基于数据分析的工业机器人换油策略研究
2021-12-21王欣王朴赵帅李鲁辉张明
王欣,王朴,赵帅,李鲁辉,张明
(北京奔驰汽车有限公司,北京 100176)
北京奔驰焊装车间采用高度柔性及自动化的生产线,依赖于大量的工业机器人设备与技术。北京奔驰装焊车间总计约2000台工业机器人运行,随着多个新项目的开展即将拥有更多的工业机器人。在自动化程度越来越高、机器人设备越来越多的背景下,如何统筹、高效、准确地管理机器人并且及时掌握机器人的运行状态对于北京奔驰的生产运营有着十分重要的意义。
机器人长期运行,由于减速机内齿轮磨损产生一定量的金属屑,流入的空气尘埃及其他硬质颗粒,齿轮润滑油在冷却过程中产生的水分等因素均会造成齿轮油变质,需要维护人员定期进行机器人齿轮油的更换,工业机器人原换油策略为每五年更换机器人齿轮油,每台需花费约10000元。但该策略存在诸多缺点,例如成本高昂、大量停产工时及人员需求、无法精准维护。
为降低运营成本及提升人员效率,重新规划制定机器人换油策略:基于每台机器人的实时数据判断机器人状态,通过采集机器人运行数据,包括实时数据如电机温度、扭矩、电流、运行时间等,抽取不同工况的95个齿轮箱油样送至专业油品分析实验室,得到油品成分分析结果,建立了油品质量评估模型,通过线性回归、CART树、KNN模型对比,选择线性回归算法和LR算法参数进行调优,使用模型计算出了现场所有机器人油品质量,进行排序并制定换油计划。仅通过机器人换油方案的优化,节省换油成本费用约300万元。
1 机器人运行数据采集
基于物联网MQTT协议(Message Queuing Telemetry Transport),将开发好的客户端安装到KUKA机器人操作系统内,并搭建可以接收数据的服务器,数据以订阅的方式进行发送。机器人定期将打包好的数据发送到服务器,就可以从服务器侧实时获得机器人内部各种资产信息和运行数据,例如机器人型号,位置,电机运行速度、时间、扭矩、电流、运行日志等信息,从而实现对机器人的状态监控。
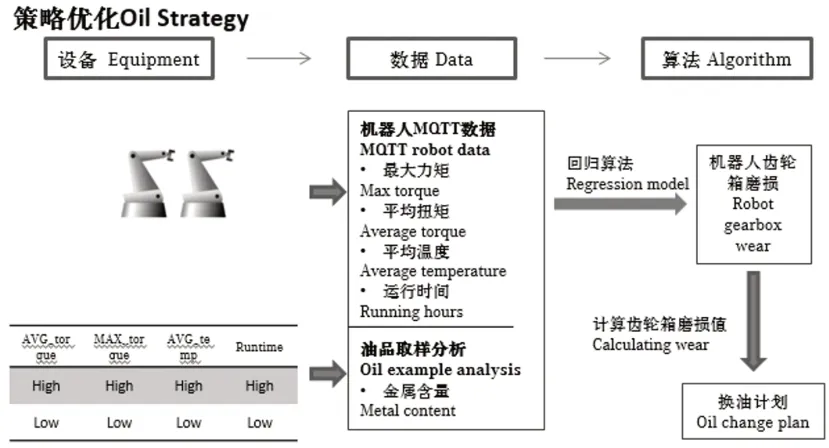
图1 机器人换油策略概念模型建立
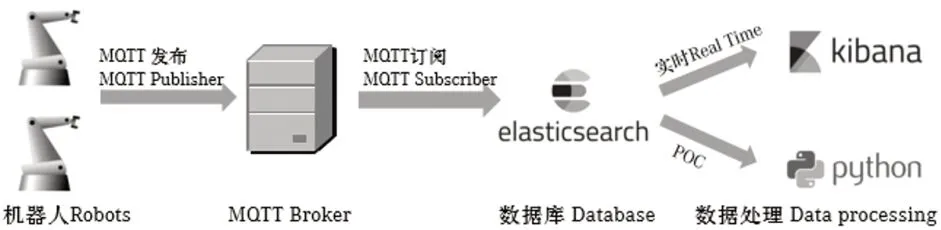
图2 基于MQTT协议数据采集流程
基于MQTT传输,Elastic Search数据存储,Kibana数据展示的高效平台。实时监控收集电机温度、扭矩、电流、运行时间等指标值,进行数据分析。采集的部分数据结果如下:
(1)Robot:机器人功能代号;AVG_torque:平均扭矩。
(2)Axis:机器人轴号;MAX_torque:最大扭矩。
(3)full_axis_name:机器人轴型号;AVG_temp:平均轴温度;Runtime:运行时间。
2 机器人齿轮油品成分分析
抽取不同工况的95个机器人齿轮箱油样送至专业油品分析实验室,得到油品成分分析结果,通过SPSS对油品分析结果进行统计分析,得到标准差、均值、百分位数等结果如图3。

图3 基于SPSS进行油品数据统计分析
基于标准差对各元素进行排序,排序结果如表2。

表1 基于Kibana采集机器人运行数据
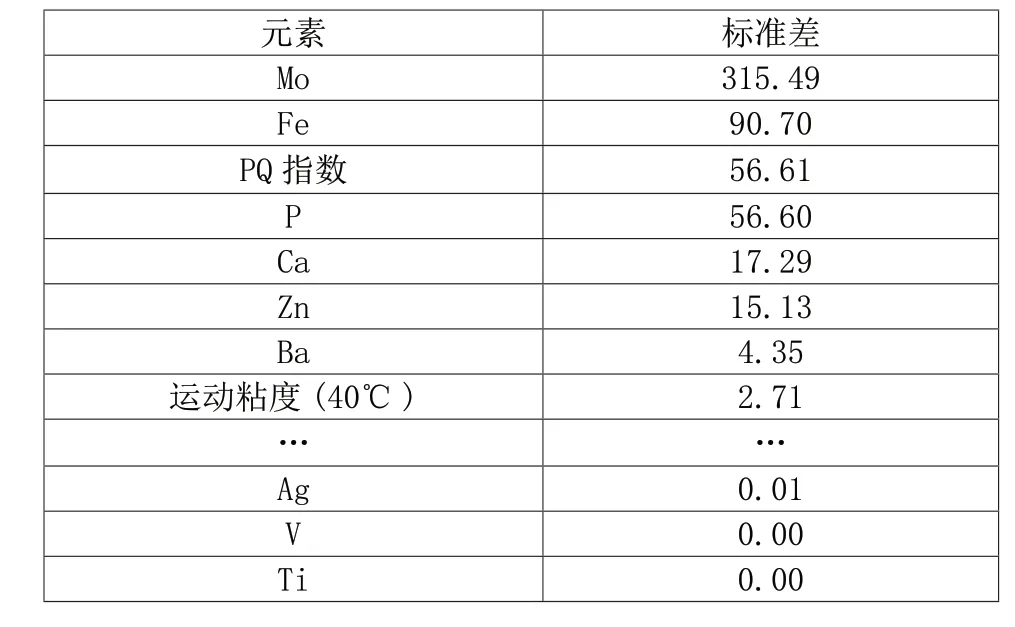
表2 油品特征因素标准差排序
由于MO元素,Fe元素,PQ指数,P元素,Ca元素及Zn元素的标准差较大,对油品质量的衡量相关性较大,利用SPSS对如上元素进行相关性分析,分析确定各元素变量之间的相关性。
根据油品分析结果各元素的标准差及相关性分析,Fe元素及MO元素为主要影响因素,从相关性分析得出随着机器人运行时间的增加MO元素含量降低,且Mo元素为润滑油中本体包含的元素,因此干扰项不作为本次分析结果的影响因素。
润滑油配方中不应含有Fe元素,从相关性图中分析得出随着运行时间的增加Fe元素含量会相应的增加,结合齿轮箱及齿轮制作原材料分析,随着齿轮的磨损产生了铁屑,导致润滑油Fe元素升高,因此算法将Fe元素作为衡量油品质量评价的主要因素。
3 建立油品质量评估模型
3.1 分析机器人数据与Fe元素之间的关系
利用Python建立机器人电机平均扭矩,最大扭矩,平均温度,运行时间等因素和油品质量影响因素Fe元素之间的结构性关系,由于随着机器人运行时间的增加,Fe元素含量也会相应的增加,大于200点为统计学异常数据,剔除异常数据后进行各特征之间的相关性计算,确认特征对结果的贡献值。
通过相关性分析得出各特征与Fe元素线性相关程度为:平均力矩>最大力矩>平均温度>运行时间>轴号。
3.2 质量评估模型建立
如下图例为机器学习的黑箱,应用机器学习可以不用关系内部计算细节逻辑。
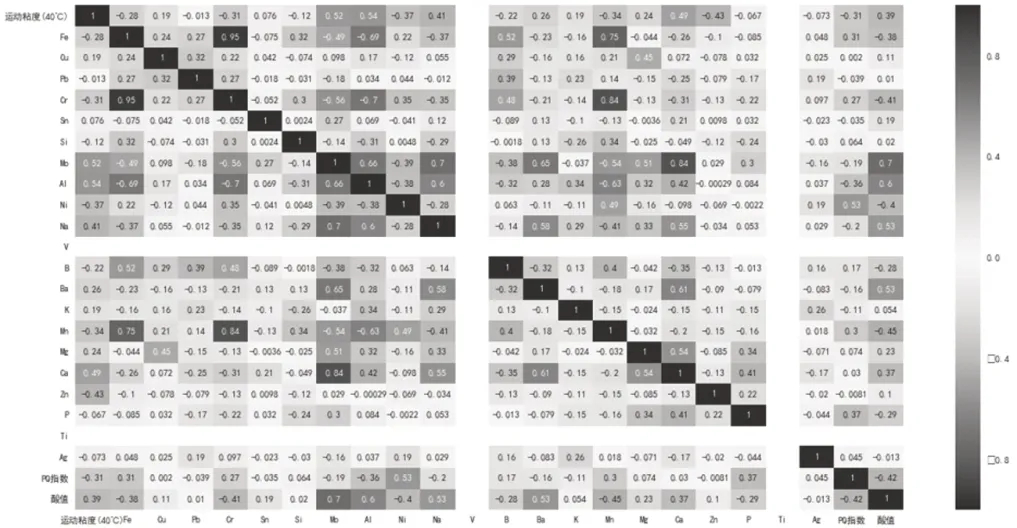
图4 油品特征因素相关性分析

图5 MO元素与运行时间散点图

图6 Fe元素与运行时间散点图

图7 各特征相关性图
数据上,多个维度的特征作为一组输入数据,一个维度作为匹配的输出数据。只需要根据选择的智能算法调整学习的参数,通过模型的训练即可观测结果的准确度。本例采用了SVM支持向量机的回归方法,将机器人的轴数据、运行时间、温度、电流 扭矩、负载等7个维度作为一组输入特征,对应Fe含量作为目标值,进行模型的训练。由于SVM支持向量机算法本身具备了相关性筛选能力,可以使机器人发送更多的维度特征数据,进行模型训练。

图8 各特征相关性散点图
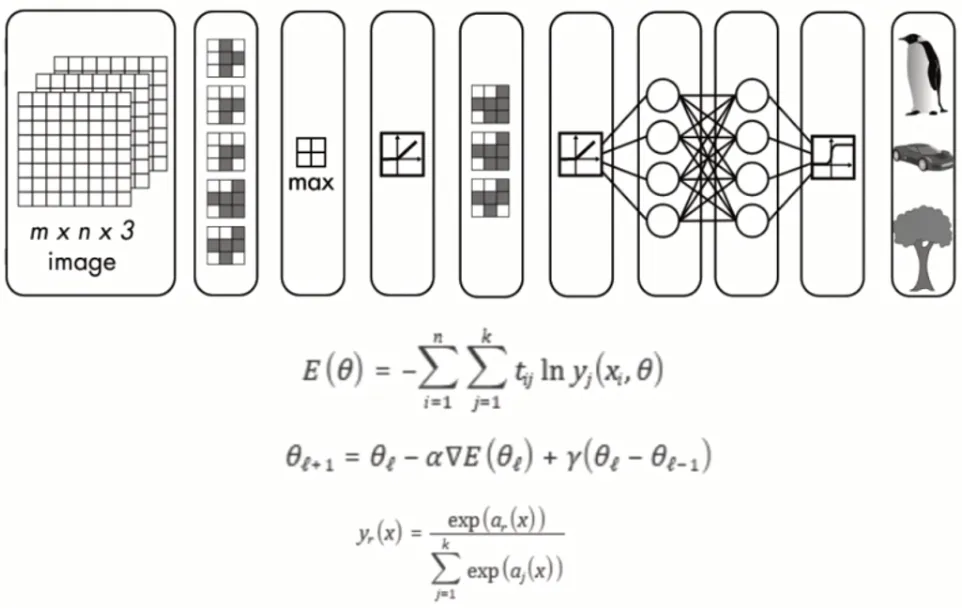
图9 机器学习训练模型

图10 训练集模型与Fe元素结果对比
4 结果及分析
目前主流的机器学习回归方法主要包含线性回归、CART树、KNN算法3种。
线性回归中的“线性”指的是系数的线性,而通过对特征的非线性变换,以及广义线性模型的推广,输出和特征之间的函数关系可以是高度非线性的。
CART树种算法即可以用于分类,也可以用于回归问题,测试数据集时,运行速度比较快,在相对短的时间内能够对大型数据源做出可行且效果良好的结果,但容易发生过拟合及容易忽略数据集中属性的相互关联。
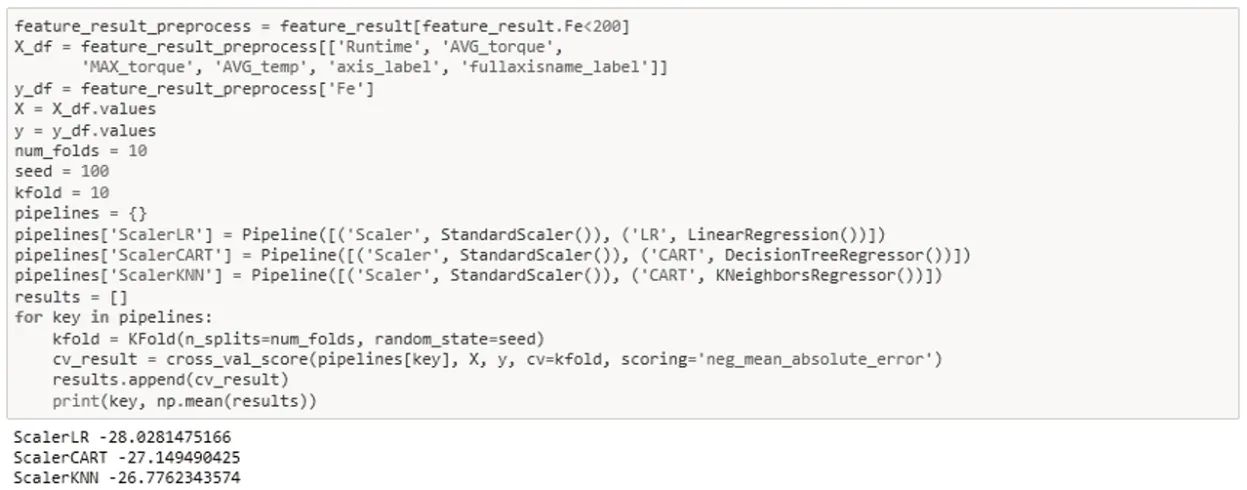
图11 三种模型测试结果对比
KNN算法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,KNN是一种在线技术,新数据可以直接加入数据集而不必进行重新训练,理论简单,容易实现,但在样本不平衡时,预测偏差比较大。
本章节对三种算法模型进行相关测试。
4.1 质量评估模型测试
4.1.1 用线性回归、CART树、KNN模型测试结果

4.1.2 去除共线性特征测试
去除共线性特征,误差值增加:
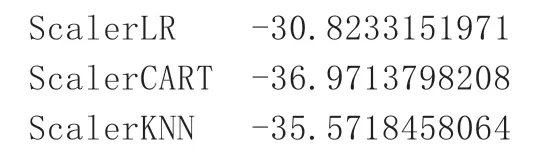
4.1.3 使用高次时间函数测试
使用高次时间函数,LR误差有所增加:

监测结果发现去除共线性特征及使用高次时间函数,误差值随之增加,综上,线性回归算法误差值受影响较小,因此选取最优的线性回归算法。
4.2 LR数算法调参
基于线性回归算法已经完成模型创建,但输出结果与实际结果存在一定的偏离,需使用LR数算法调参。
调参完成后最终输出结果与Fe元素实际含量进行数据对比,相当于预测样本,预测总体趋势相当,经验证准确率为75%。
5 结语
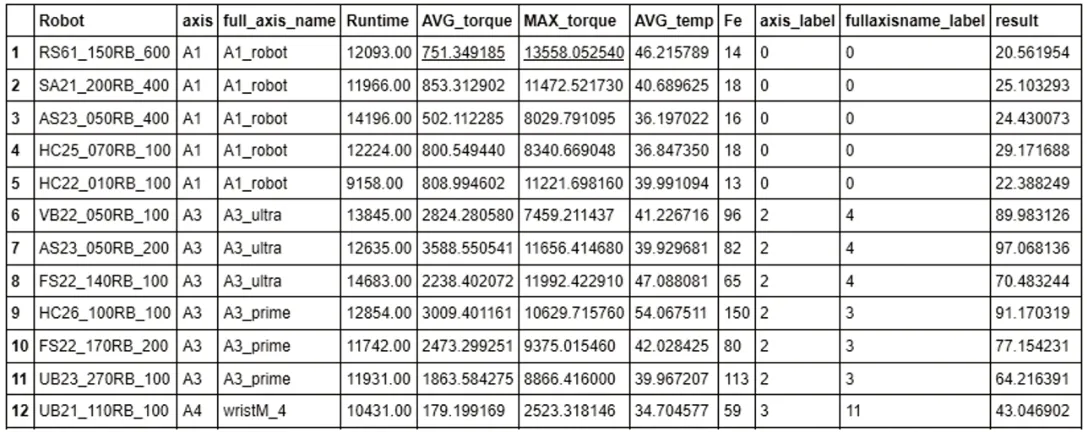
图12 检测模型结果输出
本案例基于工业物联网技术,对机器人各项运行参数进行数据采集,结合现场油品特征因素提取分析,利用Python建立油品质量评估模型,通过对线性回归、CART树、KNN模型对比,选取最优的线性回归算法,最后利用LR算法参数调优,实现油品质量评估模型的建立,经过测试集检验,模型的准确率达75%。后续设备维护保养过程中,可使用模型计算出现场所有机器人油品质量并进行排序,工程师可在后端计算算法每周按相关信号进行计算,相关计算结果会被用来做触发更换机油的报警,并制定换油计划。
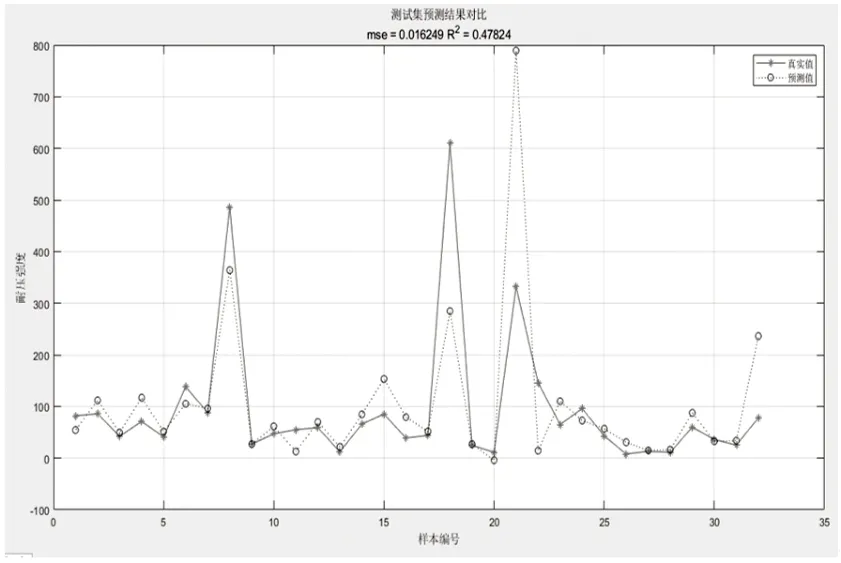
图13 测试模型结果与Fe元素真实值对比
根据供应商指导手册,每五年更换机器人齿轮油,每台需花费大约10000元。根据实际计算的Fe含量进行油液更换,一个产品生命周期结束,以MRA1480台机器人计算,可以节省300万元的润滑油更换费用,大幅度降低设备运营维护成本。
奔驰装焊维护团队在基于物联网技术获取底层设备信息及相关数据采集后,将机器学习等大数据分析方法引入并应用于设备预测性维护中,能够更加有效精准的指导机器人的维护保养及设备预测性维修,我们将不断推动技术创新与数据挖掘。
