基于注意力的多尺度水下图像增强网络
2022-01-04刘小晗付飞蚺
方 明 刘小晗 付飞蚺
①(长春理工大学计算机科学技术学院 长春 130022)
②(长春理工大学人工智能学院 长春 130022)
1 引言
近年来,各国均在积极发展海洋战略,海洋信息的获取、传输和处理等关键技术对合理开发和利用海洋资源至关重要。水下图像是海洋信息的重要载体,然而水下图像受复杂的水下环境和光照条件影响,具有对比度低、纹理模糊、颜色失真、非均匀光照和可视范围有限等问题(真实水下图像如图1所示)。对图像进行清晰化处理,提高图像的质量,有利于获取更多信息,进一步进行水下目标跟踪和检测等任务。

图1 水下图像
目前在水下图像增强方面已经提出了很多传统的方法,如直方图均衡化[1]、颜色校正和对比度增强、基于融合的方法[2]等。由于水下图像接近陆地的雾图,因此基于去雾暗通道先验的方法[3]提出了一些适用于水下的去雾和增强算法[4-7]。常用的水下物理模型是由大气散射模型发展过来的,考虑了不同波长的光在水下的衰减程度不同。后期,Akkaynak等人[8]研究发现,目前的水下成像模型忽略了一些关键的组成部分,因而提出了修正的水下模型。然而,完善后的模型由于需要考虑各类参数的复杂性而限制了其广泛应用[9]。
由于深度神经网络可以实现复杂非线性系统的端到端建模[10],可用其拟合退化的水下图像到清晰水下图像之间的复杂映射关系,替代传统方法的复杂物理参数估计。因此,陆续有研究者提出深度学习方法在水下图像增强任务中的新方法。Hashisho等人[11]使用ClycleGAN生成成对的水下数据集,并使用UNet进行训练。但是使用ClycleGAN训练时间较长,针对水体影响导致模糊较严重区域,颜色恢复效果不理想。Li等人[12]提出了基于融合的卷积神经网络,制作的UIEBD数据集的图像分别经过白平衡、直方图均衡化、伽马校正后输入到卷积神经网络中进行特征融合。该方法能够很好地恢复出水下物体的颜色和细节,但是需要先对退化的水下图像进行处理,对于水体影响较大区域颜色恢复效果依然不理想。Fabbri等人[13]使用生成对抗网络的方法,但是处理后的图像边缘相对于原图比较模糊。Islam等人[14]同样基于生成对抗网络,提出了提升视觉感知的快速水下图像增强,达到了实时的效果。Zhang等人[15]在生成对抗网络的基础上进行了改进,引入梯度差损失来锐化图像避免图像模糊,该方法提升了图像的清晰度及细节特征,但是恢复的水下图像有些颜色失真。Park等人[16]提出了自适应加权的多鉴别器CycleGAN网络,在CycleGAN的基础上增加了内容鉴别器,保留输入图像的内容,并使用自适应加权方法限制两种鉴别器的损失,输出结果能够很好地恢复图像的颜色信息,但是在细节恢复上还可以进一步提升。
一般来说,基于深度学习的水下图像增强的重点在于数据集的获取,以及设计有效恢复水下图像细节和颜色的网络结构。针对这两个问题,本文提出了更接近真实水下场景的数据集合成方法,并提出了一个端到端的基于注意力的多尺度水下图像增强网络。对合成水下数据集和真实水下数据的主观与客观评价指标分析表明,本文提出的方法相比于其他水下图像增强方法,颜色和细节恢复得更好。本文的主要贡献:
(1)使用水下成像模型以及水体参数合成了一组新的数据集,该数据集同时考虑了水深和场景到相机的距离,在参数上更具有随机性,生成的水下图像具有多样性,更接近水下的复杂环境;
(2)在网络中引入像素和通道注意力机制,使网络更加关注水体影响较大区域的像素和更重要的通道信息;
(3)设计了一个多尺度特征提取模块,该模块使用不同采样率的平滑空洞卷积得到不同尺度的特征,再将这些特征通过注意力机制进行加权,以达到对不同尺度的特征采取不同的关注度的目的。
2 基于注意力的多尺度水下图像增强网络
2.1 数据集合成
目前有监督的网络在广泛的视觉任务中取得了显著的效果。然而,水下图像增强任务不同于一些高级视觉任务有公开的大型数据集。现有相关文献所使用的水下数据集大致分为3类:(1)使用NYU-v2 RGBD中的室内场景图及深度图按照水下成像模型进行合成[17-19];(2)使用CycleGAN[11,20]的无监督方式用清晰图像生成符合水下风格的图像,从中挑选出效果好的图像对作为数据集,这种方法训练时间较长,需要人工去挑选效果好的图像,耗时耗力,并且很难控制模拟出各类水体特征;(3)UIEBD数据集[12],由真实水下场景图像,通过12种现有方法进行处理,从中挑选出效果最好的图片作为对应的参考图。但是该数据集仅有890对图像,对于深度学习网络训练数量不足,很难训练出泛化能力强的网络。
因此,本文基于NYU-v2 RGBD数据集,利用水下成像模型重新合成水下数据集用于网络训练。相比于其他使用该数据集合成的方法,本文的数据集同时考虑了水深和场景到相机距离对图片的影响,更接近水下真实场景,同时采用随机性更高的水体参数,特征的覆盖能力更好,水下场景更具有多样性与复杂性。
由于水下场景与陆地雾天场景接近,为了描述水下物体的成像过程,常使用改进的雾霾成像公式进行修正,得到水下成像模型[21],如式(1)、式(2)所示
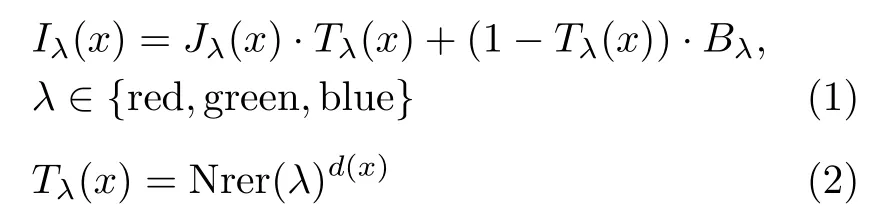
其中,x是水下场景的一点,Iλ(x)是相机拍摄到的水下图像,Jλ(x)是场景点的辐照度,Tλ(x)为中间能量比,表示从水下场景中的点x反射后到达相机的亮度百分比,d(x)为场景到相机的距离,Bλ是均匀的全局背景光,Nrer(λ)为归一化剩余能量比,即每单位传播距离的剩余能量与初始能量之比。
由于光在水下会发生衰减,因此光照通过深度为D(x)的水体到达场景x经过衰减,如式(3)所示


由于不同水体的衰减系数不同,根据式(6)以及Zhou等人[23]提供的参数合成不同水体(1),(2),(3)中成像的水下图像,其中参数如表1所示。
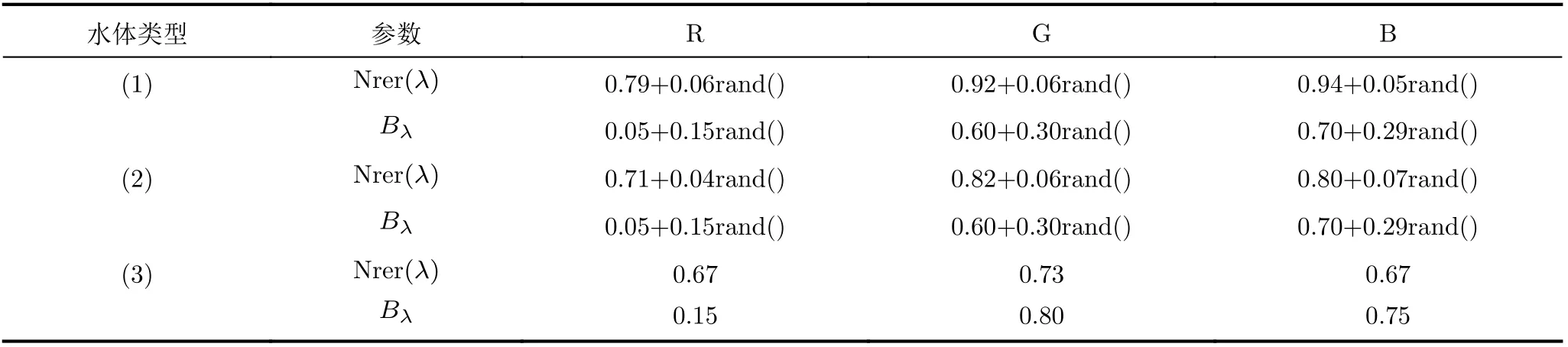
表1 不同水体中红(R),绿(G),蓝(B)通道中参数设置[23]
该组参数根据真实水下图像对比选取了3组更接近真实情况的水体参数,在参数中加入了随机数,使数据更具有多样性。NYU-v2数据集提供了清晰图片,以及场景深度d(x)。之后,考虑到第(3)种水体衰减较大,水深过深时图像几乎看不到物体,因此在前两种随机设置D(x)∈[0.5,10],第(3)种D(x)∈[0.1,2]。最终合成了一个包含不同水体类型的图像数据集,共7245对图像。部分水下图像视觉效果如图2所示,图2(a)为原图,图2(b)-图2(d)分别为水体类型(1),(2),(3)中的图像。从主观视觉效果上看本文生成的水下图像很接近真实水下图像,并且本文依据水下物理模型进行合成,符合水下成像原理。因此在真实水下数据集难以获得的情况下,使用该数据集进行深度学习训练是合理的。

图2 本文合成的水下图像
2.2 网络结构
本文的目的是设计一个高效且鲁棒的端到端网络,该网络使用合成数据集进行训练,同时对于不同水体中得到的偏色模糊的真实水下图像也有着非常好的效果,在恢复图像颜色的同时保留了图像细节,使图像在整体视觉效果上更接近陆地拍摄的清晰图像。
网络结构如图3所示,由3部分组成:(1)基础网络;(2)多尺度特征提取模块;(3)注意力机制模块。其中,整体网络参数如表2所示。基础网络由两个CINR单元(卷积层+InstanceNorm层+ReLU层),2个下采样和CINR单元,残差块组(本文采用3个残差块),2个反卷积和CINR单元,1个CINR单元组成。其中在下采样和反卷积阶段,将相同大小的特征层进行连接。为了使网络能够对各种大小图片均有很好的效果,扩大特征提取的感受野,在基础网络的前面增加1个多尺度特征提取模块(Multiscale Feature Extraction module, MFE),结构如图3(b)所示,该模块使网络能够关注到不同尺度的特征,从而增强整体的颜色与结构的恢复能力。最后引入了注意力机制模块(Attention mechanism,Attn),如图3(c)所示,该模块使网络能够对不同通道特征、不同像素特征进行加权,关注到更重要的区域,如由水体导致的模糊区域。训练网络时使用平滑L1损失和感知损失,使输出的图像与真实图像在颜色和内容上保持一致。

表2 网络参数表
2.2.1 注意力机制模块(Attn)
为了更好地处理水下图像的颜色以及水体对图片区域的影响,本文同时使用通道注意力机制和像素注意力机制[24],结构如图3(c)所示。该模块在处理不同类型的信息时提供了额外的灵活性,更加关注水下水体影响较大区域的像素和更重要通道信息。在通道注意力机制中,首先,利用全局平均池化将通道方向的全局空间信息转化为通道描述符。之后,特征通过1个全连接层,1个ReLU激活函数、1个全连接层、再加1个Sigmoid激活进行处理。


图3 网络结构图
2.2.2 多尺度特征提取模块(MFE)
在本文的网络中,为了获取到不同层次的特征[25],设计了一个多尺度特征提取模块(图3(a)所示)。其中多尺度是指不同大小采样率rate=1,2,4的空洞卷积提取不同尺度范围的特征信息,由于空洞卷积不同的扩张率,感受野不同,获得的特征区域信息大小不同。在1维情况下,给定1-D输入f,空洞卷积的输出为
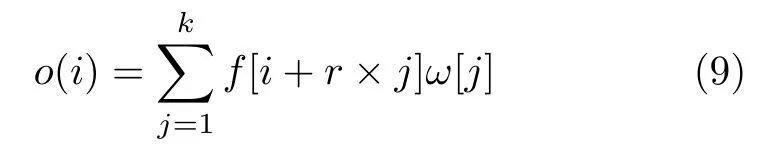
其中,r为扩张率,k为感受野大小,当r=1时,扩张的卷积对应于标准卷积。当r>1时,扩张卷积即在标准卷积的卷积核中每两个相邻权重之间插入r −1个0,感受野的大小由k扩张为(k −1)×r+1,不同大小的感受野可以获取到不同范围的信息。考虑到原始的空洞卷积,当采样率大于1时,输出特征层中相邻的特征值与输入特征上是完全独立的,会导致图像出现伪影。本文采用文献[26,27]提出的平滑空洞卷积,如图4所示。下一层的4个不同的点通过不同的颜色来指示,可以看出,它们是由上一层完全不相关的点获得的,这将可能导致网格伪影。它在扩展卷积之前增加了一个额外的可分离共享卷积层,从而增加了输入单元之间的依赖性。不同采样率的平滑空洞卷积得到的特征通过2.2.1节的注意力机制模块将不同尺度的特征进行权重分配,再将特征连接到一起,经过一层卷积,自适应地提取不同尺度的特征,得到的特征再与输入进行相加,输向下一阶段。

图4 平滑空洞卷积
2.2.3 损失函数
本文使用平滑的L1损失和感知损失[28]训练网络。其中,L1损失用来在训练过程中约束生成图像与参考图的像素值一致,由于L1范数可以防止潜在的梯度爆炸,而平滑的L1损失对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值的敏感度较低。平滑的L1损失(Ls1)可以表示为

其中

感知损失用来度量内容的感知,利用从预先训练的深度神经网络来提取的多尺度特征,将参考图像卷积得到的特征图与生成图像卷积得到的特征图作比较,使得高层信息,也就是内容和全局结构接近。本文使用预先训练的VGG16[29]作为损失网络,从前3个阶段的最后一层提取特征。感知损失(Lpe)表示为

3 实验
3.1 训练设置
按照前文所提出的方法进行水下数据集生成。并随机选取6882张图片作为训练集。训练过程中,随机截取256×256大小的区域作为输入。Batch size为16,初始学习率设为0.01,一共150个epoch,每30个epoch,学习率乘以0.5。感知损失权重系数λ为0.04。
本研究实验GPU环境为:Intel(R) Core(TM)i9-7960X CPU @ 3.30 GHz,Ubuntu18.04,64位操作系统,运行内存32 GB,NVIDIA Corporation GV100 [TITAN V],CUDA10.1,cuDNN 7.6.0,Python 3.6。CPU环境为:Intel(R) Xeon(R) CPU E3-1220 V2 @ 3.10 GHz,Windows10。
3.2 评价指标
本文在合成数据集上使用常用的PSNR和SSIM[30]作为评价指标。在真实数据集上,由于没有真实值对比,因此选择使用水下图像质量测量UIQM[31]作为评价指标。UIQM由3个水下测量指标组成:水下图像色彩测量UICM,水下图像清晰度测量UISM,水下图像对比度测量UIconM。计算公式为

其中,根据文献[31]设置c1=0.0282,c2=0.2953,c3=3.5753。
3.3 合成水下图像评估
本文与其他方法的效果进行了比较,对比的方法包括水下暗通道先验(UDCP[32]),基于图像模糊和光吸收的水下图像恢复(IBLA[33]),基于快速场景深度估计模型的水下图像恢复(ULAP[34]),基于融合方法的水下图像增强(DUIENet[12]),基于GAN网络的快速水下图像增强(FUnIE-GAN[14])。本文随机选取了145张图像作为测试集。实验结果如图5所示,图5(a)为合成的水下图像,图5(b)为原始清晰图像,图5(c)为UDCP方法处理效果,可以看出颜色对比度有些过度,图5(d)、图5(e)分别为IBLA和ULAP方法,这两种方法针对该合成图像效果不明显,图5(f)、图5(g)分别为DUIENet和FUnIE-GAN方法,能够恢复一些颜色和细节,但是还有模糊感,图5(h)为本文方法,结果最清晰也最接近真实图像。另外对每种方法进行PSNR和SSIM值计算,测试集上的均值如表3所示。可以看出,无论哪一个指标,本文方法数值结果都最优。从主观视觉效果和客观数据结果来看,本文的方法是有效的。

表3 不同方法在合成数据集上的PSNR和SSIM值

图5 不同方法在合成数据集上的处理效果
3.4 真实水下图像评估
为了验证本文方法在真实水下图像上的有效性,本文对78张真实水下图像进行了实验。图6所示为部分图像的效果图对比,图6(a)为真实水下图像,图6(b)-图6(g)分别是UDCP, IBLA, ULAP,DUIENet, FUnIE-GAN以及本文方法的处理效果图。本文的方法相比于其他方法整体色调更接近陆地清晰图像,消除了水下图像由于水体原因造成的偏色情况,效果对比度更高,色彩更加鲜艳。在第1幅图中,几乎完全去除了蓝色的水体遮挡,恢复了水下物体的真实颜色,同时细节也更加清晰。第2幅图中,本文方法恢复的图像边缘更清晰,对比度更高;第3幅图中本文方法颜色对比度更接近陆地图像;第4幅图中,鱼的视觉感官更加清晰,而且地面颜色恢复也更好。每张图像的UIQM数值结果如表4所示,加粗为最优值。

表4 图6中图片的不同方法的UIQM值

图6 不同方法在真实数据集上的处理效果
本文对78张图片均进行了处理并计算了UIQM数值,其中UIQM的值为UICM, UISM, UIConM的加权和。对78张图片取平均值,每种方法的数值结果如表5所示。可以看出本文方法得到了最优结果。图7细节放大图的比较,图7(a)-图7(c)分别为DUIENet, FUnIE-GAN和本文方法。本文方法细节表现更加清晰。

表5 不同方法在真实数据集上的UIQM值

图7 细节放大图
3.5 消融实验
为了验证网络的有效性,本文在145张测试集上进行了消融实验,验证注意力机制模块(Attn)、多尺度特征提取模块(MFE)以及感知损失的有效性。结果如表6所示。存在注意力机制模块、多尺度特征提取模块和感知损失情况下取得了最高的评优值。

表6 网络结构消融实验数值结果
3.6 运行时间
本文对每种方法的运行时间进行了统计,结果如表7所示。该结果为在CPU上处理1张大小为480×640的图像所需要的时间。可以看出本文方法虽然不是最快的,但是结果与处理效果较好的深度学习方法DUIENet相当。

表7 不同方法运行时间表(s)
4 结束语
本文设计了一个基于注意力的多尺度水下图像增强网络,网络中引入了注意力机制,包括通道注意力和像素注意力,让网络能够更加关注到由于水体导致的模糊区域,从而更好地恢复水下图像,同时设计了一个多尺度特征提取模块,使网络能够更好地提取不同尺度的特征。使用水下图像成像模型以及水体参数合成了更加真实的数据集进行训练,训练好的网络不仅在合成数据集上获得了很好的效果,对于真实水下图像也能够很好地还原场景的颜色及细节。对比实验结果表明,本文方法要优于现有的很多方法,对水体造成的偏色能够有效地去除,增强后的图像很好地还原了物体原有特征。但同时,本文方法时间复杂度略高,很难满足实时处理的要求,这也是需要进一步改进的方向。
