基于分布式优化思想的配电网用电负荷多层协同预测方法
2022-01-05李知艺赵荣祥
谭 嘉, 李知艺, 杨 欢, 赵荣祥, 鞠 平, 2
(1. 浙江大学 电气工程学院,杭州 310007;2. 河海大学 能源与电气学院,南京 211100)
为加快推进我国“碳达峰、碳中和”的目标进程,构建以新能源为主体的新型电力系统是必由之路.随着新能源装机容量跨越式增长[1],分布式新能源、储能、电动汽车等新元素在配电网层面涌现,丰富了负荷内涵,改变了负荷特性[2].相比传统负荷,集成了这些新元素的配电网负荷具有更大的波动性和随机性,这将为配电网功率实时平衡带来巨大的挑战.
用电负荷预测(不包含网损)是保障电网安全和经济运行的基本前提之一[3].智能电表、传感器等设备的广泛使用使得配电网积累了海量的、来源多样的历史负荷数据,为数据驱动的负荷预测技术奠定了必要的数据基础[4].目前,负荷预测的方法主要有数学统计方法和机器学习方法[5].数学统计方法主要包括回归分析法[6]、卡尔曼滤波法[7]、时间序列分析法[8]等.这类方法主要采用线性分析的思路,因此在处理负荷与其他因素(比如天气)非线性关系时具有一定的局限性,预测效果一般.从20世纪80年代起,支持向量机[9]、人工神经网络[10]等机器学习方法取得了长足发展,但这些方法在数据样本较多时普遍存在无法收敛的问题[11].近年来,以长短期记忆(Long Short-Term Memory, LSTM)神经网络为代表的深度学习算法解决了时间序列的长期依赖问题,在负荷预测应用上取得了不错的效果.除了研究传统的单一对象负荷预测以外,部分学者同样致力于研究如何提高包含多个对象的负荷预测准确度[12-16].尤其在不同电压层级的待预测对象具有层级化结构的情形下.例如,220 kV高压输电变电站采集负荷与110 kV次级输电变电站采集负荷.针对层级化负荷结构,通常需要在不同层级分别进行负荷预测,从而形成完整的多层负荷预测结果.然而,该研究面临的主要挑战是如何保证产生的预测结果既在数学上满足单负荷预测准确度,又在物理上符合不同层级负荷之间的关联规律.具体来说,呈现层级化结构的上层负荷与下层负荷具有聚合一致性,即下层所有相关节点的负荷预测值之和应等于上层节点的负荷预测值,这样才能保证电力调控、负荷控制等决策的实现效果.而由于各层负荷功率在峰值大小、测量精度等方面存在差异,现阶段各层独立预测的结果难以达到聚合一致性.传统的方法(如自下而上和自上而下方法)由于忽略了负荷预测偏差随层级结构的叠加性,难以协同提升各层级负荷的预测准确度.文献[17]将跨层级负荷预测建模为最优广义最小二乘法回归问题,然后通过梯度下降法求解,以改善底层负荷的预测结果,进而自下而上按层级结构累加汇总得到上层的负荷预测.文献[18]采用机器学习中的极端梯度提升机(XGBoost)和随机森林算法先对所有层级负荷分别进行预测,然后建立新的机器学习模型,将先前得到的底层和上层预测结果作为输入,并把修正后的底层负荷预测结果作为输出.
理论上,多层负荷协同预测可以看作一个以各层负荷预测总误差最小为目标,以聚合一致性为约束条件的分布式优化问题.以机器学习问题为例,分布式优化算法主要有分布式梯度下降算法、二阶优化算法、邻近梯度算法、坐标下降算法和交替方向乘子算法(Alternating Direction Method of Multipliers,ADMM)等,每种算法各有优劣[19].其中,交替方向乘子法[20]因融合对偶分解和拉格朗日乘子法优点,在解决分布式优化问题时收敛性好,鲁棒性强,受到研究学者的关注.因此,本文选用ADMM算法作为求解多层负荷协同预测问题的算法框架.另外,由于底层负荷数据来源多,同步性差,难以在不同供电区域之间实时共享,即负荷量测和预测数据以孤岛的形式呈现,亟需一种新的框架来打破数据孤岛.联邦学习因为能解决数据孤岛问题而受到研究学者的广泛关注[21],其于2016年由谷歌首次提出,并实现了数万台移动设备在终端数据不共享的情况下通过本地更新模型来完成学习任务[22].由于联邦学习解决的问题与本文面临的供电区域数据孤岛问题相似,故考虑采用联邦学习的架构实现多层负荷协同预测模型的分布式训练.
鉴于上述分析,本文提出一种基于分布式优化思想的配电网负荷多层协同预测算法,旨在通过多个深度学习模型的分布式联邦训练,提升所有层级负荷的整体预测准确度.算例结果表明,与传统方法相比,本文方法在整体预测准确度上有明显的提升.
1 基于ADMM算法的多层负荷协同预测模型
1.1 模型构建方法
配电网多层级负荷预测以2级和3级负荷为主[23].例如,“220 kV高压输电变电站-110 kV次级输电变电站-10 kV中压配变”属于3级负荷预测问题,“220 kV高压输电变电站采集负荷-110 kV次级输电变电站采集负荷”等问题属于2级负荷预测问题.由于3级负荷层级结构具有现实普遍性且兼具理论研究难度,故本文以3级负荷层级结构为例,介绍基于ADMM算法的多层负荷协同预测模型.
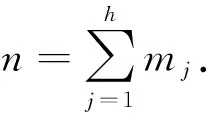

图1 3级负荷层级结构Fig.1 Three-level load hierarchical structure
基于上述分析,搭建n个负荷预测模型,分别对应n个底层供电区域.首先考虑底层区域的预测准确度,则整体的负荷预测目标函数定义为
(1)

将底层供电区域的负荷预测结果逐级聚合,得到除L1以外的全部节点预测值.需注意的是,要使得所有上层节点负荷预测误差最小,仅考虑L2各节点负荷预测约束条件是不够的.例如,当得到的L2节点预测值均偏小,在聚合计算顶层负荷预测结果时,误差的叠加会导致顶层负荷预测误差更大.因此,同时考虑顶层节点的预测约束条件也很有必要.综上,结合负荷实际值,构造h+1个等式约束:
(2)
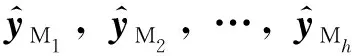
经过分析,本文把一个3级负荷预测问题描述成具有h+1个等式约束的n分块优化问题,然后采用ADMM算法求解.
1.2 分解协调方法
ADMM是一种求解分布式优化问题的算法,其通过分解协调过程,将大的全局问题分解为多个较小的局部子问题,并通过协调子问题的解来得到全局问题的解.在处理复杂的优化问题时,ADMM算法具有较快的收敛速度,能得到更高质量的解,且在解决具有加和约束的优化问题上具有独特优势,适用于求解本文的约束优化问题[25].因此,对于本文1.1节所构建的具有等式约束的n分块优化问题,采用ADMM算法求解.
具体地,对于如式(1)、(2)所示的优化问题,采用ADMM算法引入对偶变量,根据拉格朗日乘子法,得到增广拉格朗日函数:
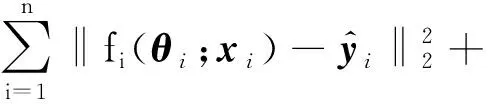
(3)
式中:[θ1θ2…θn]是n个模型的待优化参数;λ为拉格朗日乘子;ψ为求取向量所有元素均值的函数;ρ为惩罚因子.对每个等式约束,都引入一个拉格朗日乘子λj,因此式(3)中λ共含有h+1项.
由于ADMM算法在更新单个模型参数时需固定其余模型,故对于正在更新的模型来说,Lρ(θ,λ)损失函数中其余模型预测的均方误差项可视为常数项.为简化求解过程,当更新某个模型参数时,删去损失函数中与该模型不存在耦合关系的“常数项”,均方误差项只含该模型预测的单个供电区域误差.同理,聚合负荷的误差项也只包含与该模型耦合的上层节点误差.
基于上述分析,得到求解式(3)的ADMM迭代过程如下,按顺序交替执行每个步骤:
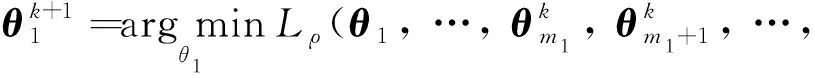
2 LSTM-ADMM多层负荷协同预测模型
2.1 基于联邦学习架构的模型训练流程
考虑到底层负荷的数据孤岛问题,采用联邦学习的架构进行模型的交替训练和通信.
联邦学习目标是在保证数据隐私和不共享数据的情况下完成用户客户端的联合建模.联邦学习根据是否需要第三方服务器分为两种,分别是客户端-服务器架构[26]和对等网络架构[27].前者是让多个客户端利用本地数据训练本地模型,通过中央服务器聚合各个客户端的模型参数并更新全局模型,然后将全局模型参数下发给各个客户端,继续用本地数据更新模型,直到全局模型收敛为止.后者在训练过程中,不需要第三方服务器,客户端之间可以直接通信.为了降低通信开销,选择对等网络架构来对n个底层供电区域进行联邦训练.
多层负荷协同预测模型的联邦学习架构如图2所示.在第k+1次迭代过程中,对n个模型按顺序依次进行更新.当更新第i个模型时,前i-1个模型已完成第k+1次更新,因此输出值固定为第k+1次迭代的值;第i+1~n个模型由于还未进行第k+1次更新,输出值固定为第k次迭代的值.图2中的①、②、③表示更新第i个模型的一系列执行步骤,其中步骤①表示各模型根据输入特征得到输出值,步骤②表示模型i同步接收这n-1个模型的输出值并构造损失函数,步骤③则指采用梯度下降法更新本地模型参数.紧接着采用同样方法更新第i+1,i+2, …,n个模型的参数,完成后进入第k+2次迭代,继续联邦训练,直到迭代次数达到设定值,算法迭代结束.
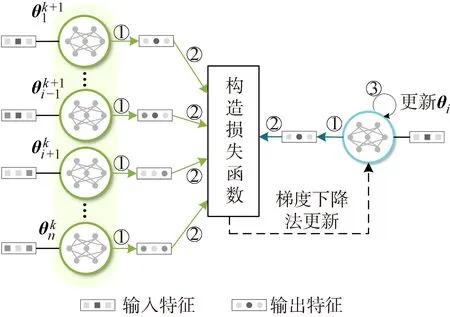
图2 多层负荷协同预测模型的联邦学习架构Fig.2 Federated learning structure of multi-level load collaborative forecasting model
2.2 LSTM网络与输入/输出特征构建
多层负荷预测模型的性能不仅与整体模型架构有关,还与单个供电区域负荷模型的预测性能息息相关.目前,应用于负荷预测研究且取得不错效果的深度学习算法有门控循环网络(GRU)、深度残差网络(ResNet)、卷积神经网络(CNN)、LSTM以及几种算法的组合模型,这些模型都可应用于本文提出的基于ADMM算法的多层负荷协同预测方法中.而且在具体的研究过程中,n个供电区域负荷模型可选取相同模型,也可以是异构模型.为使本文所提方法极具说服力,采用最具代表性的LSTM神经网络作为供电区域负荷预测的基础模型.
LSTM网络是在循环神经网络基础上,通过引入遗忘门、输入门和输出门,并通过遗忘机制和保存机制剔除某些不重要信息,保留有用信息并存入神经元信息中[28].LSTM结构如图3所示,其特殊结构使得它有利于解决长时间序列对历史数据长期依赖的问题,并且可以显著改善训练过程中梯度消失及梯度爆炸问题[29].LSTM内部计算过程如下:

图3 LSTM结构Fig.3 Structure of LSTM
遗忘门:
ft=σ(Whfht-1+Wxfxt+bf)
(4)
输入门:
it=σ(Whiht-1+Wxixt+bi)
(5)
(6)
(7)
输出门:
ot=σ(Whoht-1+Wxoxt+bo)
(8)
ht=ot⊙tanhct
(9)
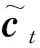
确定LSTM网络的输入和输出特征是使模型获得优异性能的关键.其中输入特征通常是影响负荷变化的属性信息,例如气象因素、季节信息、日期信息(星期)等[30].同时考虑到负荷数据具有周期性,待预测日当天的负荷与前一周的负荷以及14日前同一时刻的负荷有很大相关性.因此本文LSTM网络的输入特征包括历史负荷、温度、月份和星期,且所有的输入特征串联成向量作为模型的单个特征,输出特征即为待预测日当天的实际负荷数据.另外,LSTM网络采用典型结构,即1个输入层、多个隐藏层和1个输出层的结构[31].前一层的输出作为后一层的输入,最后通过全连接层输出得到负荷预测值.
2.3 多层负荷协同预测算法流程
基于分布式优化思想的多层负荷协同预测算法训练步骤如下.
步骤1搭建n个LSTM模型,各模型在本地独立预训练L次.
步骤2将1.2节构造的增广拉格朗日函数作为模型损失函数,采用梯度下降法并结合联邦学习架构,按照ADMM迭代顺序交替训练各模型,并更新拉格朗日乘子.
步骤3通过不断迭代训练各模型参数,最终模型学习到相应供电区域的负荷变化规律以及上下级负荷的聚合一致性.训练结束,保存各模型参数.
步骤4将测试集样本中底层区域的输入特征分别输入训练好的模型中,输出得到L1各区域的负荷预测结果:
L1:f1(θ1;x1),f2(θ2;x2), …,fn(θn;xn)
步骤5将L1负荷预测结果逐级聚合,得到L2与L3全部节点预测结果:
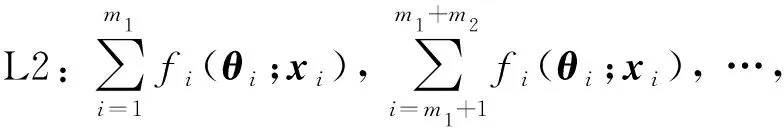
其中第1个训练步骤,各LSTM模型在本地独立预训练L次,是为了使各模型达到预测准确度较高的初始状态,在此基础上进行联邦训练可以减少迭代次数.不仅如此,在准确的初始状态下,基于ADMM算法优化调整各模型能进一步提高整个层级结构的负荷预测准确度.
3 算例分析
3.1 实验数据与平台
本文所用数据来源于2017年全球能源预测竞赛[32],由独立系统运营商新英格兰(ISONE)发布,该数据集包含3层负荷,底层包含8个区域.选择马萨诸塞州(MASS)的东南部(Southeastern MASS, SEMA)、中西部(Western and Central MASS, WCMA)、东北部(Northeastern MASS, NEMA)和佛蒙特州(VT)这4个底层区域的负荷数据等比缩小,构造配电网3级负荷层级结构.其中L2的MASS负荷数据是SEMA、WCMA、NEMA 3个区域负荷数据的总和,L2的VT负荷数据与L1对应的VT区域负荷数据相同,构造的3级负荷层级结构如图4所示.使用数据包括从2013年1月1日至2016年12月31日的负荷数据、干球温度、露点温度和对应的月份与星期,数据分辨率都为1 h.在构造数据集时,对于底层区域,选取待预测日前1,2,3,4,5,6,7,14日的负荷数据以及当天干球温度、露点温度、当天对应的月份、星期作为输入特征(共242个数据),待预测日当天的实际负荷数据作为模型输出特征.对于L2和L3的区域,将待预测日当天的实际负荷数据作为标签.数据预处理时,输入特征、输出特征和标签数据按照区域的不同,分别进行归一化.以上构造的全部输入、输出特征和标签数据共同构成联邦预测模型的数据样本,按照8∶2的比例划分训练集和测试集.本文的模型构建及训练均在Python编程环境下的PyTorch深度学习框架下进行,使用硬件平台为Intel Core i5 CPU和 NVDIA GTX 1660 GPU.

图4 ISONE负荷数据层级结构Fig.4 Hierarchical structure of ISONE load data
3.2 模型超参数设置
为实现多客户端的联邦训练,共搭建4个LSTM模型,每个模型结构和超参数的选择都相同.经过多次试验,最终确定LSTM模型由1个输入层、4个隐藏层和1个输出层构成,其中隐藏层神经元个数都为100.输出层是一个线性的全连接层,将输出数据特征限制为24,即待预测日当天24个时刻的负荷值.
此外,采用Adam优化算法更新模型参数,并将学习率设置为10-3.多次试验表明,模型预训练迭代次数为200时,底层负荷的预测误差已小于3%,达到了较准确的初始状态,因此确定预训练迭代次数为200,联邦训练迭代次数设为500,批处理数为128,拉格朗日乘子λ初始值设为0.1,惩罚因子ρ设为0.1.
3.3 实验评价指标
选取平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)、均方根误差(Root Mean Square Error, RMSE)和平均精度[33](Mean Accuracy, MA)作为预测结果的评价指标:
(10)
(11)
MA=1-MAPE
(12)

3.4 实验结果分析
在对比实验中,将本文方法与各层独立预测以及自下而上的传统方法进行比较,对测试集的数据进行24 h的短期负荷预测,得到MAPE、RMSE、MA这3种指标的实验结果分别如表1~3所示.各层独立预测方法分别对每个区域负荷采用单个LSTM模型进行预测,忽略了上下级负荷聚合一致性的约束,该方法作为实验的基础对照方案.自下而上的传统方法用LSTM模型得到底层区域的负荷预测,再按层级结构累加汇总成上层的负荷预测,以下简称传统方法.同时,为了体现本文方法选取LSTM作为基础模型的优越性,将LSTM替换为人工神经网络(ANN)和线性回归方法,对比3种模型在本文方法下的预测效果.表1~3中,将各列指标最优的数据加粗,以突出预测性能最佳的方法.另外,表中分别用“√”、“×”表示是否考虑聚合一致性.从表中可以看出,结合LSTM的本文方法获得的负荷预测结果不仅满足了上下级负荷聚合一致性的约束条件,而且显著提高了预测精度.
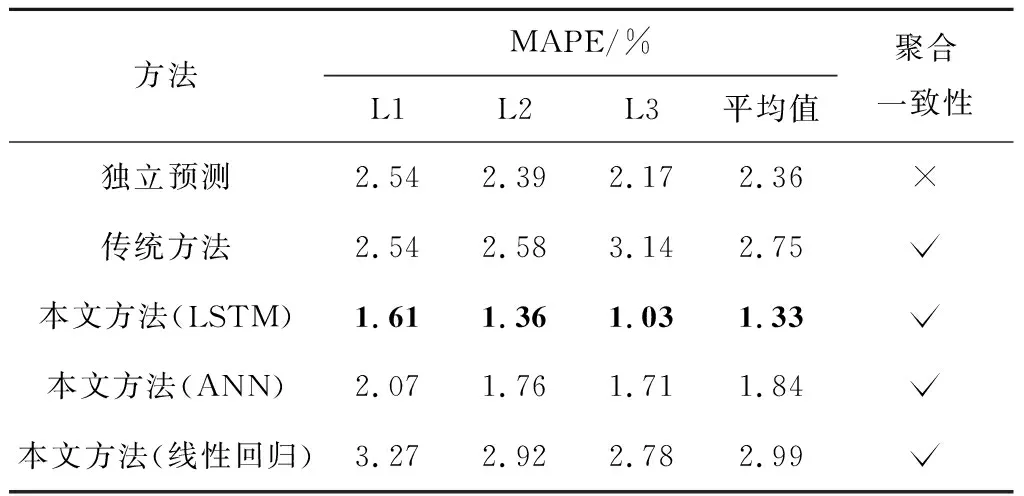
表1 不同方法的负荷预测MAPE比较
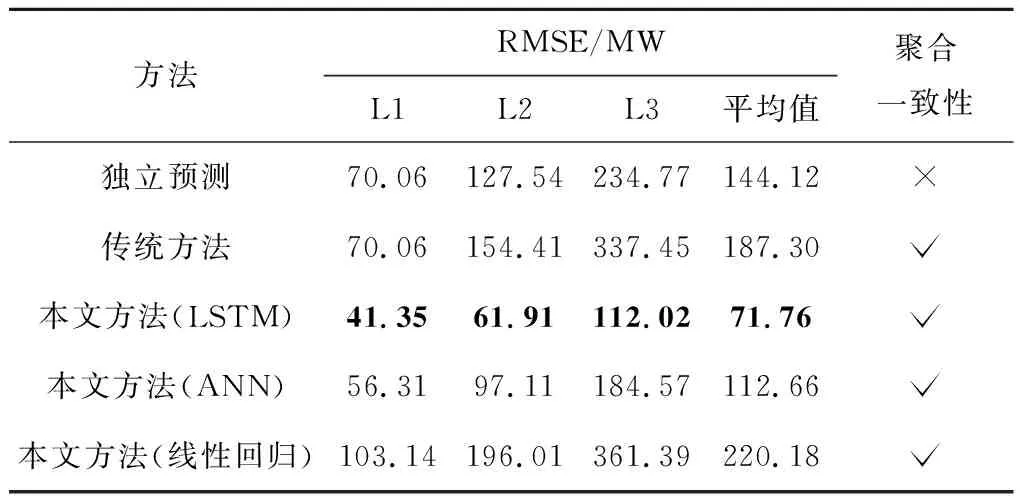
表2 不同方法的负荷预测RMSE比较
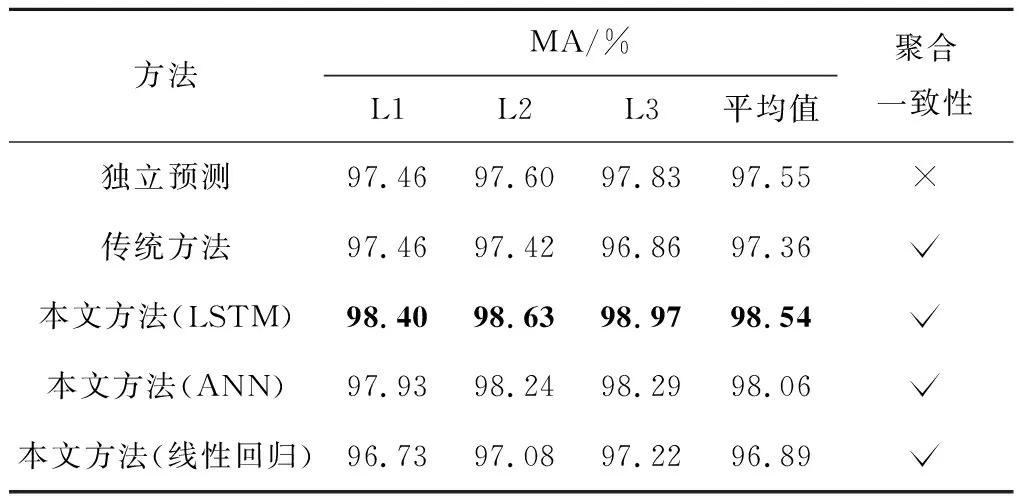
表3 不同方法的负荷预测MA比较
具体来说,首先对比均采用LSTM的独立预测方法、传统方法以及本文方法.与传统方法相比,本文方法对每层负荷预测的误差(MAPE,RMSE)都更小、平均精度(MA)都更高.随着层级的增加,MAPE逐层递减,L3的MAPE低至1.03%,是采用传统方法获得的同一层级MAPE的1/3.对比均方根误差,本文方法获得的RMSE在绝对数值上显著小于传统方法,前者的RMSE平均值是后者平均值的0.38,可见本文方法预测效果显著突出.对比两种方法在整个层级结构的平均精度,本文方法的MA高达98.54%,同样优于传统方法.将本文方法与独立预测方法进行对比,不难发现,本文方法获得的预测结果不仅满足上下级负荷的聚合一致性,在预测精度上更是优于独立预测方法.这主要得益于ADMM算法在模型联邦训练过程中融入了难以显式建模的区域负荷间的相关性以及负荷的聚合一致性,在模型交替训练过程中不断修正原始负荷预测数据,因而得到精准的负荷预测结果.综上可以说明,本文的ADMM算法在预测效果上全面优于各层独立预测方法和传统方法,可作为电网统一各个层级的负荷预测结果的有效方法之一.此外,对比LSTM、ANN和线性回归方法,不难发现,在本文方法的框架下,采用LSTM基础模型获得了最高的预测精度.这说明本文方法的预测效果依赖于所选取的基础模型,而LSTM作为深度学习算法的代表性模型,相比机器学习方法和数学统计方法体现出了明显的优势.
为验证结合LSTM的本文方法所训练的模型已达到稳定,绘制训练过程中平均绝对百分比误差随迭代次数的变化曲线,如图5所示.图中分别展示了3个层级的MAPE,其中L1、L2、L3分别选取SEMA、MASS和ISONE数据作为代表.可以看出,当迭代次数达到500次时,各层的MAPE已趋于最小值并在最小值附近轻微振荡,说明模型已达到收敛.
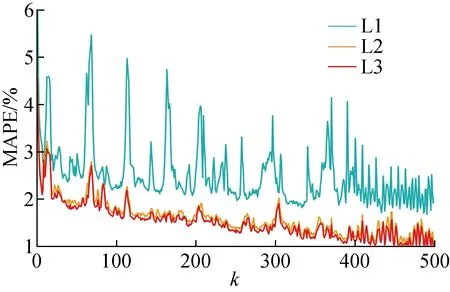
图5 MAPE变化曲线Fig.5 Variation curves of MAPE
另外,绘制5种方法的负荷预测曲线,如图6所示,预测数据选取测试集中连续的5天,数据分辨率为1 h,图中L为负荷.可以看出,结合LSTM的本文方法得到的负荷预测曲线误差最小,对于每一层级的数据都最好地拟合了实际负荷的变化曲线.而结合线性回归的本文方法预测误差最明显,这说明数学统计方法在预测效果上已逐渐被机器学习和深度学习方法所超越.当仅关注独立预测方法、传统方法和本文方法(LSTM)时,对于L2和L3的数据,传统方法的误差最大,这主要是由于随着层级结构的增加,下层负荷预测误差会在上层负荷叠加.对于各层数据,本文方法(LSTM)的负荷预测曲线都比各层独立预测得到的曲线更贴近实际值,这进一步佐证了本文方法预测准确度比独立预测方法还要高,大大提升了各层级负荷预测准确度.
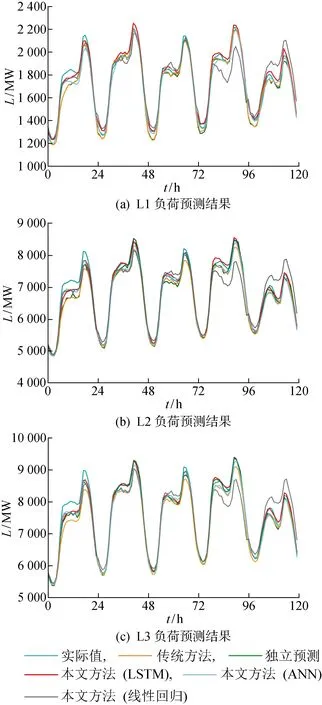
图6 三级负荷层级结构的预测结果Fig.6 Forecast results of three-level load hierarchical structure
4 结语
本文提出了一种融合ADMM与LSTM算法优势的多层负荷协同预测方法,其在满足负荷预测数据自下而上聚合一致性的同时,显著提升了所有层级负荷的整体预测准确度.采用的深度学习算法依靠纯数据驱动,无需任何显式的建模,就能学习负荷的变化规律.同时,在负荷聚合一致性的约束下使用ADMM算法,使得模型的训练过程融入了负荷数据间的相关性以及负荷聚合一致性,进而达到提升负荷预测准确度的目的.算例结果表明,该方法具有突出的预测效果,可以帮助电网更好地协调各个层级的负荷预测结果.然而,本文未考虑节假日等假期因素对负荷预测的影响,在后续研究中,可在本文基础上进一步增加节假日的输入特征,也可以考虑电价、湿度、降水量等其它特征,通过关键影响因素关联分析确定最佳的输入特征集,进一步提高负荷预测准确度.
