基于手机加速度传感器的人体步态识别研究*
2021-12-30段小虎留沧海
段小虎, 蒋 刚, 留沧海
(西南科技大学 制造科学与工程学院,四川 绵阳621000)
0 引 言
运动状态识别为解决运动监测提供了技术基础,建立一种有效的人体步态识别方法,推断人的运动状态,进而评估人的运动状态,给人们提供运动建议,引导人们制定健康计划[1]。目前人体步态识别的研究主要有以下两种途径:1)基于图片或视频的运动状态识别[2,3],通过摄像头采集人行走时的不同步态图像进行分类,这类技术可以应用于户外公共场所和室内监护,对摄像头的布置比较敏感,不能实现对个体长时间的运动步态的跟踪识别。杨文璐等使用Kinect传感器建立下肢康复动作评估系统,识别和引导受试者的康复动作[4]。2)基于传感器的行走步态识别[5],通过带有心率、加速度等传感器的可穿戴设备,对个体行走步态的24 h跟踪识别。张乾勇等设计了一种基于加速度信息与脚底压力的下肢运动信息采集系统,对4种常见行为(走路、跑步、上楼和下楼)进行识别[6]。基于传感器的行走步态识别可以看作是一个时间序列分类问题,常用的算法有决策树[5]、K最近邻(K nearest neighbour,KNN)[7]、支持向量机(support vector machine,SVM)[8]、神经网络[9,10]等。
随着深度学习的发展,深度学习算法已被应用于模式识别的研究中,Zhan L等人使用深度神经网络替代人工提取步态特征进行步态识别[11]。Sainath T N等人使用卷积神经网络(convolutional neural network,CNN)和长短期记忆(long short term memory,LSTM)组合模型,用CNN提取语音抽象特征,LSTM进行特征分类,取得了较好的效果[12]。张加加等人使用CNN与SVM融合的方法识别步态图片[13]。深度学习虽然有较好的识别率,但其计算量较大,目前的便携设备如手机等难以满足深度学习算法的计算量。随着智能手机的大规模普及,利用手机中内置的传感器识别人的日常行为具有可行性和应用前景[14]。
本文采用手机加速度传感器采集的数据,首先对数据集进行预处理和特征提取,再采用SVM、KNN和随机森林算法对样本的6种类别进行训练、测试和验证。
1 加速度数据的获取与数据预处理
1.1 加速度数据的获取
本文的数据集是福坦莫大学无线数据挖掘实验室的公开数据集[15],该数据集使用手机加速度传感器采集,共收集了步行、慢跑、上楼梯、下楼梯、静坐、站立6种步态,数据采样频率是20 Hz,采集过程中手机放在大腿的便携包里。手机的坐标轴方向和放置位置如图1左图所示,手机的放置方向固定,手机X轴、Y轴的放置方向如图1右侧所示,Z轴指向前进方向。
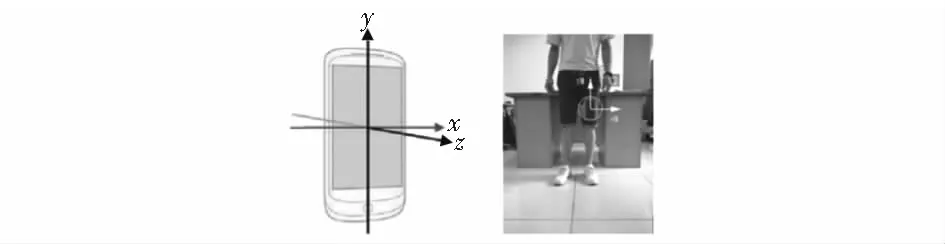
图1 手机的坐标轴方向和放置位置
该数据集收集的样本数量为1 098 212条,使用Python选取其中224 920条数据。6种步态的加速度传感器波形如图2所示。
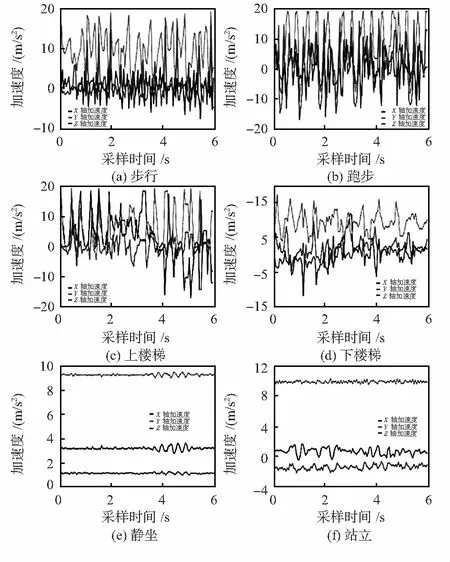
图2 6种步态的加速度传感器波形
6种步态具有较为明显的特征。
1.2 数据预处理
数据预处理主要包括数据平滑和数据分窗。
数据平滑使数据特征更加明显并过滤噪点。使用2次三点均值平滑,公式如下
(1)
式中xi为传感器某一轴的加速度值,xi+1,xi+2,xi+3,xi+4分别为之后加速度传感器的4次采集值。采用2次三点均值平滑后,采样点会减少4个,不影响总体数据分布。平滑后的步行波形如图3所示。
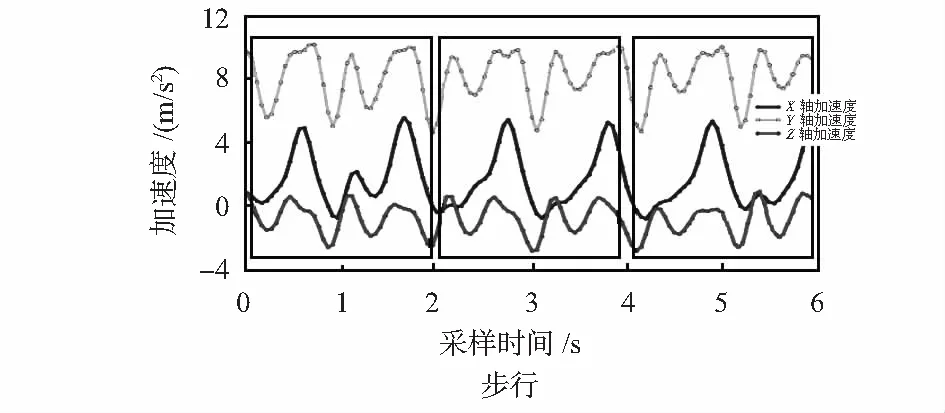
图3 原始数据平滑和加窗
采集到的数据为时间序列数据,通过分窗把数据分组,以便对窗口内的数据进行特征提取。文献[12]使用10 s的窗口,识别会有延迟,考虑到手机步态识别的实时性和健康人行走一步所需要的时间为0.4~0.6 s[16],本文选取的窗口大小为2 s。窗口含有的数据量为40条,原始数据分窗后共产生5 623个窗口,如图3为在平滑后的数据上加窗。
2 统计特征的提取
为了使用机器学习算法进行分类,需要人工提取特征。本文使用时域上的加速度作为样本,提取均值、标准差、轴间的相关系数共9个特征。方差:X轴、Y轴、Z轴的方差,共3个;均值:X轴、Y轴、Z轴的平均值,共3个;相关系数:XY轴、YZ轴、XZ轴的相关系数,共3个;以一个窗口的40条数据作为一个样本,统计9个特征。
X轴加速度的均值E(X)、方差σ(X)以及和Y轴的相关系数Corr(X,Y)计算如下
(2)
(3)
(4)
特征提取之后,步行所对应的样本数量为2 322条,慢跑为2 013条,上楼梯为586,下楼梯为310,静坐为52,站立为 40条,样本分布并不均衡,对于非均衡问题使用混淆矩阵和AUC评估。
3 分类算法的选择
本文采用SVM、KNN和随机森林算法进行分类和对比,使用Scikit-learn作为算法构建工具。
3.1 分类性能度量指标
常用分类性能度量指标有正确率,混淆矩阵、受试者工作特征曲线(receiver operating characteristic curve,ROC)曲线。
正确率是指在所有测试样例中错分的样例的比例。计算如下
(5)
正确率掩盖了样本如何被分错的事实,混淆矩阵能更好地帮助人们了解分类中的错误。本文使用多分类混淆矩阵。
ROC曲线是另外一个度量分类中非均衡问题的工具。对于不同的ROC曲线进行比较的一个指标是曲线下的面积,简称AUC。AUC能够给出分类器的平均性能,一个完美分类器的AUC为1,而随机预测的AUC为0.5。
3.2 SVM算法实验结果分析
使用70 %的样本对SVM算法进行训练,使用的核函数为线性核与高斯核。线性核函数的惩罚参数为C,C值大则对分类误差的惩罚增大,C值小则对误分类的惩罚减小。所以最小化目标函数包含两层含义:使‖w‖2/2尽可能的小,也就是间隔尽可能大,同时使分类点的个数尽可能的少。
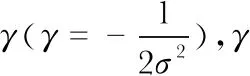
3.2.1 线性核函数的分类实验
使用线性核函数,选用不同C,使用十折交叉验证得出C和准确率的关系如图4所示。
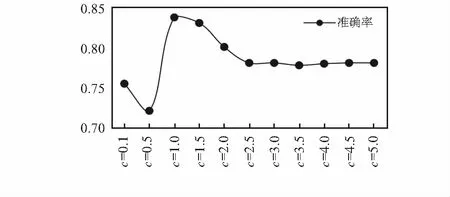
图4 C和准确率的关系
当C值选取到1.0时,平均准确率较高。使用C=1.0作为参数,取30 %的样本作为测试集,生成的混淆矩阵如表1所示,平均准确率为82.5 %。
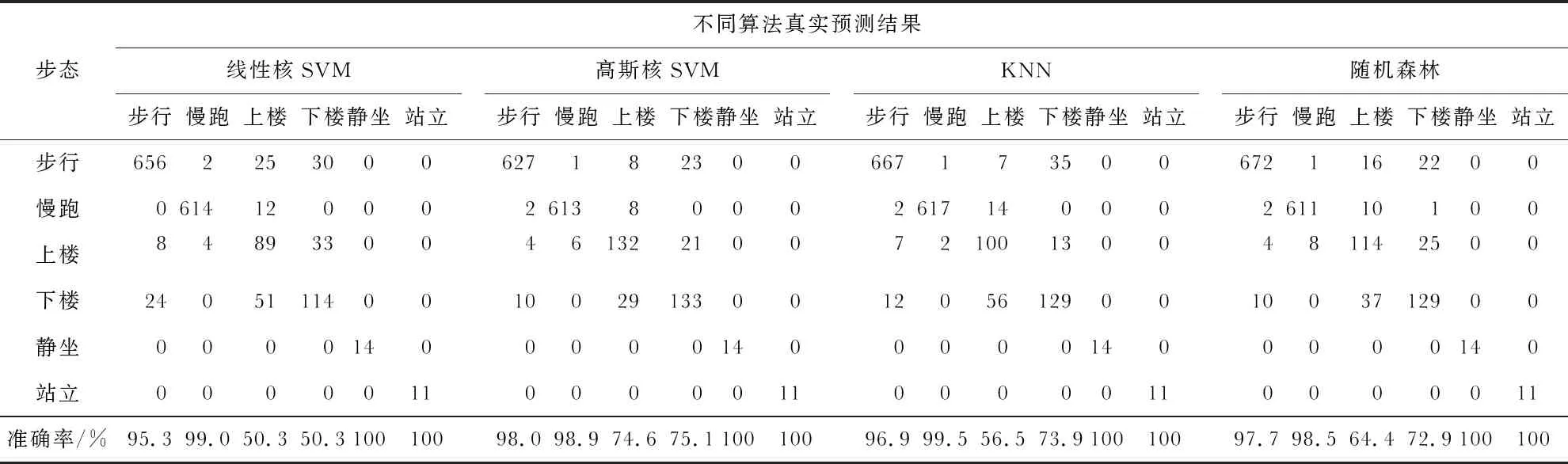
表1 不同算法的混淆矩阵
3.2.2 高斯核函数的分类实验
选用不同C和γ,使用十折交叉验证得出高斯核函数SVM模型的C和γ与准确率的关系如表2所示。
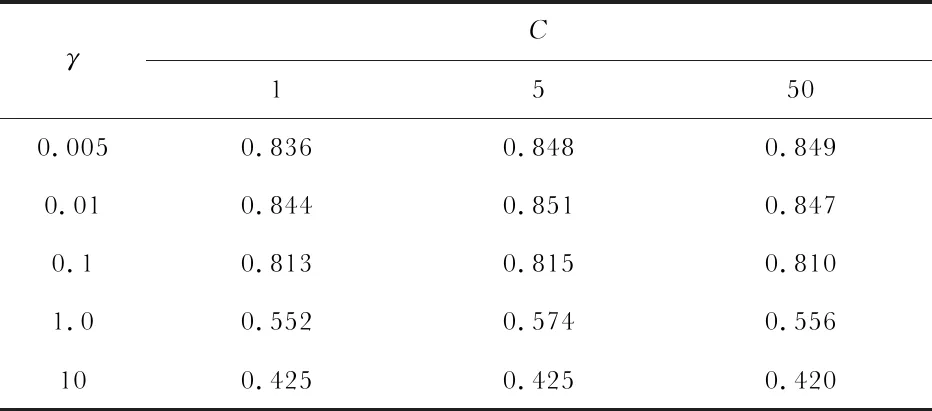
表2 C和γ与准确率的关系
C对准确率的影响较小,γ对准确率的影响较大,所以重点关注γ值的选择。取C=5,从0.005到10遍历γ值之后,得出最优γ值为0.01。使用30 %的数据作为测试集,得到的混淆矩阵如表1所示,平均准确率为91.1 %。
3.3 KNN算法的分类实验
KNN算法主要考虑2个要素:K值的选取和分类决策规则。K值表示距离待分类样本距离最近的K个样本。本文通过交叉验证选择一个合适的K值。对于分类决策规则,一般使用多数表决法[18]。取30 %的样本作为测试集,选择K值为4,得到混淆矩阵如表1所示,平均准确率为78.3 %。
3.4 随机森林算法的分类实验
常见的决策树算法有 ID3、C4.5、CART[19]。本文用随机森林算法建立多棵CART算法决策树,针对每棵决策树,从5 623个样本中随机有放回的抽取n个样本,并从9个特征中随机选取k个特征,建立决策树。重复100次,建立100棵决策树,通过投票决定步态样本的类别。取30 %的样本作为测试集,得到的混淆矩阵如表1所示,随机森林算法的平均准确率为88.9 %。
各个分类算法的准确率、AUC和测试集计算时间如表3所示。
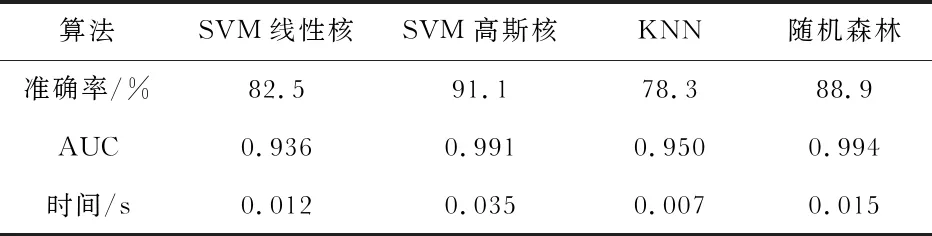
表3 算法的准确率、AUC和测试集计算时间
可以看出,以三轴加速度的平均值、方差和相关系数作为特征的模型,平均准确率达到80 %以上,但上下楼梯的准确率较低。仅以数据集作为训练和测试难以说明实际中运用手机加速度传感器进行步态识别的效果,本文接下来设计了验证实验。
4 实验验证
为了验证特征提取的有效性,本实验利用实际生活中的场景进行验证,用手机采集加速度,采集界面如图5所示。

图5 采集界面
每种步态各采集了4 000条数据组成了100个样本。得到不同算法的准确率百分比如表4所示。
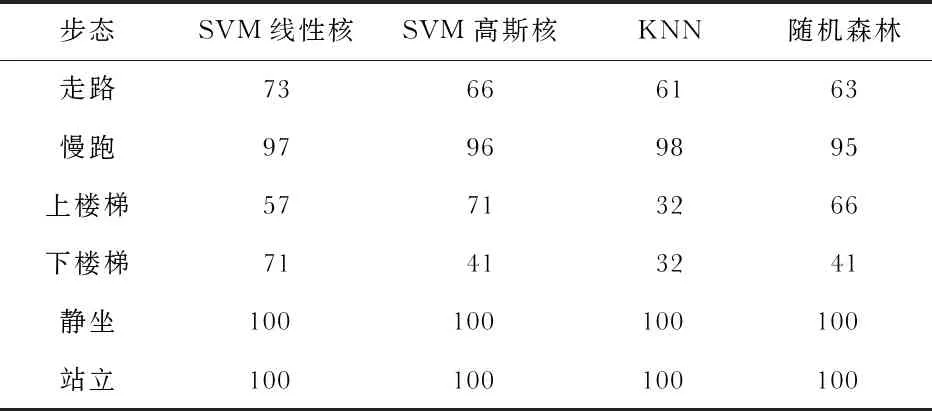
表4 不同算法的准确率百分比 %
验证实验的准确率并没有测试集高,尤其是上楼梯和下楼梯的准确率较低,一方面是因为无法保证实验设备和实验场地与WISDM数据集完全相同;另一方面实际生活中上下楼梯时在楼梯的转折处存在平地,导致上楼梯时会被误识别为下楼梯,下楼梯时会被误识别为走路或慢跑。以识别效果较好的SVM线性核为例,上楼梯的准确率为57 %,识别错误的样本中37 %被误识别为下楼梯,6 %被误识别为步行;下楼梯的准确率为71 %,识别错误的样本中9 %被误识别为上楼梯,12 %被误识别为慢跑,8 %被识别为步行。
站立和静坐的状态很好识别,因为这两种活动的加速的几乎不会变化。结果表明四种算法中相对表现较好的为两个SVM算法。
5 结 论
本文提出了一种基于加速度传感器的人体步态识别方法,使用常用的统计量作为模型特征,设计了4个算法模型来进行实验,能够较好地识别步行、慢跑、静坐、站立4种行走状态,但对上下楼梯的识别效果一般。算法的平均正确率达到80 %以上,并进行了实验验证,说明了本文提出的特征提取及识别算法方法的有效性。另一方面,测试集的计算时间较短,与文献[18]等提取步态峰度,偏度,峰值强度等特征[20]和文献[10]等深度学习方法相比,本文特征提取方法较简单和模型计算量较小。
