基于多通道自注意力机制的刑事案件量刑技术
2021-12-17蔡怡蕾李尚叶麟张宏莉
蔡怡蕾,李尚,叶麟,张宏莉
(哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001)
0 引言
目前司法刑事案件在其审查判决过程中,主要依靠法官等一系列的司法工作者对案件进行审查,并依据国家律法和案件真实情况对其进行理解和决策分析,从而对案件进行可信、公正地判决。依据中国对刑事案件判案依据的有关规定,在不与《中华人民共和国宪法》等国家级法规相抵触的前提下,可参考地方相应的法律法规进行审判,且法官在案件量刑中拥有一定程度的自由裁量权。因此,会造成针对同一案件,不同的地区、不同的法官对案件判决的侧重点不同的情况,从而导致对案件的量刑有失偏颇。而且近年来刑事案件一审判决数量显著增加,而司法工作者人数反而有缩减趋势。目前司法判决中的主要矛盾即是日益增长的数据与不平衡、不充分的司法人力和司法公正之间的矛盾,如何更好的满足人民群众对司法的需求,减轻司法工作人员的繁重负担是当今司法领域亟需解决的问题。近年来,随着科技的发展,人工智能技术日趋完善,利用人工智能技术处理海量数据,将计算机技术引入司法领域已经成为不可阻挡的趋势,是当下“案多人少”、效率低等问题的有效解决办法。
当前司法领域中,“AI+”正处于发展阶段,现有方法还不够成熟,无法满足人民群众对智慧司法的需求。现如今已有的案件判决中存在着很多高质量的判决案例,且随着社会的发展数据量不断增多,这足以为“人工智能+司法”提供良好的数据基础。本文借助历史案件数据,采用合适的模型对案件量刑进行学习,使其逐渐承担法官的案件决策工作,为法官提供决策建议,逐步解放法官,减轻司法工作者工作负担,使其更加高效、公正的进行司法决策,从而促进司法工作的透明性和可信度的提高。同时,智慧司法可打破非司法工作者与专业人士之间的壁垒,使法律判决的结果更加可信。
本文以司法决策为目的,着重研究司法决策中的辅助量刑问题,结合人工智能和领域知识对案件进行剖析,充分发挥计算机科学与其他学科相结合的优势,努力打造透明、公正的司法量刑,为人民群众提供公开合法的司法判决,对于维护司法公正,构建法治社会具有重要意义。
1 相关工作
早在上世纪五十年代,研究学者就意识到了智慧司法的重要性,提出将法律领域信息化,结合计算机领域知识推出自动检索和案件判决模型。现如今,智慧司法主要方向包括案件分类、辅助量刑、证据推理、法律推理、类案推送、文书编写、法律问答以及信息检索与查询等[1]。
在刑期预测方面,林等人在强盗罪和恐吓取财罪2 个罪名的案件中提取出21 个要素标签,并增加自动提取特征标签,通过对标签一系列的分析后,对这2 种罪名进行罪名分类和刑期预测[2];Li等人使用多通道层次注意力神经网络学习案件事实、被告人基本信息以及法律法规之间的内在联系和深层语义,从而构造罪名预测、法律推荐以及刑期预测的统一框架,在评估指标上都达到了新的高度[3];Zhong等人认为法律判决预测中罪名预测、法条推荐、刑期预测、罚款预测等各个子任务之间存在一定的拓扑依赖性,因此将该依赖关系转化为图结构,构建包含拓扑关系的多任务学习框架进行司法判决多任务共同预测,从而提高法律判决的可信性和可解释性[4];Yang等人基于LJP 子任务之间的关系,提出可以基于注意力机制的多角度双向神经网络,通过前向预测和后向验证,显著提高了各子任务的预测准确率[5];Chen等人基于案件罪名进行刑期预测,提出针对罪名的特征筛选机制的深度神经网络模型,该模型可针对多罪名案件进行刑期预测,提高了基于各个罪名的刑期预测以及总刑期预测的准确率[6]。在司法判决预测(LJP)中,还有其它各类子问题,如证据推理问题中,Vlek等人认为所有案件的判决必须经过一系列的证据推理,为案件准确判决提供坚实基础,同时结合叙述性和辩论性方法,通过贝叶斯网络生成不同证据的概率值,从而还原真实的案件信息[7];Walker等人提供了一个用于建模复杂法律推理的可视框架,该框架基于多谓词默认逻辑将法律法规与专家知识进行结合,在规则推论和证据评估上发挥巨大作用[8]。在案件分类问题中,Luo等人基于案件事实的信息构建罪名预测模型框架,提出基于Attention 机制的深度神经网络对案件事实部分和法律法规部分进行向量表示,并将法律法规信息融入案件事实,从而实现罪名预测[9];Wang等人根据法律文本以及案件描述的文本特点,将罪名预测问题划分为分层多标签分类问题,将父子标签进行匹配,从而优化案件罪名预测问题[10]。
近年来,随着人工智能的发展,“AI+NLP”问题取得了一系列的突出成果,其中一些基础神经网络模型得到业界广泛认可,如Word2Vec、卷积神经网络以及循环神经网络等。在此基础之上,业界学者对其进行深入研究,并产生了许多具有跨时代意义的研究成果。ELMo(Embeddings from Language Models)模型开辟了多义词向量的大门,该模型不同于以往单词与向量之间的一一映射的固定模式,而是考虑到语法和语义的复杂性,结合上下文产生适合当前语言环境的词向量[11];BERT 的提出是NLP领域内重要的里程碑,在11 个NLP 任务中取得卓越表现,训练出的Word-Level 向量变成Sentence-Level 的向量,下游具体NLP 任务调用更方便[12];Yang 针对文本结构提出层次注意力机制(Hierarchical Attention Networks,HAN),该注意力机制可以将模型结构拆分为2 部分,分别为句子级别的Attention 结构和单次级别的Attention 结构,在文本分类任务上准确率有大幅度提升[13];Google 团队与2017 年提出自注意力机制(Self-Attention)在业界引起极大轰动,解决了RNN 系列注意力机制中存在的参数多,速度慢等问题,在各个任务上均取得优秀表现[14]。
2 模型
基于多通道自注意力机制的刑事案件辅助量刑技术模型的基本结构如图1 所示。该模型将被告人基本信息、案件事实描述与法律条文进行融合,构建刑事案件的辅助量刑模型。本文将该模型的输入输出形式化的表示如式(1)(2)所示。

图1 基于多通道自注意力机制的刑事案件辅助量刑技术模型基本结构图Fig.1 The basic structure of criminal case auxiliary sentencing technology model based on multi-channel self-attention mechanism

其中,Sp为被告人基本信息,包括被告人犯罪历史、精神状况等信息;Sa为法律条文知识库,中国法律条文甚多,其中涉及到量刑的法条主要为《中华人民共和国刑法》,本文主要研究的是刑事案件中的故意伤害罪,但由于案情中所出现的情况较多,可能会涉及到除《中华人民共和国刑法》第二百三十四条以外的其它条文,如针对自首情节的第六十七条法文、针对未成年人犯故意伤害罪量刑规定的第十七条条文等;Sf为案件事实描述,该部分含有被告人进行犯罪的原因、实施过程、犯罪性质、犯罪后果、对社会危害程度以及犯罪后悔过态度等信息,该部分是量刑的主要信息部分;Rt为刑期的判决结果,由于本文采用回归的方法对刑期进行预测,因此,Rt为向量空间的一个非负实数。
利用上述模型进行刑期预测的步骤如下:
(1)输入数据在经过分词后进行向量化表示,构成词向量矩阵;
(2)以被告人基本信息和案件事实描述为输入,将其输入至法条提取器中,对法律条文知识库中的法律条文数据进行提取,找出和当前案件可能有关系的前若干条法律条文,并将其作为法律条文部分的输入,本文中该法条提取器为SVM 分类器;
(3)将各部分输入数据输入到Embedding 层,对词向量进行进一步的调节,为后续工作提供良好基础;
(4)将各部分的输入通过编码器进行文档编码,鉴于注意力机制在自然语言处理中表现出来的优异能力,此部分采用多头自注意力机制进行文档编码处理,被告人基本信息、案件事实描述和法律条文的向量表示分别表示为dp、df和da;
(5)将法律条文的文档表示da输入到文档聚合器中,将被告人基本信息dp和案件事实描述df联合起来形成2 部分的上下文向量表示,并以此作为文档聚合器注意力机制的Query 部分进行编码计算形成向量表示dw;
(6)最后,将文档聚合器所生成向量dw输入至多层感知机(MLP)中进行刑期预测回归计算。
2.1 法条提取器算法
法条提取器是根据被告人基本信息和案件事实描述,在法律条文知识库中选取其可能依据的前若干条法律条文,法条提取过程如图2 所示。
图2 法条提取过程图Fig.2 The process of law extraction
本文采用TF-IDF 进行文本特征处理,得到文本中每个词的特征值。在使用SVM 进行文本多分类时,采用OVO 的方法,将多标签分类问题转化为多个二分类问题。在OVO 方法中,若要对文本进行n分类,在其中包含n(n-1)/2 个分类器。本文中法律条文知识库为《中华人民共和国刑法》集合,其中包括有452 条法律法规。
2.2 文档编码器算法
本文采用多头自注意力机制进行文档编码,其原因在于:
(1)自注意力机制比CNN 和RNN 神经网络参数少,计算复杂度低;
(2)自注意力机制不同于基于RNN 的注意力机制,其可实现并行计算,速度较快;
(3)自注意力机制进行计算时采用词与词之间直接进行相似度计算的方法,使每两个单词之间的距离均为1,解决了RNN 网络中过长序列导致的长期以来关系削弱的问题;
(4)多头注意力机制在自注意力机制的基础上进行扩展,从以往的一个关注点增至多个关注点,每个头学习到不同表示空间的特征,侧重点各有不同,从而更加全面学习文本信息。
自注意力机制基本结构如图3 所示。文本中的每个单词都要和其它所有词进行相似度计算,以学习到句子内部关系。在计算相似度时,为防止点积计算结果过大,选取缩放点积的方法对其进行调节,即在点积计算后除以尺度标度,其中dk为词向量维度;之后对相似度值归一化为概率分布,其中,并且∈[0,1] ;将权重向量再乘以Value 后再将各向量进行相加,得到最终的Attention值。其公式如式(3)所示。

图3 自注意力机制基本模型结构Fig.3 The structure of self-attention mechanism

其中,Q为Query;K为Key;V为Value。Q,K,V3 个矩阵均是文本词向量矩阵进行线性变化得到的,其公式(4)、公式(5)和公式(6)如下,其中Q'=K'=V'。
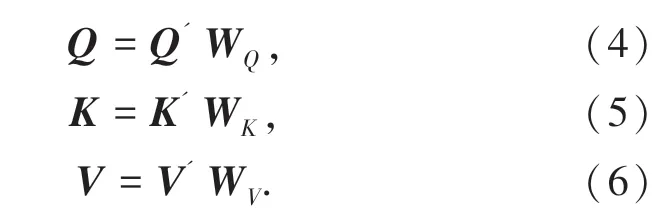
多头自注意力机制的基本模型结构如图4 所示,其本质是构造多个不同自注意力机制,在对不同的注意力机制计算得到结果后,将结果进行拼接,通过线性层的转化得到最终的注意力值,计算公式如式(7)所示。的注意力结果;W*是权重矩阵;b*为偏置。为使
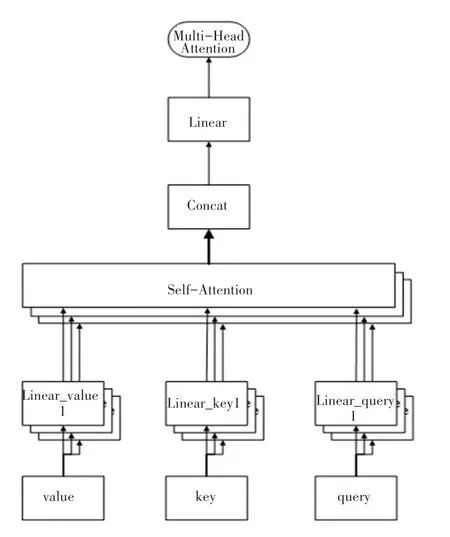
图4 多头注意力机制基本模型结构Fig.4 The structure of multi-head Attention mechanism

其中,headi表示多头自注意力机制的第i个头每个头都有各自的侧重点,每个自注意力机制的输入需不同,headi计算公式(8)所示。
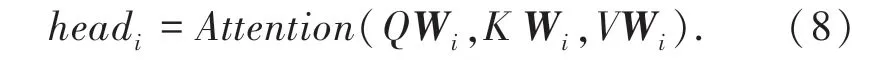
其中,Wi为第i个头计算所需的权重矩阵,不同的头进行线性变换所使用的权重矩阵不同,从而使注意力更为广泛。
2.3 文档聚合器算法
文档聚合器中使用的方法在自注意力机制的基础上进行改进,在式(3)Self-Attention 中计算Query时所使用并非法条信息,而是使用被告人基本信息和案件事实描述的上下文向量,由式(9)经线性变化得到。Query 的计算方法如式(10)所示。

其中,dp为被告人基本信息向量表示,df为案件事实描述向量表示。
3 实验
3.1 实验数据
文本中实验数据均爬取自中国裁判文书网(http:/ /wenshu.court.gov.cn/),本文主要爬取关于故意伤害罪有关裁判文书一审判决书,其中北京市11 003 条,湖北省10 956 条,河南省12 955 条,山东省11 692条。裁判文书格式较为固定,如图5 所示,方便对裁判文书中被告人基本信息、案件事实描述以及案件判决中罪名、所涉及《中华人民共和国刑法》法条以及刑期进行信息提取。

图5 判决文书示例Fig.5 The example of judgment document
3.2 实验结果与分析
3.2.1 部分参数调节
(1)法条提取器参数调节:使用SVM 进行刑期提取的实验评判结果见表1,其中刑期预测误差采用平均绝对误差(MAE)进行衡量。由实验结果可知,随着法条提取条数的增加,法条的召回率逐渐增加,即分类器对正确标签识别率增加。考虑到召回率增加到一定程度会使刑期预测的误差增大,且模型的训练时间增加,本文中选取7为法条提取数量;
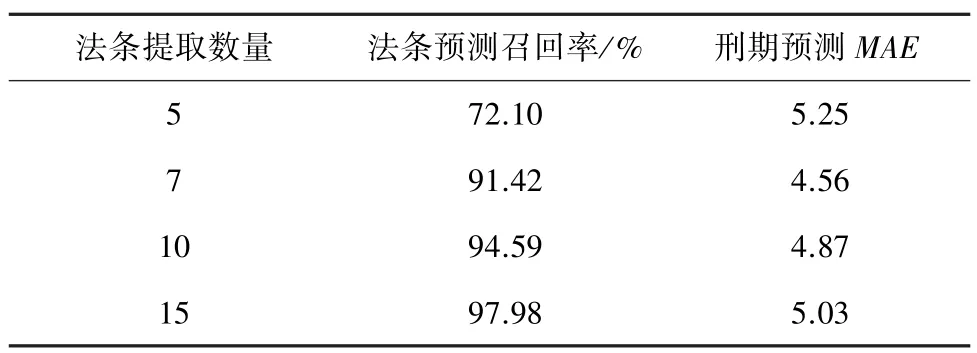
表1 法条提取数量对比实验结果Tab.1 Comparative experiment on the number of law strips extracted
(2)文档编码器参数调节:实验结果见表2,其中刑期预测误差采用平均绝对误差(MAE)进行衡量。由此可见,其实验与理论相一致,刑期预测的误差随着头数量的增多而有一定程度的增加,但到达一定程度后会呈现下降趋势,且头的数量与每一轮的训练时间成正比。

表2 多头注意力机制中头的数量对比实验Tab.2 The comparative experiment on the number of heads in the multi-head attention mechanism
3.2.2 刑期预测
本文中使用的实验基线模型有以下几个:
(1)LSTM-Linear:LSTM-Linear 模型以LSTM网络对文本进行向量化表示,最后通过全连接层对刑期进行预测;
(2)BiLSTM-Linear:考虑到文本中某一词语不仅与前文有关,后续文本同样对其有所影响,因此采用Bi-LSTM 模型对文本进行向量化表示,更好的学习到全文特征,之后再采用全连接层对刑期进行预测;
(3)Fact_Law_Info_NN:Fact_Law_Info_NN 模型即基于多通道自注意力机制的刑事案件量刑模型;
(4)Fact_Law_NN:为了验证本文中加入被告人基本信息的有效性,Fact_Law_NN 模型在Fact_Law_Info_NN 模型的基础上减少被告人基本信息通道,其余结构与参数不变,进行刑期预测。
本文中所采用的评价指标有以下几种,其中y为预测值,为真实值:
(1)平均绝对误差(MAE),式(11)。

(2)对称平均绝对百分比误差(SMAPE),式(12)。
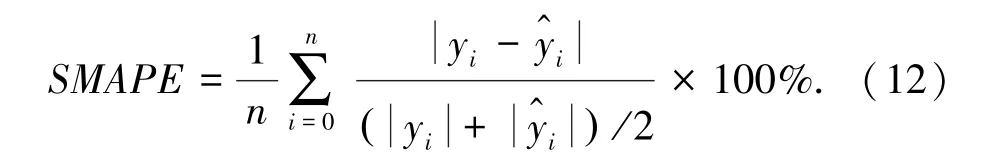
(3)精准匹配率(Exact Match,EM),预测值和真实值相等的数量占总数量的百分比,∑()为真实值与预测值相等的数量,式(13)。

(4)ACC_p%:预测值与真实值误差在p%以内的比值,式(14)。其中,∑((y≥(1-p%) )∧(y≤(1+p%) ))为预测值y∈[(1-p%),(1+p%) ]的数量,本文中选取p=10、p=20 以及p=30 这3 个值。

实验结果见表3。从实验结果可见,MAE在Fact_Law_Info_NN 模型上的结果最好,在ACC_10%指标上提升了近5%,Fact_Law_Info_NN 的精准匹配率同样在各个模型中脱颖而出。综合来看,Fact_Law_Info_NN 模型在刑期预测任务上具有最好的表现效果。
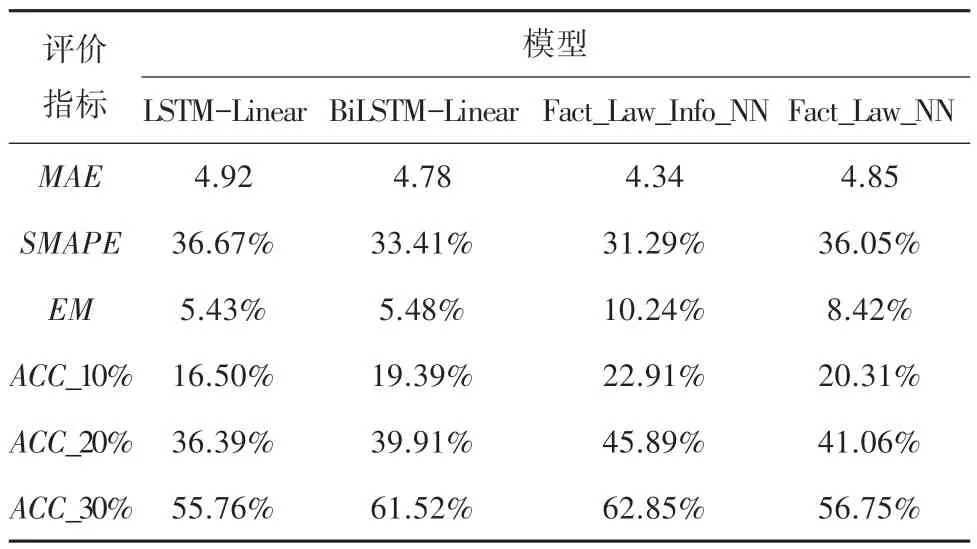
表3 实验结果Tab.3 The results of experimental
为了考察不同阶段刑期预测的情况,现将刑期分为以下几段:(1)0~6 个月;(2)6~12 个月;(3)12~36 个月;(4)36~120 个月;(5)120 个月以上。在Fact_Law_Info_NN 模型上对其进行各个阶段准确率的实验。其计算方式如式(15)所示。

其中,y为预测值;为真实值;Count(y∈[a,b))为y取值在区间[a,b)的个数。实验结果如图6 所示。
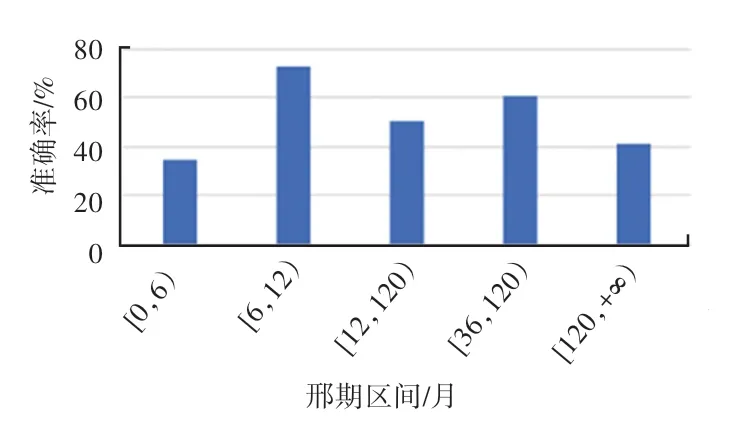
图6 刑期分段准确率Fig.6 Accuracy rate of sentence
由实验结果可见,刑期在[6,12)和[36,120)区间的准确率较高,其主要原因如下:
(1)刑期较低的案件其案件较为简单,所犯罪行较轻,此时认罪态度、被害人谅解程度对其影响较大,且法官存在自由裁量权。除此之外,部分人为因素也会导致对于相似案件的判决差别较大;
(2)刑期较高的案件,往往较为复杂,对于案件的判决影响因素较多,因此相较于中间阶段的刑期准确率较低。
考虑到不同地方法院对案件的判决具有细微差别的量刑方法,因此,将不同省份的数据分别单独提取并采用Fact_Law_Info_NN 模型进行训练,实验结果见表4。由实验结果可见,各个省份的准确率均不同,但大多低于全数据集的准确率,其原因主要有以下两点:

表4 各省份实验结果Tab.4 Experimental results of different provinces
(1)不同的省份在刑事案件量刑中均依据《中华人民共和国刑法》,但是不同地方根据当地实际情况对其在法定范围内进行调整。同时,法官具有一定的自由裁量权,因此导致不同地方对相似案件的量刑有所不同;
(2)各个省份的训练数据集较少,当训练迭代一定轮次后,出现过拟合现象,且此现象的出现较训练全数据集更早,因此其准确率不如全数据集的准确率高。
4 结束语
本文围绕刑事案件的辅助量刑进行研究,提出基于多通道自注意力机制的刑事案件辅助量刑模型,通过对被告人基本信息、案件事实描述以及法律法规的深层次学习,将其结合表示,从而对刑期进行预测。在实验验证中,本文所提出模型在MAE、SMAPE、EM以及ACC_10%等测量指标上均具有优越性。在MAE指标上,基于多通道自注意力机制的刑事案件辅助判决模型达到最优,其将误差降低至4.34,在ACC_10%等指标上,该模型相较于其他模型有所提升。在此基础上,将刑期进行分段,评估不同阶段刑期预测的准确率。同时,本文将各个省份的数据分别进行训练,以验证不同省份数据对于该模型的灵敏度影响。
