基于多维聚类的配变负荷注意力短期预测方法
2022-01-05钟光耀邰能灵黄文焘傅晓飞纪坤华
钟光耀, 邰能灵, 黄文焘, 李 然, 傅晓飞, 纪坤华
(1. 上海交通大学 电子信息与电气工程学院,上海 200240;2. 国网上海电力公司,上海 200122)
随着“双碳”目标的提出,电力作为清洁、高效的二次能源,将在支撑社会经济发展、服务民生用能需求、构建清洁低碳、安全高效能源体系中发挥更加重要的作用[1].电力供需平衡对于保障能源安全意义重大.配电网负荷预测是调度的基础,其预测精度对配电网运行的可靠性、安全性与经济性均有重要影响[2].根据时间尺度划分,配网负荷预测可分为超短期、短期、中期和长期.在空间尺度上,系统负荷预测侧重于一个城市、一个省甚至全国的负荷系统,因此负荷水平通常较高,负荷曲线相对平滑[3].微电网负荷预测侧重于用户,因此负荷水平通常较低,负荷曲线有明显的波峰波谷和周期特性.同时微电网负荷对城市交通等因素较为敏感.随着配网管理的精细化发展,单个配变的短期负荷预测特点与系统级短期预测不同.配电变压器因用户数少,负载功率呈现波动性强、非线性程度高等特点,且单个配变的短时功率受天气和用户偶然用电行为等因素影响.因此配变短期预测准确度较低.此外,随着配网规模的不断增长,负荷预测处理大量数据的效率尤为重要.
负荷短期预测方法主要有统计学方法以及机器学习方法[4].统计学方法包括卡尔曼滤波[5]、线性外推[6]、小波分解法[7]等.统计方法对时序序列的稳定性要求较高,而短期预测数据的波动与突变较为频繁,因此难以有效反映气象、事件等因素的非线性影响.近年来,模糊推理系统[8]、支持向量机[9]以及人工神经网络[10]等机器学习算法逐渐应用于短期负荷预测,有效提升了模型的非线性拟合能力,其预测准确度普遍优于统计方法.随着深度学习方法的发展,循环神经网络以及深度置信网络等均已应用于短期负荷预测.深度学习方法非线性拟合性强,因此有更好的预测精度[11-12].由于循环神经网络易遇到梯度消失等问题,文献[13]采用长短期记忆(Long Short-Term Memory, LSTM)模型进行超短期负荷预测,解决了循环神经网络长期记忆消失的问题,并验证了LSTM的准确性高于梯度提升以及支持向量机算法.文献[14]在LSTM 正向传递基础上增加了反向传递,提出了一种针对新能源系统负荷的双向长短期记忆网络短期预测模型.文献[15]将 LSTM 和XGBoost 结合,利用混合模型进行负荷预测,有效提升了准确度.文献[16]利用卷积神经网络(Convolutional Neural Networks,CNN)提取负荷特征,再利用LSTM进行负荷预测,减小了特征提取的误差,从而提高了预测准确度.然而,若输入的时间序列过长,LSTM仍易出现长期信息丢失的问题,影响负荷预测准确率[17].深度学习中的Attention机制能够自主增强局部信息的权重,增强模型的全局信息处理能力.在LSTM中引入Attention机制能够有效突出序列中关键部分,提高LSTM长期信息记忆力,从而提升负荷预测时间长度以及准确性.
配电网负荷数量大且用电行为特性存在巨大差异.采用统一泛化模型训练预测所有配变时,算法收敛性差、预测准确率低,甚至可能导致无法预测.如果逐个对单台配变进行预测建模,虽不会产生收敛性问题,但计算资源需求大且稳健性差.通过聚类将负荷分为多个群体,针对群体进行针对性建模,能有效提升负荷预测准确度以及效率[18].文献[19-20]、[21-22]分别对负荷序列和日负荷峰谷值进行聚类,有效提升了负荷预测的准确率.文献[23]、[24]分别使用主成分分析法和自编码器对负荷序列进行降维处理,提升了聚类效果.以上方法对负荷进行聚类时,仅利用负荷序列点对点的欧式距离或者部分负荷信息,丧失了负荷序列的时序特性.然而在负荷预测中,负荷的时序特性尤为重要.短期电力负荷主要受到天气因素以及节假日等因素的影响[25].文献[26]通过选取待预测日的影响因素相似日,构建负荷预测模型,取得了较高的预测精度.文献[27]通过聚类挑选合适的样本,提升了节假日的预测准确度.但相似日算法在每次预测时,都需寻找待预测日的相似日进行建模,计算较为繁琐,且预测长度有限.
本文针对大规模配电预测中负荷用电行为以及影响因素多样的问题,提出一种基于多维聚类的配变负荷Attention-LSTM短期预测方法.利用动态归整算法计算了负荷序列的时序相似性,并利用改进的k-means双层聚类方法对负荷进行聚类分析,将所有负荷分为欧式距离接近、时序相似性较高以及影响因素接近的类.再依据影响因素序列相似性对负荷数据集进行分类.针对每一类负荷的每一种影响因素序列类搭建Attention-LSTM网络模型,并进行针对性训练以及预测.经某配网负荷多源数据验证,并与其他预测方法对比,证明本文所提方法准确率提升了2.75%且效率提升了616.8%.
1 负荷聚类预测结构
为了避免大规模配电负荷预测过程中资源消耗过大,对所有配变进行如图1所示的模型构建.

图1 负荷聚类预测模型构建过程Fig.1 Process of load forecasting model construction
具体步骤如下:
步骤1由于电网数据在采集过程中,数据存在重复、缺失以及异常等问题.对配变负荷以及影响因素数据进行数据预处理,去除异常值和重复值以及插入缺失值.
步骤2对每个配变提取日负荷特征值,通过非参数核拟合得到代表配变日负荷特征的典型日负荷序列.以典型日负荷序列作为配变的日负荷特征,能够减少配变聚类的数据量和提升聚类的准确度.
步骤3依据典型日负荷序列对所有配变进行聚类分析,输出共k′类的配变负荷分类结果.通过聚类降低了模型数量,提高了预测效率.
步骤4依据步骤3的配变负荷分类结果,对每一类配变负荷进行影响因素序列分类,输出共k″类的影响因素分类结果.通过影响因素序列分类使每一个分类结果对应的负荷序列变化趋势接近.
步骤5通过步骤3和4,得到k′k″类配变负荷和影响因素序列分类结果.对每一个分类结果构建相应负荷预测模型.
步骤6在配变负荷预测阶段,每个配变选择相应的模型,得到最终负荷预测结果.
2 配变典型日负荷序列及其分类方法
2.1 日负荷非参数核拟合与典型负荷序列提取
若将配变每日负荷序列加入聚类集合中,不仅造成聚类算法复杂度增大、效率降低,还会产生同一配变不同日负荷序列属于不同类的情况,导致配变负荷分类不准确.因此通过加权叠加每日负荷序列得到配变的典型日负荷序列,代表配变日负荷特征,以便对配变进行聚类分析.由于配变容量较小,当用户启动或者关闭大功率电器时,负荷波动较大.因此判定异常数据较为困难,易造成典型日负荷序列计算不准确.故采用非参数核拟合配变负荷日特征指标,以拟合联合概率作为权重,降低异常数据影响.
从全天、峰期、平期、谷期4个角度选取5个特征来反映负荷的日负荷特点.选取指标如表1所示.表中:Pmax、Pmin、Pav分别为每日负荷最大值、最小值、平均值;Pav, peak、Pav, sh、Pav, val分别为峰期、平期、谷期负荷平均值.
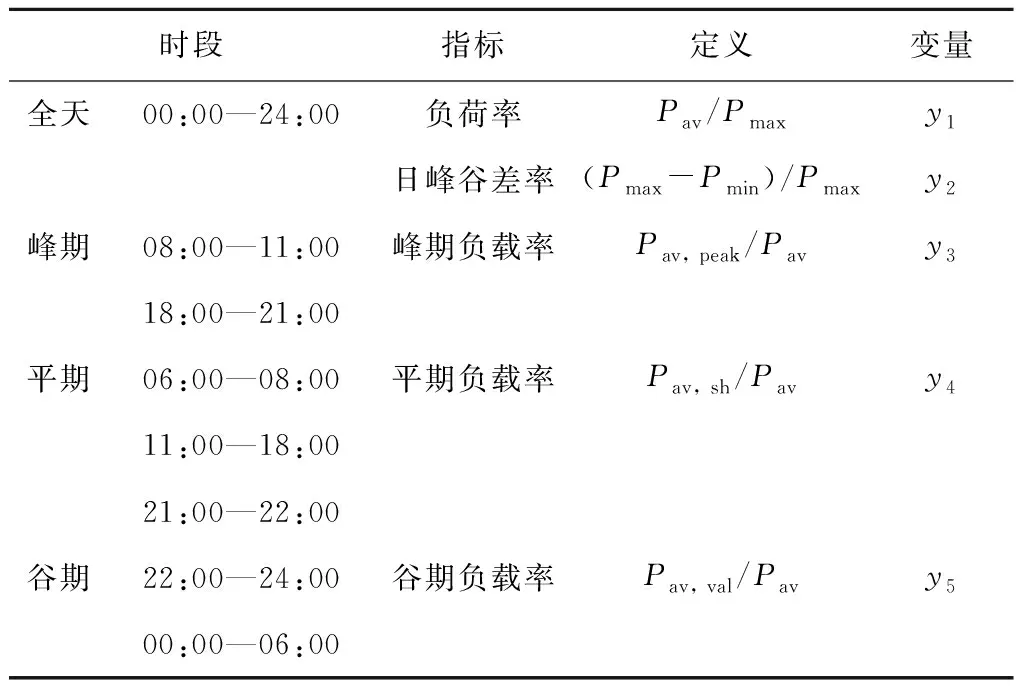
表1 日负荷特征指标Tab.1 Daily load pattern indexes
针对每个配变负荷,首先选取其过去一年的日负荷数据Xi,Xi=[xi,1xi,2…xi,96],i=1, 2, …, 365 (每15 min一个负荷点).再通过日负荷数据计算日负荷特征指标Yi,Yi=[yi,1yi,2yi,3yi,4yi,5].
对表1中的5个特征指标yi分别进行非参数核概率密度拟合,得到每个配变负荷5个特征指标的概率密度分布,拟合公式为
(1)
式中:h为平滑系数;y为日特征指标值;T为样本选取时间长度;K(·)为核函数;σ为数据标准差;N为样本数量.
核函数的选择具有多样性,当平滑系数确定时,核函数选择对于拟合效果有重大影响.本文选取的核函数以及相应曲线如图2所示.在拟合过程中,选取拟合效果最优的核函数.

图2 核函数形式与曲线图Fig.2 Kernel function form and graphs
以特征指标Yi的非参数核拟合联合概率作为日负荷序列的权重值,对一年内日负荷序列加权相加得到负荷的日典型负荷序列:
(2)
式中:fj(Yi)为负荷第j个特征值第i天的拟合概率;Li为第i天配变负荷日负荷序列.
2.2 负荷双层聚类方法
为了实现负荷的准确聚类,首先对典型日负荷序列进行归一化处理,随后按典型日负荷序列相似性以及影响因素相似性进行分类,得到具有最大相似负荷特性配变类.
2.2.1典型日负荷序列相似性 如图3所示,序列a、b、c为3个配变负荷归一化后的日典型负荷序列.由于序列a、c的欧式距离小于与序列b的欧氏距离,传统k-means聚类方法常将序列a、c归为一类.但是序列a、b的形状接近,即负荷变化趋势更加接近,在利用时序信息的预测算法中,更应归属于同一类.因此引入动态时间归整(Dynamic Time Warping,DTW)算法来判断序列的动态相似性.DTW算法将时间序列进行缩短和延伸调整不同时间点之间的对应关系,以对应点之间的距离衡量序列间的动态相似性.经计算,序列a、b的动态归整距离远小于与序列c的动态归整距离.因此DTW算法可以有效评估序列间的动态特性.

图3 负荷曲线图Fig.3 Graph of load curves
两个典型日负荷序列Lc,1、Lc,2,Lc,1=(l1,1,l1,2, …,l1,96),Lc,2=(y1,y2, …,ym′).归整路径为W=(w1,1,w1,2, …,wm,m′),i为序列Lc,1中的坐标,j为序列Lc,2中的坐标,i≤m,j≤m′.归采用动态规划方法求解归整路径距离,动态规划计算公式为
(3)
所求得的wm, m′即是时间序列X、Y的动态归整路径距离.
本文充分考虑同时刻负荷特性以及序列时序特性,将欧式距离与动态归整距离相结合,形成欧式归整距离:
(4)
在k-means聚类中,以欧式归整距离作为相似性计算方法.
2.2.2影响因素相似性 当负荷日典型序列相似而影响因素不同时,无法选取合适的影响因素相似时间序列.故在利用欧式归整距离进行k-means聚类基础上,对同一类负荷根据影响因素进一步分类.本文将每日负荷转换为日平均负荷并分析与各种因素相关性,选取因素包括日平均温度、日平均湿度、日平均风速、日类型和天气类型.其中日平均温度、日平均湿度、日平均风速均经过归一化得到相应序列.日类型主要包括工作日、周末以及节假日.天气类型主要包括晴、多云、阴、小雨、中雨、大雨.阴雨天不方便出行以及除湿需求会增加用电量,导致阴雨天比晴天用电量大.天气以及日类型的标记值如表2所示.当一天存在多种天气时,标记值取为当天所有天气标记值最大值以及最小值的平均值.
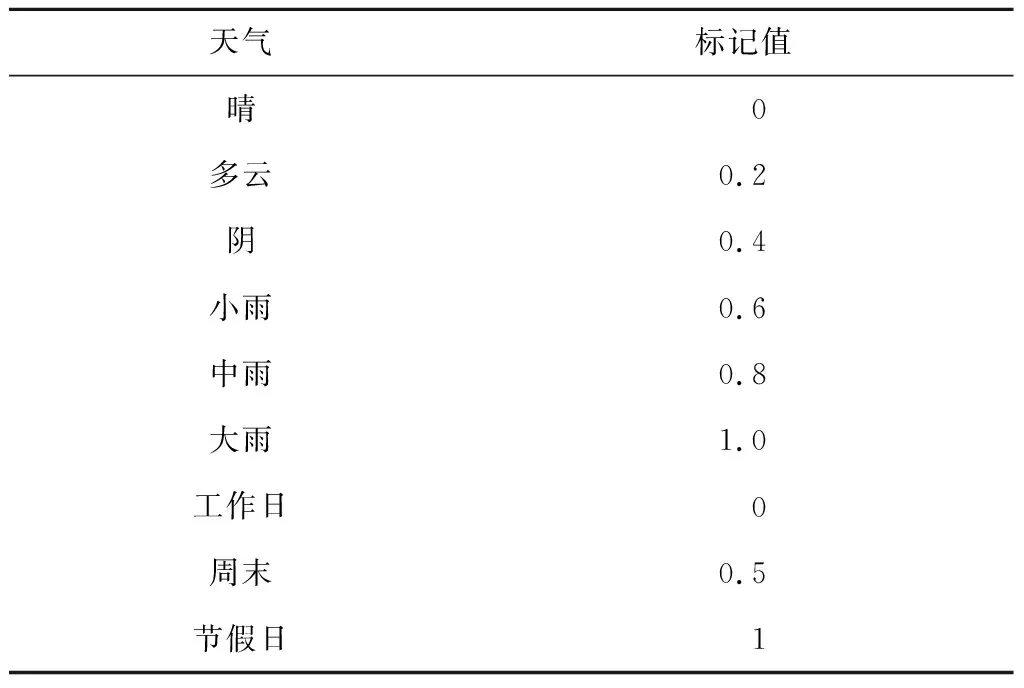
表2 天气以及日类型对应标记值Tab.2 Weather and day type corresponding tag values
通过格兰杰因果检验方法获取负荷和不同因素的影响关系.以日平均负荷与日平均温度为例,首先获取同长度的日平均负荷序列P以及日平均温度序列T.其格兰杰因果检验模型为
(5)
(6)
式中:Pt为t时间的功率值;αu,0为无约束回归模型的常数项;p为变量P的最大滞后期数;αu,i为无约束回归模型滞后的变量P的系数估计值;Pt-i为P的第t-i个滞后项;q为滞后的变量T的最大滞后期数;βu, i为无约束回归模型滞后的变量T的系数估计值;Tt-i为T的第t-i个滞后项;εu,t为无约束回归模型的随机误差项;αr,0为有约束回归模型的常数项;αr,i为有约束回归模型滞后的变量P的系数估计值;εr,t为有约束回归模型的随机误差项.式(5)为无约束回归模型,式(6)为有约束规划模型.
利用无约束和有约束回归模型构造F统计量:
F(q,n-p-q-1)
(7)
式中:RSSr和RSSu分别为有约束和无约束回归模型的残差平方和;n为样本容量.
若F≥Fα(q,n-p-q-1) (α分位点),则认为系数估计值βu,i显著为0,即日平均温度不是引起日平均负荷变化的格兰杰原因,其间不存在联动关系;反之,若F 采用相同的方法求得日平均湿度、日平均风速、日类型和天气类型是否为日平均负荷的影响因素.若影响则标记为1,若不影响则标记为0.可得配变的影响特征向量Zi=[zi,1zi, 2zi, 3zi, 4zi, 5]. 2.2.3双层k-means聚类方法k-means算法存在两个问题,一是需要提前确定初始分类数,二是初始中心分布对最终分类结果存在较大影响.同时将负荷影响因素相差巨大的负荷分在同一类不利于影响因素相似时间序列选取.因此为了得到负荷序列形态以及影响因素相似的配变簇,提出了基于反向修正原理的双层聚类模型. (1) 以欧式归整距离作为相似度的判定标准,通过k-means聚类算法对日典型负荷序列进行聚类,得到K类具有相似时序负荷特性的配变负荷. 选用大卫-博尔丁指标(Davies-Bouldin Index,DBI)作为聚类结果的评判指标,DBI指标(IDBI)基于类内距离与类间距离的比值,计算公式为 (8) (2) 针对同一配变群计算其影响因素特征序列熵值,计算公式为 (9) 式中:Z为配变群内影响特征序列的集合;z为集合Z中的特征序列;p(z)为z序列在Z集合中的占比. 若某一类熵值大于等于阈值,则代表该类配变的影响因素区别较大.不应将这些配变分为同一类.因此,选取其中占比最大的两个特征序列,并将其所对应典型日负荷序列作为两个新类.剩余特征序列分别计算与上述两个特征序列的欧式距离,将对应典型日负荷序列加入特征序列欧式距离较近类的子集.若某一类熵值小于阈值,则认为该类负荷的特征序列接近. (3) 重复步骤(1)、(2)的聚类流程,直至聚类中心大于等于最大聚类中心数Kmax或者聚类结果不再变化.最终得到负荷序列形态以及影响因素相似的配变簇. LSTM擅长处理时序性数据.在对电力负荷数据进行预测时,LSTM可以有效挖掘数据之间的时序信息以及非线性关系.但是针对影响因素突变导致的负荷数据突变,LSTM拟合效果不佳.同时LSTM丧失了数据的周期性特征.若将影响因素作为特征输入,导致网络参数过多,模型收敛困难,准确率的提升有限.为解决上述两个问题,减弱气象因素、日类型因素对短期电力负荷的影响,同时兼顾负荷数据的时序性、周期性、非线性,在第2节的基础上,对同一个类负荷选择影响因素相似时间序列构建数据集. 通过第2节聚类后,每个类中负荷具有相似的影响因素特征向量.选取其中占比最大的特征向量作为该类的特征向量Zc. 再对Zc中分量为1的因素通过相关性分析计算影响的程度.分别计算日平均负荷与日平均温度、日平均湿度、日平均风速、日类型和天气类型的相关系数,得到每个类的相关系数向量ρ=[ρ1ρ2…ρM],M为影响因素特征数量. 选取连续D1时间内的日平均温度、日平均湿度、日平均风速、日类型和天气类型序列.选取时间窗为2D,滑动步长为1,共获得D1-2D+1个2MD的影响因素矩阵: (10) 得到相似性: (11) AP(Affinity Propagation)聚类算法相对于k-means算法,无需同类取平均值作为聚类中心,无需提前指定聚类中心.同时AP聚类算法的误差平方和低于其他聚类算法.因此在进行影响因素相似时间序列选取时,具有一定的优势. 影响因素相似时间序列选取步骤如下: (1) 初始化吸引度矩阵R和归属度矩阵A. (2) 计算的相似性矩阵更新吸引度矩阵R: rt+1(i,k)= (12) 式中:rt+1(i,k)为第t+1轮迭代吸引度矩阵R的i行k列值;S(i,k)为相似度矩阵S的i行k列值;at(i,k)和rt(i,k)分别为归属度矩阵A和吸引度矩阵R的i行k列值. (3) 更新影响归属度矩阵A. at+1(i,k)= (13) (4) 根据衰减系数λ对吸引度矩阵R和归属度矩阵A进行衰减 (14) (5) 若矩阵稳定或者大于最大迭代次数,输出聚类中心,流程结束,得到k″类影响因素相似时间序列分类结果.否则转至(2). 配变短期负荷预测中,历史数据从采集到导入数据库存在滞后性,因此预测长度要求较长.当预测长度过长时,易导致LSTM训练难以收敛、长期信息丢失等问题. 时序负荷数据中存在大量无关信息,每个时刻负荷往往与历史负荷中的几个时刻点相关性较高,例如前几日同时刻负荷.Attention通过自动对历史负荷值进行重要度分配,加强相关性较高时刻的负荷影响,减弱相关性较低时刻的负荷影响.提升了模型长期信息记忆能力,从而提高LSTM负荷预测模型的准确率.Attention-LSTM结构如图4所示. 图4 Attention-LSTM结构Fig.4 Structure of Attention-LSTM 主要包括4层模型,每层描述如下: (1) 输入层:输入经过预处理后的历史负荷数据l1,l2,…,lT. (2) LSTM层:多层LSTM结构网络,对输入的历史负荷数据进行特征提取,得到不同时刻的特征值ht. (3) Attention层:赋予LSTM隐层中各个特征权重αt, 代表不同时刻的负荷值对于预测时刻负荷的重要度.权重的更新公式为 (15) (16) St=f(St-1,yt-1,ct) (17) 式中:g,hj,atj,ct为神经网络中的隐藏参数.当短期负荷预测长度过长时,Attention层能够有效提高历史信息中重要部分的重要度,忽略非重要部分.因此增加了LSTM 的长期记忆能力,提高了负荷预测准确度. (4) 输出层:经过Attention-LSTM结构输出负荷预测结果Y. 配电网计量系统一天共f个采样点.数据集构建方式采用输入-输出对的形式,为考虑负荷的周期性,选取D作为输入长度和预测长度.故每组数据包含作为输入的前fD个点与作为输出的后fD点.总体框架如图5所示. 图5 短期负荷预测流程Fig.5 Forecasting process of short-term load (1) 针对每个典型负荷序列类的每个影响因素相似时间序列集合均构建一个LSTM模型. (2) 根据影响因素相似时间序列的日期构建输入输出集. (3) 选取80%的输入输出集作为训练集,20%作为测试集. (4) 对每个模型进行训练,待模型收敛后,利用测试集进行检验,若满足要求则保存超参数,否则重新训练. (5) 当要预测下一个七天负荷时,首先查找当前配变所属的类.再通过天气预报构建未来的天气因素序列,查找该天气因素序列与各个影响因素相似时间序列类中相似度最高的类.选择相应LSTM模型,载入超参数.将历史fD的负荷值输入模型,得到未来fD的负荷值. 选取某市配网370台公变以及340台专变2019年7月1日至2020年10月1日的负荷数据以及气象数据,负荷数据的采样频率为15 min一次,一天有96个数据,气象数据为一天一个数据点.以2019年7月1日至2020年6月30日的负荷以及气象数据作为训练集,2020年7月1日至2020年10月1日的负荷以及气象数据作为测试集.首先计算每个配变的典型日负荷序列作为配变特征.再对所有典型日负荷序列进行聚类分析,得到负荷序列形态以及影响因素相似的配变簇.然后对每一个配变簇的数据集进行相似时间序列分类.对相应的相似时间序列类搭建Attention-LSTM模型并进行训练,以测试集验证模型的准确率以及效率. 对每个配变的负荷数据进行预处理,去除重复值以及异常值,插入缺失值.提取每日的5个特征值:负荷率、日峰谷差率、峰期负载率、平期负载率、谷期负载率.对5个特征分别利用参数法和非参数法进行概率密度估计,其中参数法为高斯函数,非参数核函数分别为高斯核函数、均匀核函数、叶帕涅奇核函数、指数核函数、三角核函数、余弦核函数.5个特征的分布函数曲线以及实际概率密度分布如图6所示. 图6 负荷日特征拟合结果图Fig.6 Fitting results of load daily feature 从图6中可以看出,非参数核函数的拟合效果优于参数法,其中三角核函数的拟合效果最优.因此选用作为三角核函数进行非参数拟合.通过2.2节的方法得到每个配变的典型日负荷序列. 以欧式归整距离作为相似性判定依据,选取聚类中心数量范围为2~13.对每种聚类中心数分别进行多次k-means聚类,并选取IDBI值最低的聚类结果作为该种聚类中心数的最优聚类结果,结果如表3所示.因此选取最优聚类数k=5. 表3 DBI结果Tab.3 Results of DBI 对于每个类,通过格兰杰因果检验得到每个配变的影响特征序列.计算得到每个类的熵值如表4所示,选取阈值为0.4. 表4 每类熵值结果Tab.4 Entropy results for each type 第二类的信息熵值明显大于其他类的信息熵值,且大于阈值.选取影响因素特征向量占比最大的两类,Z1=[1 1 0 1 1],Z2=[1 1 0 0 1]作为新类.将剩余的配变分入影响特征向量欧式距离较近的一类.以6类负荷分类结果作为k-means初始状态重新聚类,得到新的聚类中心结果如图7所示,图中t′为时刻.每类负荷影响因素特征向量的熵值均小于0.4,故停止聚类.聚类结果为6类,其中类2、3序列的欧式距离及时序特性较为接近,通过影响因素的不同区分成两类. 图7 负荷聚类中心图Fig.7 Center graphs of load cluster 依照第3节的方法对过去一年的多维影响因素序列进行影响因素相似时间序列选取,共得到9种类型.根据相关性分析结果,负荷普遍为温度强驱动型.故仅展示每种聚类结果的温度信息.9条聚类中心曲线主要存在平均值以及动态特征的差异.季节不同,负荷曲线的特性会存在明显的区别.计算每条聚类中心曲线的平均值可以主要分为如图8所示的3类,分别对应冬季、春秋季、夏季的影响因素相似时间序列典型曲线. 图8 影响因素相似时间序列划分结果的温度曲线Fig.8 Temperature curves of division results of similar time series of influencing factors 由于一般负荷具有周期性,因此输入、输出长度均设置为96×7.将七天96×7个历史负荷数据作为LSTM网络的输入层,输出层为下个七天的96×7个负荷值.LSTM网络参数设置为:神经元数为8,学习率为0.002,网络深度为2,优化方式为自适应矩估计优化器.对每类配变的每类影响因素相似时间序列均训练一组超参数.为验证本文方法有效性,设置3个对比组,使用模型均为LSTM.对比组1:LSTM模型仅利用历史负荷数据且每个配变配置一套超参数.对比组2:每个配变配置一套超参数,LSTM在输入历史负荷序列的基础上增加影响因素序列,包括每个时刻的温度、湿度、风速以及每天的天气与日类型.对比组3:利用改进k-means进行负荷分类,但不进行影响因素相似时间序列分类.每种负荷类配置一套超参数. 为了评价模型的预测精度,选用平均绝对百分比误差以及均方根误差作为评判指标,其计算式分别为 (18) (19) 实验环境为i5-9400F处理器、16 GB内存、NVIDIA GeForce GTX 1660显卡,编程语言环境为python3.7,软件架构基于Tensorflow框架.应用本文方法及对比组方法,均训练50轮 epoch.6个负荷类在不同方法下的MAPE、RMSE以及模型50轮epoch所需的训练时间和泛化时间如表5所示,预测结果曲线如图9所示. 表5 预测结果Tab.5 Forecasting results 可见,对比组1、2、3的MAPE分别为5.42%、4.07%、4.88%,RMSE分别为0.166 kW、0.125 kW、0.148 kW.相对不同对比组,本文方法MAPE值分别降低了3.38%、2.03%、2.84%,RMSE分别降低了0.103 kW、0.063 kW以及 0.085 kW.710组配变的平均训练效率相对于对比组1、2分别提升了600%和616%.从图9中可以发现,对比组1、3由于在预测过程中未加入影响因素相关信息,预测负荷曲线与前七日负荷曲线接近,无法准确预测出趋势变化.实验组与对比组2增加了影响因素信息,预测曲线与实际曲线趋势接近,准确预测了负荷趋势变化.两种方法的准确率均高于对比组1和3.对比组2由于模型参数过多,导致预测曲线存在一定的波动.对比组1结果表明配变负荷受到各个因素的影响较大.若仅基于历史负荷数据进行预测,无法预测由于影响因素变化导致的负荷变化,导致预测精度不足.对比组2结果表明将影响因素加入LSTM神经网络能一定程度提升负荷预测准确度.但是由于不同配变影响因素不同而且输入维度的增加容易使网络陷入局部最优,导致准确度的提升有限.对比组3结果表明对负荷根据典型日负荷序列进行聚类,能够提升模型的准确率.但是不进行影响因素相似时间序列划分,即不考虑影响因素,准确性仍然较低. 图9 负荷预测结果图Fig.9 Graphs of load forecasting results 综上所述,本文提出的基于多维聚类的配变负荷Attention-LSTM短期预测方法在效率以及准确度的提升上具有良好的效果. 本文将负荷序列时序特性以及影响因素特性加入配网负荷聚类分析中,得到相似时序特性以及影响因素关联性的配变簇.并依据影响因素特性进行相似时间序列分类.有效解决了配网负荷数量大、特征复杂、预测难的问题,提高了配变负荷预测的准确度以及效率.主要结论如下: (1) 利用非参数核方法有效提升了日负荷特征概率密度估计的准确度,得到更加准确的日典型负荷序列. (2) 对所有日负荷特征序列以欧式归整距离以及影响因素作为相似性判定原则进行双层聚类得到负荷的分类结果.结果表明此方法在负荷序列聚类问题上具有良好的效果. (3) 利用AP聚类算法对多影响因素进行相似时间序列分类,相较于传统的k-means分类、余弦相似度分类,提升了效率与分类准确性. (4) 利用负荷双层聚类以及影响因素AP聚类的结果划分数据集,构建不同的Attention-LSTM网络.选取某市级配网实测负荷数据以及气象等影响因素数据进行对比实验表明,所提方法的负荷预测的准确率提升了2.75%且效率提升了616.8%.能够适用于大规模配变的负荷预测场景,具有较高的应用价值.

3 影响因素相似时间序列聚类

4 Attention-LSTM负荷预测模型
4.1 Attention机制

4.2 负荷预测模型

5 算例分析
5.1 典型日负荷序列计算

5.2 典型日负荷序列双层聚类



5.3 影响因素相似时间序列划分

5.4 基于LSTM的短期负荷预测



6 结论
