基于在线评论与IPA-Kano模型的酒店服务质量管理研究
2021-12-28黄官伟邵立轲
黄官伟 邵立轲
(同济大学经济与管理学院,上海 200092)
中国的旅游市场已具有相当的规模,根据世界旅游城市联合会(WTCF)和中国社会科学院旅游研究中心共同发布的《世界旅游经济趋势报告(2020)》,2019年中国的旅游行业总收入居全球第二,国内旅游人次增速、国内旅游收入增速均居亚太地区首位。此外,得益于国内疫情的有效控制,国内旅游市场恢复迅速,大量出境游需求回流入国内,助推国内旅游市场的进一步发展。作为旅游出行的重要环节,在线酒店预订产业发展已渐趋成熟,携程、艺龙等头部企业均已成功登陆资本市场。
相较于发展日渐成熟的在线预订市场,我国酒店业连锁化程度低,连锁化率不到30%,存在大量的单体酒店,服务缺乏统一标准与有效指引。
1 国内外研究进展
1.1 服务质量的测度
服务质量通常被定义为客户对服务提供商及其服务的印象。高服务质量能提高顾客满意度,从而吸引更多的顾客,为企业带来更多的回报。由于顾客才是服务质量的最终判定者,传统的服务质量测度多采用问卷调查法,其中最为著名的是Parasuraman等人(1988)开发的SERVQUAL量表,该量表从可靠性、反应性、保证性、移情性和可感知性五个方面度量了顾客对服务的期望值以及最终感知质量,为许多学者提供了思路。在此基础上,Cronin与Taylor于1992年提出SERVPERF模型,只采用服务绩效这一个变量来衡量顾客感知价值;Parasuraman等人也于1994年对SERVQUAL量表进行了扩展,增加了感知质量与理想质量、感知质量与适当质量的差异。但问卷调查法存在一些问题:一方面由于问卷的分发与收集需花费大量的时间与精力,很难大规模开展,因此收集到的数据规模有限,以致代表性不足;另一方面填问卷时被访者会意识到自己的观点被记录,因此有可能会隐瞒自己的真实想法。
进入互联网2.0时代后,在线评论的出现为针对消费者的定量研究的开展提供了理想的数据源——在线评论具有数据规模大与自发性的特点,能更真实地反映消费者群体的态度,相比传统的渠道的数据具备更高的可信度。许多学者通过对在线评论的挖掘实现了对消费者偏好的测度:Ya-Han Hu与Kuan-Chin Chen(2016)基于在线评论内容、情感倾向、作者以及可见性构建了对评论有用性的预测模型;Paul Phillips等人(2015)使用人工神经网络对瑞士酒店的在线评论进行了分析,发现房间质量、积极的评论数、酒店声誉以及客房星级评分对于酒店的平均客房收入(RevPar)有积极影响。因此,本研究将沿用这一思路,通过机器学习算法对在线评论进行挖掘,将得到的顾客偏好信息作为后续服务质量管理的基础。
1.2 服务质量的提高
服务质量提高的主要思路是通过对服务质量要素进行分类,制定针对性的服务提升策略实现的。Martilla和James(1977)提出的重要性绩效分析模型(IPA)使用重要性和绩效来创建一个二维矩阵,将整体区域划分为四个象限:“继续保持”,“关注过度”,“低优先级”和“重点关注”,以此来对产品质量要素进行分类;Noriaki Kano等人(1984)认为用户满意度随需求被满足情况的变化应是非线性的,并提出了Kano模型(图1)。
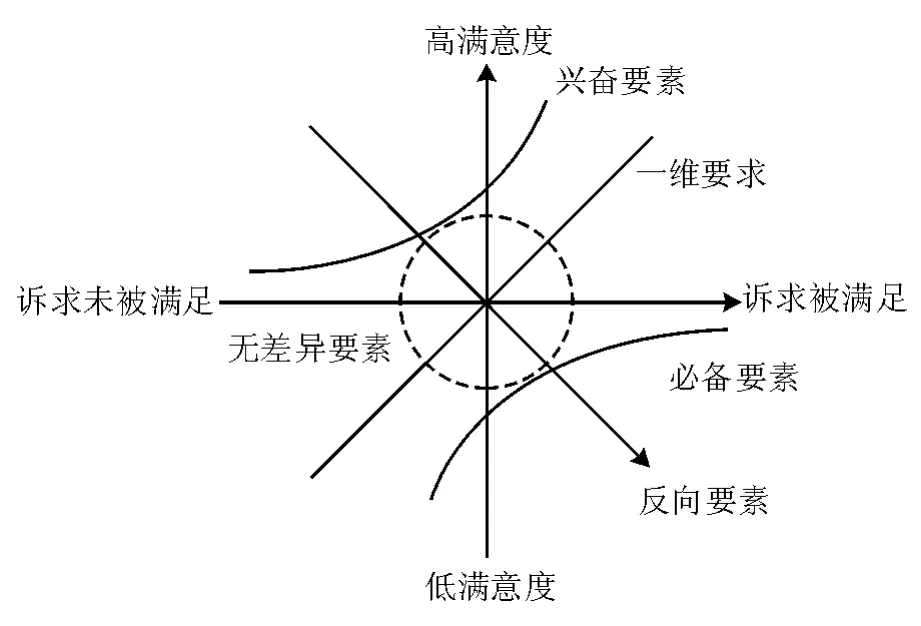
图1 Kano模型
IPA模型与Kano模型都可用于服务质量要素的分类,但二者侧重点有所差异:IPA模型主要基于重要性和满意度发现更具提升潜力的服务质量要素;而Kano模型侧重于刻画各服务质量要素随满意度变化的规律。将两者结合,就能筛选出对于提高顾客满意度边际效应最大的服务质量要素,Ying-Feng Kuo等人在2012年提出了IPA-Kano模型(表1):将Kano模型中具备优化价值的兴奋要素、必备要素与一维要素从重要性与满意度两个维度进行二次分类,得到整合了IPA与Kano后的综合分类标准,并制定了不同类别要素的优化方向与优化优先级。IPA-Kano模型自提出后已在移动图书馆、移动餐厅、医疗服务等领域应用。

表1 IPA-Kano模型与服务优化方向
HS*9
1.3 酒店业服务质量研究
服务质量的研究通常需要划分服务质量要素,由于研究重点与方向的差异,学者们划分的要素也有所差异(表2):

表2 酒店服务质量研究进展
在总结前人的研究成果后,本研究最终确定的服务质量要素为餐食、装修、房间设施、服务、酒店设施、酒店位置、隔音、清洁、性价比。部分学者对酒店品牌进行了研究,但由于酒店品牌主要是通过影响用户对于服务的期待值来影响顾客满意度,对于酒店服务质量的评价与改进并无实质影响。因此,本研究划分的服务质量要素并未包括酒店品牌。
2 基于在线评论的IPA-Kano模型
本研究的主要目的是使用机器学习算法对在线评论进行挖掘,计算顾客对于不同服务质量要素的偏好,以此为基础对服务质量要素进行分类并制定服务提升策略。整体研究思路分为三部分:(1)评论特征信息提取;(2)顾客偏好计算;(3)服务质量要素分类与服务提升策略制定。研究框架如图2所示。
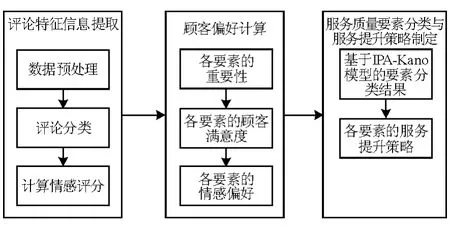
图2 研究框架图
2.1 评论特征信息提取
评论特征信息提取阶段的主要目的是使用机器学习算法对在线评论数据进行处理,将非结构化的文本数据转化为能代表评论特征的结构化数据。
首先需要对在线评论进行预处理:(1)数据清洗。剔除重复文本、无意义文本以及长度过短的文本(5个字以下)。(2)分词与停用无意义词。(3)替换近义词。(4)文本分段。由于在线评论是对整个服务过程的综合评价,一条可能会涉及多个服务质量要素,本研究将所有评论按标点符号拆分为评论片段,使每条评论片段尽量只对应一个要素。
然后需要对评论文本进行分类。本文采用朴素贝叶斯算法对所有评论分段进行分类,朴素贝叶斯算法对于缺失数据不敏感且在多分类任务上表现较好,比较适用于文本分类。分类完成后得到各服务质量要素对应的文本分段集合Xj(j是各服务质量要素对应的编号)。
使用Python语言的开源库Snow NLP计算各评论分段的情感评分xijn)(第i条评论在第j个服务质量要素上的第n条评论分段),分别汇总属于同一条评论、同一服务质量要素的正负向评论片段,计算

2.2 顾客偏好计算
顾客偏好计算阶段的主要工作是基于上一阶段得到的文本特征,使用联合分析方法,测量各服务质量要素对顾客满意度的影响程度。本文采用基于部分价值函数模型的联合分析方法,模型如下:

其中,y是顾客满意度的列向量,即每条评论中顾客对酒店的整体评分;α是常数项;J表示服务质量要素的总数;Xjpos是第j个服务质量要素上的列向量,即同理),如果评论中未涉及该维度,则与是评分的权重,即本阶段希望得到的顾客对该服务质量要素的正/负向情感偏好。
2.3 服务质量要素分类与服务提升策略制定
2.3.1 基于Kano模型的服务质量要素分类
Kano模型将产品质量要素分为5类,为了对服务质量要素进行分类,本研究设置了三个观察点:(-1,βjneg)、(0,0)和(1,),并基于估计出的β值,构建两个指标:

Rangej表示顾客对于第j个服务质量要素偏好的变化范围,Backlogj表示顾客对于第j个服务质量要素的综合偏好。
若||≤γ且||≤γ(γ是事先确定的阈值),则该服务质量要素为无差异要素;相反地,若|Backlogj|≤δ*Rangej(δ是事先确定的系数)且Backlogj≥0,则该服务质量要素属于一维要素;若|Backlogj|≤δ*Rangej且Backlogj<0,则该服务质量要素属于反向要素;若|Backlogj|>δ*Rangej且Backlogj≥0,则该服务质量要素属于兴奋要素;若|Backlogj|>δ*Rangej且Backlogj<0,则该服务质量要素属于必备要素,根据分类规则可以构建一个决策树,如图3所示。
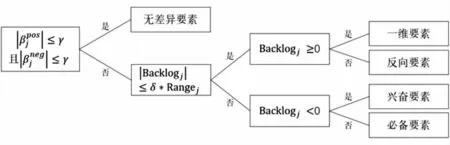
图3 Kano模型分类决策树
2.3.2 基于IPA模型的服务质量要素分类
IPA模型从重要性和绩效两个方面来对服务质量要素进行分类。在重要性方面,本研究通过构建Importancej变量来实现服务质量要素重要性的测量:

在绩效方面,本研究采用顾客对某一服务质量要素的满意度,即该要素上评论分段情感评分的均值¯xj来估计:
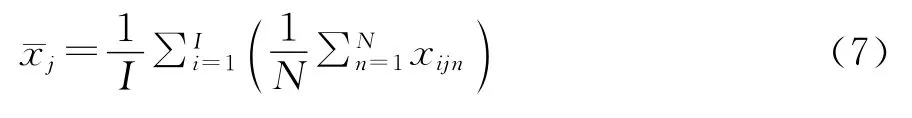
其中,N表示第i条评论中第j个服务质量要素上的评论分段的总数;I表示评论总数。
对于各要素的重要性与满意度,若其值高于平均水平,则记为高,否则应记为低。
2.3.3 基于IPA-Kano模型的服务质量要素分类
综合IPA与Kano模型的分类结果,决策优先级,确定各服务质量要素最终的类别、服务提升的方向以及决策的优先级。本研究赞同应当对低满意度的要素采取“提升服务”的策略,对满意度高的要素采取“继续保持”的策略。但关于策略的优先级,本研究进行了一定修改:提升服务时优先级Pri必备>Pri一维>Pri兴奋,因为服务水平由低到高变化时曲线的斜率k必备>k一维>k兴奋;采取继续保持策略时,优先级Pri兴奋>Pri一维>Pri必备,因为服务水平由高到低变化时曲线的斜率k兴奋>k一维>k必备。在相同情况下,重要性较高的要素优先级也较高。最终本研究修改后的IPA-Kano模型如表3所示。

表3 本研究修改后的IPA-Kano模型
3 实验与结果分析
3.1 数据准备
由于酒店在线预订行业集中度较高,头部平台活跃用户数据拔高明显,本研究采用行业活跃用户排名第一的携程网作为数据来源。使用Python爬取上海地区的9家连锁酒店评论共计10389条,如表4所示。将所有评论按标点符号拆分为评论片段,然后对评论片段进行数据预处理,最终将每条评论片段转化为一组特征词的集合。

表4 数据集合
3.2 顾客偏好估计
基于文献研究,本研究将酒店服务质量划分为酒店位置、服务、餐食、装修、房间设施、酒店设施、隔音、清洁和性价比9个维度。使用朴素贝叶斯算法对评论片段进行分类,首先随机抽取3000条评论(约占整体评论片段5%)进行人工标注,作为模型训练集与测试集。使用Python中的sklearn进行模型的训练与调优,最终模型精度为81.41%,评论片段的分类结果如表5所示:

表5 评论片段分类结果
使用Python语言的开源库Snow NLP对所有评论片段计算情感评分,为方便后续研究的开展,对Snow NLP得到的情感评分进行转换,使其取值区间为[-1,1]。计算与,将全部10389条评论数据作为输入数据进行参数估计,使用SPSS25进行计算,得到各要素的顾客偏好与的估计结果(表6)。
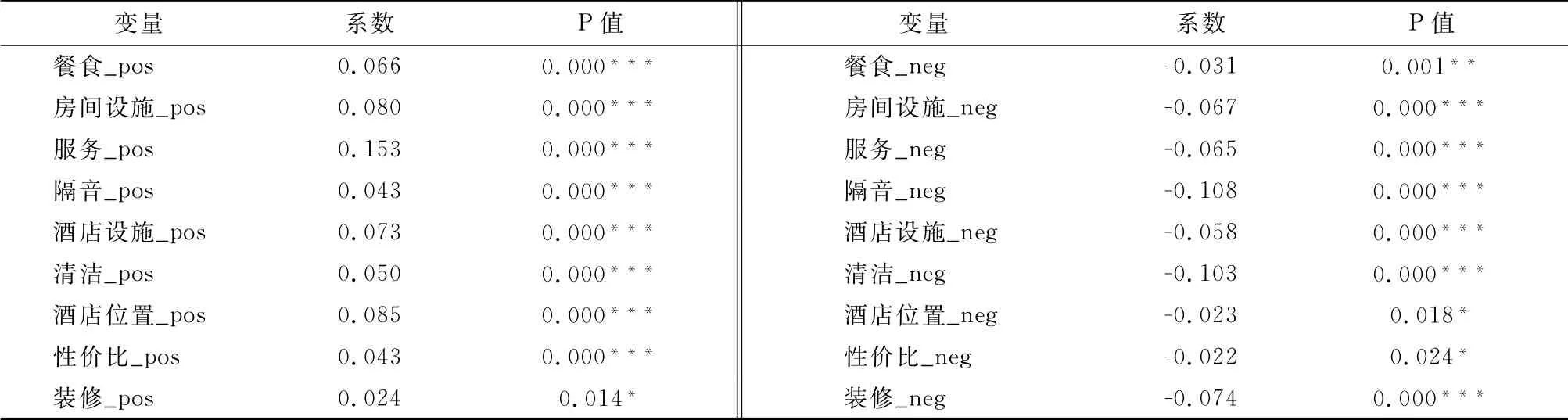
表6 各维度的权重估计结果
3.3 服务质量要素分类
结合实际数据,本研究将γ与δ分别设置为0.01与0.2。计算各服务质量要素的Range、Backlog、Importance与xj值,得到结果见表7。

表7 参数计算结果
根据前文提到的Kano模型分类标准,清洁、隔音与装修属于必备要素,当顾客对于这些要素的需求得不到满足时,易造成顾客的满意度大幅下降,而当顾客的需求得到基本满足后,其对于满意度的贡献并不明显;酒店设施与房间设施属于一维要素,当顾客在这些方面的需求被满足时会提高顾客满意度,反之亦然;服务、餐食、酒店位置与性价比属于兴奋要素,是酒店的加分项,这些方面的需求被满足后能大幅提高顾客的满意度。
结合各要素重要性与满意度的评分,得到最终IPA-Kano模型分类结果(表8)。针对顾客满意度低于平均值的要素(隔音、装修与房间设施)应采取提升服务的策略。又因为隔音与装修属于必备要素,在满意度水平较低时提升效率更高,因此优先级排序为Pri隔音>Pri装修>Pri房间设施;对于余下顾客满意度高于平均值的要素,应采取继续保持的策略,考虑到顾客需求得到满足后兴奋要素、一维要素与必备要素对满意度的影响依次递减,各要素的优先级应为Pri服务>Pri酒店位置>Pri餐食>Pri性价比>Pri酒店设施>Pri清洁。

表8 IPA-Kano模型分类结果
4 结语
用户生成内容一直是互联网2.0时代以来的研究热点,得益于用户生成内容的出现,研究者们终于可以以相对较低的成本获取大范围的用户数据用于研究。本研究提出的服务质量管理研究思路具备以下两方面意义:
一方面,通过文本挖掘技术与联合分析法实现了基于大体量用户数据的用户偏好测量,研究样本更具备代表性,研究结果更具备客观性与可信度;另一方面,在后期对用户数据的分析与研究上使用已经过学界验证与认可的成熟模型(IPA-Kano),保障了研究体系的科学性与严谨性,使最终结果更具备理论与实际意义。
本研究仍然存在一定不足,后续的研究可以从以下方向开展:首先,由于目前文本挖掘技术尚未完全成熟,对部分反问或包含讽刺、反语的文本未能准确地进行识别与处理,这需要在未来进一步优化文本特征提取与语义理解的相关算法;其次,随着互联网技术的进步,用户生成内容的形式日益丰富,除了评论文本外,还常常包含图片、视频等多媒体数据,在后续研究中可以将其他媒体形式的数据纳入研究范围,研究多模态数据下服务质量管理研究的新思路。
