基于Python 的政府开放数据可视化应用研究
2021-12-14侯瑾菲梁艺多
侯瑾菲 梁艺多
(大连外国语大学软件学院,辽宁大连 116044)
1 概述
自美国政府于2009 年掀起开放政府数据运动后,世界各国竞相跟进,这一理念也逐渐成为全球关注焦点。我国的上海市于2012 年6 月首次上线了“上海市政府数据服务网”,随后北京、广东、武汉等地也陆续展开行动。截至2020 年底,我国已有140 多个省级、副省级和地级政府上线了数据开放平台。随着各地开放数据集的不断增多,“如何高效利用政府开放数据”的问题也逐渐引起业界学者的广泛思考。陈美强调“政府数据开放利用能够推动信息内容产业和信息服务业发展”[1]。范佳佳对全球53 个国家的政府开放数据利用效率进行评估并给出排名[2]。周文泓等基于对应用开发的调查讨论了我国地方政府开放数据利用进展并提出优化策略[3]。宋卿清等对国内外政府数据开发利用的进展情况进行总结并提出对我国的政策建议[4]。吕富生讨论了政府数据再利用的“限制型”模式和“开放型”模式并给出可行路径[5]。可见,现有研究都是从宏观角度分析与讨论政府数据开放利用的整体情况、实施路径和政策建议等,并未从微观角度即数据本身出发研究政府开放数据的具体应用工具、方法、过程和效果等。近年来,随着人工智能的发展,Python 语言获得了学术界和产业界的极大关注,被广泛应用于网络爬虫、数据分析、机器学习、自然语言处理等领域。因此,本文将采用Python 网络爬虫和数据分析技术,以政府数据开放平台中的幼儿教育数据为例,从数据利用的微观视角开展数据的获取及可视化分析,并针对分析结果提出一定启示,为开放政府数据应用问题的研究提供一个全新的思路和参考。
2 实验方案设计
2.1 数据来源
本文选取广州市政府数据开放平台作为调研的目标平台。该平台于2016 年10 月起试运行,截至目前,共有63 个政府部门参与数据开放,为大众提供有关经济发展、教育科技和资源环境等16 个主题分类的数据,数据集总数为1520 个,数据总量共计1.44 亿条。其中,教育类主题数据集为97 个。本文以幼儿教育数据为例,采集包括广州市白云区、花都区和从化区等11个区在内的幼儿园数据,将其作为可视化分析的目标对象。
2.2 步骤设计
应用Python 工具采集开放政府数据的过程为:首先,爬虫程序借助Requests 库对目标数据集中以HTML 格式保存的介绍页面和以JSON 格式保存的表格数据分别进行爬取。其次,使用Beautiful Soup 库提取介绍页面HTML 文件中有关数据表格的标题、表头以及数据总数等信息,并将其写入CSV 文件。再次,使用JSON 库提取以JSON 格式保存的表格数据记录,并将其写入CSV 文件。最后,使用Matplotlib 库对数据结果可视化。实验的整体步骤如图1 所示。
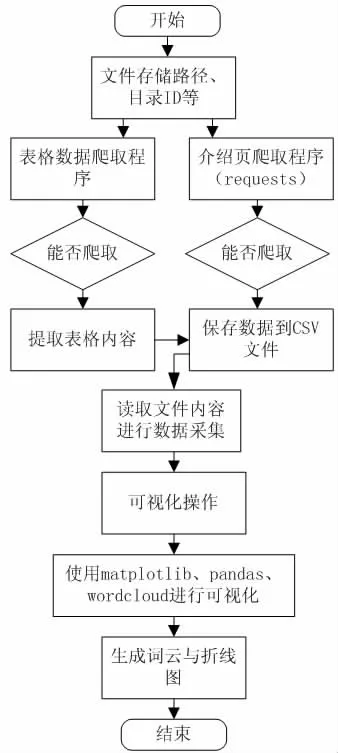
图1 实验的整体步骤
3 采集过程实现
3.1 获取JSON 格式数据
在从“广州市政府数据统一开放平台”网站爬取“广州市各区幼儿园一览表”数据时,首先需要定义Headers 等初始数据,并使用Requests 获取JSON 格式的表格数据。相关代码如下:

3.2 从JSON 中提取信息
从JSON 格式的广州市各区幼儿园一览表中提取列信息,包括:年份、行政区域、幼儿园名称、地址、联系电话、以及办园性质等。相关代码如下:

3.3 把信息存入CSV 文件
把提取的“广州市各区幼儿园一览表”的各列数据存入到CSV 文件中。相关代码如下:
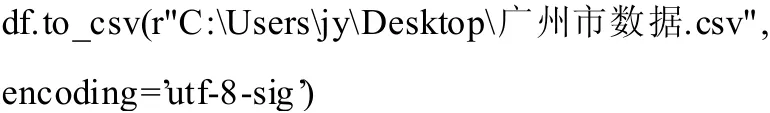
3.4 程序整体框架及采集结果
将上述功能进行组合进而形成程序整体框架。相关代码如下:

过以上方法,本次共采集到广州市各个区的幼儿园数据1741 条,所有数据均保存在CSV 文件,且该文件将作为下一步数据可视化分析应用的数据来源和处理对象。
4 可视化应用实现
4.1 词云图的绘制
此模块将使用词云图来生成重要关键词。首先,使用Python的Jieba 分词做分词处理。之后,使用Python 的wordcloud 库生成词云图,在此步中将会创建一个词云对象,并输入所生成云图的长、宽、背景颜色以及中文词库等。最后,使用Python 的matplotlib 库进行可视化绘图。相关代码如下:

生成的词云如图2 所示。

图2 词云图
4.2 人口数与幼儿园数量的可视化分析
据调查,广州市的常住人口为1490.44 万人。其中,白云区人口最多,为271.44 万人,番禺区为177.7 万人,海珠区为169.36 万人,天河区为174.66 万人,增城区为121.85 万人,越秀区为117.89 万人,荔湾区为97 万人,花都区为78.24 万人,南沙区为49.93 万人,黄埔区为52.76 万人,从化区为63.49 万人。从平台上爬取的各区幼儿园数量为:白云区322 个,番禺区为307个,海珠区为190 个,天河区186 个,增城区为155 个,越秀区为116 个,荔湾区为103 个,花都区为98 个,南沙区为244 个,黄埔区为229 个,从化区为73 个。将各区人口数与幼儿园数量的整体趋势进行对比,结果见图3。
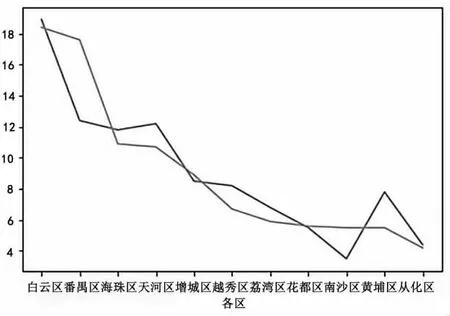
图3 各区人口数与幼儿园数量的趋势对比
可见,广州市各区人口数与幼儿园数量基本呈现正相关。说明广州市在设立幼儿园时,充分考虑了所在区的人口数量因素。人口数越多,对学前教育的需求越大,相应地需要设置更多的幼儿园以充分保障学前儿童的教育机会,整体上促进了教育资源的公平、均衡配置。
4.3 幼儿园数量与优质园数量的可视化分析
对爬取到的广州市各区幼儿园数量与所含一级幼儿园数量的整体趋势进行对比分析,结果见图4。
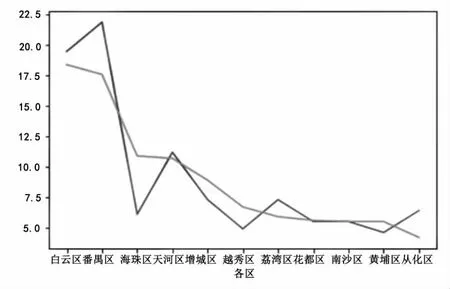
图4 各区幼儿园数量与优质园数量的趋势对比
可见,各区幼儿园数量与一级幼儿园数量呈正相关性。说明各区幼儿园的数量越多,就容易引起同行业间的激烈竞争。为了争取更多、更高质量的生源,各幼儿园普遍注重在软、硬件方面的投入,不论是园区场馆的扩建、器材设备的购置,还是幼师的引进与培养、学前教育理念的更新等,都积极对标一级幼儿园的认定标准,并竭力促进各项指标达标,无形中孵化出更多的优质幼儿园,促进了本区内学前教育水平的整体提升。
5 研究启示
当前,人类正处于信息爆炸的社会,大数据已成为时代的主旋律。政府数据开放是顺应大数据发展趋势的重要举措,大量高质量、高价值数据因公开而得以共享和使用。本文立足于政府开放数据的应用视角,从数据集自身出发,基于Python 技术对其开展网络采集及可视化分析,得到如下研究启示:
第一,数据驱动研究范式下需要更加注重数据自身的分析与挖掘。大数据的产生在一定程度上引起了科学研究范式朝向数据驱动型的创新转变,政府开放数据使得人们可通过互联网获取更多、更海量的数据。为了实现数据资产价值最大化,可采用一定的数据分析方法(如数据的采集、清洗及可视化技术,机器学习算法等)对数据内蕴含的因果关系、关联关系等进行深入分析与挖掘,必将更大程度地提升政府开放数据的利用效果。
第二,开放政府数据的数据集样本应确保无偏性、多变量的特性。通过爬虫等数据采集技术获取的数据记录数量往往较多,但数据样本是否具有典型性并不明确,由此导致采用此类样本数据的分析结果可能并不具备普遍性和适用性。此外,如果采集的样本数据所具有的变量个数较少,就意味着对数据自身特性的描述并不全面,也难以开展更深入、更客观的数据分析。因此,政府部门在开放数据时,有必要从源头严控数据质量,确保所开放数据样本具有更广泛的代表性,同时尽可能提供有关数据样本更多表征其不同属性的变量描述。
第三,开放政府数据应建立常态化的数据更新机制,以确保数据的及时性和持续性。大数据时代下,数据的日生产量数以亿计,其中蕴含的决策导向以及价值取向也瞬息万变。数据驱动的研究过程除了要以巨大的数据量为支撑深入挖掘其内部存在的规律与模式外,也应注重对即时数据的及时捕捉以及对目标数据定时定期、规律性的跟踪。因此,政府开放数据应确保其自身是最新发布的,具备较高的时效性,同时对已发布的数据应按照日、周、月等频率开展定期的更新与维护。
第四,开发和设计更多、更强大、更稳定的算法以实现开放数据的智能化应用。数据可视化分析虽然能实现对数据的应用,但其本质上还是基于可视化展示结果辅助人类更好地进行问题决策,属于浅层的智能应用。如果基于现有算法进行改进和优化,使之可以基于输入的原始开放数据通过算法的智能计算与分析直接代替人进行科学决策,算法输出的结果已经是非常明确的行动指示,即实现了更高级的智能应用,这将成为未来政府开放数据利用的一个重要发展方向。
