基于随机森林算法的珠海一号高光谱影像土地利用信息提取
2022-01-06杨远陶曹礼刚陈景珏
杨远陶, 刘 瑞, 曹礼刚, 杨 梅, 陈景珏
(成都理工大学 a.地球物理学院,b.地球勘探与信息技术教育部重点实验室,c.地球科学学院,成都 610059)
0 引言
土地利用现状是国家和政府制定相关土地政策、合理规划土地配比以及布局生产的重要依据,而了解土地利用情况最传统的方法是利用大量的人力,通过实地调查和记录,最终汇总成一张土地利用现状图,这样的方式会耗费大量的人力和财力,且时间周期很长。近年来,随着遥感技术的应用领域越来越广泛,结合遥感技术的土地利用分类技术成为一种低成本,高精度的新方法。因此,基于遥感影像的土地利用信息提取成为了一个新的热点。而目前的遥感数据主要分为多光谱遥感影像数据和高光谱遥感影像数据。相较于多光谱数据,高光谱遥感影像数据具有更加细微的光谱特征且信息量大,解决了多光谱影像光谱信息不足的情况。
在土地利用信息提取过程中最关键的环节是高光谱影像分类方法,这也是目前国内、外学者一直研究的一个热点问题。选择一个可以更加快速且精确的对影像进行分类的算法,成为一个关键的问题。目前比较主流的影像分类算法包括最大似然法、决策树、支持向量机、人工神经网络法等[1-5],然而,在进行土地利用信息提取时,由于土地利用信息的复杂化、格局破碎化、同物异谱和同谱异物现象,单分类器已经难以满足更高的分类精度需求[6-7]。
目前基于传统的分类算法衍生了各种机器学习的算法,为影像分类算法提供了新的方向[8],在机器学习算法中,表现最优的是随机森林算法,它作为一种多分类器组合的分类算法,可以应对单分类器在面对复杂的土地利用信息分类中效果不佳的问题。
1 数据来源与预处理
1.1 数据来源
这里所使用的高光谱数据为珠海一号高光谱卫星数据,2018年4月26日珠海一号卫星成功发射升空,标志着国内首个自主运营的高光谱星座的成功建立,也是多颗高光谱卫星的组网在国内首次实现。总共包含了32个波段的珠海一号卫星涵盖了400 nm~1 000 nm的光谱范围,在光谱分辨率达到3 nm~8 nm的同时,其空间分辨率达到10 m,且幅宽达到了150 km,每2 d就可以完成一次重访,设计的有效工作年限为5 year。具体波段信息如表1所示,珠海一号的卫星体积小,但它在星上的存储容量大且卫星的成本较低。同时珠海一号卫星还具备幅宽大,卫星空间分辨率高,重访周期短等优势[9]。
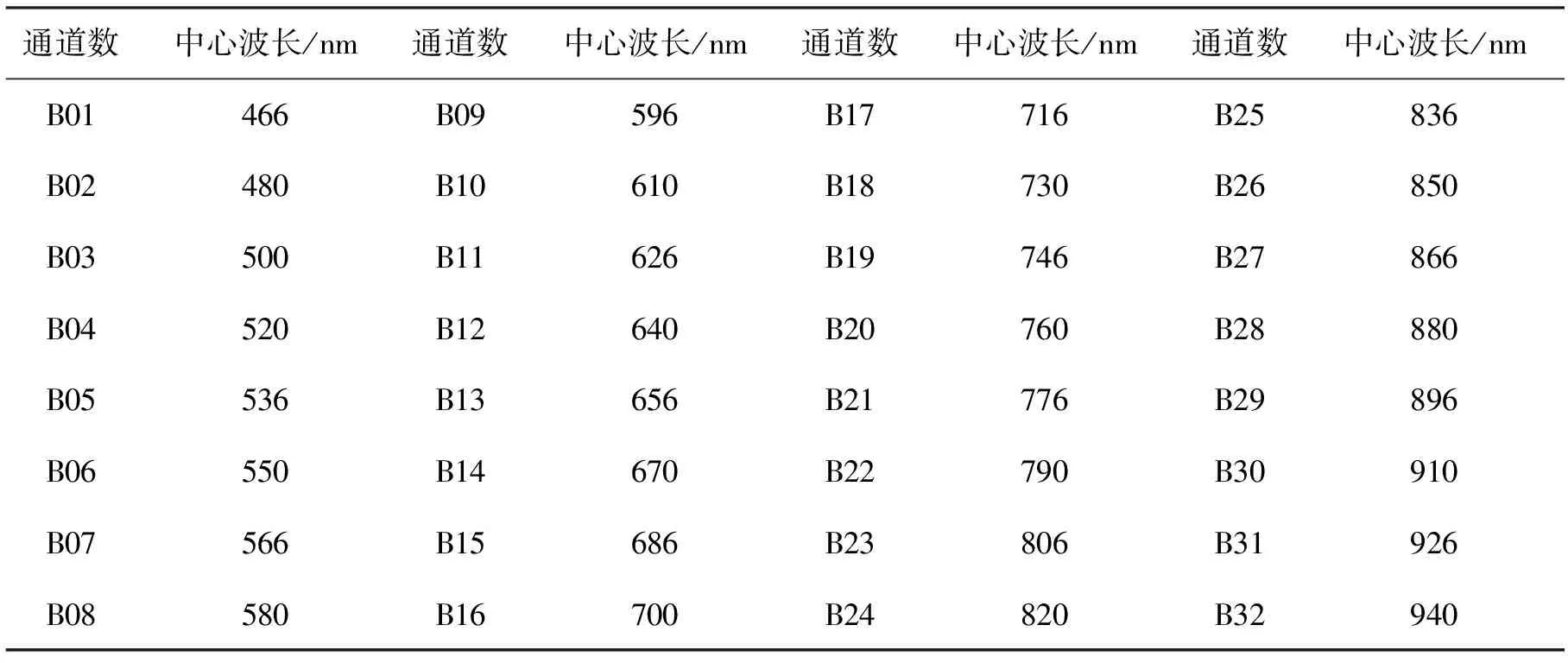
表1 珠海一号高光谱数据中心波长
1.2 数据预处理
珠海一号高光谱数据是没有经过去除积分级数处理的数据,因此需要对数据进行辐射定标、大气校正、影像裁剪等预处理。
在珠海一号高光谱影像中,包含了32个波段,其中波段b1~b2对应的是蓝光波段;波段b3~b8对应的是绿光波段;波段b11~b21对应的是红光波段;波段b22~b32对应的是近红外波段,为了提高运算速率,分别计算这些波段的标准差(表2),当影像波段的标准差越大时,说明此波段所含的信息也就越丰富。结合实际情况,通过比较这些波段的标准差的大小,最终选择了波段b2作为蓝光波段、b6作为绿光波段、b15作为红光波段和b25作为近红外波段。
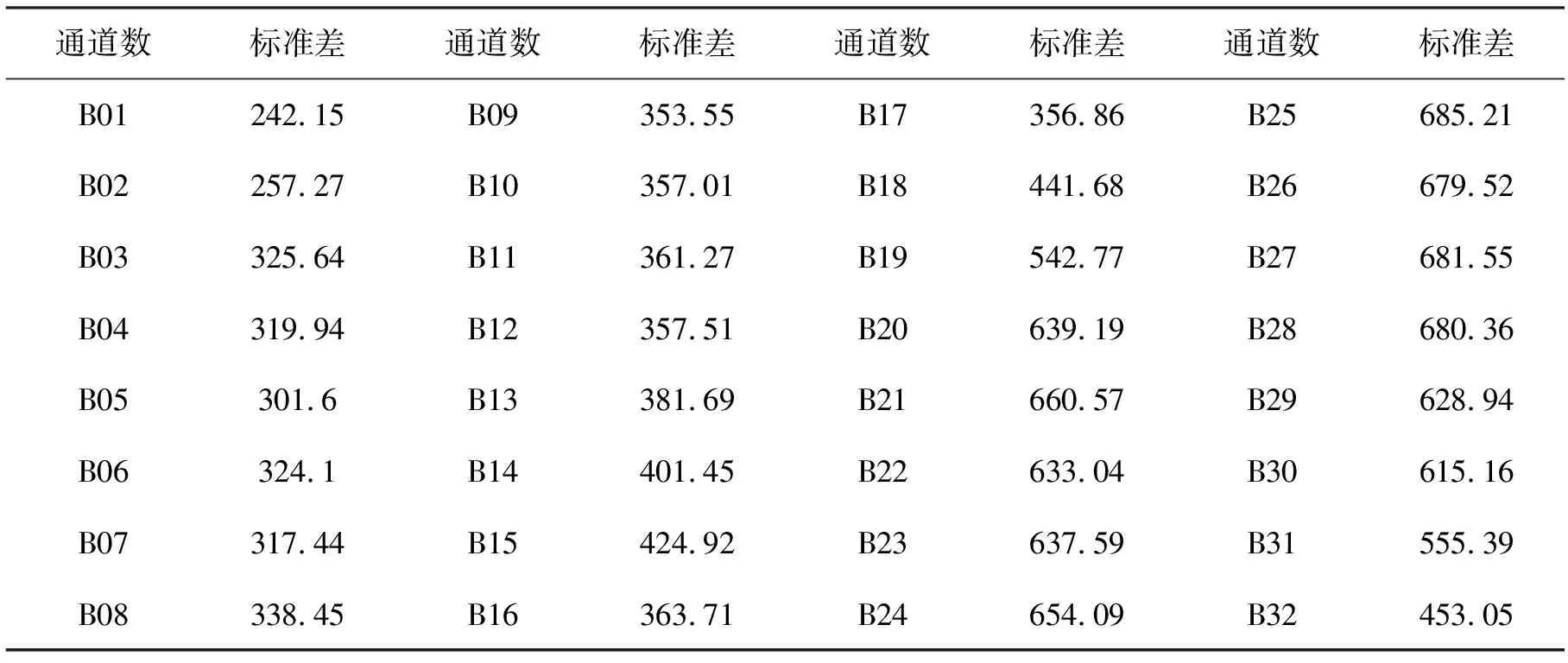
表2 各波段对应的标准差

图1 研究区概况Fig.1 Overview of the research area
1.3 研究区
这里获取了2018年10月6日珠海一号的高光谱数据。此景影像主要覆盖了江西省南昌市进贤县的大部分区域。进贤县在浙赣铁路与316、320国道交汇处,它位于江西省的中部,主要在潘阳湖南岸,面积为1 971 km2。
2 研究方法
2.1 最大似然算法
最大似然法分类是目前遥感影像分类方法中最经典的分类方法之一[10]。在遥感影像中那些具有最大似然的像元将会被划分到相应的类别中,根据遥感影像中的波谱信息,可以得到影像中各个类别的一个概率密度函数。式(1)表示像元x被划分为类别的后验概率。
gi(x)=p(wi|x)=p(x|wi)p(wi)/p(x)
(1)
式中:p(wi)是类别的先验概率;wi表示从类别观测到像素x的条件概率。通常假设每一类别的p(wi)都是相同的,根据数学原理,利用多元正态分布作为概率密度函数。在正态分布的情况下,后验概率gi(x)可以表示为式(2)。
(2)
式中:i是波段数;x是有i个波段的影像数据;gi(x)是x中属于类别wi的可能性;ui是类别i的平均向量;∑i是类别i的方差-协方差矩阵。在方差-协方差矩阵是对称的情况下,似然度与欧几里德距离相同,而在决定因素彼此相等的情况下,似然度与马氏距离相同。为了移除多余的项,需要对式(2)进行取对数运算,因此可以得到的最终函数为:
(3)
由式(3)得到的判别公式就为最大似然法的判别公式。
2.2 决策树算法
决策树分类算法的分类过程类似于一个倒着的树状结构,从第一级开始,把遥感影像数据集一级一级的往下细分。决策树有一个根节点、多个中间节点和K个叶子节点组成。决策树的分类过程分为三个步骤:
1)生成一颗倒立状的树状结构。
2)根据这棵树的根节点到叶子节点的路径生成一系列的规则。
3)通过步骤2)的一系列规则加入遥感影像数据,最终得到分类或者预测结果。
因此,决策树的分类思想可以理解为构建一颗倒立的树状结构,通过生成的一系列的规则,然后根据这些规则将原始数据进行归类的过程[11-12]。
2.3 随机森林算法
2.3.1 算法思想
随机森林分类算法是一种基于决策树的机器学习算法[13]。它是Bagging算法和Random Subspace算法的组合。以决策树{h(X,θk);k=1,2,…,n}∈{true,false}作为基本构成单元,通过将多颗决策树组合在一起来提高分类的准确性,由此构建了随机森林分类器(图2)。随机森林算法的基本思想是:首先,从原始训练样本集中利用 bootstrap 抽样抽取K个样本,抽取的样本必须满足每个样本的样本容量都与原始训练集大小一样。其次,K个决策树模型是由抽取的K个样本所建立的,这K个决策树模型就组成了随机森林分类器。最后,用这K颗决策树对测试样本集进行分类,得到K种分类结果,依据K种分类结果对每个记录进行投票表决,决定其最终分类。
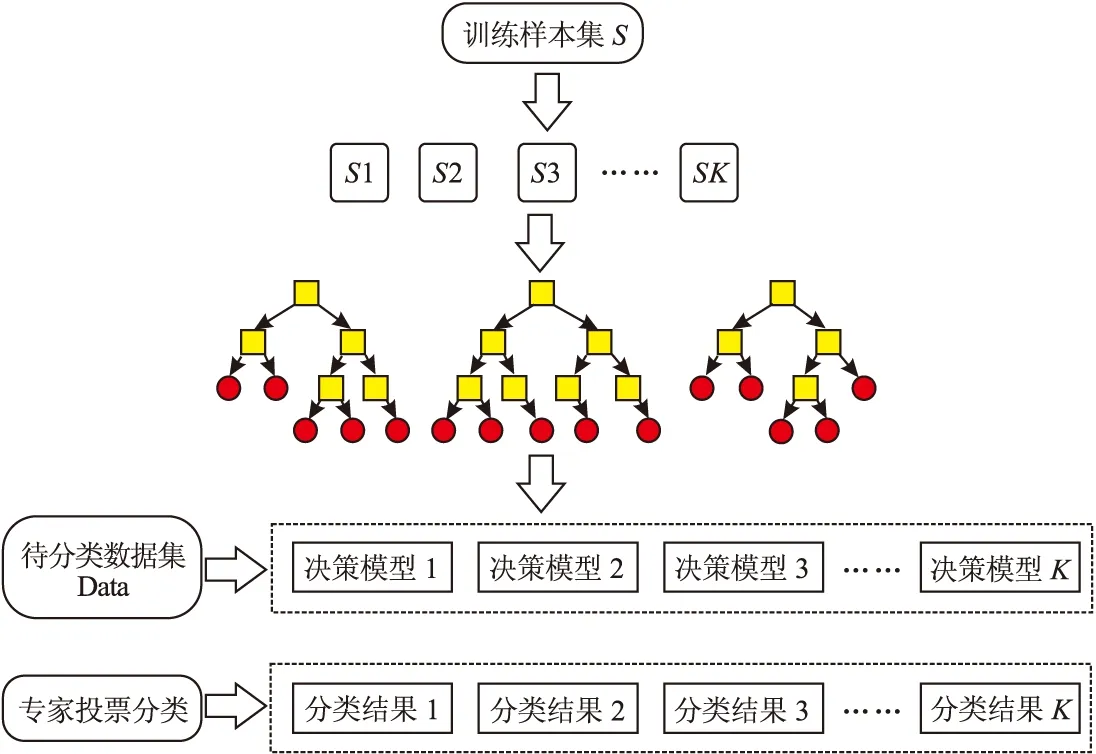
图2 随机森林分类示意图Fig.2 Schematic diagram of random forest classification
2.3.2 基本原理
在随机森林模型构建的过程中,最关键的一步就是从属性子集K选取最佳分类节点方法[14]。目前流行的有三种,分别是基尼系数、信息增益和信息增益率。它们所对应决策树类型为CART、ID3和C4.5。最佳分裂属性是从对应值最佳的属性中挑选出来的,当属性值为离散时,即可进行下一步分裂;若属性值为连续变量时,则需要再选取最佳分裂点。具体计算方法是基尼系数为一种判断分配平等程度的指标,基尼系数越小表示分配平等程度高,因此分类效果越好,计算公式为式(4)与式(5)。
(4)
(5)
在信息论中,熵值的定义则表示信息熵。数据样本的纯度越高,信息熵的值则越大,分类的效果就越好。样本T的信息熵可表示为:
(6)
其中:Pi表示样本i占总样本数量的比例。通过特征A作用,样本T将会被划分为k个部分。此时信息熵为式(7)。
(7)
因此信息增益率则为式(9),信息增益率与分类效果呈正相关关系,计算如下:
(8)
(9)
随机森林模型是以CART决策树为基本分类器的一个集成学习模型,因此笔者选择基尼系数作为节点分裂方法。
随机森林算法主要有以下几个优点:①鲁棒性好,无需担心过拟合现象;②数据兼容性好,对离散数据和连续数据都可以进行处理,即使数据缺失了部分特征也不影响分类结果;③抗噪声能力强;④算法容易实现,效率高;⑤可以并行化处理。在实际应用过程中,有时需要对随机森林算法进行评价。对于一个分类器来说,最重要的评价标准即是分类精度,随机森林也不例外。因此,对随机森林分类器的性能评价主要从分类精度来进行。
3 实验结果与分析
3.1 实验结果
笔者选取珠海一号高光谱影像作为实验数据,以最大似然、决策树和随机森林三种算法作为影像的分类算法。首先对影像数据进行预处理,根据研究区的实际情况,将研究区土地类型分为了水体、道路、耕地、草地、林地、城乡建设用地和裸地七类。其次通过目视解译的方式,选取适量的样本,作为模型的训练和验证样本。训练样本分别加入三种模型进行训练,把训练好的模型用于原始影像预测得到最终的分类结果(图3)。最后将分类结果结合验证样本评价其模型的分类精度。
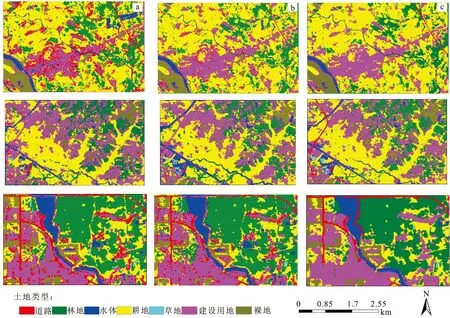
图3 各算法分类结果Fig.3 Classification results of each algorithm(a)最大似然;(b)决策树;(c)随机森林
在图3中,通过将实验结果和原始影像进行同位置比对可以看出,最大似然法(图3(a))在分类时对道路像元较为敏感,但将很多城市像元错误地划分为道路类型,在结果图上出现了许多较大的道路斑块。决策树算法(图3(b))在水体和建设用地区分上表现出更高的精度;随机森林模型(图3(c))的结果显示其在各种地物类型区分上都表现出较优的性能,尤其是在道路和城市建设用地的区分上,解决了前两种方法出现的道路斑块较多的问题,并且在耕地、裸地的划分上也表现出较好的结果。
3.2 总分类精度
分类精度是一个客观评价分类方法优劣的指标,在进行分类精度评价时,为了保证分类精度评价的客观性,采用控制变量法。除了分类方法可变以外,使用同一套训练样本和验证样本,采用最大似然法、决策树和随机森林三种分类算法对研究区进行分类。由混淆矩阵计算得出分类模型的分类精度如图4所示。
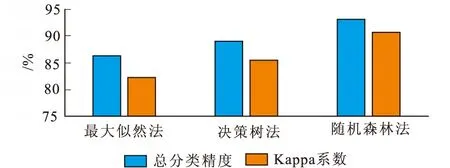
图4 各算法分类精度及Kappa系数Fig.4 Classification accuracy and Kappa coefficient of each algorithm
图4表明,最大似然法的分类精度是最低的,决策树法居中,分类精度最高的为随机森林算法,总分类精度达到了93%。随机森林算法相较于最大似然法提高了接近七个百分点,显然随机森林分类算法优于最大似然分类算法。
3.3 各地类分类精度
由表3可以看出,在相同的条件下,不同地表覆盖类型的分类精度差别较大,具体来看,林地、耕地、城乡建设用地和裸地的分类效果较好,精度都达到了90%以上,而草地的分类效果表现较差,分类精度仅70%,其余地类的分类精度都在80%~90%之间。综上所述,在高光谱土地利用信息提取中,随机森林算法较最大似然分类算法和决策树分类算法更加精确,在区分复杂的地类时也体现出更明显的优势,特别是在林地和城市建设用地的区分上,分类精度分别高达98.2%和95.26%(图3)。

表3 不同分类方法分类精度比较
4 结论
高光谱图像分类算法研究是高光谱研究领域中的一个重要方向,具有重要的实际意义。本研究针对当前高光谱图像分类过程存在的一些难题,笔者提出了一种结合波段标准差和随机森林算法的高光谱遥感影像分类模型,并且将该模型与传统的最大似然分类算法和决策树分类算法进行对比。通过分类精度评价得到随机森林算法、决策树法和最大似然法的分类精度分别为93.14%、89.07%和86.38%。结果表明,利用随机森林模型可以明显地提高高光谱影像的分类精度,而且极大地减少了影像错分和漏分的现象,可为高光谱影像在土地利用信息提取中提供一种新的参考。
笔者利用影像标准差的方式,对高光谱影像进行降维,这样可以弥补多光谱影像波段的不可被替换的缺陷,在未来的土地利用信息提取上具有广阔的应用前景。
这里采用了基于机器学习的随机森林算法对影像进行分类,这种多分类器集成的分类算法,弥补了在单一分类器下分类精度较低且容易出现过拟合的缺陷,提高了分类精度,能够快速且准确地提取土地利用信息,实现了土地利用信息快速可视化的目的。
虽然随机森林算法在高光谱土地利用信息提取上取得了较高的精度,但在样本选取和数量上存在一定的主观性因素,因此在样本的选择和样本的数量将成为下一步的研究目标。
