联合Cameron分解和融合RKELM的全极化HRRP目标识别方法
2022-01-08王晶晶
王晶晶 刘 峥 谢 荣 冉 磊
(西安电子科技大学雷达信号处理国家重点实验室 西安 710071)
1 引言
高分辨一维距离像(High Resolution Range Profile,HRRP)反映了目标上各个散射中心沿雷达视线方向上的分布情况,体现了目标的重要特征,广泛应用于雷达自动目标识别(Radar Automatic Target Recognition,RATR)[1,2]。另外,极化信息反映了目标距离单元内散射部件的表面粗糙度、对称性、取向等特性,也是刻画目标散射特性的重要特征。相比于低分辨极化回波,高分辨极化回波能够得到目标的局部散射特性,使得极化描述参数的模糊性大大降低,RATR性能得以提升[3,4]。
近年来,学者对基于全极化HRRP的RATR技术研究越来越多。文献[5]利用非相干分解方法提取多类飞机目标在不同度量尺度下沿径向距离的散射熵、散射角和各向异性度特征进行目标识别;然而,非相干分解需将目标高分辨距离单元沿径向作空域平均,损失了由高分辨体制表征的目标细节信息,使其识别性能欠佳。文献[6]分别提取单个极化通道的偏度、变异系数和能量聚集区长度特征,然后利用动态组合的方法得到分类器,最后对各个分类器进行决策级融合;该方法能够区分某一角域内的飞机目标,但当角域范围增大时,识别性能较差。文献[7]对圆锥体(仿真弹头)、球体和圆柱体这3类简单散射体的电磁仿真数据提取极化不变量特征,实现了对3类目标的大于80%的分类性能,但极化不变量难以区分复杂目标。文献[8]结合了散射中心的几何绕射理论(Geometric Theory of Diffraction,GTD)模型参数和Krogager分解参数,确定了目标中包含的散射中心类型,并将各散射中心类型数目作为特征,利用快速密度算法进行聚类,实现了对3类地面车辆目标在一定角域范围内的分类;该方法对目标的角域范围敏感,在目标角域范围大于10°时,识别性能已无法满足要求,此外,由于GTD模型参数受噪声影响较大,该方法在信噪比(Signal-to-Noise Ratio,SNR)降低时的识别性能变差。文献[9]利用联合稀疏表示对全极化HRRP的幅度特征进行融合,提高了目标识别的性能,但是该方法中完备字典的建立需要目标完备的训练样本,因此,该方法在样本数较少时性能较差。文献[10]在联合稀疏表示的基础上,利用多视角全极化HRRP观测数据,提出了一种基于联合稀疏性的多视全极化HRRP目标识别方法。文献[11]利用不同极化HRRP之间的相关性,提出了多任务压缩感知的方法,提高了识别性能;然而,文献[10,11]均要求雷达收集到一帧相关性较高的目标回波,这在很多情况下难以满足。文献[12,13]首先提取目标的全极化属性散射中心参数,然后利用极化分解等方式分析目标上部件的整体极化信息,避免了像素级的散射机理分析,使得分析结果更加稳健可靠,然而属性散射中心的提取需要目标的多个连续方位下的HRRP,对雷达的数据收集条件要求较高。
考虑到现有方法存在的缺陷,本文结合高分辨信息和极化信息,利用Cameron相干分解[14]得到目标在三面角、二面角和1/4波长器件这3个散射基上沿距离维的投影分量,并作为目标特征进行融合分类。Cameron相干分解作用于目标各个距离单元的散射矩阵,在保留高分辨信息的同时提取了目标沿径向距离的形状结构信息,实现了对目标散射特性更加精细化的描述。在分类阶段,考虑到简化核极限学习机(Reduced Kernel Extreme Learning Machine,RKELM)[15]方法随机选择支持矢量造成识别性能不稳定的缺陷,结合聚类算法提出了基于原型聚类预处理的RKELM方法,并在此基础上提出了特性级融合RKELM和决策级融合RKELM,提高了目标识别性能。在实验部分,利用10种地面民用车辆的全极化回波数据验证了本文所提方法具有良好的噪声稳健性和泛化性能。
2 基于Cameron分解的目标特征提取方法
2.1 Cameron分解
Cameron分解是一种基于目标全极化数据的相干极化分解方法。相比于非相干分解,它在对目标的散射特征进行描述的同时,保留了目标回波的高分辨细节信息。在Cameron分解中,互易性和对称性是目标的基本散射特性。由于本文研究单站雷达体制下的目标识别问题,因此,目标回波满足互易性。在互易性限制下,目标的Sinclair散射矩阵S为
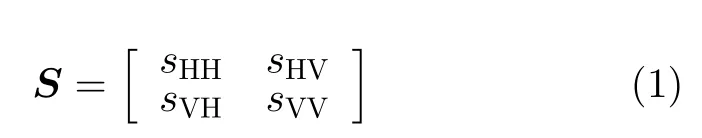
其中,H代表水平极化,V代表垂直极化,HV代表垂直极化发射、水平极化接收方式,sHV为HV极化方式回波,sHH,sVH和sVV定义方式类似,sVHsHV。
散射矩阵S经Cameron分解后的形式如式(2)。
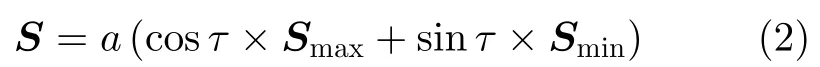
其中,a‖S‖F为矩阵S的Frobenius范数,代表目标在该距离单元处的散射能量大小;Smax为归一化最大对称分量;Smin为归一化最小对称分量;τ为散射矩阵偏离对称散射机理的角度,当τ0时,SaSmax对应完全对称散射体;随着τ的增大,S中非对称散射分量越来越大;当τπ/4时,S对应完全非对称散射体。
由于最大对称分量Smax中携带了S的大部分信息,Cameron重点关注了Smax的特性。对于Smax,存在定向角ψ,使得旋转后的散射矩阵为对角矩阵。
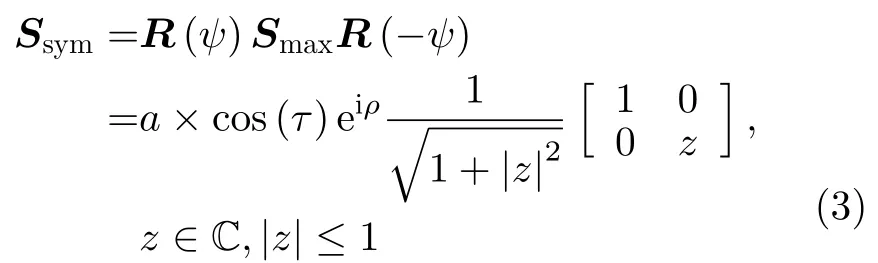
其中,R(ψ)为旋转变换操作,C 为复数空间。z决定了目标的对称散射类型,它可用一个单位圆盘表示,如图1所示,圆盘被划分为6个部分,每个部分对应的标准对称散射体和z值如表1所示,其中,i为虚数单位。在此需要说明的是,三面角、球和平板的散射特性一致,所对应的z值均为1,本文统一用三面角表示。
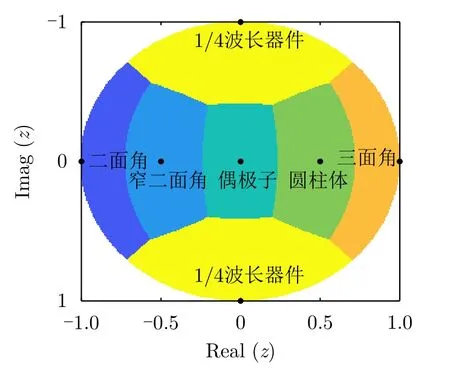
图1 对称散射体所对应的 z值的单位圆盘表示Fig.1 Unit disc representation of z values and the corresponding symmetric scatterers
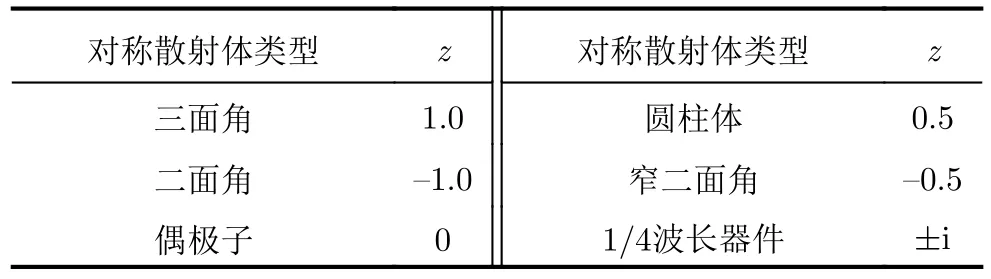
表1z值与对应的对称散射体Tab.1z values and the corresponding symmetric scatterers
Cameron定义了对称散射体空间中的任意两点z1和z2之间的距离为
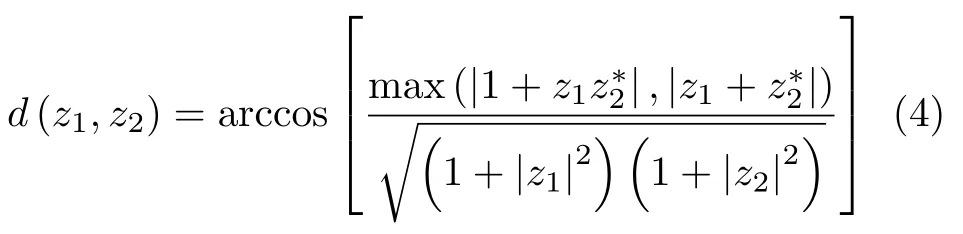
对于空间中的任意点z,计算其与6个标准散射体之间的距离,并将其归为与其距离最近的散射体类型。
2.2 基于Cameron分解的全极化HRRP目标特征提取
设散射矩阵S′经Cameron分解后的最大对称分量为,其经旋转操作后的散射矩阵为
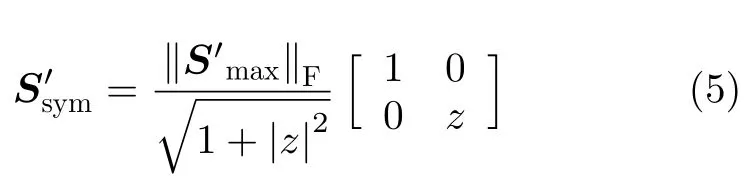
根据Cameron分解,本文称
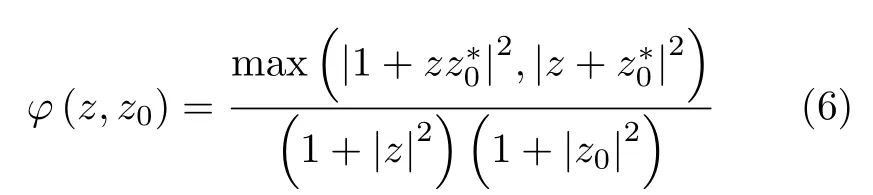
为S′与标准对称散射体之间的相似性参数,其中,z01.0,−1.0,0,0.5,−0.5,±i。相似性参数φ(z,z0)∈[0,1],其值越大,表示散射体与z0所对应的散射体之间越相似。设zzr+i∗zi,则z所对应的散射体与标准散射体之间的相似性计算方式如表2所示。
按照表2计算得到标准散射体之间的相似性参数,如表3所示。可以看出,对称散射空间的6个标准散射体之间并非完全独立。例如,三面角与圆柱体之间的相似性参数高达0.949,说明三面角与圆柱体的相关性较大;二面角与窄二面角之间的相似性参数高达0.949,说明二面角与窄二面角的相关性较大。而三面角和二面角之间的散射特性是相互正交的。本文定义
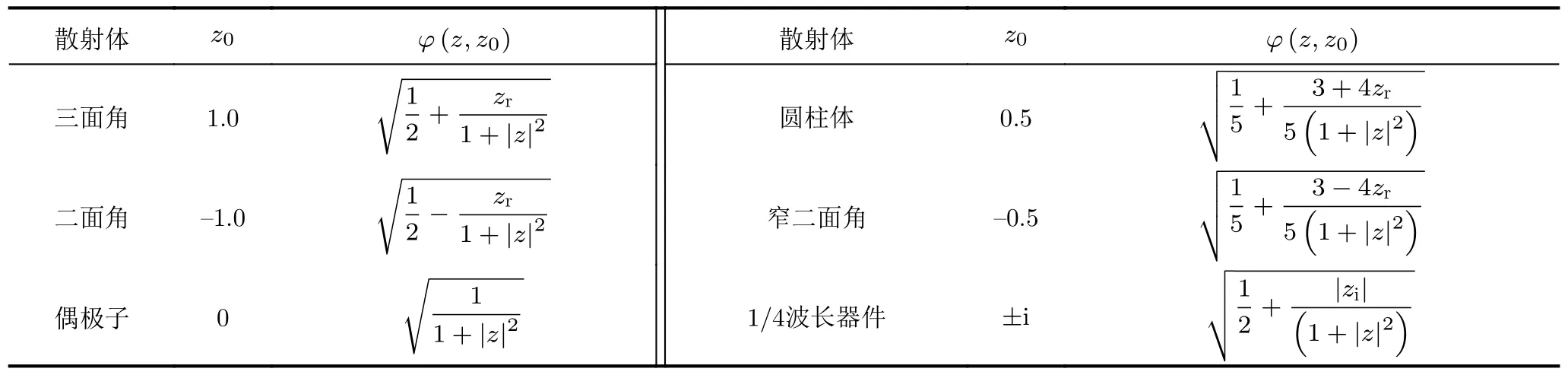
表2 任意散射体与标准对称散射体之间的相似性计算方式Tab.2 Calculation of similarity between arbitrary scatterers and standard symmetric scatterers
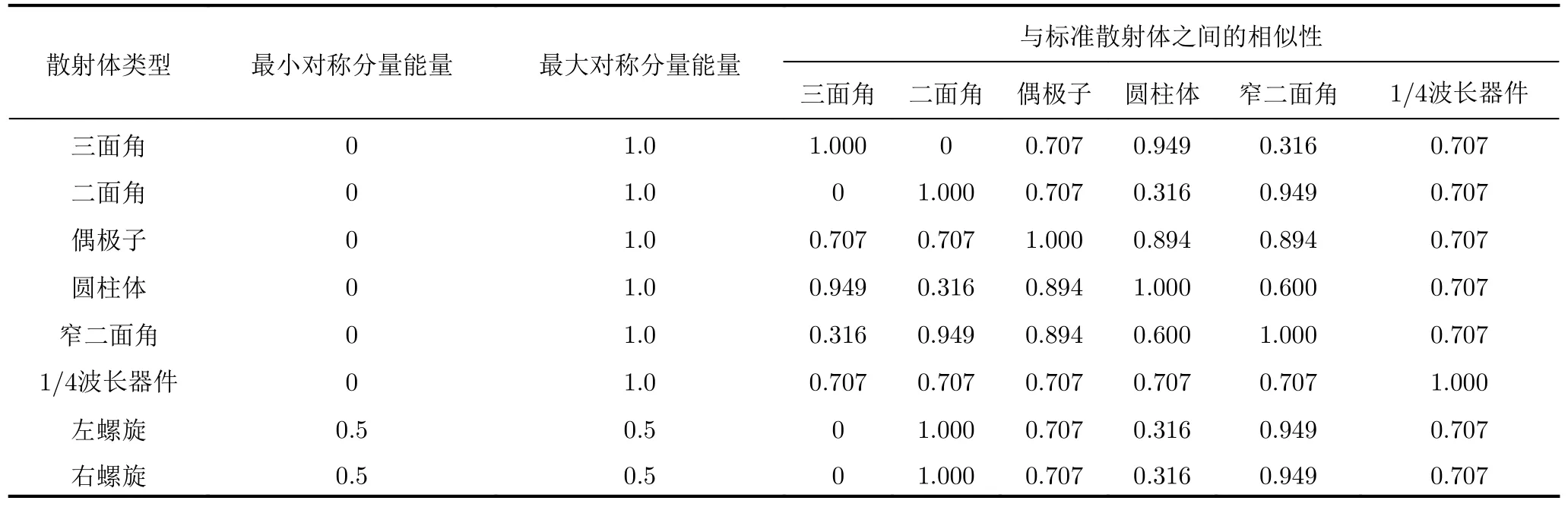
表3 标准散射体的Cameron分解参数和相似性参数Tab.3 Cameron decomposition parameters of the standard scatterers and their similairity parameters
为散射矩阵S′在z0所对应的标准散射体上的投影,则对于圆盘空间中的任意z,有
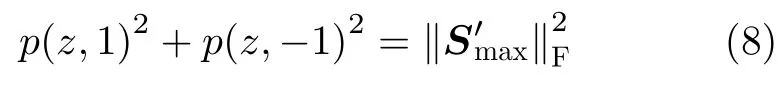
由此,可将三面角和二面角的散射矩阵作为基表征对称散射体的散射特性。然而,仅采用三面角和二面角造成了散射特性的混淆,无法描述圆盘空间中任意z的复数特性。例如,偶极子和1/4波长器件的散射特性不同,但它们与三面角和二面角的相似性参数值是相同的。由于1/4波长器件描述了两个同极化通道之间的相位差特性,且z与1/4波长器件的相似性参数体现了z的虚部特性,因此,本文将散射体在三面角、二面角和1/4波长器件上的投影作为目标特征。
设目标全极化HRRP的长度为N,距离单元索引为n1,2,...,N,本文提出的基于Cameron分解的全极化HRRP目标特征方法具体步骤如下:
(1) 对每个距离单元的全极化散射矩阵S(n)进行Cameron分解,得到最大对称分量幅度‖Smax(n)‖F和z(n);
(2) 计算z(n)在三面角、二面角和1/4波长器件这3个标准散射体上的相似性,分别记为φ(z(n),1),φ(z(n),−1)和φ(z(n),±i);
(3) 计算目标在三面角、二面角和1/4波长器件这3个散射基上沿距离维的投影ptr,pdi和p1/4:
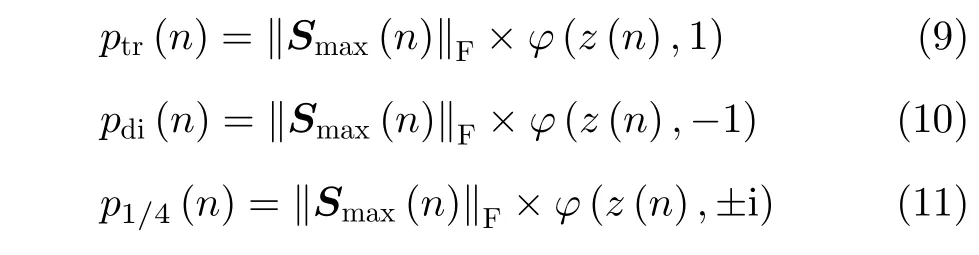
3 融合RKELM
信息融合技术综合利用各类传感器的性能优势,能够有效提高目标识别系统的稳定性、可靠性和准确性。按照融合系统中数据层次的不同,信息融合方法可划分为数据层融合、特征层融合和决策层融合。数据层融合目标识别方法直接将各传感器采集到的目标数据进行融合,然后将融合后的数据进行特征提取和分类,它是最低层次的融合,能够提供目标的细微信息,信息损失最少,准确性最高,但是实时性较差。决策层融合目标识别方法首先将各传感器收集到的目标数据进行特征提取和分类识别,然后将各传感器的识别结果进行融合,它是最高层次的融合,对各传感器的要求不高,具有很大的灵活性,但是由于各传感器自身信息的不完善,识别性能可能不高。特征层融合目标识别方法将各传感器获取的目标数据分别进行特征提取,然后将各个特征进行融合,最后利用融合后的特征进行分类识别,它介于数据层和决策层之间,能够在获取高的识别效能的同时具有很大的灵活性。
本节将2.2节得到的3个特征视为逻辑意义上的传感器获取的数据进行融合,以获得更为准确可靠的目标识别结果。
简化核极限学习机(RKELM)是一种单隐层神经网络,不同于传统的神经网络迭代计算网络权重,它通过在训练样本中选择隐层节点,并利用广义逆理论解析求解输出层权值,能够在提高训练速度的同时获得更高的泛化性能。鉴于此,本文设计了RKELM特征级融合算法和决策级融合算法。此外,考虑到RKELM随机选择支持矢量可能导致识别结果的不稳定性问题,本文提出了一种基于聚类预处理的RKELM算法。下面分别介绍基于原型聚类预处理的RKELM算法及其融合框架。
3.1 基于原型聚类预处理的RKELM
RKELM算法随机选择支持矢量计算样本在高维空间中的特征,虽然取得了良好的识别效果,但是随机选择策略可能造成支持矢量分布不均匀,某两个节点的支持矢量可能极为相似,导致隐层节点数的浪费。当隐层节点数较少时,其识别性能不稳定。鉴于此,本文提出了基于原型聚类预处理的RKELM算法,该方法首先将训练样本进行聚类,然后将聚类中心作为RKELM的支持矢量进行后续计算。
设训练样本为X[x1x2...xNl],包含来自C类目标Nl个样本,RKELM的隐层节点数为Nh,则首先将X进行原型聚类,划分为Nh个不相交的训练样本簇,得到的原型向量集为Yp[y1y2...yNh],yj为第j个簇的原型向量,j1,2,...,Nh。样本的聚类结构可以用原型向量集Yp刻画,且Yp内的向量两两之间的距离较大。因此,以Yp作为RKELM的支持矢量,可以更加全面地表征目标的特征空间,提高目标识别性能。不失一般性,本文采用的原型聚类算法为K-means++[16]。
设T为X的类别矩阵,其中,tn为第n个训练样本xn的类别向量,若xn的类别为c,则tn中第c个元素为1,剩余元素为0,n1,2,...,Nl,c1,2,...,C,则基于原型聚类预处理的RKELM算法的训练阶段按照以下步骤进行:
(1) 利用K-means++算法将训练样本X进行聚类,其中,聚类簇数为Nh,得到的聚类中心为Yp
(2) 将聚类中心Yp作为RKELM的隐层节点,计算核矩阵K0:
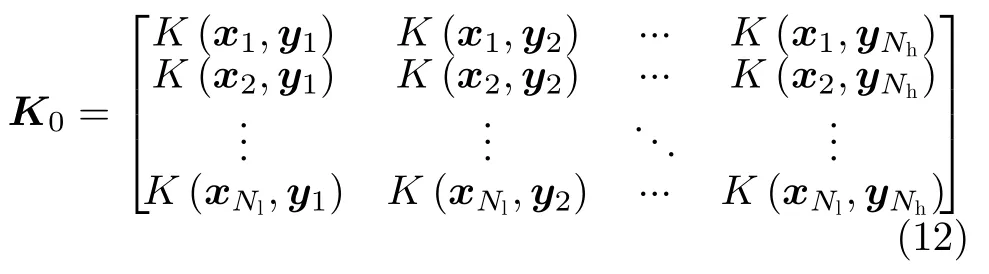
其中,K(·,·)为核函数。
(3) 根据经验误差最小化准则,计算输出层权重矩阵β ∈RNh×C
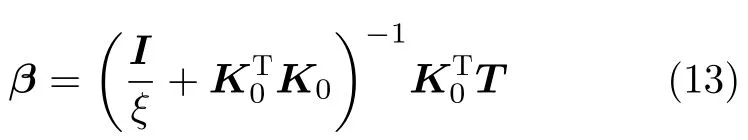
其中,ξ为正则化参数,I为Nh维的单位矩阵。
在测试阶段,设xu为测试样本,则其类别向量可计算为
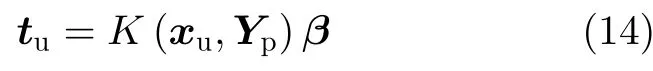
tu中最大值所对应的类别即为样本xu的类别。
3.2 基于原型聚类预处理的特征级融合RKELM

则特征级融合网络的核矩阵为
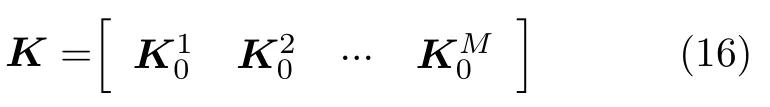
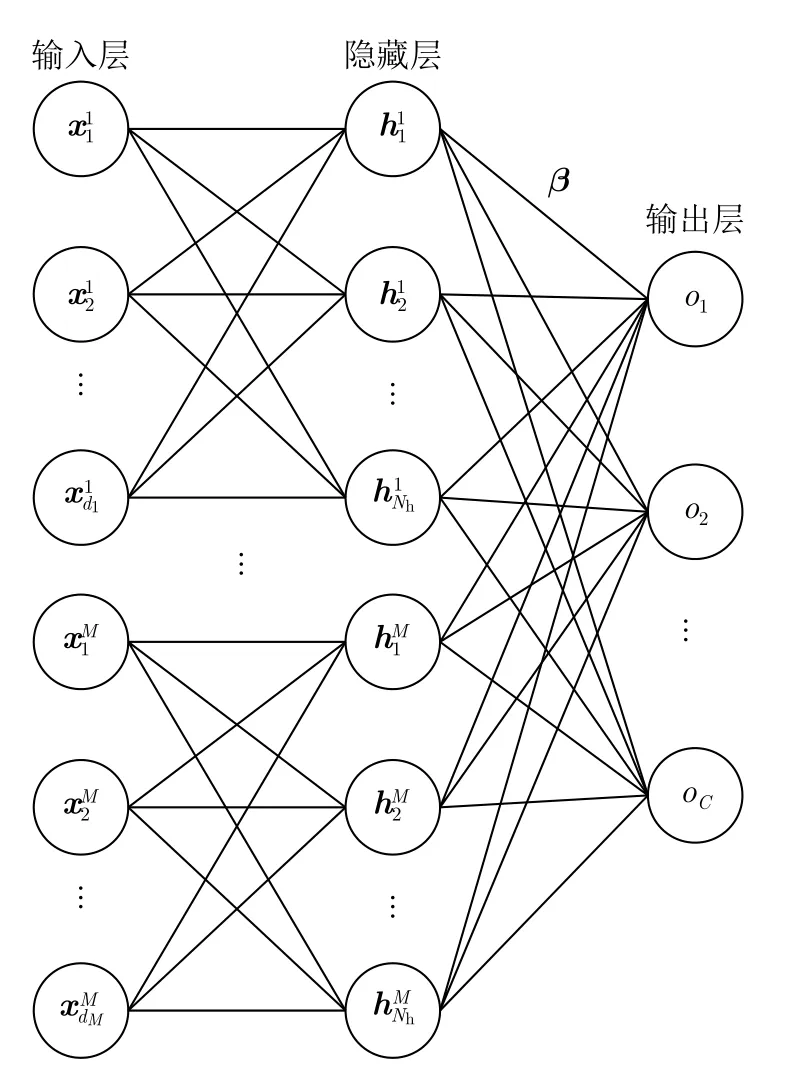
图2 基于原型聚类预处理的特征级融合RKELM网络结构Fig.2 Feature level fusing RKELM network based on prototype clustering preprocessing

类别向量tu中最大值所对应的类别即为测试样本 的预测标签。
3.3 基于原型聚类预处理的决策级融合RKELM
决策级融合RKELM首先利用RKELM子网络对M种特征分别进行识别,然后对子网络的识别结果进行融合。基于原型聚类预处理的决策级融合RKELM网络结构如图3所示。
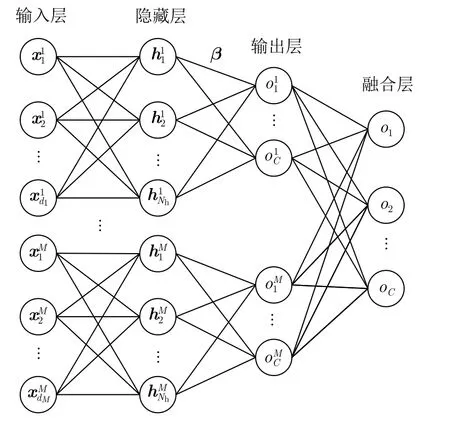
图3 基于原型聚类预处理的决策级融合RKELM网络结构Fig.3 Decision level fusing RKELM network based on prototype clustering preprocessing
将第m个RKELM子网络的输出表示为om由于RKELM算法的输出范围并不统一,给后续决策级融合带来困难,本文利用文献[2]中的方法将其输出值映射到[0,1]之间,并使,得到第m个 子RKELM网络第c个输出节点的概率。
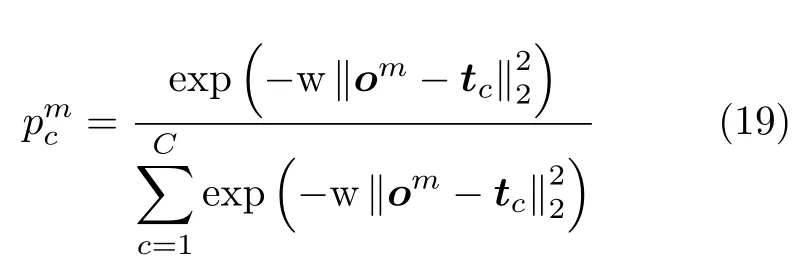
其中,w为常数。
由于2.2节中提取的3路极化特征相对独立,故3个RKELM子网络得到的标签概率是相对独立的。因此,在对3个标签概率进行融合时,采用概率乘融合策略,该策略不需要额外的参数,实现简单,融合方式按照式(20)计算。
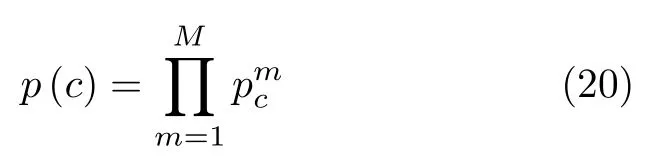
其中,p(c)即为融合后样本属于第c类的概率。
4 实验结果与性能分析
4.1 实验条件介绍
本文利用美国空军研究实验室公布的10类民用车辆全极化电磁仿真数据[17]验证所提算法的有效性。10类民用车辆分别为Toyota Camry,Honda Civic 4dr,1993 Jeep,1999 Jeep,Nissan Maxima,Mazda MPV,Mitsubishi,Nissan Sentra,Toyota Avalon和Toyota Tacoma,其电磁仿真示意图如图4所示。雷达信号的中心频率为9.6 GHz,频率间隔为1 0.4 8 M H z,极化方式分别为H H,H V和VV。实验中选取以9.6 GHz为中心的128个频率合成目标的极化HRRP,合成带宽为1.34 GHz。由于入射余角为30°的仿真数据同时仿真了地面和车辆的复合电磁散射,本文选用该入射余角数据验证所提算法。目标方位角为[0:0.0625:360]°,由于目标的CAD模型是方位对称的,故将方位角为[0:0.0625:180]°的单视样本作为实验数据,即每种目标有2880个全极化HRRP样本。
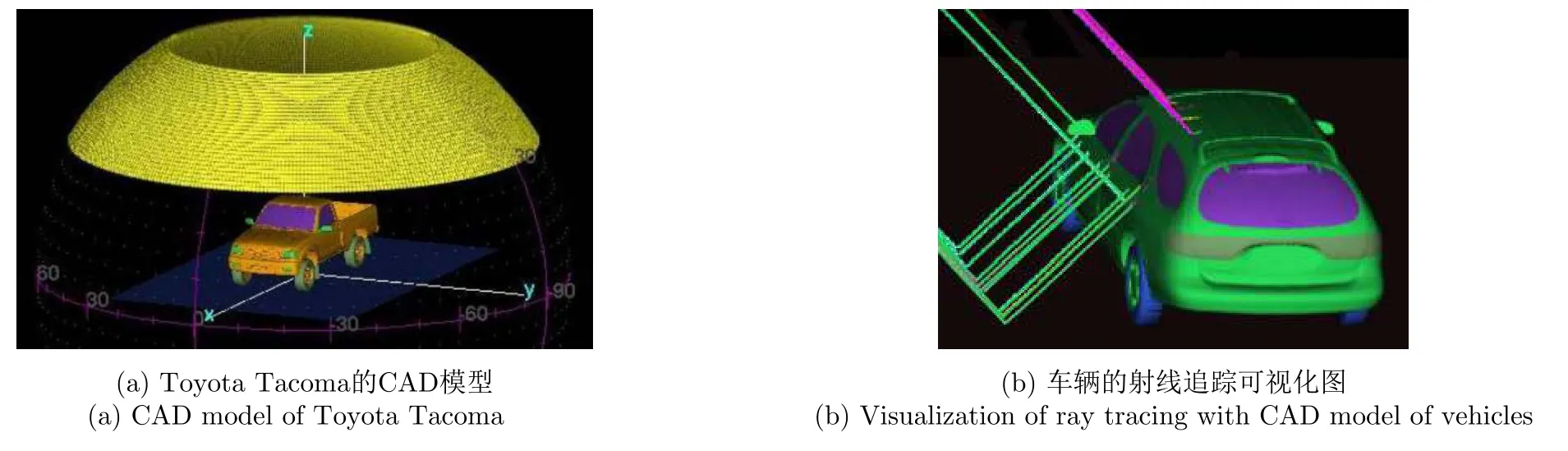
图4 民用车辆回波仿真示意图Fig.4 Diagram of simulated echo from civilian vehicles
实验采用S折交叉验证的方式说明算法有效性:设第c类目标的HRRP样本数为Nc,将该目标数据分为S份,第ξ份数据包含索引为[ξ ξ+S ξ+2S...Nc −S+ξ]的样本,其中ξ1,2,...,S,在第ξ次实验中,将第ξ份数据作为训练样本,其余S −1份数据作为测试样本,目标平均识别率为S次实验结果的平均值。由于该仿真数据可视为转台数据,目标和雷达之间没有发生平动,故无需进行平移匹配。针对HRRP的幅度敏感性问题,实验采用l2范数归一化对全极化HRRP进行幅度归一化操作。
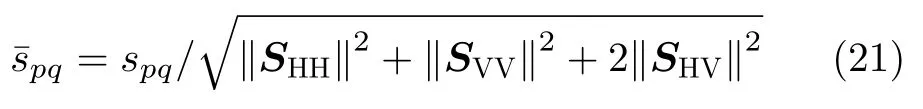
其中,p,q{H,V}。
“互联网+”行动计划为改变传统农业发展模式提供了新思路,是实现农业大发展的必由之路。农业发展不仅需要精准扶贫,也是发展南充经济、打造美丽南充的需要。现在,我国正处于全面建成小康社会决胜期,南充市“塌陷”地带的发展亟需采取超常规的举措来实现精准脱贫,“互联网+”的提出为南充市广大农村贫困地区的精准扶贫工作提供了新思路和新途径。通过互联网思维和技术的导入,形成了“互联网+农业”的新模式,使农业产、供、销产业链条体系和模式得到创新,休闲农业等农业新业态的产业链得到拓展。
以下介绍中为了方便描述,将本文所提算法记为“Cameron+特征级RKELM”和“Cameron+决策级RKELM”。为了证实所提全极化HRRP目标识别方法的有效性,将其与以下方法进行了对比:
(1) 将HH,VV和HV极化回波的幅度作为输入特征,分别利用特征级RKELM和决策级RKELM进行识别,以验证采用的基于Cameron分解特征的优势,该方法分别记为“幅度+特征级RKELM”和“幅度+决策级RKELM”;
(2) 根据文献[5],由Cloude非相干分解方法提取目标的散射熵、散射角和各向异性度特征,利用特征级RKELM和决策级RKELM进行识别,以验证所提的基于Cameron分解特征的优势,该方法记为“Cloude+特征级RKELM”和“Cloude+决策级RKELM”;
(3) 由Krogager[18]相干分解方法得到目标沿雷达视线方向的三面角、二面角和螺旋体散射分量特征,利用特征级RKELM和决策级RKELM进行识别,以验证所提的基于Cameron分解特征的优势,该方法记为“Krogager+特征级RKELM”和“Krogager+决策级RKELM”;
(4) 由Cameron分解得到的特征输入到基于随机选择支持矢量的特征级RKELM和决策级RKELM中进行识别,以验证本节提出的基于原型聚类预处理的RKELM方法的优势,该方法记为“Cameron+特征级RKELM(随机)”和“Cameron+决策级RKELM(随机)”;
(5) 分别将HH,VV和HV幅度作为特征,将基于原型聚类预处理的RKELM作为分类器,验证多个特征融合相比于单个特征识别性能的优势,分别记为“HH+聚类-RKELM”、“VV+聚类-RKELM”和“HV+聚类-RKELM”。
实验所采用RKELM算法的核函数均采用高斯核函数。
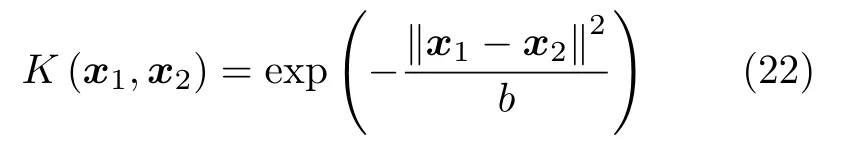
其中,参数b的取值由搜索法得到。
实验结果均用MATLAB语言编程得出,计算机运行环境为64位Windows系统,硬件条件为16 GB RAM和Intel i7 CPU@3.6 GHz。
4.2 特征可分性分析
10种车辆的全方位Cameron分解特征的结果如图5所示,其中,红色表示目标在三面角散射基上的投影ptr,绿色表示目标在二面角散射基上的投影pdi,蓝色表示目标在1/4波长器件散射基上的投影p1/4。从图中可以看出,距离雷达较近的距离单元中ptr的分量较大,这是因为这些距离单元回波由车辆直接反射,如图4(a)中的紫色信号传播路径所示,车辆表面较为光滑,其散射特性为奇次散射,与三面角散射特性类似;中间距离单元的散射类型较为复杂,有二面角散射、三面角散射等多种散射类型;Toyota Camry,Nissan Maxima和Nissan Sentra车辆回波距离雷达较近的距离单元中pdi的分量较大,这是因为该距离单元回波经车辆和地面二次散射得到,如图4(b)中的绿色信号传播路径所示,其散射特性与二面角散射类似。以上分析结果说明了Cameron分解特征能够较为准确地得到目标各个距离单元实际的物理散射类型。
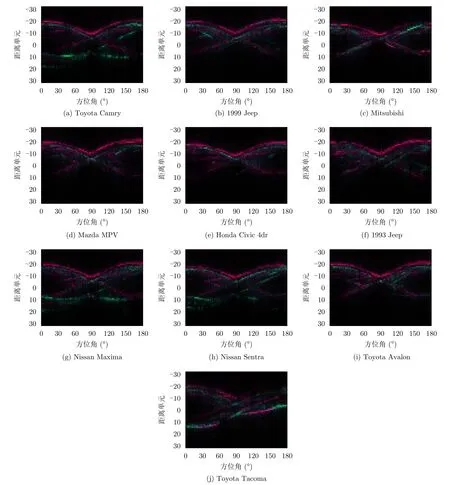
图5 10类民用车辆的Cameron投影特征RGB图Fig.5 RGB images of the Cameron projection features from 10 civilian vehicles
下面对所采用的Cameron分解特征和对比特征的可分性进行分析,对比特征包括全极化回波的幅度特征、Cloude分解特征、Krogager分解特征、单极化HH幅度、VV幅度和HV幅度特征。
ReliefF特征评价准则函数[19]利用局部类间距离和类内距离的差值作为特征可分性依据,可有效衡量特征的非线性可分性,然而差运算受特征的绝对幅度影响较大。考虑到这一点,本文提出改进的ReliefF特征评价准则,即采用局部类间距离和类内距离的比值作为特征可分性依据,可去除特征绝对幅度对可分性值的影响。改进的ReliefF特征评价准则定义为
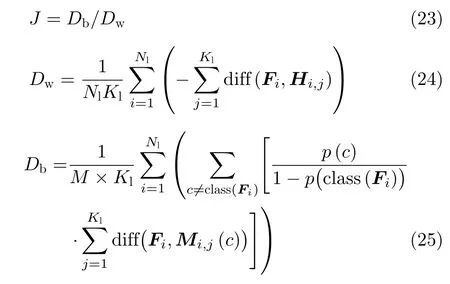
其中,Fi为训练样本中第i个特征,Kl为近邻点个数,Hi为与Fi类别相同的样本中距离最近的Kl个样本集合,Hi,j为Hi中第i个样本,Mi,j(c)表示类别为c的样本中距离特征Fi最近的Kl个样本集合,c与Fi的类别不同,p(c)为第c类样本出现的概率,class(Fi)为特征Fi对应的类别,diff(·,·)表示特征之间的距离,本文采用Euclidean距离。
由上述定义可知,Dw为样本与其类别相同的Kl个近邻样本的平均距离,可衡量类内样本局部散布情况,Dw越小,表示同类样本越紧密;Db为样本与其类别不同的Kl个近邻样本的平均距离,可衡量类间样本局部散布情况,Db越大,表示不同类样本之间越分散。特征可分性J的值越大,表示特征的可分性越高。
表4为本文所采用的Cameron分解特征和对比特征改进的ReliefF特征可分性值。从表中可以看出,本文采用的Cameron分解特征的可分性是最高的,这是因为所采用的Cameron分解特征能够更加精细地描述目标的散射特性。对于地面民用车辆来说,其Cloude分解特征的可分性反而低于单个极化分量的可分性,这是由于Cloude分解损失了目标的高分辨细节信息,而高分辨细节信息在地面民用车辆的分类中贡献较大。Krogager分解将目标回波分解为沿雷达视线方向的三面角散射、二面角散射和螺旋体散射分量,然而地面民用车辆的螺旋体散射分量较小,可分性较低。3个单极化幅度特征中,VV极化分量的可分性是最好的,HH极化分量次之,而HV极化分量的可分性最差。

表4 特征改进的ReliefF可分性值Tab.4 Seperability measure of features by the modified ReliefF
4.3 目标识别性能分析
本节对所提方法和对比方法在不同隐层节点数、训练样本数和信噪比下的识别性能进行分析。在RKELM方法中,隐层节点数对其识别性能的影响较大,当采用8折交叉验证,即每类目标的训练样本数为360,测试样本数为2880时,所提方法和对比方法在不同隐层节点数下对10种民用车辆的正确识别率如表5所示。从表中可以看出,(1)在使用相同的分类器时,本文采用的Cameron分解特征的识别概率是最高的,这与4.2节对特征的可分性分析结论一致;(2)特征级融合的识别概率高于决策级融合,这是因为特征级融合在特征层对特征进行拼接,变相增加了隐层节点数;(3)利用全极化特征进行识别的性能高于单极化特征,这是因为极化特征提供了目标散射类型等信息,可有效提高识别性能;(4)当隐层节点数较少时,基于原型聚类预处理的RKELM融合方法的优势更加明显,是因为当隐层节点数较少时,聚类中心能够更加全面地表征特征空间的结构,而随机选择的支持矢量的偏差较大;而当隐层节点数较多时,随机选择的支持矢量对特征空间的描述也较为全面。
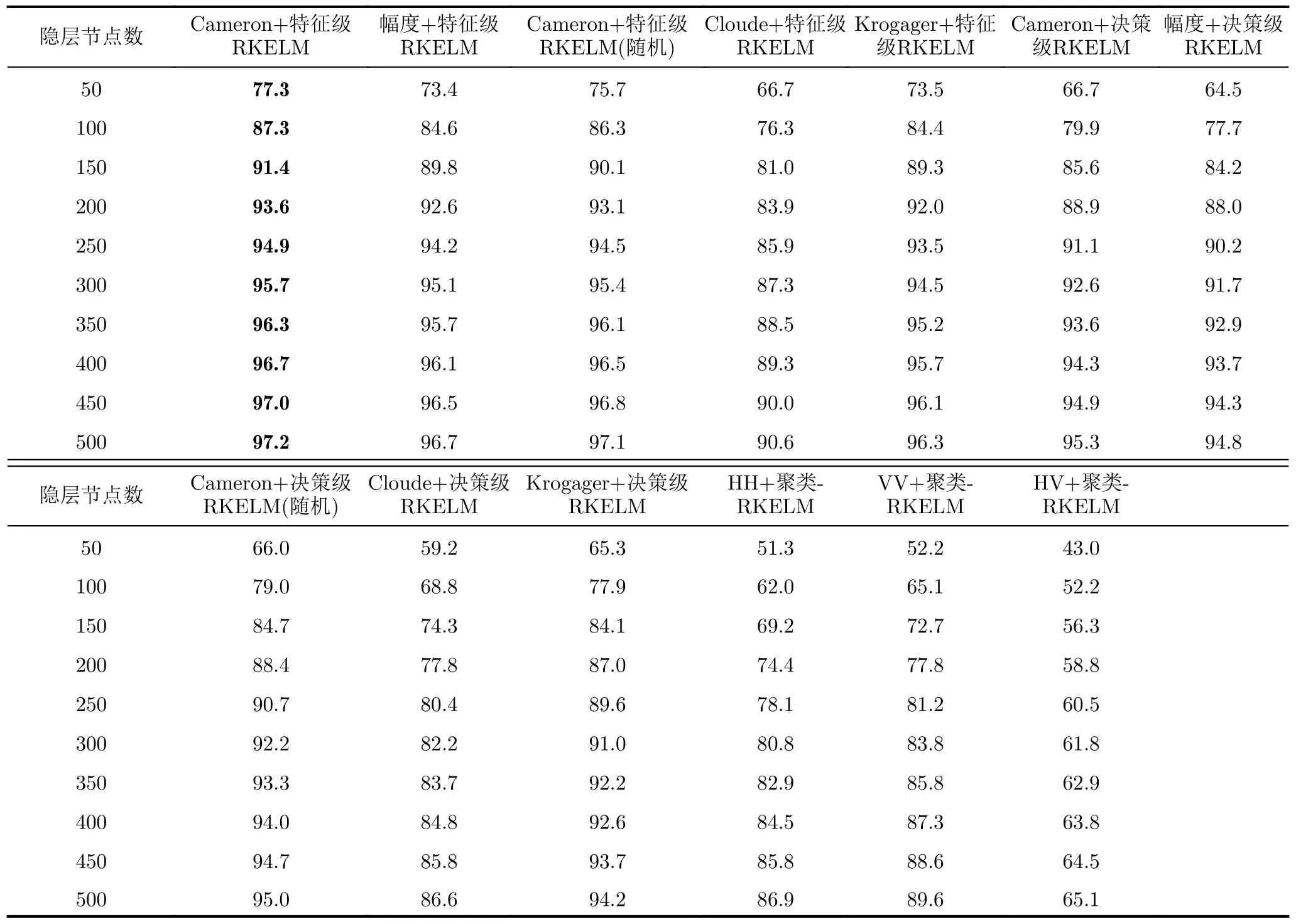
表5 所提方法和对比方法在不同隐层节点数下的识别性能(%)Tab.5 Recognition performance of the proposed methods and comparative methods with different number of hidden layer nodes (%)
下面分析训练样本数对识别结果的影响。图6(a)和图6(b)分别为当隐层节点数为200和400时,所提方法和对比方法在不同训练样本数下的识别性能。从图6可以看出:(1)当训练样本数逐渐增多时,识别性能逐渐提升,这是因为更多的训练样本能够更好地描述目标的特性;(2)所采用的Cameron分解特征表现出的识别性能是最好的;(3)当隐层节点数为200时,在所有的训练样本数下,相比于对比方法,特征级融合RKELM方法的识别性能最好,说明其泛化性能最好;而当隐层节点数为400时,在训练样本数较少的情况下,特征级融合RKELM过度拟合训练样本,因此,其性能低于决策级融合RKELM,而在训练样本数较多的情况下,其识别性能表现更好。

图6 平均识别率随训练样本数的变化Fig.6 Average recognition rates versus size of training data
在实际应用中,测试样本的信噪比可能较低,因此,识别算法对噪声的稳健性是至关重要的。下面对测试样本加入复高斯白噪声,以验证所提方法的稳健性。全极化HRRP的信噪比定义为
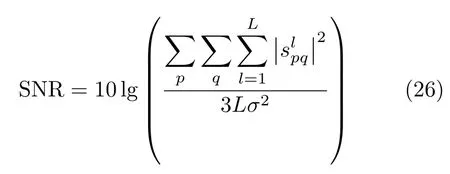
式中,p,q{H,V},L为目标所占距离单元个数,为目标回波中第l个距离单元在q发射极化p接收极化方式下的幅度,σ2为噪声功率,lg(·)表示以10为底的对数运算。
下面采用8折交叉验证的方式分析算法对噪声的稳健性,即每类目标的训练样本数为360,测试样本数为2880。图7(a)和图7(b)分别为当隐层节点数为200和400时,识别性能随信噪比的变化趋势。从图中可以看出,在所有的信噪比条件下,所提Cameron分解特征的噪声稳健性最好,且特征级RKELM的稳健性高于决策级RKELM;另外,在3个单极化分量中,VV极化的噪声稳健性是最高的,HH极化次之,HV极化的噪声稳健性是最差的。

图7 平均识别率随信噪比的变化Fig.7 Average recognition rates versus SNR
从以上对目标识别性能的分析可知,所采用的Cameron特征对目标的特性描述较为精细,表现出较高的可分性和噪声稳健性;当训练样本数较多时,所提的特征级融合RKELM方法的识别性能高于决策级融合RKELM方法,而当训练样本数较少时,决策级融合RKELM的泛化性能高于特征级融合RKELM方法。
5 结论
本文提出了一种联合Cameron分解特征和融合RKELM网络的全极化HRRP目标识别方法。所提方法的主要贡献可概括为:(1)利用Cameron分解,定义了散射矩阵在标准散射体上的投影,并将散射体在三面角、二面角和1/4波长器件上的投影作为目标特征,该特征同时描述了目标的高分辨信息和形状结构信息,可分性较高;(2)结合聚类算法和RKLEM网络,提出了基于原型聚类预处理的RKELM方法,提高了RKELM方法在隐层节点数较少情况下的识别性能;(3)提出了特征级RKELM和决策级RKELM网络框架,实现了对全极化HRRP特征的融合分类。实验部分利用10种民用车辆的电磁仿真数据验证了所提全极化HRRP目标识别方法的噪声稳健性和泛化性能。
