中国人工智能发展水平、区域差异及分布动态演进
2021-12-30吕荣杰郝力晓
吕荣杰,郝力晓
(河北工业大学 经济管理学院,天津 300401)
0 引言
科技是国之利器。2020年10月29日,中国共产党第十九届中央委员会第五次全体会议审议通过了《中共中央关于制定国民经济和社会发展第十四个五年规划和二O三五年远景目标的建议》,科技创新首次在五年规划中单独成章,并置于各项重点任务之首。当前,人工智能已成为引领未来的战略性技术,是各国力图在新一轮国际科技竞争中掌握主导权的着力点。中国在人工智能领域已经取得一定进展,主动掌握人工智能发展情况,研判大势,把握方向,对战略层面的系统研发布局至关重要。因此,本文研究的核心问题是:如何测度人工智能发展水平?我国人工智能发展的空间分布特征和时间演进趋势如何?上述问题的解决,可以为研究人工智能对经济社会的影响提供实证依据,为掌握我国人工智能整体发展格局,推动高质量发展和区域协同发展提供政策依据。
测度人工智能发展水平是一个新问题,但关于技术创新评价的研究由来已久。已有文献主要使用评分模型、增长模型、访谈调查法、问卷调查法和构建指标体系法对技术水平进行衡量。其中,评分模型[1-2]是针对某一个具体产品或设备进行评分,而本文涉及的人工智能作为一个技术领域,包含众多产品类型,甚至细分技术领域,因而评分模型不适用于本研究;增长模型[3-6]是通过设置技术上限,动态预测技术发展趋势,而本文研究对象是当前人工智能发展情况,属于静态下的技术状态研究;访谈调查法主要是运用专家默会知识对技术发展现状进行评估,主观和定性方法很难准确评估多个省份多年来的人工智能发展水平面板数据;问卷调查法[7-8]是针对企业进行微观数据调查,微观数据有助于研究人工智能应用对调研企业发展的影响,但容易忽略宏观经济重新配置的情况,也很难反映中国人工智能整体发展格局;构建指标法是通过利用多个客观数据,从多个方面对当前技术状态进行测量,该方法对于产品种类较多、缺乏直接统计数据的人工智能来说,是最优选择。
鉴于此,本文构建人工智能发展评价指标体系,测度我国人工智能发展水平。在此基础上,利用Dagum基尼系数和核密度估计探究我国人工智能发展的地区差异。首先,基于2003—2018年我国内地30个省份(西藏因数据不全,未纳入统计)数据,利用熵权法测度我国人工智能发展水平;其次,采用Dagum基尼系数测算我国人工智能总体差异并对其进行分解,探究差异来源及贡献;再次,采用Kernel核密度估计法分析四大区域及各区域内部人工智能发展的动态演进,进一步揭示我国人工智能发展分布动态规律;最后,总结研究结论,给出具体政策建议。
1 指标体系构建
已有文献对构建技术创新能力评价指标体系开展了卓有成效的研究,并取得了可观的研究成果。然而,作为一个具体技术领域,人工智能发展评价指标体系的研究仍处于初始阶段。
技术创新能力评价一般采用单一指标或多指标构建两种方法。单一指标法是指直接采用研发投入、专利申请量、技术市场成交额或新产品销售额等指标衡量创新能力[9-10],但事实上,单一指标有时难以准确反映技术创新能力,如技术研发投入常常与技术创新产出不对等,专利申请量与转化为实际生产力的专利量相差甚远。因此,单一指标法的优点在于指标含义清晰、数据易于收集与整理,缺点是具有局限性和片面性。多指标构建法是指综合运用多个指标对企业和地区技术创新能力进行评价。企业技术创新能力评价指标体系主要包括投入、产出和组织环境3个维度,其中产出往往包括技术创新产出[11]和生产制造产出[12-13],组织环境主要包括决策能力[14]、企业控制力[15]和营销能力[16]等。对于区域或国家技术创新能力评价指标体系构建,《国家创新指数报告2018》从创新资源、知识创造、企业创新、创新绩效和创新环境5个方面对全球40个国家创新能力进行评价;陶长琪和周璇(2016)基于创新能力系统观,从技术溢出、环境—技术耦联、环境规制角度对省域技术创新能力进行评价。可见,要素禀赋、产出能力和外部环境是评价企业和区域技术创新能力的主要维度。
目前采用多指标方法构建人工智能发展评价指标体系的研究较少。Ding[17]、陈明艺和胡美龄[18]认为,硬件、教育科研、数据是推动人工智能发展的组成要素,并从这3个维度构建人工智能发展评价指标体系。该指标体系反映了人工智能发展的基础条件,但忽略了人工智能的生产和应用。孙早和侯玉琳[19]从基础建设、生产应用、竞争力与效益3个方面对工业智能化进行衡量,并基于 “信息化基础+信息化应用+信息化绩效” 思路,认为工业化与信息化融合会带来绩效提升,因而在竞争力与效益指标中包含经济绩效和社会绩效两个基础指标,经济效益和社会效益越好,则工业化与信息化融合越好。对本研究而言,人工智能发展带来的效益尚不明朗,仍是学者们正在探讨的问题[20-23]。因此,选择社会和经济发展程度反映人工智能发展水平,并不适用于本研究。
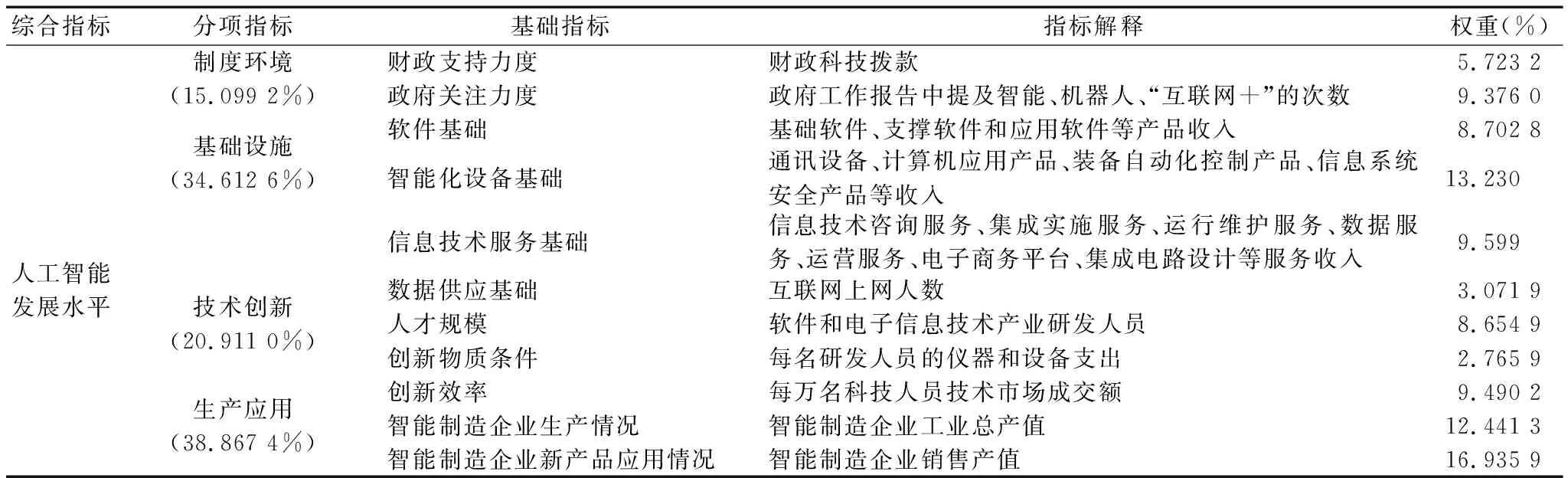
综上,本文基于技术创新评价理论框架,结合工业智能化评价指标体系,构建人工智能发展测度指标,包括制度环境、基础设施、技术创新和生产应用4个维度,共涉及财政支持力度、政府关注力度、软件基础、智能化设备基础、信息技术服务基础、数据供应基础、人才规模、创新物质条件、创新效率、智能制造企业生产情况、智能制造企业新产品应用情况11个基础指标(见图1)。鉴于实证分析需要和数据可得性,本文选择的测度指标不可能全面概括人工智能发展涉及的方方面面,而是尽可能在可行范围内最大程度反映人工智能发展水平。
本文指标体系遵循樊纲[24]构建市场化指数的两个基本原则。首先,由于每个分项指标只能从某一特定角度反映人工智能的应用,本文从不同角度对上述分项指标均采用两个及以上基础指标进行度量,选择的每个指标至少能在一定程度上、一定时期内近似地反映人工智能发展情况。其次,选择的指标必须是可度量的,而且能够获得具体数据。有些指标虽然理论上可行,但缺乏数据来源,则宁可暂缺,避免以主观判断代替客观度量。在某些情况下,虽然能够获取数据,但经过验证发现其可信度较低,也尽量避免使用。指标具体定义如下:
(1)制度环境。制度环境是指人工智能发展的外部软环境,本文使用财政支持力度和政府关注力度两个指标进行测度。财政支持是国家财政以无偿拨付的方式,如财政拨款、财政补贴等,对政府扶持的产业、部门或企业进行资金方面的支持。由于缺乏政府对人工智能产业资金支持的具体统计数据,本文依据李旭辉等[25]的做法,选用科技拨款作为测度指标。政府重视是保障产业长期稳定发展的法规基础,智能、“互联网+”、机器人等在政府工作报告中出现的次数能够反映政府在制度建设上对人工智能发展的重视程度。
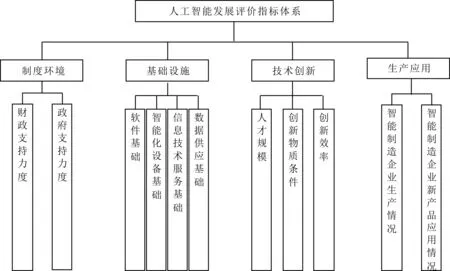
图1 人工智能发展评价指标体系
(2)基础设施。基础设施是指人工智能发展的外部基础建设情况。本文从软件基础、智能化设备基础、信息技术服务基础和数据供应基础4个方面对基础设施进行测度。软件基础的测度指标是基础软件、支撑软件、应用软件等软件产品收入;智能化设备基础的测度指标为通讯设备、计算机应用产品、装备自动化控制产品、信息系统安全产品等营业收入;信息技术服务基础的测度指标为信息技术咨询服务、集成实施服务、运行维护服务、数据服务、运营服务、电子商务平台服务、集成电路设计等服务收入;数据供应基础的测度指标为各省份互联网发展水平,用互联网上网人数衡量。
(3)技术创新。技术创新是指企业发展人工智能的内部环境,主要包括人才规模、创新物质条件和创新效率3个基础指标。由于缺乏人工智能相关直接数据,本文用软件与电子信息技术产业研发人员表征人才规模,用每名研发人员拥有的仪器和设备支出测度创新物质条件,用每万名科技人员技术市场成交额表征创新效率。
(4)生产应用。生产应用是指人工智能产出与应用水平,主要包括智能制造企业生产情况和新产品应用情况两个基础指标。智能制造企业生产情况的测度指标为计算机、通信及其它电子设备制造业,仪器仪表制造业,电器机械及器材制造业,专用设备制造业等企业主营业收入;新产品应用的测度指标为上述企业的销售产值。
2 数据来源与模型构建
2.1 数据来源
中国人工智能发展并不是最近几年才开始的,早在1989年,我国就召开了首次中国人工智能联合会议,进入21世纪后,与人工智能相关的课题不断获得国家重点和重大基金计划支持。综合考虑中国人工智能发展阶段和相关数据的可得性,本文最终确定样本区间为2003—2018年中国内地30个省份面板数据。其中,财政支持力度、创新物质条件和创新效率等数据来自《中国宏观经济数据库》,政府关注力度数据来自省级政府工作报告,软件基础、智能化设备基础、信息技术服务基础、人才规模等相关数据来自《电子信息产业统计年鉴》,数据供应基础数据来自《中国统计年鉴》,智能制造企业生产情况和新产品应用情况等相关数据来自《中国科技数据库》。考虑到样本时间跨度较长,本文按照最近邻法思想对缺失值和异常值进行修正。
2.2 模型构建
2.2.1 熵权法
作为客观赋值方法,熵权法是根据指标离散程度判断其对综合评价的影响,熵权法仅依赖数据本身的离散性,能够避免权重赋予时可能存在的主观性,具有一定数学意义。本文将2003—2018年全部数据设为基础数据,对权重进行测算。
首先,建立指标矩阵,假设人工智能发展评价指标体系中有m个指标,n个评价对象,可以得到多指标矩阵X=(xij)m×n。其中,xij表示第j个被评价对象的第i个指标值。其次,将指标矩阵标准化,为规避量纲不一致带来的影响,本文采用临界值法对指标矩阵X=(xij)m×n进行标准化处理,得到S=(sij)m×n。然后,计算熵和熵权,第i个评价指标的信息熵计算公式为:
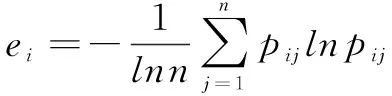
(1)
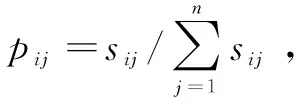
第i个评价指标的熵权wi计算公式为:
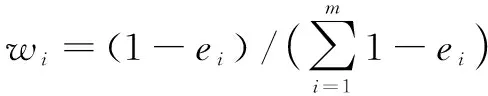
(2)
最后,计算各被评价对象的综合得分。
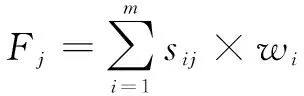
(3)
2.2.2 Dagum基尼系数
传统方法无法解决地区差异中的分解和样本描述问题,而Dagum基尼系数及其分解方法能够有效弥补这一欠缺。因此,本文采用Dagum基尼系数及其子群分解方法,对中国人工智能发展水平区域分布差异进行分析。根据Dagum[26]的分解理论,总体基尼系数(G)可以分解为区域内差异贡献(Gw)、区域间差异贡献(Gnb)和转移变异贡献(Gt),其测度结果可以反映人工智能发展水平的相对差异及其来源情况。
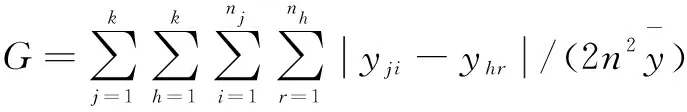
(4)
G=Gnb+Gw+Gt
(5)
第j个区域的基尼系数Gjj和区域内差异贡献Gw可表示为:
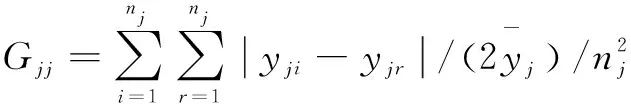
(6)
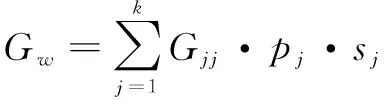
(7)
j、h区域间基尼系数Gjh可表示为:
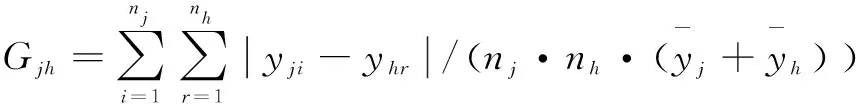
(8)
j、h区域间差异贡献Gnb可表示为:
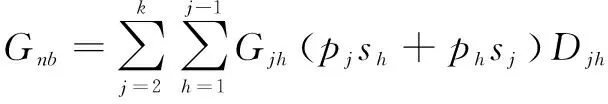
(9)
转移变异贡献Gt可表示为:
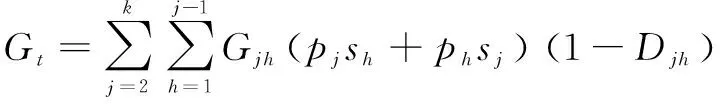
(10)
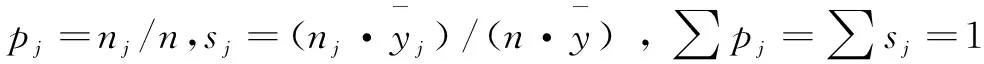
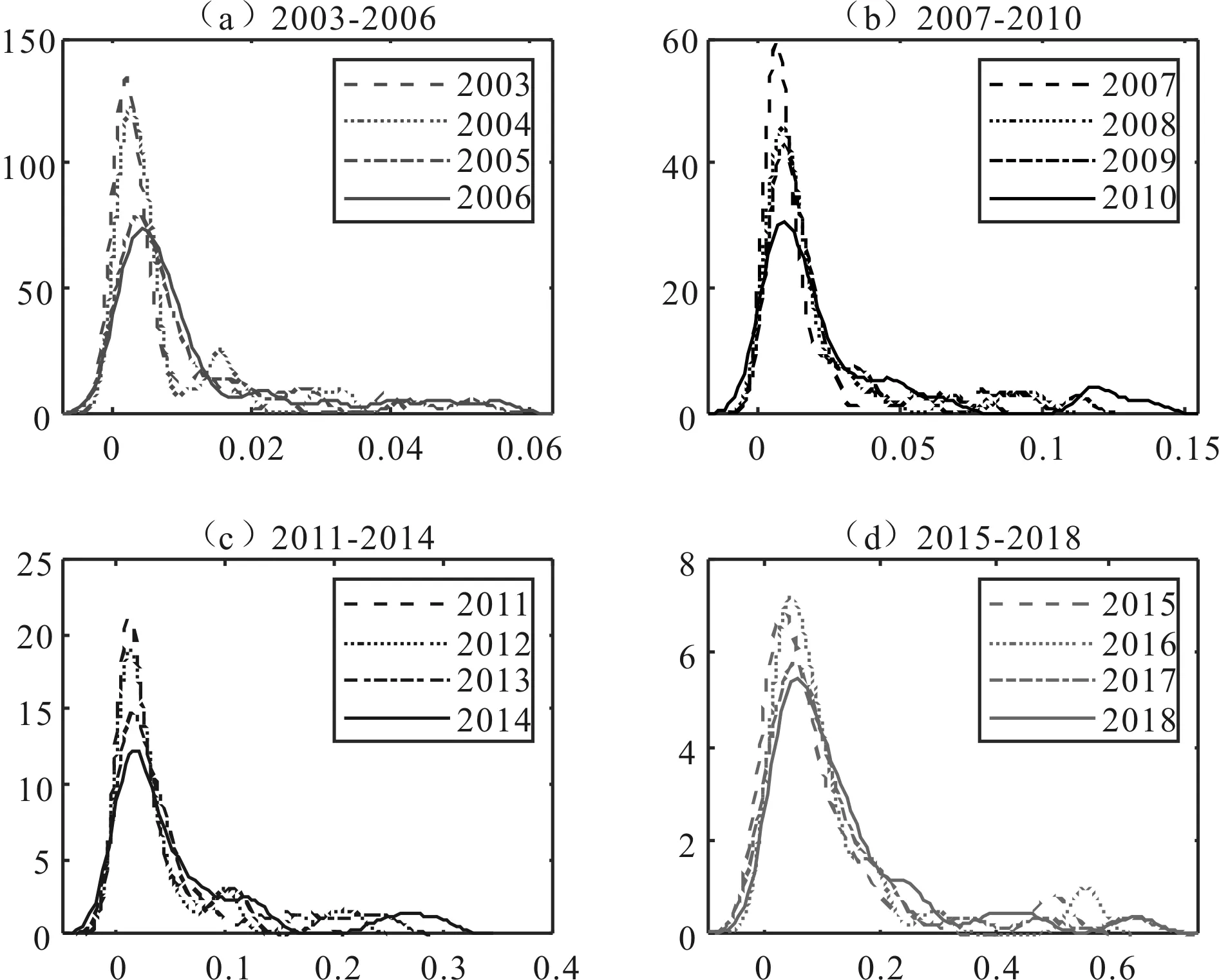
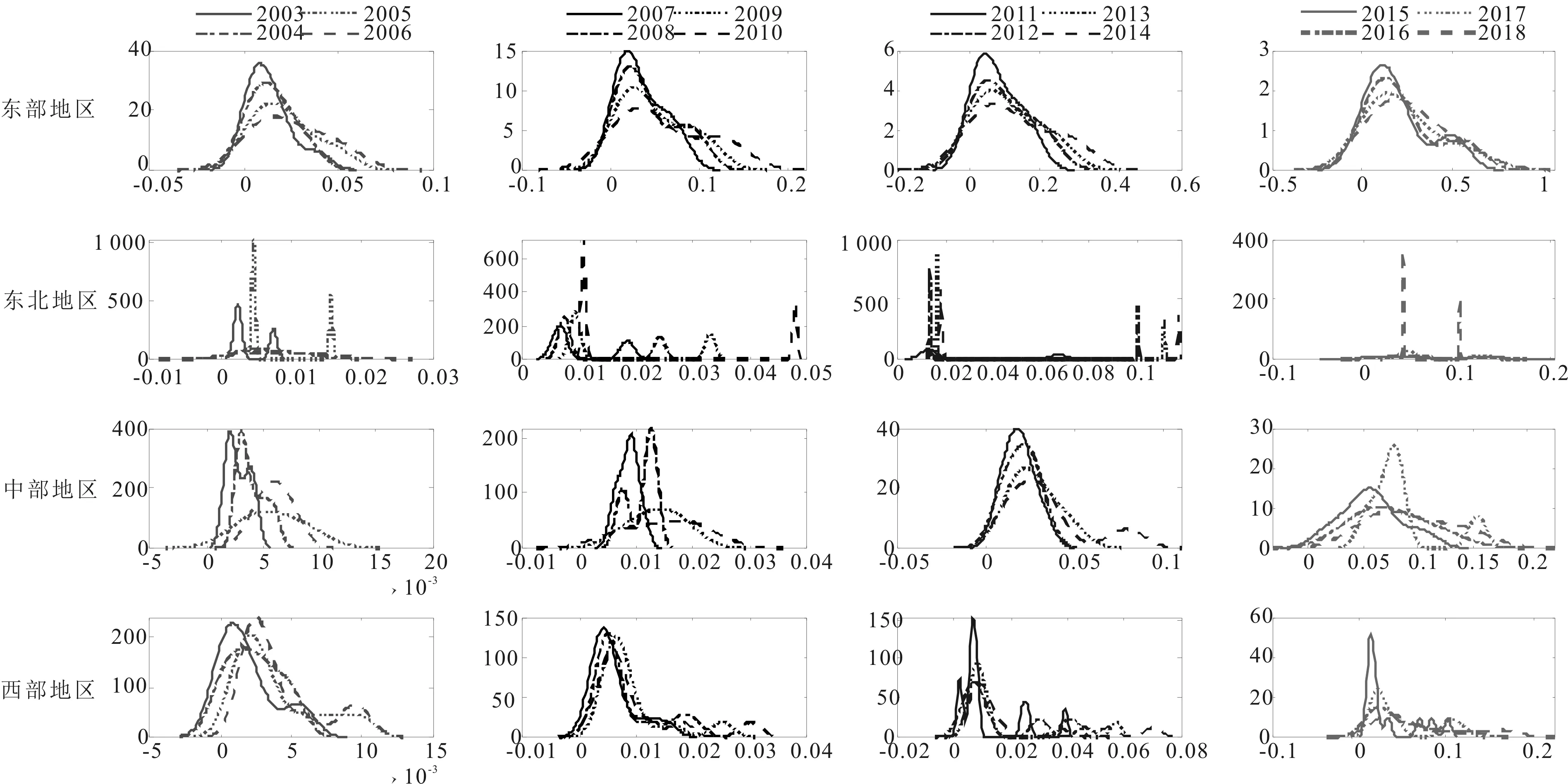
Djh表示j、h区域间人工智能发展水平的相对影响;djh表示区域间人工智能发展水平的差值,即j、h区域中所有yji>yhr的样本值之和的数学期望;pjh是转移变异的一阶矩,表示j、h区域中所有yji Djh=(djh-pjh)/(djh+pjh) (11) (12) (13) 其中,Fj、Fh分别是j、h区域的累计分布函数。 2.2.3 核密度估计 核密度估计利用平滑的峰值函数拟合样本数据,使用连续密度曲线描述随机变量的分布形态,具有模型依赖性弱、稳健性强等优点。因此,本文采用核密度估计方法对人工智能发展水平的概率密度进行估计,并用连续密度曲线对人工智能发展的分布动态情况进行可视化描述。 假设随机变量X1,X2,…,XN独立同分布,其密度函数f(x)未知,可以通过经验分布函数得到密度函数的核估计。经验分布函数为: (14) 其中,I(z)为示性函数,N为观测值数量,z为条件关系式。当z为真时,I(z)=1;当z为假时,I(z)=0。核密度估计式为: (15) 基于熵值法,本研究测算出各基础指标和分项指标的权重,如表1所示。 观察表1可以发现,生产应用(38.867 4%)在4个维度中所占权重最大,基础设施(34.612 6%)紧随其后,表明夯实人工智能发展的基础设施建设,助力相关智能制造企业发展,可以有效提升人工智能发展水平。此外,制度环境中政府关注力度(9.376 0%)权重超过其余大部分基础指标,说明从制度层面优化营商环境是推动人工智能产业发展的加速器。 表1 人工智能发展评价指标体系及权重 对于中国省际人工智能发展水平的测度,本文基于30个省份连续16年数据,共计480个样本。受限于篇幅,测度结果未全部展示,图2仅列示了主要年份的中国省际人工智能发展情况。可以看出,中国省际人工智能发展水平不断提高,2011—2015年和2015—2018年主要省份人工智能发展速度明显加快。此外,北京、广东、江苏、上海、浙江属于中国人工智能发展领跑者,2011年之后,山东、四川、福建、陕西、湖北、辽宁、湖南、海南、湖北、重庆、天津等开始发力,属于人工智能发展的追赶者,其余省份人工智能发展水平相对落后。 图2 主要年份中国省际人工智能发展水平 本文运用Dagum基尼系数及子群分解方法,对中国人工智能发展的总体差异、区域内差异、区域间差异和转移变异进行分析,以反映人工智能发展的差异程度及来源。 (1)中国人工智能发展的总体差异。表2测算的总体基尼系数反映出2003—2018年中国人工智能发展水平在全国层面的空间分布差异及其演变趋势。从全国层面看,中国人工智能发展的区域差异较大,基尼系数分布在0.480 3~0.594 9之间,空间非均匀特征显著。从演变趋势看,基尼系数总体上呈现N型走势,2003年基尼系数为0.579 92,随后下降至2009年的0.515 9,年均递减率达到2.068 2%,表明此阶段人工智能发展不均衡问题得到持续缓解;2009—2015年,基尼系数又开始增大并保持在0.562 7~0.594 9之间,说明相较于前一阶段,此阶段人工智能区域发展不均衡程度加剧;2016年以后,基尼系数开始回落,到2018年,降至0.480 29,说明近几年人工智能发展不均衡现象有所改善,但总体上,区域差异仍然较大。 (2)中国人工智能发展的区域内差异。从表2可以看出,东部地区人工智能发展的区域内差异最大,平均值达到0.415 6,波动幅度较小,下降趋势不明显;西部地区略低于东部地区,平均值为0.381 1,但波动幅度较大,2003—2010年呈正U型波动,2011—2018年呈倒U型波动;东北地区平均基尼系数小于东部和西部地区,2003—2012年呈上升趋势,2012年以后,基尼系数开始不断下降;中部地区人工智能发展的区域内差异最小,平均基尼系数为0.211 5,但考察期内的基尼系数呈波动上升趋势。 (3)中国人工智能发展的区域间差异。从表3可以看出,东—西区域间差异最大,平均基尼系数达到0.721 2;其次是东—中和东—东北,平均基尼系数分别为0.623 9和0.552 8;东北—中和中—西区域间差异较小,平均基尼系数分别为0.351 5和0.367 4。从波动趋势看,东—西与东—中波动趋势基本一致,呈下降—上升—下降的小幅波动趋势;东北—西和东北—中波动趋势基本一致,呈下降—上升—下降的大幅波动趋势,2012年和2013年东北—西的基尼系数一度超过东—东北同期数据,而2018年东北—西的基尼系数却小于所有区域间基尼系数;中—西波动幅度在2003—2008年较小,在2009—2014年上升幅度较大,2014—2018开始明显下降。 具体而言,2014—2018年,东北—西、东—西和中—西的基尼系数均呈下降趋势,表明该阶段西部地区人工智能发展水平有所提高。2007—2012年,东北—西和东北—中的基尼系数呈上升趋势,表明该阶段东北与中西部地区人工智能发展水平差距有所扩大。东北—中和中—西的基尼系数呈交错变化趋势,2004—2008年,人工智能发展水平的中—西差异大于东北—中,2009—2014年,东北—中差异逐渐扩大,超过中—西差异,2014—2018年,东北—中差异大幅缩小,开始小于中—西差异,到2018年,两者都维持在0.33左右。2003—2017年,东—西和东—中的基尼系数变化趋势基本一致,但在2017—2018年,东—西的基尼系数有所下降,而东—中的基尼系数有所上升。 表2 全国及四大区域人工智能发展的基尼系数 表3 人工智能发展区域间基尼系数 (4)中国人工智能发展区域差异来源及其贡献。表4报告了中国人工智能发展区域差异来源及其贡献,2003—2018年,区域间差异贡献占比最大,远大于区域内差异和转移变异贡献,但2010年以后基本呈下降趋势,由2010年的71.905 1%下降至2018年的65.925 3%。区域内差异贡献率维持在22%左右,2010年以后呈小幅上升趋势,由2010年的21.639 5%上升至2018年的23.406 7%。转移变异主要用于识别区域间的交叉重叠现象,如东部地区人工智能发展水平显著高于西部地区,但东部地区人工智能发展水平较低的部分省份可能低于西部地区人工智能发展水平较高的省份(如四川、重庆、陕西等)。2003—2009年,转移变异贡献基本维持稳定,到2009—2014年,转移变异贡献明显增加,表明湖北、湖南、四川、重庆等中西部地区省份人工智能发展水平超过东部地区部分省份(如河北等)。综上,中国人工智能发展水平总体差异主要来自于区域间的巨大差距,区域内差异并不是导致总体区域差异的主要原因,而不同区域间的交叉重叠对于总体差异造成的影响更小。区域间差异贡献远超转移变异贡献,说明不同区域间人工智能发展的净差异较大,从而造成全国范围内人工智能发展不均衡。 表4 基尼系数分解结果 前文利用Dagum基尼系数从相对差异角度刻画了中国人工智能发展的区域差异及其来源,下文将从绝对差异角度,利用核密度估计法,通过估计核密度曲线的位置、形态和延展性等,探讨2003—2018年中国人工智能发展的分布动态特征。 3.3.1 全国人工智能发展整体分布动态 本文对省际人工智能发展水平进行年度核密度估计,并绘制不同时段人工智能发展水平的分布动态图(见图3)。由图3可知,观测期内,中国人工智能发展大致可以分为2003—2006年、2007—2010年、2011—2014年和2015—2018年4个阶段。这4个阶段的分布曲线不断右移,其中,2003—2010年右移幅度较小,到2011—2014年右移幅度增大,尤其是2015—2018年右移幅度最大,说明我国人工智能发展水平正在不断提升,尤其是2015年之后,提升速度最快。此外,4个阶段的主峰高度持续下降,曲线宽度不断扩大,意味着省际间人工智能发展水平的绝对差异呈扩大态势。 从分布位置和形态看,主峰位置不断右移,主峰高度持续下降。具体地,2003—2006年、2007—2010年、2011—2014年和2015—2018年主峰中心位置横坐标分别位于0~0.005、0.01~0.02、0.02~0.05和0.07~0.1之间,主峰高度分别位于75~137、30~60、12~22和5~8之间。从分布延展性看,4个阶段都具有右拖尾现象,且延展性呈明显拓宽趋势,表明每个阶段都存在人工智能发展水平相对较高的省份,且随着时间推移,其相对水平不断提升。此外,4个阶段均出现侧峰,且侧峰不断右移,但峰值较小,说明中国人工智能发展水平存在一定梯度效应,各梯度发展水平在考察期内均有所提升,整体呈现出多级分化趋势。 3.3.2 区域层面人工智能发展水平分布动态 对区域层面人工智能发展水平进行核密度估计,结果如图4所示。整体看,东部地区人工智能发展水平呈正态分布;东北地区表现为强烈的两极分化;中部地区2003—2010年呈正态分布,2011—2018年开始出现侧峰,但侧峰峰值较小;西部地区呈现出强烈的多级分化趋势,有多个小侧峰出现。这说明东部地区人工智能发展具有扩展效应,东北地区呈现两极分化效应,中部地区扩展效应和回程效应程度相当,西部地区则表现为多极分化效应。可能的原因是,人工智能发展领跑省份都位于东部地区,东部地区通过技术溢出带动周围地区人工智能发展;东北地区仅辽宁的人工智能发展水平较高,而吉林和黑龙江属于人工智能发展的落后者,促使与人工智能相关要素进一步向辽宁集中;中部地区的湖北和湖南人工智能发展水平相对较高,但与区域内其它省份差距不大,因而在引入人工智能资本、智能应用等方面对其它省份可能存在扩散效应,但同时也不可避免地在人才、企业生产等方面具有回程效应;西部地区的四川和重庆人工智能发展水平排名基本处于前10位,陕西在10~15位之间,而其它省份则处于25位之后,多极分化效应促使人工智能发展要素向多个中心点集聚。 图3 不同时段人工智能发展水平分布动态 从分布位置看,四大区域的主峰位置都在不断右移,说明考察期内人工智能发展水平在不断提升。其中,东部地区4个阶段的平均峰值分别为0.015、0.02、0.05、0.15,东北地区平均峰值分别为0.005、0.01、0.02、0.05,中部地区平均峰值分别为0.005、0.01、0.025、0.075,西部地区平均峰值分别为0.001、0.005、0.007、0.025。这说明考察期内,东部地区人工智能发展水平提升速度最快,2003—2010年东北地区和中部地区人工智能发展水平相当,但2011—2018年中部地区略高于东北地区,西部地区人工智能发展水平提升较慢。从分布形态看,四大区域的主峰峰值均在不断下降,主峰跨度变宽,说明考察期内各区域人工智能发展水平整体差异扩大。其中,东部地区4个阶段的最高峰值最大,主峰跨度最宽,表明东部地区内部人工智能发展水平差异最大,这印证了Dagum基尼系数分析结果。从分布延展性看,考察期内四大区域均表现出右拖尾现象,说明四大区域内都存在人工智能发展水平相对较高的省份,如东部地区的北京、上海、广东、江苏、浙江等,东北地区的辽宁,中部地区的湖北和湖南,西部地区的四川、重庆和陕西等。此外,考察期内四大区域的核密度曲线都具有较好的延展性,说明人工智能发展水平相对较高的省份,其相对水平也在提升。 图4 区域人工智能发展水平分布动态 实施区域协调发展战略是新时代国家重大战略之一,而人工智能作为经济发展的新引擎和社会建设的新机遇,势必会为区域协调发展带来新格局。在此背景下,本文构建人工智能发展评价指标体系,通过对2003—2018年中国内地30个省份面板数据进行相应处理,测度中国省际人工智能发展水平。进一步地,利用Dagum基尼系数和核密度估计方法,考察中国人工智能发展水平的区域差异及分布动态演进特征。本文主要结论如下: 首先,人工智能发展评价指标体系包含制度环境、基础设施、技术创新和生产应用4个分项指标,且权重分别为15.099 2%、34.612 6%、20.911 0%和38.867 4%。其次,北京、广东、江苏、上海、浙江属于中国人工智能发展领跑者,山东、辽宁、天津、四川、重庆、湖南、湖北、陕西、福建属于追赶者,考察期内其余省份属于落后者。第三,总体上,中国省际人工智能发展空间非均衡特征显著,样本期内基尼系数始终保持在0.480 3~0.594 9之间,区域间贡献率为69.642 3%,区域内贡献率为22.177 0%,转移变异贡献率为8.180 7%。具体地,东—西、东—中和东—东北的区域间差异是主要差异来源,平均基尼系数分别为0.721 2、0.623 9、0.552 8;东北—中、东北—西和中—西的区域间差异较小,平均基尼系数分别为0.353 8、0.470 7、0.367 4;东部、东北、中部和西部地区的平均基尼系数分别为0.415 6、0.314 9、0.211 5、0.387 9,其中,东部和西部的基尼系数超过东北—中和中—西区域间基尼系数。最后,在样本观测期内,中国人工智能发展水平不断提升,但发展水平的绝对差异在逐渐扩大。无论是全国层面还是四大区域层面,人工智能发展均呈现出显著的非均衡态势,具体表现为:东部地区表现为扩展效应,东北地区呈现出两极分化效应,中部地区扩展效应和回程效应相当,西部地区呈现出多极分化效应。 根据以上研究结论,我国人工智能发展存在空间非均衡性,降低区域间差异程度,合理控制区域内部极化现象已经成为人工智能产业发展过程中亟待解决的问题。为此,本文提出以下建议: 首先,重视区域内发展不均衡问题。核密度估计结果表明,四大区域人工智能发展水平均存在区域内差异,这对我国人工智能发展既是挑战也是机遇。挑战在于,人工智能是引领未来的战略性技术,人工智能产业发展不平衡,势必会加剧我国经济发展不平衡问题;机遇在于,“星星之火,可以燎原”,在各区域设立一个或多个人工智能发展高地,促使与人工智能发展相关的资金、技术、人才等由中心点向四周有序扩散,待人工智能产业外溢之时,便是形成“燎原”之日。此外,由于基础设施建设是人工智能发展的基石,对于人工智能发展水平较低的区域,需要充分发挥社会主义制度集中力量办大事的优势,夯实基础设施建设,提供培育人工智能发展的平台。 其次,统筹区域间人工智能协调发展,促进人工智能与实体经济深度融合。本文实证结果表明,区域间差异是人工智能发展的主要差异来源。探索人工智能带动实体经济发展模式,通过缩小人工智能发展区域间差距,促进区域经济协同发展,是当前我国人工智能发展进程中亟需解决的问题。Dagum基尼系数表明,东—西、东—中、东—东北区域间差异最大。因此,在推进人工智能发展过程中,要分阶段、分批次实施建设,不能 “一把抓”。根据构建的指标体系,除需要营造有利于人工智能发展的制度环境和技术创新环境外,西部地区要重点夯实人工智能发展的基础设施建设,而中部和东北地区则要制定相关政策,重点助力相关智能制造企业发展。此外,根据人工智能发展的领跑者、追赶者和落后者角色,政府可以制定省际间协作机制,打破阻碍人工智能技术流动的壁垒。例如,依照 “点、线、面、体”递次推进,领跑者形成线,追赶者形成面,最终缩小区域间差异,形成中国人工智能发展优势,带动国家竞争力整体跃升和跨越式发展。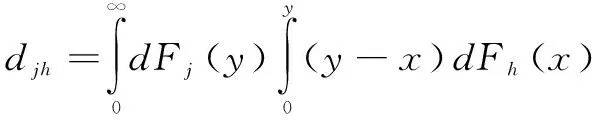
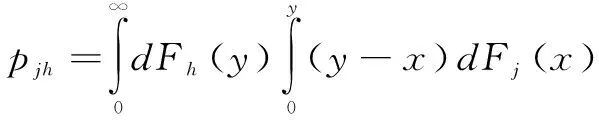

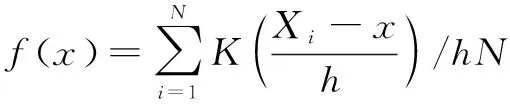
3 实证分析结果
3.1 人工智能发展评价指标权重及测算结果分析
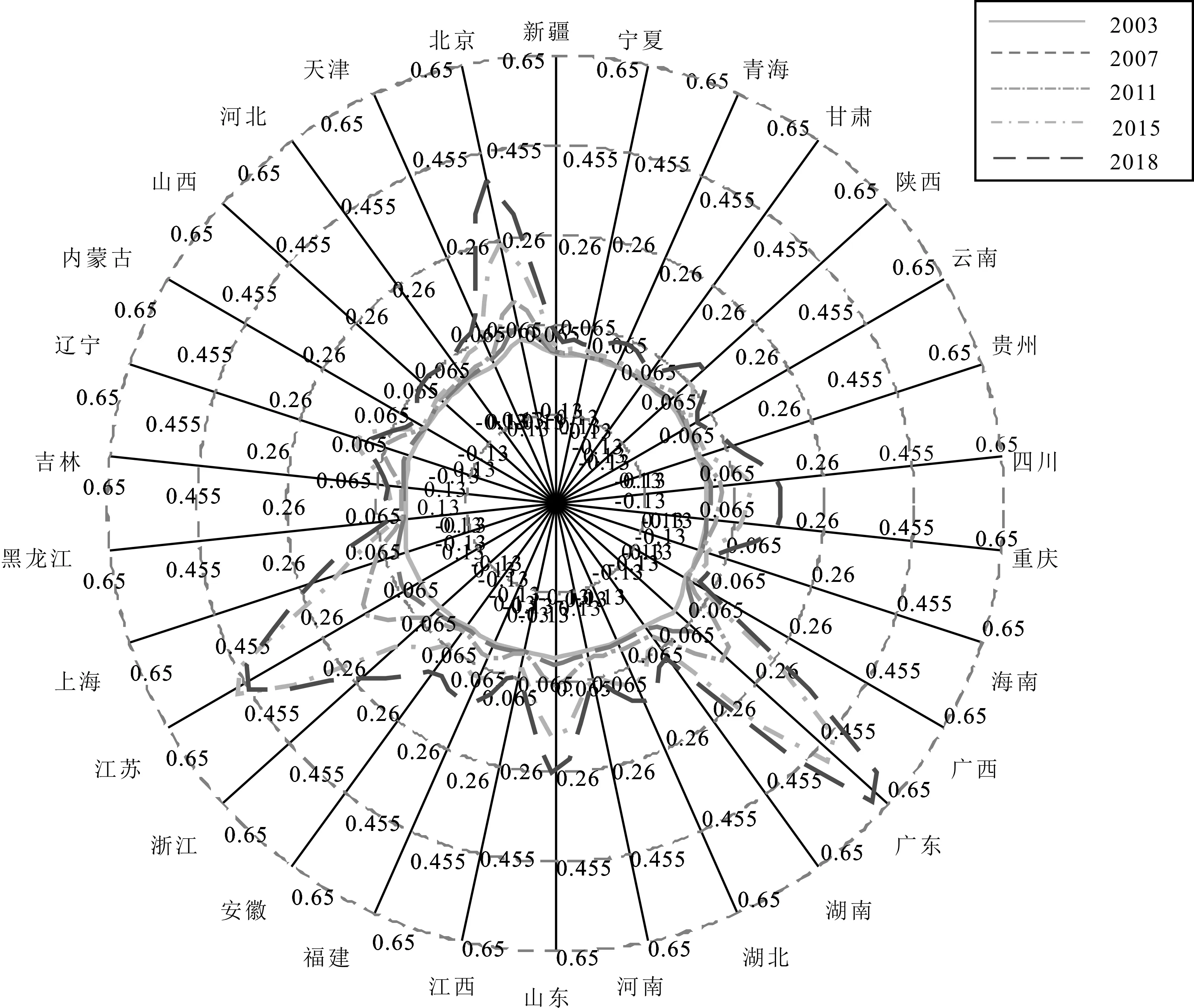
3.2 人工智能发展区域差异及来源分析
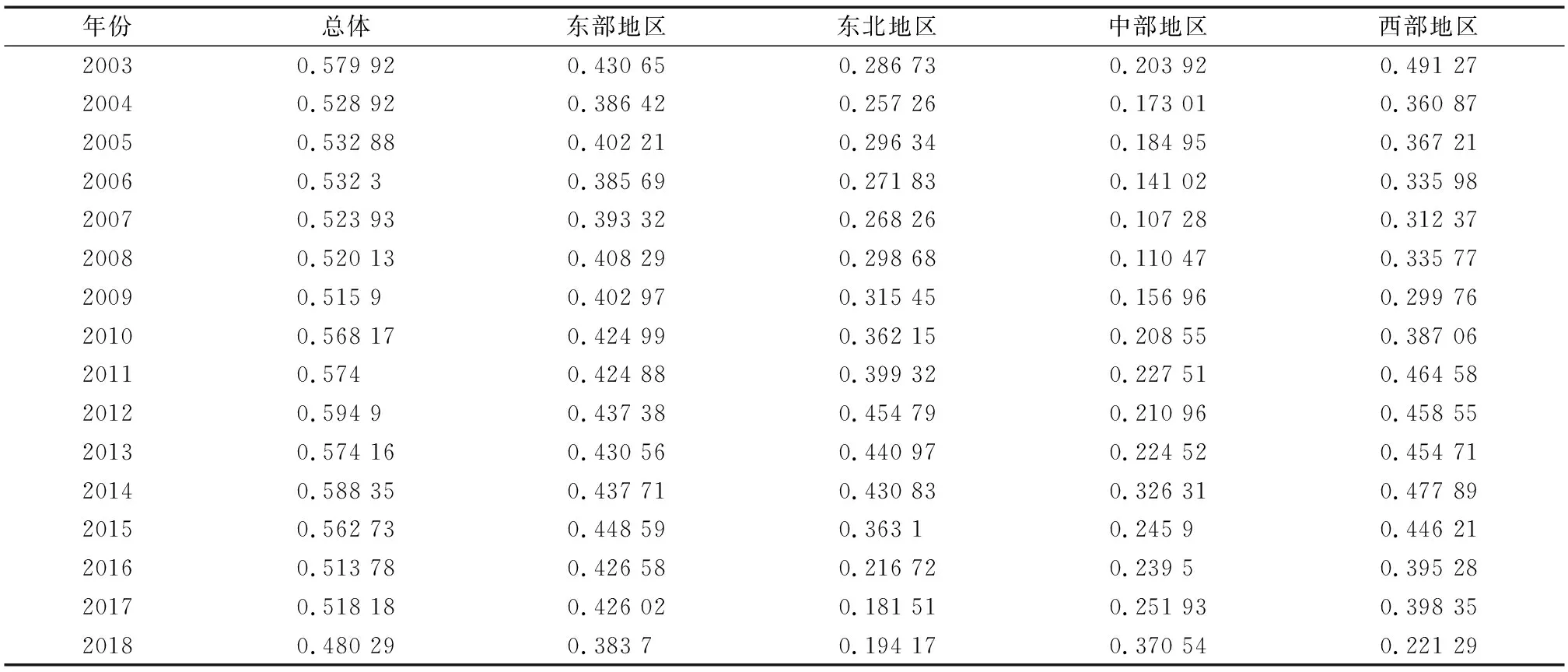
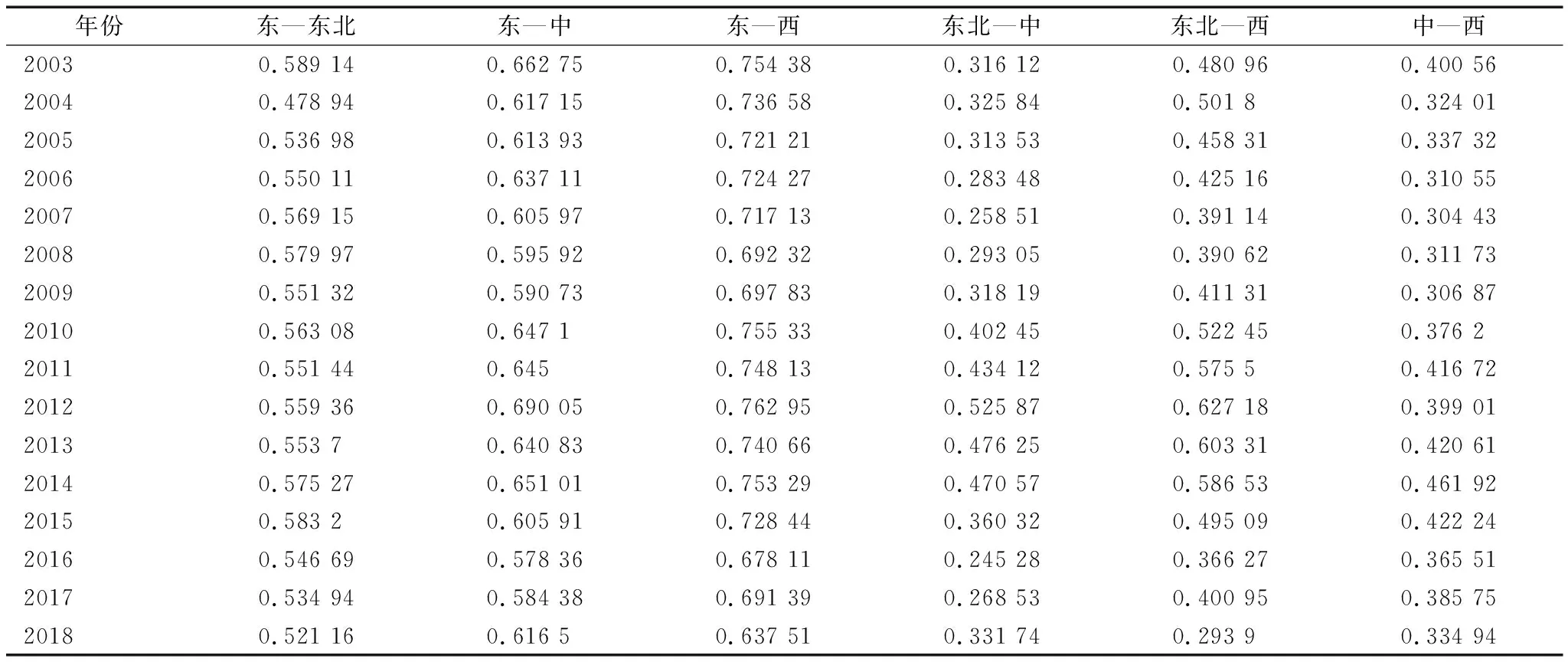
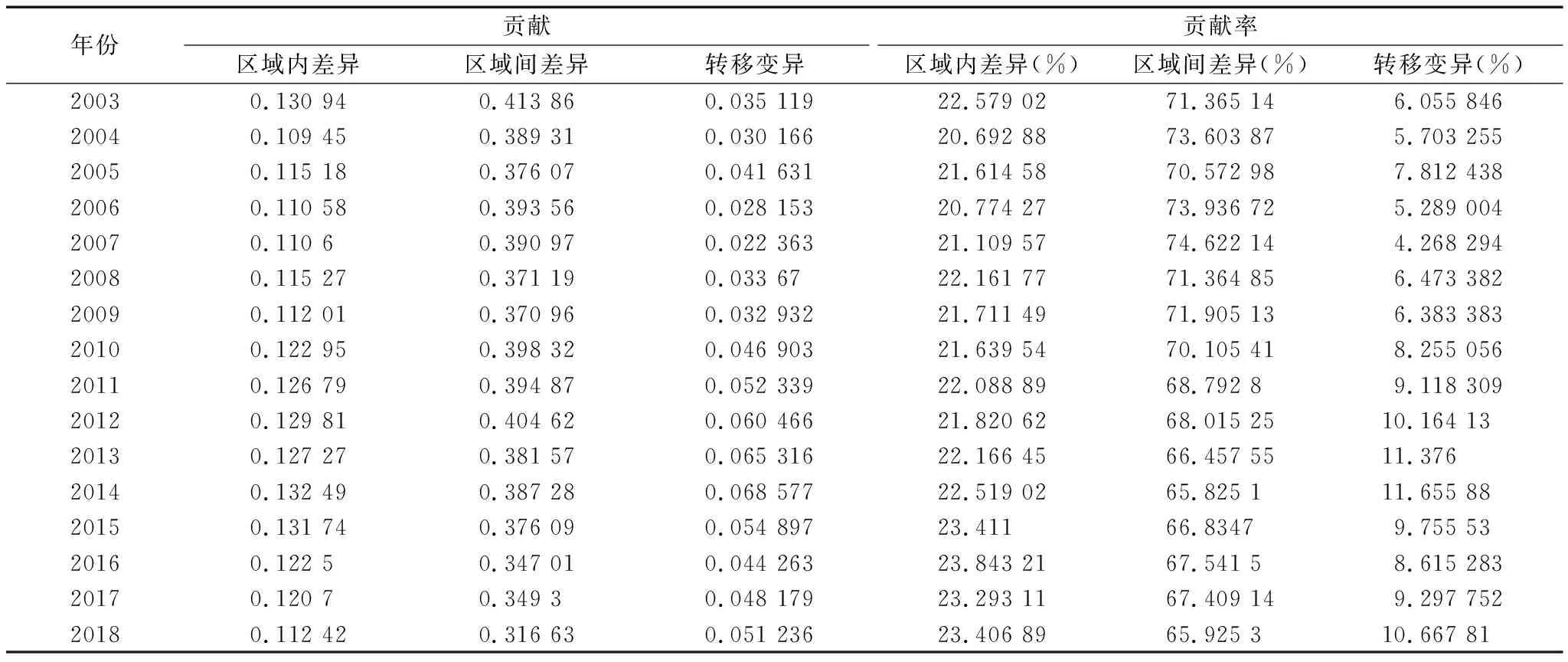
3.3 人工智能发展分布动态分析
4 结论与政策建议
4.1 研究结论
4.2 政策建议
