基于改进麻雀算法-支持向量机的输电线路故障诊断
2021-12-15石万宇魏军强赵云灏
石万宇,魏军强,赵云灏
(华北电力大学,北京 102200)
0 引言
输电网络覆盖区域广,输电线路走廊的地理环境复杂多变,经常受恶劣天气影响或外力破坏从而发生故障。输电线路故障包括外界因素引起的故障,主要有雷击、鸟害、大风、覆冰等[1-2]和人为引起的故障。这些故障类型中,雷击故障占总故障数量的50%以上,所以对输电线路的雷击故障进行分类诊断意义重大[3]。线路是否发生雷击故障不仅与雷电的雷电流和距离有关,也与输电线路自身的属性、特征有关,所以迫切需要研究输电线路在内外部多种因素影响下的故障分类诊断。
但是,以往基于模型驱动的雷击故障诊断无法应对更加复杂的线路情况。而随着智能电网的建立,电网中产生的大量复杂数据可以被应用,提供了数据基础,基于数据驱动的故障诊断模型被广泛应用[4]。目前大多使用机器学习等算法实现线路故障的分类诊断,例如SVM(支持向量机)[5-7]、人工神经网络[8-9]、决策树[10-11]、模糊推理[12-13]等应用到故障诊断。SVM 模型在分类领域有着强大的分类效果,它对数量集较少的小样本有着较高的分类准确率和泛化能力。
目前,将SVM 模型直接应用在线路故障数据分类诊断中存在较大的局限性,有着准确率不高,分类识别精度和算法运行效率较低等诸多问题,SVM 核函数构造方法和参数的优化方法仍然值得探索[14]。如今群体智能优化算法正逐渐被广泛应用,目前研究比较多的有两种算法:ACO(蚁群算法)[15-16]和PSO(粒子群算法)[17-19]。
SSA(麻雀搜索算法)是一种新型优化算法[20],该算法借鉴了麻雀的捕食和反捕食行为,搜索寻优能力强,具有稳定性高,收敛速度快的优点。
本文通过自适应t 分布[21]改进的麻雀搜索算法对SVM 中的惩罚参数和核函数参数进行优化,并研究构建了基于tSSA-SVM 算法模型的输电线路故障分类诊断方法。首先,采用自适应t 分布算法对麻雀优化算法进行优化,构建tSSA 优化算法,提高算法寻优效率;然后基于tSSA 优化算法改进的SVM 模型,通过tSSA 算法对传统SVM 模型径向基核函数宽度参数σ、惩罚因子C等关键参数进行优化,构建出基于tSSA-SVM 的输电线路故障诊断模型,实现对输电线路故障有效诊断,从准确率和所用时间上来看,本文所提模型具有较高的分类诊断效率。
1 tSSA 算法
1.1 SSA 算法
麻雀是群居动物,往往会集体外出觅食,它们在觅食时一般会分为两个类型的群体:发现者和加入者。发现者群体承担发现食物的责任,它们选择方向和区域进行搜索并寻找食物;加入者是后来加入的麻雀,为了提高觅食效率会跟随发现者进行搜索。发现者和加入者所占整个种群的比例是不变的,但是麻雀可以在发现者和加入者之间动态选择。同时,麻雀还存在反捕食行为,当外围搜索的麻雀遭遇天敌或其它生物的威胁,会对整个种群发出预警,使种群避开此区域,调整搜索位置。根据麻雀的这种群体行为方式可以模拟出一种智能优化算法,进行解空间的寻优。麻雀搜索算法的核心为发现者搜索、加入者搜索和侦查行为模式[20,22]。
1.1.1 发现者搜索
发现者负责确定搜索食物的方向和区域,同时进行觅食,搜索范围较加入者要更大,在种群中所占比例也更大,一般取种群数量的60%~70%。所有麻雀个体是否能够优先找到食物,取决于每个个体对应的适应度函数值的好坏。同时,发现者大多处于种群外围,需要负责对周围环境进行预警,即发现威胁者时,发现者需要带领加入者去往安全位置继续进行搜索。
设定预警值R(R∈[0,1]),安全值S(S∈[0.5,1]),当预警值大于安全值,即R>S 时,表示有发现者发现威胁者存在,此时需要向种群发出预警,种群作出反捕食策略,所有麻雀转移至安全位置继续搜索。当预警值小于等于安全值,即R≤S 时,表示所有麻雀周围都是安全的,可以继续搜索觅食。
1.1.2 加入者搜索
种群中剩下的所有麻雀都作为加入者。如果加入者所储备的能量较少,即适应度值较低,使得其当前位置觅食位置很差,表示当前的搜索方向不合适,需要更换方向去往其它位置。同时,由于加入者跟随发现者进行搜索,当发现者发现食物时,加入者可以获得其中一部分食物或者在位置周围觅食。
1.1.3 侦查行为模式
处于种群边缘位置的麻雀有一部分需要负责侦察预警,它们一般占种群数量的10%~20%。面对威胁者的到来预警者可以及时预见到危险并向种群发出警报,此时不论是发现者还是加入者都需要调整搜索位置远离危险,进入安全区域搜索。同时,处于种群中心位置的麻雀会随机移动,当警报发出时,它们会向其他麻雀位置靠近以减少被捕食的可能。
1.2 自适应t 分布
t 分布被称为学生分布[21,23]。其概率密度函数如下:
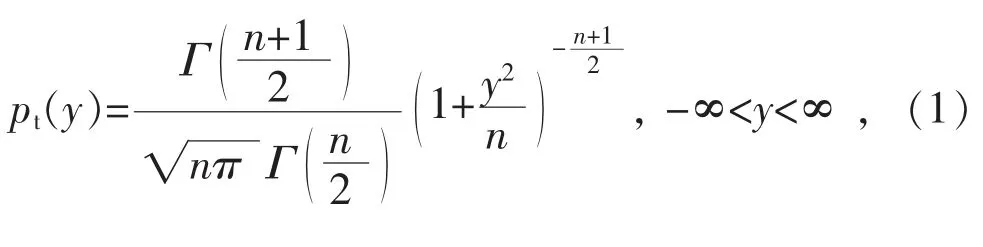
式中:n 为参数自由度。
在进化规划里柯西变异和高斯变异是最为常用的变异算子,而柯西分布和正态分布是t 分布两种边界位置的特殊分布。标准正态分布密度N(0,1)的期望为0,方差为1。标准柯西分布概率密度C(0,1)的期望不存在,方差是无限大。根据t 分布的概率函数,当n→∞时t(n)→N(0,1),即当n→∞时,t 分布为标准正态分布;当n=1 时t(n)→C(0,1),即当n=1 时,t 分布为标准柯西分布。所以t 分布的优势就在于可构造t 算子φ,通过t 算子衔接高斯算子和柯西算子。发挥出两类算子的优势。
基于自适应t 分布变异的麻雀搜索算法将麻雀算法的迭代次数k 作为t 分布的自由度参数,在迭代前期k 较小时,t 分布类似柯西变异,具有较强的全局搜索能力;迭代后期k 较大时,类似高斯变异,具有较强的局部搜索能力。这样使t分布由于迭代次数的变化具有自适应能力。
与粒子群优化算法向最优解移动的优化机制不同,麻雀搜索算法是通过麻雀位置的跳跃来逼近最优位置附近。这种机制导致算法容易陷入局部最优,而基于自适应t 分布的变异改进可使麻雀跳出局部最优位置,提高算法全局搜索能力。
2 基于tSSA 优化的SVM 算法
2.1 SVM
SVM 常用于二分类,与感知机不同,它的基本模型是定义在特征空间上的间隔最大的线性分类器。SVM 的基本思想是寻找一个最优超平面,使得不同数据最近分界面与超平面的距离最大,并且能够正确划分训练数据集[24]。
SVM 通过核函数将输入空间映射为高维特征空间,然后在特征空间中寻找最优超平面。核函数的选择对于SVM 的分类性能有着重要影响,常用的核函数有多项式核函数、RBF(高斯径向基)核函数,以及Sigmoid 核函数三种。由于RBF核函数可以直观地反映两个数据向量间的距离,所以应用该核函数。对SVM 分类器效果影响最大的是核参数σ 和惩罚参数C。一般参数是通过经验和大量实验人为地确定各个参数的值。
核参数σ 影响分类模型支持向量的个数和映射空间中样本特征的分散程度。σ 的值越大,映射空间的样本特征越分散,支持向量越少,算法的运行速度和准确性越小。
惩罚参数C 代表回归模型对离群点的重视程度。惩罚参数越大,对离群点的重视程度就越高,分类的容错率变低;惩罚参数越小,对离群点的重视程度越低,分类的容错率越高。同时参数过大或者过小都会引起算法的过拟合或欠拟合。
选定合适的核参数σ 和惩罚参数C 才能更好地发挥分类器的性能,常用的参数试凑法选择度较低,通常采用优化算法对其进行改进。
2.2 tSSA-SVM 算法
本文采用基于改进的tSSA 算法对SVM 参数进行优化,在SVM 参数初始化的基础上加入改进的优化算法。
基于自适应t 分布变异的麻雀优化算法tSSA的思想是,为了避免迭代后的麻雀陷入局部最优位置而无法到达全局最优位置附近,利用自适应t 分布变异对全体麻雀位置进行变异操作,将麻雀带出局部最优位置,从而继续进行全局搜索,增加了麻雀位置状态的多样性的同时,也提高了搜索速度。
对一个优化问题,若存在m 个变量,则搜索空间为m 维。此时假设存在n 只麻雀,则在搜索空间中第i 只麻雀的位置为[xi1,xi2,…,xim],其中i=1,2,…,n,这样所有麻雀的位置可用矩阵X表示。设定适应度值为SVM 对数据集的分类错误率。
优化算法的实现设计步骤如下:
Step1 初始化。设定种群数量N,最大迭代次数iter,发现者所占比例PD,预警麻雀所占比例SD,安全值ST,参数(C,σ)的上边界ub 和下边界lb。然后随机初始化麻雀种群。
Step2 计算当前所有麻雀的适应度值,在适应度值较优的麻雀中按比例PD 选取一部分作为发现者,其余麻雀作为加入者。
确定当前最优适应度值fb和其对应麻雀个体的位置xbest;同时确定最差适应度值fw和其对应麻雀个体的位置xworst。
Step3 按照公式更新发现者和加入者位置。麻雀发现者的位置更新公式如式(2)所示:

式中:k 为当前迭代次数;α 表示(0,1]之间的随机数;T 为最大迭代次数;R 为预警值;S 为安全值;Q 为服从标准正态分布的随机数;L 为所有元素都为1 的1×m 的矩阵。
加入者的位置更新公式如式(3)所示:

Step4 计算所有麻雀位置的适应度值,确定最优适应度值fb和其对应麻雀个体的位置xbest,同时确定最差适应度值fw和其对应麻雀个体的位置xworst。
Step5 根据预警麻雀所占比例SD 在所有麻雀中随机挑选一部分作为预警麻雀。利用式(4)更新预警者位置。
预警麻雀个体位置更新公式如式(4)所示:
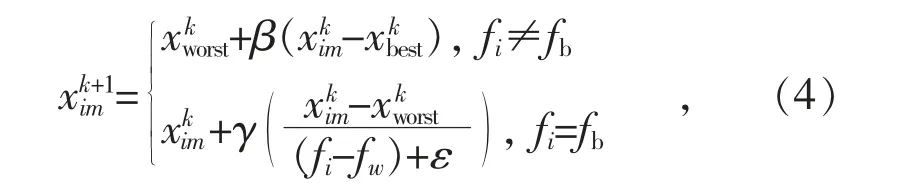
式中:β 为控制移动步长,是服从均值为0,方差为1 的正态分布的随机数;γ 为控制移动步长的参数,同时还表示移动方向,是[-1,1]范围内的随机数。fi为第i 只麻雀的适应度值;fb为当前种群中最好的适应度值;fw为当前种群中最差的适应度值。ε 是一个为了避免分母为0 而加入的一个无穷小数。
当fi≠fb,即某只麻雀的适应度值不是最优适应度值时,此时麻雀位置处于种群外围,易受威胁者和捕食者的攻击,需要向最优位置也是最安全的位置移动。当fi=fb时,该麻雀的位置处于中心位置,当发现危险时,该麻雀向其他麻雀靠近以避免被捕食者攻击。
Step6 再次更新所有麻雀适应度值,确定最优适应度值和最优位置。
Step7 利用自适应t 分布对所有麻雀位置进行变异,避免陷入局部最优。基于麻雀算法的迭代次数k,用t 分布变异更新麻雀位置。t 分布变异更新公式如式(5)所示:

式中:xi和分别为t 分布变异前后第i 只麻雀的位置;k 为迭代次数;φ(k)为以迭代次数k 为参数自由度的t 算子。
计算所有麻雀变异后的适应度值,并与变异之前的最优适应度值进行比较,取变异前后更优的适应度值对应的麻雀位置。
Step8 终止条件判断。判断是否满足终止条件,即是否达到最大迭代次数。如果满足终止条件,则转向Step 9;否则转向Step 3。
Step9 优化算法终止。输出SVM 分类器最优参数。
Step10 将最优参数输入到SVM 分类器,得到最优SVM 分类模型,输出分类诊断结果。
基于改进麻雀算法tSSA 优化SVM 的算法流程如图1 所示。
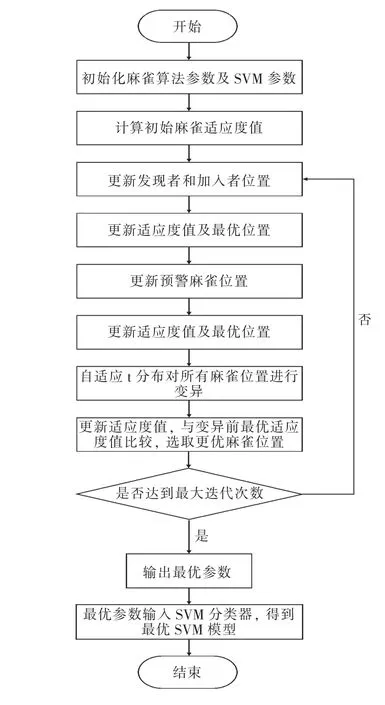
图1 tSSA 优化SVM 算法流程
3 基于tSSA-SVM 的雷击故障分类诊断模型
根据输电线路故障特征样本数据对线路是否发生雷击故障进行分类诊断,建立分类诊断模型。其流程如图2 所示。

图2 基于tSSA-SVM 线路雷击故障分类流程
分类诊断流程如下:
流程1,模型的输入与输出。通过发生雷击故障的线路和杆塔数据以及雷电流数据,分析雷击线路后影响线路故障状态的重要特征因素,利用样本构建输电线路雷击故障特征矩阵,以是否发生雷击故障作为输出。
流程2,样本数据预处理。对样本数据采用归一化预处理,归一化映射公式如式(6)所示:

式中:x 为原样本数据;x′为归一化处理后的数据。
流程3,参数初始化。初始化tSSA 算法的种群参数和SVM 的惩罚参数C 和核参数σ。
流程4,参数优化。利用tSSA 算法优化SVM初始参数。将分类错误率函数作为优化的适应度函数,最终经过n 次迭代得到最优参数核参数σ和惩罚参数C。
流程5,对模型进行训练。样本的标签为是否发生雷击故障,通过训练集对基于tSSA 优化后SVM 模型进行训练,再用测试集验证模型准确率,通过模型预测的分类结果与实际类别来判断模型的适应性与有效性。
4 算例分析
4.1 数据来源
数据来自某省近5 年的雷击导致输电线路故障的杆塔和线路的数据,以及雷电定位系统。共获得样本数据为1 062 个,构成原始样本数据集。分类类别为发生故障和未发生故障两类。
对输电线路故障相关特征进行特征选择,最终选取14 个对线路故障的发生具有较大影响的输电线路内部和外部特征因素,其中包含线路参数、雷电参数、地形参数等,关键特征因素如下:海拔高度、雷电流大小、雷电与线路距离、地面倾斜角、导线保护角、杆塔高度、横担高度、避雷线平均高度、导线平均高度、接地电阻、接地形式、杆塔电感、冲击接地电阻、几何耦合系数。
在1 062 个样本数据中选取800 个样本作为训练集数据,剩余262 个样本构成测试集数据。线路故障的样本统计情况如表1 所示。

表1 线路故障的训练集与测试集样本统计
4.2 参数设定
tSSA 优化算法参数的初始值设定,种群数量为20,迭代次数为50,发现者比例为70%,预警麻雀所占比例20%,预警值为0.6,SVM 参数(C,σ)的下边界为[0.1,0.1],上边界为[100,100],并且优化算法以SVM 的分类错误率为寻优的适应度值。
4.3 模型分类结果
在Intel(R)Core(TM)i7-5500U CPU@ 2.40 GHz,内存为8.00G 的计算机上,使用MATLAB分析软件,对所提基于tSSA-SVM 的输电线路故障诊断模型进行了测试分析。基于tSSA 优化后的SVM 模型的惩罚参数C 为6.761 9,核参数σ 为10.543 8。基于tSSA 优化的SVM 输电线路故障诊断模型测试结果如图3 所示。

图3 tSSA-SVM 算法对测试集分类结果
在262 组测试样本中,有254 组分类正确,仅有8 组分类错误。模型的分类准确率为96.946 6%,模型测试结果统计分析如表2 所示。

表2 测试结果统计分析
4.4 结果比较与分析
原始SVM 算法经过多次试凑,取惩罚参数C 为12,核参数σ 为22,此时分类准确率为94.656 5%。基于tSSA-SVM 的输电线路故障诊断模型的分类准确率相较于原始SVM 算法提高了2%。参数的选择对于SVM 的分类结果影响巨大,试凑法难以有效得到合理的模型运行参数。SVM算法对测试集的分类结果如图4 所示。

图4 SVM 算法对测试集分类结果
为了比较tSSA-SVM 算法的故障分类诊断性能,再加入PSO-SVM 算法模型对雷击故障数据进行诊断分类,两种算法优化SVM 后的分类效果及适应度曲线如图5 所示。
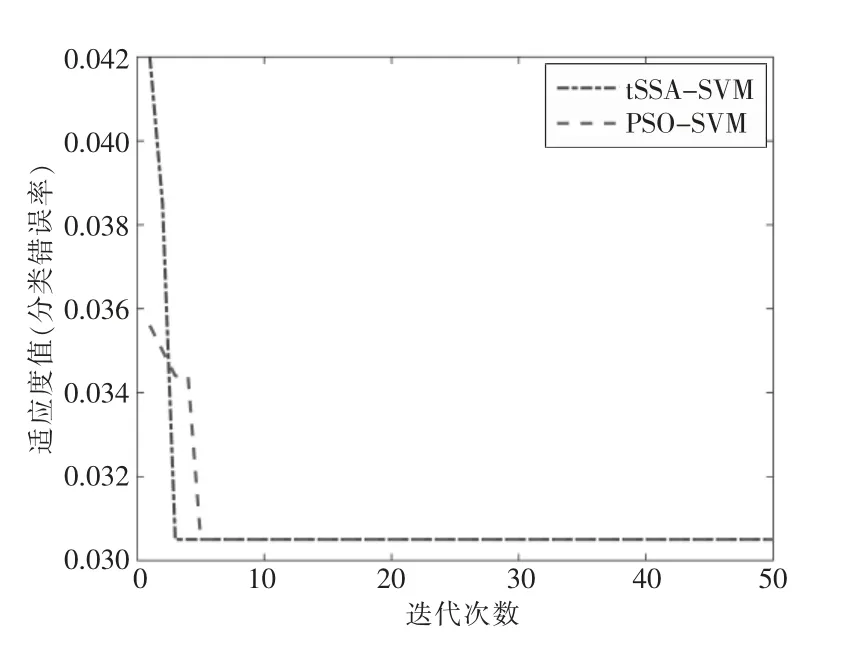
图5 tSSA-SVM 和PSO-SVM 分类算法的适应度曲线
由图5 中可以看出两种优化算法优化后的SVM 分类器最终分类结果相同,分类准确率都为96.946 6%。但是tSSA-SVM 只需迭代2 次可达到最优,PSO-SVM 算法迭代3 次才达到最优,收敛速度较慢。并且通过对tSSA-SVM 算法和PSOSVM 算法各自进行10 次运算并取平均运行时间,得到tSSA-SVM 运行时间为168.951 861 s,PSO-SVM 运行时间为443.869 640 s,可见tSSASVM 的运算效率比PSO-SVM 提高了161.455%,分类速度更快,如表3 所示。

表3 两种算法的测试集分类平均运算时间与准确率
由结果可知,基于经典SVM 的线路故障分类方法测试集的准确率最低,这是因为其参数的选择无法固定,只能通过经验或者试凑法选择合适参数才能获得较高的诊断准确率。而PSO-SVM算法准确率同tSSA-SVM 相同,但是运行时间更长,收敛速度更慢,算法效率较低,如果面对更加庞大的数据集将耗时更大。本文提出的算法tSSA-SVM 分类准确率最高,时间效益最好,相比另外两种分类模型具有明显优势。
5 结论
本文提出了一种通过基于自适应t 分布的改进麻雀搜索优化算法,并通过其优化支持向量机模型的参数,构建一种基于tSSA-SVM 算法的输电线路故障分类诊断的方法模型。传统SVM 模型需要选择合适的参数,参数的不同严重影响分类效果。通过改进的麻雀搜索算法优化SVM 模型核心参数,即核参数σ 和惩罚参数C,可以使SVM 分类器分类效果达到最优。同时,为了解决麻雀搜索算法易陷入局部收敛,无法趋于全局最优的缺点,加入了自适应t 分布来调整麻雀的位置。这种混合变异方法既保证了算法进化初期全局探索能力较强,又提升了算法的效率和精度。
对于输电线路雷击故障诊断,基于tSSASVM 算法建立了输电线路雷击故障分类诊断模型,研究得到影响线路故障14 个内外部关键特征,再通过电网运行数据获取样本数据,来验证所提模型的诊断性能。与SVM 和PSO-SVM 算法模型相比,所提出的tSSA-SVM 算法具有更高的故障诊断准确率和诊断效率。与PSO-SVM 优化算法相比,所提tSSA-SVM 算法运行分析时间短,收敛速度快,占用计算资源更少。
麻雀搜索算法和其他新型优化算法相比有一定优势,有很大改进空间,未来在大数据领域或有更多应用。同时输电线路故障诊断模型的新方法仍值得继续研究。
