面向问句复述识别的语义正交化匹配方法研究
2021-12-27朱朦朦武恺莉
朱朦朦,武恺莉,洪 宇,陈 鑫,张 民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
问句复述识别,旨在判断两个自然问句的语义是否等价。该任务不仅要准确理解问句的语义,还要比较两个问句语义是否一致。比如问句“红米手机质量怎么样?”与 “红米手机好不好”,两者都是询问红米手机好不好,为复述关系。作为一项基本任务,问句复述识别对其他自然语言处理任务的研究也存在重要价值。在机器翻译任务[1]中,问句复述识别可以更好地理解问句语义,得到更准确的翻译;在问答任务[2]中,通过找到相似语义的问句,获得正确答案。同时,问句复述识别还可以被应用在多个生活领域,如智能问答机器人[3]、搜索引擎等。
深度神经网络模型的出现推动了自然语言处理任务的研究,问句复述识别任务也不例外。卷积神经网络(Convolutional Neural Network, CNN)[4]具有处理速度快和特征提取能力强等优点,经常被应用在机器翻译和文本分类[5]任务中。循环神经网络(Recurrent Neural Network, RNN)、长短时记忆网络(Long Short Term Memory Network, LSTM)[6],不仅可以处理串行化数据,还可以保留上下文信息,在文本处理任务中被广泛应用。前人在这些基本神经网络基础上,提出了大量优秀模型,用于问句复述识别任务的研究。问句复述识别通常被当作二分类任务,从问句语义理解和问句对的联合特征抽取两个方向进行研究。因此,模型可以被分为基于问句语义理解和基于融合语义抽取特征两类。Severyn等人提出的Convnet模型[7]和Wang等人提出的BiMPM模型[8]都是为了获得更好的问句表示,属于基于问句语义理解一类。Gong等人提出的DIIN模型[9],则更关注问句对之间的交互和融合,属于基于融合语义抽取特征一类。以上方法都是将问句编码为统一向量表示,再对两个问句进行比较。然而,人们在日常生活中比较两个句子时,通常是根据两个问句的相同点和不同点进行判断的。因此,本文提出了语义正交化匹配方法(Semantic Orthogonal Matching Method, SOMM),将语义正交化引入到该任务中,尝试找出两个问句的相似语义编码表示和差异语义编码表示。
通过使用SOMM方法,模型不仅可以获得一个问句相对于另一个问句的相似语义表示,而且可以获得一个问句相对于另一个问句的差异语义表示。比如输入问句P和问句Q,该方法可以将问句P表示为Pdiff和Psame两部分,其中,Pdiff是问句P相对于问句Q的差异语义表示,Psame是问句P相对于问句Q的相似语义表示,同样地,对问句Q也会得到对应的Qdiff和Qsame。每一个问句都会被拆分为差异表示和相似表示两部分。实验结果表明,应用该方法的模型获得了与前沿工作可比的性能。本文的主要贡献如下:
(1) 将语义正交化思想引入问句复述识别任务中,提出了语义正交化匹配方法,该方法获得的句子相似表示和差异表示,既增强了对问句语义的理解,又实现了多粒度的问句交互。
(2) 分别在中文复述识别语料LCQMC[10]和英文复述识别语料Quora[11]上进行实验,实验结果证明了语义正交化匹配方法的有效性,且发现该方法对编辑距离小的问句判别更为准确。
本文的组织结构如下,第1节主要回顾前人在问句复述识别任务上的相关工作;第2节具体介绍本文提出的SOMM方法;第3节给出实验部分;第4节分析和对比实验结果;第5节为总结与展望。
1 相关工作
问句复述识别是文本匹配的一个分支,早期的问句复述识别通过字符串相似度或词频等特征判断两个句子语义是否相同。随着对自然语言理解研究的深入,人们希望机器不仅可以理解问句语义,还可以识别问句语义是否一致。对深度神经网络建立二元分类模型,即可实现对问句的复述识别。根据处理问题的侧重点不同,可以将现有模型架构分为以下两类。
1.1 基于句子语义表示的模型架构
基于句子语义表示的模型架构分为单句语义表示模型和跨句语义表示模型,下面分别对两种模型的具体做法进行介绍。
1.1.1 单句语义表示模型
单句语义表示模型一般使用孪生神经网络(Siamese Network)或伪孪生神经网络(Pseudo-Siamese Network)。孪生神经网络由共享权重值的两个神经网络组成,而伪孪生神经网络的两个神经网络不共享权重。在问句复述识别任务中,首先将两个问句分别输入到神经网络中,得到问句的句子表示,再计算这两个句子表示的距离,作为两个问句的相似程度,最后根据相似度进行分类,获得复述识别结果。Convnet模型是典型的基于单句语义表示的模型架构,该模型使用字符级输入,用LSTM等网络分别对问句进行句子编码,再计算两个句子表示的相似度,将得出的结果作为分类器的输入,进而判别两个句子是否互为复述关系。单句语义表示的模型架构简单,训练速度快,比较容易实现,但其缺点是: 语义表示较为单一,没有考虑另外一个句子的语义影响,并且两个问句之间没有交互。
1.1.2 跨句语义表示模型
跨句语义表示模型是指在对句子进行编码表示的同时,结合另一个句子的语义信息,得到更丰富的语义表示。该类模型一般利用注意力机制[12]。在对句子编码的过程中,将两个句子中的注意力相关的语义编码到彼此的句子表示中,增强句子原有的语义表示。BiMPM模型是跨句语义表示的代表,该模型首先使用双向长短时记忆网络(Bidirectional Long Short Term Memory Network, BiLSTM)[13]分别对问句进行编码,得到每个句子的前向语义表示和后向语义表示,再利用4种不同的注意力机制,将两个句子的前向语义表示和后向语义表示分别进行交互,最后通过聚合交互的输出得到每个句子的语义表示。此种基于跨句语义的表示模型在一定程度上弥补了单句语义表示模型的缺点,但交互过程较为复杂。
1.2 基于句子融合语义抽取特征的模型架构
基于句子融合语义抽取特征的模型,主要是解决如何从融合语义中抽取出联合特征的问题。模型首先对两个句子的向量表示进行融合,再对融合向量进行特征提取。该类模型更多地关注句子表示的融合以及联合特征的抽取。在DIIN模型中,作者首先分别对两个句子进行编码,得到对应的向量表示,再将两个句子的表示按位融合,利用DenseNet[14]作为卷积特征提取器提取联合特征。这类模型架构可以更好地将句子特征融合,并抽取出高维的联合特征,但其无法获得更丰富的句子语义表示。
2 语义正交化匹配方法
2.1 模型概览
针对问句复述识别任务,本文从问句语义理解和问句对之间的交互关系两个方向进行探索,提出了SOMM方法。问句复述识别任务,即对给定的两个自然问句P和Q,识别两者是否互为复述关系。其中句子Pw=(pw1,…,pwi,…,pwm),句子Qw=(qw1,…,qwj,…,qwn),m、n分别为问句P和问句Q的长度,pwi、qwj分别为问句P的第i个单词和问句Q的第j个单词。
本文提出的SOMM方法,可以被运用到现有的模型架构中获得更好的性能。SOMM方法的整体架构如图1所示,共有4层,分别为词向量层、语义正交化编码层、语义交互层和输出层。

图1 使用SOMM方法的模型架构图
首先,模型通过词向量层,对问句中的每个单词进行向量表示,再将其输入到语义正交化编码层,获得句子的表示,两个句子表示在语义交互层进行融合,最后经过输出层获得判别结果。下面将通过一个例子具体介绍本文提出的模型框架。比如问句P为“港囧什么时候上映”,问句Q为“芈月传什么时候上映”。首先将分词后的两个问句分别经过词向量层进行句子编码,再将句子编码输入到语义正交化层。
在语义正交化层中,编码后的问句P和Q被依次输入到LSTMS中,由于参数共享,编码时两个问句中的相似部分“什么时候上映”被突出,获得对应的Psame与Qsame。编码后的问句P同时被输入到LSTMP中,在正交化损失LP的限制下,问句P相对于问句Q的差异部分“港囧”被突出,获得Pdiff,同理,问句Q相对于问句P的差异部分“芈月传”也被突出,获得Qdiff。在语义交互层,将两个问句的相似表示与差异表示分别进行比较,由于“港囧”和“芈月传”两个差异表示区别较大,最后在输出层就可以判定问句P和问句Q是不是复述关系。
2.1.1 词向量层
该层的主要功能是将句子中每个单词或短语编码为向量表示,由这些向量表示拼接得到向量矩阵,用于表示整个句子。单词的向量表示称为词向量,获得词向量通常有两种方法: 一种是使用预训练词向量,如GloVe词向量[15],该类词向量一般由语言模型在特定语料上训练得到,可以被直接使用;另一种是随机初始化的词向量,该类词向量在模型训练过程中会被不断更新。针对中文数据集,本文使用的是Shen等人[16]提供的预训练词向量,该词向量是由Shen等人在百度百科语料上使用Word2Vec模型训练得到的。针对英文数据集,本文使用的是GloVe词向量,该词向量由Pennington等人在维基百科语料库上使用词共现矩阵和GloVe模型学习得到。词向量层不仅能够将单词编码为词向量,还可以使用词性标注、句法树分析等预处理工具,将词法和句法信息也编码到句子向量表示中。词向量层将得到两个句子的向量表示,分别为PE:[pE1,…pEi,…,pEm]和QE:[qE1,…qEj,…,qEn],其中pEi为句子P的第i个单词的向量表示,qEj为句子Q的第j个单词的表示。
2.1.2 语义正交化编码层

其中,X为输入句子第t个时刻的词向量,既可以表示问句P的词向量又可以表示问句Q的词向量;n为总步数;[·,·]为拼接操作。
在本层中,共使用3个不同的BiLSTM,两个私有,一个公有。两个问句都分别被输入到私有BiLSTM和公有BiLSTM中,由于公有的BiLSTM为两个问句的共享网络,可以获得每个问句相对于另一个问句的相同部分的表示,即Psame和Qsame。当加上正交限制后,私有的BiLSTM就可以获得每个问句相对于另一个问句的不同部分的特有表示,即Pdiff和Qdiff。这样就达到了将每个句子都拆分成相似表示和差异表示两个部分的效果。本文将在2.2节具体介绍语义正交化方法。
2.1.3 语义交互层
该层主要是对语义向量的交互和融合。在第1节的相关工作中,本文介绍了三类现有的模型架构。按照模型架构的不同,语义交互层也存在三种不同的交互方式。
对于基于单句语义表示的模型架构,语义交互层如图2所示。

图2 基于单句语义表示的语义交互层
将问句P表示为Psame与Pdiff的拼接,问句Q表示为Qsame与Qdiff的拼接,对这两个问句拼接后表示计算余弦相似度,作为分类器的输入,该过程计算如式(4)~式(6)所示。
P=[Psame,Pdiff]
(4)
其中,Cosine()为余弦相似度函数,hlast为该层的语义交互结果。
对于基于跨句语义表示的模型架构,语义交互层如图3所示。将Psame与Qsame使用双向注意力机制进行交互,得到P′same和Q′same,将Pdiff与Qdiff也使用双向注意力机制进行交互,得到P′diff和Q′diff。问句P表示为P′same和P′diff拼接;问句Q表示为Q′same和Q′diff拼接,最后将两个问句的表示拼接,作为分类器的输入,该过程计算如式(7)~式(9)所示。
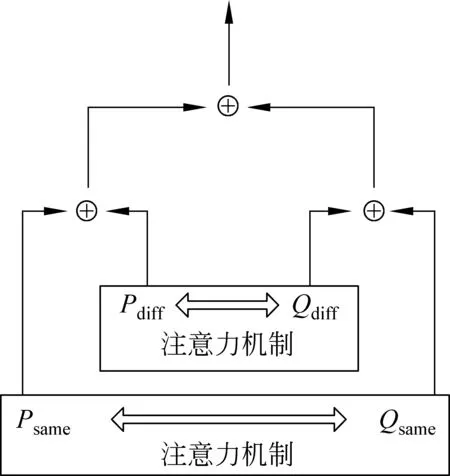
图3 基于跨句语义表示的语义交互层
其中,Attention为双向注意力机制。
针对基于句子融合语义抽取特征的模型架构,语义交互层如图4所示。首先将问句P、Q分别表示为Psame与Pdiff、Qsame与Qdiff的拼接,如式(4)、式(5)所示。再将两个句子表示按位融合,利用DenseNet作为卷积特征提取器提取联合特征,并将这联合特征作为分类依据,hlast的计算如式(10)所示。

图4 基于融合语义抽取特征的语义交互层
其中,⊙表示按位相乘运算。
2.1.4 输出层
该层是对已经获得的特征向量hlast进行解码,一般使用全连接网络和softmax函数进行二分类,预测出每个分类的概率,预测如式(11)所示。

2.2 正交化匹配方法
前人在解决复述识别问题时,通常是将每个句子进行编码,得到一个统一的句子表示。这个统一的句子表示既包含了和另外一个句子相关的部分,也包含了和另外一个句子不相关的部分。复述识别任务的核心问题是比较两个问句的相同点和不同点。
这种统一的句子表示,使得模型不仅要提取出两个问句的不同点和相同点,还要对其进行比较,增加了模型的复杂度。常见的区分两个句子的方法有两种: 第一种方法是利用注意力机制,根据相关性系数,使得每个问句都可以注意到另一个问句的信息。这种方法只能在一定程度上反映每个语义片段和另外一个问句中的相关性,但不能很好地区分相关与不相关部分;第二种方法是将句子表示进行融合,在融合的语义表示中抽取联合特征,用来当作复述关系的判别依据。这一种方法利用联合特征作为判断依据,只利用了两个问句的相关部分的语义信息,而没有利用不相关部分的语义信息,这就无法做到两个句子语义信息的充分比较与交互。
对于给定的两个问句,若能抽取出两个问句的相关语义信息和不相关语义信息,就可以实现多粒度的语义信息比较和交互,使得复述关系的识别更为准确。因此,本文提出SOMM方法,使句子语义正交化,实现对句子信息的拆分,利用拆分后的句子表示进行句子之间的交互。在第4节将会给出具体的对比结果。如图1语义正交化编码层所示,对于给定的问句P和问句Q,模型利用3个不同的BiLSTM对其进行编码,分别为私有特征语义编码器LSTMP、LSTMQ和公有特征语义编码器LSTMS。
公有特征语义编码器LSTMS被两个问句共享使用,问句P和问句Q被分别输入到该网络中,利用网络权重值共享,得到问句P相对于问句Q的相似编码表示Psame以及问句Q相对于问句P的相似编码表示Qsame。Psame和Qsame的计算如式(12)、式(13)所示。
其中,PE、QE分别为句子P和Q的词向量表示。
私有特征语义编码器LSTMP用于对问句P进行编码,在加入正交限制后,就获得了问句P相对于问句Q不同的编码表示Pdiff;私有特征语义编码器LSTMQ用于对问句Q进行编码,同样加入正交限制,获得问句Q相对于问句P不同的编码表示Qdiff。Pdiff、Qdiff的计算如式(14)、式(15)所示。
其中,PE、QE分别为句子P和Q的词向量表示。
句子表示的正交化通过损失函数实现,本文使用的是Bousmails等人[17]提出的损失函数,其计算如式(16)所示。


其中,Lall为总的损失,L为交叉熵损失,可由式(17)计算得出,LP、LQ分别为句子P和Q的正交化损失,其计算如式(19)、式(20)所示。
3 实验配置
本节主要介绍实验的相关配置,包括使用的数据集、评价指标以及实验参数设置。
3.1 数据集与评价指标
本文分别在两个数据集上进行实验,验证SOMM方法在问句复述识别任务中的有效性。
3.1.1 LCQMC数据集与评价指标
Liu等人[10]提出了大规模中文数据集LCQMC,该数据集包含大量的中文问句对,每一个问句对都有一个类别标签,表示该问句对是否互为复述,其正负样本分布如表1所示。在本文中,LCQMC使用的数据集划分与原作者发布的一致。

表1 LCQMC数据集的样本分布
在LCQMC数据集上,本文采用4个指标对其性能进行评估,分别为精确率P,召回率R,调和平均值F1值、准确率Acc。
3.1.2 Quora数据集与评价指标
Quora数据集为问句复述识别任务中常用的英文数据集,该数据集包含大量英文问句对及其对应的类别标签,其数据量的大小以及对应的正负样本分布如表2所示。在本文的实验中,使用的Quora数据集划分与BiMPM论文中的数据集划分一致。
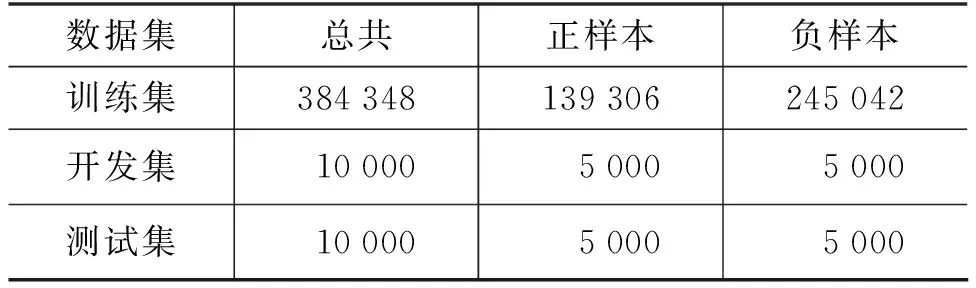
表2 Quora数据集的样本分布
在Quora数据集上,本文采用准确率Acc评估模型性能。
3.2 参数设置
对于中文数据集LCQMC,本文使用结巴分词对问句进行处理,得到每个问句对应的单词,再使用Shen等人提出的中文预训练词向量,将单词映射成向量表示。对于英文数据集Quora,直接使用300维的GloVe词向量对问句中的单词进行向量映射。在训练阶段,batch_size为64,LSTM的隐藏单元为200,优化函数为Adamax,学习率为0.002。
本文实验平台配置如下: 操作系统为CentOS 7.5,显卡型号为GTX 1080 Ti,显存大小为12GB。本文使用Pytorch深度学习框架进行实验,Python版本为3.6.3。
4 实验结果分析
本节主要介绍SOMM方法和业内其他方法在LCQMC及Quora数据集上的实验结果对比,针对结果进行相关分析;并探索了不同数据分布对SOMM方法的影响。
4.1 LCQMC实验结果
本节主要介绍SOMM方法在LCQMC数据集上的实验结果。为了充分验证该方法的有效性,本文在现有的两类模型架构上使用SOMM方法进行实验,即基于句子语义表示的模型架构和基于句子融合语义抽取特征的模型架构,其中,基于句子语义表示的模型架构又分为单句语义表示和跨句语义表示。对于每一种模型架构,本文都选取了一个具有代表性的模型作为基础模型。三个基础模型的实现方式如下。
对于基于单句语义表示的模型架构,本文使用的基础模型架构如下: 将两个问句输入到词向量层和BiLSTM中,得到每个问句的向量表示,再根据两个向量表示的余弦相似度进行分类,判断两个问句是否互为复述。
对于基于跨句语义表示的模型架构,本文使用BiMPM模型架构作为基础架构。为了获得句子的跨句语义表示,该模型首先使用BiLSTM获得句子的前向表示和后向表示,然后使用4种不同的注意力机制分别对两个句子的前向表示和后向表示进行交互融合,获得每个句子的跨句语义表示,最后将两个问句的跨句语义表示进行拼接融合,输入分类器。
针对基于句子融合语义抽取特征的模型架构,本文将Gong等人提出的IIN作为基础架构,首先将两个句子进行编码得到对应的向量表示,再将两个句子的表示按位融合,利用DenseNet作为卷积特征提取器提取联合特征,并将联合特征作为分类依据。
本文分别在三种基础架构上使用SOMM方法并进行对比实验。首先,将基于单句语义表示的交互层与SOMM集成,形成第一套实验系统;其次,将上述系统中的单句语义表示替换为跨句语义表示,从而形成第二套实验系统;最后,将融合语义特征的交互层与SOMM进行集成,形成第三套实验系统。本文2.1节对上述架构给出了详细解释,并分别对应于图2~图4。在数据集LCQMC上的实验结果如表3所示。

表3 LCQMC语义正交化实验结果
从表3的实验结果可以看出,无论在基于语义表示的模型架构,还是在基于句子融合语义抽取特征的模型架构,使用本文提出的SOMM方法,在调和平均值F1值与准确率Acc上都得到了显著的提升,充分证明了SOMM方法的有效性。对于单语义模型BiLSTM,在使用SOMM方法后,F1值提升了0.81%,Acc提升了1.58%;对于跨句语义模型BiMPM,在使用SOMM方法后,F1值提升了1.74%,Acc提升了2.26%;对于语义融合抽取模型IIN,在使用SOMM方法后,F1值提升了2.87%,Acc提升了2.53%。
为了与现有模型的性能进行比较,表4列举了现有模型在LCQMC上的实验结果。结果表明,本文在BiMPM模型上使用SOMM方法后,无论词向量层使用字符级还是单词级,调和平均值F1与准确率Acc都超过了现有模型的性能,证明了SOMM方法的有效性。
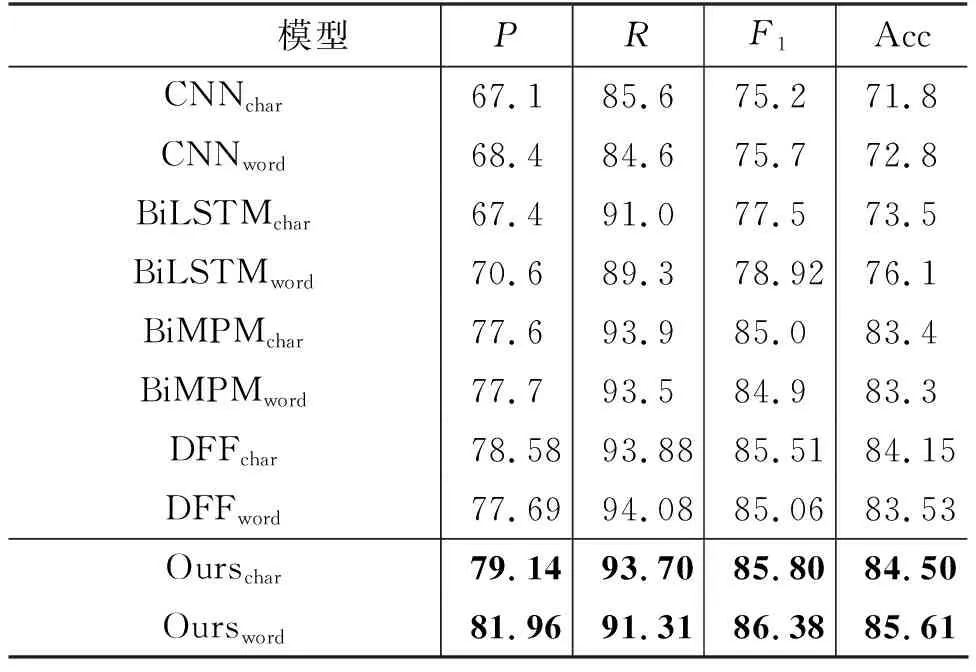
表4 LCQMC实验结果
当模型按字符输入时,F1值分别比CNN、BiLSTM、BiMPM、DFF高了10.6%、8.3%、0.8%、0.29%,Acc值分别比CNN、BiLSTM、BiMPM、DFF高了12.7%、11%、1.1%、0.35%。当模型按单词输入时,F1值分别比CNN、BiLSTM、BiMPM、DFF高了10.68%、7.46%、1.48%、1.32%,Acc值分别比CNN、BiLSTM、BiMPM、DFF高了12.81%、9.51%、2.31%、2.08%。
4.2 Quora实验结果
在Quora语料上,为了验证语义正交化方法的有效性,本文使用BiMPM模型作为基础架构进行实验。实验结果如表5所示。
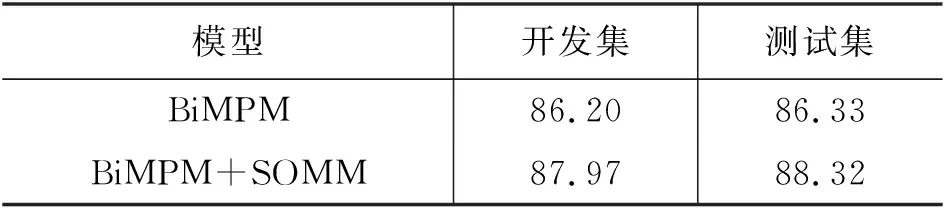
表5 Quora语义正交化实验结果
由于实验环境或其他因素限制,本文未重现出BiMPM模型原作者在Quora语料上的实验结果,即在开发集上准确率为88.69%,测试集上准确率为88.17%,但本实验的核心是验证语义正交化方法的有效性。实验结果表明,BiMPM在加上语义正交化方法后,准确率在Quora语料的开发集上提升了1.77%,在测试集上提升了1.99%。表6为现有模型在Quora数据集上的结果。

表6 Quora实验结果
4.3 测试结果分析
为了进一步探索数据分布对SOMM方法的影响,本节针对测试集做了补充实验。LCQMC的测试集共有12 500条,Quora的测试集共有10 000条。本文为了观测模型在测试集上的性能,将两个测试集按照莱文斯坦距离进行划分。莱文斯坦距离又称Levenshtein距离,是编辑距离的一种,常用来比较两个字符串之间的相似度[18]。下文的编辑距离都是指莱文斯坦距离。该距离是指对于两个字符串,一个字符串转换为另外一个字符串所需要的最少编辑次数,其中,编辑操作分为插入、删除和替换。
本文使用编辑距离衡量两个问句的差异程度。编辑距离越大,两个字符串差距越大,两个问句的差异程度也越大。在中文数据集LCQMC中,两个问句之间的编辑距离是指一个问句转换为另一个问句所需的最少编辑汉字的次数。在英文数据集Quora中,两个问句之间的编辑距离是指一个问句转换为另一个问句所需的最少编辑单词的次数。图5是两个测试集按编辑距离划分的数据分布图,横坐标为编辑距离的范围,纵坐标为具体的数据量。

图5 测试集数据分布图
图5表明,LCQMC测试集整体的编辑距离较小,10以内的编辑距离占据了总测试集数量的92%以上,而Quora测试集的编辑距离分布较为均衡,但编辑距离在10以内的也占据了65%以上。由此可以看出,两个测试集的问句对大部分都很相似。依据图5的数据划分,在基础模型BiMPM上使用2.1节中介绍的SOMM方法进行对比实验,并比较这两个模型在不同数据分布上的性能表现。
图6为模型在LCQMC测试集上的实验结果,图7为模型在Quora测试集上的实验结果。其中,横坐标为编辑距离的范围,纵坐标为模型的准确率。实验结果表明,无论是LCQMC数据集,还是Quora数据集,在编辑距离为15以内的测试数据上,使用了SOMM方法的BiMPM模型在评价指标准确率上均有所提升。这表明SOMM方法在编辑距离小于15的数据上有着更好的表现。对于编辑距离较小的问句对,SOMM方法可以更准确地区分出两个问句的相同点和不同点,再将两个问句的相同点和不同点分别进行比较,就得出了较为准确的判断依据。
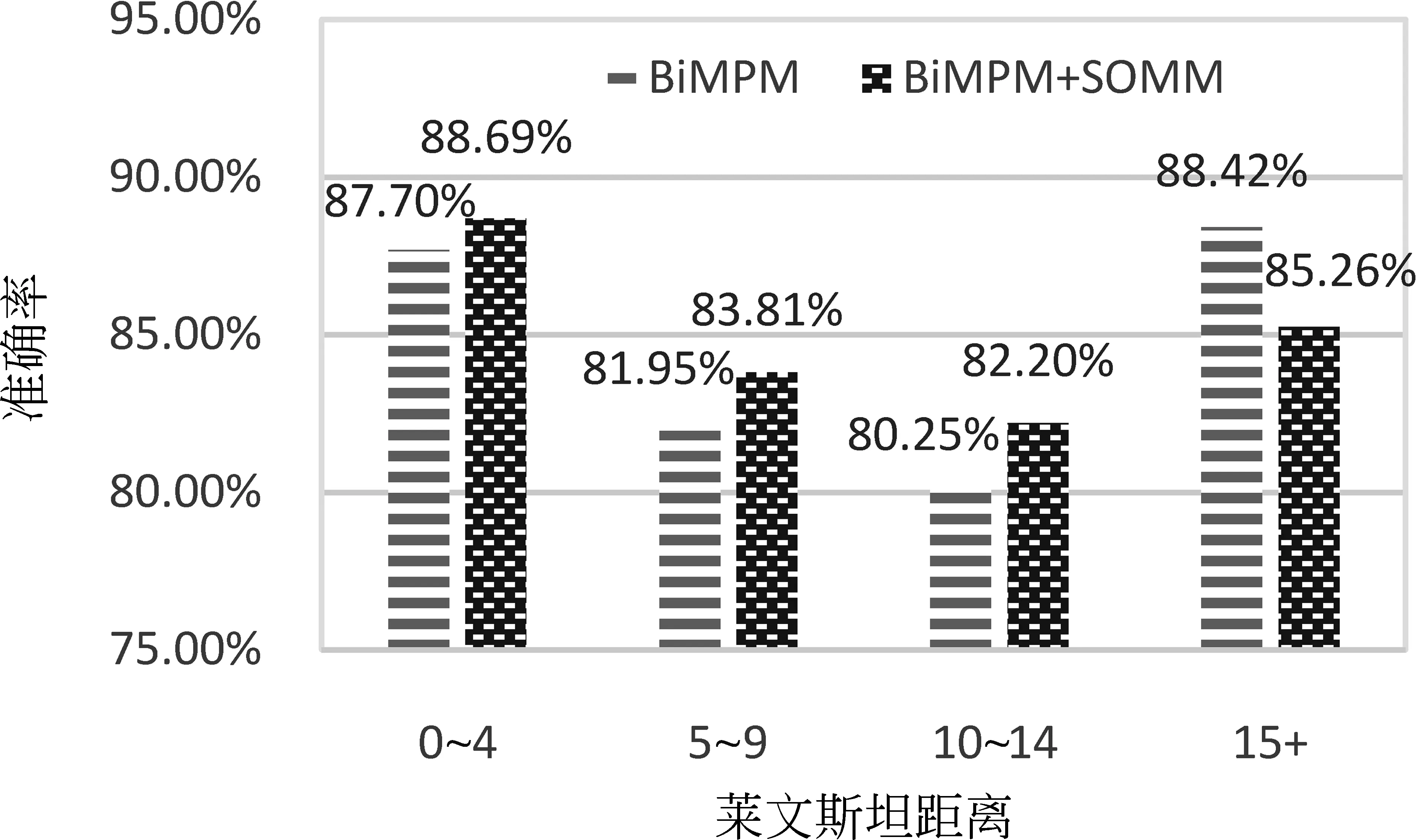
图6 准确率分布图——LCQMC

图7 准确率分布图—Quora
例1是LCQMC测试集上的两个问句对:
问句1: 木瓜牛奶怎么煮?
问句2: 怎么做木瓜炖牛奶?
标签: 1
问句3: 欣赏是什么意思?
问句4: 欣赏的赏是什么意思?
标签: 0
(例1)
基础模型BiMPM对这两个问句对都预测错误,但在加上SOMM方法后都预测正确。例1中的问句1与问句2互为复述,问句3与问句4不是复述关系。虽然两个问句对的编辑距离都为2,但是对应的标签却不相同。正是因为基础模型BiMPM使用了SOMM方法,获得了更好的性能。
SOMM方法既区分出了两个问句的不同点和相同点,又使得每个问句的相似语义表示与差异语义表示相互关联,不仅丰富了问句的表示,又使得两个问句之间充分交互,才得到了更为准确的预测结果。
5 总结与展望
本文针对问句复述识别任务的特点,将SOMM方法应用到该任务中,实现了对问句语义的拆分。通过SOMM方法,每个问句都被拆分为两个部分,即与另一个问句的相关部分和不相关部分,得到一种新型的问句表示。这种新型的问句表示,可以直接被应用在基于单句语义模型架构或基于融合语义抽取特征的模型架构上,也可以在基于跨句语义模型的架构上实现句子之间的多粒度语义交互。本文在中文数据集LCQMC和英文数据集Quora上进行实验,验证了SOMM方法在问句复述识别任务上的有效性。为了探索SOMM方法在不同数据分布上的性能表现,本文还将两个数据集的测试集按照编辑距离划分,观测模型性能,证明了使用SOMM方法的模型更适用于编辑距离小于15以内的数据。
在未来工作中,将进一步完善SOMM方法在问句复述识别任务中的应用,将基于跨句语义的模型架构与基于融合语义抽取特征的模型架构相结合,实现更深层次的语义理解和交互。同时,也会尝试将SOMM方法应用到其他自然语言理解任务中。目前,问句复述识别模型主要是基于语义相似度,还未实现基于意图相似度。大规模的数据集和意图相似的准确定义都将成为未来的重要研究方向。
