方法需要进行“足迹判定、花纹判别、DNA 鉴定”[2]等操作,这需要对大量数据进行统计与分析。计算机技术迅猛发展,同时无人机或相机[3]可以大量收集视觉数据,使得计算机视觉技术成为一种很有前途的野生动物监测方法。因此,近些年研究人员逐渐把计算机视觉技术应用在对野生动物的保护和监测上,例如拉毛措等人[4]提出了高原野生动物物种检测算法。KÖRSCHENS M 等人[5]设计了一种野生大象的重识别方法。LI SHUYUAN 等人[6]制作了一个东北虎的关键点检测和重识别任务的数据集ATRW。于慧伶等人[7]基于ATRW 数据集设计一个了对东北虎的重识别方法。
关键点检测任务的目标是根据图像预测人的关键点位置,进而重建人体的关节,在人机交互、行人重识别等方向有着重要作用。关键点检测是一种基于目标检测算法并应用在关键点的信息捕捉上的智能算法,具有能将空间中的信息通过摄像头转化为可量化处理的数据信息的功能。随着深度卷积神经网络在关键点检测任务中的应用,检测精确度也在逐步提升。
本文在关键点检测算法研究的基础上进一步研究野生动物的关键点检测问题,使野生动物关键点检测具有更高的准确度。本文的贡献如下:
(1)首次在野生动物关键点检测任务中使用Transformer 模型捕捉野生动物各个关键点的依赖关系,充分利用全局信息和局部信息进行关键点预测;
(2)引入SGE 注意力模块,设计新的BasicBlock,改善提取特征的空间分布;
(3)提出一种多分辨率融合方法,在特征融合前通过空间注意力对特征进行权重分配,从而获得更丰富的融合特征。
经过实验验证,所提方法在ATRW 数据集上的平均准确率与基线方法相比提高了1 个百分点。
1 相关工作
1.1 人体关键点检测
2D 人体关键点检测也称为人体姿态估计。作为计算机视觉的一个基础任务,人体关键点检测可应用在动作识别、行为分析等任务中。单人姿态估计和多人姿态估计是人体关键点检测的两大主要任务。
单人姿态估计[8]针对图像中只有一个人的情形。文献[9]首先将CNN 应用到人体关键点检测任务中,文献[10]在CNN 的基础上引入了马尔科夫随机场来进行关键点检测,并把关键点以热图的形式显示出来。TOMPSON J 等人[11]在文献[10]的模型中引入了多分辨率输入,使模型的检测准确度得到提高。SUN K 等人[12]设计了高分辨率网络(High-Resolution Network,HRNet)在关键点检测任务中达到了当时最好的效果。
多人姿态估计的模型也可以应用到单人姿态估计任务中,其姿态估计方法主要有两种:一种是先检测出图中的每一个人,再对其中每个人进行关键点检测(自顶向下的方法);另一种是先把图片中所有的关键点检测出来,再判断检测出的关键点具体属于哪一个人(自底向上的方法)。
1.2 Transformer
ASHISH VASWANI 等人[13]设计的Transformer 模型在自然语言处理方向得到广泛应用。近几年,Transformer 模型在视觉任务中展现出很强的活力,DETR[14](Detection Transformer)、ViT[15](Vision Transformer)、SETR[16](Segmentation Trans-former)分别将Transformer 模型应用到目标检测、图像分类和语义分割任务中。YANG S 等人[17]将Transformer 引入到人体关键点检测任务中,使用Transformer 的自注意力机制来捕捉各个关键点的依赖关系。本文对文献[17]的网络进行了改进,将其应用在野生动物关键点检测的任务中。
1.3 注意力机制
注意力机制已经成熟应用在自然语言处理和计算机视觉领域。注意力机制可以通过分配权重来提高对高效信息的关注度,如通道注意力[18]通过对不同通道进行权重赋值来实现通道的注意力分配,空间注意力[18]通过对不同特征的权重赋值来提高对目标区域的关注度。
2 方法
网络整体结构如图1 所示,本文用CNN 网络来提取野生动物的特征,将提取的特征进行序列化和位置嵌入,输入到Transformer 模型中得到关键点的依赖关系,最后通过一个MLP(Multi-Layer Perceptron)层预测关键点的热图。在训练时使用均方差函数作为损失函数。
2.1 Transformer 模型介绍
2.1.1 数据处理
与传统Transformer 模型不同,在本文的模型中并未使用解码结构。研究的目的是得到野生动物各个关键点之间的依赖关系,因此不需要进行解码输出。网络的输入图像为I∈R3×HI×WI,经过CNN 网络的处理得到维度为d的Xf∈Rd×H×W特征图,然后将特征图展平为一个序列X∈RL×d(L=H×W),把X中的向量xi∈Rd(i=1,2,3,…,L)命名为Token。

2.1.2 位置嵌入PE(Positional Encoding)
Transformer 需要对输入序列X进行位置嵌入,从而获得序列的相对位置和绝对位置(相对位置指Token 之间的距离,绝对位置指Token 在序列中的位置),采用正余弦函数公式(1)~(4)得到位置嵌入向量。由于sin 和cos 函数在不同维度上(i表示维度)函数周期不同,在同一方向上(如x方向),根据pos和i的变化可以产生唯一的函数取值组合,从而产生唯一的位置信息,并且,sin 和cos 函数的值域为[-1,1],能够很好限定嵌入向量中值的大小,使训练过程更加稳定。
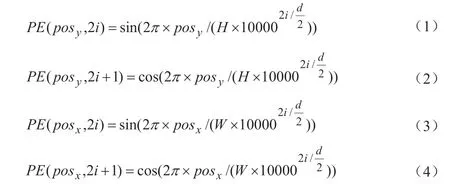
其中,i=0,1,2,…,d/2-1——维度;
posx、posy——x和y方向上的位置,然后将其转换成RL×d的形式后加入到输入序列X中,得到Xp。
2.1.3 自注意力机制
自注意力计算过程如图2 所示,由Xp∈RL×d经过投影得到Q、K,由X∈RL×d经过投影得到V,如公式(5)~(7)所示:

其中,Q——Query 矩阵;
K——Key 矩阵;
V——Value 矩阵;
WQ、WK、WV∈Rd×d——随机初始化的权重矩阵。
如公式(8)所示,将Q和K进行内积运算后除以,经过Softmax 函数处理得到自注意力权重矩阵,权重矩阵乘以V得到自注意力计算结果Z∈RL×d。
2.1.4 预测热图
输入序列X与Z经过残差网络求和,LN(Layer Normalization)模块对数据进行归一化处理后将结果传递到前馈神经网络(Feed-Forward Network,FFN),再经过残差块和LN 模块的处理得到当前Transformer 编码层的输出。整体过程可用公式(9)、(10)表示:


其中,LN 表示进行层归一化处理,即对层中所有神经元进行归一化(设层中有m个神经元,输入为B={x1,x2,...,xm},则归一化过程可用公式(11)、(12)表示,先求出均值μ和方差σ2,然后根据均值和方差求出最后以γ和β为缩放参数和平移参数进行缩放和平移,得到归一化结果);FFN 由一个以ReLU 函数为激活函数全连接层和一个以线性函数为激活函数的全连接层组成,FFN 对应图2 中的前馈网络(Feed-Forward);X是未经过位置嵌入的输入;Xt表示当前编码层的输出。将Xt作为下一层的输入,经过N层的编码层处理,最后经过一个MLP 层获得关键点的预测热图。


其中,ε——极小值,防止分母为0。
2.2 改进的BasicBlock
本文以HRNet 作为Backbone 网络,在HRNet 网络的BasicBlock 中引入SGE 注意力机制,如图3 所示,改进的BasicBlock 包含两个具有相同输出通道的3×3 卷积层,一个SGE 注意力模块和一个残差连接。
SGE 注意力模块[19]按照通道维度C将特征图分为G个Group(本文将G设置为64),每个Group 表示为X={x1,…,m},其中,xi∈RC/G(i=1,2,3,…,m)为子特征,m=H×W,完整的特征由以Group 形式分布的子特征组成。SGE 注意力机制通过在每个Group 里生成注意力因子来得到子特征的重要性,具体操作如图4 所示。
(1)对X进行平均池化操作,经过函数Fgp(·)处理得到向量g;
(2)g与xi点乘得到ci,对ci进行标准化得到结果ai;
(3)ai经过 sigmoid 函数后,得到的结果与xi进行点乘得到。

其中,ε——极小值,防止分母为0。
2.3 多分辨率融合
使用HRNet 对图像进行特征提取,不同分辨率表征关注的信息不同,高分辨率表征更关注局部信息,低分辨率表征更多地保留全局信息。HRNet 的融合模块可以进行多尺度特征融合,使表征保持高分辨率的同时,拥有更丰富的特征信息。融合模块如图5 所示,将空间注意力模块加在表征融合之前,使其在融合之前能够提取更值得关注的特征信息以提高融合效果。输入的特征经过平均池化和最大池化操作生成两个2D图,把两图拼接在一起(通道拼接),使用尺寸为7×7 的卷积核进行卷积和降维处理(降为1 维),最后经过Sigmoid 函数后生成空间注意力矩阵Ms,Ms与输入特征点乘得到新的融合特征。空间注意力计算方式如公式(19)所示:
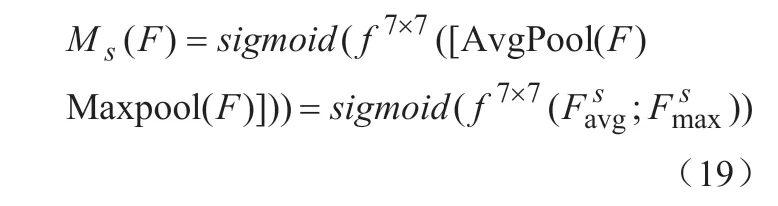
其中,f7×7——卷积核尺寸为7×7 的卷积操作。



3 实验结果与分析
3.1 数据集
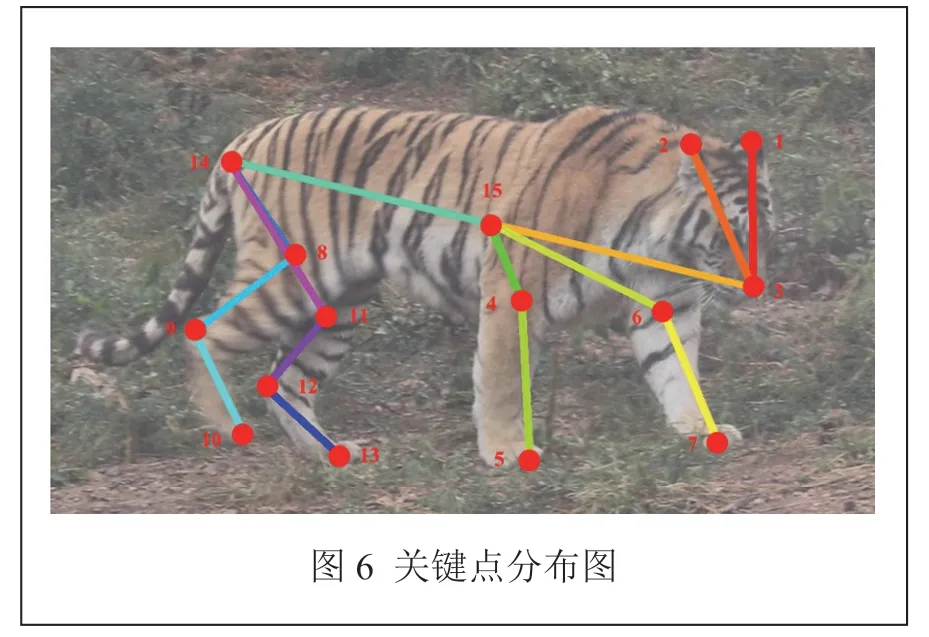
ATRW 数据集是针对野生动物东北虎的关键点检测和重识别任务的数据集,东北虎的关键点定义如表1 所示。相较于其他野生动物关键点检测数据集,ATRW数据集规模更大,注释更详细。在本文的实验中,训练集有3,609 张图片,测试集有1,032 张图片,验证集有515张图片。图6为东北虎关键点的可视化分布图。

表1 关键点的定义
3.2 评估准则
由公式(20)计算模型准确度:

其中,TP(True Positives)——检测正确的目标数;
FP(False Positives)——检测错误的目标数。
关键点相似性指标OKS(Object Keypoint Similarity)定义如公式(21)所示:
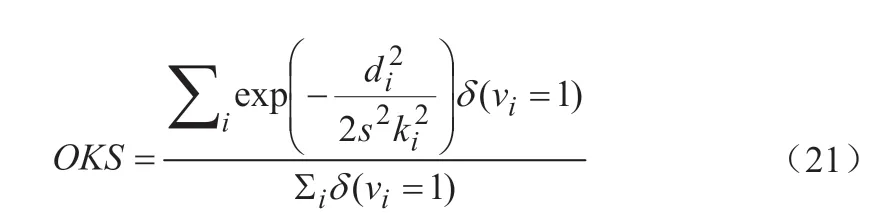
其中,di——真实的关键点与估计的野生动物关键点的欧氏距离;
vi——该关键点是否遮挡;
s——目标尺寸;
ki——每个关键点的乘积常数。
使用mAP(mean Average Precision)表示检测结果,mAP为OKS分别取(0.55,0.6,…,0.9,0.95)时所有准确度(Precision)的平均值。
3.3 实验环境
本文在版本为Ubuntu18.04 的Linux 服务器上进行实验,实验所用的CUDA 版本为11.2,Python 版本为3.6.6,Pytorch 版本为1.10。实验参数设置:初始学习率设置为0.0005,学习率衰减系数为0.1,训练周期为260。
3.4 对比实验
分 别 使 用AlphaPose、ResNet 和HRNet 等 网 络在ATRW 数据集上进行野生动物关键点检测,从表2 各网络的实验结果可以看出,本文方法的mAP 比AlphaPose、ResNet 和HRNet 的结果分别高了30.5 个百分点、14.7 个百分点和1 个百分点。实验结果表明,本文所提出的方法有效地提升了野生动物关键点检测的准确度。

表2 各网络的实验结果
3.5 消融实验
为测试本文方法中设计的模块对模型性能的贡献,进行了消融实验,表3 显示了在ATRW 数据集上的实验结果。从结果可以看出,本文整体网络相较于HRNet 有1 个百分点的性能提升。进行消融实验,加入 Trans-former 模型后,mAP 相对于HRNet 提高了0.5个百分点,在此基础上,分别使用改进的BasicBlock和具有空间注意力的融合模块,mAP 分别又得到0.3个百分点的提高。实验结果证明了所提方法的有效性。

表3 消融实验结果
3.6 可视化结果
在ATRW 数据集中选取了4 张图片的测试结果进行可视化展示,如图7 所示,图中不同颜色的点和连线分别表示东北虎的关键点和关键点连线。从图中可以看出,本文方法在野生动物的关键点检测任务中有较好的表现,对于某些有遮挡的关键点也能正确识别。

4 总结
本文以CNN 作为基础框架,首次把Transformer模型应用在野生动物关键点检测的任务中,同时设计了引入SGE 注意力机制的BasicBlock 和引入空间注意力机制的特征融合模块。在ATRW 数据集上的实验结果表明,改进的BasicBlock 在提取特征时能够改善所提特征的空间分布,提取到更有效的特征;设计的多分辨率表征融合模块在不同分辨率表征融合之前,能够提取更值得关注的特征信息,获得更好的融合效果;Transformer 模型能够捕捉关键点之间的长距离依赖关系,能够充分地利用全局信息和局部信息,从而使预测结果更准确。
