基于DeepLab V3+改进的图像语义分割模型
2021-12-17徐志凡杜洪波韩承霖李恒岳祁新林凯迪黎诗
徐志凡,杜洪波,韩承霖,李恒岳,祁新,林凯迪,黎诗
(沈阳工业大学 理学院,沈阳 110870)
0 引言
图像语义分割在计算机视觉领域起着重要的作用,在虚拟现实[1-2]、医学影像[3-4]、人机交互[5-6]等领域有着越来越普遍的应用。
深度学习[7]与传统语义分割算法的结合,使图像语义分割精度得到极大的提升。全卷积网络(FCN)[8]为最初与深度学习结合的网络,其是传统卷积神经网络(CNN)的扩展,为减少计算量FCN 将CNN 中的全连接层转化为卷积层。但FCN 产生的分割图较为粗略。SegNet[9]为了提高效果,复制了最大池化指数,引入更多的跳跃连接。这些语义分割模型在空间分辨率方面有着明显的缺陷,于是RefineNet[10]利用残差连接的思想,降低了内存使用量,提高了模块间的特征融合。由于基于FCN 的很多架构都未引入充分的全局信息,PSPNet[11]提出了一个金字塔池化模块,充分利用了局部信息与全局信息,使得最后的分割结果更加精确。综上所述可以发现,提高图像语义分割的精确度是目前的主要研究方向和热点。
Google 团队自2015 起提出了一系列DeepLab模型[12-15],在语义分割领域有着重要作用。虽然其中的DeepLab V3+模型的分割效果最优,但其在解码器部分对于特征图的多尺度连接不够充分,使最终的语义分割图的分割精细度尚有提高的空间。本文据此提出了一种基于DeepLab V3+改进的模型,优化了编码器与解码器部分,在公开数据集上进行验证,结果表明MIoU 相较于原模型有所提高。
1 DeepLab V3+模型与改进
1.1 DeepLab V3+基础模型
DeepLab V3+网络模型为编解码结构。编码器部分的基础网络ResNet101 提取图像特征,生成语义特征图;ASPP 模块则将空洞卷积与SPP 进行结合,对生成的特征图进行不同扩张率的空洞卷积采样,将得到的特征图concat 融合后进行1x1 的卷积,最后得到具有高级语义信息的特征图。解码器从基础网络ResNet101 的某一个block 中提取一张带有低级语义信息的特征图,将其与编码器所得的高级语义特征图进行concat 融合,最后进行上采样得到与输入图像同样大小的语义分割图。该模型结构如图1 所示。
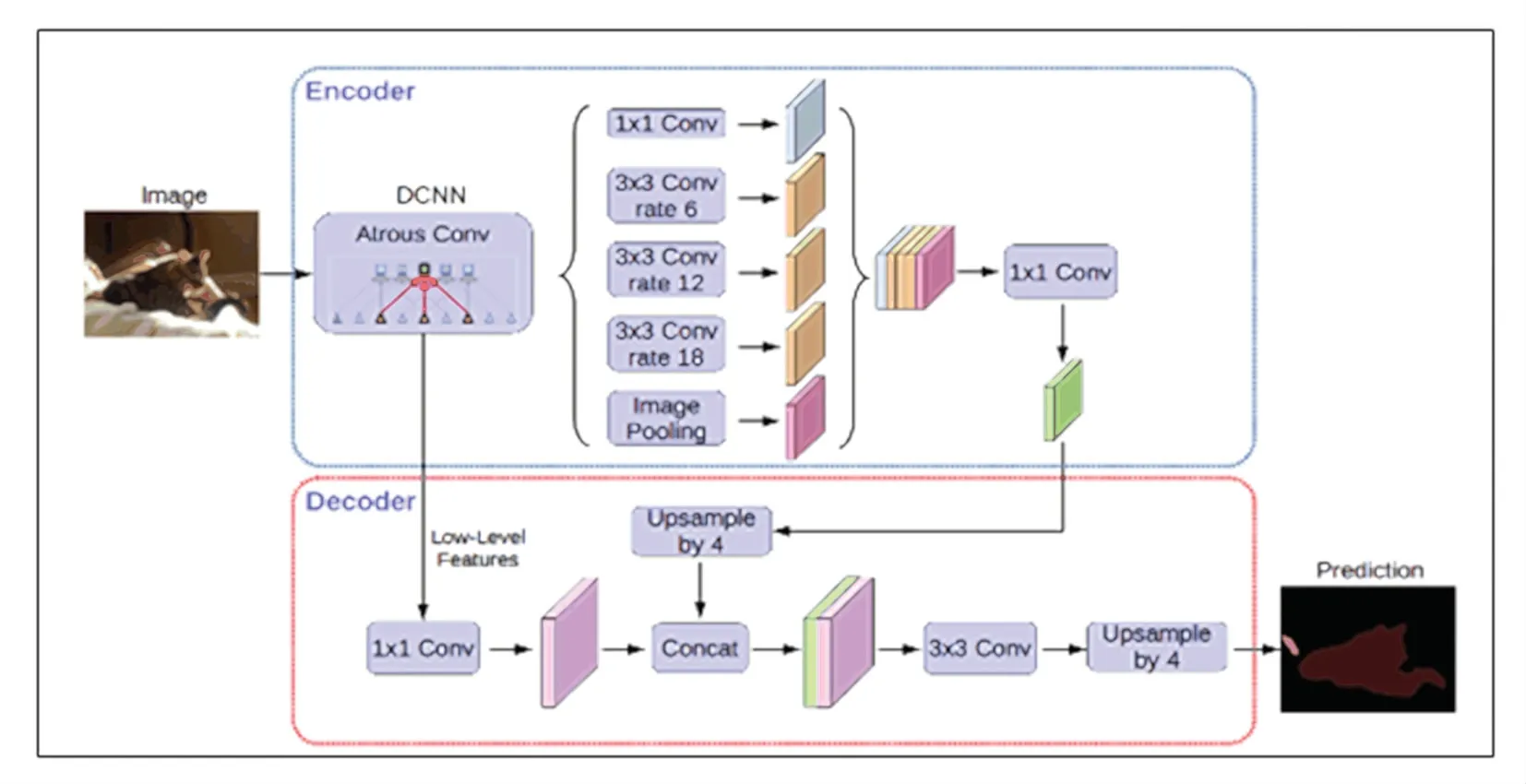
图1 DeepLab V3+模型结构图Fig.1 DeepLab V3+model structure diagram
1.2 改进的DeepLab V3+模型
对于语义分割来说,在计算量减少的同时分割精细度越高越好。虽然DeepLab V3+算法可以达到较高的分割精细度,但其在解码器部分对于特征图的多尺度连接并不充分,仅有高级语义特征图与低级语义特征图的连接会使模型的学习能力不足。为了提高模型的学习能力,得到更为精细的语义分割图,且在不增加计算量的前提下,可利用编码器结构中的ASPP 模块,增加中级语义特征图。虽然在ASPP 模块中对基础网络中得到的特征图进行了多尺度信息的提取,但是不同尺度的特征图包含的信息是不同的,且不同尺度的特征图中的信息差异较大,统一进行融合后很难学习。为此,本文模型引入中级语义特征图。中级语义特征图含有丰富的语义信息,使得解码器部分高级语义特征图与低级语义特征图的连接更为平滑,保留了更多的细节信息。经实验对比,改进后的模型分割精度有所提高。
在不增加计算量的前提下对编码器中的ASPP模块进行改进,一方面先将基础网络ResNet101 所得的语义特征图并行处理,采用扩张率分别为6、12、18 的3x3 卷积提取特征,将多尺度信息做concat融合处理,并通过1x1 卷积,调整中级语义特征图在语义分割预测图中所占的比重。另一方面将ASPP模块前两层输出的特征图同样以concat 融合处理得到高级语义特征图,并和中级语义特征图一起输入到解码器部分,为图像语义分割做准备。改进后的整体模型的结构如图2 所示。
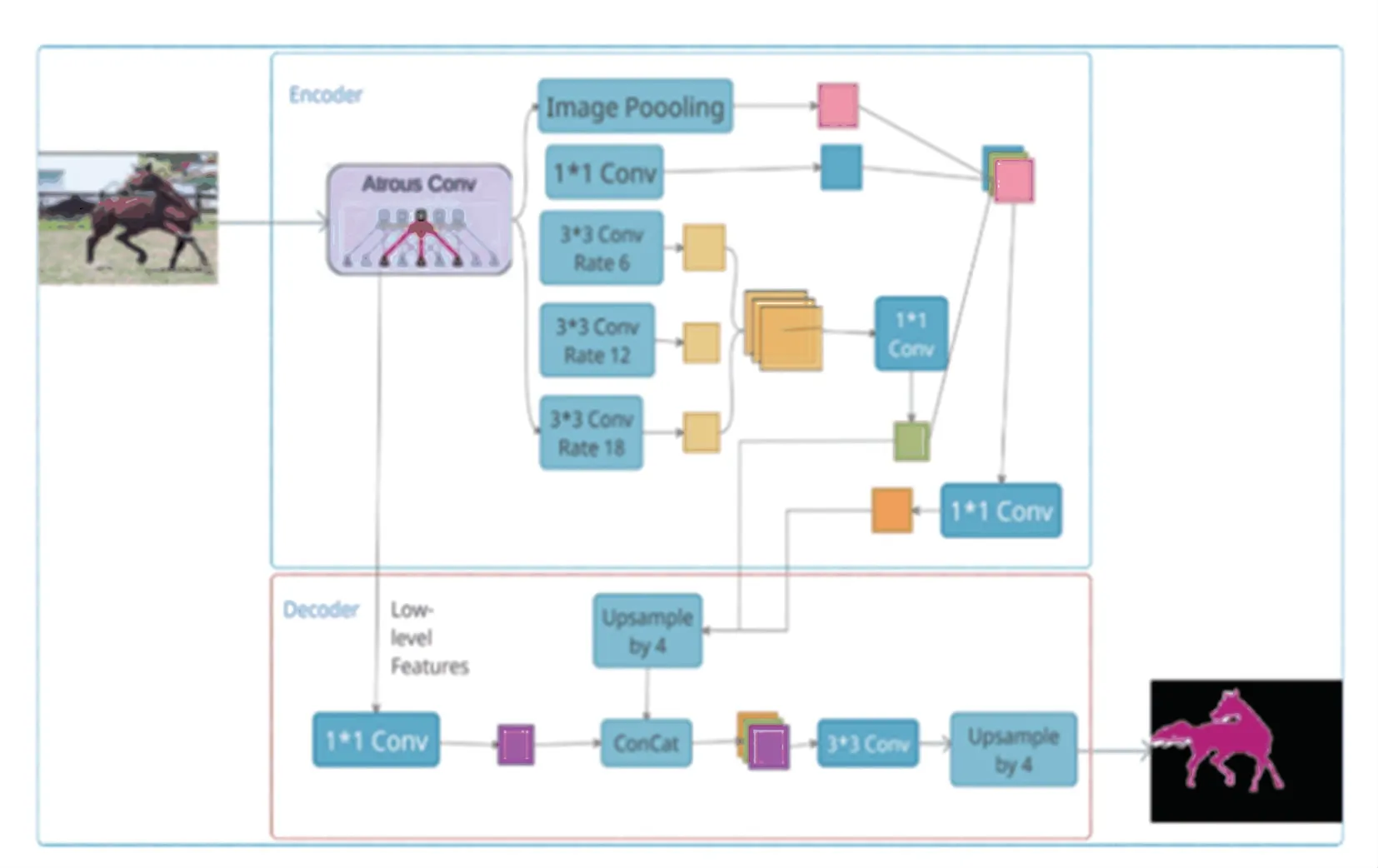
图2 改进的DeepLab V3+模型图Fig.2 Improved DeepLab V3+model diagram
2 实验及结果分析
2.1 实验环境
实验仿真环境为 python3.6、Anaconda3、TensorFlow1.15、Keras2.2.4。硬件环境为深度学习GPU 运算塔式服务器主机,采用可支持两个INTEL XEON SP 的可扩展处理器(10 核/20 线程2.2G),内存为双16G(24 个DIMM 插槽),GPU 使用1 块GeForce RTX3070。
2.2 数据集
实验采用测试图像语义分割任务模型性能的2个主流图像数据集:COCO 2017 数据集[16]、PASCAL VOC 2012 增强版数据集[17]。其中COCO 2017 数据集进行预训练,PASCAL VOC 2012 增强版数据集用于对模型进行测试和评价。
2.3 实验分析
在训练模型开始之前,将训练图像统一裁剪成513x513 像素,出于高效读取数据的考虑,将图像转化为Tfrecord 文件。为增强分割图片的显示效果,对真实结果和预测结果采用RGB 彩色图显示。训练参数见表1。
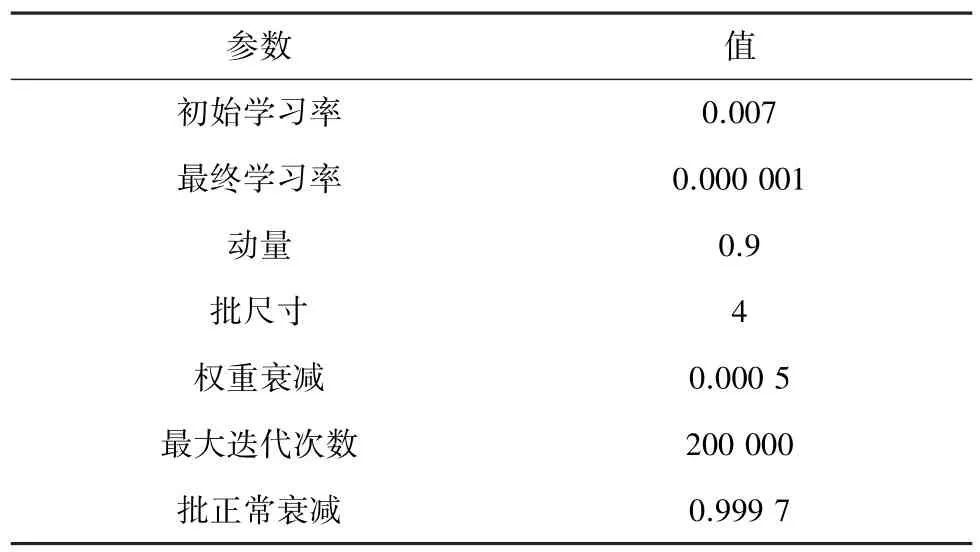
表1 模型参数配置Tab.1 Training parameters
学习率采用多项式自动衰减,当迭代次数超过200 000 次,学习率为0.000 001。对损失函数采用动量梯度下降法优化,在PASCAL VOC 2012 增强版数据集上共计迭代150 307次。总损失函数为交叉熵损失,如式(1)所示:
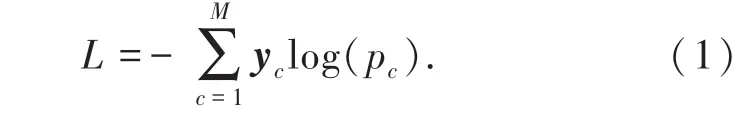
其中:M代表类别数;yc是一个one-hot 向量,元素只有0 和1 两种取值(若该类别和样本类别相同则取1,否则取0);pc表示预测样本属于c的概率。
总损失如图3 所示。由图中可见,总损失在大约14 万次左右开始收敛。
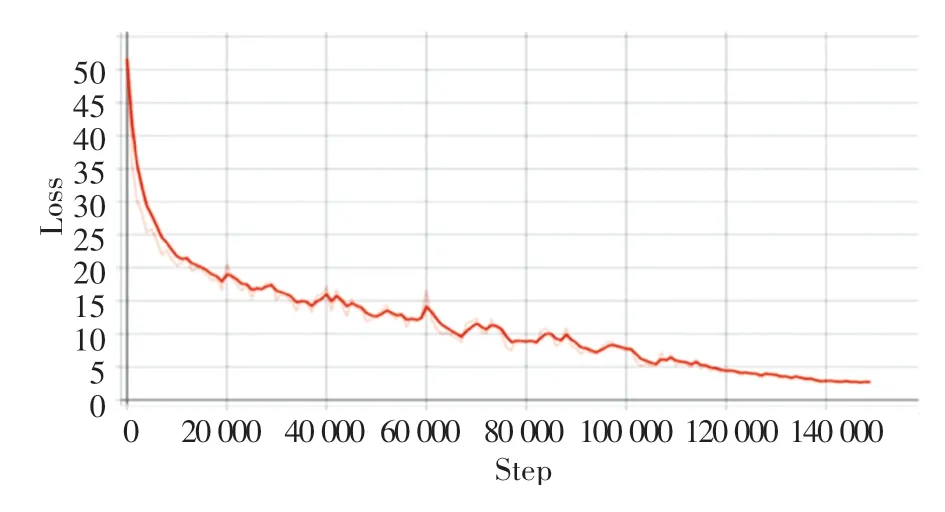
图3 总损失图Fig.3 Total loss graph
如图4 所示,改进后的模型不仅在单个目标的图像中(图4 中第一行)有着良好的分割效果,在拥有多个目标的图像中(图4 中第二行)也有不错的分割精细度。

图4 改进后模型在验证集上效果Fig.4 Improved performance on the validation set model
2.4 实验对比
通常在语义分割领域有4 种经典评价指标:像素准确度(PA)、均像素准确度(MPA)、平均交并比(MIoU)以及频权交并比(FWIoU)。本实验选用MPA与MIoU作为衡量标准。
(1)MPA:计算分割正确的像素数量占像素总数的比例,再取平均:

(2)MIoU:计算分割图像与原始图像真值的重合度,再取平均:

其中,pij表示真实值为i,被预测为j的数量;pii是真正的数量;pij表示预测为真但实际为假的数量;pji表示预测为假但实际为真的数量。
3 种模型对比测试结果见表2。由此可见,改进后的DeepLab V3+模型不仅相对于PSPNet 模型在均像素精度(MPA)上提高了16.08 %,平均交并比(MIoU)提高了6.25 %,而且相对于原DeepLab V3+模型在均像素精度(MPA)上提高了0.54 %,平均交并比(MIoU)提高了0.76%,验证了改进的模型有着更好的分割效果。
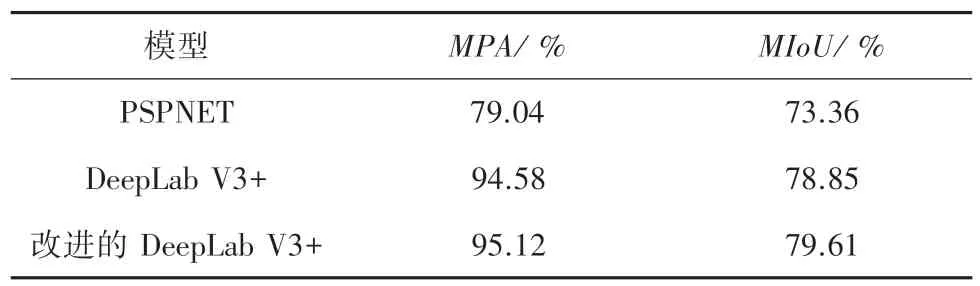
表2 3 种模型对比测试结果Tab.2 Comparison test results of three models
为进一步体现模型的分割性能,采用模型输出的语义分割图像来对比说明。在图5 中:(a)为原图,(b)为DeepLab V3+分割的效果,(c)为改进的DeepLab V3+分割的效果。图中黄色圈所标注的是改进前后二者之间的差别,验证改进的DeepLab V3+分割效果更优。例如:从图5 中第一行可以看出,改进的DeepLab V3+模型更为精细的分割出了飞机尾翼,而DeepLab V3+模型并没有达到;由5 中第二行可见,改进的DeepLab V3+模型对鸟类的头,羽毛与尾部的边界分割相比于DeepLab V3+更为精准。这表明改进的DeepLab V3+模型在增加了中级语义特征图后模型的学习能力更强,对边界的分割的精细度更精准。

图5 基于两种模型对比分割结果Fig.5 Compare segmentation results based on two models
改进后的模型不仅分割效果更优而且在单张图片处理速度(MS)与模型大小(MB)上也更优。在单张图片的运行时间上,改进后的模型速度提高约6.41%,且模型容量减少了11.2%,详见表3。

表3 两种模型对比测试结果Tab.3 Comparison test results of two models
3 结束语
本文针对DeepLab V3+模型在解码器部分对于特征图的多尺度连接不充分的问题,提出了一种基于DeepLab V3+模型的改进算法,该算法对DeepLab V3+网络模型进行了优化,在解码器部分增加了中级特征层,在COCO 2017 数据集和PASCAL VOC 2012 增强版数据集上进行验证,结果表明改进模型的MIoU 有所提高。但是还存在计算量过大,对于移动端的实时分割还远远达不到要求等问题。因此,减少计算量,轻量化模型结构等将成为下一步的研究方向。
