基于CNN和BiLSTM的钓鱼URL检测技术研究
2021-12-14卜佑军张稣荣王方玉
卜佑军, 张 桥,, 陈 博, 张稣荣, 王方玉
(1.中国人民解放军战略支援部队信息工程大学,河南 郑州 450001; 2.郑州大学 中原网络安全研究院,河南 郑州 450001)
0 引言
近年来,互联网快速发展,在线购物、电子商务和网络社交等基于互联网的应用给人们的工作和生活带来了极大的便利。据中国互联网络信息中心CNNIC统计,截至2020年3月,中国网民规模达到了9.04亿,互联网普及率达到了64.5%[1]。与此同时,网民信息亦面临着安全威胁,如网络攻击者通过网络钓鱼窃取个人敏感信息进而非法获取经济利益。截至2020年8月,中国反钓鱼联盟累计认定的钓鱼网站数量达到了469 252个[2]。因此,如何及时、有效地检测钓鱼网站已经成为亟待解决的问题。
目前,针对网络钓鱼,黑名单方法只需进行简单的数据库查询操作,是一种较为简单的检测方法。Malware Domain List和PhishTank这2种算法使用的都是基于黑名单的检测方法[3-4]。然而目前网址生成算法比较成熟,每天都会出现大量的钓鱼网址,黑名单数据库无法及时包含所有的钓鱼网址。根据Sheng等[5]的研究,约47%~83%的钓鱼网址在钓鱼事件发生12 h之后才被列入黑名单中。Aleroud等[6]指出约有93%的钓鱼网址没有被主流的黑名单收录。基于黑名单检测钓鱼网页的局限性在于要不断收集钓鱼网址样本并及时更新黑名单数据库。
针对黑名单方法存在的局限性,有研究人员使用机器学习方法来检测钓鱼网页。Liu等[7]提取网页内链接关系、敏感词排序等特征,利用机器学习识别钓鱼网页,取得了较高的准确率及较低的误报率,实验结果表明,该方法可以识别91.44%钓鱼网页。Ma等[8]利用机器学习在多个公开数据集上测试,实验结果表明,该方法的检测准确率达到了94%。该类方法使用机器学习技术达到了较高的检测准确率且能够识别未知的钓鱼网页,但也存在较大的局限性:①需要大量的手动特征工程,其中许多特征需要相关专家来确认;②需要获取网页内容,增加了客户端开销和风险且检测算法的时间复杂度高;③有些钓鱼网站能够隐藏其网页内容,即向不同的客户端提供不同的内容[9],比如,钓鱼网站可能会将合法页面发送给蜜罐客户端,但将钓鱼网页发送给其他人工访问客户端。
为了克服上述2种检测方法的弊端,已有研究者使用了深度学习技术,通过自动提取URL特征来判别其所属类别,以检测其对应网页是否为钓鱼网页。Kim[10]于2014年利用CNN对文本进行分类,实验结果表明,CNN在文本上具有较强的分类能力。此后有一些研究人员尝试使用CNN对钓鱼URL进行检测。Zhang等[11]利用单词级别的卷积神经网络对URL进行分类,即根据特殊字符对数据集中的URL进行单词级别的划分并形成一个语料库。训练语料库中的每个单词表示为一个向量,然后将待测URL分词,获取单词的向量表示并组合形成一个向量矩阵输入到卷积神经网络中来判断相应的URL所属类型。Cui等[12]利用字符级别的卷积神经网络检测恶意URL,即将URL按字符划分,获取每个字符的向量且组合形成一个向量矩阵,然后将此矩阵输入到卷积神经网络中来判断相应的URL所属类型。Yu等[13]在对恶意域名的检测实验中对比了多种深度学习模型,如CNN、RNN,在这些实验中,基于深度学习的检测方法均优于基于手工特征的传统机器学习方法。
虽然上述工作已经取得了较好的表现,但仍然存在以下3个问题:①基于单词划分URL在测试时无法获得新出现的单词的嵌入向量,基于字符划分URL会导致URL中一些特有的敏感词丢失有效信息;②无法获取特殊字符的分布与类型及与周围词的前后关系;③URL是一种序列数据,数据之间存在着长距离依赖关系, CNN无法获取URL数据的长距离依赖关系。
针对以上问题,本文提出了一种基于卷积神经网络(convolution neural network,CNN)和双向长短记忆网络(bi-directional long short-term me-mory, BiLSTM)的钓鱼URL检测方法CNN-BiLSTM。该方法通过CNN来获取URL的空间局部特征,通过BiLSTM获取URL的长距离依赖特征。此外,对URL的分词方法做了改进,提出了一种基于敏感词分词的方法,有效提升了URL数据信息的利用程度。实验中通过与传统机器学习方法和单一模型的比较表明了所提方法的有效性。
1 字符词向量
深度学习模型只能处理经过数值化的向量,因此在对URL数据提取特征时需要先将其分词、编码并转化为d维词向量,用不同词在d维空间的距离来表示它们之间的语义相似度。当前使用深度学习方法检测URL常用的分词方法有基于单词划分URL和基于字符划分URL 2种。
基于单词划分URL使其转化为单词级词向量,利用特殊字符分割URL可能会使单词的数量相当大,造成该数据集的特征也按比例增大,通常会大于相应训练数据集中URL的数量,导致在进行特征向量的转换时内存受到限制,在测试集上无法获得新出现单词的嵌入向量。
相比于按单词划分URL,基于字符划分URL使URL转化为字符级词向量能够在测试集上获得新的URL的嵌入向量,避免了无法从不可见的单词中提取特征的问题。另外由于字符总数是固定的,在进行特征向量的转换时不会受到内存的限制且字符级分类器的大小保持固定。但是将URL划分为单个的字符会导致一些敏感词如login、password、registed等丢失部分有效信息,因此,根据字符划分URL不足以使神经网络分类器从URL字符串中获取较为全面的信息。
针对上述分词方法存在的问题,本文提出了一种基于敏感词分词的方法,如表1中以网址www.ccd.cn.bank.com为例。首先根据特殊字符和敏感词对URL进行单词级别划分,并将特殊字符看作单词处理以获得特殊字符的有效信息。然后对其中的非敏感词进行字符级别划分,而将其中的敏感词作为一个整体与其余字符进行区分,这样能够明显标记URL中的重点信息,有利于神经网络分类器提取更具有代表性的特征。

表1 URL的3种分词方法Table 1 Three methods of URL segmentation
2 模型结构
基于CNN-BiLSTM检测URL类别的模型框架包括4个部分。URL输入依次经过词嵌入层、卷积神经网络层、循环神经网络层和全连接层,最终输出URL的分类结果。其中循环神经网络层采用长短期记忆网络, 各层网络的细节如下所述。
2.1 词嵌入层
URL本质上是由一系列字符或由特殊字符分隔的单词组成。词嵌入层将U转换为神经网络能够识别的特征向量,即得到它的嵌入矩阵表示U→X∈RL×K,使得矩阵X包含一组相邻分量xi(i=1,2,…,L),其中xi为URL中的字符或单词的向量表示,xi∈RK为K维向量。本文根据URL数据集和敏感词汇表(account,admin,administrator, auth,bank,client,confirm,cmd,email host,login, password,pay,private,registed,safe,secure,security, sign,service,signin,submit,user,update,validation, verification,webscr)确定每条URL中字符及关键字的总长度L为300。若L超过300,则在URL末尾将多余的字符截断;若L小于300,则在其末尾用
U′=(u′1,u′2,…,u′300)。
(1)
式中:u′i为URL中字符或单词的编码。
随后将矩阵U′经词嵌入层转换为300×64的包含语义信息的二维稠密矩阵X,作为卷积层的输入,如式(2)所示:
X=(x1,x2,…,x300)。
(2)
式中:xi是64维列向量。
2.2 卷积网络层
如图1所示,将词向量矩阵输入到卷积神经网络中,通过卷积核从特征矩阵中自动提取局部特征,卷积核高度h设置为2,宽度与字符向量的维度一致为64,卷积核的数量为200,卷积核滑动步长设置为1。对于某个卷积核f在第i个滑动窗口处获取的URL嵌入矩阵设为Xi:
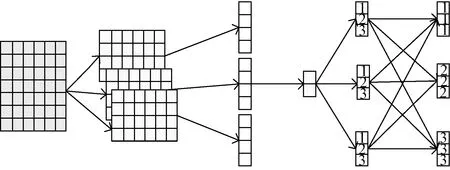
图1 卷积层网络结构Figure 1 Convolution layer structure
Xi=[xi,xi+1,…,xi+h-1]。
(3)
式中:xi为字符或敏感词的向量表示。
(4)
式中:Wf和bf分别为权重矩阵和偏置项;σ(·)为激活函数, 使神经网络具有拟合非线性函数的能力。
卷积核遍历整个嵌入矩阵后产生一个特征图,记为cf:
(5)
将X经所有卷积核卷积池化后得到的新特征图堆叠得到一个序列矩阵,记为M:
M=[m1,m2,…,ms]。
(6)
式中:s=「(L-h+1)/pl⎤,pl为池化窗口;mi为所有卷积核对URL词嵌入矩阵的同一区域经卷积、池化操作后的特征所组成的特征向量,mi∈Rn×1,n为卷积核个数。
2.3 BiLSTM层
双向长短记忆网络BiLSTM由2个方向相反的LSTM组成,二者网络结构相同,但权重参数不同。LSTM是RNN的一种变体,RNN由于梯度消失或梯度爆炸的原因只能获取短距离依赖信息,LSTM通过在网络节点上加上门结构以控制数据流动,避免梯度消失或梯度爆炸的问题。LSTM有3个门,自左向右分别为遗忘门、输入门、输出门,如图2所示。每个门都由一个激活函数σ(·)和一个点乘操作组成,其中σ(·)输出0~1的数值,描述了数据通过此门的比例程度,正向 LSTM 依时间顺序读入数据,以使信息沿时间起点正向传递,从而获取序列的前文信息,分为以下4个步骤。
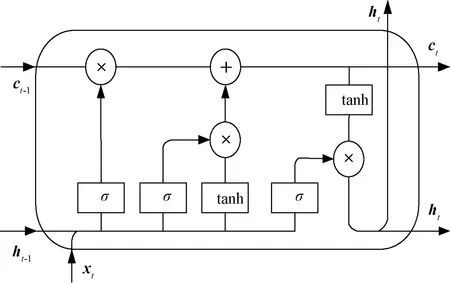
图2 LSTM网络结构Figure 2 LSTM network structure
步骤1通过遗忘门从(t-1)时刻的细胞状态ct-1中丢弃一定比例的信息。遗忘门t时刻的值为
ft=σ(wf·[ht-1,xt]+bf)。
(7)
式中:wf为遗忘门权重矩阵;bf为遗忘门偏置;ht-1为(t-1)时刻的隐藏状态。
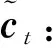
it=σ(wi·[ht-1,xt]+bi);
(8)
(9)
步骤3更新(t-1)时刻的细胞状态ct-1,计算t时刻的细胞状态。首先利用旧细胞状态与遗忘门输出点乘以丢弃旧细胞的部分信息,然后利用临时细胞状态与输入门输出点乘以得到需要加入细胞的新信息,最后利用二者的和得到新的细胞状态ct:
(10)
步骤4通过输出门的σ层计算输出比例ot,然后将新的细胞状态输入tanh层进行处理,最后将二者进行点乘操作得到t时刻输出的值ht:
ot=σ(wo·[ht-1,xt]+bo);
(11)
ht=ot⊗tanhct。
(12)
细胞状态ct水平方向自左向右移动,新的细胞状态是旧细胞状态的累加。这种细胞状态的累加方式会导致对神经网络进行训练时其导数也是一种累加形式而不是累乘,避免梯度消失或梯度爆炸的问题,能够对之前的信息进行长期记忆。逆向LSTM则沿时间终点逆向传递以获取序列的下文信息,信息传递过程与正向LSTM类似。
本文将卷积网络层的输出M看作时间轴上的序列信息作为BiLSTM的输入,mi与BiLSTM第i个时刻的输入对应。正向LSTM通过遗忘门、输入门、输出门来记忆i=s时刻之前的信息,将此时刻的输出记为hF。反向LSTM通过遗忘门、输入门、输出门来记忆i=1时刻之后的信息,将此时刻的输出记为hR。将2个不同方向的LSTM最后时刻的输出进行拼接,记为h=hF⊕hR(⊕表示拼接运算符),以获取URL不同方向的长距离依赖特征。
2.4 全连接层
全连接层用于完成最终的分类功能,本文将其网络层数设置为1,神经元个数设置为2,通过softmax激活函数计算待测URL属于钓鱼或合法网页的概率:
(13)
式中:zi=wih+bi,wi和bi分别为权重和偏置参数;i为URL类别索引(0表示钓鱼URL,1表示合法URL);k为URL类别总数,值为2。
2.5 模型实现
首先基于敏感词分词方法对URL进行分词,并对分词后的数据进行整数编码,将其映射为300×1的一维矩阵;通过词嵌入层转换为300×64的二维稠密矩阵;通过一个卷积层进行卷积操作,并使用最大池化窗口获取更具有代表性的特征,实验中采用的卷积核个数为200,池化窗口为2,滑动步长为1,将所有卷积核对词嵌入矩阵经卷积池化后形成的特征图按列堆叠形成200×298的矩阵,将其每行作为BiLSTM层对应时刻的输入;利用BiLSTM的双向网络结构获取序列数据的上下文信息,充分学习特征之间的长距离依赖关系,实验中该网络的隐藏层神经元个数设置为64,经过该网络后,特征矩阵被转化为一个128维的向量;最后使用全连接层中的softmax函数将BiLSTM层输出的向量转换为URL属于合法或钓鱼的概率,根据交叉熵损失函数计算概率值和真实值之间的损失,通过反向传播算法更新网络模型参数。模型的整体结构如图3所示。
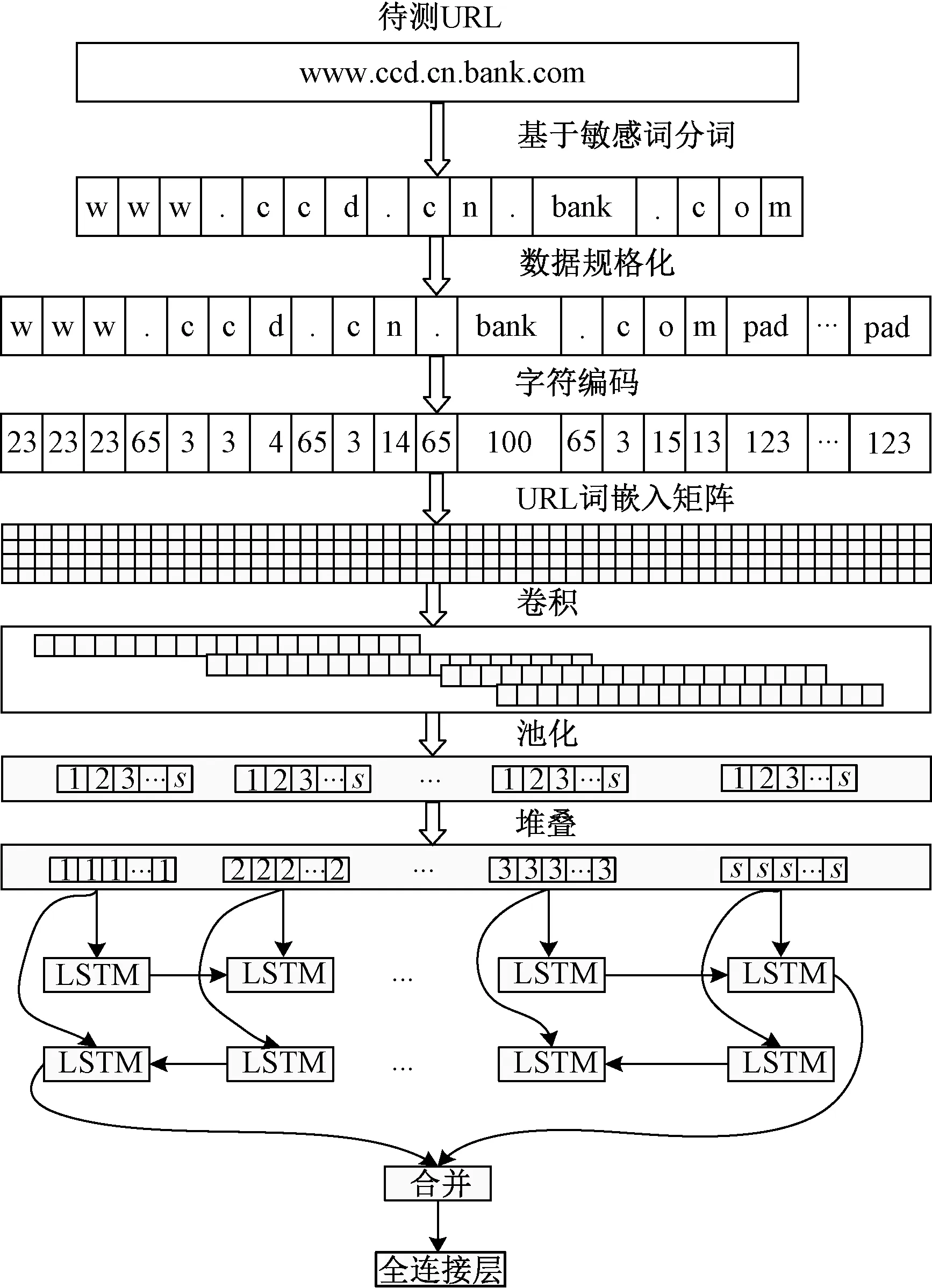
图3 CNN-BiLSTM网络结构Figure 3 CNN-BiLSTM network structure
3 实验部分
3.1 实验数据
本文采用的数据集包括多个平台提供的开源样本,从PhishTank和Malware Patrol获取钓鱼URL,从Dmoz和Alexa获取合法URL,以此来丰富URL数据的来源。对数据去重后,数据集中共包含206 200条带标签的URL样本,其中钓鱼样本105 100条,合法样本101 100条,二者比例约为1∶1。
3.2 评估标准
本文为了验证钓鱼网页检测方法的有效性,采用准确率Accuracy、精确率Precision、召回率Recall和F1值作为评价指标。Precision表示被正确判断为钓鱼网页类别的网页占全部被判断为钓鱼网页类别的网页的比重,体现了检测方法对合法网页的区分能力,Recall则体现了对钓鱼网页的识别能力,F1值同时考虑到了精确率和准确率,是二者的加权平均,能综合评估检测模型的性能。计算式为
Accuracy=(TP+TN)/(TP+FP+TN+FN);
(14)
Precision=TP/(TP+FP);
(15)
Recall=TP/(TP+FN);
(16)
F1=2·Precision·Recall/(Precision+Recall)。
(17)
式中:TP表示预测的钓鱼网页实际为钓鱼网页的数量;FP表示预测的钓鱼网页实际为合法网页的数量;TN表示预测的合法网页实际为合法网页的数量;FN表示预测的合法网页实际为钓鱼网页的数量。
3.3 实验结果与分析
3.3.1 CNN-BiLSTM在数据集上的准确率
本文对URL数据集采用十折交叉验证法,即将样本分为10组,其中1组包含10 510条钓鱼URL和10 110条合法URL作为测试集,另外9组包含94 590条钓鱼URL和90 990条合法URL作为训练集,该过程循环10次,保证每组样本数据都能作为测试集预测,将得到的10次测试结果取平均值评测模型的检测能力。图4是本文所提模型在十折交叉验证下,其准确率在训练集和测试集上的平均变化曲线。从图4中可以看出,训练过程中模型的参数收敛正常,当训练轮数为30时,模型的训练、测试准确率趋于稳定。
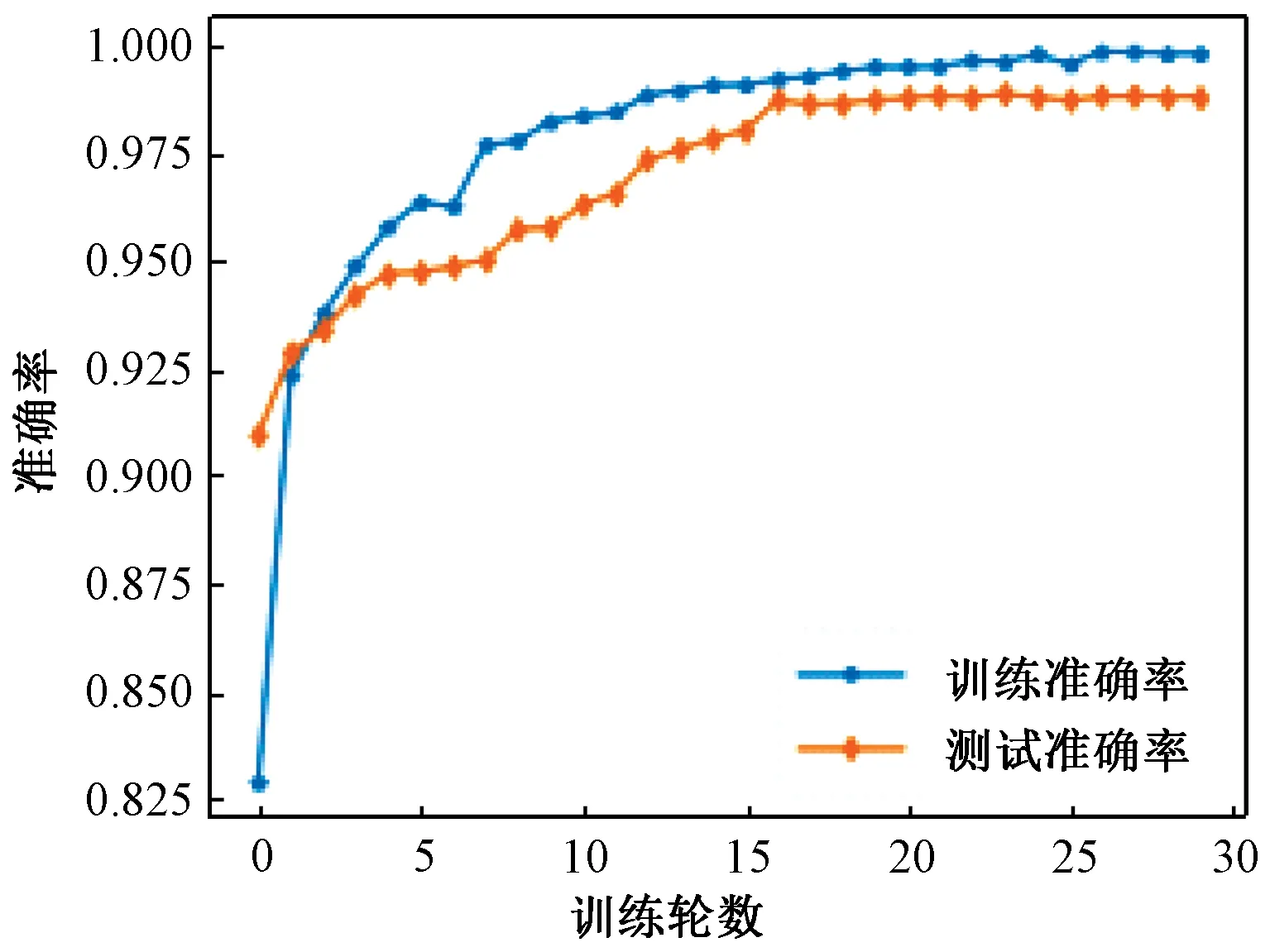
图4 CNN-BiLSTM在训练集和测试集上的准确率变化曲线Figure 4 Accuracy curve of CNN-BiLSTM on training set and test set
3.3.2 不同模型在数据集上的检测效果
为了体现基于敏感词(sensitive word)分词方法的有效性,首先通过对URL数据采用3种不同的分词方法来训练CNN模型,分别为基于字符划分URL的字符级CNN模型char-CNN、基于单词划分URL的词级CNN模型word-CNN、基于敏感词划分URL的敏感词级CNN模型sw-CNN,观察它们在测试集上的检测效果,如表2所示。与char-CNN、word-CNN相比,sw-CNN在准确率、精确率、召回率和F1值这4个评估指标上均达到较好的检测效果,这表明本文所提出的基于敏感词分词的方法能够有效提升检测模型对钓鱼URL的检测能力。
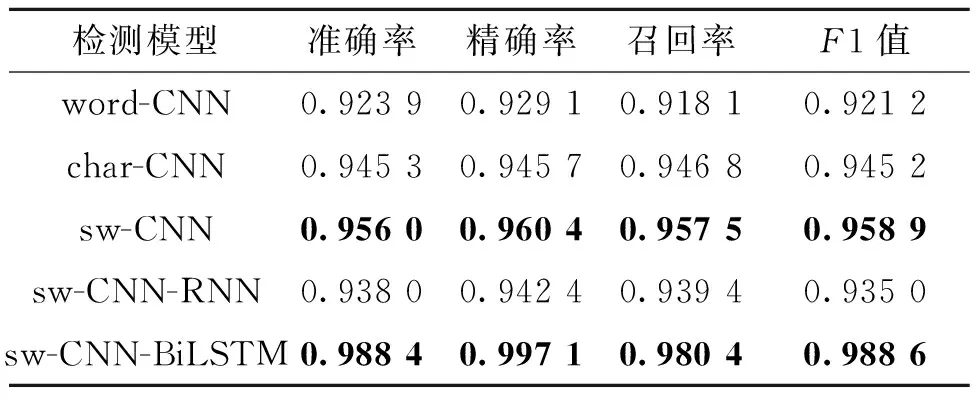
表2 所有模型在测试集上的最终检测结果Table 2 Final test results of all models on test set
此外,为体现检测模型CNN-BiLSTM的优势,将其与深度学习模型CNN、CNN-RNN对比,通过对URL数据采用敏感词分词的方法来训练生成2个检测模型sw-CNN-RNN、sw-CNN-BiLSTM,观察它们在测试集上的检测效果,如表2所示,同时对这些模型在训练集与测试集的准确率做了记录,如图5、6所示。结合表2、图5、图6可以看出,本文所涉及的5种检测模型在相同数据集上均获得了较高的检测准确率。其中,检测模型char-CNN在训练集及测试集上刚开始就达到了较高的准确率,但随着训练轮数的增加,准确率的提升程度不大。word-CNN在训练集与验证集上的准确率变化曲线与char-CNN类似,但准确率低于char-CNN模型,该结果可能源于以下3个方面:①通过“.”“”“?”等特殊字符对URL分词时忽略了特殊字符所具有的有效信息;②为了避免内存受限,将数据集中仅出现一次的单词统一标记为
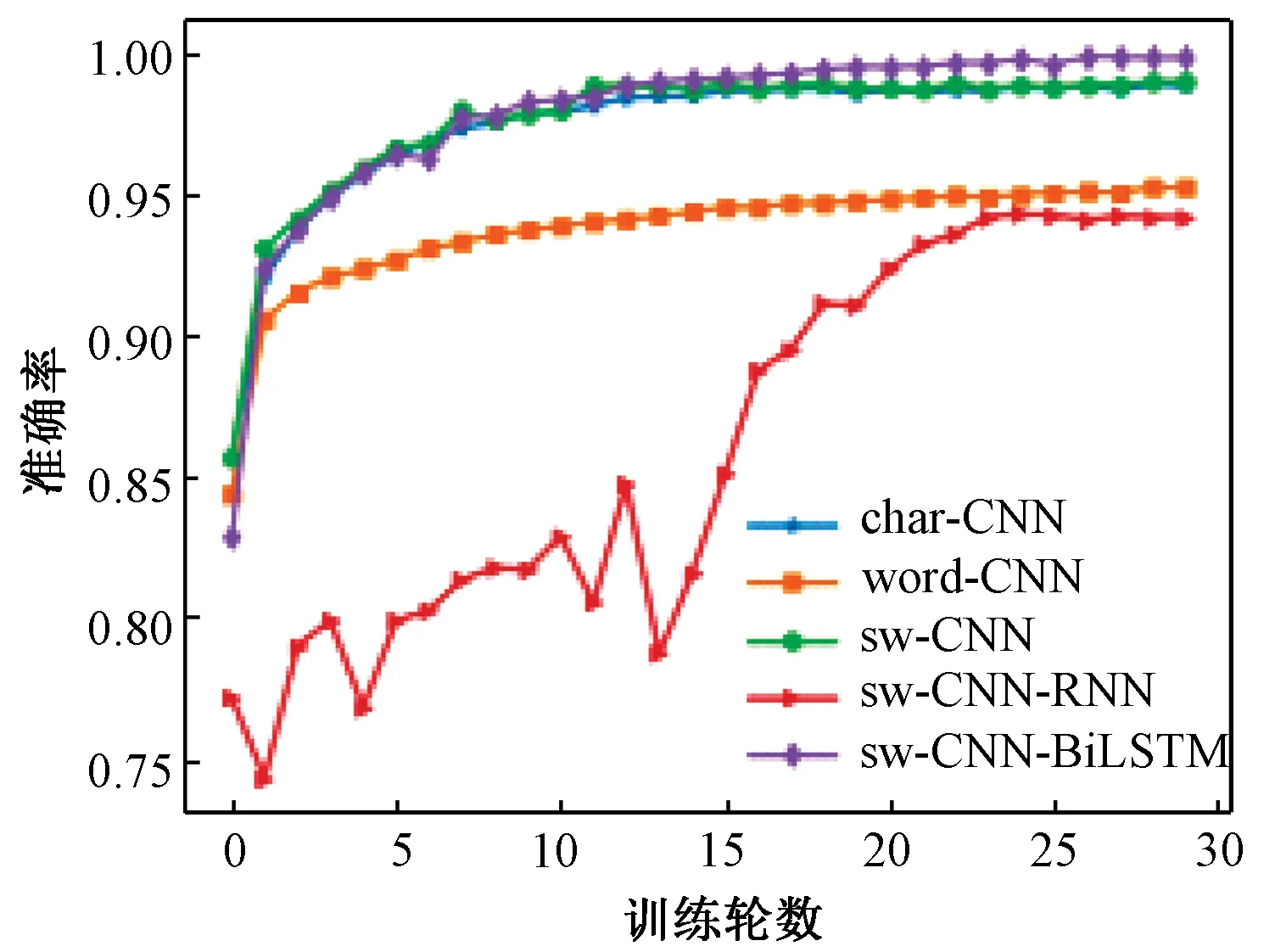
图5 不同模型在训练集上的准确率Figure 5 Accuracy of different models on training set
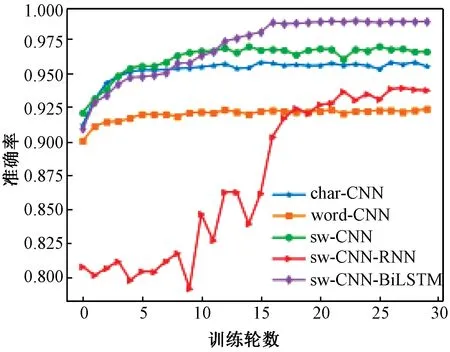
图6 不同模型在测试集上的准确率Figure 6 Accuracy of different models on test set
sw-CNN-RNN虽然采用混合网络模型用于提取URL特征,但由于RNN无法获取到URL的长距离依赖特征,反而导致其检测准确率低于单模型结构的char-CNN和sw-CNN。检测模型sw-CNN-BiLSTM相比以上模型能够获取到更为充分的URL特征,达到了最高的检测准确率、精确率、召回率和F1值。
3.3.3 不同模型对不同长度的URL的检测效果
另外,在实验过程中发现,sw-CNN-BiLSTM对URL短字符串也有较好的检测效果。为了研究其对短字符串的检测性能,在相同的实验环境下,将URL长度分别设置为15、25、50、100、200、300、400,观察其检测效果,结果如图7所示。在URL长度降至15时,sw-CNN-BiLSTM的检测准确率也能达到87%,而sw-CNN-RNN、sw-CNN与word-CNN的准确率分别为72%、78%、70%。实验结果表明,sw-CNN-BiLSTM对URL短链接也有较好的检测效果。
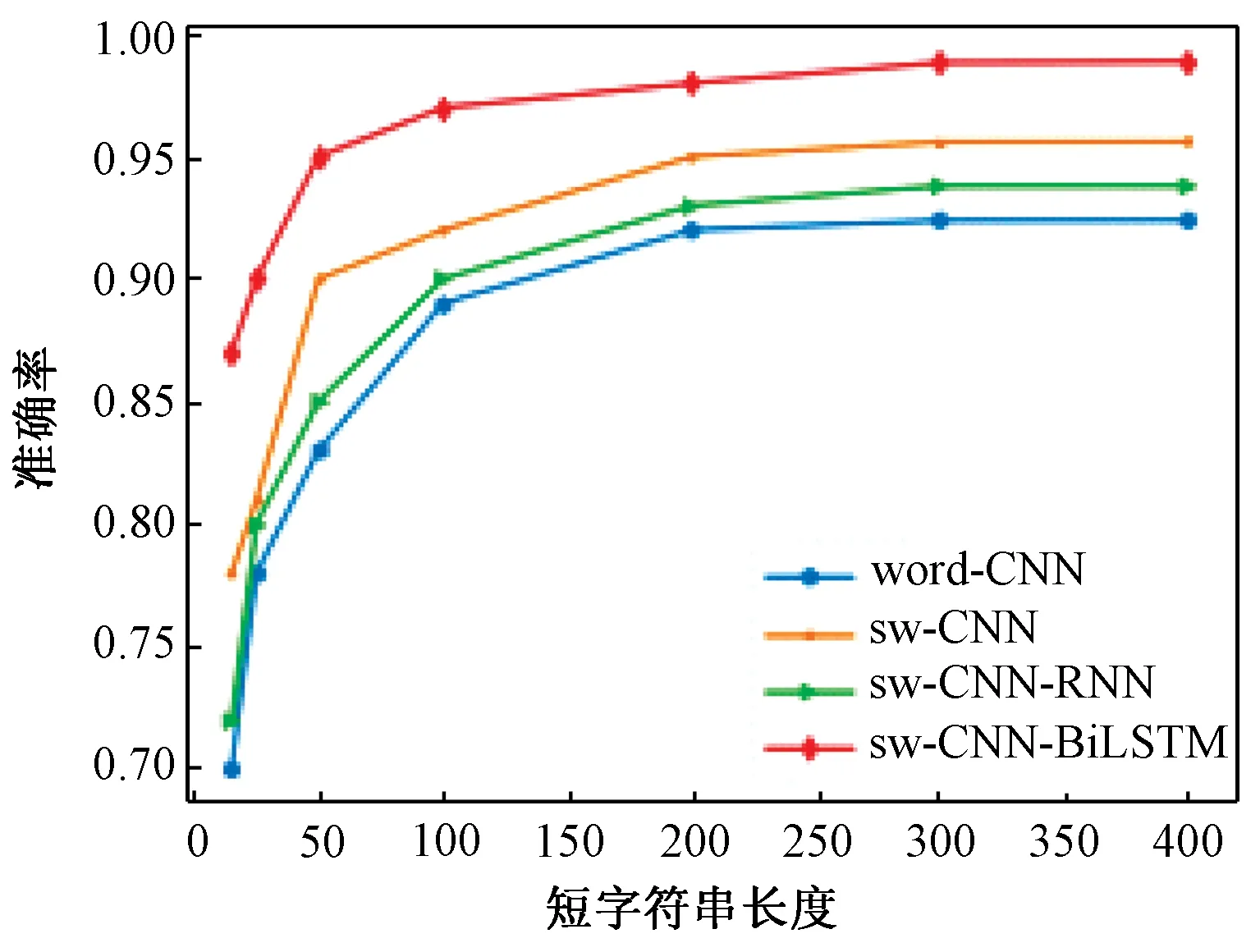
图7 不同模型在测试集上对不同长度的URL的检测准确率Figure 7 Detection accuracy of different models for URL of different length on test set
4 结论
(1)提出了一种融合CNN与BiLSTM的检测模型,该模型能够兼顾CNN和BiLSTM的特点,充分提取URL数据的空间局部特征及长距离依赖特征。
(2)提出了一种基于敏感词分词的方法,该方法能够获取新出现单词的嵌入向量,也能获取URL中敏感词、特殊字符的有效信息,提升了URL数据信息的利用程度。
(3)在数据集上的实验结果表明,本文所提出的基于CNN-BiLSTM的钓鱼URL检测方法可以有效提升对钓鱼网页检测的能力。
