一种莱斯衰落信道下基于注意力机制的双向循环神经网络调制识别算法
2021-12-14胡佩聪杨文东吴凤广王晋芳
胡佩聪,杨文东,吴凤广,王晋芳
(1.陆军工程大学,江苏 南京 210007;2.电子信息系统复杂电磁环境效应国家重点实验室,河南 洛阳 471000;3.32319 部队,新疆 乌鲁木齐 830002)
0 引言
调制方式的自动识别(Automatic Modulation classification,AMC)是介于信号检测和信号解调之间的一项技术,其主要任务是实现信号的智能接收与处理。在合作通信领域,该技术主要用于智能无线电系统,包括认知无线电与软件无线电;在非合作通信领域,其主要用于电子对抗、通信侦察以及信号监测等[1]。
早期的调制识别依靠操作员使用耳机、示波器或频谱分析仪等工具对调制方式进行判定,该方式受技术员的知识储备、装备熟悉程度以及个人经验等主观因素影响较多,识别效果有限。随着技术的进步,人们开始针对不同环境下的各类调制信号采用不同的方法实现调制的自动识别。比较传统的调制方式识别技术主要可以分为基于似然比(Likelihood Based,LB)的调制方式识别技术[2]以及基于特征(Feature Based,FB)的调制方式识别技术[3]两类。基于似然比的调制方式识别算法具有较高的准确率,但它需要信号模型中随机变量的概率分布等先验信息,而这在实际应用中通常是无法获取的。另外,该算法计算复杂度高,有的场景仅存在理论上的计算可能。基于信号特征的调制方式识别算法计算复杂度较低,通过合理设计特征参数与分类器能获得较好的分类结果,但特征参数的设计与分类器的选择对性能影响较大。近年来,随着计算机硬件以及大数据的发展,基于深度学习的调制方式识别方法[4]被大量研究,典型的神经网络结构如深度神经网络[5-6](Deep Neural Network,DNN)、卷积神经网络[7-13](Convolutional Neural Network,CNN)、循环神经网络[14-15](Recurrent Neural Network,RNN)等均被应用于调制识别技术。
注意力机制[16](Attention Mechanism,AM)作为一种优化算法于2014 年提出,近年来广泛应用在深度学习中的各个领域。注意力机制是一种资源分配机制,其核心思想是合理改变对信息的关注度,忽略无关信息并放大有用信息。神经网络通过结合注意力机制改变网络权重,给有效信息分配足够的关注,从而提高模型的准确率。文献[17]针对资源受限的终端设备研究了基于门控循环单元(Gated Recurrent Unit,GRU)的循环神经网络结构调制识别性能,分析了GRU参数设置对识别准确率的影响。文献[18]采用多个长短时记忆(Long Short-Term Memory,LSTM)层搭建循环神经网络,并引入了时间注意力机制,对不同噪声影响下的调制信号进行了有效分类;仿真结果表明,该方法对不确定噪声条件的信号具有鲁棒性且识别性能接近理想的最大似然分类器。文献[19]提出了一种改进的LSTM网络的调制识别算法,通过长短期记忆网络提取信号特征,利用注意力机制为学习到的特征分配权重,仿真结果表明,该算法能以较低的时间代价取得较高的准确率。
本文采用的注意力机制引入了在训练中不断学习的新向量,通过它衡量特征的重要性并分配权重,结合双向循环神经网络构建了算法模型。针对莱斯衰落影响下的数字信号,该算法可以有效提取信号特征并将其进行分类,能以较好的训练表现获得较高的调制方式识别准确率。
1 信号模型
接收端信号模型表示为:
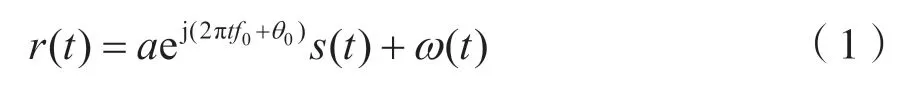
式中:a表示信道衰落;f0表示频率偏移;θ0表示相位偏移;ω(t)表示零均值的加性复高斯白噪声;s(t)为输入信道的信号。
s(t)可表示为:
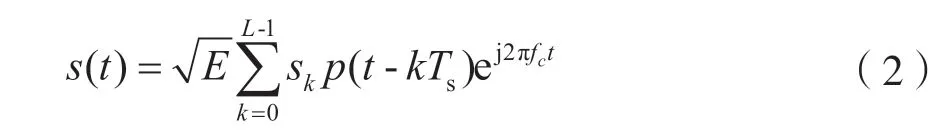
式中:E为信号能量;L为码元序列长度;sk为信号码元序列;p(t)为发送码元波形;Ts为码元宽度;fc为载波频率。
在接收端对信号进行下变频,匹配滤波等预处理,得到受衰落影响的基带符号序列。
莱斯分布,又称广义瑞利分布,其概率密度函数为:
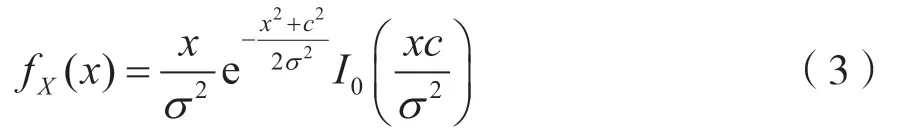
式中:c2表示镜像分量(直射分量)的功率;σ2表示散射分量的功率;I(·)表示第一类零阶贝塞尔函数。莱斯K因子定义为镜像分量和散射分量功率之比为:

此时,概率密度函数可由莱斯K因子表示为:
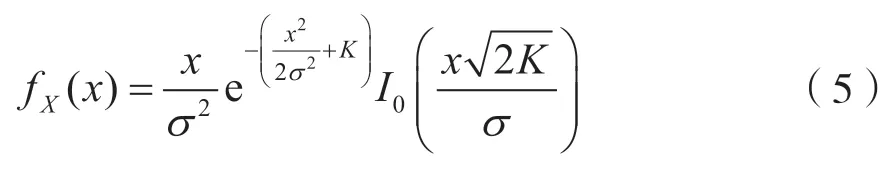
莱斯K因子决定了衰落程度,当莱斯K因子趋于零时(K<-40 dB),即不存在镜像分量的情况下,莱斯分布退化为瑞利分布;当莱斯K因子足够大时(K>15 dB),莱斯分布趋于高斯分布。图1 以1 000 个样点的16 正交振幅调制(Quadrature Amplitude Modulation,QAM)星座图为例,展示了相位偏移为0,信噪比分别为15 dB 和20 dB 时不同莱斯K因子对信号的影响。从图1 可以看出,莱斯衰落对信号的影响体现在两个方面:一是对信号的尺度进行了放缩,二是使信号的相位产生了偏移。进一步通过对比可以看出,随着信噪比的升高,星座图各点区分越发明显,在相同信噪比条件下,莱斯K因子越大,越接近理想信道下的星座图。

图1 受不同程度莱斯衰落影响的16QAM 信号星座
2 调制识别算法模型
2.1 RNN 模型
RNN 通常在处理序列信息时使用,能探索序列的顺序所蕴藏的信息。RNN 对序列中的所有元素做同类型的操作,并构建序列中先前元素的记忆,以预测下一个元素。典型的RNN包括LSTM网络和GRU网络。
LSTM 网络通过引入LSTM 块使梯度可以随时间变化而变化,从而让网络权重能根据输入信息动态变化,解决了传统循环神经网络因梯度消失问题导致的无法训练长期依赖信息问题。LSTM 块的内部结构如图2 所示,ft表示遗忘门,决定来自上一层的信息是否被记录;it表示输入门,决定该输入信息是否被使用;at表示产生备选信息的来源,用于更新记忆单元状态ct;ot表示输出门,决定输出给下一层的信息;ht表示隐藏状态。
输入门和输出门都只在需要过去的信息时才打开门并传播信号,从而实现有选择性地保存过去的信息。遗忘门的作用是接收从记忆单元传来的误差,在需要的时候“遗忘”记忆单元中保存的值从而实现对信息权值的控制。其具体实现过程为:
式中:W*、U*表示权重矩阵;b*表示偏置向量;sigmoid与tanh表示激活函数;“。”表示Hadamard积,又称为逐元素积。
通过以上运算,LSTM 将学习到的特征保存为记忆单元,根据训练情况将保存的记忆进行选择性的保留或者遗忘。在多次迭代后,留住了重要的特征信息,使得网络在处理具有长时间依赖的任务中有较好的性能表现。
GRU 网络也能训练长期依赖信息,且相较于LSTM 网络结构更为简单,运算时间更短。图3 展示了GRU 内部结构,它仅由重置门rt和更新门zt构成,重置门将储存信息与当前输入相结合,更新门根据训练情况更新储存的信息。
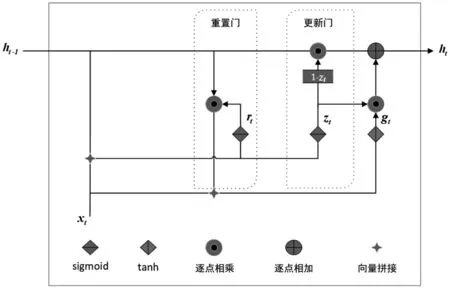
图3 GRU 内部结构
式(12)、式(13)、式(14)、式(15)展示了其具体的实现过程,从中可以看出,GRU 网络实现的功能与LSTM网络相似,但参数要少于LSTM网络。
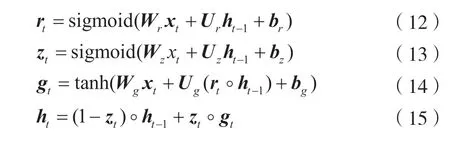
2.2 注意力机制双向门控循环单元神经网络模型
一般的RNN 都是以从过去到未来的单向流动为前提建立的模型。在有些情况下,如对有的时间序列数据进行分类时,双向循环神经网络(Bidirectional Recurrent Neural Network,BiRNN)能递归地反馈过去和未来的隐藏层状态,可获得更高的分类精度。注意力机制借鉴了人脑通过提取重要特征鉴别事物的方式,最初主要应用于图像识别领域,随着研究的深入,逐渐在文本分类、调制识别等不同领域流行。
图4 为文献[19]提出的改进的LSTM 模型结构,图5 展示了本文提出的注意力机制双向门控循环单元神经网络(Bidirectional Gated Recurrent Unit Neural Network,BiGRU)模型结构。通过对比可以看出,本方法将LSTM 层替换为BiGRU 层,且通过引入随机初始化并在训练中不断学习的向量uz来衡量BiGRU 网络提取的特征向量hi(i=1,2,…,N,N为神经元个数)的重要性。
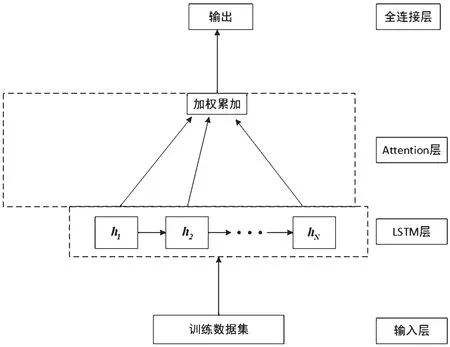
图4 改进的LSTM 模型结构
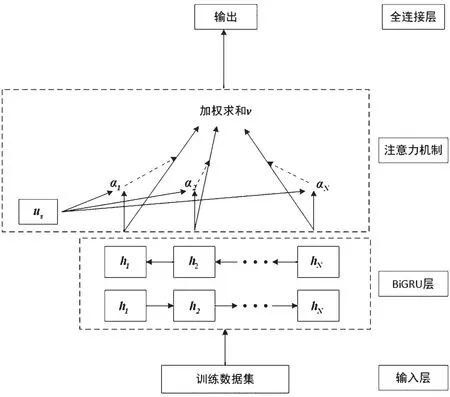
图5 注意力机制BiGRU 模型结构
分配权重的过程如式(16)、式(17)、式(18)所示,首先将神经元隐藏状态hi通过一个多层感知机(Multi-Layer Perception,MLP)获得其隐藏表示ui,然后结合uz通过softmax 函数获得权重αi,经加权求和得到最终的特征向量v,最后将该特征向量分别通过两层全连接层获得分类结果。
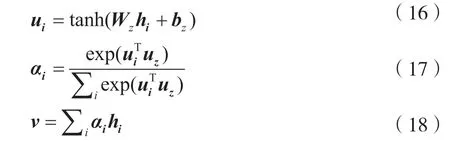
具体训练步骤如下文所述。
步骤1:初始化网络参数,其中全连接层第一层网络节点数为128,激励函数为ReLU,第二层网络节点数为输出类别数,激励函数为Softmax;
步骤2:将数据分批次送入神经网络进行训练,每批次训练的数据量为100 个信号序列(batch_size=100);
步骤3:BiGRU 层对数据进行特征提取,再由注意力机制为提取的特征合理分配权重获得新的特征向量,最后送入全连接层进行分类,同时为抑制过拟合,在BiGRU 层后添加Dropout 层,参数设置为0.5;
步骤4:采用多类别交叉熵为损失函数计算损失值,并通过自适应矩估计(Adam)对网络参数进行优化,其学习率为0.001,学习率更新参数为β1=0.900,β2=0.999,模糊因子为ε=10-8;
步骤5:将训练数据集的20%作为验证集,用于验证网络的训练效果,所有数据训练一轮为一次迭代,训练的停止条件为迭代次数达到100 次或者训练损失值连续10 次迭代没有改善。
步骤6:不满足停止条件则更新网络参数并跳至步骤2,否则停止训练,获得训练好的网络模型与分类结果。
3 实验仿真与分析
3.1 数据集
本文用MATLAB 对莱斯衰落影响下的2 进制振幅键控(Amplitude Shift Keying,ASK)、4ASK、正交相移键控(Quadrature Phase Shift Keying,QPSK)、8PSK、16 正交振幅调制(Quadrature Amplitude Modulation,QAM)以及64QAM 6 类信号进行仿真并产生相应的训练以及测试数据集。训练数据集中每类调制方式产生100 000 个带标签的信号序列,每个信号序列长度L=100,接收的第i个符号序列满足:
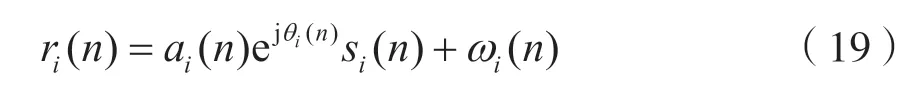
式 中:n=1,2,…,L;ωi(n)~CN(0,1);θ(n) 服 从[0,2π)之间的均匀分布;a(n)服从莱斯分布;同一符号序列ai(n)与θi(n)相同;不同符号序列之间ai(n)与θi(n)不同,每个符号序列的平均信噪比服从[-10 dB,30 dB]之间的均匀分布。
为了检验网络的实际效果,本文采用与训练数据集相同的信噪比范围,信噪比间隔为2 dB,且每类调制信号对应于相应信噪比采用蒙特卡洛方法产生的1 000 个符号序列作为测试数据集。
3.2 仿真与分析
本文的实验平台为Intel Core i5 10210U CPU,内存12 GB;数据集由MATLAB2019a 仿真产生;网络模型由基于TensorFlow 和Keras 的深度学习库搭建。
考虑到num_units是循环神经网络的核心参数,该参数决定了循环神经网络层的输出维度,对网络性能有重要影响,因此本文研究了该参数设置对模型调制识别性能的影响。以本文提出的模型为研究对象,采用莱斯K因子为5 dB 时产生的数据集,通过对网络核心参数num_units 设置不同的值比较其分类准确率获得合适参数,从而进行进一步研究。仿真结果如图6 所示,当该参数值小于40 时,参数值越大,识别准确率越高;当参数值大于40 时,准确率提升已不明显。考虑该参数值越大,网络所耗费的时间成本越高,在后续研究中将网络参数num_units 的值设置为40。
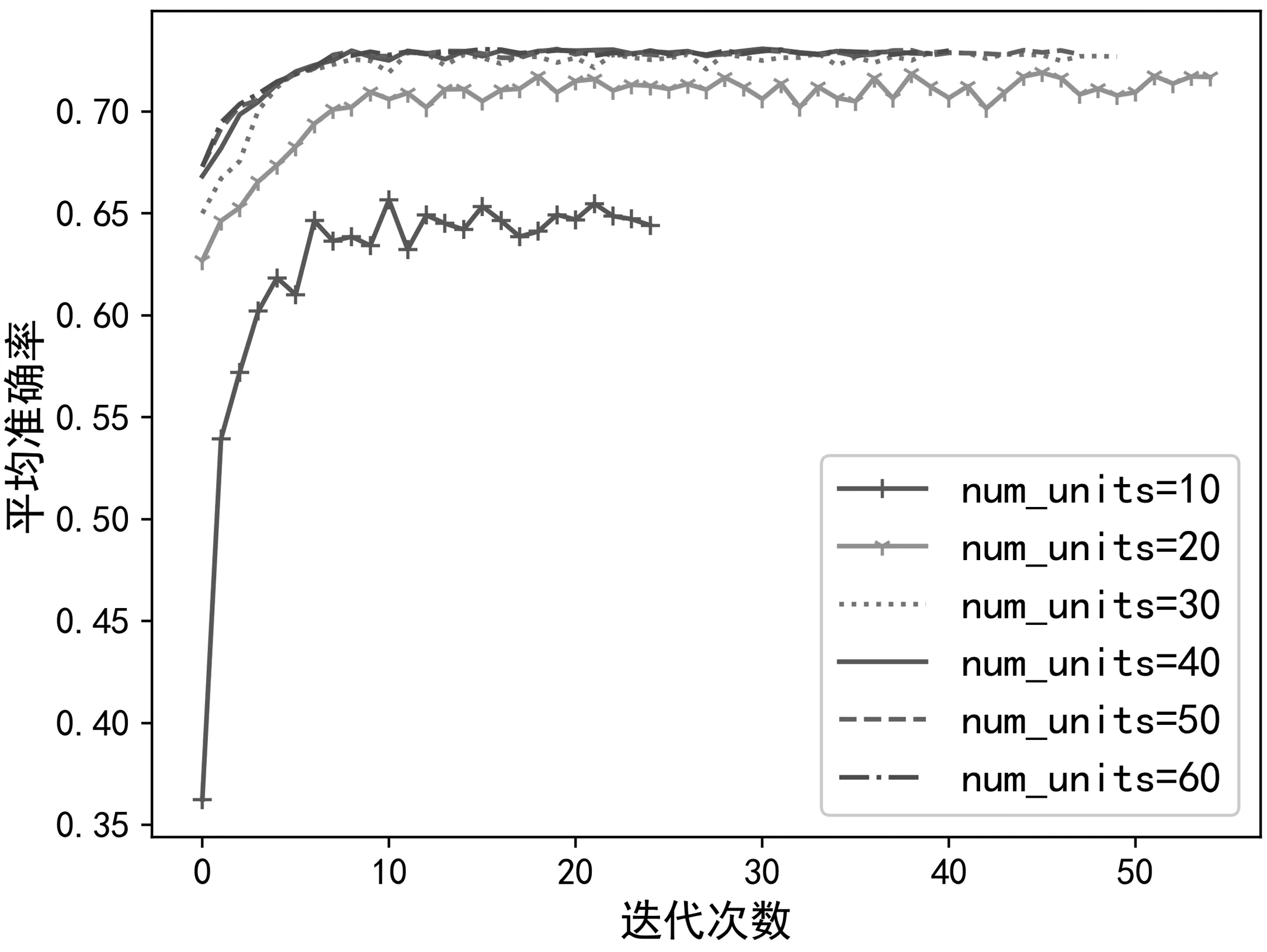
图6 不同参数下的识别准确率
确定关键参数后,为验证该模型是否具有比较优势,采用莱斯K因子为5 dB 时产生的数据集分别训练单层LSTM 模型和文献[19]中的改进的LSTM 网络模型(核心参数num_nuits 设置与本文一致),并比较各模型的分类性能。表1 对比了各种模型的计算复杂度,从中可以看出,模型1(LSTM模型)单次迭代时间最短,模型3(本文模型)次之,模型2(改进的LSTM)所需时间最长。为了比较各模型训练表现,图7 展示了不同模型的损失值。从图7 可以看出模型3 获得了较低的损失值,模型1 与模型2 分别在第7 次和第9 次迭代以后过拟合现象越来越突出,模型3 在第8 次迭代后也出现了过拟合现象,但相对于模型1 和模型2 而言过拟合程度不大,这是因为模型3 采用了双向循环神经网络。双向考虑,即进一步考虑从未来到过去的做法,比起单向考虑从过去到未来的时序关系,能提高模型的泛化能力,从而抑制过拟合的程度。图8 对比了不同模型的识别准确率,该准确率对应于该次迭代计算的网络模型参数下,获得的交叉验证数据集的平均识别准确率。从图7 中可以看出,模型3 具有更高的识别准确率。结合计算复杂度,训练表现以及识别准确率三方面因素,可以得出模型3 综合性能最优。
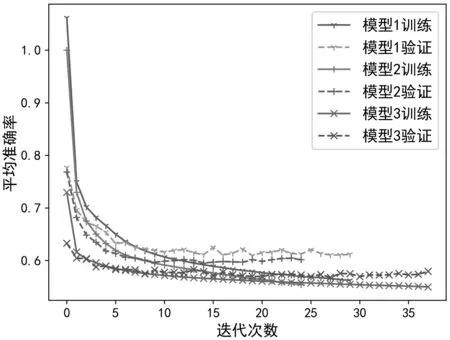
图7 不同模型损失值对比
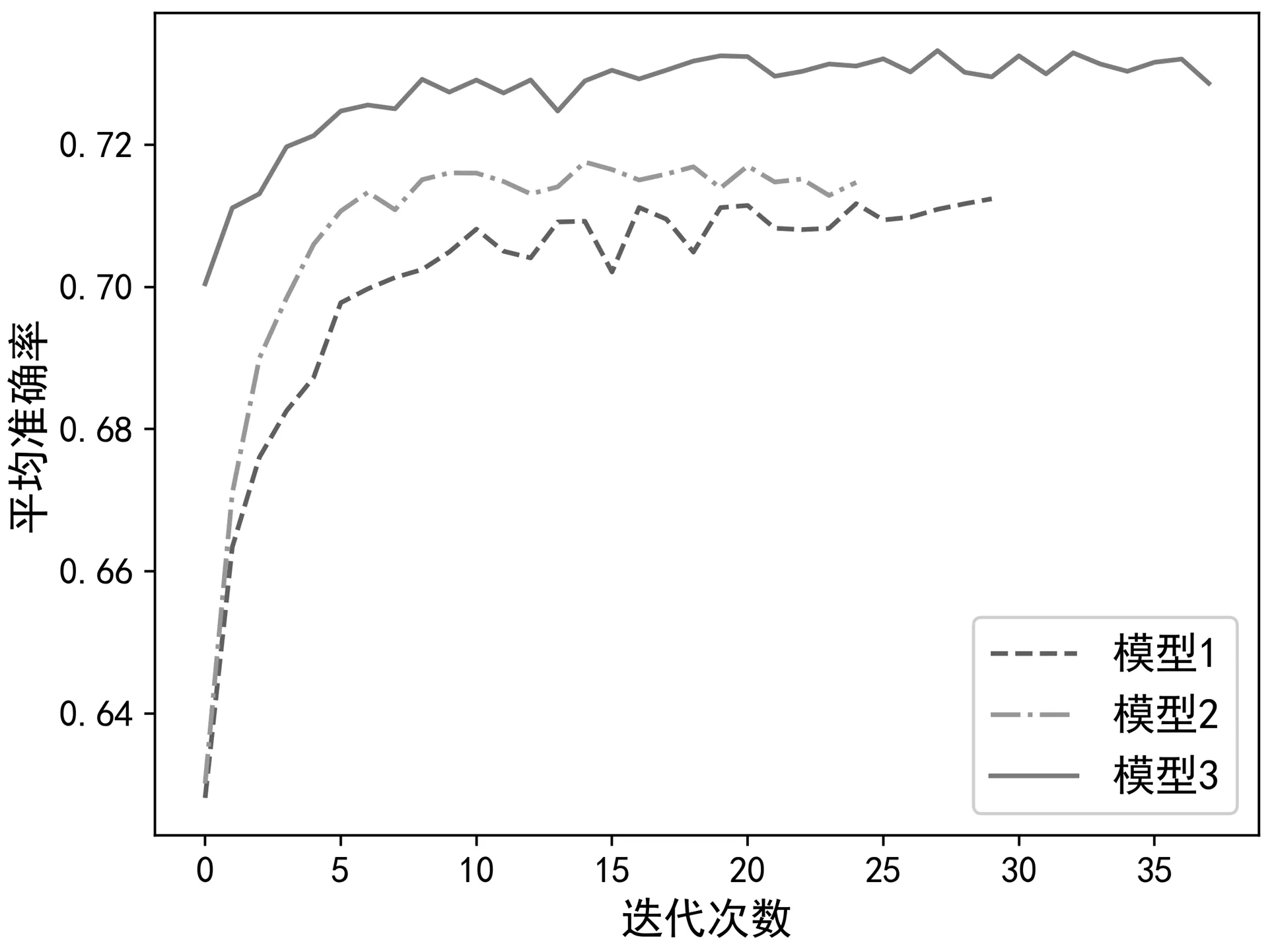
图8 不同模型识别率对比

表1 各模型计算复杂度对比
为进一步研究模型3 对莱斯衰落影响下信号的识别性能,本文进一步仿真产生了莱斯K因子为-40 dB、5 dB 和15 dB 时的调制信号数据集,并分析该模型对于不同莱斯衰落程度信号的识别性能。图9为不同莱斯衰落程度的数据集下各调制方式平均识别准确率随信噪比的变化图,从图中可以看出,随着信噪比的提升,信号调制识别的准确率逐渐上升,且莱斯K因子越大,分类性能越好。图10 展示了莱斯K因子为5 dB 的数据集下各类信号的识别准确率,从图中可以看出,信噪比较低时(SNR<0 dB),识别效果较差,错判较多。当信噪比大于14 dB时,除多进制正交幅度调制(Multiple Quadrature Amplitude Modulation,MQAM)信号外的识别准确率接近100%。随着信噪比进一步提高,MQAM 信号识别准确率提升明显。图11 进一步展示了莱斯K因子为5 dB 的数据集下信噪比为8 dB 时该模型的识别混淆矩阵,从中可以看出,在该信噪比下,调制方式分类的难点在于16QAM 信号与64QAM 信号,二者之间存在严重的误判,原因在于二者星座图具有一定的相似性,再加上受莱斯衰落影响,一定程度上增加了误判的可能性。
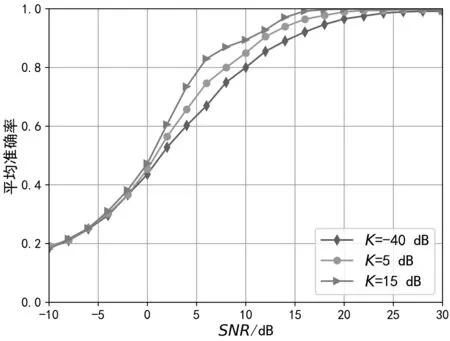
图9 不同莱斯衰落程度平均识别准确率对比
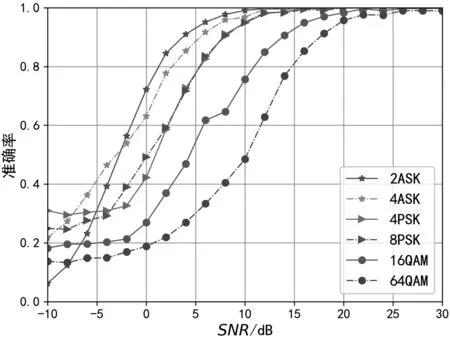
图10 各类信号识别准确率
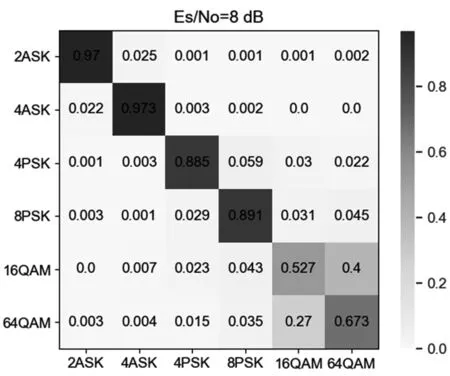
图11 混淆矩阵
4 结语
本文以莱斯衰落影响下的6 种数字调制信号为研究对象,探讨了一种基于注意力机制的BiGRU 模型的调制识别性能。实验结果表明,与单层LSTM 模型以及一种改进的LSTM 模型相比,本文提出的模型在训练表现、识别准确率等方面均具有优势。
