Unsupervised Domain Adaptation Based on Discriminative Subspace Learning for Cross-Project Defect Prediction
2021-12-14YingSunYanfeiSunJinQiFeiWuXiaoYuanJingYuXueandZixinShen
Ying Sun,Yanfei Sun,2,*,Jin Qi,Fei Wu,Xiao-Yuan Jing,3,Yu Xue and Zixin Shen
1Nanjing University of Posts and Telecommunications,Nanjing,210003,China
2Jiangsu Engineering Research Center of HPC and Intelligent Processing,Nanjing,210003,China
3Wuhan University,Wuhan,430072,China
4Nanjing University of Information Science and Technology,Nanjing,210044,China
5Carnegie Mellon University,Pittsburgh,15213,USA
Abstract:Cross-project defect prediction(CPDP)aims to predict the defects on target project by using a prediction model built on source projects.The main problem in CPDP is the huge distribution gap between the source project and the target project,which prevents the prediction model from performing well.Most existing methods overlook the class discrimination of the learned features.Seeking an effective transferable model from the source project to the target project for CPDP is challenging.In this paper,we propose an unsupervised domain adaptation based on the discriminative subspace learning(DSL)approach for CPDP.DSL treats the data from two projects as being from two domains and maps the data into a common feature space.It employs crossdomain alignment with discriminative information from different projects to reduce the distribution difference of the data between different projects and incorporates the class discriminative information.Specifically,DSL first utilizes subspace learning based domain adaptation to reduce the distribution gap of data between different projects.Then,it makes full use of the class label information of the source project and transfers the discrimination ability of the source project to the target project in the common space.Comprehensive experiments on five projects verify that DSL can build an effective prediction model and improve the performance over the related competing methods by at least 7.10%and 11.08%in terms of G-measure and AUC.
Keywords:Cross-project defect prediction;discriminative subspace learning;unsupervised domain adaptation
1 Introduction
Software security is important in the software product development process.Defects are inevitable and damage the high quality of the software.Software defect prediction (SDP) [1-3]is one of the most important steps in software development and can detect potentially defective instances before the release of software.Recently,SDP has received much research attention.
Most SDP methods construct a prediction model based on historical defect data and then apply it to predict the defects of new instances within the same project,which is called withinproject defect prediction (WPDP) [4-6].The labeled historical data,however,usually are limited.New projects have few historical data,and the collection of labels is time-consuming.However,plenty of data are available from other projects,and cross-project defect prediction (CPDP) [7,8]has emerged as an alternative solution.
CPDP uses training data from external projects (i.e.,source projects) to train the prediction model,and then predicts defects in the target project [9].CPDP is challenging because a prediction model that is trained on one project might not work well on other projects.Huge gaps exist between different projects because of differences in the programming language used,developer experience levels,and code standards.Zimmermann et al.[7]performed CPDP on 622 pairs of projects,and only 21 pairs performed well.In the machine learning literature [10],such works always require different projects to have similar distribution.In WPDP,this assumption is easy,but it cannot hold for CPDP.Therefore,the ability to reduce the distribution differences between different projects is key to increasing the effectiveness of CPDP.
To overcome this distribution difference problem,many methods have been proposed.Some researchers have used data filtering techniques.For example,Turhan et al.[11]used the nearest neighbor technique to choose instances from the source project that were similar to instances from the target project.Some researchers have introduced transfer learning methods into CPDP.For example,Nam et al.[12]used transfer component analysis to reduce the distribution gaps between different projects.These works usually have ignored the consideration of conditional distributions of different projects.
Unsupervised domain adaptation (UDA) [13,14]focuses on knowledge transfer from the source domain to the target domain,with the aim of decreasing the discrepancy of data distribution between two domains,which is widely used in various fields,such as computer vision [15],and natural language processing [14].The key to UDA is to reduce the domain distribution difference.Subspace learning is the main category of UDA,which can conduct subspace transformation to obtain better feature representation.In addition,most existing CPDP methods ignore the effective exploration of class label information from the source data [11].
In this paper,to reduce the distribution gap across projects and make full use of the class label information of source project,we propose a discriminative subspace learning (DSL) approach based on UDA for CPDP.DSL aims to align the source and target projects into a common space by feature mapping.In addition,DSL incorporates class-discriminative information into the learning process.We conduct comprehensive experiments on five projects to verify that DSL can build an effective prediction model and improve the performance over the related competing methods by at least 7.10% and 11.08% in terms of G-measure and AUC,respectively.Our contributions are as follows:
1) We propose a discriminative subspace learning approach for CPDP.To reduce the distribution gap of the data between source and target projects,DSL uses subspace learning based on UDA to learn a projection that can map the data from different projects into the common space.
2) To fully use the label information and ensure that the model has better discriminative representation ability,DSL incorporates discriminative feature learning and accurate label prediction into subspace learning procedure for CPDP.
3) We conduct extensive experiments on 20 cross-project pairs.The results indicate the effectiveness and the superiority of DSL compared with related baselines.
The remainder of this paper is organized as follows.The related works are discussed in Section 2.The details of DSL are introduced in Section 3.The experiment settings are provided in Section 4.Section 5 gives the experimental results and analysis.Section 6 analyzes the threats to the validity of our study.The study is concluded in Section 7.
2 Related Work
In this section,we review the related CPDP methods and subspace learning based unsupervised domain adaptation methods.
2.1 Cross-Project Defect Prediction
Over the past several years,CPDP has attached many studies and many new methods have been proposed.Briand et al.[16]first proposed whether the cross system prediction model can be investigated.They developed a prediction model on one project and then used it for other projects.The poor experimental results showed that applying models across projects is not easy.
Some methods focus on designing an effective machine learning model with an improved learning ability or generalization ability.Xia et al.[8]proposed a hybrid model (HYDRA)including genetic algorithm and ensemble learning.In the genetic algorithm stage,HYDRA builds multiple classifiers and assigns weights to different classifiers to output an optimal composite model.In ensemble learning phase,the weights of instances can be updated by iteration to learn a composition of the previous classifiers.Wu et al.[17]employed dictionary learning in CPDP and proposed an improved dictionary learning method CKSDL for addressing class imbalanced problem and semi-supervised problem.The authors utilize semi-supervised dictionary learning to improve the feature learning ability of the prediction model.CKSDL combines cost-sensitive technique and kernel technique to further improve the prediction model.Then,Sun et al.[18]introduced adversarial learning into CPDP and embedded a triplet sampling strategy into an adversarial learning framework.
In addition,some methods focus on introducing transfer learning into CPDP.Ma et al.[19]proposed transfer naive bayes for CPDP.They exploited the transfer information from different projects to construct weighted training instances,and then built a prediction model on these instances.The experiment indicated that useful transfer knowledge would be helpful.Nam et al.[12]employed transfer component analysis for CPDP,which learns transfer components in a kernel space to make the data distribution from different projects similar,and an experiment on two datasets indicated that TCA+achieves good performance.Li et al.[20]proposed cost-sensitive transfer kernel canonical correlation analysis (CTKCCA) to mitigate the linear inseparability problem and class imbalance problem in heterogeneous CPDP.They introduced CCA into heterogeneous CPDP and improved the CCA to obtain better performance.Liu et al.[21]proposed a two-phase method called TPTL based on transfer learning,which can address the instability issue of traditional transfer learning.TPTL first selects source projects that have high similarity with target project.Then,TPTL uses TCA+in the prediction model on the selected source projects.
Hosseini et al.[22]evaluated 30 previous studies,including their data metrics,models,classifiers and corresponding performance.The authors counted the common settings and concluded that CPDP is still a challenge and has room for improvement.Zhou et al.[23]compared the performance of existing CPDP methods.In addition,they built two unsupervised models—ManualUp and ManualDown,which only use the size of a module to predict its defect proneness.They concluded that the module size based models achieve good performance for CPDP.
Existing CPDP methods cannot consider the conditional distribution differences between different projects and ignore the discriminative information from both source project and target project.From the above consideration,we propose DSL to improve the performance of CPDP.
2.2 Unsupervised Domain Adaptation
Unsupervised domain adaptation has attracted much attention,and it aims to transfer useful information from the source to the target domain effectively in unsupervised scenario.Domain adaptation methods have been applied to various applications,such as computer vision [15]and natural language processing [14].Subspace learning based unsupervised domain adaptation aims to learn a mapping for aligning the subspaces between two projects.Sun et al.[13]proposed subspaces distribution alignment method for performing subspace alignment to reduce distribution gaps.Long et al.[24]adapted both marginal distribution and conditional distribution between the source and target domains to reduce the different distributions simultaneously.Zhang et al.[25]proposed guided subspace learning to reduce the discrepancy between different domains.
In this paper,we introduce subspace learning based unsupervised domain adaptation into CPDP,which can effectively reduce the distribution gap between different projects.We also make full use of the class information from source project and propose a discriminative subspace learning approach for CPDP.
3 Methodology
In this section,we present the details of DSL.Fig.1 illustrates the overall framework of the proposed DSL approach for CPDP.
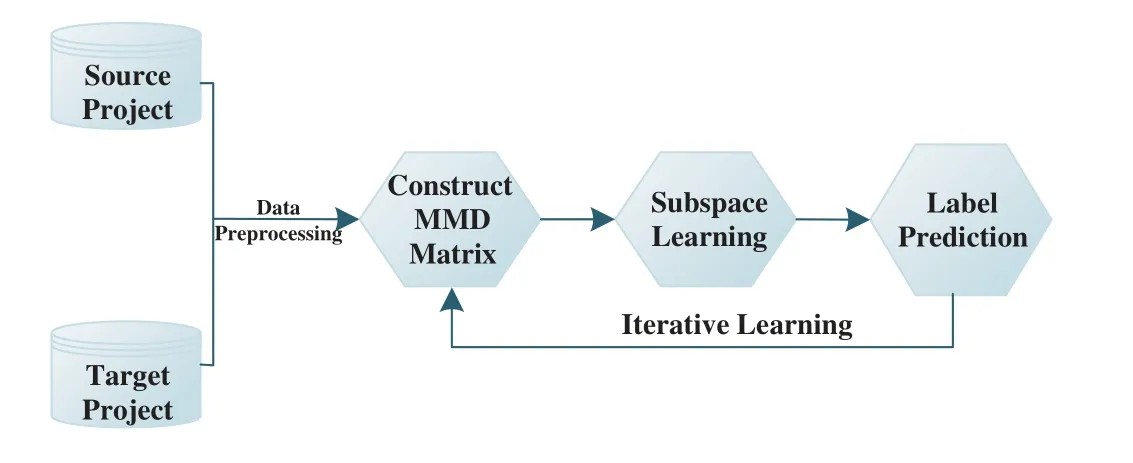
3.1 Data Preprocessing
To alleviate the class imbalance problem,we perform SMOTE [26]technique on the source project,as is one of the most widely used data preprocessing methods in CPDP.Previous works [27,28]have demonstrated that dealing with the class imbalance problem is helpful for SDP.
3.2 Notation
Given t he labeled source projectS={Xs,Ys}=and the unlabeled target projectT={Xt}=whereXsandXtare the data sets andYsis the label set.nsandntare the numbers of instances from source and target projects,respectively.Here,denotes theith instance in the source project,anddenotes theith instance in target project.yisis the corresponding label ofxis.aijsdenotes the value of thejth metric in theith instancexisin source project.aijtdenotes the value of thejth metric in theith instancexitin theTsource project;anddis the metric dimension of the source or target project.In CPDP,the labels of the target projectare unknown.
3.3 Subspace Learning
To minimize the distribution discrepancy between the projects,we seek an effective transformationP.We construct a common subspace with the projectionP.The mapped representations with the projection matrix from the source and target projects are represented aszs=PTxs,andzt=PTxt,respectively.
To effectively reduce the distribution discrepancy between the different projects,we consider the distances of conditional distributions across the projects.The maximum mean discrepancy(MMD) criterion [29]has been used widely to measure the difference between two distributions.We minimize the distanceFmmd(S,T)between the source and target projects as follows:

wherep(ys|xs)andp(yt|xt)denote the conditional distributions from the source and target projects.Cdenotes the number of label classes in CPDP.In this paper,the label of an instance is defective or non-defective,andC=2.ncsandnctare the numbers of the instances from source and target projects in classc.Specifically,the label of the target instance is unknown in CPDP.A feasible method is to use the target pseudo label,which can be predicted by the source classifier.We can make full use of the intrinsic discriminative information of the target project during the training process.In addition,we employ multiple iterations to improve the accuracy of the predicted labels.
Using matrix tricks,we rewrite Eq.(1) as follows:
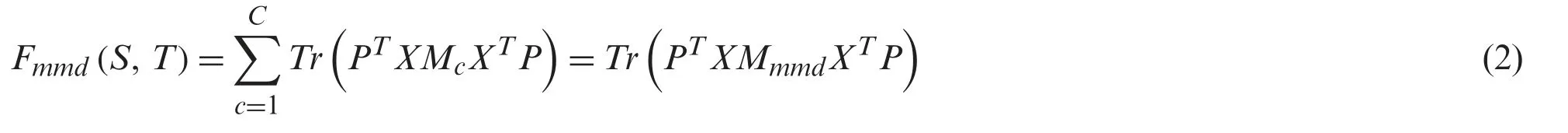
whereX={Xs,Xt} combines the source project and target project data,andMcdenotes the conditional MMD matrix with classc,which is computed as

3.4 Discriminative Feature Learning
Minimizing Eq.(1) can align the source data and target data,but it cannot guarantee that the learned feature representations are sufficiently discriminative.To ensure that the feature representations from the same class are closer than those from different classes in the common space,we design a triplet constraint that minimizes the distance between the intra-class instances and maximizes the distances between the inter-class instances.This constraint is based on the prior assumption of consistency.This means that nearby instances are likely to have the same label.
Specifically,we focus on the hardest cases,which are the most dissimilar instances within the same class and the most similar instances in the different classes.For each instancezisin the source project,we choose the farthest instancezjswith the same class as a positive matching,and the nearest instancezkswith a different class as a negative matching.Finally,we construct the tripletfor each instance in the source project.Then,we design the following formulation:
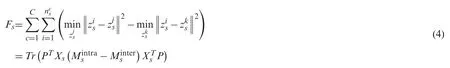
whereanddenote the distance between the instance pairs.Similarly,we defnie the triplet for the target instances in the same way and the formulation can be represented as
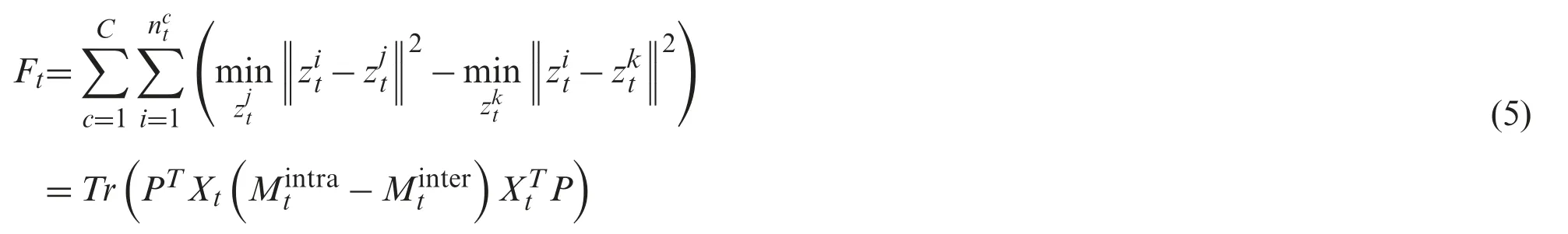
We obtain the whole formula for the source and target projects as

We formulate the overall equation of the DSL by incorporating Eqs.(2) and (6) as follows:

whereαis a balance factor andβis a regularization term.
The optimization of DSL is represented as follows:
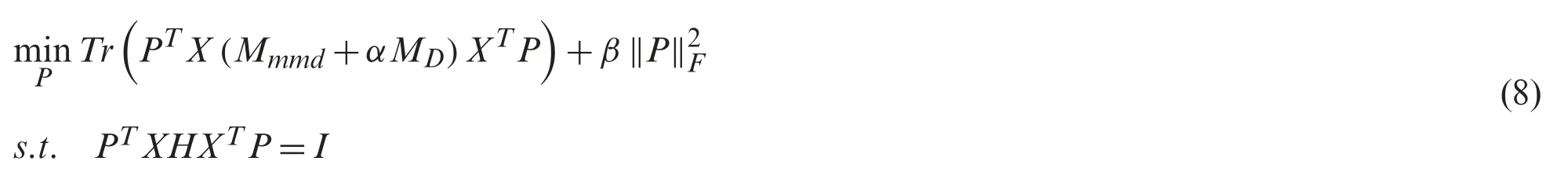
whereIis an identity matrix andH=I-(1/n)1 denotes a centering matrix similar to that in [24].The constraint condition ensures thatPTXcan preserve the inner attributes of the original data.The optimization problem of Eq.(8) can be solved as a generalized eigendecomposition problem.To solve Eq.(8),we denote Lagrange multipliers asand then we rewrite Eq.(8) as
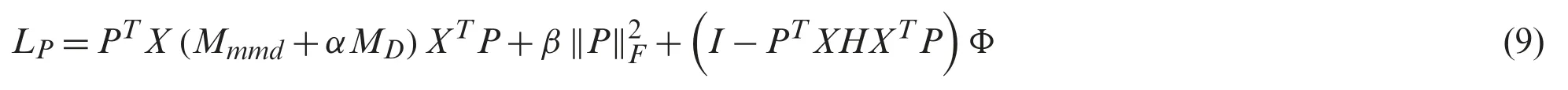
We set the derivative ofPto 0,and then we compute the eigenvectors for the generalized eigenvector problem:

By solving Eq.(10),we can obtain the optimal transformation matrixP.We iteratively updatePandMto benefit the next iteration process in a positive feedback way.
3.5 Label Prediction
To further improve the prediction accuracy of the target data,we design a label prediction mechanism.Considering that predicting target labels by using a source classifier directly may lead to overfitting,we utilize the label consistency between different projects and within the same project to obtain more accurate label prediction results.
In the common subspace,we believe that the classifier will be more accurate when the target instances are close to the source instances.Moreover,similar instances should have consistent labels.We assign larger weights to similar target instances that are close to the source instances,and assign smaller weights to dissimilar target instances that are far from the source instances.
The formula for label prediction can be defined as
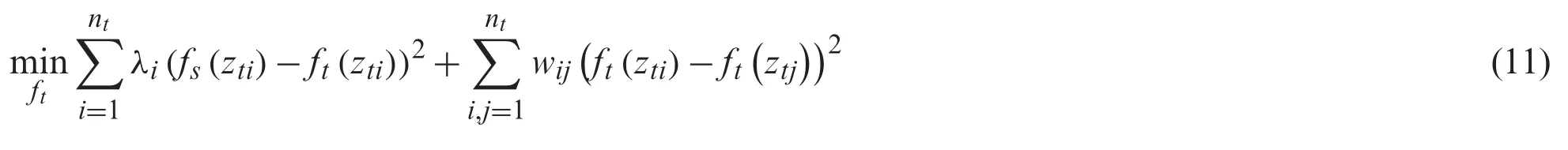
wherefs(zti)is the prediction label forztifrom the source classifier.ft(zti)is the expected label forzti.λiis a weight factor forzcti·wijis a binary matrix that is used to measure the similarity between different instances from the target project.If theith instance andjth instance are nearest neighbor,the value ofwijis 1,otherwise the value ofwijis 0.λican be calculated by the following formula:wherent/nctis used to balance the effects of different classes.lcidenotes the distance between the target instance with pseudo labelcpredicted by the source classifier and the instance with an expect labelc.


Then,we obtain the solution of (13) asThe label ofztiisWe summarize the DSL approach in Algorithm 1.

Algorithm 1:The proposed DSL approach Input:Source data set Xsand corresponding label set Ys,target data set Xt.Output:The prediction label of Xt.1.Data preprocessing.2.Construct the initial MMD matrix by Eq.(3).Repeat 3.Obtain the map matrix P by solving Eq.(10).4.Obtain fe at ure representation Zs and Zt in the common subspace.5.Obtain the pseudo labels by the source classifier.6.Use label prediction to update the pseudo labels of the target data.7.Update Mmmd and MD.Until Maximum number of iterations achieved.8.Obtain predict label by using label prediction.
4 Experiment
4.1 Dataset
We adopt five widely used projects from the AEEEM dataset [30]for CPDP.The AEEEM dataset is collected by D’Ambros et al.[30]and contains the data about Java projects.The projects of AEEEM are Equinox (EQ),Eclipse JDT Core (JDT),Apache Lucene (LC),Mylyn (ML) and Eclipse PDE UI (PDE).Each project consists of 61 metrics including entropy code metrics,source code metrics,etc.The data is publicly available online:http://bug.inf.usi.ch/.Tab.1 shows the detailed information for each project.
4.2 Evaluation Measures
In the experiment,we employ two well-known measures,the G-measure and AUC,to evaluate the performance of the CPDP model;these have been widely used in previous SDP works [20,31].The G-measure is a harmonic mean of recall (aka.pd) and specificity,and it is defined in Eq.(14).Recall is a measure defined asTP/(TP+FN).Specificity is a statistical measure that is defined asTN/(TN+FP).TP,FN,TN,andFPmean True Positive,False Negative,True Negative and False Positive,respectively,and they are defined in Tab.2.

The AUC is used to evaluate the performance of the classification model.The ROC curve is a two-dimensional plane with recall and pf.Pf,i.e.,the possibility of false alarm,which is defined asFP/(TN+FP).The AUC calculates the area under ROC curve.
The values of the G-measure and AUC range from 0 to 1.A higher value means better prediction performance.AUC=0.5 signifies a model that is randomly guessing.
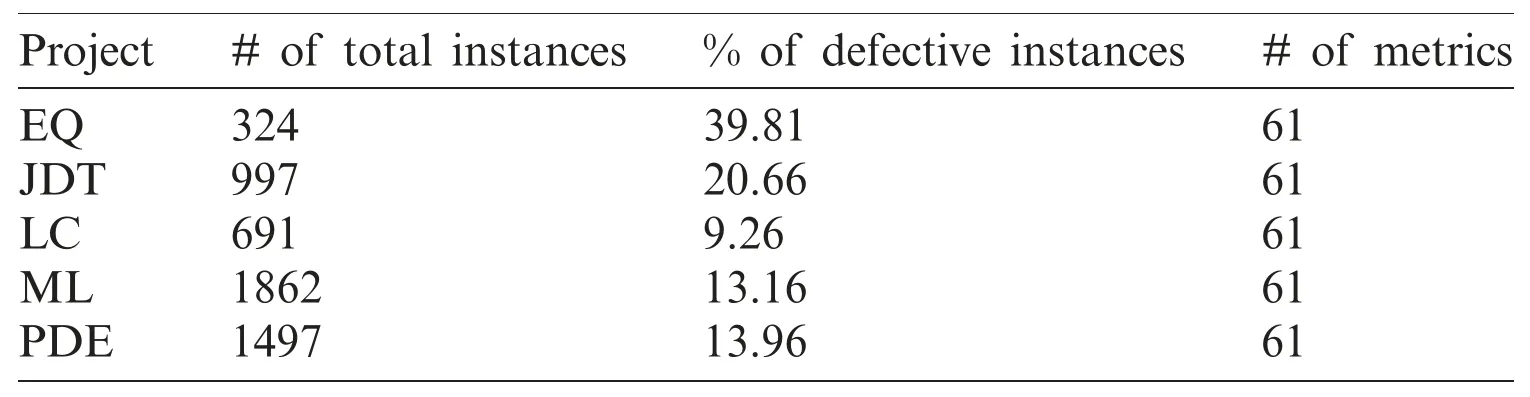
Table 1:Experimental data description

Table 2:Four kinds of defect prediction results
4.3 Research Question
In this paper,we answer the following research question:
RQ:Does DSL outperform previous related works?
We compare DSL with defect prediction models including TCA+[12],CKSDL [17],CTKCCA [20]and ManualDown [23].TCA+,CKSDL and CTKCCA are successful CPDP methods.ManualDown is an unsupervised method that was suggested as the baseline for comparison in [23]when developing a new CPDP method.
4.4 Experimental Setup
Similar to prior CPDP methods [17,20],we count cross-project pairs to perform CPDP.For each target project,there are four prediction combinations.For example,when EQ is selected as the target project,JDT,LC,ML and PDE are separately selected as source project for training.The prediction combinations are JDT→EQ,LC→EQ,ML→EQ,and PDE→EQ.We can obtain 20 cross-project pairs for the five projects.In DSL,we setα=1 andβ=0.1 in Eq.(10)empirically.We fix the maximum number of iterations to 10 in experiment.
5 Experimental Results and Analysis
5.1 RQ:Does DSL Outperform Previous Related Works?
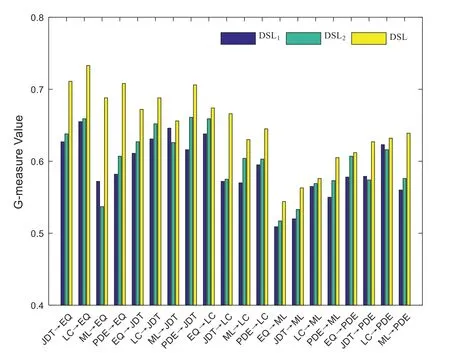
Tabs.3 and 4 show the G-measure and AUC results of DSL and the baselines for each crossproject pair.The best result of each combination is in boldface.Fig.2 shows the boxplots of G-measure and AUC for DSL and the baselines.From Tabs.3 and 4 and Fig.2,it is evident that DSL performs best in most cases compared with the baselines and obtains the best average result in terms of G-measure and AUC.In terms of the overall performance,DSL improves the average G-measure values by 7.10%-19.96% and average AUC values by 11.08%-15.21%.

Table 3:Comparison results in terms of G-measure for DSL and baselines.The best values are in boldface
DSL obtains good performance may for the following reasons:Compared with TCA+and CTKCCA,which reduce the distribution gap based on transfer learning,DSL embeds the discrimination representation into the feature learning process,and obtains discriminative common feature space that can reduce the distribution gap of data from different projects.Compared with ManualDown,DSL can utilize the class label information from the source project and discriminant information from the target project,which then obtain more useful information for the model training process.Compared with CKSDL,DSL can align the data distributions between different projects and has strong discriminative ability that can transfer it from the source project to the target project.Thus,in most cases,DSL outperforms the baselines.
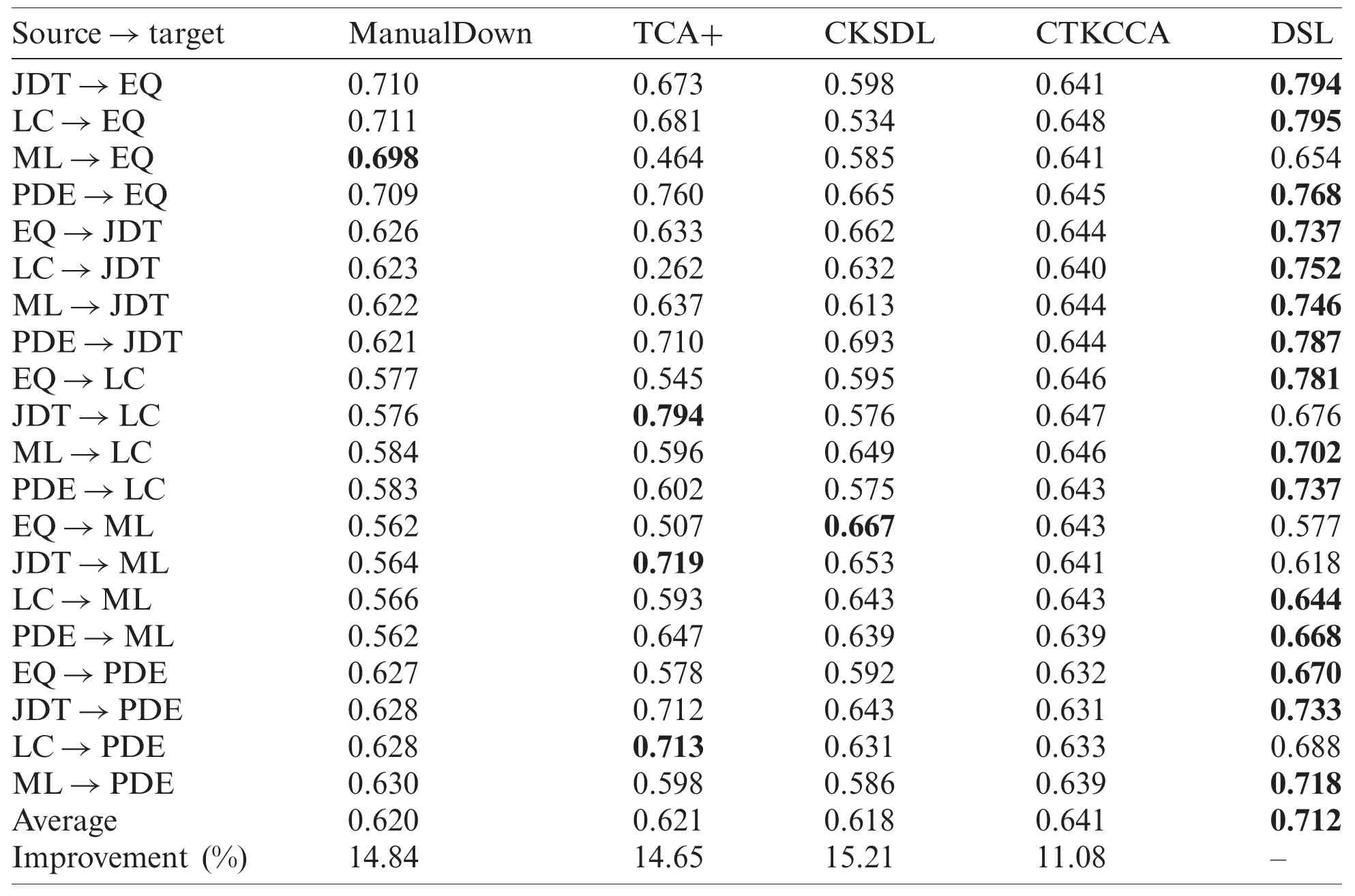
Table 4:Comparison results in terms of AUC for DSL and baselines.The best values are in boldface
5.2 Statistical Test
We perform the Friedman test [32]with the Nemenyi test on the two measure results to analyze the statistical difference between DSL and baselines,which has been widely used in SDP [33,34].For each evaluation measure,we compute the ranking of comparison methods on each cross-project pair.We apply Friedman test to determine whether the methods are significantly different.Then we apply Nemenyi test to compare the difference among each pair of methods.For a method pair,we compute their difference in rank by using critical difference (CD) value.If the difference in rank exceeds CD,we consider that the methods have significant difference.CD is defined as

whereqαdenotes the critical value at significance levelα,Nis the number of cross-project pairs,andLdenotes the number of methods.
The Friedman test results on the G-measure and AUC are visualized in Figs.3 and 4 respectively.A lower rank means better performance.The methods that have significant differences are divided into different groups.As shown in Figs.3 and 4,DSL performs better than the baselines with lower ranks.For the G-measure and AUC,DSL belongs to the top-ranked group without other methods,which means that it achieves the best performance,and that DSL has significant differences when compared with the baselines.
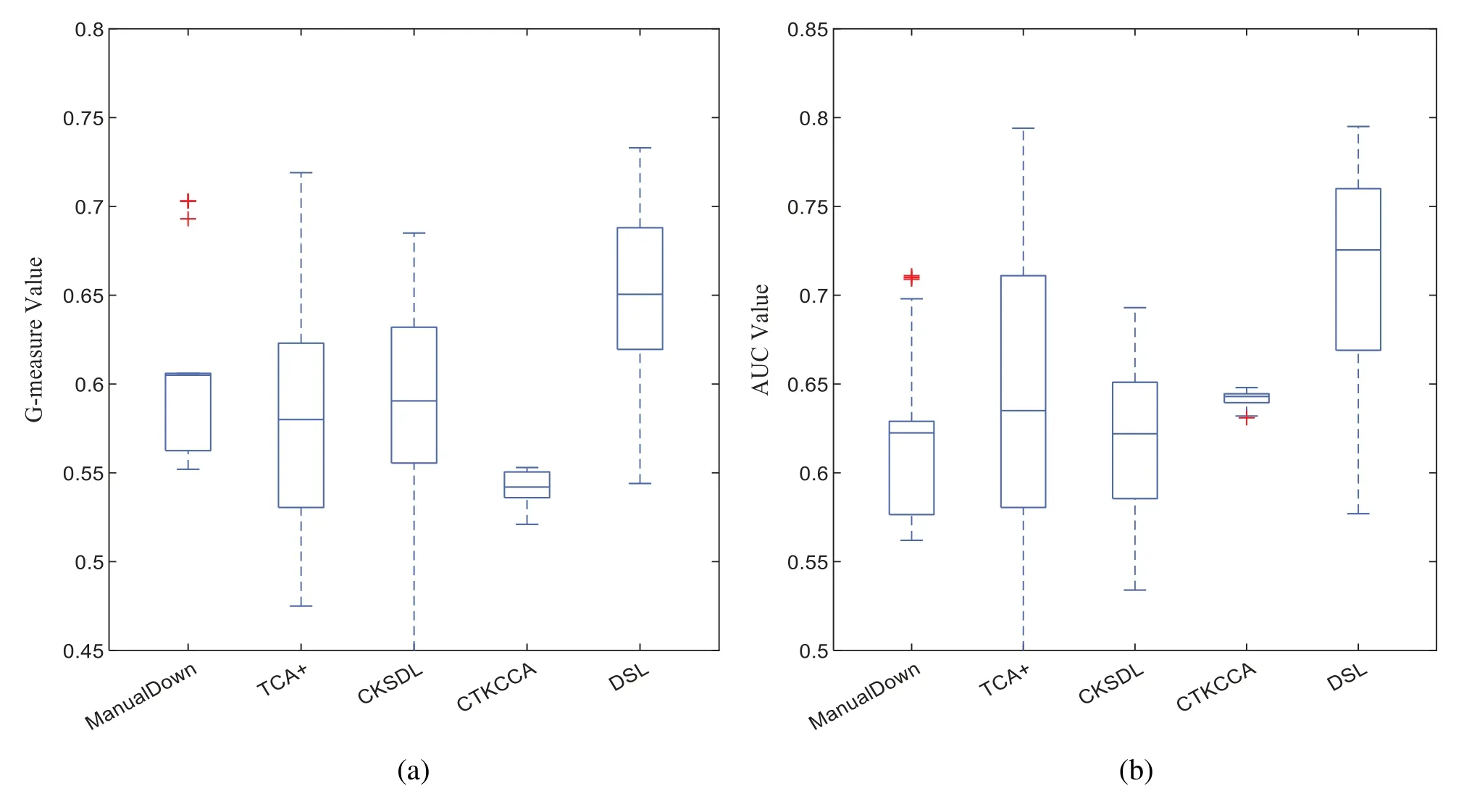
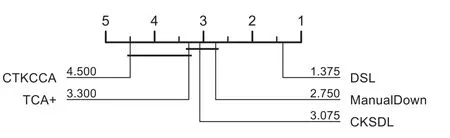
Figure 3:The results of statistical test in terms of G-measure for DSL and the other methods
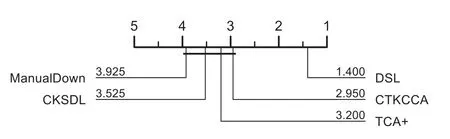
Figure 4:The results of statistical test in terms of AUC for DSL and the other methods
5.3 Ablation Study
To deeply investigate the impact of different parts of DSL,we conduct an ablation study.We evaluate DSL and two variants of DSL:
Subspace learning (DSL1):Using subspace learning based on conditional distribution for CPDP.
Subspace learning and discriminative feature learning (DSL2):Using subspace learning and discriminative feature learning for CPDP.
The experimental settings are the same as those in Section 4.4 on 20 cross-project combinations.The results are reported in Figs.5 and 6.From the figures,the results of DSL are improved on different projects.Clearly,in the mapped feature space,the distribution difference is reduced.Discriminative learning can help us explore the discrimination between different classes.The pseudo labels provided by label prediction can facilitates subspace learning and discriminative feature learning.Thus,discriminative feature learning and label prediction boost each other during the iteration process.Discriminative feature learning and label prediction play important roles in exploring discriminative information for CPDP.
5.4 Effects of Different Parameter Values
We conduct parameter sensitivity studies to verify the impact of parametersαandβon DSL.The value ranges ofαandβare from 0.001 to 10.We report the experimental results in terms of the G-measure and AUC in Fig.7.
From Fig.7,we can observe that DSL achieves good performance under a wide range of values.Whenα∈[0.5,5]andβ∈[0.05,0.5],DSL performs stably and outperforms the other cases.The results are not very sensitive to the parameters,which demonstrates the robustness of DSL.In the experiments,we setα=1 andβ=0.1.
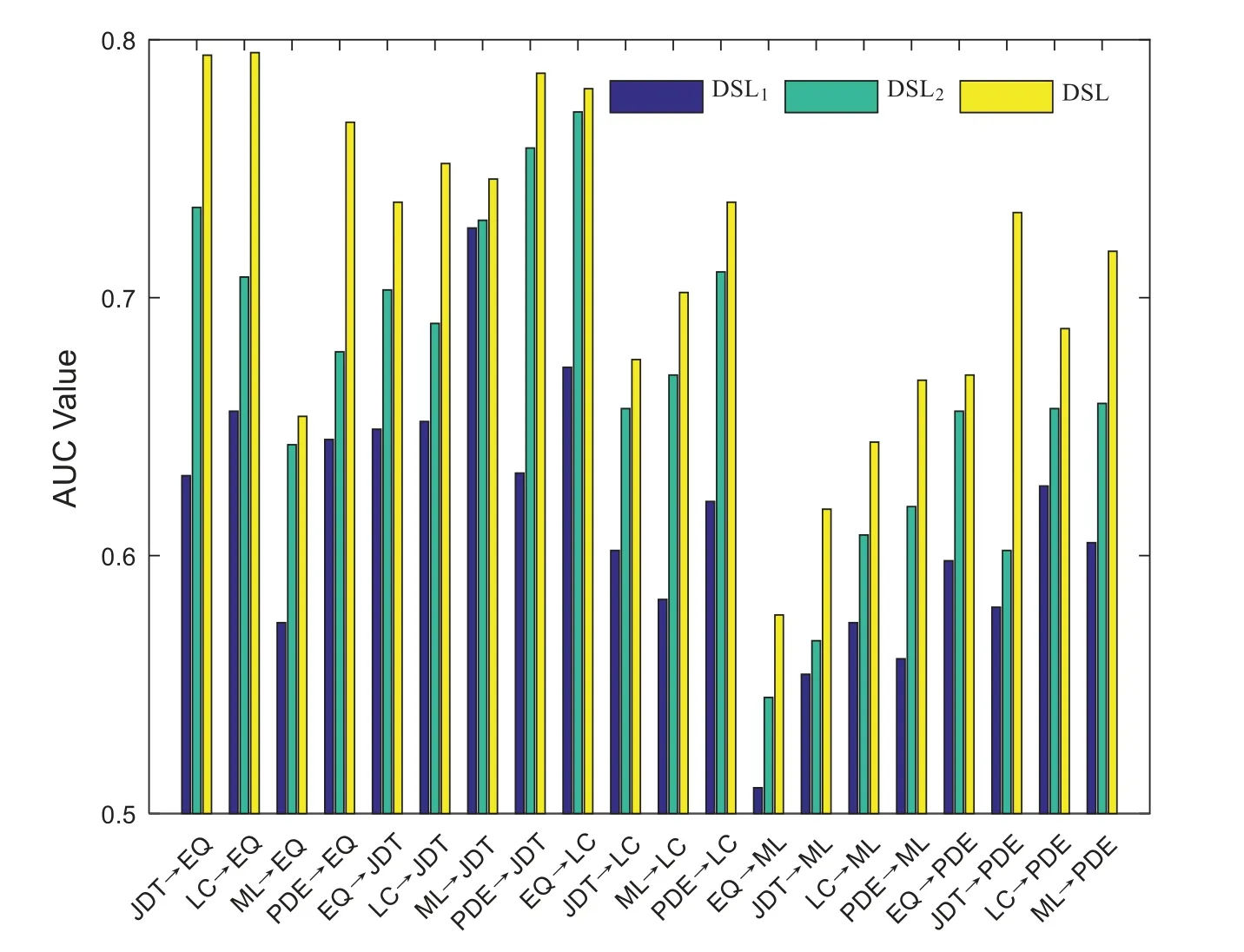
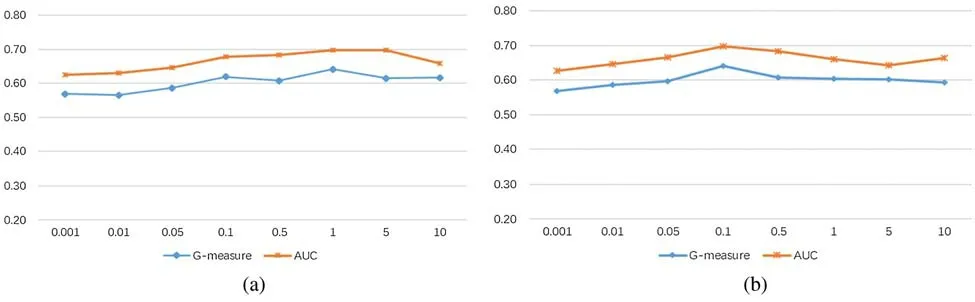
Figure 7:The mean G-measure and AUC values with various values of α and β.(a) Parameter α.(b) Parameter β
6 Threats to Validity
Internal validity mainly relates to the implementation of comparative baselines.For the baselines whose source codes can be provided by the original authors,we use the original implementation code to avoid the inconsistency of re-implementation.For the baselines do not public codes,we follow their papers and implement the methods carefully.
Construct validity in this work refers to the suitability of the evaluation measures.We employ two widely used measures and the selected measures are comprehensive indicators for CPDP.
External validity refers to the degree to which the results in this paper can be generalized to other tasks.We perform a comprehensive experiment on 5 projects in this paper.However,we still cannot claim that our approach would be suitable for other software projects.
7 Conclusion
In this paper,we propose a new model for CPDP based on unsupervised domain adaptation called discriminative subspace learning (DSL).DSL first handles the problem of large distribution gap in the feature mapping process.Furthermore,the discriminative feature learning is embedded in the feature mapping to make good use of the discriminative information from source project and target project.Extensive experiments on 5 projects are conducted.The performance of DSL is evaluated by using two widely used indicators including G-measure and AUC.The comprehensive experimental results show that DSL has superiority in CPDP.In our future work,we will focus on collecting more projects to evaluate DSL and predicting the number of defects in each instance by utilizing the defect count information.
Funding Statement:This paper was supported by the National Natural Science Foundation of China (61772286,61802208,and 61876089),China Postdoctoral Science Foundation Grant 2019M651923,and Natural Science Foundation of Jiangsu Province of China (BK0191381).
Conflicts of Interest:No conflicts of interest exit in the submission of this manuscript,and manuscript is approved by all authors for publication.
杂志排行

Computers Materials&Continua的其它文章
- Distributed Trusted Computing for Blockchain-Based Crowdsourcing
- An Optimal Big Data Analytics with Concept Drift Detection on High-Dimensional Streaming Data
- Bayesian Analysis in Partially Accelerated Life Tests for Weighted Lomax Distribution
- A Novel Deep Neural Network for Intracranial Haemorrhage Detection and Classification
- Impact Assessment of COVID-19 Pandemic Through Machine Learning Models
- Minimizing Warpage for Macro-Size Fused Deposition Modeling Parts