基于深度学习和时空关联的大数据分析系统研究*
2021-12-23李威
李 威
(1.北京锐安科技有限公司,北京 100192;2.北京市网络空间数据分析与应用工程技术研究中心,北京 100192)
0 引言
随着深度学习技术的发展,人脸识别、声纹识别、命名实体识别技术得到了广泛应用[1-2],但是传统方法采集的人脸、声纹、实体和其他结构化数据存在数据孤立的问题。例如,虽然采集到了人脸,但是人脸的身份难以确定。因此,充分发掘数据的关联关系,利用关联关系对实体进行多维度刻画,是提升数据价值的重要手段。文章提出一种基于深度学习进行实体识别,并利用同一时空获取关联关系,通过大数据分析获取多时空中关联强度的方法。智能采集设备具有丰富的采集能力,广泛采集声光电信息,一类形成视频、图像、声音以及话语等非结构化数据,一类形成如经纬度、射频识别ID、电子设备ID 以及操作信息等结构化数据。基于深度学习的数据处理特点,非结构化数据经过预处理后形成特定大小数据作为深度神经网络的输入,统一视同图片,利用深度学习进行图像的实体识别和特征归一,基于同一时空,将实体与其他实体、实体与结构化数据即属性进行关联。随着不同时空采集数据的积累,实体之间、实体与不同属性之间的关联度产生显著差异,因而能够揭示客观世界的规律。系统将实体和属性数据聚合形成档案,提供查询分析功能。文章介绍了基于深度学习和时空关联的大数据分析系统的需求分析、系统架构以及系统数据流,并对数据预处理、数据存储组织、数据分析挖掘的算法和实现等关键子系统展开阐述。
1 系统构建分析
1.1 系统应用需求分析
系统应用需求包括关联查询、数据碰撞分析、数据统计等3 个方面的功能。
查询检索功能围绕着图像实体与属性关联形成的档案信息和时序日志信息,提供以图搜档、以属性搜图的功能,以及对采集数据日志搜索和时序轨迹数据查询。日志搜索根据采集设备标识、属性信息、时间范围搜索日志数据。时序轨迹数据查询,根据实体ID、属性、时间范围搜索归属于同一实体的时序日志数据,形成轨迹刻画和地图展示。
数据碰撞分析包括时空数据碰撞分析和混合轨迹分析。以图像、属性、时间为碰撞范围,获取命中的数据,通过地图显示,支持根据时间范围、区域、采集前端进行筛选检索。混合轨迹伴随分析选择特定时段、区域,可分析该时段区域内实体和属性同时同地出现的伴随情况。
数据统计分析包括采集量统计、档案统计、采集点位统计研究实体属性关联置信度。对所有接入的采集数据分时段按照数据类别统计,包括图数量、属性数量、形成的档案数量、前端采集点位数量和采集量。实体属性关联置信度基于实体属性关联次数,通过关联率算法,依据关联率取值区间给出关联置信度。
1.2 系统架构设计
大数据分析系统整体分为前端的采集系统和后端的数据中心,系统架构如图1 所示。
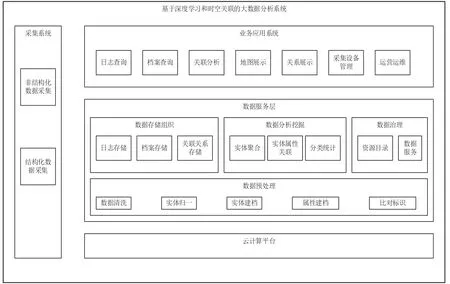
图1 系统架构
采集系统是部署在各类室内外场所的前端感知设备,如道路、园区、广场等室外场所,以及门禁、楼道、走廊等室内场所。采集系统具备视频图像采集及电磁信号采集能力,能够输出非结构化数据和结构化数据。
前端设备数量根据实际情况规模差异巨大,从几百台到数千台不等。采集数据量规模随前端设备数量增加而增长,后端的数据中心的容量能够水平延伸,动态扩容。
后端的数据中心基于云计算平台构建,依托云计算平台提供的存储、计算能力构建数据服务层和业务应用系统。数据服务层通过数据服务支撑业务应用系统开展相关业务。
数据服务层包括数据预处理、数据存储组织、数据分析挖掘以及数据治理几个子系统。数据预处理包括数据清洗、实体归一、实体建档、属性建档以及比对标识模块。数据清洗模块提供一段时间间隔(窗口)内的数据去重功能,实体归一模块对来自前端的图,通过数据分析挖掘提供的能力进行实体识别,并归一到唯一实体ID。实体建档模块按照唯一特征ID 建立实体档案。属性建档模块按照属性建立档案。比对标识模块能够对预设的比对条件,如图、实体ID、属性等及其组合规则对来源数据进行比对,按照规则对命中数据进行标识。数据存储组织子系统包含日志存储、档案存储、关联关系存储模块,提供日志、档案以及关联关系的存储功能。数据分析挖掘子系统包括实体聚合、实体属性关联和分类统计模块。数据治理包括资源目录和数据服务模块。
业务应用系统对外提供功能应用,基于数据服务层的能力,提供日志查询、档案查询、关联分析、地图展示、关系展示、采集设备管理以及运营运维等功能。
1.3 系统数据流设计
大数据分析系统的数据,在采集、数据预处理、数据存储组织以及数据分析挖掘几个关键子系统中流转加工过程。系统数据流,如图2 所示。
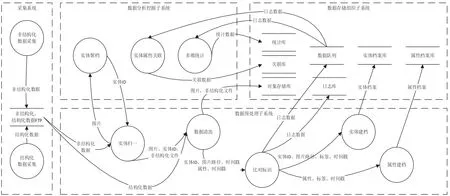
图2 系统数据流
采集子系统。采集功能输出的非结构化数据,原始数据按照业务需要经过系统预处理后形成特定规格的图片(如120×120 像素)。文件名带有采集时间戳,文件数据写入FTP 指定目录。结构化采集功能输出采集到的属性、时间戳数据,按照文本文件格式5 000 条记录一个文件,写入FTP 指定目录。
数据预处理子系统。实体归一功能从非结构化数据FTP 读取图片数据,将图片通过接口送给数据分析挖掘子系统的实体聚档获取特征归一ID,也就是同一实体的唯一ID。数据清洗功能的数据有两个,一是图片和实体ID 数据,二是属性数据。在预设的时间窗口(如2 min)内,判断数据是否重复,丢弃重复数据,实现数据清洗。清洗后的数据包括结构化的数据,如实体ID、时间戳,属性、时间戳,图片和原始非结构化数据文件。图片和原始非结构化数据存入对象存储库。结构化数据经过比对标识功能,与预设的比对数据(如实体ID、属性)进行比对,对命中数据在标识字段进行标记。比对标识后输出数据包括实体ID 结构化数据和属性结构化数据,统称为日志数据,写入数据队列。实体ID 结构化数据进入实体建档功能,属性结构化数据进入属性建档功能,形成档案后分别写入实体档案库和属性档案库。
数据分析挖掘子系统。实体聚档功能实现图片实体的识别和比对,给出系统唯一的ID。根据识别算法,使用特征点计算特征向量,通过特征向量的欧氏距离计算图像实体相似度,在相似度一定范围内归为同一实体。实体属性关联功能实现图像和属性的关联,从数据队列读取流式数据,对同一点位设备的图像数据和属性数据,在一个时间区间内(如2 min)形成一次数据关联。实体ID 与属性形成的关系称为关联,不同实体ID 关系称为伴随关系,即同时同地出现。形成的关系数据存入关联库。多维统计功能从数据队列获取数据,针对设备输出、实体ID、属性等维度按时间区间统计数据量,统计数据写入统计库。
数据存储组织子系统。接收外部子系统数据流,提供数据队列、实体档案、属性档案、统计库、关联库、对象存储库以及日志库等数据存储功能。
2 关键算法及实现
2.1 数据预处理算法及实现
数据预处理子系统基于开源软件Apache Flink实现。Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。系统逻辑结构如图3 所示。
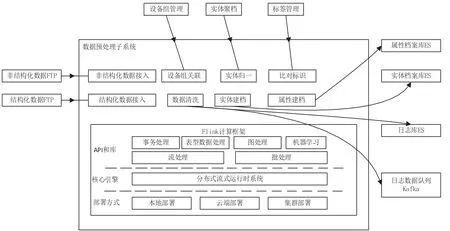
图3 数据预处理子系统
Flink 提供流处理和批处理API 支持,其核心引擎是分布式流式运行时系统。Flink 支持本地、云端和集群3 种部署方式,按照系统规模灵活选择[3]。规模较小时,如支持10 台以下前端采集设备的演示系统,单台高性能服务器即可支撑系统搭建,可以采用本地部署模式。大规模应用,如支持1 000前端采集设备的生产系统,需要采用云端部署或集群部署模式。
通过实现一个Flink 自定义数据源读取FTP 数据,实现非结构化数据接入和结构化数据接入。数据接入后,在流处理过程中实现设备组关联、实体归一、数据清洗、比对标识、实体建档以及属性建档功能。设备组关联是根据应用系统设定的前端采集设备组与设备ID 对应关系,对来源数据根据设备ID 回填设备组信息。在采集设备实际部署中,通常要在同一点位不同方向部署多台设备形成一个设备组。实体归一功能将图片传送给实体聚档,实体聚档返回唯一的实体ID。如果图片质量不能达到聚档要求,则返回空,系统丢弃此数据。
数据清洗的处理逻辑是在一个时间窗口内(如2 min)属于一个设备组数据范围。对于人像数据,根据实体ID 去重,相同实体ID 的保留一组数据。对于属性数据,根据属性值去重。计算方法为在窗口内以设备组+实体ID 或设备组+属性构建哈希索引,并根据哈希值进行比对判断是否重复。清洗后的数据形成实体数据集和属性数据集两个数据集,构成了日志数据、写入数据队列以及日志库。
比对标识从业务系统的标签管理功能获取标签的比对规则,根据规则进行数据匹配,匹配成功后设置标签值。
实体档案包括实体ID、图片路径、原始非机构化文件路径、标签、时间戳、设备组以及设备ID等字段,写入实体档案库。
属性档案包括属性、标签、时间戳、设备组以及设备ID 等字段,写入属性档案库。
2.2 数据分析挖掘算法与实现
数据分析挖掘子系统包含实体聚档、实体属性关联和多维统计3 个核心功能。
实体聚档是利用深度学习技术进行实体识别和特征比对。实体识别通过特定的深度神经网络,识别数据中的实体。根据业务需要实体,它可以是数据中的人、车、物、字符、声纹或其他概念实体[4-6]。特征比对其本质是1:N的多分类问题,使用训练好的神经网络提取图片深度特征,使用最近邻分类器通过比较深度特征之间的距离进行身份识别。特征距离的度量常使用欧氏距离或余弦相似度。例如,图像Xi和Xj的特定实体特征分别为F(Xi)和F(Xj),当特征之间的距离在预先设定的阈值t范围内时,即:
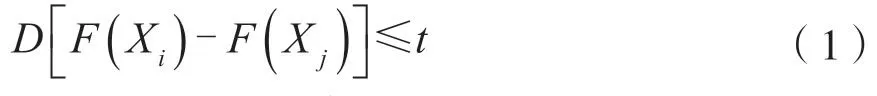
则认为这两幅图像来自同一个实体[7]。
基于特征向量的大规模数据检索,面临特征数量大、特征维数高导致检索性能低下的问题。系统通过构建高维度特征索引,加速查找[8]。实体聚档将给定的图片与系统已存图像进行搜索比对,匹配成功则返回唯一ID。匹配不成功,认为是新增实体,则分配唯一ID 并存入系统。
实体属性关联实现同一时空的实体和属性的关联,通过设备组ID 判断是否属于同一采集空间,一定时间区间(2 min)内算作同一采集时间。本系统实际场景中,一般2 min 内一个设备组采集回来图片小于10张,但采集的属性数据则在数百个的量级。这些数据中图片实体和属性共同出现一次,则记录为一次关联,按照设备组统计关联次数和属性出现次数,关联次数Ng={N1,N2,…,Nn},N1表示在设备组1 的关联次数;属性出现次数Mg={M1,M2,…,Mn},M1表示属性在设备组1 的出现次数。
关联率P的计算:

关联率取值范围[0,1]。实体属性关联有两个方向的关联率:一是由实体到属性的关联率,即上述计算方法;二是由属性到实体的关联率,按照上述方法取关联次数与实体出现次数比值可得。
多维统计包括设备组ID 为统计维度的采集数据量统计、日志量统计、图片量统计、设备统计以及档案统计。统计数据在流式处理过程中计算,结果写入关系型数据库。
2.3 数据存储组织算法与实现
数据存储组织子系统实现数据的缓存和持久化存储,包括数据队列、对象存储库、关联库、统计库、日志库、实体档案库和属性档案库。
数据队列是数据接入后缓存的队列,为后续数据分析挖掘提供数据通道。数据队列基于Kafka 实现,包含,人像Topic 和识别码Topic 这2 个Topic数据。
对象存储库用于存储图片文件和原始非结构化文件,系统需要存储大量的非结构化文件。本系统实际场景中,一台前端采集设备一般每天产生2 万张图片,系统按照1 000 台前端设计,每天产生2 000 万张图片,存储周期是3 个月,图片存储总量是18 亿张图片及其原始非结构化文件。为满足海量小文件存储的高速、高带宽、大容量、可伸缩性要求,图片库基于FastDFS 构建[9]。为便于数据存储和老化,按天建库,超过3 个月的库文件定期清库并回收存储空间。
关联库存储关联关系和伴随关系,以及关联次数和实体、属性的出现次数,具备大数据量的高速写入和读取能力,实现实时的读取和回写(6 万次/秒)。关联库基于内存数据库Redis 实现,主要有实体次数表、属性次数表、实体-属性关联次数表、实体-属性关联率表、属性-实体关联率表,如图4 所示。利用Redis 的Key-Value 存储形式,以实体次数表为例,Key 为实体ID,Value 为Set 类型,可以填充多值,里面存放此实体ID 在某一设备组ID 下出现的次数。预处理子系统在处理每个实体ID 时,从表中查出其Key 对应的Value,对其所属设备组ID 的次数加1 后组成新的Value Set(含全部出现的设备组及次数),并回写Value。其他表处理逻辑类似。

图4 数据存储子系统设计
日志库存储结构化日志数据。日志库、实体档案库、属性档案库基于ElasticSearch 实现。ElasticSearch 是一个开源的分布式搜索引擎,具备高可靠性,支持时间索引和全文检索,对外提供丰富的接口API,用于索引、检索和配置修改[10]。
统计库存储统计数据基于MySQL 实现。
3 结语
本文介绍基于深度学习和时空关联的大数据分析系统的研究体系,从系统架构设计和数据流设计角度介绍系统的整体概貌,然后阐述了系统的关键算法和实现。系统研发完成后已经在多处项目中上线运行,在实体建档、实体-属性关联、轨迹分析等重要功能上达到了设计意图,满足了项目需求。实际运行中发现以下问题需进一步改进:一是复杂场景下实体识别的成功率偏低,导致实体数据不完整以及实体归一不完全;二是属性的采集中无关数据量较大,大量垃圾数据占用存储空间增加了算力消耗。
