二次文本差异化的失配问题及其改进算法
2021-12-17公鑫杨春花
公鑫,杨春花
(齐鲁工业大学(山东省科学院)计算机科学与技术学院,济南 250300)
0 引言
现代大型软件的开发一般基于版本管理系统由多人协作完成,开发者每天将变更的代码提交到软件仓库中,而阅读和理解代码变更则成为代码评审以及日常开发和维护工作的基础[1-2]。
当前对代码变更的审阅一般在文本差异化分析(textual code differencing)工具提供的Hunk 集上进行。例如,图1 是典型的文本差异化分析工具GNUDiff 返回的一个Hunk 示例。一个Hunk 由一段连续的被删除(-)和插入(+)的行以及前后1~3 个上下文行构成。一个Hunk 集构成了源代码修改前后的代码变更,变更审阅者只需要查看这些Hunk,就可以知道代码哪里发生了什么改变,不需要人工对比2 个版本的源代码,提高了代码变更的理解效率。
对于复杂的变更,以行为单位的Hunk 结果不能展现Hunk 内部的具体变化。为此,许多工具如Kdiff3 和Beyond Compare 4、GitHub Diff等对Hunk内部的删除行和添加行之间进行二次差异化分析,从而获得细化的变更结果。图2 是Beyond Compare 4 对图1 的Hunk 进行二次差异化分析的结果,该结果展示在并排(side-by-side)窗口中,其中发生变化的行和单词(Token)进行了加亮显示。后文均默认新版本为右侧文本,老版本为左侧文本。Hunk 内的二次差异化分析方便用户快速理解Hunk 内行的具体变化,但是当前的二次差异化分析工具得出的结果存在失配现象,主要体现为行之间的失配和一个完整Token 的拆分现象。根据图2 的展示,老版本(左)的132~134 行被分析为与新版本(右)中第161~163行匹配对应;而新版本(右)中“Constraints”等单词(Token)的部分字符被分析为差异文本。前者是一种行失配,因为事实上老版本(左)的132~134 行应该与新版本(右)中第161~162 行相似性匹配,这种匹配体现了对该变量声明语句的编程风格的变化。

图1 Hunk 例子Fig.1 Hunk example

图2 Beyond Compare 4 分析结果Fig.2 Beyond Compare 4 analysis results
在前期研究工作中,作者发现这种失配现象在许多工具中都或多或少的存在,由于这种失配现象造成分析的结果不能反映事实上的代码变更,从而会误导代码的理解。为了克服该问题,本文在对该失配现象进行调查和分析的基础上,提出了一个对其进行克服的算法,并将该算法进行了实现和验证。
1 国内外研究现状
代码差异化分析是理解代码变更的基础,通过比较源代码修改前后2 个版本,获得变化了的代码。代码差异化分析主要分为2 类:文本差异化和树差异化。
文本差异化分析算法将源代码看成一个字符串,因此代码修改前后2 个版本之间的比较就变成了2 个字符串间的比较,一般基于最长公共子序列算法实现[3-4]。最经典的文本差异化算法是GNUDiff,目前各种版本管理系统如Git、SVN 和客户端管理工具source tree、以及eclipse等IDE 的External Compare1 插件中集成的diff 工具或窗口基本都基于该算法。其它典型的文本差异化分析方法包括LDiff、LH Diff、JSync等,这些方法返回基于文本行的变更,以Hunk为单位返回。正如Kdiff3、Beyonce Compared 4等工具提供对Hunk 内的二次差异化分析,获得Hunk 内部的差异文本。文本差异化分析算法可以分析各种类型的源代码文件,而且效率高,因此在实践中被广泛采用[5-6]。
树差异化分析算法,将2 个版本的源代码分别进行语法分析形成抽象语法树(AST),通过对比2棵AST 之间的不同,输出变动的结点[7-8]。最著名的算法是Change Distiller,还存在算法GumTree、CLDIFF、MTDiff、Diff/TS 和IJM 支持对移动代码的差异检测,而CSLICER 和RTED 不支持对移动代码差异检测,这些树差异算法可以输出语法意义上的代码变更集,但是由于相比文本差异化算法来讲效率低,而且一般针对特定的开发语言,因此在实践中没有被广泛采用。
为此,一些工具对Hunk 内部进行二次差异化分析,将Hunk 内部删除行和添加行之间进行相似性比较,获得细化的差异化结果。例如,针对图1 的Hunk,Beyonce Compared 4 对其进行二次分析,返回如图2 的差异结果。但是这些二次差异化分析工具返回的结果存在许多不合理的现象,主要表现为行失配和单词(Token)失配,前者指语法上相似的语句行之间的不匹配,后者由于单词没有作为基本单位进行差异化分析造成的一个或多个单词的内部子串作为差异化结果输出-即Token 被拆分的现象,如图2 所示。
这两种失配现象在大多数对Hunk 进行二次差异化分析的工具中普遍存在,给变更理解者造成不好的体验,同时容易误导给出错误的变更结果。
因此,为了克服此现象,本文提出基于Token(单词)的Hunk 内二次差异化分析算法,以Token为基本单位,进行语句行间的相似性匹配以及相似行内的Token 差异分析。该算法已实现,并在5 个开源项目进行了验证。
2 二次差异化分析中的失配问题
2.1 失配问题的占比
为了查清失配问题在二次差异化分析中的分布,从前期工作中一直采用的数据集中随机选取了部分提交版本,分别利用典型的二次差异化分析工具Kdiff3、Beyonce Compared 4 对其分析,人工对其结果中的失配情况进行分析。
数据集是由5 个开源项目组成,分别从各个项目的有效文件中各随机抽取100 条,共500 条数据,每条数据为一文件的某2 个版本。这些数据分别利用工具Kdiff3、Beyonce Compared 4 分析后,人工判断其差异结果,具体分析结果如图3 所示。在Kdiff3 和Beyonce Compared 4 工具对该数据集分析结果中,均有50%以上的结果存在错误,其中由于编程风格等原因造成的语句失配与由于Token 部分差异而造成的Token 失配所占比重尤为突出,可见这些问题在现有工具中是普遍存在的,所以本文的研究是有意义的,同时该数据集用来验证本文算法及工具是有效的。

图3 Kdiff3、Beyond Compare 4 差异分析情况Fig.3 Kdiff3、Beyond Compare 4 difference analysis
2.2 问题分析
图2 所示是对图1 所示的Hunk 应用Beyond Compare 4 得到的差异结果。从该结果可以看出,老版本(左)的第132~134 行被分析为与新版本(右)中第161~163 行对应,新版本160 行分析为添加行,黑色的字符为差异字符。从该结果容易看出,BeyondCompare4 是将每一个删除行和添加行分别视为一个字符串,然后应用最长公共子序列算法分别得到的差异的字符,没有体现每个删除行和添加行之间的匹配关系,也没有以单词(Token)为单位,造成了一个Token 的内部子串被部分差异化的现象。新版本的第 163 行中的最后一个单词constraints,被解释为其中的“c”和“rai”被增加。如果一个Hunk 中存在大量的修改行,且修改无规律的话,这种分析结果将会干扰变更理解,增加理解者的负担。
图4 是对图1 所示Hunk 应用KDiff3 工具得到的分析结果,可以看出,依据KDiff3 的结果,新版本(右)中的第160 行、161 行、和163 行被分析为添加行,老版本(左)中的132 和133 行被分析为删除行,老版本的第134 行被分析为修改成新版本的第162 行(即老版本的第134 行和新版本的第162 行二者相似性匹配)。然而,从理解者的角度,容易看出,老版本的第132~134 行属于一条赋值语句,其实际被修改成了新版本中第161~162 行所属的赋值语句,这种修改实际是编码风格上的改变(即仅仅涉及到回撤、Tab等分隔符的改变)。因此,KDiff3的这个结果一定程度上给理解者造成误导。

图4 Kdiff3 分析结果Fig.4 Kdiff3 analysis results
分析图4 中KDiff3 的结果,不难看出,其首先在删除的文本行和添加的文本行之间进行了相似性匹配,然后在匹配的文本行内部又进行了一次最长公共子序列算法,得到差异的子串。但是编码风格的修改,可能会使一条语句分散到连续的多个文本行中,因此这种基于文本行的行与行之间的匹配,不能保证得到的是一条完整语句之间的匹配。因此,要克服KDiff3 的这种局限性,需要首先识别一条完整语句对应的文本行,然后再进行语句间的匹配。
通过以上分析,可以看出造成行失配和Token失配现象是由于在二次差异化分析时没有实现语法意义上行与行之间的匹配,以及匹配的语句内部的差异以字符为单位而不是Token为单位进行的。针对这两点,提出基于Token 的Hunk 内二次差异化分析算法。
3 基于轻语法分析的Hunk 内二次差异化分析算法
基于对二次差异化分析方法产生原因的分析,可以发现失配问题的主要原因是在Hunk 的删除行和添加行之间未进行语法意义上行之间的相似性匹配。因此,本文提出基于轻语法分析的Hunk 内二次差异化分析算法,之所以称为轻语法分析是指针对流行编程语言如Java、C等的语句构成形式,将Hunk 中的文本行映射为语句行,并从每个语句中抽取其单词(Token)构成一个Token 序列,然后对语句所对应的Token 序列之间应用相似性匹配和最长公共子序列算法,从而实现二次差异化分析。
3.1 算法架构
算法的总体架构如图5 所示。算法的输入是一个Hunk,该Hunk 是通过GNU-Diff 算法产生Hunk集中的一个元素,由删除行、添加行和上下文行构成,输出二次差异化分析后的Hunk,包括删除的语句、添加的语句、以及更新语句内部的差异单词(即添加的Token 和删除的Token)。

图5 算法框架图Fig.5 Algorithm framework
算法主要由语句识别、语句相似性匹配和语句内部差异化3 个步骤构成。
首先,对每个删除的行和添加的行分别进行语句识别。该步骤将根据源文件所用编程语言的特点,将跨行的语句进行合并处理,必要的话需要添加相应的上下文,该步骤结束将得到一个删除语句序列和一个添加语句序列。
其次,对所有的删除语句和添加语句进行相似性匹配,得到最相似的语句对。其中,匹配的语句识别为语句更新(update);删除语句中未匹配的语句识别为语句删除(del);添加语句中未匹配的语句识别为语句添加(add)。
最后,对每个语句更新,分别产生老版本语句和新版本语句的Token 序列,对这两个Token 序列进行差异化分析,得到差异的Token。
3.2 算法
算法HunkDiff 实现了提出的算法,其描述如算法1 所示。
算法输入一个Hunkh,由3 部分构成:删除行集合L-、添加行集合L+和上下文行集合Lcontext。其中,Hunkh是GNUDiff 算法分析得到Hunk 集的一个元素。
一般地,一个差异化分析算法的输出是一个编辑操作(edit operations)集合,常见的编辑操作分为添加ADD,删除DEL,和更新update。因此,本算法的输出是差异化分析后的Hunkh',其是一个四元组:(SDEL,SADD,Supdate,Delta),其中SDEL为删除语句操作的集合;SADD为添加语句操作的集合;Supdate为更新语句操作的集合。
对于每一个语句更新操作,设为< s-,s+ >,其中s-是老版本的语句,s+是新版本的语句,则该算法会分析此语句内部的Token差异,将识别的结果存到Delta中。具体地说,Delta中的每个元素是一个三元组:(<s-,s+>,TDEL,TADD),其中<s-,s+ >是一个语句更新操作;TDEL是删除的Token集合;TADD是新增的Token集合;剩余的Token则是未修改的。
该算法的步骤解释如下:
算法首先通过辅助函数identifySentences 分别对删除行集合L-和添加行集合L+进行语句识别,根据源文件编程语言的特点,得到语句集合S-和S+;
其次,对集合S-和S+中语句逐一进行相似性匹配,得到集合SDEL、SADD和Supdate。相似性匹配算法matching在算法2 中描述;
省水利厅按照水利部和省领导的指示认真组织学习《条例》,并把贯彻落实《条例》当成在浙江省实施最严格水资源管理制度的一个契机。根据杭嘉湖地区的实际情况,省水利厅组织专家和水行政主管部门负责人在大量调查研究的基础上,形成了贯彻落实《条例》的方案,于2012年2月向浙江省人民政府上报了《关于贯彻落实〈太湖流域管理条例〉意见的函》,经省政府批准后实施。
最后,对于集合Supdate中的每个语句更新操作<s-,s+>,执行语句内的差异化分析,对应于算法的第7~15 行。通过辅助函数TokenSplit 对s-和s+中的Token进行识别,得到各自的Token序列l-和l+;对序列l-和l+执行最长公共子序列算法,得到一个最长公共子串的下标序列index-和index+,其中index-代表公共子串在老版本中的下标,index+代表公共子串在新版本中的下标,具体定义如下:

从l-中抽取不在index-中的下标序列,得到老版本中的Token差异集合TDEL,该功能用辅助函数genDiffTokens(l-,index-)来实现。同理,依据index+,得到新版本中的Token差异集合TADD。因genDiffTokens 函数实现简单,在此省略其描述。
算法1HunkDiff
输入一个Hunkh=(L-,L+,Lcontext),其中L-、L+和Lcontext分别为删除、添加的文本行和上下文行。
输出二次差异化后的Hunkh'=(SDEL,SADD,Supdate,Delta),其中SDEL为删除的语句集合;SADD为添加的语句集合;Supdate为更新的语句集合;Delta包含每条语句更新内部的差异Token。

若Hunk 中删除语句行为m,添加语句行数为n,且存在最大相似语句对max(m,n);每个相似语句对必存在有限序列的字符串,即相似语句对的差异化分析为常数级;所以算法1 的时间复杂度为O(m*n*max(m,n))。
3.3 相似性匹配matching 算法的描述
算法matching 实现了语句行之间的相似性匹配,其描述如算法2 所示。
该算法输入语句行集合S-和S+,输出语句删除操作集合SDEL、语句增加操作集合SADD和语句更新操作集合Supdate。算法设置辅助变量:相似对序列Simlist,匹配标志数组Matched-和Matched+。
算法首先将S-中的每条语句与S+中的每条语句逐一进行相似性比较,将对应的语句及其相似值存入序列Simlist。相似性比较在2 条语句所对应的Token串之间进行,相似性计算采用Jaccard系数计算[9]。已知Token串l-=(t1,t2,...,tm)和l+=(t1,t2,...,tn),Jaccard值计算如式(1):

最后,语句集合S-和S+中剩余的语句分别加到SDEL和SADD中返回。
算法2matching
输入一个删除语句行集合S-和一个添加语句行集合S+。
输出语句删除操作集合SDEL,语句增加操作集合SADD,Supdate为语句更新操作集合。

3.4 示例
流行编程语言Java、C 的语句,绝大多数是以“;”、“{”或“}”为语句结束标记,辅助函数identify Sentences以此为一条语句的结束标记,对于不存在此标记的一行或多行语句,将借助上下文中的标记符。以图1 所示Hunk为例,辅助函数identify Sentences在输入该Hunk 后,首先根据java 语言的语句特点,将以“;”、“{”或“}”结束标记符结尾的语句行划分记录为一条语句,使得由于个人编程风格等原因而跨行的语句,在差异分析时能够完整的参与比较,可能存在无结束标记符的语句行,为此将借助上下文的语句行。得到的删除集合S-和添加集合S+,分别记录一条语句{<132,134>}和3 条语句{<160,160>,<161,162>,<163,163>}。
根据集合S-和S+进行语句的相似性匹配,得到相似对序列Simlist={<132,134>,<161,162>,1},由于序列Simlist内只包含了一组相似度为1 的元素,所以该Hunk不存在语句更新操作和删除操作,仅存在语句增加操作集合SADD={<160,160>,<163,163>}。
如果存在集合Supdate,会将Supdate中元素的语句s-和s+进行差异化分析,得到的基于Token 的最长公共子序列,进而得到TDEL和TADD,即得到Delta,具体结果如图6 所示。
4 算法实现与验证
4.1 算法实现
该算法采用Java 语言实现,已知源文件的2 个版本,首先通过GNU-Diff 得到Hunk 集,然后对每个Hunk 应用提出的算法,获得Hunk 的二次差异化分析结果。同时,设计和实现了一个Diff 工具HunkDiff,依托Eclipse 平台,借助于Eclipse 插件External Diff 对项目提交数据进行获取后,将提交中的源代码文件的修改采用当前的算法实现抽取结果,基于可视化框架JavaFX 设计了Diff 展示窗口对结果进行展示。
该工具对图1 的Hunk 应用提出的算法后得到的结果如图6 所示。可以看出,图6 的结果克服了行失配和Token 失配,符合变更的真实意图。相比Beyonce Compared 4 和Kdiff 3 的分析结果,HunkDiff工具通过忽略回撤符进行语句间的差异分析,避免了这种由于编写风格而产生的差异,减少了对不必要代码行的分析;同时基于Token 的语句内差异分析,使得差异分析结果更加准确,提高了代码差异分析准确率。

图6 HunkDiff 分析结果Fig.6 HunkDiff analysis results
此外,本工具为了能够更加简单、明了的展示代码差异,还对结果的展示方面做了进一步的处理,采用了All/Diff 模式,如图7 所示,该模式可选择是全文整体展示差异的模式,还是省略相同部分仅展示差异的模式。这使得差异分析结果更加准确、清晰的展示出来,极大的提高了开发者与代码评审者阅读和理解代码的能力。

图7 All/Diff 模式Fig.7 All/Diff mode
4.2 算法验证
本文随机抽取了5 个开源项目中的部分提交记录作为数据源,将提出的算法与Kdiff3、Beyonce Compared 4 的结果进行了验证和分析。
4.2.1 数据来源
表1 展示了5 个开源项目的概况。该数据集抽取自5 个开源项目的某个时间段的提交,采用MiniGit 工具构建,一直用于本课题组的差异化分析方法的研究中[10]。其中eclipseJDTCore 开源项目,这是一个针对Java 的集成开发环境。Maven 开源项目,这是一个通过信息描述来管理项目的构建、报告和文档的一个开源的管理工具。jEdit 开源项目,这是一个跨平台的文本编辑器。google-guice 是一个轻量级的依赖注入容器。folly 是一个c++组件库,包含在Facebook 上广泛使用的各种核心库组件。本文算法主要是针对java 和c++代码文件变更的分析,其中代码文件数量约为实际文件数的60%,同时去掉一些只是更改注释代码文件,有效文件约为实际文件的50%,有效提交次数也大大降低,由于一个代码文件可能提交了多次,所以本文中一个实验数据为一文件的某次提交记录。

表1 项目概况Tab.1 Project overview
4.2.2 语句相似性判断阈值的选择
在Hunk 内语句间相似对比时,通过设置语句的相似阈值,避免对不相似语句和完全相同语句的对比分析,只对较为相似的语句组进行后续的差异分析,进一步提高算法的效率。本文设相似度阈值SIM,表示语句间相似程度,阈值越大,要求的相似度程度就越高。随机的抽取开源项目中一些有效数据为实验数据,分别设置阈值SIM为0.35、0.5、0.65、0.8,得到的差异结果准确率见表2。

表2 不同阈值SIM 结果Tab.2 Different threshold SIM results
根据表2 结果,当阈值SIM为0.35时,判断语句为相似语句的标准较低,会导致一些无变更关系的语句也被判定为相似语句,造成差异误区;而当阈值SIM为0.8时,判断语句的标准较高,会使一些变更较大的语句没被判定相似语句,进而差异结果不尽合理;所以当阈值SIM为0.5时,语句间相似比较结果更加合理,差异结果的正确率为最优,因此后续实验阈值SIM为0.5。
4.2.3 实验结果
表3为Kdiff3、Beyonce Compared 4、和HunkDiff工具对5 个开源项目中各100 条有效数据的差异分析结果,工具HunkDiff 的差异分析结果的正确率平均在85%左右,相比其它工具,极大提高了差异识别的准确率。本文工具不仅较好的实现其它差异工具基本能够识别的差异问题,还较好的解决了当前存在的语句、Token 失配问题。

表3 Kdiff3、Beyonce Compared 4、HunkDiff 差异分析结果Tab.3 Kdiff3、Beyonce Compared 4、HunkDiff analysis results
对于上述Kdiff3、Beyonce Compared 4 工具差异分析准确的数据,HunkDiff 工具基本也能实现对其差异分析;对差异分析不准确的数据,应用提出的算法工具对其进行了分析,分析结果见表4。对当前工具差异不准确数据集的差异分析正确率平均为70%以上,有效的克服了现有工具存在的差异不合理问题。
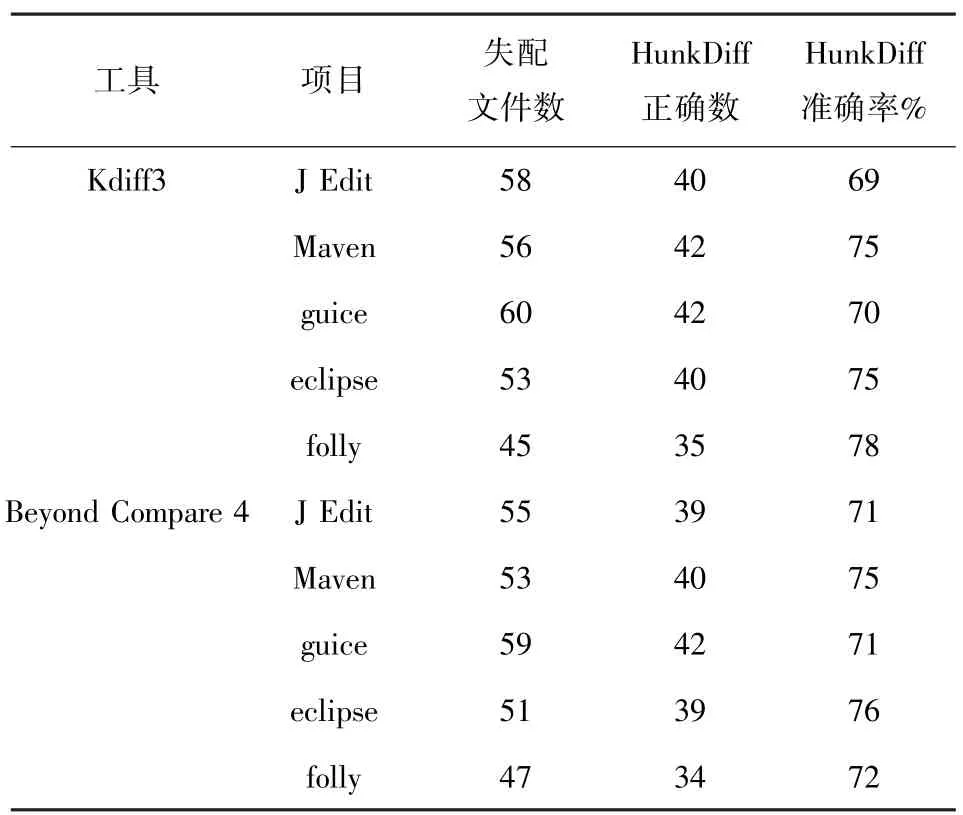
表4 HunkDiff 分析结果Tab.4 HunkDiff analysis results
5 结束语
针对当前Hunk 内二次差异化算法存在的失配问题,提出了一种基于Token 的二次差异化算法,通过文本行向语句行的映射和语句间的相似性匹配,解决了语句失配的现象。对于更新的语句,采用基于Token 的最长公共子序列算法,获取内部差异的Token 集,克服了Token 被拆分的问题。该算法当前采用Java 语言实现,并设计了一个HunkDiff 工具对结果进行展示。通过在5 个开源项目的数据集上对该工具进行了实验验证,表明了该差异分析算法的可行性。该工具能够帮助软件开发者与测试者分析代码,及时发现并解决一定的软件开发、维护以及重构活动等问题。本文算法还存在得到的Hunk 不准确和多个最长公共子序列的部分问题,后续工作需进一步解决这方面问题,继续提高差异分析准确率,推广其到其他语言开源项目中的差异分析。
