一种基于栈式压缩自编码的高光谱图像分类方法
2022-01-05郭棚跃刘振丙
郭棚跃, 刘振丙
(1. 桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004;2.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
高光谱图像中包含丰富的图谱信息,根据这些信息可实现对地面物体的准确分类,因此其被广泛应用于军事目标探测、生态环境监测、城市发展规划及地质勘测等领域[1-2]。其中,对获取的高光谱图像进行准确的分类在该领域的研究中扮演着极为重要的角色。
近年来,为了解决高光谱图像分类问题,学者提出了很多基于光谱信息的分类算法,如K近邻、贝叶斯、最大似然估计及随机森林等[3-5]。虽然这些算法取得了较好的分类效果,但由于高光谱图像存在“同物异谱、同谱异物”现象,且样本标注点较少,导致以上算法存在分类精度较低、模型稳定性差。支持向量机(support vector machine,简称SVM)对高维数据的敏感度较低,可以解决光谱维数过高出现的Hughes现象[6],Wang等[7]将复合核引入支持向量机,提高了其分类性能。文献[8-9]将复合核引入支持向量机,提高了其分类性能。HSI图像中包含光谱信息及丰富的空间信息,许多研究人员将空间信息和光谱信息融合作为特征进行分类并取得了较高的分类精度[10]。Li等[11]通过马尔科夫随机场模型处理空间邻域信息,并结合逻辑回归实现了高光谱图像的分类。Chen等[12]将相邻像素点间空间相干性合并,同时将小邻域内的所有像素点联合表示在特征空间中,有效提高了不同类别数据之间的可分性,但是该方法对所有的领域像素贡献相同,对边缘非均匀区域的贡献较小。Zhang等[13]通过对中心像素周围不同的相邻像素赋予不同权值来提取空间特征,有效解决了联合稀疏模型中领域权重贡献相同的问题。以上方法虽然有很好的分类效果,但需根据特定领域的先验知识进行人工特征提取。
卷积神经网络(convolutional neural network,简称CNN)近年来得到了快速发展,以至于深度学习在语音识别、自然语言处理、图像处理等领域广泛应用[14-16]。Zhao等[17]提出了一种通过局部判别嵌入算法来实现光谱特征提取,使用2-D-CNN提取待分类像素点的邻域空间特征,然后融合空间特征和光谱特征进行分类。刘启超等[18]提出了一种小规模样本下高光谱图像分类的空-谱卷积稠密网络算法。该算法通过光谱维一维卷积和空间维二维卷积的分离卷积结构构成隐层单元,并通过多个隐层单元堆叠构造深度网络。然而CNN是有监督学习模型,需要大量的有标签数据进行训练,以便获得更为鲁棒和更优的分类网络权重参数。相比于卷积神经网络,自编码网络[19](autoencoder,简称AE)属于无监督神经网络模型,在网络训练时无需大量的标记样本,能够很好地重构原始数据特征信息。Chen等[20]首次使用堆叠自编码网络(stack autoencoder,简称SAE)提取高光谱图像的光谱-空间特征,并使用逻辑回归进行分类,取得了很好的分类效果。
AE网络能够很好地重构原始数据的特征信息,但输入数据中的扰动会对输出结果产生影响[21]。压缩自编码(contractive autoencoder,简称CAE)引入了雅克比矩阵,能够很好地重构出原始数据,同时具有良好的抗扰动性[22-23]。为了得到更能代表待分类像素点空间特征的空间信息,提取更加鲁棒的深层特征信息,结合空-谱信息和堆栈压缩自编码(stacked contractive autoencoder,简称SCAE),提出了一种新的高光谱图像分类方法。该方法将邻域空间信息与光谱信息融合,利用栈式压缩自编码提取图像的深层特征,并通过逻辑回归(logistic regression,简称LR)进行地面物体的准确分类。
1 方法
提出的高光谱图像分类算法框架如图1所示,主要分为光谱空间信息融合、特征提取和分类决策3个阶段。首先使用主成分分析(principal component analysis,简称PCA)对高光谱图像进行降维处理,然后提取待分类像素点的邻域空间信息,将其展开成一维向量并与光谱信息拼接融合;使用SCAE网络提取融后的深层特征;将提取到的特征送到LR层进行类别确定。
1.1 空-谱信息融合
高光谱原始数据中包含丰富的光谱信息,同时也包含丰富的空间信息,将高光谱图像的空间信息和光谱信息进行融合能够有效提高分类准确率。在提取领域信息前使用PCA对数据进行降维处理,其降维过程如下:
像素点原始光谱数据大小为
(1)
其中,x1,x2,…,xp为每个像素点的光谱向量值,对于一个有m行n列的高光谱图像,其共有M=m×n个像素点,其所有波段图像的均值为
(2)
x的协方差矩阵为
Cov(>x)=[(>x-E(>x))(>x-E(>x))T]。
(3)
通过式(4)可得协方差矩阵
(4)
对协方差矩阵进行特征值分解,可得
Cx=ADAT,
(5)
其中:D=diag(>λ1,λ2,…,λn),为由特征值构成的对角矩阵;A为协方差矩阵Cx对应的特征向量构成的正交向量,
A=(>a1,a2,…,aN)。
(6)
对原始图像数据进行线性变换:
yi=ATxi,(>i=1,2,…,R),
(7)
yi即为原始图像xi经过PCA变换后的降维图像。特征值λ越大,其越能代表原始图像数据信息,对所得特征值进行由大到小排列,将其前k个特征值对应的特征向量与原始图像相乘,即可得到降至k维的图像数据。
对于经过PCA降维后的图像,选取待分类像素点邻域窗口w×w区域内的光谱信息作为其空间信息,将其展开成一维向量并与待分类点的原始光谱信息拼接融合,得到融合后的空-谱信息。
1.2 SCAE-LR分类网络模型
SCAE网络由多个CAE经过逐层贪婪训练得到,CAE网络由一个数据输入层、一个中间隐藏层和一个重构输出层组成。CAE通过在损失函数中引入雅克比矩阵,保证其具有较强的数据提取能力和抗干扰能力[24],其损失函数表达式为
(8)
为了准确识别出高光谱图像中各像素点的类别,用SCAE-LR模型进行特征提取和分类。该方法分为预训练特征提取和微调分类2个阶段,首先对SCAE网络进行预训练以提取输入数据的深层特征,然后由Softmax分类器对SCAE网络提取深层特性。对提取到的深层特征进行分类处理,在SCAE网络后接入LR层进行微调分类处理,LR层中使用Softmax作为输出层的激活函数,Softmax函数保证了输出层中每个单元的输出和为1,这样就可以将输出视为一组条件概率。假设样本共有i类,输入数据为x,则输入数据属于每类的概率为
(9)
其中,W和b是权重和偏差,根据输出概率值的大小,可确定像元的类别。
2 实验
2.1 数据集
采用Indian Pines和Pavia University数据集进行实验,以验证该方法的有效性。其中Indian Pines数据集中可用样本像素点共10 249个,分为16类,空间分辨率为20 m/pixel,每个像素点包含200个可用光谱波段,光谱波段覆盖范围为0.4~2.5 μm;Pavia University数据集中可用样本像素点共42 776个,分为9类,空间分辨率为1.3 m/pixel,每个像素点包含103个可用光谱波段,光谱波段范围为0.43~0.86 μm。2个数据集的地物分布和类别标签如图2所示。

图2 2个数据集的地物分布图
2.2 SCAE-LR模型压缩系数的确定
为了确定SCAE-LR模型中λ的值,实验中随机选取不同比例的标记样本数据作为训练集,训练样本比例值从0.1到0.5依次递增,步长为0.1。实验结果如图3所示,其中Ratio为训练样本所占总标记样本数的比值。从图3可看出,在λ取值为0.000 3时,SCAE-LR模型在2个数据集上不同比例训练集下的OA值最高。因此,实验中SCAE-LR模型的压缩系数λ设置为0.000 3。

图3 SCAE-LR模型在不同比例训练集和不同λ下的OA
2.3 模型建立
SCAE-LR模型采用Python作为编码语言,通过Pytorch深度学习框架构建网络。实验平台:Windows 10、Nvidia Tesla P100显卡。以OA、AA和kappa对模型性能进行评估,高光谱图像准确分类流程如下。
1)数据处理:首先采用PCA将高维的高光谱图像数据降至5维,筛选出代表样本特性的光谱波段,将其展开成一维向量并与光谱信息进行拼接融合。
2)预训练:利用SCAE网络对经过预处理后的数据进行处理,并将样本的深层特征送入Softmax分类器中进行类别的确定。预训练阶段迭代1 000次,微调阶段迭代500次,学习率均设置为0.01,预训练和微调阶段都用随机梯度下降法(stochastic gradient descent,简称SGD)作为优化算法。
3)测试:利用训练好的SCAE-LR模型对测试集的类别进行确定,以实现高光谱图像的准确分类。
4)对比:将LSVM、PSVM、RBF-SVM和SDAE-LR作为对比方法,其中SDAE模型结构在2个数据集中的结构分别为100-100-100-16和60-60-60-9,激活函数为ReLU,预训练迭代次数为1 000次,学习率为0.01,输出层采用Softmax作为激活函数。
3 结果与讨论
实验中使用交叉验证,每次从总体样本中随机抽取一定比例的数据作为训练集,剩余数据作为测试集,每组实验进行10次。实验将SCAE-LR、LSVM、PSVM、RBF-SVM和SDAE-LR模型各运行10次的AA、OA和kappa均值作为各模型最终性能参考值。
3.1 利用光谱信息评估分类模型
高光谱图像包含光谱信息和空间信息,本节仅采用高光谱图像的光谱信息进行实验,以验证SCAE-LR的有效性。训练集数据比例从0.1到0.5依次递增,步长为0.1。在2个数据集上,各模型的OA如图4所示。从4图可看出,随着训练样本所占比例的增加,各模型在2个数据集的OA均逐步增加,SCAE-LR网络的精度明显高于其他分类模型。SCAE-LR与SDAE-LR同属于无监督训练模型,SCAE-LR网络中引入了雅克比矩阵来提高自编码网络的抗干扰能力,在训练集相同的情况下,SCAE-LR模型能够获得更高的分类精度。
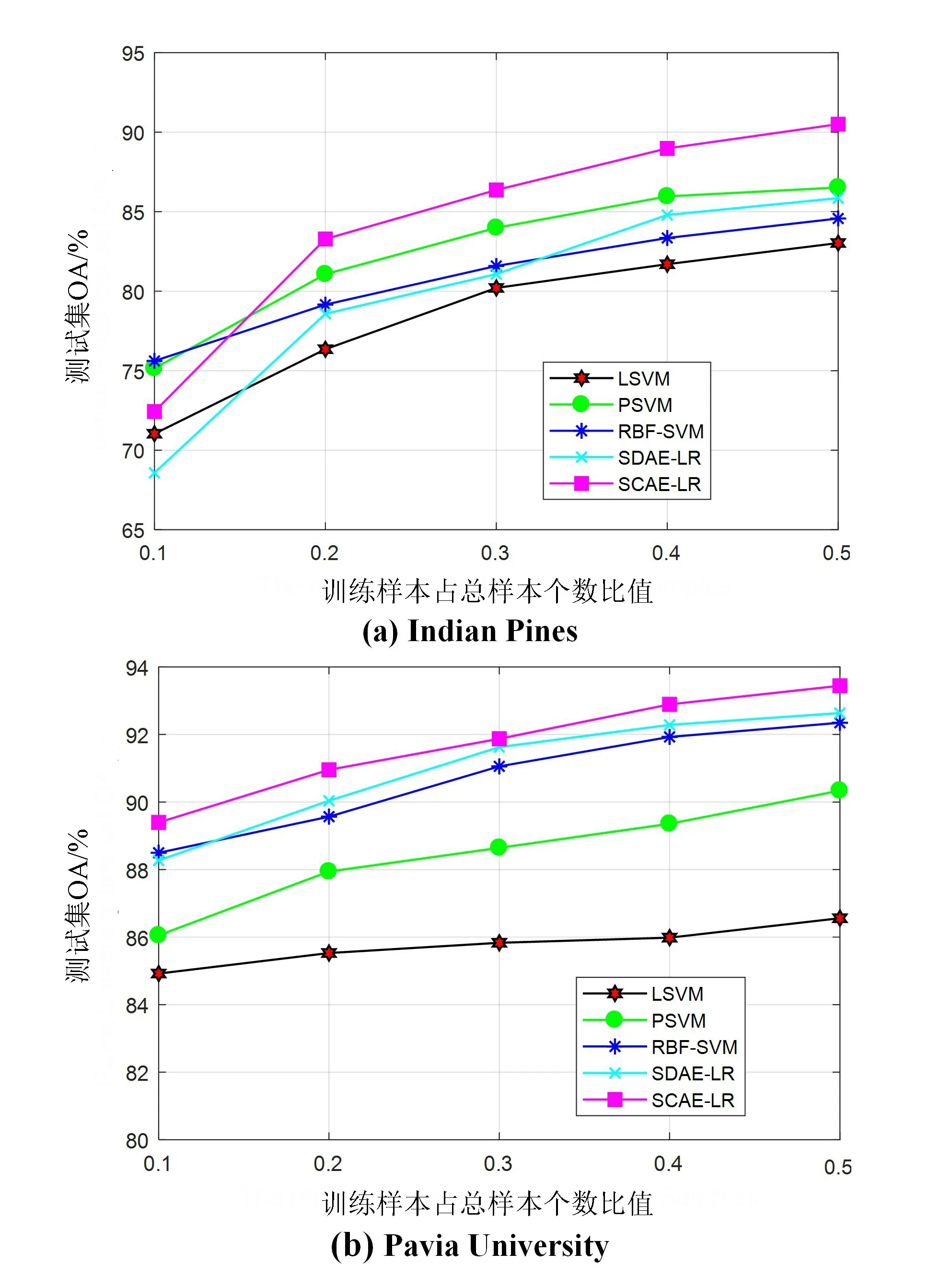
图4 不同模型在2个数据上使用光谱信息作为特征的OA
3.2 与其他分类方法对比分析
为了验证SCAE-LR结合空-谱信息方法的有效性,实验随机选取20%的样本数据作为训练集,表1和表2给出了所提方法及对比方法在2个数据集上各类别的分类精度以及在整个数据集上的OA、AA和kappa系数。
从表1可看出,在Indian Pines上,所提方法在3种评价指标上都取得了最优值,对比仅使用光谱信息的LSVM分类模型,空-谱信息特征能够取得更好的分类效果,其中所提方法在整体分类精度上比LSVM分类模型提高了约9.2%。对比SDAE-LR分类模型,所提方法能够通过损失函数中的雅克比矩阵来保证输入噪声的抗扰动性,以提取更加鲁棒性的特征,从而获得更好的分类效果。对比PSVM和RBF-SVM分类模型,SCAE-LR模型属于无监督深度神经网络模型,能够提取到更深层、更为鲁棒性的特征。Indian Pines数据集在各模型得到的分类结果如图5所示。对于Pavia University数据,随机从每类数据中选取20%的样本作为训练集,由表2可见,所提方法的OA、AA、kappa均高于对比方法。与其他方法相比,所提方法分别高于LSVM、PSVM、RBF-SVM、SDAE-LR约5.6%、8.5%、1.8%、1.3%。

表1 各方法在Indian Pines数据集上的分类性能

表2 各模型在Pavia University数据集上的分类性能

图5 各模型在Indian Pines数据集上的分类结果
4 结束语
提出了一种基于栈式压缩自编码的高光谱图像分类方法。首先对原始高光谱图像进行降维处理,提取领域空间信息与光谱信息并进行拼接融合,然后利用SCAE网络提取待分类像素点的深层特征,进而利用LR进行类别确定。为了对SCAE-LR模型的分类性能进行评估,将该方法与LSVM、 PSVM、RBF-SVM和SDAE-LR方法在2个数据集上进行了对比分析。实验结果表明,SCAE-LR模型相比于对比方法在2个数据集上均表现出了较好的分类性能,说明本方法可用于高光谱图像分类。
