基于熵权法的多属性决策算法优化及应用
2022-01-05张甜阎红灿
张甜,阎红灿,2
(1.华北理工大学 理学院,河北 唐山 063210;2.河北省数据科学与应用重点实验室,河北 唐山 063000)
供应商评价和选择已被确定为采购和供应管理职能中关键的流程之一[1],在持续强调外包的驱动下,供应商评价和选择过程变得更加复杂和重要,已成为企业供应链管理战略的核心构成部分和竞争优势的源泉,因此供应商评价和选择成为企业战略的一个重要方面[2],以达到企业和供应商的互相支持、协同发展、实现双赢。供应商评价与选择是一种典型的多目标多属性决策问题,在众多解决多目标多属性决策问题的方法中,最常用的方法即为TOPSIS法。庄忠难[3]将SCOR与混合TOPSIS法相结合,对供应商绩效进行评价;秦海霞[4]等人使用CRITIC赋权的TOPSIS法,考虑到冬小麦稳产以及水资源高效利用,构建了冬小麦综合效益多目标优化模型;魏杰[5]等人研究了基于EWM-TOPSIS模型的房柱式采场布置方案优化;李少朋[6]等人将AHP与TOPSIS相结合,构建了水资源承载力评价模型。经典的TOPSIS法中属性权重是人为给定的,加入了个人偏好,主观性较强,为了提高其客观性,且更加科学地计算权重,减少评价目标对人为主观判断的依赖性,提出了基于熵权法改进的TOPSIS评价方法,为企业原材料供应商的选取提供参考依据。
1 理论基础
1.1 多目标多属性决策
决策在社会生活实践中非常普遍。Pareto在1896年提出了最优的概念,首次找到多准则决策的影子;20世纪60年代,多准则决策作为一种标准的决策方法出现在决策科学领域;1972年J.LCochrare和M.Zeleny在美国主持召开了一次多准则决策会议,成为了多准则决策发展的开端;1981年,C.L.Hwang和K.Yoon将多准则问题分为多目标决策和多属性决策[7]。在决策中,根据决策目标的个数,将决策分为单目标决策和多目标决策。在同一个目标中,根据决策属性的个数,将决策分为单属性决策和多属性决策。在多属性决策问题中,属性之间往往存在着不可替代甚至矛盾的关系,如何分配属性权重是解决多属性决策问题的难点。在当今日益复杂的决策形势下,多目标多属性决策已成为现代决策知识的重要组成部分,广泛应用于人力资源管理[8]、运输[9]、产品设计[10]、制造[11]、质量控制[12]和位置分析[13]等诸多领域。
1.2 经典的TOPSIS法
TOPSIS(Technique for Order Preference by Similarity to Ideal Solution)法,又称逼近于理想解的排序方法,是一种常用的多目标多属性决策方法。经典的TOPSIS法基本步骤如下:
(1)构造初始评价矩阵
在一个多目标多属性决策问题中,设共有n个目标,构成目标集G={g1,g2,…,gn},每个目标都有m个属性,构成属性集A={a1,a2,…,am},xij表示第i个目标第j个属性的属性值,则初始评价矩阵X=(xij)n×m(i=1,2,…,n;j=1,2,…,m)表示为:
(2)确定最优目标和最劣目标
X中每列元素的最大值构成正理想解X+,所有正理想解X+构成的集合即为最优目标:
X+=(max{x11,x21,…,xn1,},max{x12,x22,…,xn2,},…,max{x1m,x2m,…,xnm,})=(X1+,X2+,…,Xm+)
X中每列元素的最小值构成负理想解X-,所有负理想解X-构成的集合即为最劣目标:
X-=(min{x11,x21,…,xn1,},min{x12,x22,…,xn2,},…,min{x1m,x2m,…,xnm,})=(X1-,X2-,…,Xm-)
(3)计算各评价目标与最优目标的接近程度
(1)
计算各评价目标与最劣目标的接近程度
(2)
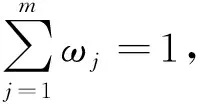
(4)计算各评价目标与最优目标的贴近程度
(3)
式中Di+为第i个目标与最优目标的贴近程度,Di-为第i个目标与最劣目标的贴近程度,0≤Ci≤1,Ci→1表明评价目标越优。
(5)根据Ci大小进行排序,得出最终决策结果
2 基于熵权法改进的TOPSIS决策算法
在多目标多属性决策问题中,熵权法可用来确定属性的客观权重。传统TOPSIS法中的权重是预先给定的,加入了个人偏好,过于依赖决策者的主观意图,具有较强的主观性。改进后的方法用熵权法来客观求取各属性的权重,计算过程不参与人为因素,减少评价目标对人为主观判断的依赖性,只依赖于数据本身,更准确地反映数据本身的规律所在、更科学地计算权重,更具有客观性。该方法对数据分布及样本含量没有严格限制,数据计算简单易行,能充分利用原始数据的信息,其结果能精确地反映各评价目标之间的差距。
2.1 信息熵
信息是一个非常抽象的概念,可以定性地分析信息量,但很难定量地计算信息量。在二十世纪中叶,C.E.Shannon借用热力学中的信息熵定义,解决了对信息的量化度量问题。热力学中的热熵是表示分子状态无序程度的物理量,C.E.Shannon用信息熵的概念来描述信源的不确定度。一个系统越有序,信息熵越低;反之,一个系统越混乱,信息熵越高。信息熵反映在属性值上理解为属性值变异程度的大小,属性值的信息熵越大,它的变异程度越大,可获取的信息量越小,其在决策中所起到的作用也越小。
定义1属性j的信息熵Ej定义为:
(4)
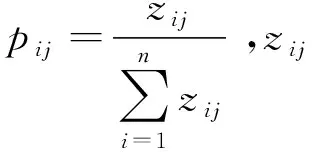
2.2 属性重要度
属性重要度可以反映出属性的权重大小,属性重要度越大,说明属性权重越大。由2.1分析出,属性值的信息熵越大,其在决策中的作用越小,权重越小。可以看出,信息熵与权重呈负相关,而属性重要度又可以反映出属性权重的大小,因此,可以得出结论,信息熵与属性重要度也呈负相关。定义2 第j个属性Aj的属性重要度定义为:
Dj=1-Ej
(5)
式中Aj为第j个属性,Ej为属性Aj的信息熵,j=1,2,…,m。
2.3 基于熵权法改进的TOPSIS算法流程
设共有n个评价目标,构成目标集G={g1,g2,…,gn},每个目标都有m个属性,构成属性集A={a1,a2,…,am},xij表示第i个目标第j个属性的属性值,则初始评价矩阵X=(xij)n×m(i=1,2,…,n;j=1,2,…,m)表示为:
Step1:构造同向化矩阵
属性同向化,一般选择正向化处理。将属性大致分为3类:
(1)对于成本型属性,属性值愈小愈佳(如患病率、失败率),属性值取倒数
(6)
(2)对于效益型属性,属性值愈大愈佳(如出勤率、成功率),属性值保持不变
x=x
(7)
(3)对于区间型属性,属性值最好落在一个确定的区间愈佳(如体温),属性值计算方法如下:
(8)
式中,[a,b]为属性x的最佳稳定区间,[a*,b*]为最大容忍区间。
将属性同向化,同向化后的矩阵Y=(Yij)n×m(i=1,2,…,n;j=1,2,…,m)表示为:
Step2:构造归一化矩阵
不同属性往往具有不同的数量级与量纲,为了消除属性间的差异性,对同向化后的矩阵Y进行归一化:
(9)
则得到归一化后的矩阵Z=(Zij)n×m(i=1,2,…,n;j=1,2,…,m)表示为:
Step3:确定最优目标和最劣目标
Z中每列元素的最大值构成正理想解Z+,即为最优目标:
Z+=(max{z11,z21,…zn1},max{z12,z22,…zn2},…max{z1m,z2m,…znm})=(Z1+,Z2+,…Zm+)
Z中每列元素的最小值构成负理想解Z-,即为最劣目标:
Z-=(min{z11,z21,…zn1},min{z12,z22,…zn2},…min{z1m,z2m,…znm})=(Z1-,Z2-,…Zm-)
Step4:计算各属性的权重
首先,计算各属性的信息熵。第j个属性的信息熵
(10)
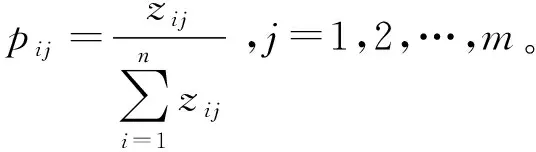
其次,计算各属性的属性重要度。第j个属性Aj的属性重要度
Dj=1-Ej
(11)
最后,计算各属性的客观权重。第j个属性Aj的权重
(12)
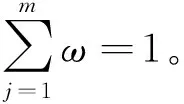
Step5:计算各评价目标与最优目标的接近程度
(13)
计算各评价目标与最劣目标的接近程度
(14)
式中Di+为第i个目标与最优目标的接近程度,Di-为第i个目标与最劣目标的接近程度,ωj为第j个属性的权重,Zj+为第j个属性的最优目标,zij为归一化后的属性值。
Step6:计算各评价目标与最优目标的贴近程度Ci
(15)
0⪯Ci⪯1,Ci→1表明评价目标越优。式中Di+为第i个目标与最优目标的接近程度,Di-为第i个目标与最劣目标的接近程度。
此外,墩台液压翻模技术应用期间容易出现较大缝隙,并且在进行液压台提升过程中,容易出现偏差,导致顶部混凝土因为受压,从而发生开裂情况,同时还存在套管倾斜幅度大、墩身尺寸相差大等各种不同类型的缺陷。因此,综合多方面因素,可以发现,在桥梁墩台施工中,墩台塔吊翻模技术与液压翻模技术相比,在具体应用过程中更加可靠,并且安全性更高。同时,该项技术不仅可以在铁路、公路等结构相对较大的建筑中应用,而且也可以应用在一些狭小的施工环境中。
Step7:根据Ci大小进行排序,给出评价结果
3 实例验证分析
某建材企业需要采购一种原材料,与之合作的有5家供应商,分别记为A、B、C、D、E,为了更客观地选择一家可以长久合作的优质原材料供应商,实地走访了该企业,进行了一次预评估,并从其《2020年合作供应商手则》中收集整理了有关数据资料。表1是手则中的部分数据。

表1 企业原材料供应商品质试评估的部分数据
式中,品质x1、供应量x3为效应型属性,价格x4为成本型属性,服务水平x2为区间型属性,规定[5,6]为供应能力的最佳稳定区间,[2,12]为最大容忍区间。
因此可由表中数据可建立初始评价矩阵X:

构造同向化矩阵Y:

构造归一化矩阵Z:
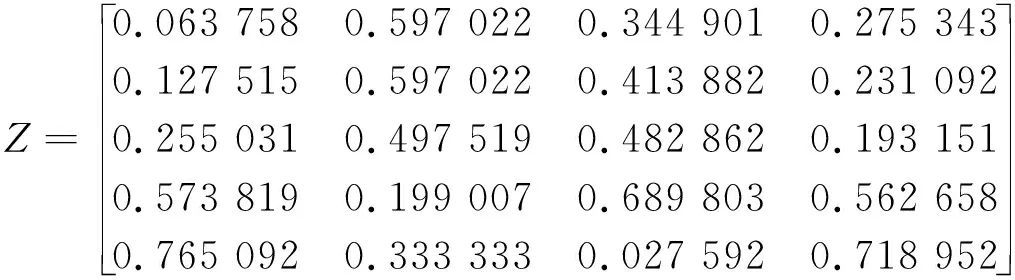
确定最优目标和最劣目标:
最劣目标Z-=(0.214 140,0.246 243,0.290 216,0.512 980,0.512 345)
计算各属性的信息熵:E1=0.816 087,E2=0.967 799,E3=0.874 222,E4=0.917 828
计算各属性的属性重要度:D1=0.183 913,D2=0.042 200,D3=0.125 778,D4=0.082 172
计算各属性的权重:ω1=0.423 701,ω2=0.097 223,ω3=0.289 767,ω4=0.189 309
计算各评价目标与最优目标的贴近程度:
C1=0,288 050,C2=0,344 805,C3=0.408 946,C4=0.731 296
TOPSIS评价结果见表2。

表2 TOPSIS评价结果
4 数据分析
根据最终排序结果,企业应优先考虑率供应商D。结合数据分析,供应商D服务水平最高、供应量最大、品质第二高且价格第二低。相比之下,供应商A的品质最差、价格最高、服务水平和供应量倒数第二,因此排在最后。结合计算出的权重,可以看出品质属性的权重最大,远远高于其他属性,除供应商D、E稍有换序外,其他3家供应商的最终排序与品质属性的排序一致。再仔细对比供应商D、E,从计算出的权重可以看出,品质权重是第一位的,价格权重是第二位的。虽然供应商D的品质略差于供应商E,但其供应量是供应商E的25倍。通过综合分析,供应商D在最终排序中位居第一是符合逻辑的。如果企业想拥有优质的原材料,建议选择供应商E,但需注意的是,可能面临原材料供应不足的窘境;如果企业希望获得优质、长期的原材料供应,建议选择供应商D。结合企业的需求即寻求长久合作的优质原材料供应商,最终建议选择供应商D。
5 结论
(1)改进后的方法采用熵权法,利用属性值固有的信息来客观求取各属性的权重,计算过程不参与人为因素,只依赖于数据本身,提高了客观和科学性,更准确地反映数据本身的规律,降低了评价目标对人的主观判断的依赖性,在一定程度上减少了主观因素造成的偏差。
(2)基于熵权法改进的多属性决策TOPSIS算法可以为企业原材料供应商的选取提供参考依据,也可以应用到更多的多目标多属性决策问题中,具有较强的现实意义和实用价值。
