基于潜在类别方法的铁路-地铁枢纽站内乘客异质性研究
2022-01-04邱海童
郑 昭 邱海童
(北京公交有轨电车有限公司,北京 100080)
引言
高速铁路和地铁的迅速发展和不断完善,对乘客吸引力和吸引范围不断扩大,两者之间的衔接必将直接影响城市综合交通运输的效率。相比普通地铁换乘站,衔接枢纽地铁站的车站设施布置更复杂,车站空间布置更加多样,在大客流的影响下,乘客行为复杂多样,异质性明显。将乘客视为同质个体进行研究显然已不符合实际。所以进行乘客异质性研究有重要的现实意义。
为更好地研究乘客异质性特点,本文吸纳社会科学研究相关经验,采用更具优势的潜在类别方法对出行乘客进行分类,以实现乘客异质性的客观描述。在进行潜在类别分析时,将乘客在楼扶梯处的微观选择行为以及乘客的生理和行为特性全部引入尽可能多的外显变量。
顾兆军等[1]使用航空旅客订票数据进行潜在类别模型分析,实现民航旅客的合理分类,以研究民航旅客的出行选择偏好。杨倩倩[2]根据旅客的订票行为、登记行为等进行聚类,将旅客划分为不同的客户群,在分析了不同客户群的出行特点及偏好后,提供有针对性的旅客服务。文佳星[3]使用京沪高铁和沪宁高铁乘客订票数据,运用潜在类别理论对高铁乘客选择行为进行详细划分,为票价优惠设计方案。乔珂等[4]运用潜在类别模型对高铁旅客市场进行细分,在完成类别划分后,进一步使用模型进行聚类分析,了解不同类型旅客的出行特征。陈建冰[5]利用潜在类别模型进行通勤个体异质性研究,对通勤过程中不可预测因素进行研究。杨洋[6]根据SP 调查数据,将受访者分为四个潜在类别,并分析每一类别的特征,可以用于辅助交通政策制定目标人群,以规划停车换乘系统。
1 枢纽地铁站乘客行为调研与数据处理
选取北京西站地铁站为调研车站,通过人工观测和视频记录的方法分别在车站站厅、站台、楼扶梯及出站闸机处采集乘客个体特性和设备参数,包括乘客性别、年龄、速度、行李、同组伴、熟悉程度和设施的通过时间,共采集291 组数据(其中楼扶梯处采集数据83 组,车站站厅、站台和出站闸机位置共采集208 组)。被调查对象的基本信息调查结果及分析如下:
(1)男性占本次调查对象的54.5%,女性占调查对象的45.5%。
(2)调查对象中97%的乘客为成年人,其中年龄主要集中在20-40 岁间,占总人数的75.1%。
(3)调查对象中同组伴乘客占比6%。
(4)调查对象携带行李多样,对乘客携带行李比例进行统计,其中未携带行李的乘客41%,携带行李箱乘客15%,携带背包乘客15%,携带手提包乘客29%。
2 基于潜在类别的枢纽地铁车站行人异质性
在交通研究中,考虑实际情形下,行人流中包含有具备不同行人个体属性而产生不同交通特性和行为偏好的个体,因此应该充分考虑行人异质性,对乘客进行类别分类,按类别标定参数。
2.1 乘客的微观行为分析
基于行人异质性对枢纽车站乘客微观选择行为进行分析。在既有研究的基础上,根据调研数据,对行人站台楼扶梯选择进行分析,确定改进模型的回归系数和预测准确率,本文选择目前较为常见的二元Logit 模型进行分析。参考史芮嘉等[7]和朱昌稳[8]的研究,选取排队人数、携带行李数量、年龄和时间敏感性为主要因素进行建模分析。
2.1.1 模型构建
基于采集数据,进行二元Logit 回归分析。
乘客选择楼梯的效用函数表示为:

乘客选择电扶梯的效用函数表示为:

式中:L表示选择自动扶梯的乘客排队长度;G表示乘客携带行李情况;N表示样本乘客的年龄;T表示样本乘客的时间敏感程度,速度高于1.5m/s可以认为乘客时间敏感性高[8]。
2.1.2 参数标定
根据楼扶梯处的实际采集数据(共采集83组),采用数据处理软件对参数进行拟合,参数拟合结果如下式所示:

行人的选择行为与排队人数、携带行李数量、年龄和时间敏感性都相关,其中时间敏感性对选择影响较为明显。模型预测准确率如表1 所示,楼扶梯选择行为的预测准确率为94%。其中选择扶梯的预测准确率为97.1%,即实际69 人选择扶梯,预测67 人选择扶梯;选择楼梯的预测准确率为78.6%,即实际14 人选择楼梯,预测11 人选择楼梯。
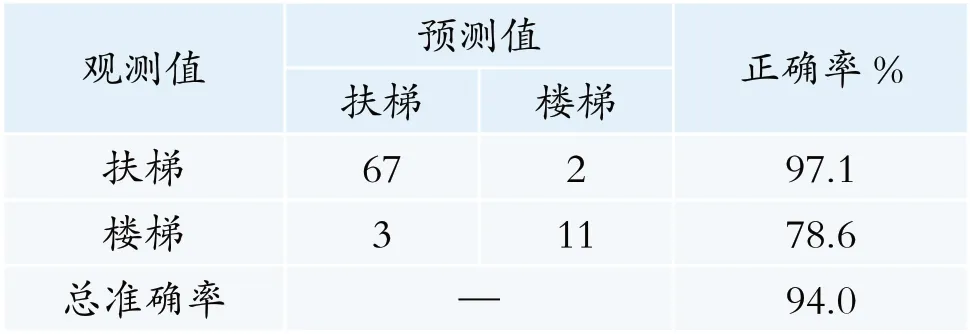
表1 楼扶梯选择统计表
2.2 乘客异质性的潜在类别分析
2.2.1 潜在类别模型构建
潜在类别模型(LCM)是用于探索分析潜在类别变量的一种模型化技术。该模型有机结合了类别数据和潜在变量,提高了类别分析的价值。建立一个完整的潜在类别模型分为三个步骤,首先进行概率参数化,然后完成模型估计,最后进行潜在分类(图1)。

图1 潜在类别模型建模步骤
Mplus 软件是一个统计建模软件,为研究者提供了灵活的数据分析工具,具有易于使用的图形界面和展示数据分析结果的模式、估计和算法。本文借助Mplus 软件展开潜在类别分析。
2.2.1.1 概率参数化
概率参数化是建立潜在类别模型的首要步骤,潜在类别模型中包含有潜在变量和外显变量,因此对应的潜在类别模型参数包括潜在类别概率和条件概率。
潜在类别概率用来表达潜在变量X属于T类别中某一水平t的概率,可以用表示其概率。显然此概率受到潜在类别变量的相对大小和其水平数目T所决定,各潜在类别的概率和为1,即:

条件概率表示在潜在类别中随机抽取一个样本,样本对外显变量所显示的概率。此概率可表示为,A表示外显变量,i表示对应的外显变量水平值。条件概率的成立需要满足同一外显水平间相互独立和各外显变量不同水平间也相互独立。此时,外显变量在各水平下的条件概率和为1,即:

在各潜在类别中,较大的条件概率值表示潜在变量对于该外显变量比重较大,影响较强。在建立潜在类别模型前,需要进行外显变量的分水平处理,保证分水平处理后的各外显变量不同维度间相互完全独立。在本文中,对乘客的六个外显变量进行分水平处理,如性别分为男女两个水平,速度按大小分为五个区间水平,组群行为分为有无两个水平等。
2.2.1.2 模型估计
实测数据的外显变量在考虑各观察数据潜在属性后,也应当满足局部独立性条件,如果把观察数据的类别属性考虑在内,外显变量之间应该是完全独立无关的。在潜在类别分析中,模型估计主要采用极大似然估计方法。对于一个具有t个潜在类别的潜在变量X的潜在类别模型,极大似然估计函数可以表示为:


将上述两式做除法,就可以得到各潜在类别中外显变量各水平的极大似然概率。

2.2.1.3 概率适配性
在模型构建完成后需要对模型进行评价,选择出拟合度高、参数适当的模型。常见的模型适配方法有极大似然法,Pearsonχ2,AIC 和BIC 四种。
潜在类别模型利用极大似然法,对各单元格的观察次数和期望次数的差异情形利用对数函数转化成似然卡方统计量G2,来反映模型拟合度。另一种检验方法是直接使用Pearsonχ2来计算模型拟合度,公式如下:

AIC 指标是基于信息理论模型适配指标,用于不同模型适配优劣比较。AIC 指标由极大似然算法推导而来。若存在h个需要比较的模型,则AIC 表示为:

其中:为第h个模型自由度, 为第h个模型适配度的卡方值。
BIC 指标是用于改善AIC 指标在数据样本量大时渐进性不足的问题。定义为:

2.2.1.4 潜在分类
分类是潜在类别分析的最终目的,将所有样本数据分到对应的潜在类别中,即通过新的类别变量来解释观察值的后验类别属性。利用贝氏分类法进行分类,计算方法如下。

利用式(15)求出旅客属于各个潜在类别的后验概率,根据后验概率大小判断乘客所属潜在类别,进而实现分类。
2.2.2 乘客类别分析案例
对在车站站厅、站台和出站闸机处采集的208组调研数据进行潜在类别分析。外显变量选取是潜在类别分析的重要准备,结合调研统计信息数据,最终选择外显变量为以下六个:性别、年龄、行李量、同伴群行为、速度、对车站舒适程度和楼扶梯选择行为。其中楼扶梯选择行为根据2.1 节所构建的Logit 模型选择概率进行判定。
2.2.2.1 数据准备
在实际建模过程中,考虑年龄、速度等数据取值范围广,行李携带形式多样,若直接选择自然值进行分析,会造成过多的参数估计,影响结果准确性。所以对原始数据进行编排处理,以数字表示外显变量的程度水平,遵循规则和处理结果见表2。

表2 外显变量分水平处置表
按照以上规则对采集的数据进行处理,将数据转化成数值信息,作为模型输入。
2.2.2.2 结果评价
模型拟合过程中,并不确定将潜在类别分为几类最合适,所以采用逐次计算的方法,即设定潜在类别由1 开始逐一增加,直到找到最好的模型匹配结果为止。根据模型拟合结果,一般选用Pearson卡方(χ2)、似然比卡方(G2)和信息指数AIC 和BIC、aBIC 来对潜在类别模型的拟合优度进行评价比较,这些指数均越小越好。
表3 列出了M1~M6 模型的拟合结果。根据适配指标可知,当潜在类别为4 时,模型满足数值拟合的要求。潜在类别由1 至4 逐次增加,似然比Log (L)绝对值、似然比卡方(G2)和Pearson 卡方(χ2)逐渐减小,BIC 指标逐渐增大,但AIC 和aBIC指标在M4模型中达到最小值。综合上述结果,可以认为潜在类别分为4 类时,更加接近枢纽地铁车站乘客类别的理想模型。
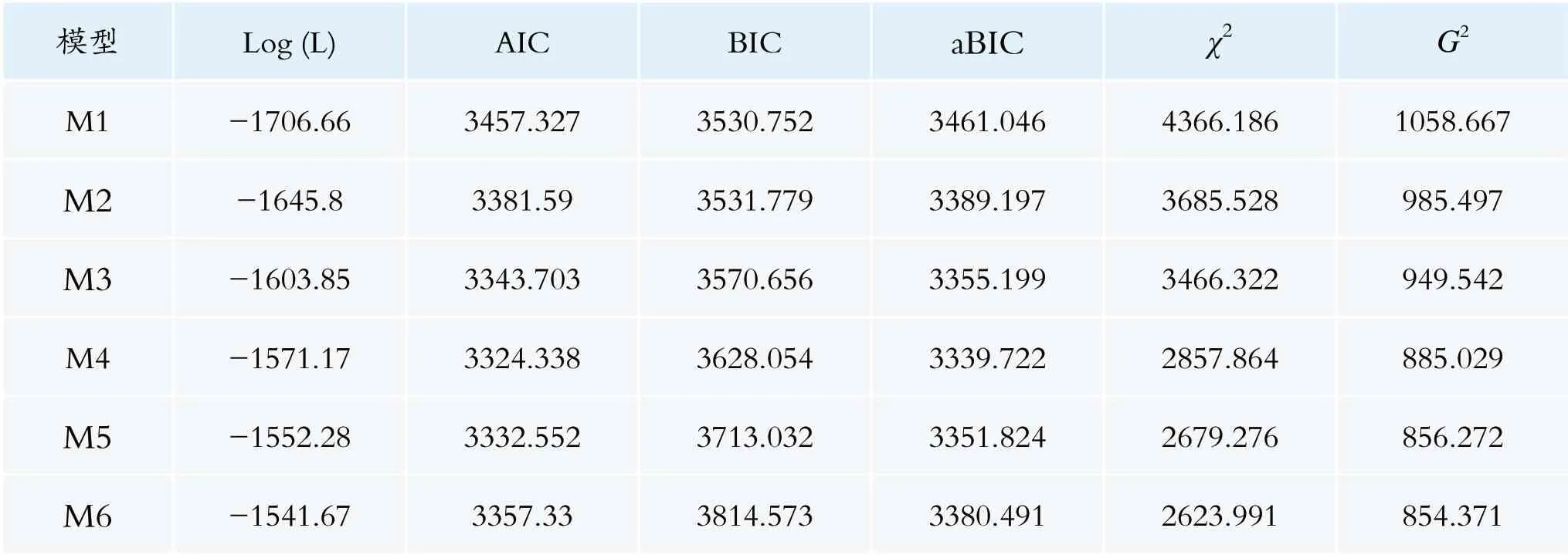
表3 不同类别模型适配指标
2.2.2.3 参数估计结果
对调研数据采用M4 模型进行潜在类别分析,表4 表示不同类别人数及概率,可以看出,第3类别的乘客人数最多,占比为38.94%,占比最大。第4 类别和第1 类别次之,分别为26.92%和19.71%。第2 类别占比较少,为14.42%。

表4 潜在类别概率统计
2.2.2.4 不同类别乘客出行特征分析
为更好地区分枢纽地铁车站内乘客异质性,需要对前文所得到的四个潜在类别进行形象化命名。如图2 所示,将各类别乘客在不同外显变量维度水平的条件概率进行统计,可以明显看出各类别乘客间的差异。

图2 各潜在类别条件概率分布图
综上,对四个类别乘客行为特征分析如下:
类别1:不熟悉环境低速乘客。该类乘客走行速度慢,半数乘客携带单件行李,对车站环境不够熟悉,认为是首次或少次到达的铁路旅客或地铁乘客。
类别2:远途组群乘客。该类乘客以中年和儿童为主,有明显的组群行为,对车站环境一般熟悉,且多数携带箱包行李,认为是多次乘坐铁路远途出行的组群乘客。
类别3:地铁通勤乘客。乘客以未携带行李和携带背包乘客为主,乘客对车站环境较为熟悉,且有半数乘客会选择楼梯,认为是地铁通勤乘客。
类别4:普通铁路旅客。该类乘客对车站环境非常熟悉,乘客间存在组群行为,且走行速度高于平均速度,乘客携带行李形式丰富,认为是经常前往车站乘车的普通铁路旅客。
3 结论
随着高速铁路和地铁的兴起,两者在乘客出行方式选择中占比重越来越大,吸引了大量的客流。本文对高铁-地铁衔接枢纽站中的地铁车站乘客行为异质性进行了深入分析和研究。对北京地铁北京西站乘客基本参数(性别、年龄、速度、行李量等)进行采集,使用二元Logit 方法和潜在类别模型方法对乘客微观选择行为和乘客类别进行研究。选择排队人数、携带行李数量、年龄和时间敏感性作为主要因素构建了乘客楼扶梯选择的概率模型,并根据实际采集数据实现模型参数标定,对采集样本的选择概率进行计算。以实际采集数据和行人楼扶梯选择概率为外显变量,使用潜在类别模型方法对车站行人异质性进行研究。借助Mplus 软件进行建模分析,实现行人类别划分。根据乘客在外显变量各维度水平条件概率和生活实际经验,将乘客分为不熟悉环境低速乘客、远途组群乘客、地铁通勤乘客和普通铁路旅客四个潜在类别,结果良好合理,研究成果能够为行人微观仿真研究中乘客的异质性描述提供新的思路和方法。
