基于MobileNetV3-YOLOv4 的车型识别
2022-01-07凌毓涛郑锡聪李夏雨
万 浪,凌毓涛,郑锡聪,李夏雨
(华中师范大学物理科学与技术学院,湖北武汉 430079)
0 引言
近年来,我国机动车数量逐年增长,截至2020 年9 月已高达3.65 亿辆,其中汽车占73.97%。汽车带来了交通的便利,但也导致道路拥挤、交通事故等一系列问题[1]。监控系统是辅助交通监管的重要设施,如何利用监控对道路上的车辆进行检测与分类成为研究热点。
在计算机视觉领域,典型的车型识别方法分为形态学图像处理与卷积神经网络(Convolution Neural Network,CNN)两种。在形态学图像处理方面,程丽霞等[2]提出一种基于灰度共生矩阵纹理特征的车型识别方法,该方法性能稳定、可行性强,但适用范围较窄,在光线较强或车身颜色较暗的情况下提取的车辆纹理特征并不清晰,会导致分类结果不准确。在CNN 方面,吴玉枝等[3]对SSD 目标检测算法进行改进,对主干特征提取网络VGG-16 增加一层卷积层,并将底层与顶层多层特征图融合后进行预测,以获取更全面的特征信息。该方法降低了模型误检率,提升了识别速度,但识别精度还有待提升。桑军等[4]提出一种基于Faster-RCNN 的车型识别方法,研究Faster-RCNN 分别与ZF、VGG16 和ResNet-101 3种不同CNN相结合的识别能力,实验结果表明Faster-RCNN 与ResNet-101 相结合的模型识别能力最强。该算法虽然精度较高,但模型参数量过大,训练和识别速度较慢。
YOLOv4 目标检测算法在速度和精度方面均表现优异,但同样存在参数量过大、难以训练的问题。为解决目前车辆检测与分类算法的局限性,本文将MobileNet 轻量级网络引入YOLOv4 目标检测网络中,得到MobileNetV3-YOLOv4 模型,大幅减少了目标检测网络的参数量,从而提升了检测速度。此外,为消除减少参数量带来的准确度不足问题,本文使用K-means 算法设置预选框用于提升模型最终识别精度,最终构建了一种实用的车辆检测与分类算法。
1 MobileNet 简介
MobileNet 网络是由谷歌提出的一种轻量级CNN。MobileNetV1 的卷积模型主要应用深度可分离卷积(Depthwise Separable Convolution)的方式替换普通卷积方式[5],深度可分离卷积流程如图1 所示。其通过对每个输入通道采用不同的卷积核分别进行卷积,然后再通过1× 1 大小的卷积核进行通道调整实现,并在卷积层后加上BN(Batch Normalization)层和ReLU 激活函数。假设输入特征图的大小为DW×DH×M,输出特征图的大小为DW×DH×N,其中DW、DH分别为特征图的宽和高,M、N分别为输入和输出特征图的通道数。对于一个卷积核尺寸为DK×DK的标准卷积来说,共有N个DK×DK×M的卷积核,因此参数量PN的计算公式可表示为:
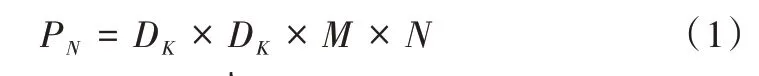
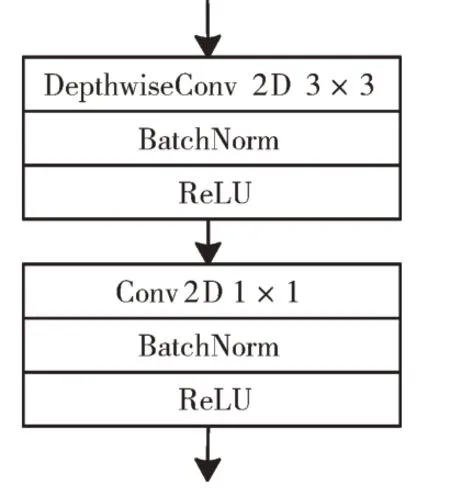
Fig.1 Depthwise separable convolution structure图1 深度可分离卷积结构
每个卷积核都要经过DW×DH次计算,其计算量QN表示为:
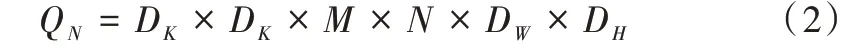
在深度可分离卷积中,一次标准卷积可分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两步操作[6]。深度卷积只需要一个尺寸为DK×DK×M的卷积核;逐点卷积的卷积核尺寸为1× 1×M,共有N个,因此其参数量PD表示为:
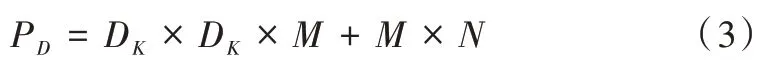
深度卷积和逐点卷积的每个参数都需要经过DW×DH次运算,其计算量QD表示为:

深度可分离卷积模块与标准卷积参数量的比值RP表示为式(5)、计算量比值RQ表示为式(6)。

由上式可知,深度可分离卷积的参数和计算量均减少为标准卷积的。
MobileNetV1 网络结构在训练过程中易出现深度卷积部分的卷积核失效,即出现卷积核的大部分参数为0 的情况,影响了特征提取效果。MobileNetV2 在V1 的基础上使用Inverted residuals block[7]结构,具体如图2 所示。首先使用逐点卷积进行特征升维,再通过深度卷积进行特征提取,最后通过逐点卷积进行降维,将ReLU 激活函数替换为ReLU6 激活函数,使模型在低精度计算下具有更强的鲁棒性,并去掉最后的ReLU 层。ReLU6 激活函数的公式表示为:

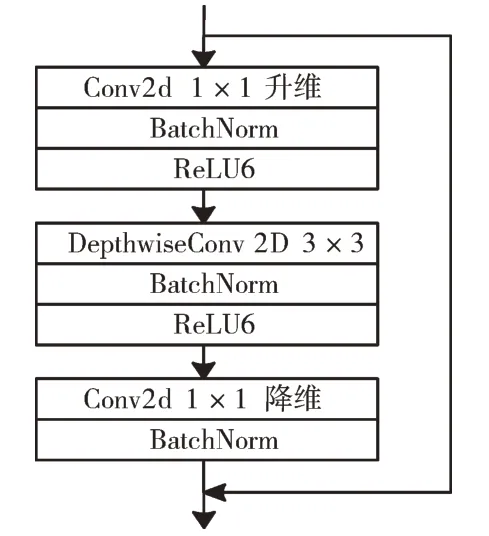
Fig.2 Inverted residuals block structure图2 Inverted residuals 结构
在输入维度与输出维度相同时,引入ResNet 中的残差连接,将输出与输入直接相连。这种倒残差结构的特点为上层和下层特征维度低,中间层维度高,避免了Mobile-NetV1 在深度卷积过程中卷积核失效等问题,而且在高维特征层使用单深度卷积也不会增加太多参数量。此外,引入残差连接可避免在加深网络深度时出现梯度消失的现象。
MobileNetV3[8]使用一个3×3的标准卷积和多个bneck 结构提取特征,在特征提取层后使用1× 1 的卷积块代替全连接层,并加入最大池化层得到最后的分类结果,进一步减少网络参数量。MobileNetV3 包括Large 和Small两种结构,本文使用Large 结构。为适应车型识别任务,将输入图片大小设为416×416。MobileNetV3_Large 结构如表1 所示,其中SE 表示是否使用注意力模块,NL 表示使用何种激活函数,s 表示步长。
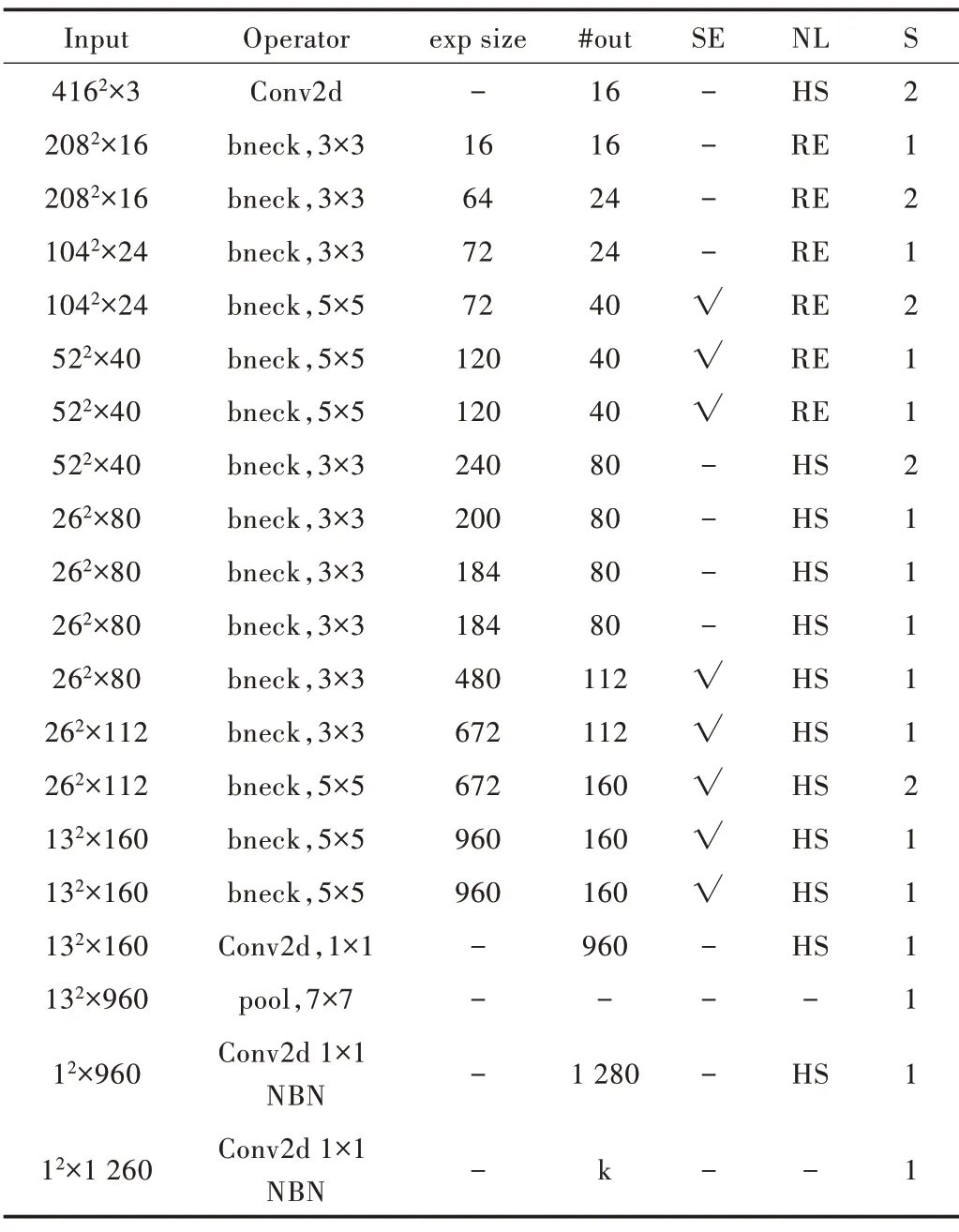
Table 1 MobileNetV3_Large structure表1 MobileNetV3_Large 结构
bneck 结构结合了V1 中的深度可分离卷积与V2 中的残差结构,并在某些bneck 结构中引入轻量级注意力模块,增加了特征提取能力强的通道权重。bneck 结构如图3 所示。
在主干模块中使用h-swish 激活函数代替swish,在SE模块中使用h-sigmoid 激活函数代替sigmoid,减少了网络的计算量。h-sigmoid、h-swish 的计算公式如式(8)、式(9)所示。
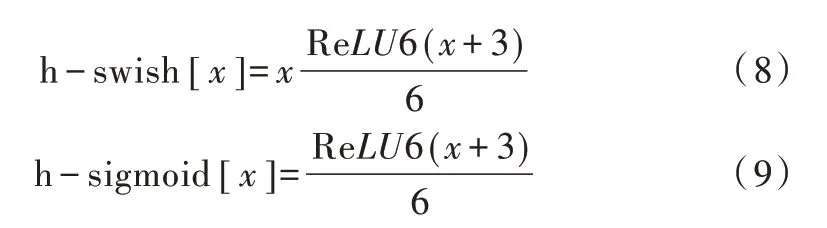

Fig.3 Benck block structure图3 bneck 结构
2 轻量级车型识别模型MobileNetV3-YOLOv4 建立
2.1 MobileNetv3-YOLOv4 整体框架
YOLOv4[9]是一个基于回归的单阶段目标检测算法,主要由CSPDarknet53特征提取结构[10]、PAnet特征融合结构[11]和进行回归与分类的head 头3 个部分组成,其可在检测目标的同时对目标进行分类。
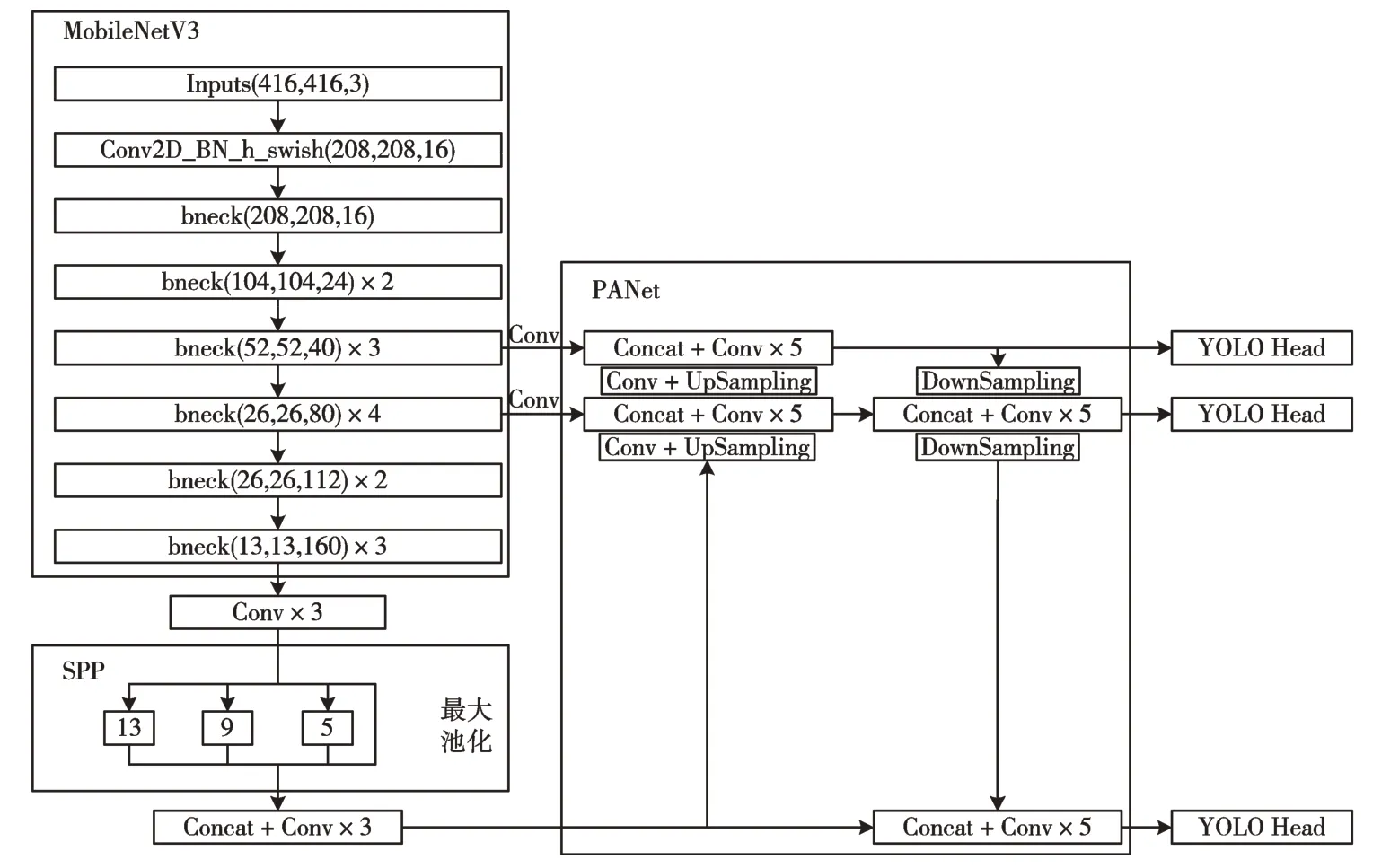
Fig.4 MobileNetV3-YoloV4 network structure图4 MobileNetV3-YoloV4 网络结构
MobileNetV3-YOLOv4 网络采用MobilenetV3 作为主干提取网络代替原有的CSPDarknet53 网络,其结构如图4 所示。SPP(Spatial Pyramid Pooling)模块分别使用4 个不同大小的卷积核对前层特征进行最大池化处理[12],卷积核的尺寸分别为13 × 13、9 × 9、5 × 5、1× 1,然后将4 个处理后的结果连接起来组成新的特征层,在增加网络深度的同时保留了前层特征,以获取更多局部特征信息。PANet 模块对MobileNetV3 主干网络特征提取的结果首先进行上采样,再进行下采样,加强了特征金字塔的信息提取能力。通过不同层的自适应池化,将特征网格与全部特征层直接融合在一起,在下采样的过程中将融合的结果传入Head 头进行回归与分类。
通过PANet 结构得到3 个特征层的预测结果,这3 个特征层的大小分别为52 × 52、26 × 26、13 × 13。Yolo Head 将输入图像划分为对应大小的网络,例如对于13 × 13 大小的特征层,将其划分为13 × 13 的网格,目标中心所在的网格负责该目标的预测,每个网格点会有3 个预设的先验框,不同大小特征层网格点的先验框大小也不相同。每个预设的先验框经过预测得到网格中心的偏移量x_offset 和y_offset、预测框的宽高h 和w,以及物体的置信度和分类结果。在预测过程中将每个网格加上其偏移量得到预测框的中心,然后通过先验框结合h 和w 便可得到预测框的位置。本文模型将所有卷积核大小为3 × 3 的标准卷积替换为深度可分离卷积,进一步减少了模型参数量。
2.2 损失函数
采用YOLOv4 模型的损失函数,包含边界框回归(Bounding Box Regression)损失、置信度损失和类别损失3个部分,其中边界框回归损失中使用CIOU代替YOLOv3 中的MSE 损失,其他两部分与YOLOv3[13]相同。
IOU为两个锚框之间的交并比,表示为:

IOU对目标尺度不敏感,且当预测框与实际框没有重叠时,IOU会出现无法优化的情况。CIOU对IOU进行了改进,不仅考虑了锚框之间的交并比,还将尺度与惩罚项纳入考虑,计算方式为:

式中,ρ2(b,bgt)表示预测框与真实框中心的欧式距离,b和bgt分别为预测框和真实框的中心点,c表示预测框与真实框最小外接矩形的对角线距离。α和υ的计算公式为:
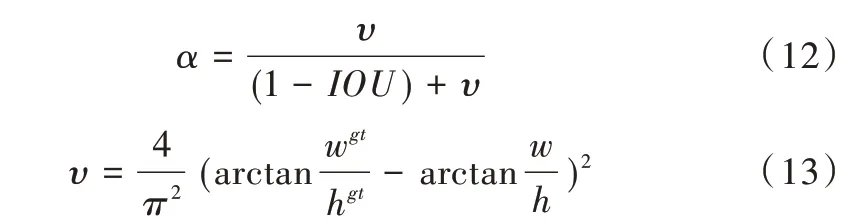
式中,wgt、hgt分别为真实框的宽、高,w、h分别为预测框的宽、高。
相应的损失Lciou表示为:

置信度损失Lconf表示为:
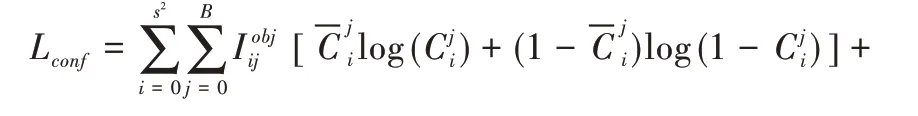

式中,S2表示分类特征层所划分的网格数,B表示每个网格点包含的先验框个数,表示预测框内有无目标,为预测目标置信度,为实际置信度,λnoobj为预设参数。
类别损失Lcls表示为:

式中,c为检测目标类别,为预测为此类的概率,为此类实际概率。
总的损失Lobject表示为:
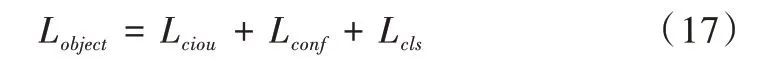
2.3 迁移学习
迁移学习是将已训练完成网络的权重迁移到一个未经过训练的网络中[14]。大部分任务或数据都具有一定相关性,且在大数据集中训练过的模型通常都具有很强的泛化能力,因此迁移学习可以将已经学习到的特征提取能力通过设定预训练权值的方式共享给新模型以加快其训练速度。对于在相对较小的数据集上训练的模型,迁移学习也能使其学习到预训练模型在大数据集上训练得到的特征提取能力,防止过拟合现象。为加快车型识别模型的训练速度,本文使用迁移学习的方式将MobileNetV3 在ImageNet 数据集上训练好的参数迁移到车型识别任务中。
2.4 K-means 聚类方法重置先验框
在目标检测算法中,通过预设不同大小的先验框分别对每个网格中心进行预测,替换使用多尺度滑动窗口遍历的方法,提升了模型的速度与精度,其中YOLOv4 的先验框是通过对VOC 数据集的目标聚类所得。VOC 数据集上的目标尺寸差异很大,因此预设的先验框差异也很大。在本文设定的车型识别任务中,车辆目标尺寸差异相对较小,因此通过K-means 聚类法[15]重设先验框可得到更好的检测效果。
首先遍历数据集中每个标签的每个目标,随机选取9个框作为聚类中心,划分为9 个区域,计算其他所有框与这9 个聚类中心的距离。如果某个框距离某个聚类中心最近,则这个框就被划分到该聚类中心所在区域,之后对9 个区域内所有框取平均,重新作为聚类中心进行迭代,直至聚类中心不再改变为止。由于不同目标框的宽高各不相同,若使用目标框中心与聚类中心的欧式距离作为距离参数可能会导致更大误差,因此选择聚类中心与目标的IOU作为距离参数,距离d表示为:

3 实验方法与结果分析
3.1 实验环境
在Win10操作系统,GPU 为GeForce RTX 2060的计算机上进行实验。Cuda 版本为10.0,Cudnn 版本为7.4.1.5,使用Pytorch 框架进行模型的搭建与训练。
3.2 数据集
使用BIT-vehicle 数据集,包含9 850 张车辆图片,分为Bus、Microbus、Minivan、Sedan、SUV 和Truck 6 种车型[16],以7∶1∶2 的比例划分训练集、验证集和测试集。K-Means 聚类得到的9 个聚类中心宽高分别为(70,140)、(91,201)、(136,172)、(136,251)、(147,194)、(158,219)、(172,264)、(222,231)、(242,282)。在训练过程中,对送入模型的图片进行数据增强,随机对图片进行翻转,对宽高进行扭曲,对亮度进行随机调整,对图片多余部分填充灰条,以增强模型的泛化能力。增强效果如图5 所示。

Fig.5 Vehicle image enhancement processing图5 车辆图像增强处理
3.3 实验结果与分析
以精确率(Precision)、召回率(Recall)、平均精度均值(Mean Average Precision)作为评估模型识别效果的指标,以每秒传输帧数(Frames Per Second,FPS)作为评估算法速度的指标[17]。精确率与召回率的计算方法如式(19)、式(20)所示。式中TP(True Positives)表示目标被分为正类且分类正确的数量,TN(True Negatives)表示目标被分为负类且分类正确的数量,FP(False Positives)表示目标被分为正类但分类错误的数量,FT(False Negatives)表示目标被分为负类但分类错误的数量。
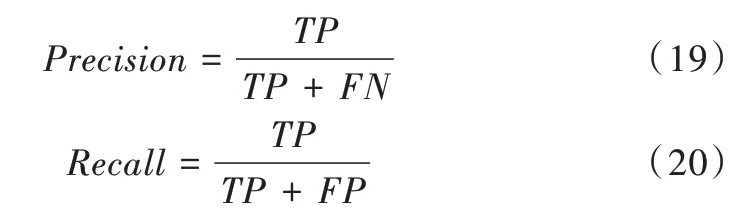
采用不同置信度会得到不同的精确率和召回率,分别将Recall 和Precision 作为x、y轴,绘制P-R 曲线,该条曲线下覆盖的面积即为此类AP(Average Precision)值。对所有分类的AP 值求平均,可得到该模型的mAP 值,计算方式为:

共训练100 个epoch,在前50 个epoch 冻结主干特征提取网络的权重,学习率设置为0.001,在后50 个epoch 解冻,对全部网络参数进行训练,将学习率降为0.000 1。最后得到各个车型的P-R 曲线如图6 所示,mAP 值为96.17%。
为验证本文方法的有效性,分别将数据集在YOLOv4和主干特提取网络为ResNet-50 的Faster-RCNN 上进行训练,训练一个epoch 记录一次损失值,各网络的损失函数如图7 所示。由损失函数的曲线可得,YOLOv4 和Faster-RCNN 的训练误差相较于MobileNetV3 收敛趋势更快。总体来说,三者验证误差收敛速度均很快,但MobileNetV3-YOLOv4 在参数解冻前训练一轮仅需约3min10s,解冻后需约4min50s;Faster-RCNN 参数解冻前训练一轮需约19min,解冻后一轮需约28min;YOLOv4 参数解冻前训练一轮需约9min,解冻后一轮需约21min25s。整体来看,MobileNetV3-YOLOv4 比其他两种模型训练速度更快。
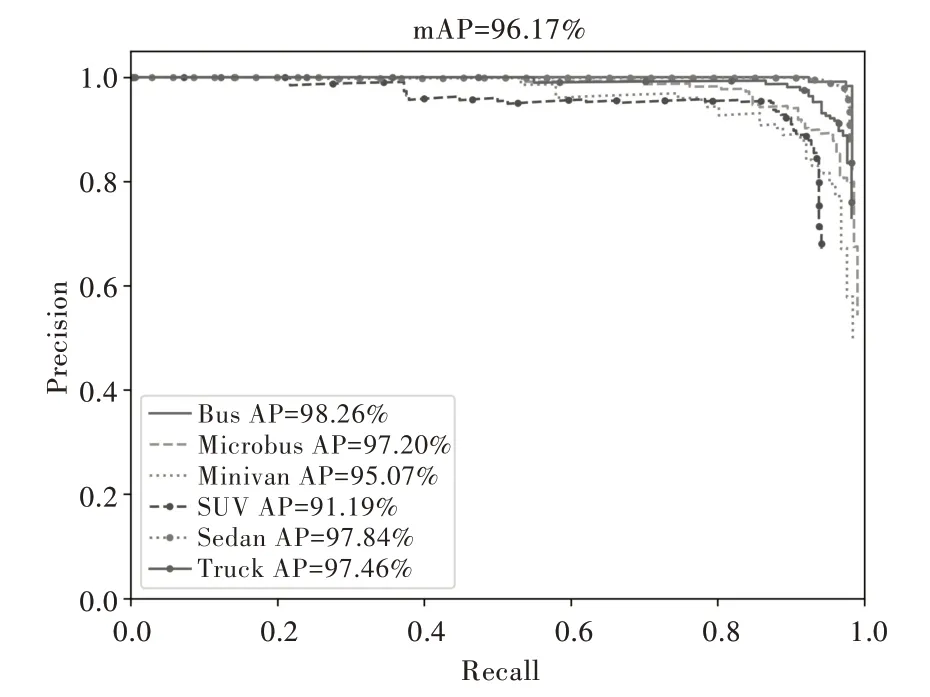
Fig.6 P-R curve图6 P-R 曲线

Fig.7 Loss function curve图7 损失函数曲线
由表2 可知,本文方法在精度达到96.17%的情况下,模型大小较原YOLOv4 降低了约80%,较Faster-RCNN 降低约50%,检测速度较YOLOv4 提升了约26%,较Faster-RCNN 提升了约130%。

Table 2 Test results of different models表2 不同模型测试结果
网络正确预测的图像如图8 所示,可以看到模型对不同车型均有不错的检测效果。

Fig.8 Model prediction results图8 模型预测结果
4 结语
本文将MobileNet 轻量级网络引入YOLOv4 目标检测网络中,得到MobileNetV3-YOLOv4 模型,并使用K-means算法设置预选框提升了模型最终识别精度。通过BIT-vehicle 数据集下的车型识别实验验证MobileNetV3-YOLOv4网络模型的有效性,实验结果表明,本文算法较YOLOv4 整体识别速度提升了约26%,且模型参数量降为原来的1/5。但该数据集拍摄的车辆图片角度较为单一,训练后的模型对于侧面拍摄的车辆图片误检率较高。为进一步增强模型的泛化能力,使其对不同角度的车辆均有较好的识别效果,后续会尝试将该模型运用于其他大型车辆数据集中进行训练,并对其进行相应改进以保证识别精度。
