多GPU异构模型实现放射治疗中卷积/积分算法的快速计算
2021-12-22赖佳路
赖佳路 宋 莹 周 莉 白 雪 侯 氢
1(四川大学华西医院放疗科 成都610041)2(四川大学原子核科学技术研究所辐射物理及技术教育部重点实验室 成都610064)
如今调强技术(Intensity Modulated Radiation Therapy,IMRT)已经广泛应用于临床,调强计划制定的质量和速度受限于剂量计算的精度与速度。目前,放疗中光子线剂量计算算法主要有蒙特卡罗算法[1](Monte Carlo,MC)、卷 积/积 分 算 法[2-5](Convolution/Superposition,CS)以及有限笔形束算法[6](Finite Size Pencil Beam,FSPB)。MC算法被称为剂量计算的“金标准”,它能计算各种复杂条件下的剂量分布[7]。由于MC计算时间太长,该方法极少应用于临床。FSPB是目前应用于临床剂量计算的方法,其计算速度快,但不能对三维非均匀介质进行修正,当介质非均匀梯度很大时候带来误差较大[8]。CS算 法 模 型 来 源 于Boyer[9]、Mohan[10]和Mackie[11]等在各自研究中提出计算模型。CS算法能进行三维非均匀性修正,其计算精度仅次于MC。尽管CS算法计算速度远远快于MC,但该算法计算速度要完全应用于临床较困难。1989年Ahnesjö[4]提出了筒串卷积叠加算法(Collapsed Cone Convolution,CCC),该算法对CS进行了简化,缩短了计算时间。目前CCC算法已经应用于Pinnacle、RayStation治疗计划系统。由于简化后的CCC算法计算精度稍逊于CS算法,本文针对的是原始的CS算法。目前,图形处理器(Graphics Processing Unit,GPU)已经广泛应用于并行计算及医学影像处理[12]。王先良等[13]借助单颗GPU对CS算法进行了加速,与仅用CPU计算相比速度提升了60倍,单野计算时间达到1 min左右。虽然加速效果不错,但该速度应用于调强计划显然不足。基于此,本文详细研究了采用1~7块GPU对CS算法的加速情况,探讨通过CPU+多GPU异构计算模型让CS算法应用于临床调强计划的可行性。
1 CS算法原理和CPU+多GPU环境搭建
1.1 CS算法原理
CS算法以点核为能量沉积核(Energy Deposit Kernel,EDK),主要涉及两个步骤[14]。首先,计算原射线在单位质量内释放的总能量(Total Energy Released Per Unit Mass,Terma)。再 将Terma和EDK进行卷积/积分得到最终沉积的能量。其原理如图1所示,均匀介质中任意剂量沉积点r处沉积的能量可通过式(1)计算。

图1 卷积/积分算法原理图Fig.1 Schematic diagram of convolution/superposition algorithm

式中:r′为光子源到光子散射点的矢量;r0为光子源到模体表面的距离;r为光子源到能量沉积点的位置矢量;D(r)为r处的剂量;T(r′)为原射线在位移处r′处产生的Terma;keff(r-r′)为有效能量沉积核,它代表原始射线在r′处与介质发生作用,产生的次级电子在位移r处单位体积产生的能量沉积分数。Terma可通过式(2)和式(3)计算[4]得到:
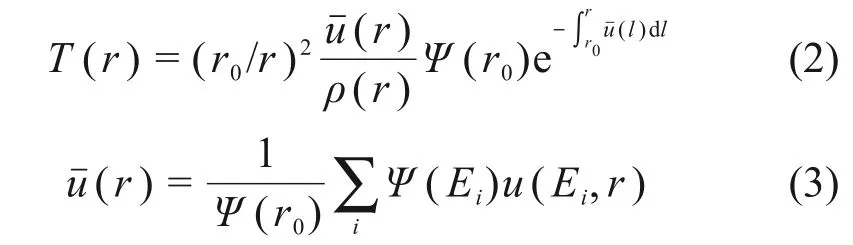
式中:Ψ(Ei)为能量Ei对应的能量注量;uˉ(r)为点r处的平均线性衰减系数;u(Ei,r)为点r对应能量为Ei的线性衰减系数。
1.2 CUDA架构
计算机统一设备架构(Compute Unified Device Architecture,CUDA)为GPU提供了一整套通用并行计算解决方案[15]。该架构由“中央”处理器(Central Processing Unit,CPU)和“协”处理器GPU组成。CPU称为主机端,GPU称为设备端。在CUDA架构中,GPU上运行的函数叫内核函数(Kernel)。Kernel函数以线程网格(Grid)的形式组织,Grid为多个可以被并行执行的线程块(Block)集合。Block包含大小相同的线程(Thread),Thread是函数执行的最基本单元。GPU的计算核心是流多处理器(SM),每个SM以线程束(warp)为单位执行,同一个warp的线程执行不同数据的相同指令,这种执行方式能有效隐藏线程的延迟和等待问题[16]。在CUDA编程模型中,编程者可以通过三个预定义变量[17]blockDim、blockIdx和threadIdx实现数组元素与线程的对应,从而实现线程间并行计算。在多GPU架构中,主机只有一个,设备可以有多个。借助CUDA 4.0工具包,可以通过cudaSetDevice()函数在各个GPU之间切换。
2 CPU+多GPU实现CS算法加速
CS算法的程序实现过程主要涉及6个步骤:
1)相关计算参数读取;
2)创建虚拟模体;
3)计算Terma;
4)计算卷积/积分;
5)剂量插值;
6)计算所有射束产生的总剂量;。其中:步骤2)~5)这4个模块(下文简称为M2、M3、M4、M5)计算数据量大、数据相关性低、数据有相同的执行程序。该4个模块适合用GPU进行加速。下面将对4个模块进行详细介绍。
2.1 创建虚拟模体
CS算法中的EDK来自MC方法在水中模拟得到的数据。模拟过程中,射束垂直入射到模体。因此计算过程中我们需要创建一个与射束中心轴方向垂直的虚拟体模,如图2所示。

图2 创建虚拟模体原理图Fig.2 Schematic diagram of creating virtual phantom

式中:θG、θT、θC分别代表机架、治疗床以及准直器角度,Matrixv→b(θG,θT,θC)为射束坐标系到人体坐标系的转换矩阵。为了得到更精确的CT密度,需要细化虚拟模体的体元。细化后的体元多达数百万以上。与CPU循环计算方式不同,借助GPU可以让一个线程负责一个体元的计算。
2.2 计算Terma
计算Terma采用射线追踪的方法[18]。射线从点源出发沿着固定的方向依次穿过多个体元,在射野平面加入射束的强度信息后计算每个体元的Terma。为了保留射束发散的物理性质,把射束看成连续的在入射表面等面积的锥形束,这样可以得到更精确的计算结果。为了保证追踪过程每个体元都至少有一条射线穿过,需要将射束细化,细化后的射束数目较多,且相互独立,该过程非常适合GPU并行计算。
2.3 计算卷积/积分
卷积计算中将要计算的体元作为中心,计算所有位于积分核半径Radcut之内对其有影响的Terma产生的剂量总和。卷积/积分中计算时间和精度受Radcut大小影响较大。参考陈炳周的研究结果[19],本文积分核半径选择3 cm。计算过程中将需要计算的体元r作为追踪的起点,沿着r′-r方向进行射线追踪,然后得到对应等效长度的积分核,对于密度不均匀的介质,需要对其做等效厚度修正,计算等效厚度使用射线追踪的方法,三维空间中点(x,y,z)的等效深度d(x,y,z)可以通过下面公式进行计算:

式中:ρ(x′,y′,z′)是体元(x′,y′,z′)相对于水的CT值;l(x′,y′,z′)表示射线穿过体元(x′,y′,z′)的几何长度。CS算法需要将点核离散化[20],为了实现精度与速度的平衡,本文中,顶点角φ和方位角θ都取48个。在计算积分之前,用光线追踪方法[21]建立一个体元密度和坐标无关的查找表,在等效厚度计算的时候,只需要按角度和步数Nsteps就可以简单地得到在x、y、z、r方向的增量,将r方向的增量Δr与体元的电子密度ρ相乘便是射线穿过体元的等效长度。该过程计算量大,非常适合GPU进行加速。
2.4 剂量插值
由于机架角度变化会改变射束坐标系,为了处理不同射束坐标系计算得到的剂量,计算得到的虚拟模体中剂量还应插值到初始模体中去,便于剂量的分析、显示等。该过程类似于模块2,同样适合并行计算。
3 测试结果与分析
本文实现了CS算法基于CUDA架构的多GPU并行计算模型。测试平台参数如表1所示。测试模体是一个大小为30 cm×30 cm×30 cm密度非均匀模体,体元密度值是相对于水为0~1.2之间的随机数,体元尺寸大小设定为0.2 cm×0.2 cm×0.2 cm,总的体元数目约为337万,该体元数目远远超过我们临床中常见部位的体元数目,如头部约160万、胸部约239万、腹部约250万。虚拟模体体元的大小和初始模体体元大小设置相同。射野的大小为10 cm×10 cm,野的分辨率为0.2 cm×0.2 cm。测试机架角度为0°和45°。光子能量采用6 MV,GPU采用1~7个。本文定义了加速比TiG/C,表示第i个模块用CPU计算花费时间与使用GPU花费的时间之比,式如(6)所示,为总的加速因子。

本文GPU计算时间包括在各个GPU上分配内存以及将数据拷贝到各个GPU上进行并行计算所用时间,由于本实验中内核启动极其快,所以本文忽略掉了内核启动时间。
表2和表3分别给出了机架角度为0°和45°时,CS算法4个模块单用CPU和采用1~7个GPU的计算时间及加速比。
多GPU并行计算的环境比传统的单GPU复杂,本文测试环境中使用的是共享系统多GPU,即一个单独的系统中包含多个GPU,这些GPU通过共享一个CPU的RAM进行连接,各个GPU数据之间不能直接传输,必须通过CPU内存进行中转。随着GPU使用个数的增加,需要在更多的GPU上为核函数所需数据分配内存,同时需要将CPU数据分别传向更多的GPU。当多个GPU挂载到总线上后,总线传输压力增大[22],由于本文研究内容需要数据在CPU和GPU之间频繁进行交换,数据传输时间延迟便成了本文研究过程中的一个关键问题。特别是对于在CPU上计算时间本身较短的情况。表2和表3中的M2、M3、M5三个模块采用多个GPU计算时间说明了这种情况。该三个模块在CPU计算时间均在1 s之内,随着GPU使用个数的增加一方面数据传输总时间增加,另一方面内核启动总时间也会相应增加,Dana Schaa与David Kaeli对共享总线结构的单GPU和多GPU的传输速率做过测试,结果表明单GPU的吞吐率甚至会高于多GPU[23]。针对本文研究情况,建议M2、M3、M5三块模块使用1~2个GPU进行计算。对于M4模块,随着GPU使用个数的增加加速倍数越来越高,分析原因是数据传输延迟和内核启动时间与模块整个计算时间相比完全可以忽略不计,当采用7个GPU时候加速倍数已经高达180倍以上。
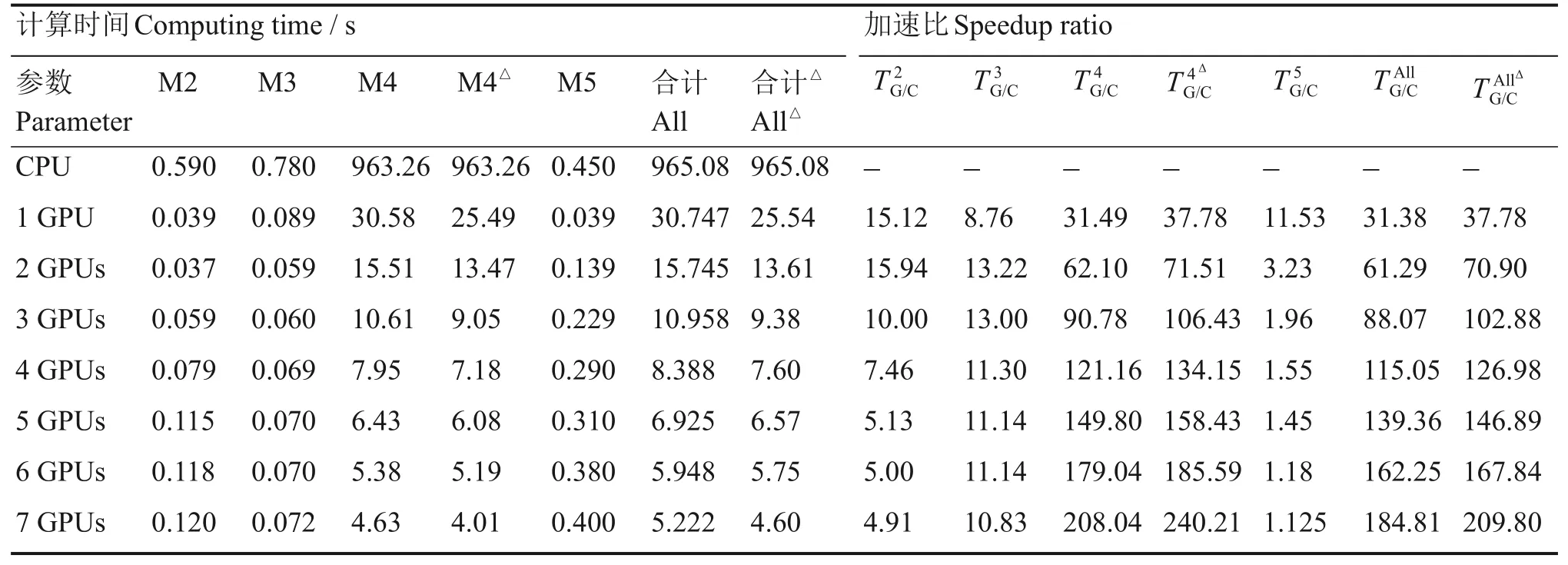
表2 机架角度为0°时,2~5四个模块计算时间和加速比Table 2 Execution time and speedup factors for 2~5 module when gantry angle was 0°

表3 机架角度为45°时,2~5四个模块计算时间和加速比Table 3 Execution time and speedup factors for 2~5 module when gantry angle was 45°
对于模块M4经过代码优化后,加速比达到了198倍以上,主要原因是研究过程中取消了M4中大量的逻辑判断语句。该模块采用CPU计算时,为了减少计算时间会加入一些逻辑判断语句来减少循环次数。GPU与CPU相比并不擅长逻辑运算,考虑到GPU中拥有大量线程,因此没必要通过逻辑判断来减少循环次数。通过测试不难发现,提高CS算法计算加速比可以通过两种方式:一是对程序代码进行优化,尽量减少逻辑判断语句;二是对程序中各个模块的GPU使用个数进行优化。表4是优化代码和各个模块GPU使用个数后计算结果,对模块M2和M5采用1个GPU,对模块M3采用两个GPU,对模块M4采用7个GPU且取消M4中逻辑判断语句。通过优化组合,最终加速倍数达到了207倍,计算时间缩短至9 s。上文提到临床中头部、胸部和腹部拥有更少的体元数目,这些部位若采用本文的方法将花费更少的计算时间,因此加速后的CS算法能够满足临床要求。

表4 通过优化代码和GPU使用个数优化后四个模块总的加速比Table 4 The speedup factors for 4 modules after optimizing code and number of GPU used
由于不是所有的CUDA函数都满足IEEE 754标准,因此有必要对结果准确性进行验证。验证过程中将CPU计算的剂量结果作为参考剂量,将采用不同GPU个数计算后的剂量结果作为评估剂量,对二者进行γ因子分析[24]。分析过程中距离标准选择3 mm,百分剂量差标准选择3%。经过评估,无论采用多少个GPU进行计算,GPU计算结果的γ通过率都是100%。说明使用不同个数GPU计算后的结果满足精度要求。值得一提的是勾成俊等[25]借助单个GPU让电子束剂量计算加速了98倍,在后续工作中,我们将研究多GPU在电子束剂量计算中加速情况。
4 结语
本文研究采用不同个数GPU对CS算法的加速结果表明:并行计算的加速倍数并非完全与GPU使用个数呈线性关系,还应充分考虑数据传输问题。对于在CPU上计算时间较短的程序代码,仅用一两个GPU进行加速即可。此外将CPU执行代码改为GPU执行代码过程中还应该考虑到逻辑运算问题,在编写GPU计算代码过程中应该尽量减少逻辑判断语句,而不是简单地对CPU代码进行移植。总之,本文研究结果表明:通过程序代码和GPU使用个数的优化,CS算法能完全应用于临床调强计划。
