基于多特征融合的机器英语翻译错误自动识别研究
2021-12-31程晓娇
程晓娇
(大连财经学院 国际教育学院,辽宁 大连 116622)
随着经济的腾飞,互联网行业正在飞速发展,英语翻译在世界贸易中的地位逐渐提升。机器翻译技术可以克服人工翻译中的多种问题,降低人工翻译的经济消耗与时间消耗。在当前这个高度信息化的时代,人们对于英语的翻译要求逐渐增加,计算机对英语语言的理解与翻译需求越发迫切[1-2]。计算机的英语翻译能力直接影响着翻译结果的应用效果,与人们的经济活动息息相关。但英语翻译结果均会出现语法错误,使计算机翻译结果出现偏差,影响英语翻译结果的输出与判断。因此,在以往的研究中,大量的专家学者提出了机器英语翻译错误自动识别方法,力求降低英语翻译错误对经济活动的影响。
张楠等人采用神经机器翻译方法对中英文翻译结果进行预测,在预测的过程中完成翻译错误结果的识别工作[3]。此方法的识别速度相对较高,但是识别精度与有效性较差。为此,使用多特征融合技术,设计新型机器英语翻译错误自动识别方法。为保证此方法设计完成后具有应用价值,构建相应的实验环节对其展开验证,确保此方法具有研究意义。
1 基于多特征融合的机器英语翻译错误自动识别方法设计
1.1 机器英语翻译信息特征提取
在本次研究中,将融合英语翻译的特征提取算法,充分利用平行语料。提取到的特征融合翻译结果,得到机器英语翻译的信息特征。通过文献分析可以发现,机器翻译可以分为两部分,分别是将源语言翻译为目标语言以及将目标语言翻译为源语言[4-5]。这两种翻译过程完全相同,且共享词语向量参数。将源语言语句设定为A={a1,a2,…,an},ai表示源语句的单词;目标端语句为B={b1,b2,…,bn},bj表示目标语句的词嵌入编码;C表示源端语句的长度;D表示目标语句的长度。设定本次翻译中使用的编码器与解码器构建为神经网络结构,编码器的主要功能是将源语句A编码为固定向量E,同时对E进行解码得到目标语句D。整合翻译过程可表示为P(B|A:α),使用乘法法则得到上述条件概率的计算过程,具体如式(1)所示。
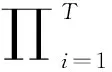
(1)
编码器由公式(1)构成,初始的隐形状态均为零向量,在进行每一步翻译时,均需要将此步骤中的单词映射为对应的向量ai的形式;然后和上一翻译步骤中的词语进行计算,得到源语句的编码向量E。将使用的编码器组建成网络形式,则存在以下(2)-(5)关系式:
wt=sigmoid(Hirai+xir+Hsrst-1+xhr)
(2)
kt=sigmoid(Hirai+xir+Hsrst-1+xhk)
(3)
nt=tans(Hinai+xin+Hsnst-1+xhn)
(4)
st=(1-kt)nt+ktnt-1
(5)
公式(1)-公式(5)中,wt表示解码器向量;Hir表示初始向量;xir表示源语句向量;Hsr表示隐藏向量;st-1表示t-1时刻的隐状态对语句的影响向量;xhr表示解码器的单词计数向量;kt表示编码器向量,xhk表示编码器的单词计数向量,主要利用式(2)与式(3)实现源语句解码与编码。nt表示步骤向量,xhn表示最大编码长度向量,主要利用该式对编码步骤进行限制;st表示t时刻隐状态对语句的影响向量,kt表示误差向量,nt表示误差向量幅度,st是机器英语翻译误差的主要原因。
因此,本文将神经网络应用到机器英语翻译信息特征提取过程中,将隐层使用tan函数表示,而后使用softmax函数[6]进行归一化处理,计算过程设定如式(6):
p(bt|b1,b2,…,bn,a:α)=softmax[v2tan(v1st+xhn)]
(6)
公式(6)中,v1、v2表示不同的归一化系数。
根据公式(6)可初步得到机器翻译特征,为了获取到可信度更高的翻译特征,使用sigmoid作为激活函数,对机器英语翻译特征进行处理,则有式(7)、式(8):
g1=relu(v1e+xhn)
(7)
ster=sigmoid(v2a+xhn)
(8)
公式(7)中,e表示可信度。
根据公式(7)-公式(8)完成英语翻译的特征提取,并将提取到的翻译特征作为本次研究的基础。
1.2 机器英语翻译多特征融合预判
根据提取到的机器英语翻译特征结合翻译自动评价方法,对机器英语翻译结果进行预判。使用皮尔逊系数[7]作为指导因素,对翻译结果进行初步分析,具体计算过程设定如式(9):
(9)
公式(9)中,o表示翻译结果的数学期望值;d表示方差。一般情况,此公式取值结果为-1或是1,当此计算结果具有较高的关联性时,取值结果趋近于1,否则,趋近于-1。
根据上述公式考虑到机器翻译译文特征,在信息预判过程中引入惩罚函数,以此保证翻译偏好程度不会对翻译结果造成影响。则有式(10):
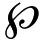
(10)
公式(10)中,N表示惩罚因子数量;εi表示翻译偏好系数;precision表示翻译信息预判结果;U表示惩罚因子,其计算公式如式(11):
(11)
公式(11)中,output表示惩罚因子输出结果,length表示惩罚因子程度;reference表示惩罚因子最优长度。
在判定过程中增加翻译信息召回率计算过程,对公式(11)进行整合后,得到新的判定计算公式(12):

(12)
公式(12)中,Counti(U)表示第i个惩罚函数;Count(U)表示初始的惩罚函数。
使用此公式对机器翻译结果展开预判,确定此结果的正确率。同时,获取正确率较低的信息作为翻译错误识别训练组,构建相应的支持向量机[8],对此部分信息进行二次判定。
对于二分类问题,为了得到最终可靠的预判结果,将训练集设定为(zi,yi),i=1,2,…,n,zi∈Rn,yi∈{±1}上,分类平面可表示为式(13):
(q*z)+k=0
(13)
公式(13)中,k表示惩罚平面斜率;q与z分别表示惩罚平面的长与宽。
根据公式(13)对样本进行正确区分,分类间隔最大化,该最优分类结果需要满足下述式(14)条件:
yi[(q*z)+k]≥1
(14)
以公式(14)为基础构建支持向量机,则此问题可优化为式(15):
(15)
其中,G表示分类过程中的代价系数;φ(·)表示判定过程中的非线性变换函数;i表示松弛变量函数。根据此公式可得到最终的判定公式:
(16)
公式(16)中,ηi表示多特征融合系数;H(zi,z)表示线性变换函数;k′表示斜率偏移系数。
使用公式(16)得到机器英语翻译多特征融合预判结果,根据此结果设定机器英语翻译错误识别算法。
1.3 机器英语翻译错误识别算法设计
根据上述设定结果,设计机器英语翻译错误识别算法实现错误翻译的自动识别,为了使此算法具有可行性,将错误翻译结果有向图作为算法的主要参考依据,错误翻译有向图绘制如图1所示。

图1 错误翻译结果有向图
将判别过程中出现问题的翻译结果绘制为有向图的形式,同时根据错误翻译结果有向图使用传统K-近邻算法[9-10]构建机器英语翻译错误识别算法。假设错误翻译结果的标签为Z,则此标签在翻译结果特征空间中可表示为:
(17)
其中,{yi=Z}表示指示函数。根据翻译结果判别结果,将翻译结果是错误结果的概率设定为p(y=1|z),则此概率的计算公式可表示为:
(18)
公式(18)中,f(z′,o)表示翻译错误判断函数。
随着翻译时间的不断延长,翻译结果的数量会不断增加,待识别区的未知错误翻译结果的数量会逐渐增加,考虑到翻译结果标签数量问题,对公式(18)进行优化,则存在:
(19)
公式(19)中,D(z)表示标签函数。
对比2组患者生活质量以及身体功能,研究组生活质量(42.45±5.45)分,身体功能(43.85±5.89)分,参照组生活质量(33.45±4.89)分,身体功能(34.12±5.01)分,数据对比t值为6.9530,p值为0.05、t值为7.1181,p值为0.05,研究组评分高于参照组患者,组间对比具有显著性差异(P<0.05)。
根据此公式对完成判别后的翻译结果错误概率进行计算,当错误概率过高时,可认定此翻译结果为错误结果,并输出此结果。
至此,基于多特征融合的机器英语翻译错误自动识别方法设计完成。
2 实验分析
为证实本次研究中提出的基于多特征融合的机器英语翻译错误自动识别方法具有应用价值,构建实验环节对此方法的使用效果加以分析。
2.1 实验环境
在本次实验过程中,将实验平台设定为windows与linux系统,在此系统中完成原始翻译信息与扩展信息的采集与处理,实验部分将在linux系统完成。在实验过程中,使用JAVA作为实验控制语言,文件的处理与实验结果输出均使用此语言进行控制。同时,设定实验结果合并规则,对实验结果展开处理,并输出此结果。
2.2 翻译信息来源与处理
实验中的训练数据主要来源于某实验室数据库,训练数据集汇总含有5000条错误句子以及对应的5000个正确句子,这些语句均为以英语为母语者的工作人员人工标记语法错误,并改正每一处错误获得。将此部分信息组合后,构建为10个实验数据组,如表1所示。

表1 实验数据组
根据上表中内容对采集到的翻译信息进行划分,同时对词向量进行训练。使用Word2vcc工具对翻译信息进行训练,将翻译信息的词汇向量维度设定为1024,窗口大小设置为10,使用负采样优化算法将翻译信息样本数量设定为10,迭代次数设定为20次。在实验准备阶段,为保证实验结果的可靠性同时降低实验结果误差,使用以往研究中预设的翻译信息模板对训练集展开训练,并对训练集进行标注,以此实验数据的划分与处理过程。
2.3 实验指标设定
由于本次实验属于识别范畴,因此,将实验指标设定为识别效果评价指标,主要包括识别准确率、召回率与自动识别有效率。在本次实验中,将其总结为下述计算公式:
(20)
其中,θi表示正确识别的翻译错误信息;θj表示可识别翻译错误信息。
(2)识别结果召回率:表示识别方法获取到的错误翻译结果数量,如式(21)所示。
(21)
其中,θa表示需识别的翻译错误信息。
(3)自动识别有效测度:此指标表示对自动识别方法使用的有效率,根据此指标可确定识别方法的使用效果,如式(22)所示。
(22)
使用多特征融合方法对表1中的数据进行识别,并使用上述公式对识别结果进行计算,确定各指标计算结果,并对多特征融合方法使用性能进行分析。为提升本次实验结果的对比性,选择神经网络以及统计模式识别方法与文中提出的多特征融合方法进行对比分析,确定每种方法使用后的优缺点。
2.4 实验结果分析
选择神经网络以及统计模式识别方法与文中提出的多特征融合方法进行对比分析,比较了三种方法的识别准确率、识别结果召回率、自动识别有效性,结果如图2、图3、图4所示。

图2 识别准确率
由图2中显示的数据进行分析可以看出,在此指标的实验结果中体现了3种方法的使用效果,多特征融合方法识别准确度相对较高,可对多数翻译错误的信息进行识别提取。与此方法相比,其他两种方法使用后只能少量地识别到翻译错误信息,无法对实验组信息进行高精度分析与识别。在多次实验中,均体现了多特征融合方法的识别精准度高于其他两种方法。因此,可以确定多特征融合方法具有较高的使用价值。
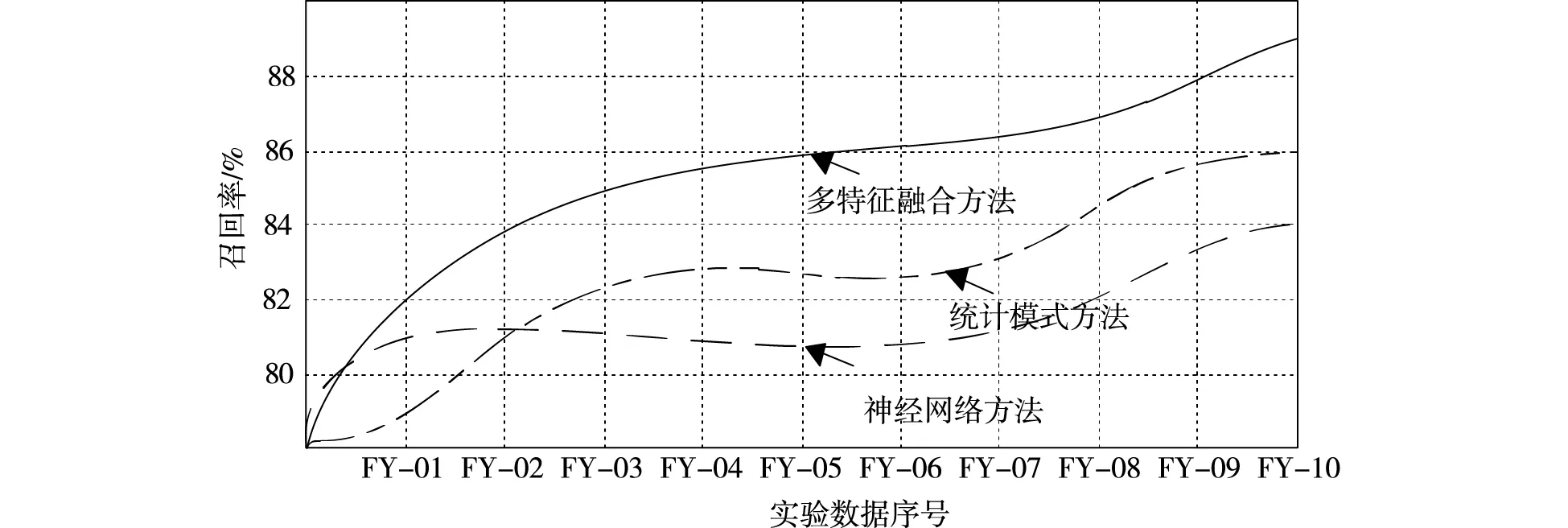
图3 识别结果召回率
在对识别准确率进行验证后,对识别结果召回率展开验证与分析。根据此实验结果可以看出,3种方法的识别召回率具有一定的差异。神经网络方法与多特征融合方法的识别结果召回率较好,可识别多种翻译信息。统计模式识别方法的识别结果召回率相对较低,无法对全部翻译信息进行识别。 因此,使用此种方法后并不能得到较高识别结果。综合上述结果,为得到最终实验结果,对不同方法的自动识别有效测度展开研究,具体结果如图4 所示。
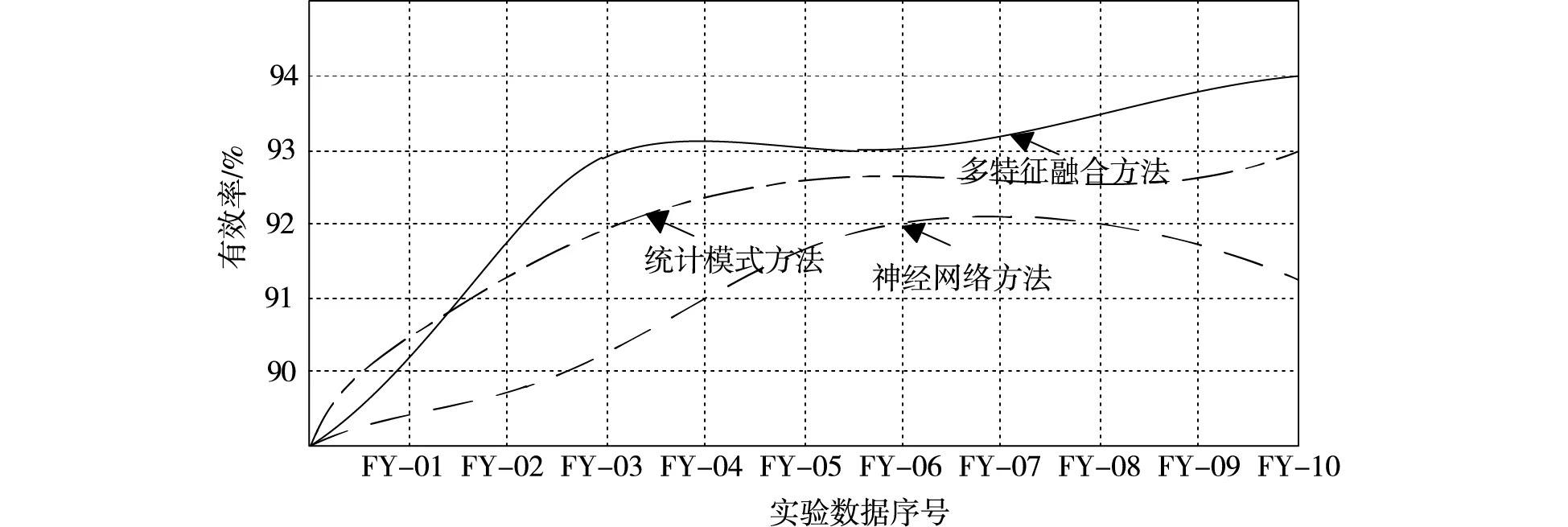
图4 自动识别有效测度结果
根据识别结果召回率与识别准确率实验结果,结合公式(22)得到自动识别有效测度结果。对此实验结果进行分析后,确定了3种方法英语翻译错误结果的识别有效率。由此实验结果可知,多特征融合方法的自动识别有效率明显优于其他两种方法,可对机器应用翻译错误进行高精度识别。因此,在日后的研究中可使用此方法完成英语翻译工作。
2.5 实验结果讨论
在本次实验中,使用识别准确率、召回率与自动识别有效测度对不同类型的自动识别方法进行分析。通过多次对比后发现,在三组实验指标中,文中提出的多特征融合识别方法为所选择实验方法中使用效果最佳的方法。由此证实了多特征融合技术,可应用在机器应用翻译错误的识别工作中。此技术应用后可有效提升识别结果的精准度与可靠性,在后续的研究中将对此方法的其他性能展开研究,并将其投入到实际问题的应用过程中。
3 结论
针对当前英语翻译结果,本文提出了一种新型翻译错误自动识别方法,经实验证实此方法具有一定的实用效果。此次将研究重点立足于识别的精准度,并没有对于其他领域展开优化。为此,在后续的研究中还需要对其他部分进行分析,针对此方法的不足进行完善与优化,以提升翻译效果,为机器翻译技术的发展提供帮助。
