基于数学建模的数据流异常检测方法
2021-12-17李焕云王胜杰
李焕云 王胜杰

摘要:针对常规异常检测方法聚合数据流数据时误判率较大的问题,设计一种基于数据建模的数据流异常检测方法。计算各个数据个体之间的欧几里度量参数,规范化处理异常数据流数据,设定数据流中的判断节点,利用数据建模技术判断数据状态,规范化处理异常数据流数据,采用临近采样方法在设定的数据集节点处构建一个检测窗口,设定检测周期后,最终实现对异常数据流的检测。准备实验数据集,设定各个数据集间的间隔周期,模拟数据流结构,准备两种常规检测方法以及设计检测方法进行实验,结果表明:设计的异常检测方法误判率数值最小。
关键词:数学建模;数据流;异常检测;误判率
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)33-0144-02
开放科学(资源服务)标识码(OSID):
数据建模是将各类数据处理为一个抽象组织,在确定管辖范围后,采用固定的组织形式将数据转化为数据处理工具的过程。使用数学建模内置的二维或是三维数字关系,搭建多个逻辑关系,采用该逻辑关系表述数据结构间的关系。数据流是一组有序的数据序列,内置数据起点以及数据终点字节,在输入流和输出流的控制下,形成一个特定的数据处理过程[1-3]。为此,在数据建模技术的支持下,构建一种数据流异常检测方法是很有必要的。国外在研究数据流异常检测起步较早,在数据库技术的支持下,率先建立了一种访问系统,并设计得到了入侵检测方法。国内在研究异常检测方法起步较晚,结合人工智能技术,研究得到了多种检测方法。
1 基于数学建模的数据流异常检测方法
1.1 规范化处理异常数据流数据
数据流内的数据由多个属性的数据构成,对应的数据有着不同的数据格式以及设计单位,所以在检测异常数据流时,应规范化处理数据流中的数据[4]。在规范化处理前,计算各个数据个体之间的欧几里度量参数,并根据该度量参数的数值,计算各个数据个体间的相似度,采用Z-score规范化处理方式处理数据流中的各项数据后,线性变换数据流中的原始数据,保持数据流中原始数据间的大小数值关系,假设属性数值的标准差后,标定属性一个有意义的最大值,标定为不同的维度参数后,形成多个维度数据空间。为了保证数据流的正常处理流程,消除数据信息流中的干扰,利用统计概率处理方法计算数据流中的标准信息熵,可表示为:
[h(x)=-i=1np(xi)n] (1)
其中,[p(xi)]表示标准最大值对应的函数,[n]表示数据空间的维度数值。当计算得到信息熵的数值大于零时,则表示数据流处于一个稳定状态。在该种稳定状态下,将数据流空间内的节点划分为不同处理顺序的数据节点,整合为不同集合的数据组后,应用数据建模技术,判断各个数据组中数据流的状态。
1.2 利用数学建模判断数据状态
使用上述得到的数据集,在划分数据集的数据分界处,设定不同的数据节点,以该节点作为状态判断点。使用该节点周围的两个数据组作为处理对象,采用距离计算方式,使用各个数据集中通用的属性数据,计算通用数据间的距离,采用数据建模方法描述数据为一个状态数据集,随机选定一个数据点,计算该点与设定节点间的距离,当该距离数值在预先设定的参数数值之间,则表示该数值为正常状态,当该数值在设定的参数数值之外,则表示对应处理的数据集为异常状态[5]。
为了增强判断数据状态时的精准性,在预先设定参数时,应在划分的数据集中定义一个局部异常因子,使用数据密度参数作为该局部异常因子的约束值,采用数学描述方法将给定的数据点处理为一个衡量数值,假设该衡量数值明显不同于局部平均数值,则认定该数据集对应的数据流存在异常,异常数据状态判断后,针对该部分异常数据,构建检测过程。
1.3 实现对异常数据流的检测
基于上述处理过程,采用临近采样方法在设定的数据集节点处不断采集数据,并构建一个滑动窗口,在采集的数据流处,建立一个数据密度估算数值关系,可表示为:
[f(x)=1Sct=1kxt] (2)
其中,[Sc]表示采样参数,[xt]表示數据密度函数,[k]表示滑动周期。在上述数值关系内,确定一个簇首数值,在密度数值返回各数据集中处理时,设定一个返回周期,按照不同的时间尺度,不断替换密度数值中的正常数据流中的数据。
为了消除检测过程中产生的误判,在簇首节点处下传一个全局分布参考数值,数据流节点结合该信息区分数据集内的有效数据,构建一个滑动区分窗口,当存在节点进入该滑动窗口时,自动触发计算窗口处理数据集的密度,并更新为下一个检测窗口,不断循环处理形成一个自动处理过程。对应多个检测状态,定义上述检测过程的异常概率,计算异常状态下的数据流相关性,并将该统计特征处理为一个联合参数,控制该联合参数在检测窗口中的比例,对应不同的比例数值,设定不同条件下的检测常量,在该检测常量的控制下,构建一个连续的数据流异常检测过程,综合上述处理,最终完成对基于数据建模的数据流异常检测方法的构建。
2 对比实验
2.1 实验准备
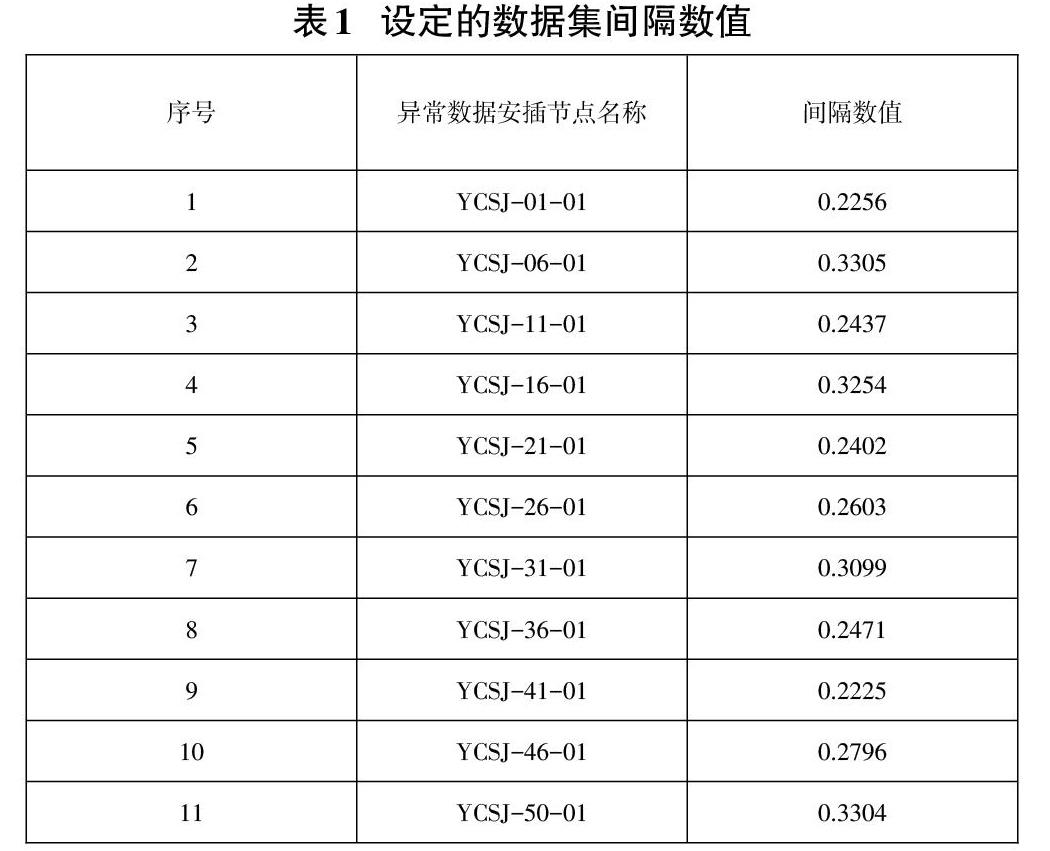
采用KDDCUP-99数据集作为处理对象,选定数据集中500个数据作为实验对象,将正常网络访问数据作为数据流正常数据,将异常访问状态下的测试数据作为异常数据流处理对象。在实际处理过程中,将不同种异常网络数据看作为相同异常状态,在标记异常数据组后,选定100组测试数据作为异常数据流,将400组数据作为正常数据流。设定每组数据在检测时的采样节点,在每四组正常数据内安置一个异常数据,并设定数据组成数据集间隔数值,设定的间隔数值如表1所示。
在表1设定的间隔数值控制下,将上述数据形成的数据流,整合为下表所示的数据特征,并对应不同的数据特征,设定不同的转化参数。并使用设定的属性数据对应设定的转换参数后,准备两种常规异常检测方法与设计的异常检测方法进行测试,对比三种检测方法的性能。
2.2 结果及分析
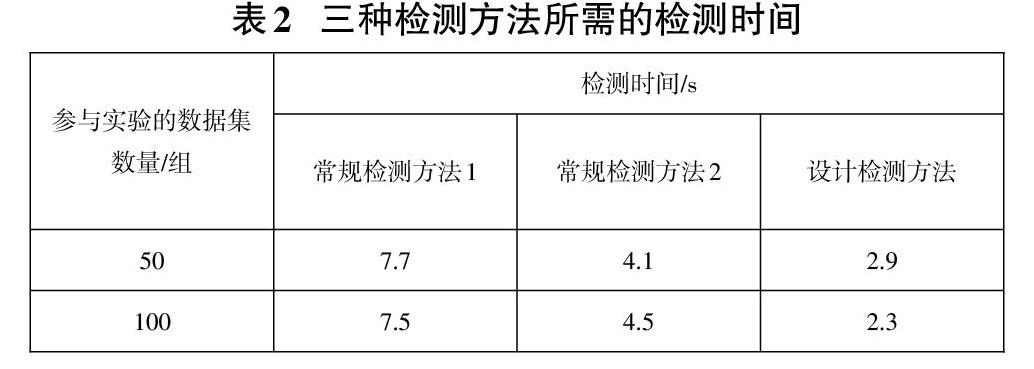
基于上述实验准备,控制三种异常检测方法从安插节点YCSJ-01-01开始检测,并将其作为起始时间统计点,统计三种检测方法的运行时间,运行时间结果如下表2所示。
由表2可知,与两种常规检测方法相比,设计的检测方法检测所需的时间最短,时效性最强。
在上述实验环境下,定义检测方法的检测误判率为误检数据占据正常数据的比例,统计不同数据周期下,三种检测方法实际产生的检测误判率,实验结果如下表3所示.
由表3可知,与两种常规检测方法相比,设计得到的检测方法产生的误判率数值最小,能够正确检测多种数据。
3 结束语
随着数据处理技术的发展,数据流形式逐渐丰富,产生的异常数据流逐渐成为当下的研究热点,在数据建模技术的支持下,构建一种异常检测方法,能够改善常规检测方法存在的不足,为今后研究检测异常数据流提供研究依据。
参考文献:
[1] 杨杰,张东月,周丽华,等.基于网格耦合的数据流异常检测[J].计算机工程与科学,2020,42(1):25-35.
[2] 邓丽,刘庆连,邬群勇,等.基于数据流时空特征的WSN异常检测及异常类型识别[J].传感技术学报,2019,32(9):1374-1380.
[3] 杜臻,马立鹏,孙国梓.一种基于小波分析的网络流量异常检测方法[J].计算机科学,2019,46(8):178-182.
[4] 徐晓丹,姚明海,刘华文.基于稀疏表征的异常点检测方法[J].华中科技大学学报(自然科学版),2020,48(7):20-25.
[5] 董书琴,张斌.基于深度特征学习的网络流量异常检测方法[J].电子与信息学报,2020,42(3):695-703.
【通联编辑:张薇】
