基于PSM-DID模型的政策对试点企业经营绩效的影响评价研究——以 “供应链创新与应用试点”政策为例
2022-01-05刘伟华孙嘉琦陈之璇刘馨允
刘伟华 孙嘉琦 陈之璇 刘馨允
(天津大学管理与经济学部,天津 300072)
引 言
21世纪的竞争不是企业之间的竞争,而是供应链与供应链之间的竞争。当前,新一轮科技革命和产业变革加速演进,在经济全球化大背景下,企业供应链愈发变得更加动态和复杂,对企业经营绩效的重要性与日俱增[1]。因此,加快供应链运作效率、提高供应链柔性与协调能力和增加供应链运营收益成为我国企业供应链创新发展的必然要求。
在这样的背景下,我国政府积极推进供应链领域政策的制定与发布,供应链在我国政策文件中提及频率明显增加,如何更好地评估既有政策带来的绩效成为政府进一步制定供应链相关政策的关键。2017年10月,国务院办公厅发布了第一份中央层面的供应链政策文件 《国务院办公厅关于积极推进供应链创新与应用的指导意见》[2],该政策文件有着重要的意义,指明了我国供应链创新与应用的必要性。但由于该政策是指导性意见,涉及企业数量广泛且不确定,难以准确评价该政策对企业带来的影响。2018年4月10日,商务部、国家市场监督管理总局、工业和信息化部、中国物流与采购联合会等八部门下发 《关于开展供应链创新与应用试点的通知》(商建函[2018]142号)(以下简称 “供应链创新与应用试点”政策),该政策有明确的时间起点,并且有着明确的政策支持对象(即269家试点企业),试点实施期为2年。该政策具备 “准自然实验”的研究条件,对该政策实施效果进行评估,不仅能够对该政策进行效果评价,考察该政策是否对试点企业有益,也能够为促进我国供应链发展的相关政策建议提出提供具体的参考。因此,研究该政策对企业经营绩效的影响对进一步完善供应链相关政策具有重要的研究价值。
在以往政策评估的研究中,有几种主流的评估方法,包括双重差分方法、工具变量法和倾向得分匹配法等[3]。其中,工具变量法应用的局限性较强,较难找到好的工具变量[4]。而由于本文选取的研究政策为试点政策,更加适合采取分组别差分的双重差分法进行研究。双重差分(DID,Difference-in-Difference)最初由普林斯顿大学的Ashenfelter和Card于1985年在一篇项目评价的文章[5]中提出,之后在计量经济学界以及社会学界被广泛应用于政策评估领域。如Zareh Asatryan等(2017)[6]结合双重差分方法和非连续性回归方法利用德国巴伐利亚州1995年引入的地方自主权来研究直接民主对财政的影响。Lori Prince Hagood(2019)[7]采用双重差分方法探讨绩效资助对国家拨款的影响,同时定量分析了不同机构类型的异质待遇效应。 Chiu-Fang等(2020)[8]应用双重差分模型研究卫生资源和服务管理局(HRSA)资助项目对美国牙医执业点的潜在影响。Lajos Baráth等(2020)[9]研究了 2006~2013年期间,不同类型的补贴对斯洛文尼亚农业全要素生产率(TFP)不同组成部分的影响。国内研究方面,用该方法进行的研究包括我国 “抓大放小”、战略重组政策(李楠和乔榛,2009)[10]、税收政策(江明轩,2011;韩仁月和马海涛,2019)[11,12]、 “营改增”政策(袁从帅等,2015)[13]、铁道部改革(Wang等,2018)[14]、 “一带一路”、 “中国制造 2025”(端利涛等,2020)[15]等。可见,双重差分模型方法在政策效果评价领域被普遍认可,但双重差分模型仍然具有一定的局限性,即难以满足样本共同趋势假设,针对此,倾向得分匹配法(PSM,Pro⁃pensity Score Matching)能够很好地克服样本选择的内生性影响,鉴于此,本文政策评估时将双重差分方法和倾向得分匹配法相结合,构建PSMDID模型以弥补双重差分方法的局限性。
资产收益率ROA指标的高低直接反映了公司的竞争实力和发展能力,也是决定公司是否应举债经营的重要依据[16],因此可以作为公司经营绩效的核心指标。本文以 “供应链创新与应用试点”政策的实施作为研究对象,构建供应链政策评价的准自然实验,基于2015~2019年的面板数据,运用PSM-DID双重差分倾向得分匹配模型探讨政策对试点企业经营绩效中的盈利指标资产收益率(Return On Assets,ROA)的影响,以研究政策的实施能否促进试点企业更有效地经营。本文的研究表明,实施 “供应链创新与应用试点”政策,对试点企业的经营绩效ROA有着显著的正向促进影响,表明我国该政策实施效果良好;此外,企业规模、企业的资产负债率、托宾Q值和企业固定资产投资比率都对ROA有显著影响。其中企业规模和托宾Q值对ROA有正向影响,资产负债率和固定资产投资比率对ROA有负向影响。
1 研究假设
为开展本文的研究,根据本政策的相关内容和本文研究目标,特提出以下假设:
(1)试点政策与企业经营绩效的关系
“供应链创新与应用试点”政策旨在推动企业提高供应链管理和协同水平、加强供应链技术和模式创新、建设和完善各类供应链平台、规范开展供应链金融业务、积极倡导供应链全程绿色化,进而全面提升企业经营绩效。针对 “供应链创新与应用试点”政策,本文将基于2015~2019年的面板数据对试点企业的经营绩效的影响效果进行评估。根据政策内容,该政策试点重点强调试点企业的创新转型和降本增效,这会促进试点企业的研发投入提升,而根据以往研究(刘睿智和张鲁秀;郑海元和李元杰)[17,18],企业在研发或者无形资产上投入的增加能够增强公司盈利能力。同时,该政策还积极推动企业同商业银行、高校、研究机构等的供应链合作以推动供应链信息化发展,而信息化水平提升有助于信息在组织内传播以及提升共享的有效程度从而有助于显著提高企业绩效[19],信息化能够增强和促进企业资源利用效率和生产率的提升[20],因而能够降低企业运作成本。因此,本文认为,该政策实施能够显著正向提升企业盈利能力,因此本文提出假设1。
H1:“供应链创新与应用试点”政策对试点企业的经营绩效ROA有显著正向促进作用。
(2)试点企业规模与企业经营绩效的关系
企业规模的大小在一定程度上反映了企业成长的不同阶段,目前对企业规模的衡量方式有两种,分别是定性和定量。其中定性方式包括公司运营形式、行业地位、股东权益集中情况等,而定量方式则包括雇员人数、资产总额、营业总额等[21]。根据经典的SCP理论,市场结构决定企业市场行为,企业市场行为又决定经济绩效,而企业规模作为重要的市场结构变量对企业绩效具有显著影响[22]。一般来说,试点企业规模越小,占有市场就越小,抗风险能力偏弱,生产技术等相对来讲不如规模较大的企业技术成熟,盈利能力相对也较弱[23],因此本文提出假设2。
H2:企业规模与企业经营绩效ROA有显著正向关系。
(3)试点企业成长能力与企业经营绩效的关系
托宾Q值是公司市场价值对其资产重置成本的比率,该指标主要反映了企业两种不同价值估计的比值,而同时也侧面反映了企业的成长能力[24]。若企业的托宾Q值越高,则对应企业的市场价值相对高于资本的重置成本,此时企业在发行少量股票的情况下能够买到较多的投资品[25],进而能够提供给经营活动的支出增多,企业主营业务以及其他业务总产出相应增加,盈利也将相应增多。因此,本文提出假设3:
H3:试点企业托宾Q值与企业经营绩效ROA有显著正向关系。
(4)试点企业负债水平与企业经营绩效的关系
负债水平一般通过资产负债率衡量,即负债总额与资产总额的百分比。当前,学术界针对资本结构与盈利能力关系也开展了相关的研究。其中,我国学者对我国上市公司的研究结果大多为负债水平与盈利能力呈反比例关系,如陆正飞和辛宇(1998)[26]对35家运输设备业上市公司的实证研究,宋忠宁和张建平(2010)[27]对江苏省上市公司的实证分析。本文认为,负债率越高的企业,其经营风险越高,导致企业很难有潜力实施更好的企业绩效。综合以往研究所得结论以及本文所选取的研究对象,本文提出假设4。
H4:试点企业负债水平与企业经营绩效ROA呈显著负向关系。
(5)试点企业固定资产比率与企业经营绩效的关系
固定资产比率不同能够在一定程度上反映出企业是轻资产型企业还是重资产型企业等,而资产异质性等很大程度上影响企业的盈利能力[28]。同时,根据固定资产比率定义,该值为固定资产与资产总额的比值,因而该比率的不同还将影响企业的流动资金,具有不同固定资产比率的公司其流动资产额、现金持有水平等不同。而柳丹(2013)[29]针对A股制造业上市公司研究得到超额现金持有量能够显著提升公司经营绩效。另外根据权衡理论,现金持有量越多,能为企业投资提供越好的支撑,并且更有效地体现出持有现金的价值增值能力,有助于企业绩效水平提升[30]。因此,本文提出假设5。
H5:试点企业固定资产比率与企业经营绩效ROA呈显著负向关系。
2 研究设计
2.1 模型构建
(1)对样本进行PSM倾向得分匹配
使用DID方法,必须要保证对照组和处理组满足共同趋势假设这一前提,即需要保证二者的被解释变量在政策实施前的时间趋势是相同的,若不满足该前提,就无法满足用对照组模拟未受政策影响时时间效应的要求,结果将存在较大的偏误,不能有效反映政策真实效果。然而由于政策涵盖领域较大,不同行业和领域以及不同企业自身存在差异性,很难保证最初所选样本能够满足共同趋势假设,因此需要借助一定方法筛选出满足共同趋势假设的样本,在此基础上再去进行政策效果的评估。关于如何选择出具有平行趋势的样本,由Rusenbaum和Rubin于1983年提出的PSM倾向得分匹配法被广泛应用于解决样本选择偏差问题中,其原理是选出可能影响处理组样本未来趋势的各种特征,并根据这些特征在对照组中选取尽可能相同的样本进行匹配,从而筛选出符合共同趋势假设的可用样本,从而减少误差。PSM有多种匹配方法,包括最邻近匹配、核匹配、半径匹配[31]。本文将采用3种方法中最为常见的最邻近匹配方法进行研究。
(2)构建DID双重差分模型评估政策效果
DID模型作为政策效应评估的广泛应用方法,能够较大程度地克服内生性的干扰,其基本思想是将政策看成一项准自然实验,通过比较处理组和对照组在政策实施前后发生的差异来反映政策效果的方向及强弱。则对于本文来讲,处理组即“供应链创新与应用试点”企业,对照组则是非试点企业,并构建DID模型。具体见下式:
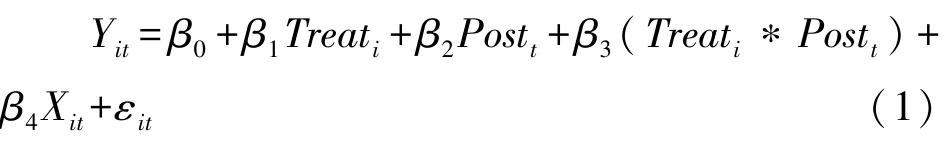
其中,Y代表被解释变量,下标i代表第i个企业,下标t代表第t年,Xit代表若干控制变量(匹配变量),εit代表随机扰动项。若个体是试点企业,属于处理组,则令Treati=1,若不是,则令Treati=0;若时间在政策实施后,则令Postt=1,若在政策实施前,则令Postt=0。根据表1可知交互项的系数β3的大小和方向能够直观反映政策效应。

表1 DID模型表格
2.2 变量选取
(1) 解释变量
本节主要评估 “供应链创新与应用试点”政策的实施对企业的经营绩效是否有显著效果,因此将 “开展供应链创新与应用试点”政策实施作为解释变量,在模型中体现为treat和post。
(2)被解释变量
小学阶段是学生语文学习的启蒙阶段,是培养学生良好学习习惯的最佳时期。在小学语文的教学中,朗读教学的开展,有利于培养学生的语感,发展学生的智力,加深学生对文本内涵的理解。因此,在新课程改革不断深入发展的社会背景下,小学语文教师要重视朗读教学,充分认识到朗读教学的积极作用,积极开展朗读教学,加强对学生的朗读训练,促进学生语文学习质量的提升,促进学生的全面发展。
本节目的在于评价该政策对企业的经营绩效是否有显著效果,而企业经营活动中往往最被关注的是赚取利润,企业的盈利能力是企业生存与发展的物质基础,也是企业业绩的最终反映之一[15],因此本文以总资产收益率ROA作为经营绩效的对应指标,着重考察经营绩效中的盈利能力部分。
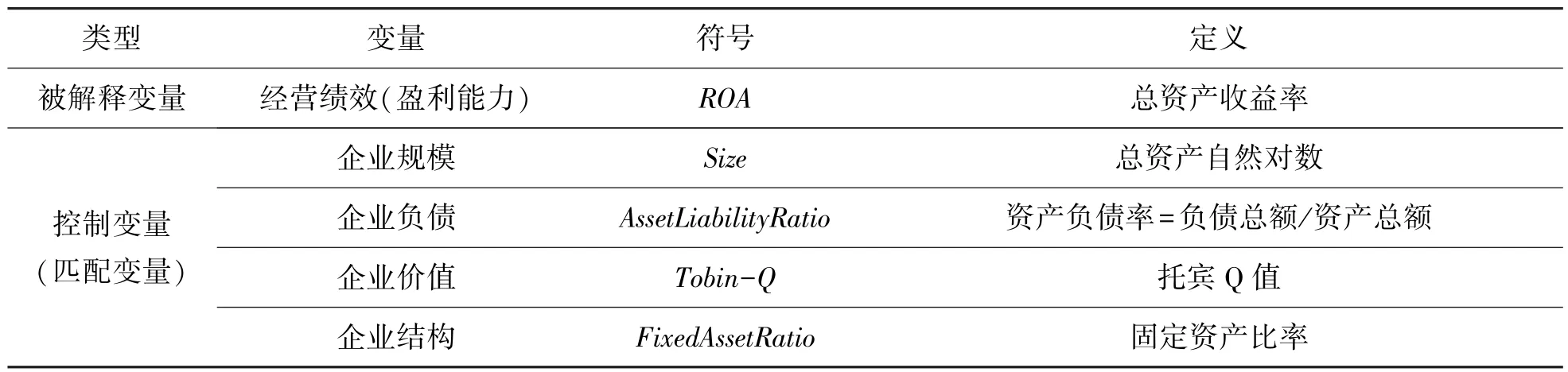
(3)控制变量(匹配变量)
为进行倾向得分匹配方法,需要将处理组即试点企业的一些主要特征作为匹配标准,采用最邻近匹配方法进行匹配。参考丁宁和丁华(2020)[32]的研究,以总资产自然对数代表企业规模,以资产负债率代表企业负债水平,以托宾Q值代表企业价值,以固定资产占总资产比重代表企业结构,以这4个指标作为匹配变量。变量说明如表2所示。

表2 变量设定
续 表
3 实证过程与结果分析
3.1 样本选取与描述性统计
本文选取样本为我国大陆A股上市公司,所有样本数据均来自于CSAMR数据库,并按照以下原则对企业数据进行初步筛选(王雄元和谭建华,2019)[33]:(1) 剔除 ST及 ST*类上市公司;(2)剔除相关数据缺失企业;(3)剔除B股企业;(4)剔除金融类上市公司。
经过处理后,最终得到3494家样本上市公司,其中,供应链创新与应用试点企业77家,非供应链创新与应用试点企业3417家,样本共包括2015~2019年5年间共15278个样本,并在99%和1%分位处进行了缩尾(Winzorize)处理,并通过Stata15.0对主要变量进行了描述性统计,统计结果如表3所示。
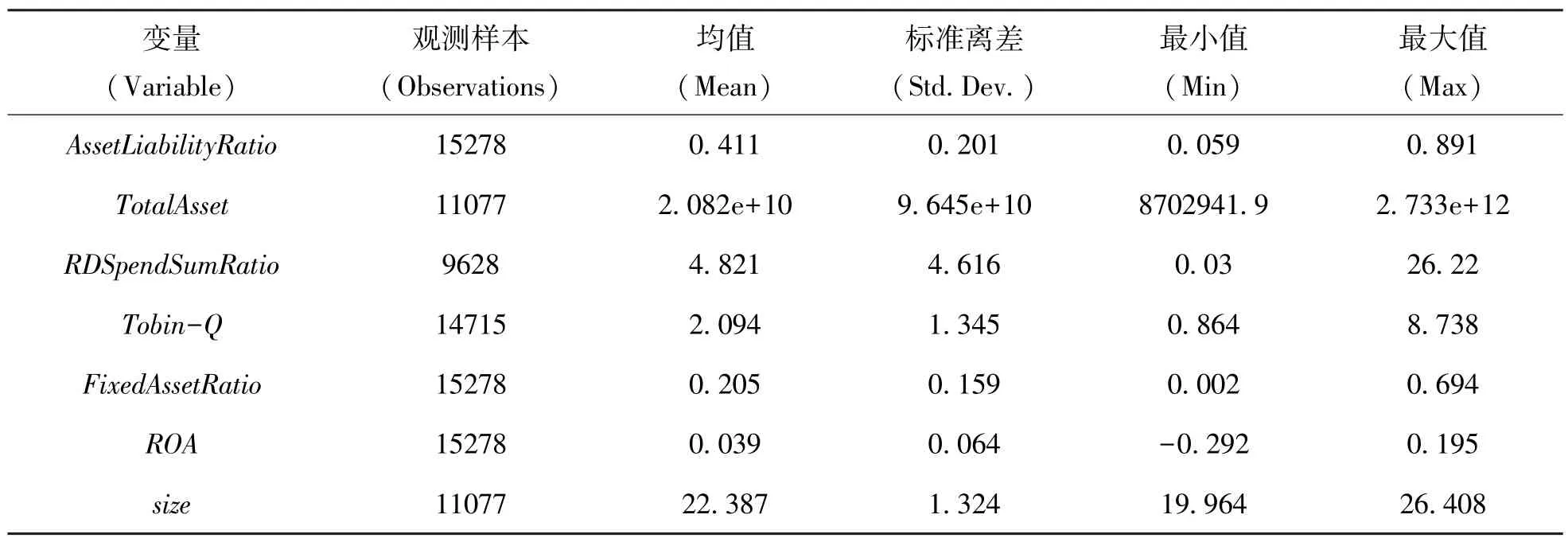
表3 主要变量的描述性统计结果
3.2 倾向得分匹配结果分析
在对样本进行相关处理后,本文对处理后的样本面板数据运用Stata15.0进行倾向得分匹配,采用的具体匹配方法是最邻近匹配,其中,匹配变量包括总资产自然对数、资产负债率、托宾Q值和固定资产比率。匹配过程中删除没有进行匹配的对照组,最终得到总样本数为10680个,具体如表4所示。
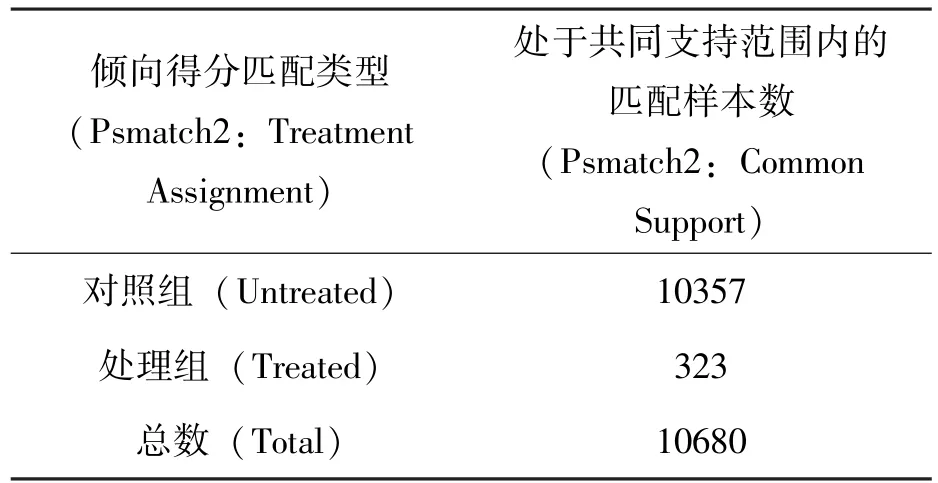
表4 倾向得分匹配样本结果
同时,由于倾向得分匹配依据样本数据各匹配变量进行匹配,因此匹配后处理组和对照组均值差异相比于匹配前大幅降低。对此幅度降低的程度需要进行平衡性检验,以保证在样本匹配后,对照组和实验组的各匹配变量间没有显著差异,本文针对样本的平衡性检验结果如表5所示,同时各匹配变量的标准化偏差如图1所示,可以直观地看出匹配前后各相关变量的标准差差异显著减小且处于共同支持范围以内,因而从平衡性检验的结果可以得知当前进行匹配之后的样本满足进行双重差分研究的共同趋势假设前提,因此将用DID方法进行接下来的政策评价研究。
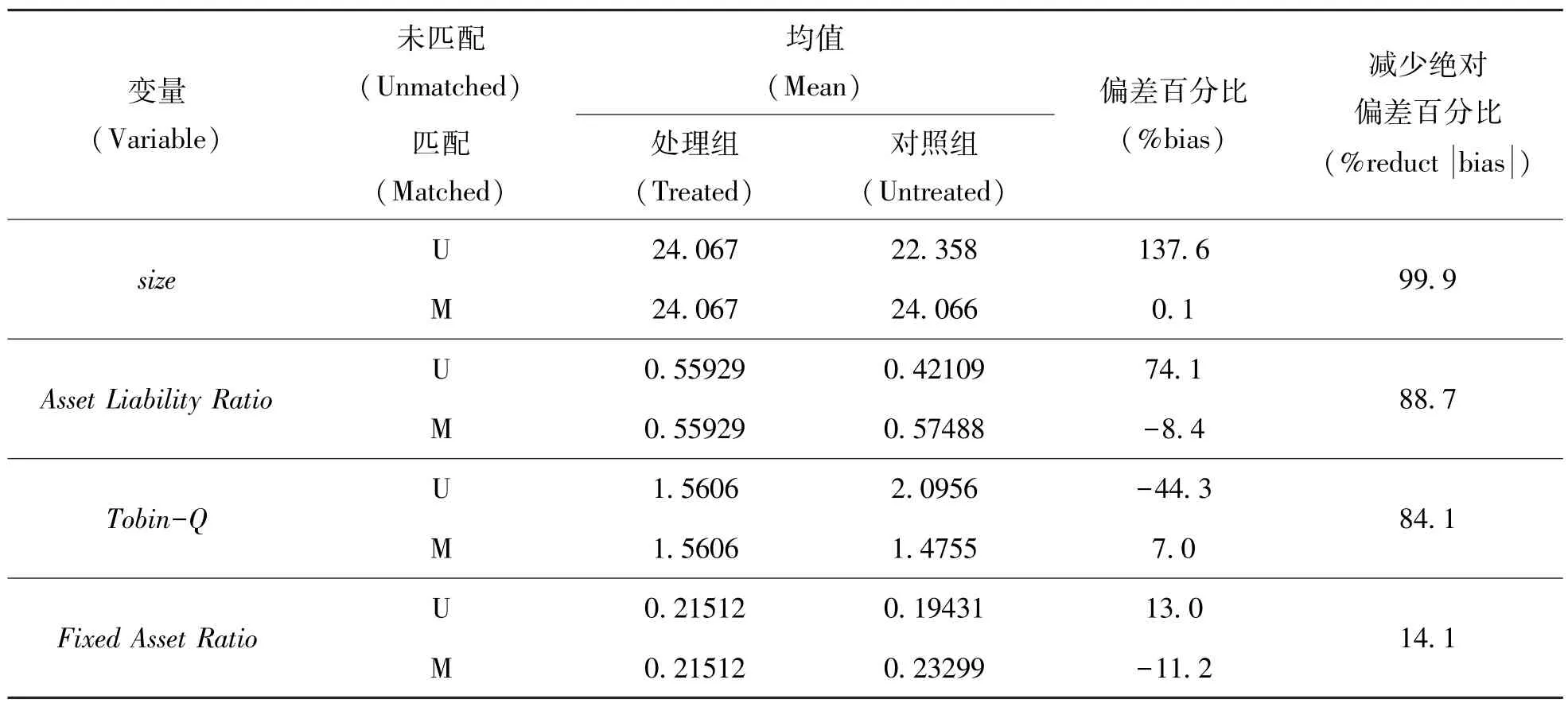
表5 倾向得分匹配平衡性检验结果
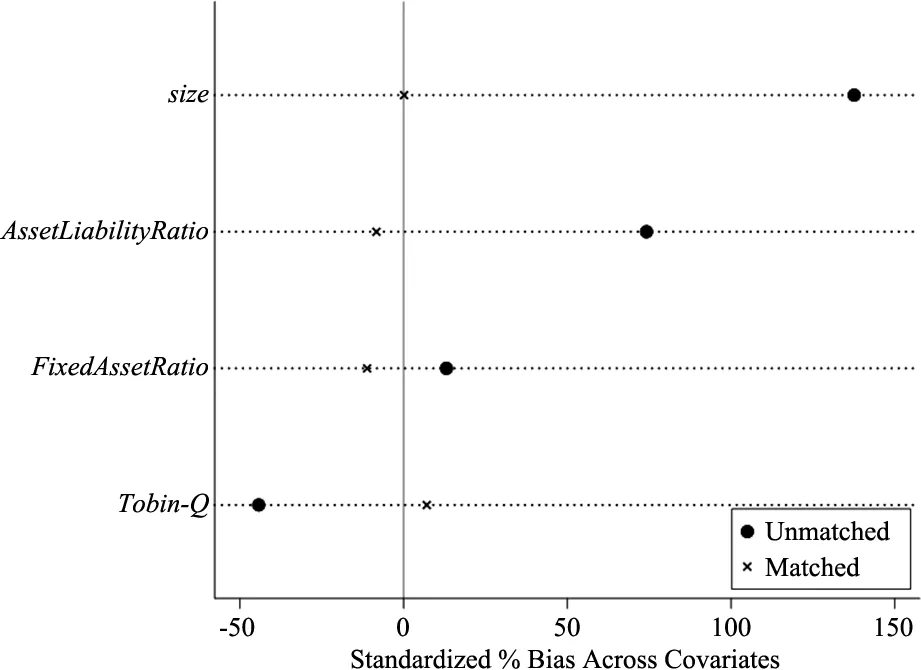
图1 各匹配变量的标准化偏差图示
3.3 PSM-DID模型运行结果分析与讨论
双重差分结果如表6所示。运用Stata15.0对经匹配后满足进行双重差分方法研究前提条件的样本进行研究,考察实施 “供应链创新与应用试点”政策对企业经营行为中经营绩效的影响,具体体现为PSM-DID模型中交互项did对企业ROA指标的影响方向和影响程度。根据结果也可以分析得知,在进行该政策对ROA的影响评价时,必须对企业规模、企业资产等匹配变量加以控制和匹配。表6为最终的模型运行结果。
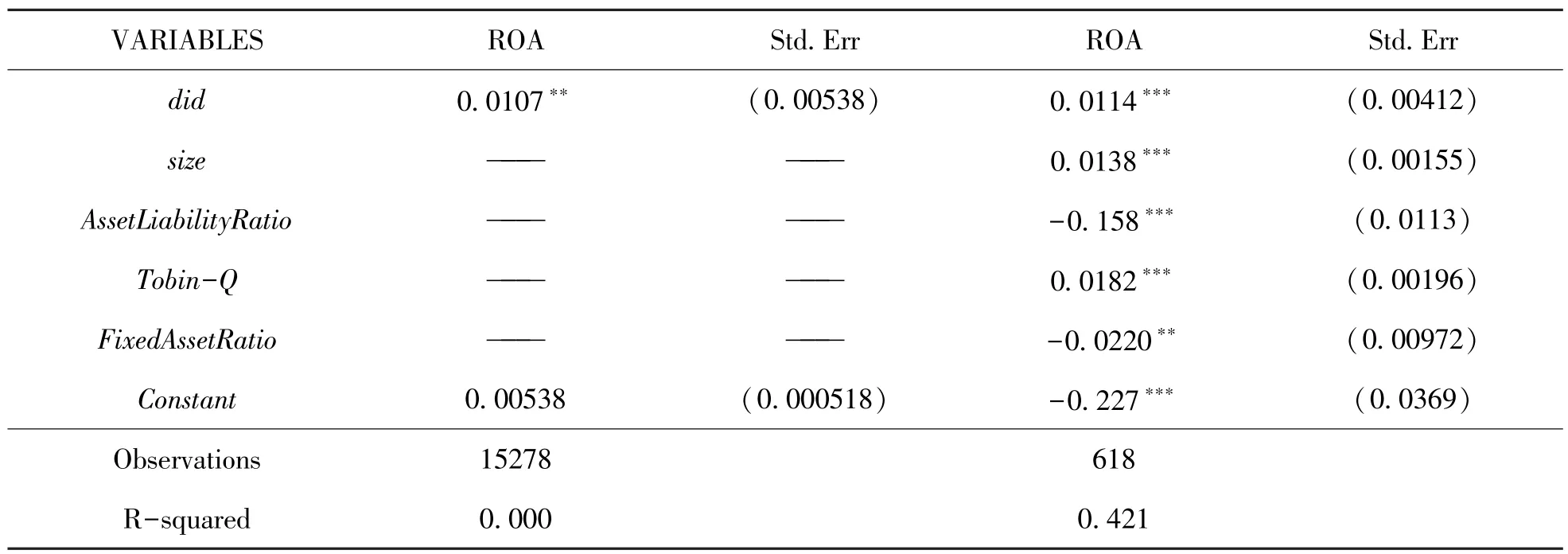
表6 供应链创新与应用试点对试点企业经营绩效的双重差分回归分析
(1)假设1的主要结论与讨论
从表6结果中可以看到,解释变量,即交互项did,对ROA的双重差分回归系数为正(0.0114),并在1%的水平上显著。因此,本文认为我国商务部等八部门于2018年开始实施的供应链创新与应用试点政策,对试点企业的经营绩效ROA有着显著的正向促进作用。该结果说明,我国开展该试点政策实施效果较好,政策成功促进试点范围内企业的经营绩效增加,增强了企业的盈利能力,因此,本文提出的假设1成立。
实际上,假设1的成立本身也来自于试点政策相关内容的推动。根据该试点政策的内容,政策可能在5个方面上促进了企业盈利能力的提升。①政策推动试点企业信息化升级以及技术的应用能够使得企业各部门数据对接加快,效率提升,在相同时间内能够完成更多的经营活动,加快供应链运作效率;②政策推动试点企业与高校和研究机构等开展密切合作,进行供应链相关领域技术的创新及研发,加快供应链新技术的推广与应用,加速试点企业所在供应链的智能化、数字化等,这也将有效提升供应链和企业的盈利效率;③政策推动试点企业建立供应链平台。 “供应链创新与应用试点”政策所选取的试点企业大多是国内知名企业,在各自领域占据较大市场份额,该政策试点过程中推动试点企业建立相关平台并发挥平台资源集聚、供需对接等功能,有效完善了各领域的现代供应链体系,其中的资源共享等福利可能使试点企业大大受益;④政策支持试点企业开拓和发展供应链金融业务,支持企业与商业银行等合作,稳固并且优化了企业经营中非常重要的资金流,同时拓展了试点企业的盈利业务领域,能够有效提升企业资产盈利能力;⑤政策要求全环节、全链条、全过程实现试点企业供应链绿色化发展,资源消耗降低一定程度上对企业经营绩效也有着正向促进的影响。
(2)其他假设的主要结论与讨论
从结果中同样可以看到,企业规模、企业的资产负债率、托宾Q值和企业固定资产投资比率都对ROA有显著关系,这说明H2、H3、H4、H5都是成立的。其中企业规模和托宾Q值与ROA有正向相关关系,资产负债率和固定资产投资比率对ROA有负向相关关系。数据验证的结果也恰好验证了将该4种变量作为倾向得分匹配变量的必要性。同时,该假设结果也可以得到合理的解释:企业规模越大,说明企业整合资源的能力更强,并且拥有一些技术,因而盈利能力更强;托宾Q值衡量了企业价值,价值越高,一定程度上企业盈利能力越高;企业资产负债率越高,则表明其收入低于成本,其盈利能力很可能较差,导致ROA也呈现负向效应;固定资产投资比率高则其现金持有水平较高,根据以往研究,有利于公司的投资盈利活动,此外,固定资产占比高,其折旧额也会高,成本提高,同时资产周转率会降低,影响经营活动效率,因此固定资产投资比率与ROA存在负向关系。
4 结论与启示
本文通过检索CSAMR数据库,获得我国2015~2019年间的3494家样本上市公司的面板数据,构建PSM-DID模型,实证检验了我国商务部等八部门于2018年开始实施的 “供应链创新与应用试点”政策对试点企业经营绩效ROA的影响,得到以下主要结论:(1)实施 “供应链创新与应用试点”政策,对试点企业的经营绩效ROA有着显著的正向促进影响,表明我国该政策实施效果良好;(2)企业规模、企业的资产负债率、托宾Q值和企业固定资产投资比率都对ROA有显著相关关系。其中企业规模和托宾Q值与ROA有显著正向相关关系,资产负债率和固定资产投资比率与ROA有显著负向相关关系。这也侧面表明了企业可以通过扩大企业规模、改善公司投资结构、减少负债、增强高附加值创造能力等方式提升自身的盈利能力。
根据实施 “供应链创新与应用试点”政策对试点企业的经营绩效有着显著的正向促进影响这一主要结论,结合该政策内容,本文能够得到一定的政策含义:(1)推动试点企业信息化升级以及技术的应用,推动试点企业与高校和研究机构等开展密切合作,推动试点企业建立供应链平台,支持试点企业开拓和发展供应链金融业务,推动试点企业供应链绿色化发展等具体政策举措能够在促进智慧供应链创新与应用的同时,有效提升企业的经营绩效和盈利能力,激发市场活力,因此,类似的政策举措可以在未来供应链相关政策制定中继续采用,甚至加大落实力度;(2)本文通过实证分析证明了试点类政策具有较好的实施效果,因此未来促进供应链发展相关政策的制定可以从试点类政策开始,以点带面,共同促进供应链体系向更智能、更可视、更协同、更绿色、更完善的方向发展。
本文仍存在一些研究的局限性,具体体现在研究过程中定量研究的部分重点只关注了政策实施对企业的影响程度,没有利用数据定量研究细致研究政策具体的作用机制。另外由于数据采集的困难性,没有能够获取2020年的数据进行研究,会在一定程度上影响研究结果的精度。在后续研究中,可以选取合适的定量研究方法以深入探究政策对企业影响的具体作用机制,这对于供应链政策制定将有着重要的参考价值。
