基于多源信息融合的API知识图谱构建①
2022-01-05王微微赵瑞莲
马 展, 王 岩, 王微微, 赵瑞莲
(北京化工大学 信息科学与技术学院, 北京 100029)
1 引言
应用程序接口(API)在软件开发中起着十分重要的作用. 87%的开发人员经常借助于API解决不同的编程问题[1], 但检索查找合适的API非常困难. 为此, 为提高API检索的效率和质量, 研究人员从API参考文档、IT问答网站等各类资源构建了相应的API推荐系统, 以帮助开发人员解决与API相关的编程问题. 目前,已有的API推荐系统有: RASH[2]、BIKER[1]和RACK[3]等. RASH针对API参考文档和Stack Overflow (SO)问答网站[4], 利用词法相似度为查询推荐API. 与RASH不同, BIKER[1]利用语义相似度, 结合API参考文档和SO问答网站, 为查询推荐API. RACK[3]则通过建立问答网站标题中的关键字和API之间的关联, 为查询推荐API. 这些方法通过寻找问答网站相似问答涉及的API, 为查询推荐API. 然而, 与编程相关的API信息常以多种形式关联, 如解决同一问题的API之间可能存在功能相似的关联. 这种关联可能有助于API检索推荐[5].但上述方法均未考虑API信息之间的关联.
知识图谱是一个能有效表示信息之间语义关联的知识网络[6], 可用于API的知识表示. 如, Liu等人[7]从API参考文档和维基百科中提取相关知识, 构建API知识图谱; Li等人[8]从API参考文档和API教程中提取警告语句, 构建API警告知识图谱; Ling等人[5]以开源项目中的API为实体, 以API之间的调用、返回、实现等为关系, 构建基于开源项目的API知识图谱. 但上述从API文档、维基百科或开源项目等构建的API知识图谱, 缺少对API实际应用场景描述方面的信息,不利于API实际应用知识的融合利用.
SO是一个面向编程人员群体的IT技术问答网站.它以解决用户实际问题为出发点, 提供了API使用目的和真实应用场景相关信息[9], 可与API参考文档相辅相成, 互为补充, 为API知识图谱的构建提供真实应用场景的支持. PyTorch是一个以Python优先的深度学习框架, 在SO中涉及大量与API相关的讨论. 因此,本文提出一种结合API参考文档和SO问答网站的API知识图谱构建方法(AKG-CMISF). 从API参考文档提取API、领域概念作为实体, 建立他们之间的包含、继承、重载等关系; 从SO问答网站中提取问答QA、API概念作为实体, 建立问答QA实体和API概念实体之间的关联关系. 在此基础上, 建立API参考文档中的API、领域概念和SO问答网站中的问答QA、API概念之间的关联关系, 将多源知识进行融合, 构建多源信息融合的API知识图谱. 具体而言, 针对API参考文档, 通过分析半结构化文本提取API实体, 通过词典匹配提取领域概念实体; 针对SO问答网站, 通过类型识别和摘要生成获取问答QA实体, 通过数据驱动识别API概念; 然后, 基于语义相似度建立API概念和领域概念之间的关联, 利用词共现方法构建API和API概念之间的关联, 依据启发式策略构建API和问答QA之间的关联, 将多源信息进行知识融合, 实现API知识图谱的构建.
为验证本文提出的方法, 分别从知识抽取的准确度和推荐应用两个角度, 对本文构建API知识图谱的有效性进行评估. 实验结果表明, 和现有API推荐系统相比, 本文构建的知识图谱的API推荐效果和效率均有提升, 表明了API知识图谱的有效性以及多源信息融合对API推荐效果的支撑.
2 基于多源信息的API知识图谱构建
本文从API参考文档和SO问答网站提取API相关知识, 通过两类API知识的融合, 构建API知识图谱, 其框架如图1所示.

图1 基于多源信息的API知识图谱构建框架
2.1 面向API参考文档的知识获取
API参考文档提供所有API的功能描述及其相关属性信息(如参数、返回值等). 本文主要选用PyTorch框架的API参考文档, 进行知识表示及获取.
2.1.1 API参考文档的知识表示
本文以API参考文档涉及的API、领域概念以及它们之间的关系作为其知识表示. API参考文档的功能描述中蕴含API的应用领域, 该信息可间接反映API和领域概念之间的关联关系. 本文API是指模块、类、方法/函数等, 它们之间存在包含、继承和重载等关系. 领域概念是对API应用领域的抽象概括. API和领域概念之间可通过“提及”关联起来. 因此, 本文将API和领域概念作为API参考文档的实体, 并将它们之间的“提及”作为实体间的关系.
2.1.2 API参考文档的知识提取
API参考文档属于半结构化数据, 不同的HTML标签表示不同类型的API实体, API标签下含有API实体的属性信息, 如功能描述、参数、返回值和返回值类型等. 因此, 本文开发了一个API实体及属性分析模块, 分析并识别API实体之间的关系. 具体而言, 通过静态分析并识别API类或方法/函数及其它们之间的关系; 根据类的声明规则, 采用正则表达式提取类和基类之间的继承关系, 实现API实体及关系的识别和提取.
针对API功能描述中隐含的领域概念, 可通过目前已有的领域概念词典进行识别. 由于本文关注的是PyTorch框架, 因此, 采用文献[10]提供的领域概念开源词典[11], 匹配并识别API功能描述中的领域概念. 即将领域概念词典加入工具的自定义命名实体识别列表中, 根据API功能描述, 利用自然语言处理spacy匹配并识别API功能描述中的领域概念.
每个API都对应一个功能描述, 功能描述隐含领域概念, 因此, 从这种对应结构中可提取API和领域概念之间的“提及”关系. 如API “torch.normal”的功能描述中包含领域概念“standard deviation”. 当领域概念“standard deviation”被识别后, 则可在API“torch.normal”和领域概念“standard deviation”之间建立“提及”关系.
2.2 面向SO问答网站的知识获取
SO问答网站含有API的具体应用场景信息, 可与API参考文档互为补充. 本文主要对SO问答网站标签为“PyTorch”的问答进行知识的表示及获取.
2.2.1 SO问答网站的知识表示
SO问答网站的文本描述中包含了与API相关的术语, 如“download”“update”等. 这些术语可能只与软件开发相关, 不限于某领域, 但往往和API出现在同一句话, 同一段落或者同一篇问答中. 由于段落是问答描述的基本逻辑单元, 故本文将与API处于同一段落的相关术语称为API概念实体.
SO问答存在目的不明确和信息过载等问题. 目的不明确是指, SO问答因未考虑用户提问的目的, 使得SO问答网站很难把握用户提问的原因, 从而找出相应答案[12,13]; 信息过载是指, SO问答的一个提问可能有多个回答. 有统计表明, 超过37%的SO问答包含一个以上的回答, 每个回答的平均字数超过789个单词[14],这增加了SO问答网站获取关键信息的难度. 本文依据提问目的对SO问答自动分类, 以识别目的类型, 明确提问目的; 并依据SO问答特征生成回答的摘要, 从而减少信息过载. 本文将包含目的类型和摘要的SO问答称为问答QA实体. 继而可建立问答QA实体和API概念实体之间的“提及”关系. 并将API概念、问答QA,以及它们之间的关系作为SO问答网站知识表示.
2.2.2 SO问答网站的知识提取
为从SO问答网站提取API概念实体, 首先需识别SO问答网站中涉及的API. SO问答网站中的API通常由<code>标签标注, 当<code>标签标注的元素部分匹配或完全匹配API参考文档中的API全限定名时, 可识别该元素为SO问答中的API. API概念与API处于同一段落, 它可能是由多单词组成的概念, 如“convolutional layer”等. 为识别多单词API概念, 本文采用一种基于数据驱动的API概念识别方法, 即在SO问答网站中寻找经常连续出现但不常单独出现的单词,将其作为API概念. 为此, 可通过自然语言处理技术,对SO问答进行分词及去停用词, 形成单字符概念. 根据连续单词出现的频率, 计算词组得分 (score), 提取API概念. 词组得分如式(1)所示:

其中,count(wiwj)表示两个连续的单词wi和wj在全文档中出现的次数,count(wi)和count(wj)分别表示单词wi和wj出现的次数,δ是一个阈值. 当两个连续出现的单词wi和wj的频率小于δ时,wi和wj不能构成双词短语. 当形成双词概念时, 重复式(1)可检测三单词短语. 由于3个以上单词构成的API概念不常见, 故本文仅识别三单词以内的短语作为API概念.
为提取SO网站的问答QA实体, 本文通过机器学习算法对提问的目的进行分类, 获得目的类型, 在此基础上, 进行基于特征提取的回答摘要生成, 实现问答QA实体的提取.
本文针对提问目的, 在Beyer等人[15]对SO问答归类的基础上, 将SO问答分为如下7类: “API USAGE”类的提问目的为: 寻求实现某功能或API的使用建议; “DISCREPANCY”类的提问目的为: 请求解决非预期结果的代码段; “ERRORS”类的提问目的为:请求修复错误或处理异常; “REVIEW”类的提问目的为: 请求最佳解决方案; “CONCEPTUAL”类的提问目的为: 询问API的原理或背景; “API CHANGE”类的提问目的为: 寻求解决因API版本变化所产生的问题的方法; “LEARNING”类的提问目的为: 询问文档或教程来学习工具或语言.
XGBoost (eXtreme Gradient Boosting)机器学习算法具有快速学习和预测的功能[16]. 它基于决策树, 采用残差拟合的方式对残差进行顺序学习, 具有较高的分类准确性, 因此本文采用XGBoost算法训练分类器对SO问答分类. 主要步骤如下:
(1) 将SO问答标注为7种类型中的一种;
(2) 通过自然语言处理过程(分词、删除停用词、词形还原等), 将提问转换成相应的单词列表;
(3) TF-IDF通过字词出现的频率反映了其重要性,本文以提问的TF-IDF作为其文本特征. 在此基础上,利用XGBoost算法识别所有SO问答的提问类型.
针对SO问答信息过载, 本文以回答中的重要段落为依据, 生成其摘要. 即根据SO问答网站的特点, 通过问题相关特征、内容相关特征和用户特征, 综合为各段落计算其特征值, 取前M(10)个段落作为其摘要. 具体特征分析如下:
(1) 问题相关特征: 若段落中包含提问中的关键词,该段落被认为是与提问相关的段落. 段落包含的关键词越多, 则相关度越大. SO的Tag标签作为关键词集,以回答段落涉及的关键词占提问与回答共同涉及的关键词的比例, 计算每个回答段落和提问的相关度. 当提问和回答中没有共同的关键词时, 则该段特征值置为0.
(2) 内容相关特征: 该特征从是否包含API、信息熵、语义模板3个子特征评估段落内容的重要性. ① 若段落中至少出现一个API, 则子特征值置为1, 否则置为0. ② 单词的逆文本频率指数IDF值可用来衡量其信息熵, 可通过式(2)计算. 其中p表示段落总数,p′表示包含某个单词的段落数.IDF值越高, 表明单词出现的频率越低, 则重要程度越高. 段落的熵值可用其单词的IDF值之和表示, 并将熵值归一化为(0,1], 作为子特征值. ③ 本文结合API推荐的句式特征和带有总结性的句式特征对Xu等人[17]的段落语义模板进行扩充,结果如表1所示. 若段落中至少包含一个句式, 子特征的值置为1, 否则置为0. 内容特征值为3个子特征值之和.


表1 表明突出段落的语义模板
(3) 用户特征: SO中每个回答都有相应的投票, 投票越高, 表明该回答的质量越高. 因此, 采用回答的票数作为当前回答中段落的票数.
对于上述3种特征, 为了避免特征得分为0, 通过添加平滑因子0.0001, 将所有特征归一化为(0,1]. 将每个特征的归一化值相乘, 作为每个段落的总分. 最终取前M(10)个段落作为问答QA的摘要.
通过对SO问答进行提问的类型识别以及回答的摘要生成, 最终获得有效的问答QA实体. SO问答通常会提及多个API概念, 当识别了API概念后, 可分别在API概念和当前问答QA之间建立“提及”关系.
2.3 知识融合
为对API参考文档和SO问答网站的API知识进行融合, 构建完整的API知识图谱, 本文分别从API实体和API概念实体、API概念实体和领域概念实体以及API实体和问答QA实体之间, 进行知识融合.
2.3.1 基于词共现的API实体和API概念实体之间的融合
词共现是指API和API概念具有相同的上下文,即出现在同一段落. API概念对API的功能作用进行抽象概括, 这是建立两者之间语义关联的关键. 共现频率是指API和API概念出现在同一段落的次数. 因此本文通过计算API和API概念的共现频率, 捕获具有语义关联的API和API概念.

如式(3)所示,freq(Ai→Acj) 表示APIAi和API概念Acj的共现频率,α为其阈值. 当共现频率不低于阈值α时, APIAi和API概念Acj之间可建立“提及”的关系.
2.3.2 基于语义相似度的API概念实体和领域概念实体之间的融合
API概念和领域概念的融合是指建立API概念和领域概念之间的关联关系, 这种关联关系有助于建立API之间的间接关联, 以提高检索到相关API的可能.
由于API概念和领域概念由词组构成, 因此, 可通过结合词法和语义相似度来确定两者之间的关系. 当二者的相似度高于给定阈值时, 可建立它们的“相关”关系. 相似度计算公式如式(4)所示:


式(4)从词法和语义两个方面度量领域概念和API概念的相似度,n1和n2代表候选的领域概念和API概念. 词法相似度simlex通过Jaccard相似度进行计算, 如式(5)所示, 其中Token(n)代表组成概念的单词. 在SO问答和API参考文档两类语料库的基础上,本文利用Word2Vec[18]训练词嵌入模型, 将概念转换为词向量. 通过式(6)计算n1和n2之间的语义相似度.Vp(n)表示概念实体向量,simcos表示两个向量的余弦相似度. 一般来说, 语义相似度的重要性大于词法相似度, 因此, 设置w1<w2.
2.3.3 基于启发式的API实体和问答QA实体之间的融合
API实体和问答QA实体之间的融合是指建立API实体和问答QA之间的关联关系. 这种关联关系的建立使得API参考文档中API的通用知识(功能描述、参数、返回值等)可以和API在具体场景下的具体知识(如何解决具体问题)联系在一起, 可为开发人员提供更全面的API信息.
一般而言, SO问答中的API并不总是以全限定名的形式存在, 例如SO问答“What does model.train() do in PyTorch”中提及API“forward()”. 然而“forward()”可以与多个API关联. 为了将问答QA实体无歧义地和相应的API实体进行关联, 本文设计了启发式策略: SO问答中代码元素的出现有局部性[19], 即同一问答出现的API通常属于同一模块或类. 通过解析HTML的<code>标签, 识别问答QA提及API的模块或类. 通过制定正则表达式识别代码块中的模块或类确定其API. 当识别了无歧义的API后, 便可在问答QA和API之间建立“提及”的关联关系.
3 实验设计及结果分析
3.1 实验设计
本文从SO官方数据(截至2020年6月发布的数据)[20]中提取标注为“pytorch”的问答, 通过剔除其没有回答和回答中评分小于1的问答, 共收集了3361个SO问答作为研究对象. 从PyTorch的API参考文档中获取27个模块, 314个类, 1570个函数或方法, 以及它们对应的功能描述和属性作为研究对象, 进行API知识图谱的构建. API概念提取时, 实验中设置阈值δ 为5, 以避免不常见短语的识别. API和API概念之间融合时, 实验中将共现频率阈值 α设置为3, 来捕获API实体和API概念实体之间的语义关联. 融合API概念和领域概念时, 考虑到语义相似度的重要性大于词法相似度, 因此实验中设置权重w1和w2分别为0.3和0.5.最终构建的API知识图谱含28 730个实体, 142 578个关系. 其中API实体1912个, API概念实体16 216个, 领域概念实体7116个, 问答QA实体3361个. 图2是构建API知识图谱的部分抽象表示.

图2 基于多源信息融合的API知识图谱
本文构建的API知识图谱以Neo4j图数据库存储,以便利用Stanford CoreNLP[21]自然语言处理工具, 通过语法分析提取查询中的关键词. 对于每个关键词, 在API知识图谱中搜索查找一个与之语义相近的概念实体. 与概念实体具有“提及”关系的API实体作为候选API, 与候选API关联的问答QA为该候选API在具体使用场景下的信息. 由于候选API可能存在多个, 因此依据候选API和查询的语义相关性对候选API进行排序. 即通过计算查询和每个候选API功能描述的语义相似度(见式(6))对API进行排序, 取前K个API推荐给用户. 本文从SO问答网站中随机抽取10个至少有一次投票且回答中含有明确API的问题作为实验对象, 通过搜索API知识图谱, 获得与其相关的API, 以此验证基于知识图谱的API推荐的有效性.
3.2 实验结果与分析
本文从知识提取以及API推荐效果两个角度评估API知识图谱的质量.
3.2.1 API知识提取的有效性分析
本实验主要从实体和关系提取的有效性说明知识提取的有效性. API实体以及它们之间的关系来自半结构化API参考文档, 根据特定HTML标签和声明,一般都会提取与之相关的实体和关系. 因此本文主要评估从非结构化文本中提取实体的有效性, 即概念实体和问答QA实体, 以及API概念和领域概念之间关系提取的有效性. 概念实体以及关系的数量超过上万个, 检查所有实体和关系需要大量时间, 因此采用随机采样. 在确保95%置信度下, 从构建API知识图谱的实体或关系中随机抽取5%的样本, 样本估计精度具有0.05的误差幅度. 问答QA实体通过提问目的类型识别和回答摘要生成获得, 因此通过分析分类对类型识别的准确性以及摘要生成的质量, 评估问答QA实体的有效性. 查询问题及相关API个数如表2所示.

表2 10个查询问题以及相关API个数
(1) 针对API概念和领域概念有效性的评估, 通过人工识别抽样结果的准确与否. 准确是指提取的概念是正确且有意义的. 经过随机采样, 从领域概念实体中获得的356个领域概念的准确度可达95.6%, 误差主要来源于领域概念词典自身; 从API概念实体采样的800个API概念的准确度为97.8%, 影响其准确度的原因主要是SO问答中常提到一些数字指标, 如“200k images”, 这些术语不应被识别为API概念. 针对API概念和领域概念关系提取的有效性评估, 人工识别抽样结果的准确性, 即API概念和领域概念之间的语义相关性是否准确. 经过随机采样, 从API知识图谱中获得4000个关系, 其中94.3%的API概念和领域概念语义被识别为是相关的, 未被正确识别的API概念或领域概念影响关系提取的有效性.
(2) 针对问答QA实体有效性的评估, 主要通过分析SO问答提问的分类效果和回答摘要生成的质量加以说明.
① 问答分类效果评估: 本文采用10折交叉验证的方法, 验证SO 问答分类的有效性. 即用精度(precision)、召回率(recall)、F1值和准确度(accuracy)对分类效果进行评估. 为了验证基于XGBoost的提问分类效果, 以常用的SVM(支持向量机)和RF(随机森林)作为对比. 结果如表3所示, XGBoost的精度相比SVM和RF分别提高了14.6%和5.7%, 准确度分别提高了5.9%和4.6%. 因此, 可以看出, 采用XGBoost算法的分类效果优于其它方法.
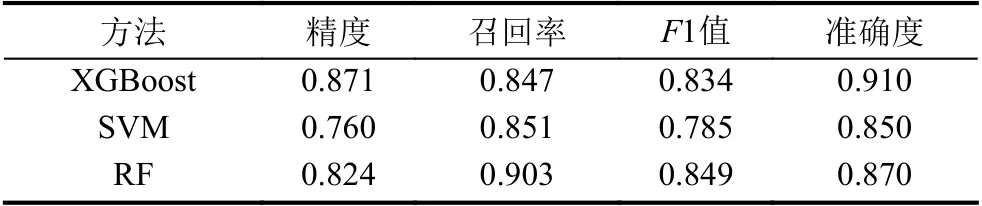
表3 不同分类算法的分类对比
② 摘要生成质量评估: 本文从相关性、有用性和多样性[17]衡量摘要的质量. 相关性表示摘要是否与问题相关, 有用性表示摘要内容能否解决问题, 多样性表示能否从多个角度回答问题. 本文设定每个指标最高分为5分(分别代表高度相关、有用和多样), 最低分为1分(分别代表不相关、无用和单一). 为了评估摘要质量, 邀请具有两年PyTorch使用经验的研究生参与评估. 表4表示评估者对表2的10个SO问答回答摘要的评价情况, 其中每个查询的3个评价指标均在3分到5分之间, 10个问题的平均结果分别为3.6、3.4和3.7, 表明基于特征提取的摘要生成方法是有效的.

表4 SO问答摘要得分的分布情况
3.2.2 本文AKG-CMISF对API的推荐效果分析
本实验选择信息检索常用的3个评价指标, HR (Hit Ratio)值、MRR (Mean Reciprocal Rank)和MAP(Mean Average Precision)对API推荐效果进行评估.HR评价的是在前K个搜索结果中, 正确结果占所有正确结果的百分比; MRR是指出现第一个正确结果的位置; MAP为所有正确结果的排名. 由于与查询相关的API个数在10以内, 因此本文设置K=10. 以最新API推荐系统——BIKER[1]作为基线, 进行API推荐效果的对比, 结果如表4所示.
由表5可知, 本文AKG-CMISF的HR比BIKER提高了49%, MRR提高了22%. 表明在搜索的前10个结果中, AKG-CMISF能够搜索到更多与查询相关的API, 并且比BIKER更早找到第一个正确API. 由此可见, AKG-CMISF相比于BIKER, 检索效率有所提高.表6表示在时间成本方面, AKG-CMISF的构建时间较长, 主要集中在分类器的训练和摘要生成, BIKER的构建时间较短, 主要集中在词嵌入模型的训练. 虽然本文方法构建的时间成本高于BIKER, 但查询时间缩短了一倍, 提高了API的检索效率.

表5 和基线API推荐方法对比

表6 和基线方法在时间成本方面的对比
3.2.3 多源信息融合对API推荐的有效性分析
本实验对比多信息源融合的API知识图谱和单信息源的API知识图谱对API的推荐效果, 以此验证多源信息融合对API推荐的有效性. 单信息源的API知识图谱构建分别从API参考文档和SO问答网站中提取API相关知识. 从API参考文档提取的知识包括API实体、领域概念实体以及它们之间的关系; 从SO问答网站提取的知识包括API实体、API概念实体、问答QA实体以及它们之间的关系体.
由表7可知, 多信息融合的推荐效果优于单信息源. 信息融合将与问题相关的API通过提及的概念间接关联起来, 提高了推荐效果. 值得注意的是, 基于API参考文档和基于SO问答网站的推荐效果相比差距较大. 分析原因可能是: API参考文档提供的功能描述不涉及具体应用场景, 因此它包含的领域概念很难和具体问题中的关键词对应起来, 导致仅使用API参考文档的推荐效果不尽人意.

表7 多源信息融合和单信息源推荐结果对比
4 结论
本文提出了一种基于多源信息融合的API知识图谱构建方法(AKG-CMISF). 该方法融合了API的功能和结构信息以及SO问答网站中API在具体场景下的使用信息, 提高了API检索的准确性. 实验从信息提取和API推荐效果两个方面验证了API知识图谱的有效性. 与现有API推荐系统相比, 本文基于API知识图谱的推荐方法在常见指标上均有提升. 同时通过实验验证了基于多信息源的API推荐效果相较于单信息源有明显提升.
下一步工作将基于该方法研发API知识图谱构建工具, 并将其应用在多个项目的API推荐.
