基于机器学习方法的洪泽湖入湖水质评价及预测研究
2021-12-30石晴宜董增川王天宇
石晴宜,董增川,罗 赟,姚 敏,崔 璨,王天宇
(1.河海大学水文水资源学院,南京 210098;2.江苏省水文水资源勘测局,南京 210029;3.长江勘测规划设计研究有限责任公司,武汉 430010)
0 引 言
水是人类和其他生命体所依赖的不可缺少的资源,建立水质模型预测水质状况具有重要的社会经济和生态环保价值。目前水质预测模型可按其内理性质分为机理性水质预测模型和非机理性水质预测模型两大类[1]。机理性模型本质上是依据水环境系统的基本物理、生物、化学特性,利用系统结构数据推导出的模型,如S-P、QUAL、WASP等模型[2-4]。机理性模型预测结果较为理想,但由于其模型搭建需要大量基础资料与长期的监测数据,而水质数据通常较为缺乏,因此在实际运用上存在一定的困难。非机理性水质预测模型是一种黑箱方法,直接对带有时间序列的水质监测数据进行预测研究,不探究水质变化内在原理。诸多学者基于数理统计方法与计算机技术,开展了大量非机理性水质预测模型的研究:邓聚龙提出的灰色模型对序列中样本数量和分布没有特殊要求,在水质预测建模中得到了较多的应用[5]。翟伟等提出了将人工神经网络结合灰色预测法,实现了对水质的动态预测[6]。张秀菊等运用支持向量回归机的理论与方法,构造水质预测模型,较好地反映了通州区新江海河站点NH3N及TP两项指标的变化趋势[7]。
为提高水质模型预测精度,提出耦合多种黑箱式模型进行综合水质预测。小波分析是一种多分辨率分析方法,可以对信号逐步进行多尺度划分,具有良好的局部检测功能,常用于表征数据变换的瞬态和奇异点特征[8]。目前小波分析已被广泛运用于水文序列多时间尺度变化特性分析[9]、水文序列消噪[10]、中长期水文预报[11]等领域。循环神经网络(RNN)是一类具有短期记忆能力的神经网络,其每个神经元在某时刻的输出可以作为输入再次输入到神经元[12],因此对时间序列的处理具有一定优势。Hochreiter 等提出的长短记忆网络[13]改进了传统的RNN存在的循环多次后出现梯度消失甚至梯度爆炸的问题[14],已用于蓝藻水华预测[15]、养殖水质分类预测[16]和地表水多因子预测[17]。水质评价是反映水体污染状况的重要方式,目前常用的评价方法有:单因子评价法、内梅罗指数法、模糊综合评价法、主成分分析法等[18]。其中,模糊综合评价法基于模糊理论,综合考虑了水环境污染因素的模糊性和不确定性[19],近年来模糊综合评价法及其改进算法被广泛应用于河流、湖泊、水库等水质评价中[20,22]。模糊神经网络是模糊理论与神经网络相结合的产物,它兼具两者的优点,既可以表示模糊和定性的知识,又具有较好的学习能力[23],而其中基于T-S 的模糊神经网络在模式识别分类方面具有优势,被证明在水质评价中切实可行[24,25]。将小波分析、长短记忆神经网络与模糊神经网络耦合进行水质预测可以结合三种模型的优势:针对水质序列波动大的特征,可利用小波分析细化水质数据,优化LSTM 预测模型输入;针对单因子水质预测难以展现水体整体状况的问题,可通过模糊神经网络预测水质变化综合趋势。
本文提出基于小波分析和长短期记忆神经网络的水质单因子预测方法,在此基础上使用模糊神经网络的方法对未来水质进行综合评价。洪泽湖是中国第四大淡水湖,位于江苏省西部淮河下游,是国家南水北调东线工程的重要调蓄湖泊和江苏省北部地区重要水源。因此,洪泽湖水质的好坏将直接影响“南水北调”水体的质量以及苏北地区乃至淮海平原的用水质量与安全[26]。本文采用洪泽湖主要入湖河道淮河(盱眙化肥厂站)的水质数据,通过WA-LSTM 模型进行水质单因子预测,利用T-S模糊神经网络评价整体水质状况,并在计算过程中,与传统LSTM模型进行对比,验证本方法的有效性和科学性。
1 方法及原理
1.1 小波变换
小波变换是用于分析和处理非平稳时间序列的有用且强大的数学工具[27,28]。小波变换通过伸缩平移运算对信号进行细化,提取时频特征。小波变换分为连续小波变换(CWT)和离散小波变换(DWT)。连续小波变换表示如式(1):
式中:f(t)为原始信号;Wf(a,b)为小波变换系数;a为伸缩因子;b为平移因子;Ψ(t)为一连续函数,被称为母小波;*表示复共轭。
由于离散小波变换的计算速度较快且开发过程更简单,实际应用中离散小波变换比连续小波变换更常用[29]。用Mallat塔式算法计算离散小波变换,计算方法见式(2)和式(3):
式中:n为样本数;j为分解级别;cAj为近似系数;cDj为细节系数;h为低通滤波器;g为高通滤波器。
Mallat重构算法进行重构,计算方法见式(4):
Mallat塔式算法离散小波分解与重构流程示意图见图1。
小波分解后得到的重构数据序列在时域和频域都有表征信号局部特征的能力,与原数据序列相比,更易检测信号的瞬态或奇异点,对于分析和处理如水质数据一类的非平稳时间序列具有明显优势。
1.2 长短记忆神经网络
长短记忆神经网络作为RNN的一种变体,同样具有重复模块的链状结构。但不同的是,LSTM 的重复模块更为复杂,且将RNN 中隐含层的神经元替换为记忆体[30],实现序列信息的保留和长期记忆。
图2为LSTM 记忆体结构,LSTM 的关键是细胞状态C,LSTM 通过3 种类型的“门控”实现细胞状态中信息的删除与添加:遗忘门(f)、输入门(i)、输出门(o)。
遗忘门确定丢弃的信息,即对于上一时刻细胞状态Ct-1的保留程度。计算方法如式(5)。
式中:σ为sigmoid 函数;Wf为输入权重;ht-1为上一时刻的隐藏层状态;xt为当前时刻节点的输入值;bf为偏置项。
输入门确定存储的信息,与遗忘门结合,更新当前时刻细胞状态Ct。计算方法如式(6)~(8)。
式中:为新信息;Wi、WC为输入权重;bi、bC为偏置项。
输出门确定输出值,由细胞状态与Sigmoid 门的输出共同确定输出信息。计算方法如下式(9)和式(10)。
式中:Wo为输入权重;bo为偏置项;ht为输出的当前时刻隐藏层状态。
1.3 基于小波分解的长短记忆神经网络(WALSTM)单因子预测模型
构建基于小波分析的LSTM 时间序列预测模型,结构如图3所示,算法步骤如下:①数据收集与预处理:收集实测水质数据,识别并删除异常数据,填补缺失值,确保模型输入的准确性和完整性;②小波分解:选取基小波,确定分解层数n,对原始信号数据进行n层小波分解,由高通滤波器产生与子波函数相关的n组细节系数,低通滤波器产生与尺度函数相关的近似系数,并进行系数重构,由小波长度转换为时域长度;③样本数据划分:将小波分解后的各组数据统一划分为训练数据和测试数据。训练数据用于训练LSTM 模型,模拟时间序列演变规律;测试数据用于分析预测精度,验证模型性能;④训练模型:将训练数据作为样本输入训练LSTM 时间序列预测模型,不断调整参数,直至满足精度要求;⑤信号预测:将测试数据输入训练好的LSTM 时间序列模型,分别对低频信号和高频信号进行预测;⑥重构信号:对LSTM 模型输出结果进行小波重构,获得水质单因子预测结果,并对比分析LSTM、WA-LSTM预测准确度。
1.4 T-S模糊神经网络模型
模糊神经网络是模糊系统与神经网络的结合,模糊系统按常见的形式可分为:纯模糊逻辑系统、T-S(Takagi-Sugneo)模糊逻辑系统和广义模糊逻辑系统等。其中基于T-S模糊系统的神经网络是一种非线性模糊推理模型,具有表达模糊推理规则、计算简单、利于数学分析的优点[31]。T-S 模糊系统采用“ifthen”规则形式来定义,输入向量为X=[x1,x2,…xk],规则为Ri的模糊推理如下:
式中:i为模糊子集数;k为输入参数总个数;A为模糊系统的模糊集;p为模糊参数;y为根据模糊规则得到的输出。该模糊推理表示输出为输入的线性组合[32]。
T-S 模糊神经网络具有输入层、模糊化层、模糊计算层、输出层四层结构。输入层节点数与输入向量的维数一致;模糊化层对输入值进行模糊化,各输入变量xj的隶属度μAij为:
式中:j为输入参数数;cij为隶属度函数的中心;bij为隶属度函数的宽度。
模糊计算层对各隶属度进行模糊计算,见式(13):
输出层根据模糊计算结果计算模糊神经网络的输出,见式(14):
其中,模糊参数、隶属度函数的中心和宽度依据实际输出与期望输出的误差进行修正。
2 算例分析
2.1 研究区概况
洪泽湖是中国第四大淡水湖,位于江苏省西部淮河下游,苏北平原中部西侧,地处淮安、宿迁两市境内,地理位置在北纬33°06′~33°40′,东经118°10′~118°52′之间。目前洪泽湖现状水体存在富营养化问题,TN、TP 污染较为严重。若TN、TP 不参评,湖区水质可维持在III~IV类;若参评,湖区水质属于V类。
洪泽湖接纳的污水以外来污染源为主,洪泽湖主要入湖河道有:淮河、新汴河、老濉河、新濉河、徐洪河、怀洪新河。选取氨氮(NH3N)、总磷(TP)、总氮(TN)、高锰酸盐指数(CODMn)四项指标浓度,根据2003-2018年洪泽湖各入湖河道的水量及水质数据,计算通过各河道进入洪泽湖的多年平均污染物通量,可得淮河入湖污染物所占比重最大,其中NH3N 占入湖总量的79.13%,TP 占入湖总量的83.38%,TN 占入湖总量的87.67%,CODMn占入湖总量的81.10%。淮河干流在1992、1994、1995、2004年等年份相继发生污染团下泄事件,对洪泽湖的水体造成严重污染,破坏了其生态系统[33]。由此可见,淮河作为洪泽湖主要污染来源,准确并及时地对其进行水质预测与评价对于改善洪泽湖水环境有重要意义。
2.2 数据来源与预处理
本文选取NH3N、TP、TN、CODMn四项指标,从江苏省水土保持生态环境监测总站收集2003-2018年盱眙化肥厂水质测站(代表淮河干流)逐月各项指标浓度共192 组数据,取前173 组作为训练数据,后19组作为测试数据。
TP 与TN 指标在2003年1月-2004年4月存在缺失,采用均值平滑法进行填补,用缺失数据前后的平均值替代缺失值。
2.3 单因子预测
为判断预测结果优劣,选取均方根误差(RMSE)和决定系数(R2)作为评价指标。其中RMSE表征模型拟合偏差,RMSE值越小,预测值相对于真实值的偏差越小;R2表征拟合优度,R2值越接近1,模型拟合能力越好。计算公式如下。
式中:n为样本数;xi为实测值;xi′为预测值为实测数据平均值。
2.3.1 小波分解
利用Matlab 对预处理后的四组数据进行小波分解,选择“db5”作为基小波,确定分解层数为3层,并进行系数重构,将原始信号分解为表征细节的高频信号D1、D2、D3和表征逼近的低频信号A3,分解结果如图5。
将经过小波分解后的各个频段信号相加还原,计算四项指标重构后与原始信号的最大绝对误差。NH3N、TP、TN、CODMn四项指标重构信号与原始信号的最大绝对误差分别为1.02×10-11、4.45×10-13、1.60×10-11、6.19×10-12,可见重构信号与原信号误差很小,可忽略不计,表明离散小波分解具有重现原始数据的能力。
2.3.2 预测结果对比分析
使用基于小波分析的LSTM 模型对前173 组数据进行训练,对后19组做出预测。设置求解器为Adam,隐藏层节点数为128,每次预测进行300 轮训练,不断调整batch_size(批量大小)及learning_rate(学习率),使模型不仅具有较高的预测精度,还能达到快速收敛的效果。为避免实验中偶然因素,每组实验进行5 次预测。经多次实验确定最优模型参数如表1所示。将各个频段的预测结果融合,实现小波重构,获得单因子预测水质浓度。再将原始信号输入传统的LSTM 模型,前173 个数据训练模型,预测后19个时间点的各项水质指标浓度。盱眙化肥厂水质监测站LSTM 及WA-LSTM 单因子预测结果如图6所示,预测结果精度如表2所示。
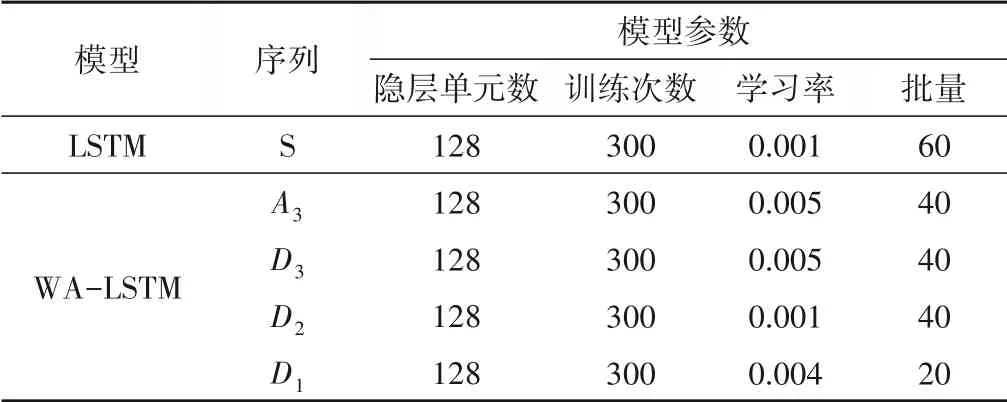
表1 LSTM及WA-LSTM 网络设置参数Tab.1 Parameters of LSTM and WA-LSTM network
由图6可以看出,传统LSTM 模型虽能预测出水质变化趋势,但存在较大误差,对于变化细节以及突变点预测精度不足:NH3N 指标未能预测两次(编号6-9)突变现象,且在后期(编号16-19)预测误差显著增大;TP 指标未能预测出浓度的陡落(编号5-6)及陡升(编号16-17);TN 指标在极大值(编号2、10、14)处的预测精度较低;CODMn预测值普遍低于实际值。而基于小波变换的LSTM 模型预测误差明显小于传统LSTM 模型,不仅能准确预测变化趋势,而且预测值与实测值十分接近。根据表2对模型进行性能分析:WA-LSTM模型的预测结果RMSE均小于LSTM,说明WA-LSTM 模型单因子预测值与实测值误差较小;WA-LSTM 模型决定系数R2均接近1.0 且远大于LSTM,表明WA-LSTM 模型性能较好,预测结果较为准确。其中TN 的预测结果精度较高,CODMn指标精度较低,但均在误差允许范围内。单因子预测结果是后续模糊神经网络综合水质预测的基础,因此为确保综合水质预测的有效性,选用WA-LSTM 单因子预测结果作为综合水质预测的输入。

表2 单因子预测精度Tab.2 Accuracy of single factor prediction
2.4 综合水质预测与评价
由于水质评价真实数据较少,采用等隔均匀分布方式内插水质指标标准数据生成训练样本和测试样本,采用的水质指标标准数据见表3。

表3 地表水环境质量标准mg/LTab.3 Surface Water Environmental Quality Standard
考虑盱眙化肥厂站TN 指标超标较为严重,因此区分包含TN和不包含TN进行综合水质预测。根据训练样本的维度确定输入层节点数,结合经验公式及试错法确定模糊层节点数,最终确定含TN 的综合水质预测模糊神经网络结构为4-8-1,不含TN 的综合水质预测模糊神经网络结构为3-6-1;根据水质指标评价标准,生成350 组训练样本,50 组测试样本,对单因子预测的19组结果进行综合水质预测,预测结果如表4所示。
由表4可知,将WA-LSTM 单因子预测作为水质综合预测模型输入,计算结果与实测数据综合评价结果基本相同。在TN参评情况下,预测结果与真实值完全一致,在预测时间段内盱眙化肥厂站水质始终处于V 类水平,水质较差。在TN 不参评时,预测值与真实值稍有偏差,预测准确率为78.9%,盱眙化肥厂站通常处于III~IV 类标准且在预测时间内有好转趋势,将III类标准作为洪泽湖目标水质标准,若TN 参评,则达标次数为0,若TN 不参评,实际达标次数为5 次,预测达标次数为3 次,可见预测水质情况稍劣于实际情况。该评价结果与洪泽湖湖区水质状况相似,进一步验证了将淮河作为洪泽湖主要污染来源进行分析的可靠性。从评价结果来看,淮河入洪泽湖水质情况虽有好转,但TN 仍为超标的主要污染物,需严格把控淮河入洪泽湖河口的水质,加大检测力度,采取改善水质的干预措施,以此改善洪泽湖湖区的水生态环境。

表4 T-S模糊神经网络综合水质预测结果Tab.4 Results of T-S fuzzy neural network comprehensive water quality prediction
3 结 论
本研究利用WA-LSTM 模型与模糊神经网络结合建立了水质综合预测模型,将其运用于洪泽湖入湖水质的综合预测与评价,主要得到以下两个结论。
(1)由于单项水质指标经过小波分解后再利用长短记忆神经网络模型进行时间序列预测更能准确地反映整体趋势,把握变化细节,因此与传统LSTM 模型相比,WA-LSTM 水质预测误差更小且模型性能更好。
(2)基于T-S的模糊神经网络综合水质预测模型,可以有效解决单因子预测不能解释水质整体情况的问题,其与WALSTM 模型的耦合使用不仅能够较好地处理水质这种高噪声数据,还可以保持较好的泛化性。□
