基于树模型机器学习的皮肤电信号情绪识别
2021-12-23何国柱乔晓艳
何国柱,乔晓艳
(山西大学 物理电子工程学院,山西 太原 030006)
0 引 言
情绪识别在人机交互、医疗健康、智能驾驶以及教育等领域都发挥着至关重要的作用.因此,非常需要一种利用计算机自动识别人类情感状态的方法.目前,自动情绪识别的研究包括生理和非生理信号情绪识别.由于生理信号的情绪识别不易受被试主观意志的影响,更接近于真实的内在心理感受,因而生理信号情绪识别比非生理信号更加客观、真实、具有说服力,逐渐成为研究的热点.情绪识别常用的生理信号包括:脑电、心电、肌电、脉搏、皮肤电反应等.其中,皮肤电反应(Galvanic Skin Response, GSR)是皮肤电导随皮肤电流大小而产生的变化,属于人体交感神经系统活动的生理反应[1].研究表明,人体皮肤电导的变化强度与情绪激动程度有关,皮肤电反应可以作为衡量情绪状态变化的生理指标.皮肤电反应与脑电、心电相比更易于测量和采集,且不易受其他生理信号干扰,因此在情绪识别领域得到越来越多的研究和应用.
目前,关于皮肤电信号情绪识别研究较多的是基于离散情感模型.Zhang[2]等人提取皮肤电信号时域、频域的统计特征,对快乐、恐惧、悲伤、愤怒和平静5种离散情绪,采用基于改进的神经网络进行情感识别研究,平均识别准确率为84.9%.刘光远等人[3]用非线性分析方法,提取皮肤电信号的最大Lyapunov指数,关联维、近似熵等非线性特征,对高兴、悲伤、恐惧3种离散情绪采用K近邻、线性判别分析 、支持向量机(Support Vector Machine,SVM) 进行情感识别研究,结果显示SVM具有更好的分类正确率,其中高兴情绪识别正确率达到了92.33%.目前,离散情感模型的情绪识别正确率高,但离散情感模型刻画的情绪种类较单一、描述情绪的模糊性和复杂性较低.基于维度模型的连续情感较离散情感更能精确细致地刻画人的复杂情绪状态,更符合实际应用,因此越来越多的学者开展维度情感模型的生理信号情绪识别;Sharma[4]等人在DEAP数据集[5]上提取皮肤电信号的时域、频域统计特征以及小波系数特征,利用主成分分析进行特征降维,基于维度情感模型采用多层感知机(Multilayer Perceptron,MLP)分别在唤醒度、效价和优势度上进行分类,正确率最高分别达到了79%,69.8%和71.2%;Atefeh[6]等人在DEAP数据集中提取脉搏信号和皮肤电信号的最大Lyapunov指数、近似熵等非线性特征,基于维度情感模型采用概率神经网络(Probabilistic Neural Network,PNN)在唤醒度和效价两个情感维度上进行分类,识别准确率分别为88.57%和86.8%.
鉴于目前维度情感模型的皮肤电信号情绪识别准确率较低,情感类别标签划分不统一,提取的生理信号情感特征不充分,而且实验中个体差异性较大,导致识别模型泛化能力差.所以,本文在DEAP维度情感生理数据集上,通过皮肤电信号构建情绪识别机器学习模型,对音乐视频情感诱发下的皮肤电信号进行多维度特征提取、归一化处理以及情感标签分析,在此基础上采用基于树模型的决策树和随机森林算法实现情绪的有效分类,获得了较好的分类准确率和泛化能力,为实现生理信号情绪自动分析和机器识别奠定坚实基础.
1 数据来源和情感标签选择
1.1 DEAP数据集
DEAP数据集[5]是Koelstra等人通过实验采集得到的多通道生理信号情感数据集,成为多数学者研究维度情感模型情绪识别算法的有力工具.该数据集记录了32名被试者32个通道的脑电信号和8个通道的外周生理信号,其中皮肤电信号为第37通道.
实验中,每个被试者分别观看40个不同情感、时长为60 s的音乐视频,被试者根据唤醒度(Arousal)、效价(Valence)、优势度(Dominance)、喜好度(Liking)和熟悉度(familiarity)对每个音乐视频分别进行评分.实验人员利用生理信号测量仪和对应的传感器或电极记录了32名被试者观看情感音乐视频时的60s生理数据以及观看视频之前自然状态下的3 s生理数据,同时还录制了前22名被试者观看音乐视频过程中的正面面部表情视频.
实验以512 Hz的采样率记录脑电信号和外周生理信号,并经过预处理之后,将数据降采样为 128 Hz.DEAP数据集中每名被试者的数据内容包含了40个不同情感音乐视频诱发下的40个通道的生理数据和4个情感维度的情感标签数据,如表 1 所示.

表 1 DEAP数据集内容
1.2 情感标签选择
DEAP数据集中情感标签是对被试通过观看不同情感音乐视频产生的情感体验进行评价获得的.被试从唤醒度、效价、优势度、喜好度这4个维度,在自我情绪评定量表(Self-Assessment Manikin, SAM)上对情绪进行量化.效价和唤醒度是目前大多数研究采用的情绪维度模式,效价表示情绪的正负性质,从悲伤、厌恶逐渐过渡到高兴、愉悦,对应的是由数字1到9的打分尺度来衡量;唤醒度表示情绪的强度程度,从放松、无聊逐渐过渡到激动、全神关注,对应的也是由数字1到9的打分尺度来衡量.每名被试者需要在每次实验后选择代表情绪量化的分值.被试每次观看不同视频后产生的情绪,都可以用SAM表的标准来量化,用作后面的识别和分析.
在情绪识别过程中,情感标签的划分对于情绪的正确分类至关重要,由于人的情绪不仅有正、负性情绪,还有介于两者之间的中性情绪;在情绪的强烈程度上,不仅有情绪的强弱之分,还会出现平静自然的状态,因此情绪识别要充分考虑到不同情绪的状态.只有确定情绪所处的状态,机器才能准确地识别情绪.为了探索情绪的模糊性对情感分类结果的影响,本文在唤醒度和效价上分别采用不同的情感标签阈值进行维度情绪状态划分.第Ⅰ类情况:情感标签分值大于或等于7作为高效价高唤醒度,小于或等于3作为低效价低唤醒度;第Ⅱ类情况:情感标签分值大于或等于6作为高效价高唤醒度,小于或等于4作为低效价低唤醒度.通过选取不同的阈值,分析情绪的模糊程度对识别结果的影响.在以上两种不同情感阈值情况下,DEAP数据集中皮肤电信号对应于效价和唤醒度情感标签的样本数量也不同,如表 2 所示.

表 2 唤醒度和效价阈值划分的样本数量
2 皮肤电信号特征提取
在生理信号测量过程中,由于每一个被试个体差异性的影响,每一个人的生理信号是不相同的.即使是一个人在不同时间、不同环境下测量到的生理信号也会不相同,为了研究被试者的生理信号与情感反应的关系,需要去除每一个被试者生理信号的基础水平差异即个体差异性,才能有效降低由于个体差异造成的影响,得到生理信号与情感变化的内在关系.本文采用的方法是:用每个被试在情绪视频诱发下的GSR数据减去平静状态下的GSR数据,然后对GSR信号的差值再进行归一化处理.
2.1 时域特征提取
本文参照Augsburg大学[7]特征提取的方法,提取了皮肤电信号的22个时域特征,包括原始皮肤电信号经过预处理后的平均值、中位数、标准差、最大值、最小值、最大值比率、最小值比率、最大值最小值之间的差值;一阶差分的均值、一阶差分的中位数、一阶差分的标准差、一阶差分的最大值、一阶差分的最小值、一阶差分的最大值比率、一阶差分的最小值比率;二阶差分的均值、二阶差分的中位数、二阶差分的标准差、二阶差分的最大值、二阶差分的最小值、二阶差分的最大值比率、二阶差分的最小值比率.
2.2 频域特征提取
已有研究表明,皮肤电信号的功率谱密度可以衡量人体交感神经系统的生理变化[8].由于皮肤电信号属于非平稳随机信号,本文利用AR模型功率谱估计方法进行频域分析和特征提取.
AR模型输出的功率谱
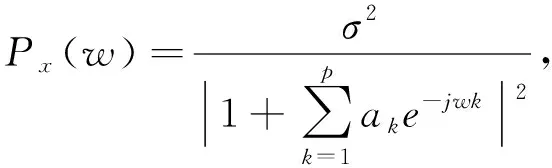
(1)
式中:σ2为方差;p是AR模型的阶数;{ak(i),i=1,2,3…p}为AR模型的参数.
利用Burg算法[9],可以快速递推实现AR模型参数的估计,经过仿真测试,模型阶数p选择9.皮肤电信号的功率谱密度如图 1 所示.
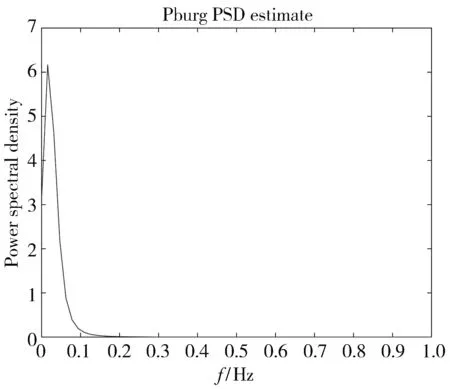
图 1 皮肤电信号的功率谱密度
2.3 非线性特征提取
小波包变换是一种分析非平稳信号更加细致、有效的方法.它将频带进行多尺度划分,对多分辨率分析没有细分的高频部分以二叉树方式分解成等频带宽的子空间,并根据被分析信号的特性,自适应地选择相应频带,使之与信号频谱相匹配,从而提高时频分辨率[10].
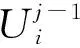

(2)
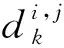
小波包节点能量可以有效表示信号分量的能量,是该节点小波包系数的平方和.小波包节点能量
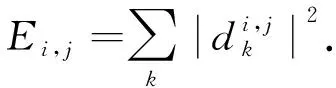
(3)
该层节点的信号总能量为不同频带小波包节点能量之和,即

(4)
则小波包节点能量占比为

(5)
小波包熵反映了随机序列的不确定性,小波包熵值越大表明序列无序性越强.皮肤电信号的小波包熵与情绪状态密切相关,在不同情绪诱发下,交感神经元兴奋或抑制的状态发生变化,导致皮肤电序列的无序性随之发生变化,因此可提取皮肤电信号的小波包熵进行情绪识别,小波包熵计算如式(6)
WEP=-∑pi,jlnpi,j.
(6)
DEAP数据集中GSR信号经过预处理之后采样频率为128Hz.采用db5小波基函数对GSR信号进行6尺度小波包分解,分解频带宽度为1 Hz,进而得到第6尺度对应频段小波包系数,计算皮肤电信号的小波包熵.
综上所述,本文提取皮肤电信号的时域、频域、非线性共24个特征.如表 3 所示.

表3 提取的皮肤电信号特征数据
3 情绪分类模型
3.1 决策树算法
决策树(Decision Tree,DT)是一种通过分支对原数据依靠其属性进行分类的树形结构,决策树由节点和有向边组成.叶结点表示最终的分类标签,非叶结点为评估条件.进行分类或测试时,将输入的原始数据集与树形结构的节点进行匹配,最终找到唯一的叶结点,则该叶结点的类别标签就是该数据对应的分类类别[11].目前,决策树的主流算法有ID3,C4.5,CART 等.ID3算法的核心是在决策树各个节点上用信息增益准则选择特征,递归构建决策树;C4.5算法对ID3算法进行了改进,在决策树生成的过程中,用信息增益比来选择特征.本文采用分类与回归树(Classification and Regression Tree, CART)模型,CART算法利用基尼系数来进行特征选择.
样本集合D的基尼系数
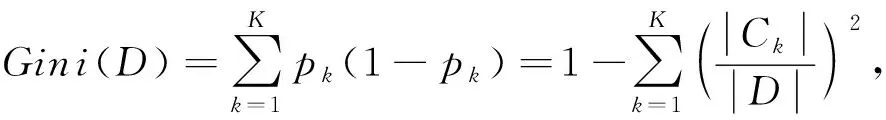
(7)
式中:pk是样本点属于第k个类的概率;Ck是样本集合D中属于第k类样本子集;K是类的个数.
样本集合D根据特征A是否取得某一可能值a,将集合D分成D1和D2两部分,即
D1={(x,y)∈D|A(x)=a},D2=D-D1.
(8)
则集合D的基尼系数为
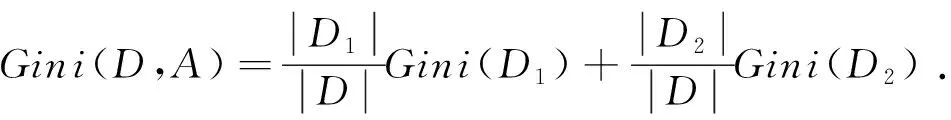
(9)
基尼系数Gini(D)表示集合D的不确定性,Gini(D,A) 表示经A=a分割后集合D的不确性.CART算法具有选择最小基尼系数的特性,基尼系数的值越小,样本的“纯净度”越高,划分效果越好.为了解决过拟合的问题,提高决策树泛化性能,需要对生成的决策树进行后剪枝处理.
3.2 随机森林算法
随机森林(Random Forest,RF)是以自举汇聚法(bagging)为基础,由多个弱分类器(决策树)组成的强分类器.首先,通过自助法(bootstrap)放回抽样并构造子训练数据集,每个子训练数据集构造一个决策树,然后随机选取特征参数对决策树进行训练.每个决策树互不相干,判决时将多个决策树分类器的判决结果进行投票,得到最终的结果[12].
设样本属性个数为Mm为大于零且小于M的整数,RF算法实现步骤为:
1) 利用Bootstrap方法重采样,随机产生T个训练集S1,S2…,ST.
2) 利用每个训练集,生成对应的决策树N1,N2,…,NT;在非叶子节点(内部节点)上选择属性前,从M个属性中随机抽取m个属性作为当前节点的分裂属性集,并以这m个属性中最好的分裂方式对该节点进行分裂.保证每棵树都完整成长,不对其进行剪枝处理.
3) 对于测试集样本X,利用每个决策树进行测试,得到对应的类别N1(x),N2(x),…,NT(x).
4) 采用投票的方法,将T个决策树中输出最多的类别作为测试样本X所属类别.
本文提取了皮肤电信号的时域、频域以及非线性共24个特征,因此样本属性个数M=24.为了保证整个随机森林算法的分类准确率,需要设置合适的决策树数量(Ntrees)来解决袋外错误率(Out-of Bag Error,OOB Error)过高和不稳定的现象.通过仿真实验,本文决策树数量设置为500.图 2 是决策树数量与袋外错误率的关系,可以看出,随着决策树数量增加,袋外错误率逐渐降低,当决策树数量为500时误差较小且稳定.

图2 决策树数量与袋外错误率的关系
本文采用5折交叉验证的方法对决策树和随机森林算法进行检验以得到稳定可靠的分类模型,即将皮肤电信号的特征样本数据随机均匀分成 5份,保留其中1份作为测试集,其余4份作为训练集,重复5次,并将这5次分类准确率的结果取平均,得到最终的交叉验证分类准确率.
4 结果与分析
4.1 仿真结果与模型评价指标
4.1.1 模型评价指标
对于二分类问题常用的模型评价指标是分类准确率(Accuracy,Acc)、精确率(Precision,P)、召回率(Recall,R)和F1值以及混淆矩阵.
分类准确率定义为
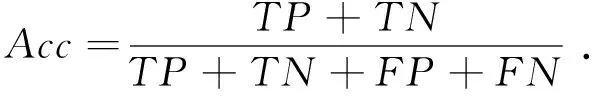
(10)
精确率定义为

(11)
召回率定义为
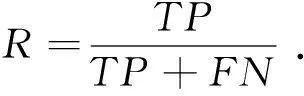
(12)
F1值定义为
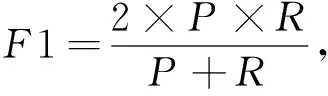
(13)
式中:TP表示将正类预测为正类数,即真正类;FN表示将正类预测为负类数,即假负类;FP表示将负类预测为正类数,即假正类;TN表示将负类预测为负类数,即真负类.本文将情感标签为高唤醒度、高效价的样本记为正类样本,低唤醒度、低效价的样本记为负类样本.
4.1.2 仿真结果
将提取到的皮肤电信号的时域统计特征、频域特征以及非线性特征,采用决策树和随机森林在唤醒度和效价两个情感维度上进行分类,分类结果的混淆矩阵如图 3 和图 4 所示,并利用式(10)~式(13)计算其分类准确率Acc、精确率P、召回率R和F1值.
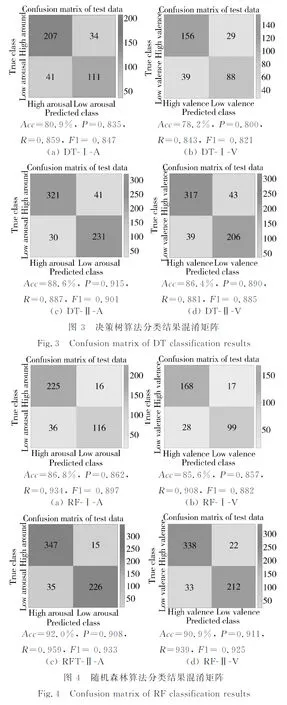
4.2 结果分析
4.2.1 情感标签阈值对分类结果的影响
本文在唤醒度和效价两个情感维度上对情感标签阈值进行划分,分为两大类.通过选取不同的情感标签阈值来研究其对情绪识别结果的影响,模型评价指标结果如表 4 所示.
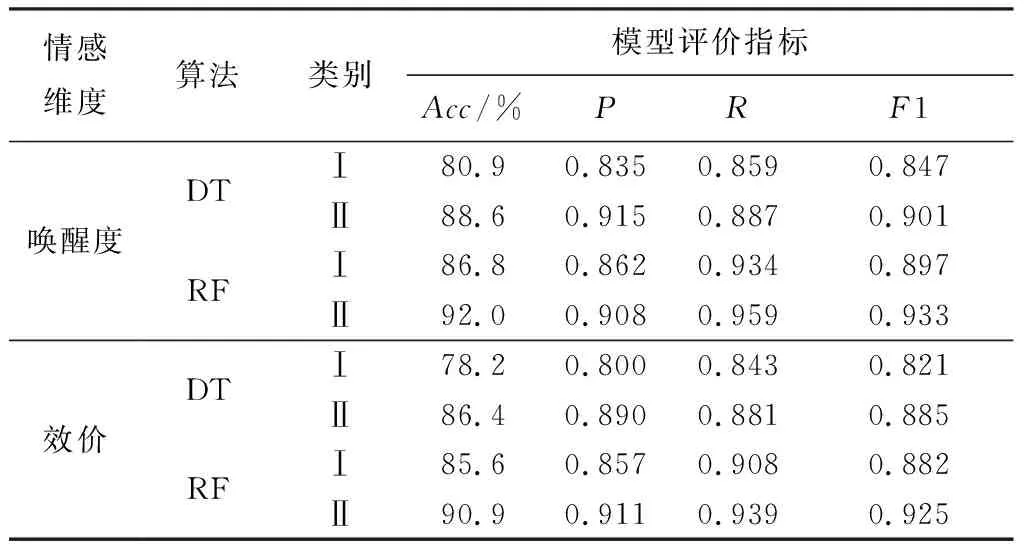
表 4 不同情感标签阈值的分类结果对比
表 4 结果表明,在唤醒度维度上,利用决策树算法在第Ⅱ类阈值设定下的分类准确率和F1值分别为88.6%和0.901,而第Ⅰ类阈值的结果为80.9%和0.847;利用随机森林算法在第Ⅱ类阈值设定下的分类准确率和F1值分别达到了92.0% 和0.933,第Ⅰ类阈值的结果为86.8%和0.897.在效价维度亦是如此.由此可知:利用决策树或随机森林算法在唤醒度和效价上进行情感分类时,无论是分类准确率Acc、还是精确率P、召回率R和F1值,第Ⅱ类阈值设定的情绪识别分类结果均优于第Ⅰ类阈值的结果.原因主要在于第Ⅱ类阈值设定,无论在唤醒度还是效价维度上模型训练的样本数量均多于第Ⅰ类阈值设定的样本量,不会出现欠拟合,可以充分学习到情感丰富的特征,从而有利于情绪的识别.因此,在进行情感标签阈值划分时,不仅需要考虑在唤醒度和效价上情绪表现的强烈程度,还需要考虑到样本数量对于情绪分类的影响.由此表明,选择合适的情感阈值和训练样本数量有利于提高情绪识别准确率.
4.2.2 分类算法对情绪识别结果的影响
本文分别采用了决策树和随机森林算法在唤醒度和效价上进行情绪识别,分类结果如表5所示.
表5结果显示,第Ⅱ类情感标签阈值情况下,在唤醒度维度采用随机森林算法分类准确率和F1值分别为92.0%和0.933,高于决策树算法的88.6% 和0.901.在效价维度上亦是如此.因此,无论是分类准确率Acc,还是精确率P、召回率R和F1值,采用随机森林算法在唤醒度和效价上进行情感分类的结果均优于决策树算法.由此表明,在皮肤电信号的情绪识别中,随机森林基于集成学习的组合分类器相比单一的决策树分类器可以提高分类准确率,并有效减少过拟合现象,提高模型的泛化能力,同时该算法具有速度快、时间开销少、稳健性好等特点.

表 5 决策树和随机森林分类结果对比
4.2.3 与其他方法比较
将本文提取皮肤电信号的时域统计特征,功率谱密度最大值和小波包熵特征,采用决策树和随机森林算法在唤醒度和效价上进行情感分类,并与其他机器学习方法相比,取得了较好的分类效果.如表 6 所示.
对于维度情感模型而言,采用决策树和随机森林算法在唤醒度和效价两个情感维度上,分类结果均优于文献[4]采用多层感知机达到的分类准确率.其中采用随机森林算法在唤醒度和效价上的情感分类准确率高于文献[6]采用概率神经网络的情绪识别结果.本文采用的维度情感模型与基于离散情感模型的情绪识别相比较,采用随机森林算法,在唤醒度和效价两个情感维度上分类准确率分别达到了92.0%和90.9%,接近文献[3]基于离散情感模型的识别准确率,远高于文献[4]维度情感模型的识别准确率.由此可知,皮肤电信号在维度模型进行情绪识别时,通过提取皮肤电信号的时域、频域和时频非线性特征,并采用随机森林集成学习的树模型算法可以获得较好的情绪识别结果和性能.
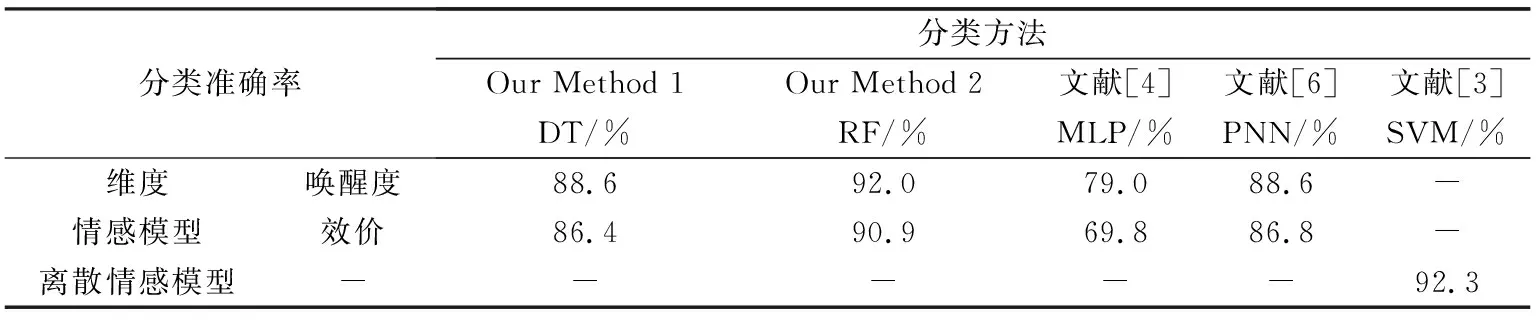
表 6 不同分类方法的分类准确率对比
5 结束语
本文基于DEAP数据集提取皮肤电信号的时域、频域以及非线性特征,并利用决策树和随机森林算法在唤醒度和效价两个情感维度上进行情绪识别.仿真实验结果表明:在维度模型上进行情感分类时,选取合适的情感标签阈值和样本数量可有效提高机器情绪识别正确率;利用基于集成学习的随机森林算法在进行情绪分类时获得比单一决策树分类器更好的识别效果;采用多特征融合以及GSR信号差值归一化处理,模型的泛化能力更强.该研究可以应用于智慧医疗、人机情感交互、教育和娱乐领域.
