基于高效通道注意力网络的人脸表情识别*
2021-12-30张红英张媛媛
韩 兴, 张红英, 张媛媛
(1.西南科技大学 信息工程学院,四川 绵阳 621010;2.西南科技大学 特殊环境机器人技术四川省重点实验室,四川 绵阳 621010)
0 引 言
面部表情是一种常见的非语言表达形式,能够有效传达个人情感和意图。随着科学繁荣和人工智能的发展,人们希望机器能够相对准确的识别面部表情达到人与机器间的交流,人脸表情自动识别在改善人机交互、远程教育、辅助医疗、驾驶疲劳监测、营销辅助等方面都有着重要的研究价值和广泛的应用空间[1]。
随着深度学习在计算机视觉领域的发展,卷积神经网络被广泛应用于人脸识别领域,并取得了优异的成绩,相比传统识别方法具有更高的识别准确率和更好的稳定性。Hu J等人[2]提出了SE-Net注意力网络,获取特征的通道依赖关系,为卷积神经网络带来显著的性能提升,Woo S等人[3]提出CBAM注意力网络,结合空间与通道注意力得到良好的识别效果,但其参数量也更加庞大。此外由于表情类间距较小,SoftMax损失函数表现不是很理想,Cai J等人[4]提出Island损失函数,增大不同表情的类间距离,结合SoftMax损失函数共同对表情特征进行监督。Li S等人[5]提出Local Proserving损失函数,缩小表情类内距离,增强非
受控环境下表情深度特征的判别能力。但卷积神经网络复杂的网络模型与难以实时性影响其进一步在实际场景的应用,且表情识别的难点在于不同表情类间差异小,相同表情的类内差距大,易受外界环境影响,因此提取出表情之间变化明显的关键特征则变得尤为重要。
针对这些问题,本文提出一种基于高效通道注意力模型与联合损失的轻量级表情识别方法,该方法基于深度可分离卷积设计新的网络,嵌入高效通道注意力模型,并提出联合损失函数提高表情判别效果。在轻量化网络模型的条件下提高识别率,实现精确快速的人脸表情识别。
1 高效通道注意力网络
1.1 改进的线性瓶颈卷积层
Howard A等人在2017年提出MobileNet[6]网络,其将传统卷积分解为两部分执行,提出深度可分离卷积,极大减少了参数的计算量并且几乎不损失精度,使网络的训练与测试时间大大减少。深度可分离卷积包括深度卷积和点卷积两个部分,传统卷积核与深度可分离卷积核的对比如图1所示。
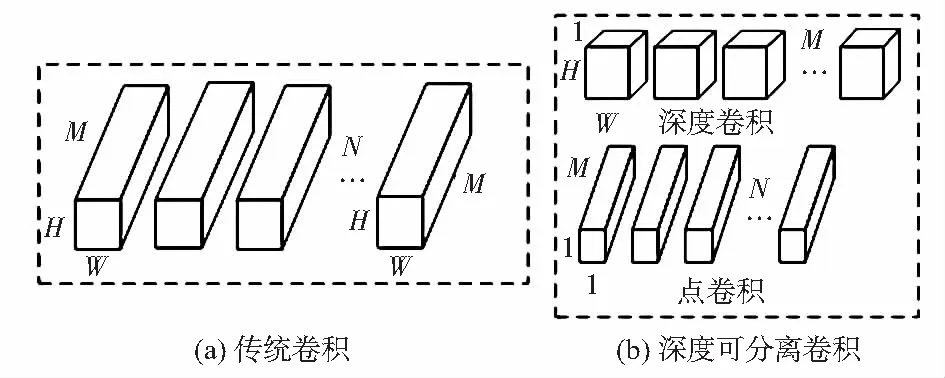
图1 传统卷积与深度可分离卷积对比
本文提出改进的线性瓶颈层以深度可分离卷积为基础,在MobileNetV3[7]的线性瓶颈层结构的基础上,对其结构进行了进一步的改进。将线性瓶颈结构中对通道进行缩放的点卷积之后的非线性激活函数ReLU部分改为PReLU[8],而使用h-swish激活函数部分则保持不变,图2为改进的线性瓶颈卷积层结构。
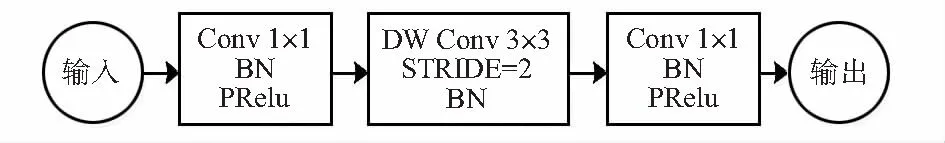
图2 改进的线性瓶颈结构
在线性瓶颈网络结构中,首先通过点卷积放缩通道,然后使用深度卷积提取特征,再使用点卷积完成线性瓶颈结构的构建,在每一个卷积层之后使用BN层防止网络过拟合,保证网络的稳定性。采用了ReLU激活函数,增加网络非线性建模能力,使网络具有稀疏性。但是ReLU函数的使用也可能导致部分神经网络失活,在大梯度流经ReLU神经元时会导致此神经元的梯度输出永久的变为零而失活,这部分的权重就无法继续更新,网络得不到学习,就会导致信息丢失。所以采用PReLU函数替代ReLU函数,其公式为
(1)
式中ai被初始化为0.25。并采用带动量的更新方式更新参数。其在负数区域会有一个很小的斜率,该区域内会进行线性预算,避免了神经网络失活状态的发生,减少了可能的信息丢失,使得后续表情特征提取更加准确,提高了表情识别的准确率。
1.2 高效通道注意力网络
为了能够从人脸表情图像深层信息中筛选出有效的特征,引入超轻量级注意模块ECA-Net[9]对改进的线性瓶颈结构的网络特征通道进行重新校准,其对识别准确率的提升效果卓越。该模块主要的作用是为每个通道生成权重并学习其相关性,将面部表情关键特征生成较大的权重,无关特征则生成较小的权重,就像加入注意力一样优先关注有用的信息,提升网络对主要特征的敏感度。图3为ECA-Net模块的结构。
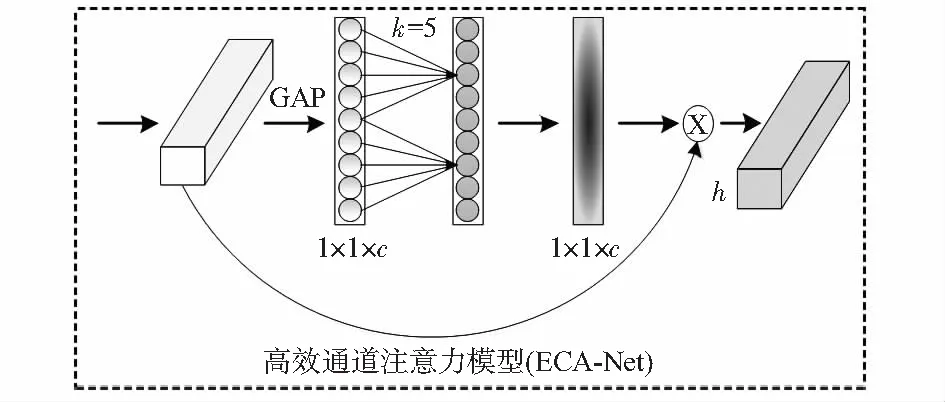
图3 ECA-Net结构
ECA-Net首先对输入的特征图的使用全局平均池化,将特征从二维矩阵压缩与提取到单个数值,然后在不降低维度的情况下通过执行大小为k的快速一维卷积来生成通道权重,获取各个通道之间的相关依赖关系,最后将生成的各个通道的权重通过乘法加权到原来的输入特征图上,将通过ECA-Net提取的特征与原本的特征的加权完成在通道空间的特征再标定。
ECA-Net通过k近邻进行局部性交互,有效减少了跨所有通道进行交互的计算量和复杂度,通过大小为k的一维卷积来为每个特征通道生成权重,获取特征通道之间的相关性,即
ω=σ(CIDk(y))
(2)
式中 CID为一维卷积,k决定了跨通道局部交互的覆盖范围,由于通道维数C大小与k成正比,得到其指数函数对应关系
C=φ(k)=2(γ*k-b)
(3)
因此,在本文给定通道维C的情况下,通过如下函数关系自适应确定参数k的大小
(4)
式中 odd为最近的奇数t。并且这里将γ和b分别设为2和1。映射函数ψ为通道维数越大则k越大,跨通道局部交互的范围也就越大。
基于改进的线性瓶颈结构与高效注意力网络模型如图4所示,在线性瓶颈结构的深度卷积层后嵌入高效注意力网络结构,将深度卷积提取的特征权重重新加权,接着通过点卷积完成通道的缩放,并加入快捷连接层构成倒置残差结构,在减少网络结构的同时防止网络过拟合,最终基于线性瓶颈与倒置残差构成高效通道注意力网络。
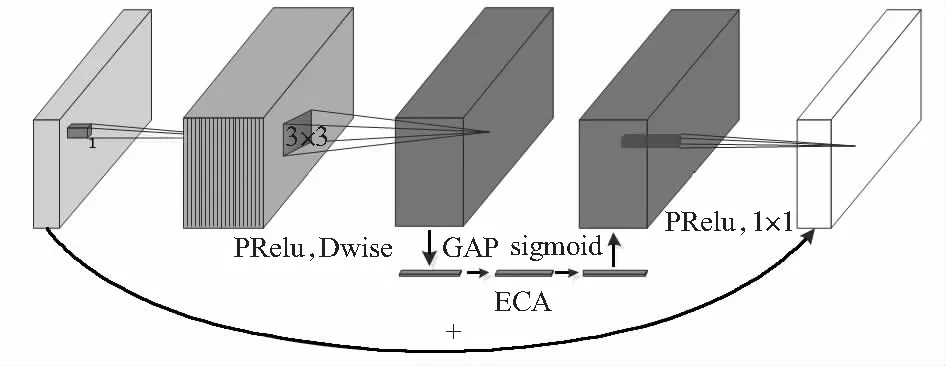
图4 高效通道注意力网络
本文设计的高效通道注意力网络结构如表1所示,网络的输入尺寸为96×96×1,其中Benck为改进的线性瓶颈模型,ECA为高效通道注意力模型,PRE为PRelu激活函数,HS为H-Swish激活函数,根据表情识别特点设计出如下网络结构,在保持网络轻量级的同时提升网络识别率。
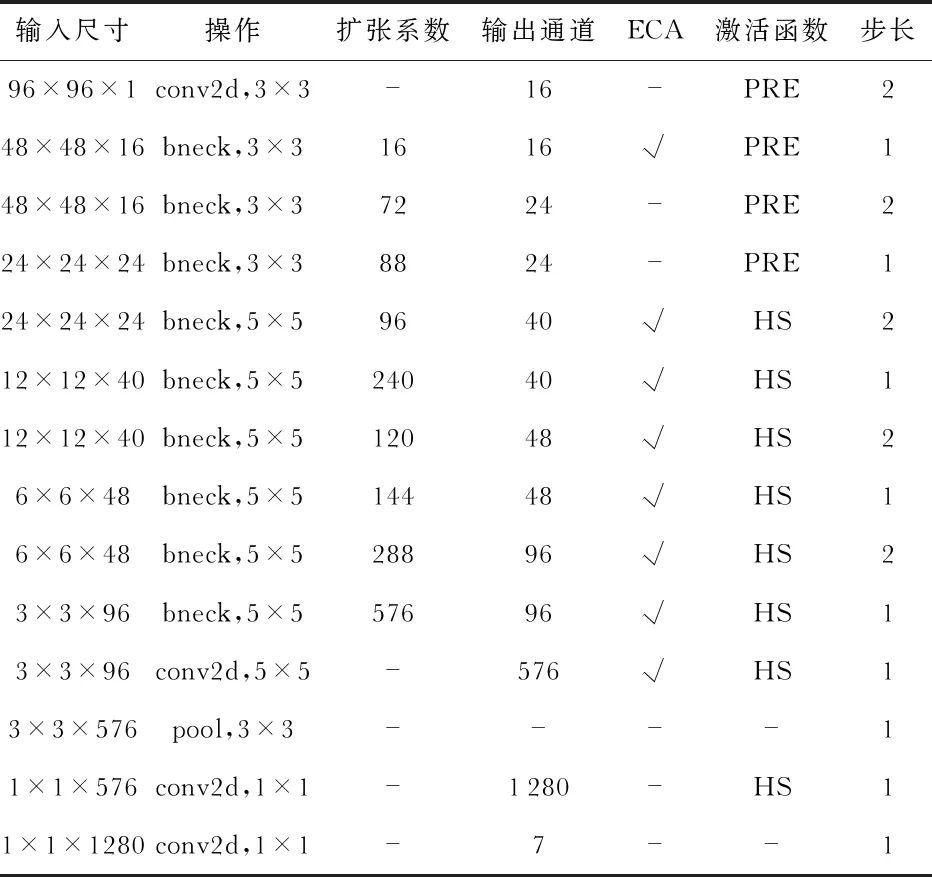
表1 高效通道注意力网络结构
1.3 联合损失函数
在传统的卷积神经网络中,SoftMax损失函数在表情识别领域表现的不是很理想,在现实生活的场景中,人脸表情不仅在类间的相似度很高,类内的差距也很大。因此本文采用联合损失函数,使用Center loss[10]用于加强类内距,改进对比损失用于改进类间的分离度,SoftMax loss保证分类的准确,联合不同损失函数特点,提高人脸表情的识别效果。
首先通过Center loss得到类中心位置,Center loss根据下式更新类中心
(5)
(6)
式中γ为学习率,t为迭代次数,δ为一个条件函数,如果条件满足则δ=1,如果条件不满足则δ=0。
得到类中心位置后,将不同类中心位置的距离通过设置的阈值进行损失的更新,改进类间的分离度,其公式为
(7)
式中D为一个批次的类数目ci和cj分别为第i类和第j类的中心,M为指定的阈值,这里设置为100。
最后得到联合损失函数公式如下
L=LS+αLC+βLH
(8)
式中α,β为更新损失函数的超参数,本文设置为4,3。
2 实验与结果分析
2.1 数据集选取及实验设置
实验中用到了两种数据集:CK+和FER—2013。网络在训练时参数更新策略采用带动量优化的随机梯度下降优化器,总共需要迭代300个批次,动量设置为0.9,每个批次的数据量设置为128,初始学习率设置为0.01,并且前80个批次的学习率保持不变,当超过80个批次后按照0.9的衰减率对学习率进行更新。
2.2 注意力模型对比试验
为了验证基于高效通道注意力模块的有效性,将改进的线性瓶颈网络作为基础网络Basis,与嵌入注意力模型SE,CBAM,ECA在FER—2013数据集上进行对比实验,并将ECA-Net的参数k手动选取3,5,7,9的值与自适应k值进行对比测试其影响。由图5可知,在相同实验参数的情况下,ECA模型手动选择k数值的识别率均低于自适应k值,验证了自适应k大小方法的有效性。嵌入注意力模型的网络相对基础网络的识别率均有明显的提升,嵌入ECA模型识别率高于CBAM模型和SE模型,准确率相比基础网络提高了1.2 %,且ECA模型的参数数量小于SE与CBAM模型,因此本文的高效通道注意力模型具有更轻量的网络模型与更好的识别性能。
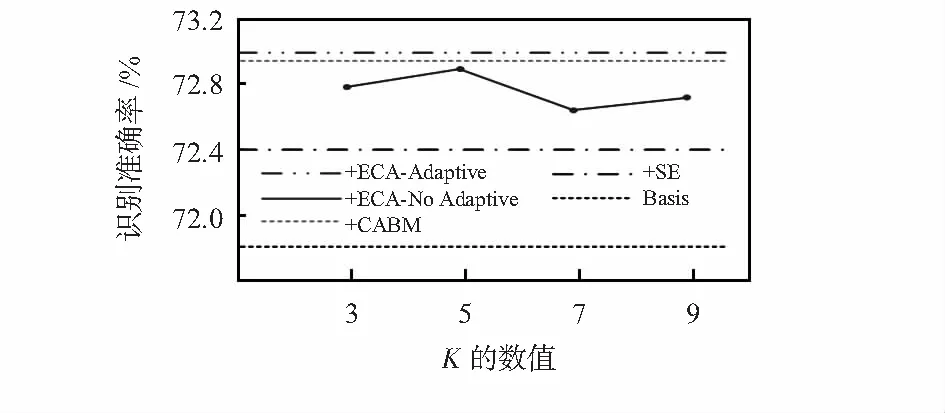
图5 注意力模型对比结果图
2.3 模块有效性验证试验
本文验证了改进线性瓶颈层,高效通道注意力,联合损失函数三个模块的有效性,实验结果如表2所示,其中Base是不加任何改进与注意力模块的基础网络,PR表示改进线性瓶颈层,ECA表示高效通道注意力模块,将各个模块分别进行对比实验,结果显示改进线性瓶颈层,嵌入ECA注意力模块与使用联合损失模块都能够有效的提升表情的识别准确率,而在使用改进线性瓶颈层加高效通道注意力模型加联合损失模块的组合时准确率提升最为显著,在FER—2013与CK+上与基础模块相比准确率提升了1.9 %和3.1 %,说明这三个模块能够共同促进表情特征的学习,明显的改进表情识别的性能,从而验证了本文方法的有效性。
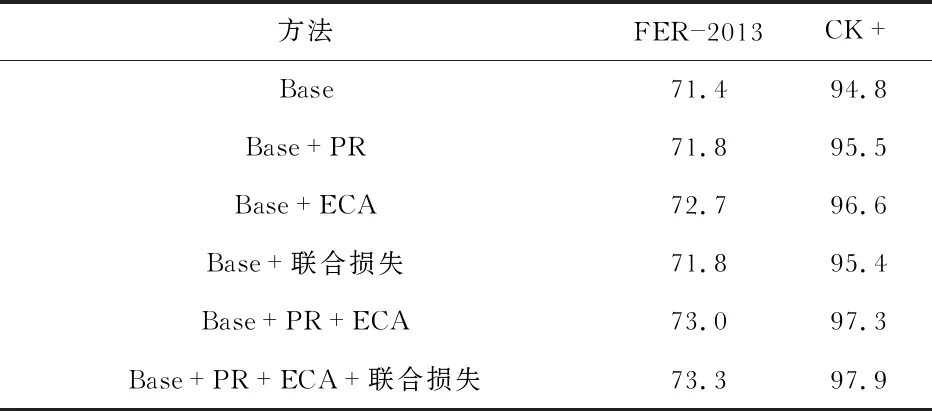
表2 不同模块识别率对比
2.4 不同方法对比试验
为了验证本文整体算法的可靠性,本文在FER—2013与CK+数据集上同当前先进的表情识别网络进行了对比实验验证。以此评估本文算法的性能。表3是不同方法在FER—2013与CK+数据集上的识别率对比,在FER—2013与CK+数据集上分别取得了73.3 %与97.9 %的更高识别率,本文方法取得了相较其他主流方法更优越的性能。
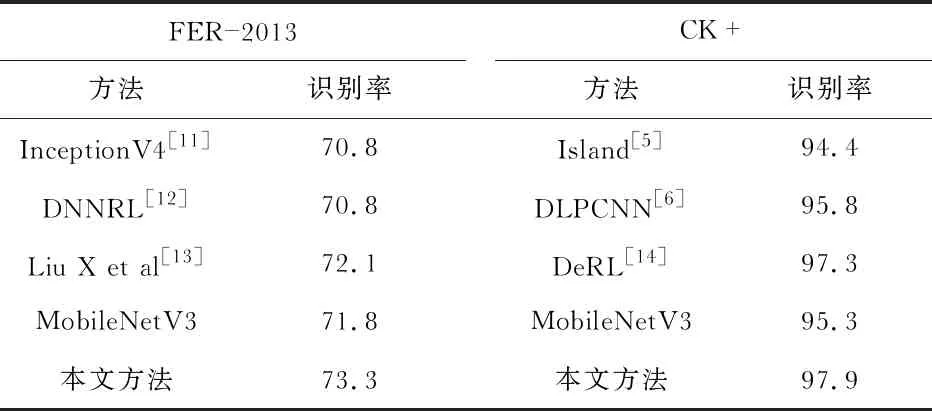
表3 与其他方法在识别率对比
3 结 论
基于深度可分离卷积改进线性瓶颈结构采用注意力模块将网络特征通道进行重新校准,加强重要表情特征作用,减少无用特征干扰,使用联合损失函数提高了网络对于人脸表情的识别准确率。实验结果表明,本文模型不仅能够更稳定地识别出七种基本的表情,而且能够满足实时性要求,识别速度达到90帧/s以上。
