面向垂直领域的阅读理解数据增强方法
2021-12-27吕政伟石智中刘多星
吕政伟,杨 雷,石智中,梁 霄,雷 涛,刘多星
(汽车之家, 北京 100080)
0 引言
随着近几年智能问答的高速发展,阅读理解问答作为其重要发展方向之一,也逐渐成为各领域的研究和应用热点。不同于传统问答系统中利用知识表示和检索方式获取答案[1-2],基于阅读理解的问答利用模型直接对非结构化文档进行认知,从而获取给定问题的答案[3-5]。这种方式减少了知识的收集和表示过程,具有重要的研究和应用价值。
阅读理解问答根据答案的产生方式,分为选择式、抽取式、生成式等类型,其中,抽取式阅读理解根据问题从文档中抽取一个连续片段作为答案,不用考虑答案的序列生成问题,答案获取方式直接,标注相对方便,难度适中,因此对抽取式阅读理解的研究相对较多。一系列大规模、高质量评测数据集的发布,如SQuAD数据集[6-7]、DuReader数据集[8]、CMRC 2018数据集[9]等,促进了对阅读理解问答的研究。但是这些数据集偏向于通用领域或百科知识,内容广而泛,针对垂直领域专业性的知识少,因此,面向垂直领域的抽取式阅读理解的数据标注和应用研究十分必要。
在抽取式阅读理解数据集的标注过程中,标注人员提出的问题容易出现标注数据模式化、表达方式单一、多样性不足的问题,从而导致在应用中造成模型的准确性和鲁棒性较差。数据增强通常被用来解决这一问题,其原理是通过无监督、半监督或者有监督的方法构造新的训练样本,对原始的训练数据进行扩充,增加训练数据的量级和多样性,从而提升模型的准确性和鲁棒性。在机器阅读理解中,常见的数据增强方法有以下几种。
远程监督方法: 为利用外部知识库自动对语料进行标注[10],构造训练数据,增加数据的量级。然而,这种方法会引入很大的噪声,影响模型的语义理解,如图1所示,当问题的答案“日本”在一篇文档中多次重复出现,答案的标注位置不能很好地确定时,将会影响模型整体的语义理解。

图1 远程监督方法构造训练数据
问题生成方法: 该方法利用模型生成标注数据中问题的同义复述[11-12],实现增加问题表达的多样性。但是,目前序列生成技术不够成熟,且缺乏适当的评测指标,生成数据的质量难以控制,最终会导致构造数据的误差大、阅读理解模型效果差。
完全生成方法: 该方法给定未标注文档,首先利用模型从文档中获取适合作为答案的片段,再根据文档内容和该片段生成相关问题。这种方法不需要已有阅读理解标注数据即可构造数据,能极大地提升构造数据的量级和覆盖范围。但该方法引入的误差较大,除了问题生成环节的误差,在答案片段选取环节、问题和答案相关性等方面也会引入误差,形成误差的累积,最终影响构造数据的质量。
上述方法都是针对通用领域的研究,忽略了数据增强与实际应用数据的结合,造成构造数据与应用数据之间的语义偏差,影响模型的应用效果。另外,在垂直领域中,领域术语多,问题更为专业,衍生出的表达方式更多样化,用远程监督或模型生成方式构造的数据,很难满足专业性和多样性,容易造成模型应用中准确率低、鲁棒性差。
针对以上问题,本文提出了一种垂直领域中基于真实用户问题的数据增强方法,该方法也是对训练数据中的问题产生复述,以增加数据的多样性,但不采用序列生成的方式,而是基于用户问题的表达形式进行构造,避免了序列生成模型的训练,增加数据的可控性。同时,构造数据是基于真实数据产生的,增加了数据的一致性。该方法首先通过实体识别构建问题的语义原型库,并利用相似度计算获取当前问题的相似原型,然后对相似原型进行语义泛化,构造出包含真实语义结构的同义问句,增加问题的多样性,从而增加整个训练数据的量级和多样性。我们将本文提出的方法在真实汽车领域数据上进行实验,结果表明,本方法能有效提升问答模型的准确率和鲁棒性。
综上所述,本文的主要贡献包括: ①提出了一种垂直领域中基于真实问题的数据增强方法,提升了模型的准确率和鲁棒性; ②在汽车领域数据上对多个模型和数据增强方法进行了对比实验,实验结果证明了该方法的有效性。
1 相关工作
SQuAD等大规模评测数据的出现,引起学术界和工业界对抽取式阅读理解的深入研究,R-Net[3]、DrQA[4]、QANet[5]等一大批深度学习模型被相继提出。随着BERT[13]、RoBERTA[14]、AlBERT[15]等预训练模型的提出,抽取式阅读理解取得了突破性进展,多种基于预训练模型的方法,在SQuAD 2.0数据集上的评价指标超过了人类水平。本文根据各种深度学习模型和预训练模型,对垂直领域抽取式阅读理解的数据增强方法进行研究,以提升各种模型在垂直领域中的准确率和鲁棒性。在机器阅读理解任务中,常用的数据增强方法有远程监督方法、问题生成方法和完全生成方法三种。
远程监督方法: 利用外部知识库自动对语料进行标注,构造训练数据,如Chen等[4]利用QA问答对作为知识库,通过检索得到相关文档片段,构造训练数据。Zhang等[16]通过知识三元组(E1,R,E2),用实体E1和关系R构造问题,实体E2作为答案,用问题和答案检索无标注文档,构造训练数据,从而增加数据量级,提升模型性能。
问题生成方法: 利用模型生成新的问题,构建训练数据,包括生成相关问题和生成同义复述问题两种。Zhu等[17]通过生成相关但不可回答的问题,提升模型的语义理解能力,在SQuAD 2.0数据集上取得1.9个F1点的提升。Gan等[18]提出引导式的生成方法,利用Seq2Seq模型生成同义问题,增加问题的多样性,提升模型的准确性和鲁棒性。
完全生成方法: 给定文档,直接利用模型根据文档内容生成相关问题和答案,构造训练数据。如Subramanian等[19]利用模型先从文档中提取关键短语,并以该短语为参考答案生成相关的问题,从而构造训练数据。Puri等[20]先用BERT从文档中提取答案片段,再将答案和文档进行拼接,利用GPT2[21]模型生成相关问题,构造训练数据。
以上几种数据增强方法都是针对通用领域的研究,忽略了数据增强与实际应用数据的结合,会造成在垂直领域应用中构造数据与实际数据之间的语义偏差,从而影响模型应用效果。另外,远程监督的方法容易引入数据噪声,问题生成方法的数据质量难以控制,并且需要训练序列生成模型,同时垂直领域中数据专业性程度高,领域实体数量多,表达多样化,因此以上方法在垂直领域中并不适用。借鉴其他自然语言处理任务中利用替换的方式进行数据增强的思想[22-23],本文提出了一种垂直领域中基于真实用户问题的数据增强方法。利用真实用户数据,对训练数据中的问题进行复述,以增加数据多样性,避免了序列模型的训练,提升数据的可控性。同时,构造数据是基于真实数据产生的,增加了数据的一致性。最后在汽车领域数据集上,本文通过实验证明,该方法对模型的准确率和鲁棒性均能有效提升。
2 数据增强方法
本文提出的数据增强方法是基于真实用户问题,该数据来源于问答系统的日志记录。首先通过实体识别对用户问题进行处理,构建语义原型库;然后利用相似度计算方法,从原型库中获取当前问题的若干相似原型;最后对相似原型进行语义原型泛化,构造出包含真实用户问题语义结构的同义问题。
2.1 问题预处理
问题预处理,是将用户问题进行实体识别,从而获取问题语义原型的过程。将问句抽象为字符序列Q=(c1,c2,c3,c4,…,cn-1,cn),对序列Q进行实体识别,得到序列如式(1)所示。
QT=[c1,…,E1(ci,ci+1),…,E2(ci+k),…,cn]
(1)
其中,Ei为识别出的实体,ci为问句中的字符,QT称为问句的语义原型。将真实用户数据进行预处理,构建问句的语义原型库,从而可以获取大量的表达多样的语义原型数据来构造训练数据的同义问题。
问句预处理过程中的实体识别是指将文本中具有特定含义的文字片段作为一个整体识别出来。在通用领域,实体的类型主要有人名、地名、机构名称、专用名词等;在汽车垂直领域,实体的类型有车系、车型、品牌、车身参数、配置等。
2.2 语义原型相似度计算

(2)
其中,ω1、ω2、ω3为权重参数;R1为实体类型相关因子,代表两个原型实体类型的相关性;R2为实体顺序相关因子,代表两个原型实体类型的先后顺序一致性;R3为语义相关因子,代表两个原型的语义相关性。


(3)
R2为实体顺序相关因子,实体先后顺序一致时R2=1,否则R2=0。R3为两个原型的语义相似度值,本文语义相似度的计算采用SBERT[24]模型,首先将原型中的实体词替换为实体名称,得到新的问题表示,利用孪生网络对问题中的字符进行向量化表示,通过计算向量的余弦值得到问题的相似度。网络的训练和推理如图2所示。训练阶段,问题1和问题2输入到BERT模型,经过平均池化,输出得到向量u和v。向量u、v及两个向量内部元素的差值|u-v|进行拼接,输入到Softmax分类器中进行训练。在推理阶段,直接计算u和v的余弦值,得到R3值。

图2 语义相似度计算网络
2.3 语义原型泛化
语义原型泛化是对相似原型进行处理获取同义问题的过程,利用问题原型中的实体内容,替换相似原型对应的实体内容,改变了相似原型问句表达的内容主体,但是相似原型的语义结构保持不变,从而构造出主体内容一致、但表达形式多样的同义问题,能有效增强构造数据中问题的多样性表达。
语义原型的泛化过程如图3所示,通过对当前问题进行处理,从原型库选取与当前问题语义原型相似的若干原型,用当前原型的实体,替换相似原型中同类别实体。例如,用“宝马X3”替换“奥迪Q3”,用“价格”替换“钱”等,保留相似原型中的其他字符不变,从而得到当前问题的同义问题。

图3 基于语义原型的同义问题构造
3 实验
3.1 实验数据
本文对提出的数据增强方法在汽车领域数据集上进行验证,该数据集通过人工标注获取,对给定的每篇资讯文章提出3~5个相关问题并标出答案位置。该数据集共包含905篇汽车类资讯文章和2 746个相关的问题,分为训练集和测试集两部分。为了验证鲁棒性,对测试集中的问题进行人工复述,每个问题生成若干个同义表达,产生鲁棒性测试集,共包含2 312个同义表达的问题,数据样例见表1,具体细节见表2。

表1 标注数据样例

表2 实验数据
本文在2.1节问题预处理部分,实体识别是用汽车领域专用的实体识别算法,能够识别出车系、车型、品牌、车身参数、配置等领域实体。2.1节中语义原型相似度计算部分,SBERT语义相似度模型需要数据进行训练。为了避免人工标注,在网络上搜集百度知道中的提问和相关提问数据,用汽车领域的关键词进行筛选,最终得到约20万组相关问题,约100万条数据。同组问题组合标记为正样本,不同组数据组合标记为负样本,构造模型的训练数据和测试数据,训练SBERT语义相似度模型。
3.2 对比实验
为了验证本文提出的数据增强方法的有效性,本文用BERT_base模型作为基准模型进行实验,其中,Batch_size为6,Epoch为4,其他超参数保持不变,对比以下各种数据增强方法。
简单数据增强方法EDA[22]: 对原始训练数据集中的问题进行处理(同义词替换、插入、删除、交换位置)得到新问题,随机抽出新问题与原始训练数据中的文档进行组合,构造训练数据。
远程监督增强方法DS[16]: 将汽车领域新闻资讯文章按段落进行切分,构建Elasticsearch索引,用汽车领域知识图谱中3万个知识三元组数据进行搜索,将检索到的段落作为文档D,用知识三元组(E1,R,E2)中的实体E1和关系R构建问题Q,实体E2作为答案A,构建训练数据(Q,D,A)。
语义原型泛化增强方法PG: 本文所提数据增强方法。
以上三种方法在测试集和鲁棒性测试集上的实验结果如图4和图5所示。横坐标Naug表示添加构造数据的数量,Naug=0表示没有添加构造数据,Naug=1表示添加了原始训练数据1倍数量的构造数据。实验结果表明,在汽车领域数据测试集和鲁棒性测试集中PG方法效果要优于其他两种方法。
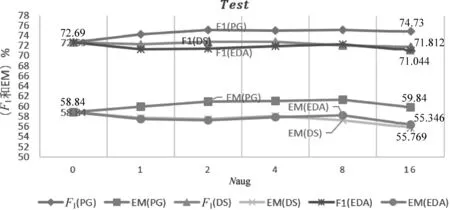
图4 在测试集上三种方法对比实验PG方法提升效果明显优于EDA和DS方法;PG方法在EM和F1指标上均有两个点以上的提升;当Naug大于16时,三种方法效果均有下降趋势。
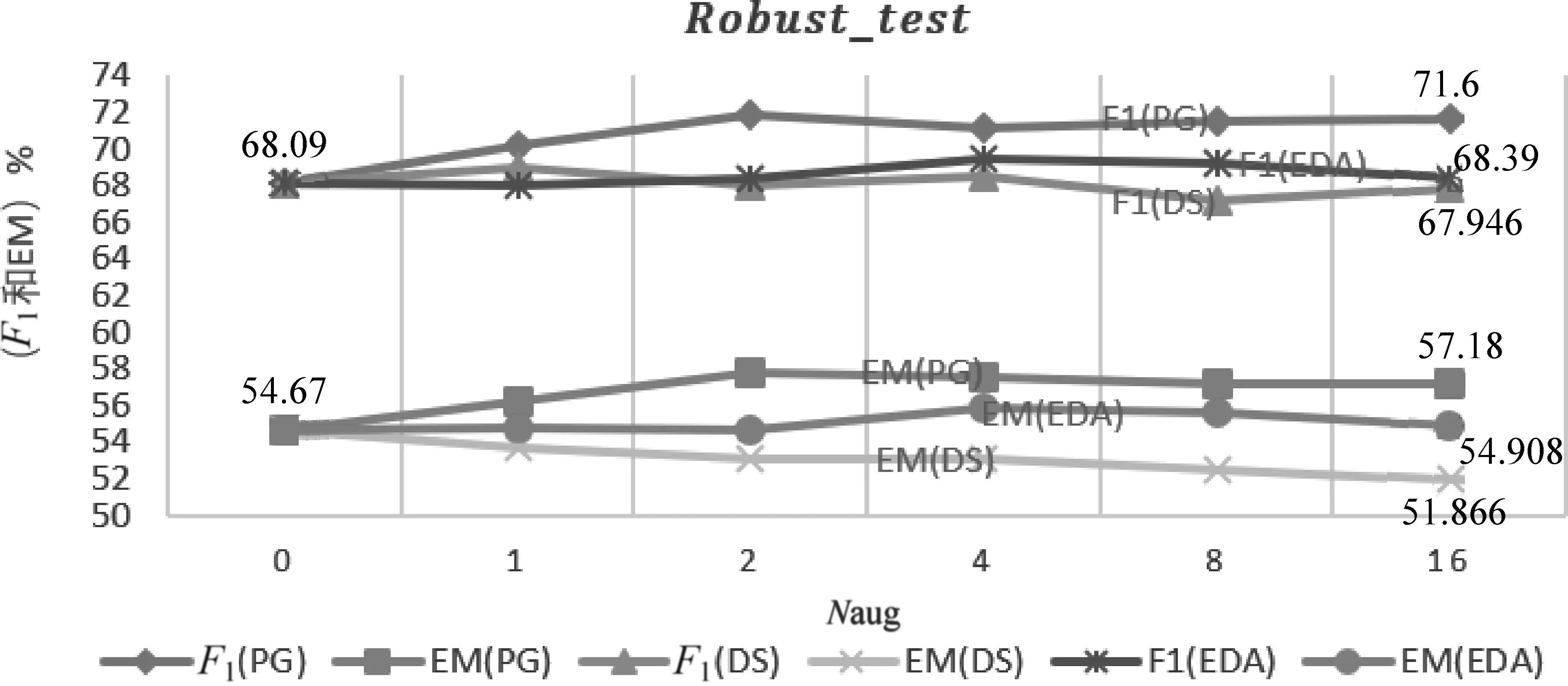
图5 在鲁棒性测试集上三种方法对比实验三种方法对F1值均有提升效果,PG的提升效果明显高于EDA和DS;对于EM指标,PG和EDA方法要优于DS方法,并且DS方法随着数据量的增加EM指标呈明显下降趋势。
从图4可以看出,在测试集中,PG方法构造的数据对测试集的EM和F1值均有两个点以上的提升。当Naug为2~8时,效果最好;当Naug超过16时,提升效果有所下降。其他两种方法效果相当,对测试集几乎没有提升效果。对于远程监督方法,汽车领域知识三元组数据量大,但是种类相对较少,构造出来的数据形式相对单一。另外,数据构造过程中也会引入较多的噪声,这些噪声可能对构造数据质量产生影响,从而影响实验结果;对于EDA构造方法,形式上相对简单,在分类任务中有效果,在阅读理解任务中表现不明显。
从图5可以看出,在鲁棒性测试集中,三种方法对F1指标均有提升效果,PG的提升效果明显优于其他两种方法,EDA的方法略高于DS的方法。对于EM指标,PG和EDA方法优于DS方法,并且DS方法随着数据量的增加,EM指标呈下降趋势。由此可以看出,DS方法构造的数据引入的噪声相对较大,对原始训练数据造成了干扰。
为进一步分析各种方法构造出的训练数据的区别,本文使用原始数据量4倍的构造数据,分别按比例(0,0.2,0.4,0.6,0.8,1)加入原始训练数据,进行实验。实验结果如图6所示,在测试集和鲁棒性测试集中,PG和EDA效果相当,仅使用构造数据就能达到与训练数据接近的效果。DS方法随着原始训练数据的增加,效果逐步提升。DS方法构造的数据完全没有使用原始训练数据,PG和EDA方法构造的数据是在对原始训练数据微调的基础上获取的,因此在仅使用构造数据时,DS方法的效果明显低于PG和EDA。


图6 训练数据占比变化图图(a)、图(b)是在测试集上随着训练数据比例增加F1和EM指标的变化,图(c)、图(d)是在鲁棒性测试集上随着训练数据比例增加F1和EM指标的变化。在测试集和鲁棒性测试集中,PG和EDA效果相当,仅使用构造数据就能达到与训练数据接近的效果。DS方法随着原始训练数据的增加,效果逐步提升;在仅使用构造数据时,DS方法的效果明显低于PG和EDA。
3.3 多模型验证实验
为了验证本文提出的数据增强方法在各种模型上的通用性,本文选择近期在阅读理解任务中表现突出的多个模型进行实验。
BERT模型BERT模型在阅读理解任务上取得了突破性的成绩,它采用多层Transformer结构堆叠而成,层数不同,模型大小也不同,本文采用层数为12的BERT_base模型进行微调,验证方法的有效性,其中,Batch_size为6,Epoch为4,其他参数不变。
AlBERT模型AlBERT模型在BERT模型的基础上进行了改进,通过词嵌入矩阵的分解和隐藏层参数共享,减少模型的参数,提升模型的性能。本文选择与BERT_base模型参数量相当的AlBERT_xlarge模型进行实验,其中Batch_size为6,Epoch为4,其他参数不变。
DrQA模型DrQA模型是一个完整的端到端的阅读理解问答系统,包含文档检索和文档阅读两个模块,本文仅使用文档阅读模块验证方法的有效性。在实验中,数据预处理采用CoreNLP[25]进行分词和实体识别,使用腾讯中文词向量[26]进行词嵌入,训练参数与原模型一致。
实验结果如表3所示,可以看出本文提出的数据增强方法在三个模型上均有效果,测试集和鲁棒性测试集的F1和EM指标都有两个点以上的提升。从模型之间的对比可以看到: BERT、AlBERT预训练语言模型在阅读理解任务中表现突出,DrQA是非预训练模型,没有经过大量无监督数据的预训练,因此效果较差;在参数量相当的时候,经过改进的AlBERT模型效果比BERT更好。

表3 数据增强方法在多个模型上的实验结果
4 结束语
本文提出了一种垂直领域中基于真实用户问题的数据增强方法,该方法对真实用户问题的语义原型进行泛化,构造同义表达问题,从而增强问题的多样性,同时提升构造数据和应用场景中数据的一致性,从而提升模型的准确率和鲁棒性。该方法结合了垂直领域的数据特点和相关技术方法,如领域实体识别技术,在汽车领域数据集上,验证多种模型,F1和EM指标均能取得2~5个百分点的提升。本文面向垂直领域的数据增强方法对其他各垂直领域均有借鉴作用,普适性强,下一步将结合本方法,在通用领域数据上进行分析和研究。
