COVID-DeepNet:Hybrid Multimodal Deep Learning System for Improving COVID-19 Pneumonia Detection in Chest X-ray Images
2021-12-16AlWaisyMazinAbedMohammedShumoosAlFahdawiMaashiBegonyaGarciaZapirainKarrarHameedAbdulkareemMostafaNallapaneniManojKumarandDacNhuongLe
A.S.Al-Waisy,Mazin Abed Mohammed,Shumoos Al-Fahdawi,M.S.Maashi,Begonya Garcia-Zapirain,Karrar Hameed Abdulkareem,S.A.Mostafa,Nallapaneni Manoj Kumar and Dac-Nhuong Le
1College of Computer Science and Information Technology,University of Anbar,Anbar,31001,Iraq
2College of Computer and Information Sciences,King Saud University,Riyadh,11451,Saudi Arabia
3eVIDA Lab,University of Deusto.Avda/Universidades,Bilbao,24.48007,Spain
4College of Agriculture,Al-Muthanna University,Samawah,66001,Iraq
5Faculty of Computer Science and Information Technology,University Tun Hussein Onn Malaysia,Johor,86400,Malaysia
6School of Energy and Environment,City University of Hong Kong,Kowloon,83,Hong Kong
7Institute of Research and Development,Duy Tan University,Danang,550000,Vietnam
8Faculty of Information Technology,Duy Tan University,Danang,550000,Vietnam
Abstract:Coronavirus(COVID-19)epidemic outbreak has devastating effects on daily lives and healthcare systems worldwide.This newly recognized virus is highly transmissible,and no clinically approved vaccine or antiviral medicine is currently available.Early diagnosis of infected patients through effective screening is needed to control the rapid spread of this virus.Chest radiography imaging is an effective diagnosis tool for COVID-19 virus and followup.Here,a novel hybrid multimodal deep learning system for identifying COVID-19 virus in chest X-ray (CX-R) images is developed and termed as the COVID-DeepNet system to aid expert radiologists in rapid and accurate image interpretation.First,Contrast-Limited Adaptive Histogram Equalization (CLAHE) and Butterworth bandpass filter were applied to enhance the contrast and eliminate the noise in CX-R images,respectively.Results from two different deep learning approaches based on the incorporation of a deep belief network and a convolutional deep belief network trained from scratch using a large-scale dataset were then fused.Parallel architecture,which provides radiologists a high degree of confidence to distinguish healthy and COVID-19 infected people,was considered.The proposed COVID-DeepNet system can correctly and accurately diagnose patients with COVID-19 with a detection accuracy rate of 99.93%,sensitivity of 99.90%,specificity of 100%,precision of 100%,F1-score of 99.93%,MSE of 0.021%,and RMSE of 0.016%in a large-scale dataset.This system shows efficiency and accuracy and can be used in a real clinical center for the early diagnosis of COVID-19 virus and treatment follow-up with less than 3 s per image to make the final decision.
Keywords:Coronavirus epidemic;deep learning;deep belief network;convolutional deep belief network;chest radiography imaging
1 Introduction
COVID-19 epidemic outbreak has devastating effects on daily lives and healthcare systems worldwide.This newly recognized virus is highly transmissible,and a clinically approved vaccine or antiviral medicine is not yet available.The first positive COVID-19 case was detected in Wuhan City in December 2019,and the disease then has rapidly spread to several cities in China and subsequently in many countries worldwide [1].The world has strived and fought to limit the spread of this epidemic.To date,the number of positive recognized COVID-19 infections in the worldwide is approximately 6,851,720 total cases,398,260 death cases,and 3,351,419 were recovered cases.Fig.1 displays the distribution of confirmed COVID-19 cases in most affected countries worldwide.The United States leads in the number of confirmed infections constituting 28.70% (1,965,912 cases) of the total confirmed cases worldwide.Similar to other flu types,COVID-19 causes respiratory diseases,and the majority of the infected people may recover without any need for special treatment.The elderly and those with chronic diseases,such as diabetes chronic respiratory disease,cancer identification,chronic respiratory disease,and cardiovascular disease,are highly likely to experience a dangerous infection [2].The most common critical symptoms are fever,dry cough,tiredness,headache,sore throat,sneezing,vomiting,dyspnea,myalgia,nasal congestion,and rhinorrhea.Patients with severe COVID-19 infection suffer from critical complications,such as cardiac injury,pulmonary edema,septic shock,and acute kidney injury [3,4].
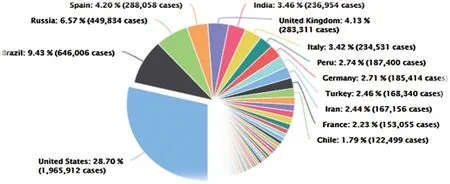
Figure 1:Global distribution of confirmed COVID-19 cases (6 June 2020) [5]
A key factor in confronting the COVID-19 epidemic is the early diagnosis and separation of infected patients.An efficient screening technique for COVID-19 infected patients can substantially limit the rapid spread of the COVID-19 virus.Several screening methods,such as reverse transcriptase-polymerase chain reaction (RT-PCR) technique,are employed to reveal the onset symptoms of the COVID-19 virus [6].Although RT-PCR is commonly used for SARS-CoV-2 diagnosis,this process is tedious and time consuming and requires user interaction.The reliability and validity of radiography imaging techniques (e.g.,images of computed tomography or CX-R) for early COVID-19 diagnosis have been established to overcome RT-PCR restrictions [7].Radiography imaging can display a wide degree of unpredictable ground-glass opacities that rapidly advance after any infection and is therefore one of the most critical biomedical imaging techniques in hospitals to detect chest abnormalities and COVID-19 infection.However,the main problem of using chest radiograph imaging is that reading and interpreting the images require a long time [8].With COVID-19 virus identified as a pandemic,the number of patients who require a chest X-ray (CX-R) image examination has dramatically increased and exceeded the low number of available expert radiologists.As a result,the pressure on healthcare systems and radiologists is increased,disease diagnosis is delayed,patient’s treatment and follow up are affected,and virus transmission likely occurs.Hence,the real-time and fully automated interpretation of radiography images is needed to help radiologists and clinicians in precisely detecting the COVID-19 infection.Computer-aided diagnostic systems based on deep learning approaches can be employed to assists radiologists to rapidly and correctly interpret and understand the details in the chest radiography images and overcome the limitations of the adopted imaging acquisition techniques [9,10].This paper proposes a novel hybrid deep learning system termed as a COVIDDeepNet system for detecting COVID-19 pneumonia in CX-R images by using two discriminative deep learning approaches.This system comprises four main steps:image pre-processing,feature extraction,image classification,and fusion.The contrast of CX-R image is initially enhanced,and the noise level is reduced using CLAHE and Butterworth bandpass filter.In feature extraction and classification,two distinctive deep learning approaches based on DBN and CDBN are employed for the automated COVID-19 infection detection in CX-R images.Finally,the results obtained from these two approaches are fused to make the final decision.The primary contributions of this research are outlined as follows:
1.A novel hybrid COVID-19 detection system is proposed and termed as a COVID-DeepNet system to automatically differentiate between healthy and COVID-19 infected subjects by using CX-R images with two successful modern deep learning methods (e.g.,DBN and CDBN).To the authors’best knowledge,this work is the first to examine the possibility of using DBN and CDBN in a unified system to detect COVID-19 infection by learning high discriminative feature representations from CX-R images.
2.Different from most of the existing systems that make the final prediction using only one trained model,the proposed COVID-DeepNet system makes the final prediction by fusing the results obtained from two different deep learning approaches trained from scratch using a large-scale dataset.Parallel architecture,which provides radiologists a high degree of confidence to distinguish between healthy and COVID-19 infected subjects,is considered.
3.A large-scale CX-R images dataset is created and termed as the COVID19-vs.-Normal dataset.To the authors’best knowledge,this dataset has the largest size,contains the largest number of CX-R images with confirmed COVID-19 infection among those currently available in the public domain.
4.The possibility of reducing the computational complexity and improving the generalization of the deep learning is further validated and examined using pre-processed CX-R images as input data to produce useful features representations during the training phase instead of using predefined features of raw images data.
5.A distinctive training procedure supported with various sets of training policies (e.g.,data augmentation,AdaGrad algorithm,and dropout method) is also adopted to increase the generalization ability of the proposed COVID-DeepNet system and avoid overfitting.
6.The efficiency and usefulness of the proposed COVID-DeepNet system are established along with its possible clinical application for early COVID-19 diagnosis with less than 2 s per image to obtain the required results.
The remainder of this paper is divided into five sections:Section 2 provides a brief overview of the current related works,Section 3 discusses the strategy used to create the COVID-19 dataset and the implementation details of the COVID-DeepNet system,Section 4 presents the experimental results,and Section 5 displays the conclusion and future work.
2 Related Works
Deep learning has been effectively applied in the medical field with promising results and remarkable performance compared with human-level action in various challenging tasks,such as breast cancer detection [11],skin cancer classification [12],nasopharyngeal carcinoma identification [13,14],brain disease classification [15],lung segmentation [16],and pneumonia detection in CX-R images [17].Several medical imaging tools using deep learning methods have also been established to help radiologists and clinicians in early COVID-19 detection,treatment,and follow-up investigation [18].For instance,Wang et al.[19]developed a tailored model termed as COVID-Net to detect COVID-19 cases using CX-R images by classifying the input image into one of three different classes (e.g.,normal,non-COVID19,and COVID19).This model has the highest accuracy rate of 92.4% as measured using a dataset containing 16,756 CX-R images collected from two different datasets (COVID-19 CX-R dataset provided in [20]and RSNA Pneumonia Detection Challenge dataset [21]).Hemdan et al.[22]proposed a deep learning system named as COVIDXNet to identify COVID-19 infection in CX-R images.A comparative study among seven deep learning approaches (e.g.,VGG19,ResNetV2,DenseNet201,Xception,MobileNetV2 Inception,and InceptionV3) was conducted using a small dataset of 50 images (e.g.,with 25 images of positive COVID-19 infection).The best performance was obtained by pre-trained DenseNet201with an accuracy rate of 91%.Narin et al.[23]also conducted another comparison study among three different deep CNN-based models (e.g.,InceptionV3,ResNet50,and Inception-ResNetV2)by using a dataset consisting of hundred CX-R images,half of which are infected COVID-19 cases.The best performance was achieved using the pre-trained ResNet50 model with an accuracy rate of 98%.Mohammed et al.[24]proposed a novel benchmarking method for choosing the best COVID-19 detection model by using the Entropy and TOPSIS method and established a decision matrix of 10 evaluation criteria and 12 machine learning classifiers for identifying COVID-19 infection in 50 CX-R images.The highest closeness coefficient of 98.99% was achieved by the linear SVM classifier.Kassani et al.[25]trained several CNN models as feature descriptors to encode the input image into low dimensional feature vectors,which are then processed by different classifiers to aggregate solutions.The performance was verified using the same dataset presented in [20].The highest accuracy rate was 99% using the pre-trained DenseNet121 model as a feature descriptor and the Bagging tree classifier.Zhang et al.[26]used a pre-trained ResNet-18 model as a feature descriptor to extract useful feature representations from the CX-R image.These extracted features are then fed to a multi-layer perception to make the final decision.The highest accuracy rate of 96.00% was obtained using a dataset of 100 images captured from 70 patients.Many researchers have attempted to detect COVID-19 infection in CX-R or CT images using various deep learning approaches [27-31].A review on COVID 19 detection and diagnosis systems based on CX-R images revealed some limitations that need to be investigated.First,most of the existing systems have been evaluated using small X-ray datasets with a few numbers of positive COVID-19 cases.The dataset sizes are not sufficient to reveal the real performance of the proposed approaches.Second,although several studies have produced high accuracy rates using pre-trained models via transfer learning,minimal attention has been given to building and training a custom deep learning model from scratch mainly due to the unavailability of a large dataset containing sufficient number of CX-R images with confirmed COVID-19 infection.In addition,changing the architecture of pre-trained models by removing/adding some layers to obtain an optimal model architecture with high confidence is difficult.Finally,most of these studies only focused on training deep learning models on the top of raw images rather than preprocessed images,thus limiting the generalization ability of the last trained model.To overcome these limitations,the present work proposed a novel hybrid COVID-19 detection system termed as COVID-DeepNet system to automatically differentiate between healthy and COVID-19 infected subjects by using CX-R images under two successful modern deep learning approaches (e.g.,DBN and CDBN).The proposed COVID-DeepNet system is trained from scratch using a large-scale and challenging dataset termed as the COVID19-vs.-Normal dataset.
3 Proposed COVID-DeepNet System
As depicted in Fig.2,a novel hybrid COVID19 detection system was proposed and termed as a COVID-DeepNet system to learn discriminative and useful feature representations by training two discriminative deep learning approaches (DBN and CDBN) over the pre-processed CX-R images.First,the adopted procedure to create the CX-R dataset was briefly described.Implementation details of the proposed approaches were then explained,such as the proposed image pre-processing algorithm,the main architecture,and training methodology of the proposed deep learning approaches (e.g.,DBN and CDBN).Algorithm 1 shows the pseudo-code of the proposed COVID-DeepNet system.
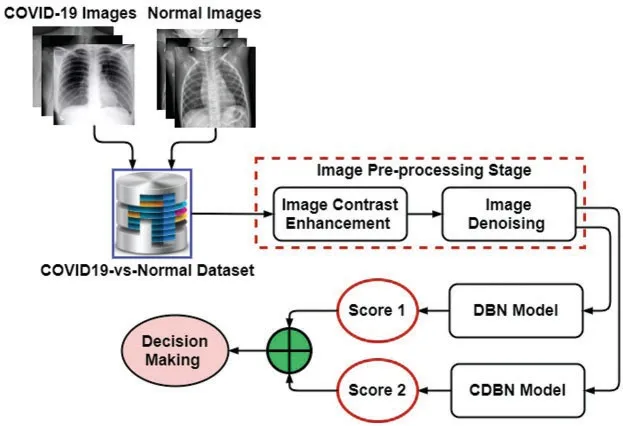
Figure 2:Block diagram of the proposed COVID-DeepNet detection system
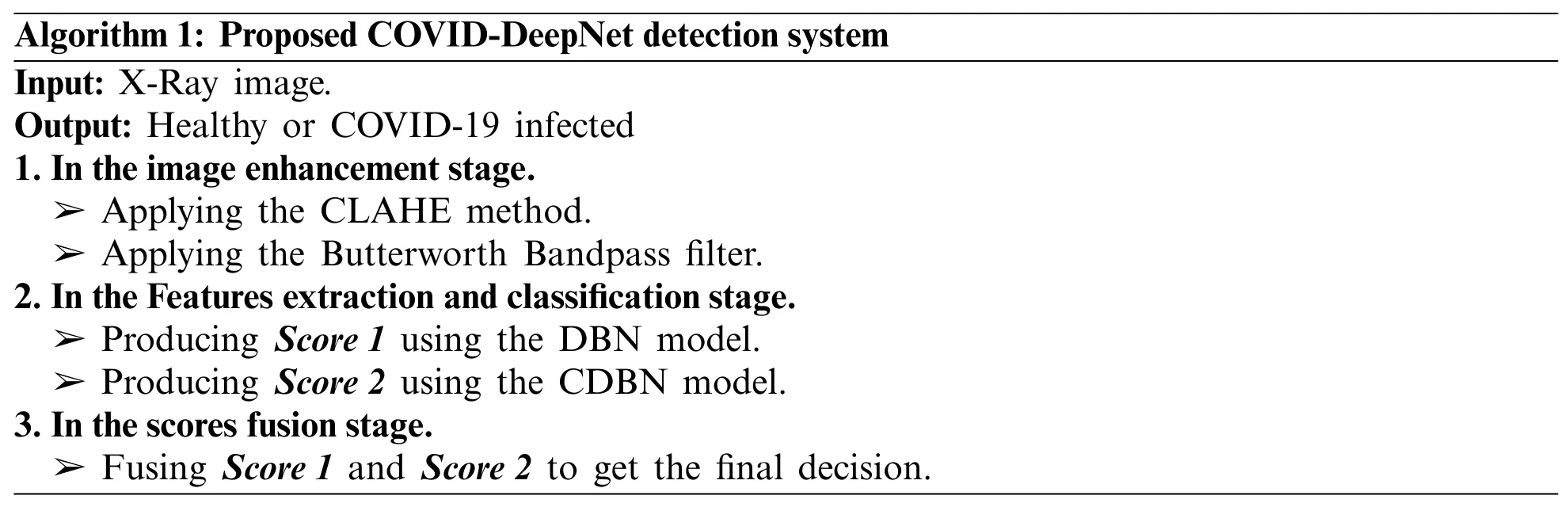
Algorithm 1:Proposed COVID-DeepNet detection system Input:X-Ray image.Output:Healthy or COVID-19 infected 1.In the image enhancement stage.➢Applying the CLAHE method.➢Applying the Butterworth Bandpass filter.2.In the Features extraction and classification stage.➢Producing Score 1 using the DBN model.➢Producing Score 2 using the CDBN model.3.In the scores fusion stage.➢Fusing Score 1 and Score 2 to get the final decision.
3.1 COVID19-vs.-Normal Dataset
Several CX-R images were carefully selected from different sources to create a relatively largescale COVID-19 CX-R image dataset of confirmed infected cases.This dataset was named as COVID19-vs.-Normal and then mixed with some CX-R images of normal cases for a reliable diagnosis of COVID-19 virus.The sources of the COVID19-vs.-Normal dataset are as follows:
• A set of 200 CX-R images with confirmed COVID-19 infection of Cohen’s GitHub repository [20].
• A set of 200 COVID-19 CX-R images with confirmed COVID-19 infection gathered from three different sources:Radiopaedia dataset [32],Italian Society of Medical and Interventional Radiology (SIRM) [33],and Radiological Society of North America (RSNA) [34].
• A set of 400 normal CX-R images from Kaggle’s CX-R image (Pneumonia [35]) dataset.
Samples of the COVID-19 and normal cases of the large-scale COVID-19 CX-R images are shown in Fig.3.The established COVID19-vs.-Normal dataset will have a constantly updated number of the COVID-19 cases depending on the availability of new CX-R images with confirmed COVID-19 infection and is available publicly at https://github.com/AlaaSulaiman/COVID19-vs.-Normal-dataset.Data augmentation was applied to prevent overfitting and enhance the generalization ability of the last trained model.First,the size of the original image was rescaled to(224×224) pixels,and five random image regions of size (128×128) pixels were then extracted from each image.Horizontal flip and rotation of 5 degrees (e.g.,clockwise and counter-clockwise)were then conducted for every single image in the dataset.A total of 24,000 CX-R images of size (128×128) pixels were extracted from both classes (e.g.,COVID-19 and normal images).Data augmentation was implemented after dividing the COVID19-vs.-Normal dataset into three mutually exclusive sets (e.g.,training,validation,and testing set) to avoid generating biased prediction results.
3.2 Image Pre-Processing Step
A raw CX-R image obtained by an electronic detector usually has poor quality and thus may be unsuitable for detection and diagnosis.Image enhancement methods should be applied to enhance the quality of CX-R images.Furthermore,training the DNNs on the top of preprocessed images instead of using raw images data can substantially reduce the generalization error of the DNNs and their training time.Hence,an effective image enhancement procedure was proposed to enhance the CX-R image’s poor quality prior to feeding to the proposed approaches(e.g.,DBN and CDBN).First,the small details,textures,and low contrast of the CX-R image was enhanced through adaptive contrast enhancement based on CLAHE [36].CLAHE is different from the original histogram equalization method that computes several histograms (e.g.,each one corresponding to a distinct part of an image) to redistribute the lightness values of the input image,as depicted in Fig.4b.Hence,this method can improve the image local contrast and enhance the visibility of the edges and curves in each part of an image.Second,the Butterworth bandpass filter was employed to reduce the noise in the image produced from the previous step,as shown in Fig.4c.The Butterworth Bandpass filter was calculated by multiplying the low and high pass filters as follows:

whereFLandFHare the cut frequencies of the low and high pass filters set as 15 and 30,respectively;n=3 is the filter order;and isF(u,v)the distance from the origin.
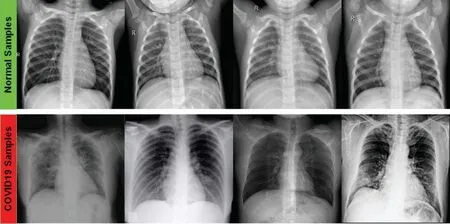
Figure 3:An example of positive COVID-19 case versus negative COVID-19 case obtained from the created dataset of COVID19 and normal CX-R images
3.3 Deep Learning for COVID-19 Detection
A hybrid deep learning detection system based on the incorporation of two discriminative deep learning approaches (e.g.,DBN and CDBN) was proposed to detect COVID-19 infection in CX-R images.To the authors’ best knowledge,the possibility of using DBN and CDBN in a unified system to detect the COVID-19 virus in the CX-R images has not been previously investigated.Fig.2 shows that the enhanced image was fed into the visible units of the proposed deep learning approaches to learn high-level feature representations.DBN is a new generative probabilistic model developed by Hinton et al.[37].Different from other conventional deep neural networks (DNNs),DBN has one visible layer and several hidden layers that can learn the statistical correlations of the neurons in the previous layer [38].Similar to other deep learning approaches,DBNs are directly applied to raw image data.Although DBNs have been effectively applied to solve many challenging problems (e.g.,face recognition [39]and audio classification [40]),scaling them to high dimensional images is challenging for two reasons.First,the input image with a high dimensionality can increase the complexity of the learning process and require a long-time for convergence.Second,the features learned by DBNs are highly sensitive to image translations,especially when the raw image data are assigned directly to the visible layer.This phenomenon can lead to discarding most of the fine details in the input image,thus seriously affecting their performance.As a solution,the proposed DBN model was trained on the top of pre-processed images rather than raw image data to remarkably reduce the training time and learn additional discriminative feature representations [41].Assigning pre-processed CXR images to the input layers of DBN and CDBN can remarkably improve their ability to learn essential and prominent feature representations with less time require to obtain the last trained models.As depicted in Fig.5,the main architecture of the proposed DBN is composed of stacking five RBMs as hidden layers.The first four RBMs can be viewed as non-linear features descriptors trained sequentially using the CD learning algorithm in an unsupervised greedy layerwised manner to learn a multi-layer non-linear generative model.The last RBM is a discriminative RBM (DRBM) trained as a non-linear classifier associated with SoftMax function to produce the probability distribution of each class label.DRBM comprises two layers of visible units to represent the input vector and a softmax label unit to represent the predicted class.During RBM training,the stochastic gradient descent algorithm was applied to maximize the log-likelihood of the training data.Hence,the updating rules for the weights can be defined as follows:
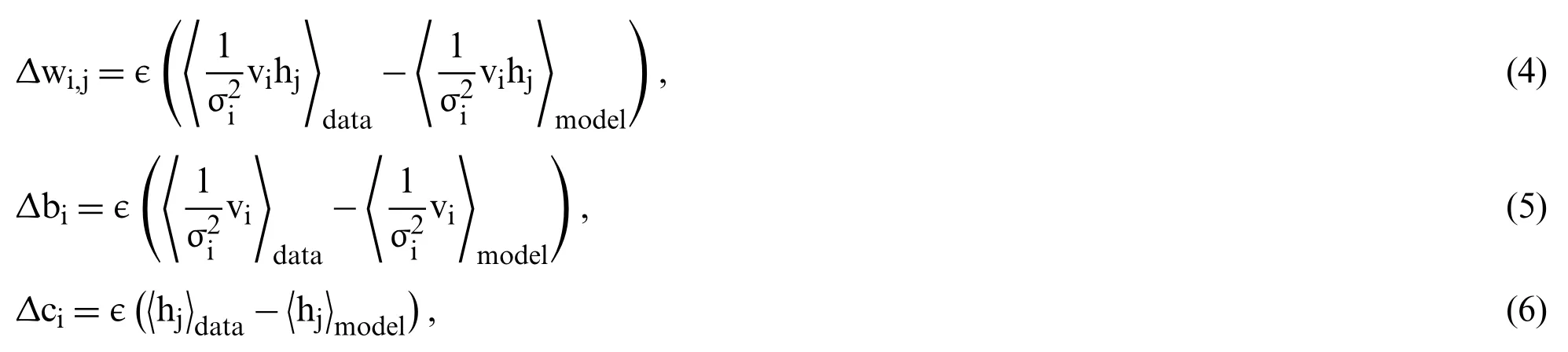
where ∊refers to the learning rate,〈·〉dataand 〈·〉modeldenote the positive stage and the negative stage,respectively.Finally,biandciand represent biases for visible and hidden units,respectively.Calculating thein Eq.(4) is diffciult.Thus,the CD algorithm [42]was used to update the parameters of a given RBM by applyingksteps Gibbs sampling from the probability distribution to compute the second term in Eq.(4).The single-step of the CD algorithm can be implemented as follows:
1.Initially,the training data are given to the visible units (vi) to compute the probabilities of the hidden units.A hidden activation (hj) vector is then sampled from the same probability distribution.
2.In the positive phase,the outer product of (vi) and (hj) is computed.
3.A reconstruction of the visible units (v′i) is sampled from (hj) withfrom which(v′i) resamples the activations of the hidden units’(h′i).(1 Gibbs sampling step).
4.In the negative phase,the outer product of (v′i) and (h′i) is computed.
5.Finally,the weights matrix and biases are updated with Eqs.(4)-(6).
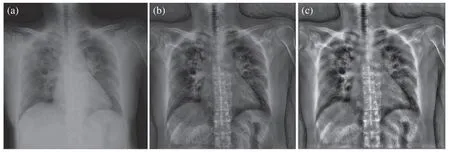
Figure 4:Proposed image enhancement procedure outputs:(a) Raw CX-R image,(b) applying the CLAHE method,and (c) applying the Butterworth Bandpass filter
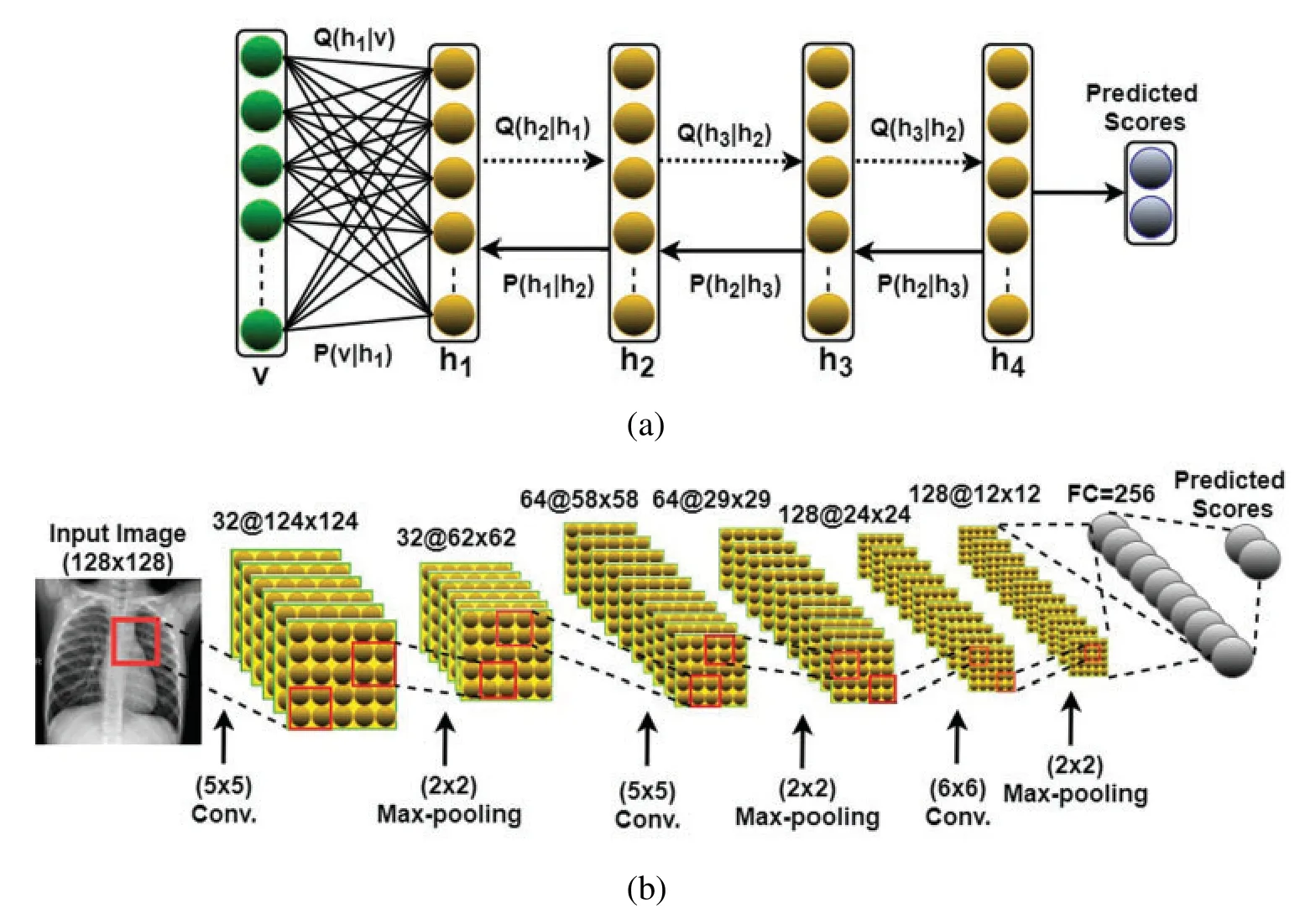
Figure 5:Main architecture of the proposed deep learning models:(a) DBN model,and(b) CDBN model
Herein,thekparameter of the CD learning algorithm was set to 1,and all the weights were randomly set with small values computed from a normal distribution of zero mean and SD of 0.02.CDBN is a hierarchical generative representation developed by Lee et al.[43]and is composed of several convolutional RBMs (CRBMs) stacked on each other as building blocks.CRBM is an expansion of the traditional RBM.Different from RBM,the weights between the visible and hidden units in the CRBM are locally shared among all positions in the input image.This scheme of sharing parameters (weights) introduces a form of translational invariance that uses the same-trained filter to detect specific useful features at different locations in an image.The proposed CDBN consists of three stacked CRBMs associated with probabilistic max pooling.CRBM uses Gaussian-valued visible units and binary-valued hidden units.The first and second CRBMs consist of 32 and 64 trainable filters (K1=32,and K2=64) of (5×5) pixels,respectively,and the last CRBM consists of 128 trainable filters (K3=128) of (6×6) pixels.The max-pooling ratio is fixed to two for each pooling layer.The output of the last CRBM is fed into one fully connected layer composed of 256 units,followed by the application of a SoftMax function to produce the probability distribution of each class label.CDBM models are highly overcomplete because each CRBM (hidden layer) has K trainable filters (e.g.,groups of units) with sizes roughly equal to that of the input image.In general,the overcomplete model runs the risk of learning trivial feature representations (e.g.,single-pixel detectors).As a solution,a sparsity penalty term was added to the objective function to obtain a small part of the fired output.In practice,the following simple update process (applied before weight updates) can be employed:

wherepis referred to as the target sparsity.In this work,the target sparsity was set as 0.005 for all the CRBMs.The proposed training methodology for DBN and CDBN models is composed of three phases:unsupervised pre-training,supervised,and fine-tuning.
1.In the unsupervised pre-training phase,the first four hidden layers (e.g.,RBMs and CRBMs) are trained using an unsupervised greedily training algorithm based on the CD algorithm to train each added hidden layer as either an RBM for DBM model or a CRBM for CRBM model.The activations produced from the first trained hidden layer acted as discriminative features extracted from the input images.These features are then assigned to the (vi) as an input to train the next hidden layer.This phase is completed when the (N−1)RBM (hidden layer) is successfully trained.After training,these (N−1) hidden layers of the model can be viewed as a feature extractor that automatically extracts the most useful and discriminative features from the raw images.The main benefit of this unsupervised greedy training algorithm is the capability to train the DBN and CDBN models by using a huge amount of unlabeled training data.
2.In the supervised phase,the last DRBM in the DBM model and the SoftMax classifier in the CDBM model are trained in a supervised manner as non-linear classifiers by using the labeled data in the training and validation sets to monitor their performance during learning.
3.Finally,the back-propagation algorithm is implemented to fine-tune the parameters of the whole DBN model in a top-down manner to achieve satisfactory predictions.
Similar to other deep learning networks,DBN and CDBN need a massive amount of training data to prevent overfitting during the training process,reduce the generalization error of the last obtained model,and achieve satisfactory predictions.Thus,simple data augmentation was implemented to artificially increase the number of training samples in the COVID19-vs.-Normal dataset (see Subsection 3.1).
3.4 Evaluation Criteria
In the prediction phase,the average values of seven quantitative performance measures,namely,detection accuracy rate (DAR),sensitivity,specificity,precision,F1-score,mean squared error (MSE),and root Mean Squared Error (RMSE) were computed to measure the accuracy and the efficiency of the proposed COVID-DeepNet model by using the testing set.These seven quantitative performance measures are calculated as follows:
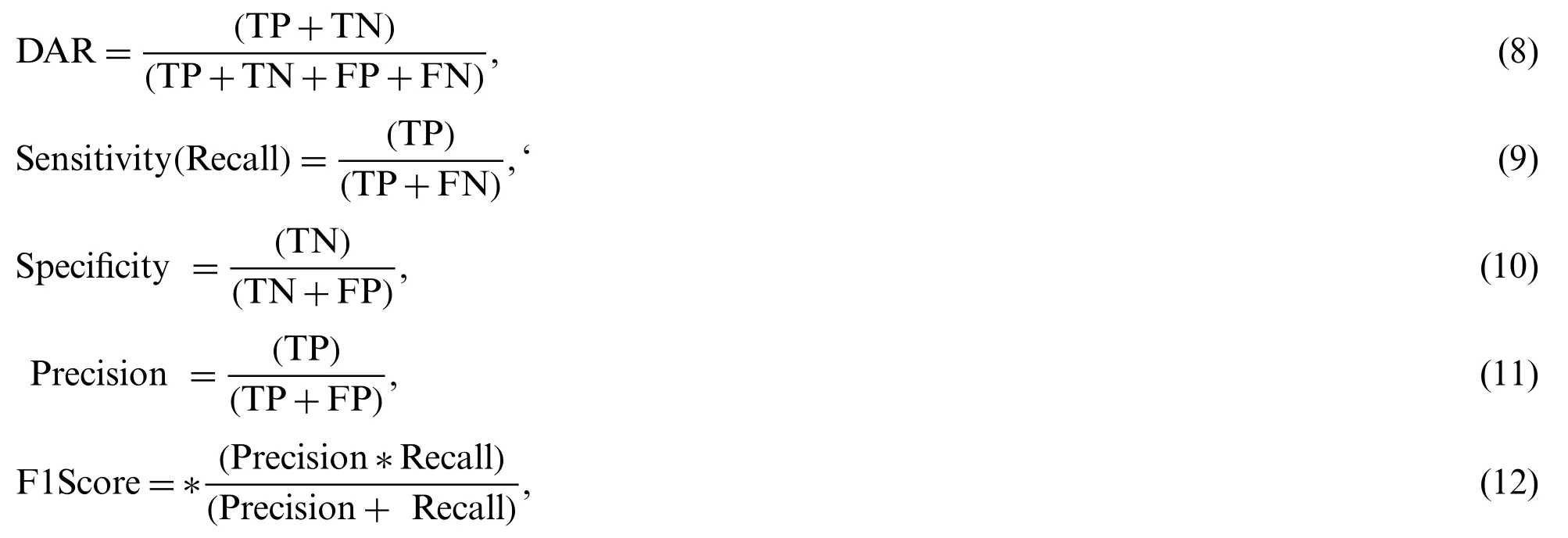
where TP,TN,FP,and FN stand for true positives,true negatives,false positives,and false negatives,respectively.

wherenrefers to the total number of data samples,Yis the vector of observed values of the variable being predicted,andis the vector ofnpredicted values.
4 Experimental Results
Several extensive experiments on COVID19-vs.-Normal dataset were conducted to reveal the effectiveness of the proposed deep learning methods (e.g.,DBN and CDBN) and their combination (e.g.,using the proposed COVID-DeepNet system) and compare their performances with the current state-of-the-art approaches.The code of the proposed COVID-DeepNet system was written to run in MATLAB R2018a and later versions and trained using Windows 10 operating system,a Core i7-4510U CPU,69 K GPU graphics card,and 24 GB of RAM.Following the proposed training methodology,all experiments were conducted using 75% randomly selected CXR images as a training set to train the proposed deep learning approaches.The remaining reset 25% images were used as a testing set to assess their generalization ability in predicting new unseen data.During learning,10% of the training set was randomly selected and employed as a validation set to assess their performance and store the weight configurations that produce the highest accuracy rate.
4.1 COVID-DeepNet Architecture and Training Details
The main architecture of the COVID-DeepNet system is based on the combined output scores produced from two discriminative deep learning methods (e.g.,DBN and CDBN).The main challenging task of using deep learning models is the huge number of structures and hyperparameters to be assessed (e.g.,number of hidden layers,filter size,number of epochs,and learning rate).Herein,several experiments were performed to find the best model’s architecture for DBN and CDBN.The influence of different values of the hyper-parameters on the performance of the proposed approaches was also analyzed.Two different training set configurations from the COVID19-vs.-Normal dataset were created and evaluated to reveal the important contribution of the proposed image enhancement procedure in guiding the learning of proposed approaches and improving their performance compared with the use of raw images as input data.The two training set configurations were as follows:(i)TrainingSet_1consists of raw images and those produced using the proposed data augmentation procedure,and (ii)TraningSet_2consists of the pre-processed and those produced using the proposed data augmentation procedure.
In DBNs and CDBMs,the values of their hyper-parameters mainly depend on each other.Furthermore,the hyper-parameters values used in a specific RBM may be affected by the hyperparameter values used in other RBMs.Thus,the hyper-parameter fine-tuning task in these two approaches requires a large cost.Therefore,a coarse search procedure was implemented to find the best hyper-parameter values.As shown in Tab.1,the proposed DBN model composed of stacking five RBMs (hidden layers) was trained in a bottom-up way using the proposed training methodology presented in (Subsection 3.3).The number of the hidden units in the first two layers was fixed to 4096 units,and the different numbers of hidden units were evaluated in the last three layers to find the best network configuration.When the unsupervised training of the first RBM(the first hidden layer) was completed,the weight matrix of the hidden layer was frozen and was used as an input data for the training of the second RBM (the second hidden layer) in the stack.With the CD learning algorithm (e.g.,one step of Gibbs sampling),the first four RBMs were trained separately in an unsupervised greedily manner.Each RBM (hidden layer) was trained for 100 epochs with a mini-batch size of 100,a weight decay value of 0.0002,a learning rate of 10−2,and a momentum value of 0.9.The weights were randomly initialized with small values computed from a normal distribution of zero mean and SD of 0.02.The last layer was trained as a non-linear DRBM classifier with SoftMax units to produce the final probability scores.The last DRBM was trained using the same hyper-parameters values of the first four RBMs.Finally,the back-propagation algorithm equipped with the dropout method was applied for the parameter fine-tuning of the whole DBN model in a top-down manner to avoid overfitting and achieve satisfactory predictions.The dropout ratio was 0.5.Initially,the whole DBN was trained in a top-down manner for 100 epochs;however,the model can be further improved by increasing the number of epochs.Therefore,the number of epochs was set to approximately 500 epochs using the early stopping procedure.As revealed in Tab.1,five DBN models were trained using two different training sets (e.g.,TrainingSet_1andTrainingSet_2),and the highest accuracy was obtained using the fourth DBN (4096-4096-3000-2048-1024) model.The training time of all the five trained models was substantially decreased by training them on the top of theTrainingSet_2containing only the processed images data.This finding confirms our argument that training the proposed DNNs on the top of the pre-processed images can remarkably improve their ability to rapidly learn useful feature representations with less time required to obtain the last trained model.Therefore,TrainingSet_2was used for all subsequent experiments.Additional information on the DBN and its hyper-parameters are given in Tab.2.For an initial CDBN architecture,only two CRBMs were greedily trained using the same proposed trained methodology described in(Subsection 3.3).This initial CDBN architecture was referred to as a CDBN-A in the subsequent experiments.The number of filters was initially set to 32 filters at each CRBM layer,and the size of the filter was set to (5×5) pixels.The CD learning algorithm (e.g.,one step of Gibbs sampling) was used to train all the CRBMs in an unsupervised greedily manner.Each CRBM was trained separately for 100 epochs with a mini-batch size of 100,target sparsity of 0.005,learning rate of 10−2,a weight decay value of 0.0005,and a momentum value of 0.95.The weights were randomly initialized with small values computed from a normal distribution of zero mean and SD of 0.02.
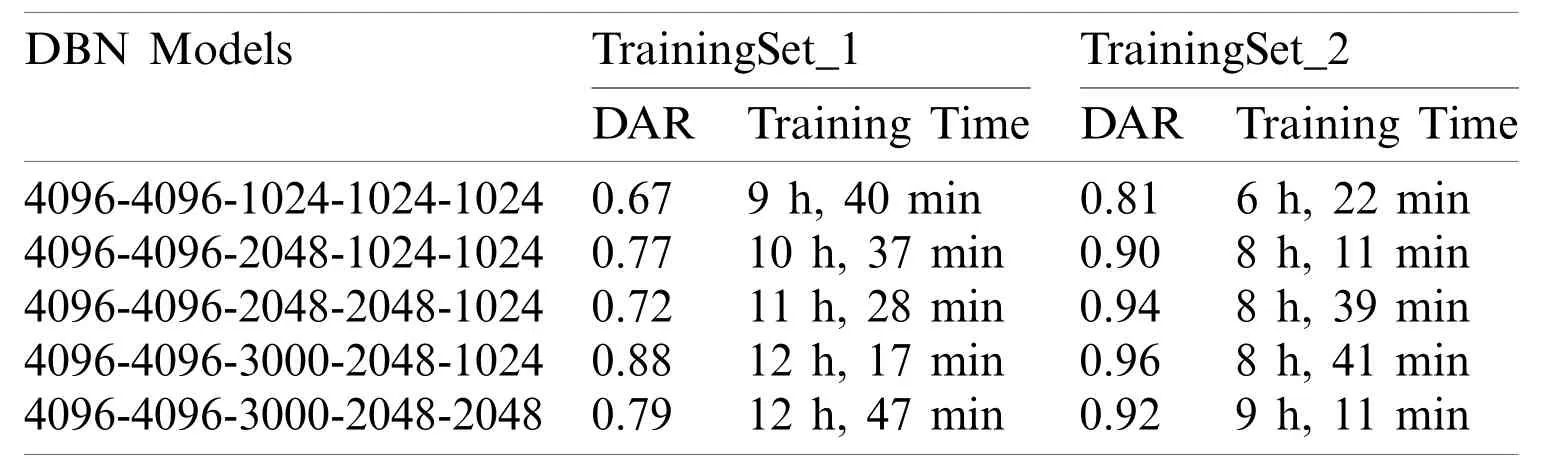
Table 1:Comparison of five different DBN architectures in terms of DAR and training time
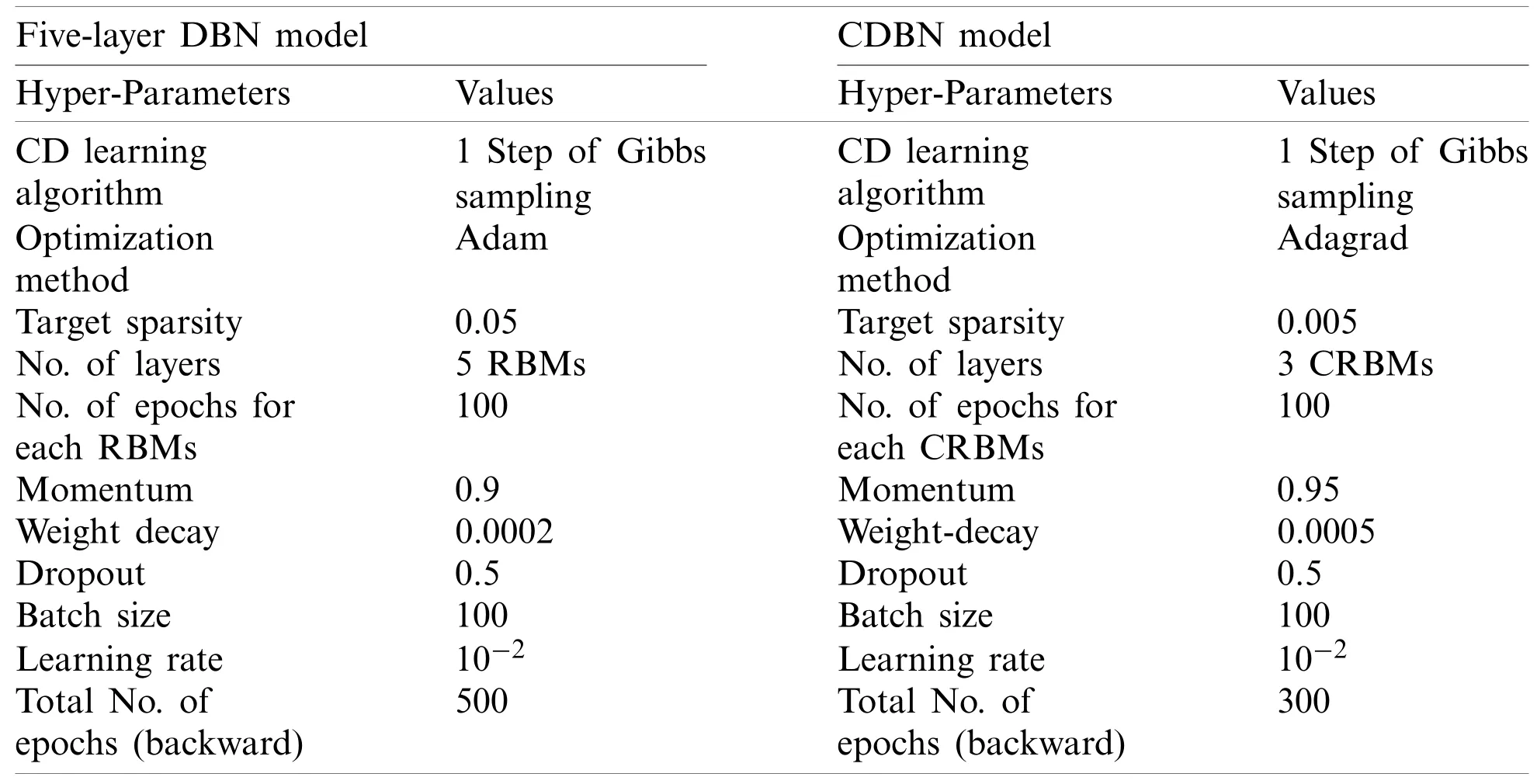
Table 2:Details of hyper-parameters for the proposed deep learning approaches (e.g.,DBN and CDBN)
The dropout technique with the dropout ratio of 0.5 was applied only for the fully-connected layer.In the fine-tuning phase,the weights of the whole CDBN-A model were optimized using the back-propagation algorithm in a top-down manner to achieve satisfactory predictions.First,the CDBN-A was trained for 500 epochs with a mini-batch size of 100.However,the performance of the CDBN-A model using the validation data declined when 500 epochs were evaluated because the last trained model started overfitting the training set (see Fig.6).

Figure 6:Finding the best number of epochs to train the CDBN-A model using the backpropagation algorithm in a top-down manner
For the CDBN model,this hyper-parameter was determined empirically by varying its value from 100 epochs to 500 epochs in steps of 10.The highest validation accuracy rate was obtained from the validation set by training the CDBN-A model in a top-down manner for 300 epochs.Moreover,a high accuracy rate can be achieved by adding a new CRBM with 128 trainable filters of size (6×6) pixels and changing the number of filters in the second CRBM from 32 trainable filters to 64 trainable filters.This newly added CRBM was trained using the same hyperparameters of the other CRBM.This new architecture was denoted as a CDBN-B model and used for all remaining experiments instead of the CDBN-A model.Additional information on the CDBN-B and its hyper-parameters are presented in Tab.2.The ROC curves of the CDBN-A and CDBN-B models are shown in Fig.7 to visualize their performances on the testing set of the COVID19-vs.-Normal dataset.Fig.8 shows the learned high-level feature representations from the last hidden layers in CDBN-A and CDBN-B model after training.
4.2 Fusion Rule Evaluation
The proposed COVID-DeepNet system makes the final decision by integrating the results produced from two different deep learning models (e.g.,DBN and CDBN).Every time a CX-R image is assigned to the proposed COVID-DeepNet system,two predicted probability scores are computed,and the highest probability score is used to assign the input image to one of two classes(e.g.,either normal or COVID-19 class).In this section,the results obtained from the DBN and CDBN models were combined and evaluated using different fusion rules in the score-level fusion(e.g.,using sum,weighted sum,product,max,and min rule) and decision-level fusion (e.g.,using AND OR rule).Additional information on how these fusion rules are implemented in both levels can be found in [44].
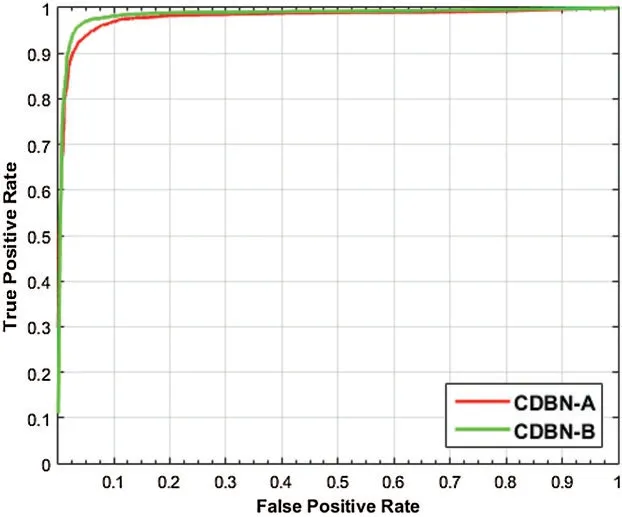
Figure 7:Performance comparison between CDBN-A and CDBN-B on the testing set of the COVID19-vs.-Normal dataset

Figure 8:Visualization of the learned high-level feature representations from the last hidden layers:(a) CDBN-A model,and (b) CDBN-B model
Parallel architecture,which provides radiologists a high degree of confidence to make their final decision and to accurately distinguish between healthy and COVID-19 infected subjects,was considered in the proposed COVID-DeepNet system.During the implementation of the weighted sum rule (WSR) at the score-level,a slightly higher weight value was given to the CDBN-B model than to the DBN model due to the better performance of the former.Moreover,normalization is not required prior to applying the score fusion rules because both classifiers generate the same probability scores and within the same numeric range [0,1].Herein,the average values of seven quantitative performance measures using various fusion rules at the score- and decision-level fusion are presented in Tabs.3 and 4,respectively.
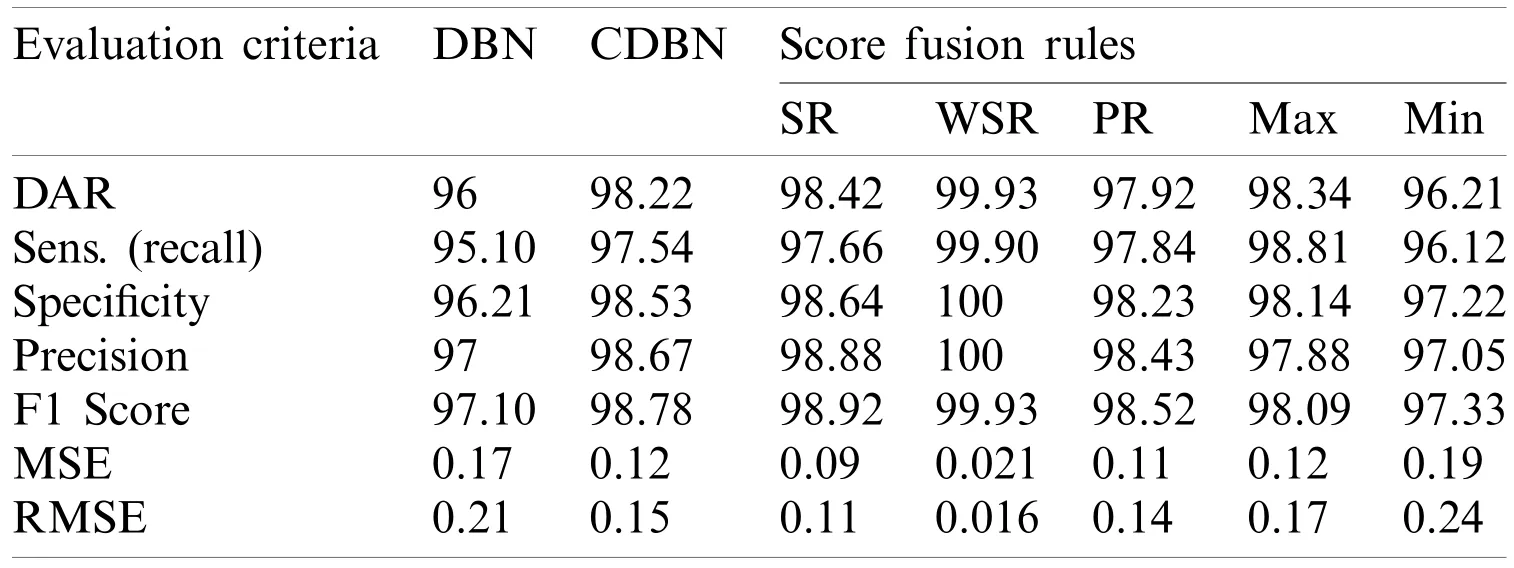
Table 3:Performance comparison of the proposed hybrid COVID-DeepNet system using five different rules in score-level fusion
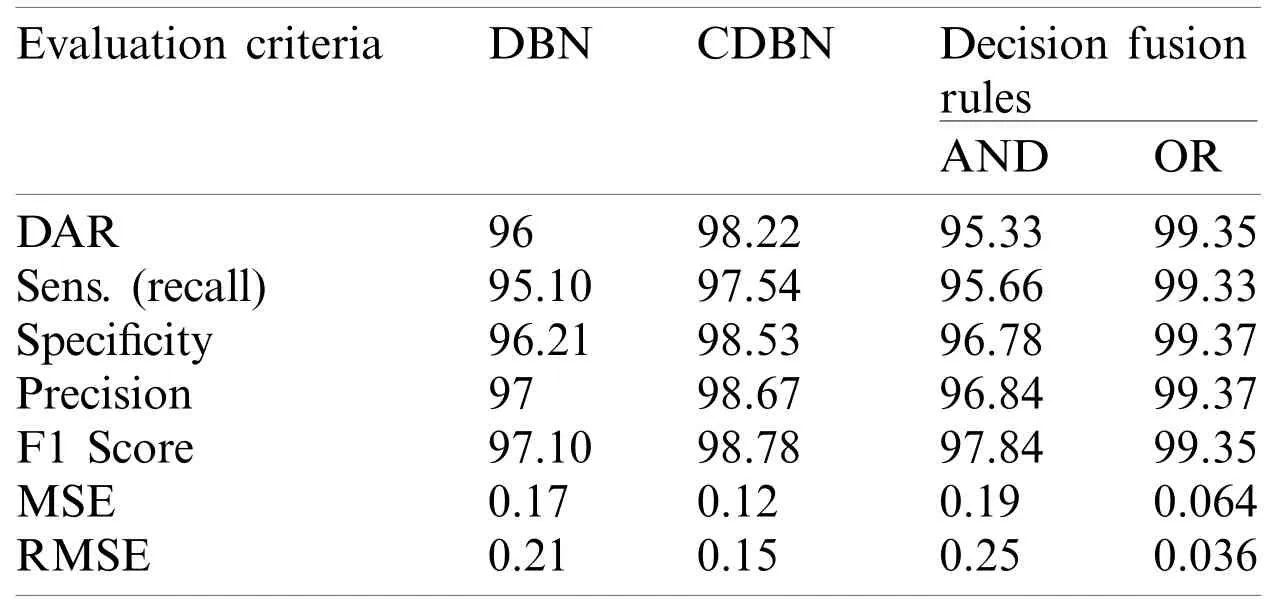
Table 4:Performance comparison of the proposed hybrid COVID-DeepNet system using two different rules in decision-level fusion
The accuracy of the proposed hybrid COVID-DeepNet system was remarkably enhanced compared with that of DBN or CDBN alone.The highest values of the adopted seven quantitative measures were obtained using the WSR and the OR rule in the score- and decision-level fusion,respectively.The proposed COVID-DeepNet system correctly and accurately diagnosed the patients with COVID-19 in the score-level fusion with a DAR of 99.93%,sensitivity of 99.90%,specificity of 100%,precision of 100%,F1-score of 99.93%,MSE of 0.021%,and RMSE of 0.016% using the WSR and in the decision-level fusion using the OR rule with a DAR of 99.35%,sensitivity of 99.33%,specificity of 99.37%,precision of 99.37%,F1-score of 99.35%,MSE of 0.064%,and RMSE of 0.036%.The high precision value of 100% achieved in the scorelevel fusion using the WSR is essential in reducing the number of misclassified healthy cases as COVID-19 cases.Finally,the two confusion matrices of COVID-19 infected and normal test results using the WSR and OR rule are shown in Fig.9.Under WSR rule,only one COVID-19 infected image was misidentified as a healthy image,and three healthy images were misclassified as COVID-19.Under OR rule in the decision-level fusion,19 COVID-19 infected images were misclassified as healthy images,and 20 healthy images were misclassified as COVID-19.Thus,WSR was used in the performance comparison of the proposed COVID-DeepNet system with current state-of-the-art systems due to its effectiveness in exploiting the strength of each classifier.These results further strengthened the possibility of employing the proposed COVID-DeepNet system in real-world settings to seriously moderate the workload of radiologists and help them accurately detect COVID-19 infection by using CX-R images.
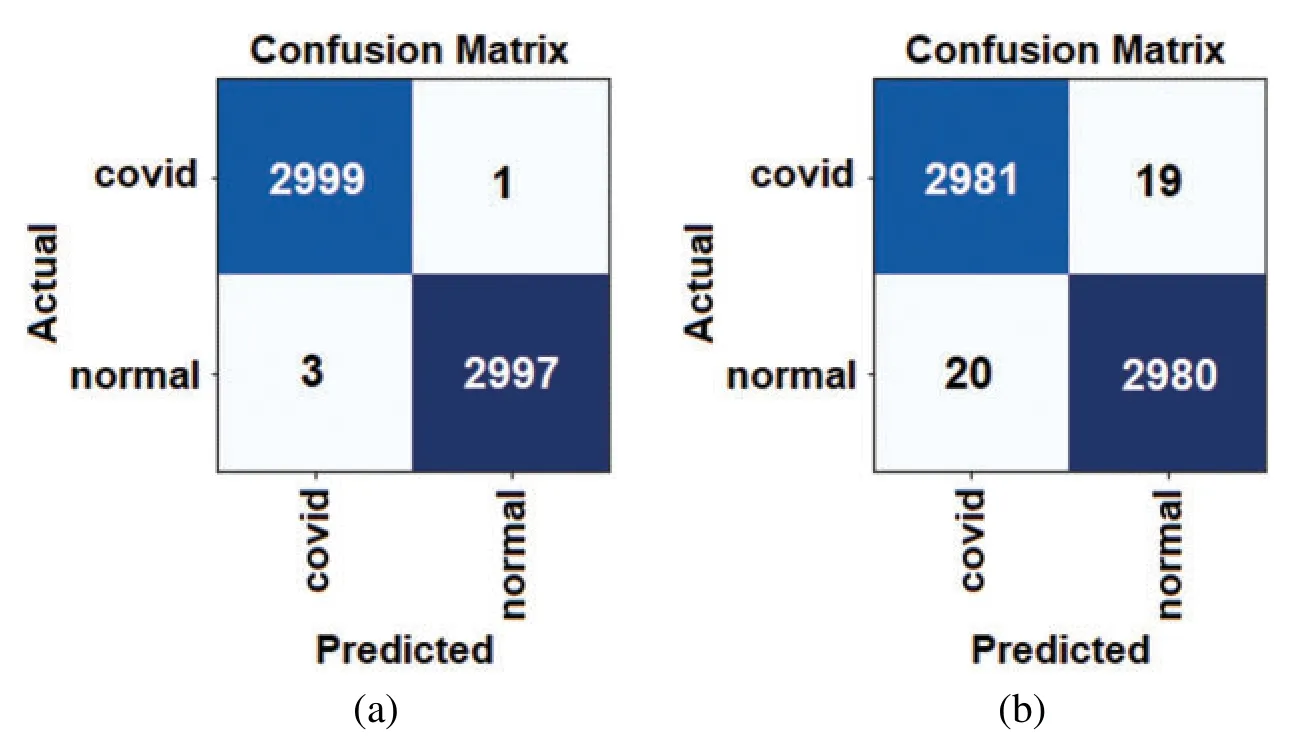
Figure 9:Confusion matrices for the proposed COVID-DeepNet system using different fusion rules:(a) WSR rule in the score-level fusion,and (b) OR rule in the decision-level fusion
4.3 Comparison Study and Discussion
The efficiency and reliability of the proposed COVID-DeepNet system were compared with those of the most current state-of-the-art COVID-19 detection systems.The first three COVID-19 detection systems were evaluated on the COVIDx dataset containing only 76 CX-R images with confirmed COVID-19.The first system was developed by Wang et al.[19]using a deep tailored designed model based on a CNN termed as a COVID-Net.The second system was proposed by Farooq et al.[27]by employing a pre-trained ResNet-50 model termed as a COVID-ResNet.The third system was proposed by Luz et al.[45].The performance of different architectures of EfficientNet was assessed using an updated version of the COVIDx dataset containing 183 chest radiography images with confirmed COVID-19.The performances of these three systems were evaluated by computing four quantitative measures (e.g.,accuracy,sensitivity,precision,and F1-score) for three different classes (e.g.,normal,non-COVID19,and COVID-19).For an impartial comparison,these four quantitative measures were averaged,and the values are shown in Tab.5.The proposed COVID-DeepNet system obtained better results compared with the other systems.Although the EfficientNet B3 model described in [45]achieved the same precision of 100%,the proposed COVID-DeepNet system produced better results in the other two measures(e.g.,accuracy and sensitivity) by using a large dataset containing many CX-R images with confirmed COVID-19.A comparison study among three different CNN models (e.g.,InceptionV3,ResNet50,and Inception-ResNetV2) was conducted by Narin et al.[23]to detect COVID-19 infected patients using CX-R images.The mean values of five different quantitative measures(e.g.,accuracy,recall,specificity,precision,and F1-score) were calculated using fivefold crossvalidation to assess their performance of these systems.The best performance was obtained using the pre-trained ResNet50 model with an accuracy rate of 98%,recall of 96%,and a specificity value of 100%.Although the ResNet50 model achieved the same sensitivity and precision with the proposed COVID-DeepNet system,its results for the other five measurements were inferior (Tab.6).

Table 5:Performance comparison between the proposed COVID-DeepNet system and three current state-of-the-art COVID-19 detection systems evaluated on the COVIDx dataset
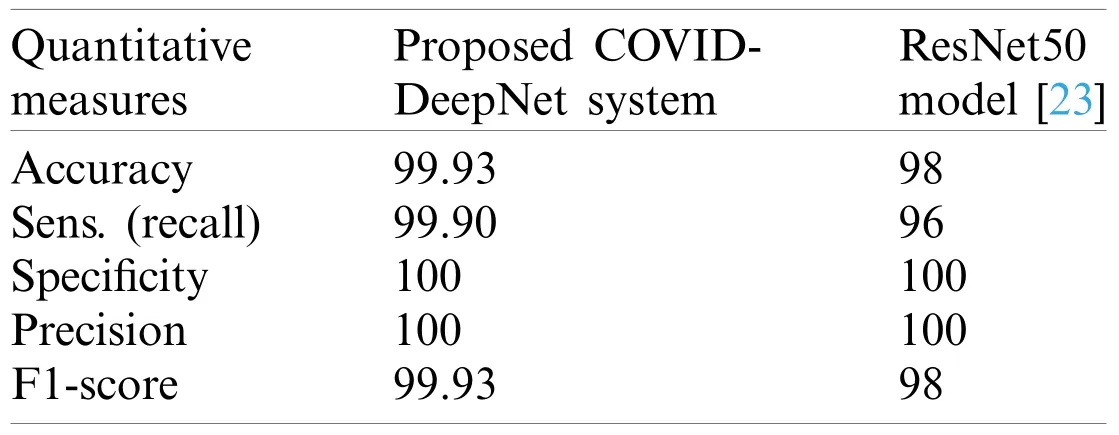
Table 6:Performance comparison between the proposed COVID-DeepNet system and ResNet50 [23]
5 Conclusion and Future Work
An accurate and automated system for COVID-19 diagnosis is presented and named as COVID-DeepNet system to distinguish between healthy and COVID-19 infected subjects by using chest radiography images.In the COVID-DeepNet system,CLAHE and Butterworth bandpass filter were applied to enhance the contrast of the CX-R image and eliminate the noise,respectively.Two discriminate deep learning approaches (e.g.,DBN and CDBN) were trained from scratch on the top of the pre-processed chest radiography images to prevent overfitting and enhance the generalization capabilities of the proposed deep learning approaches.A large-scale CX-R image dataset was created and termed as the COVID19-vs.-Normal dataset to assess the performance of the COVID-DeepNet system.The proposed system achieved comparable performance with expert radiologists with a DAR of 99.93%,sensitivity of 99.90%,specificity of 100%,precision of 100%,F1-score of 99.93%,MSE of 0.021%,and RMSE of 0.016% using the weighted sum rule in the score-level fusion.The main limitation of the proposed COVID-DeepNet system is that it was trained to classify the input CX-R image into one of two classes (e.g.,healthy and COVID-19 infected).The proposed COVID-DeepNet system is currently being trained to classify the CX-R image to other types of diseases (e.g.,bacterial pneumonia and viral pneumonia).Further experimental investigations are required to prove the effectiveness of the proposed COVID-DeepNet system using a large and challenging dataset containing many COVID-19 cases.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Recognition and Detection of Diabetic Retinopathy Using Densenet-65 Based Faster-RCNN
- Adaptation of Vehicular Ad hoc Network Clustering Protocol for Smart Transportation
- Computational Microfluidic Channel for Separation of Escherichia coli from Blood-Cells
- A Fractal-Fractional Model for the MHD Flow of Casson Fluid in a Channel
- Simulation,Modeling,and Optimization of Intelligent Kidney Disease Predication Empowered with Computational Intelligence Approaches
- Prediction of Time Series Empowered with a Novel SREKRLS Algorithm