基于传统机器学习与深度学习的学生评教情感分类对比分析
2021-12-14洪雪峰
洪雪峰
基于传统机器学习与深度学习的学生评教情感分类对比分析
洪雪峰
(广东金融学院 互联网金融与信息工程学院,广东 广州 510521)
通过在网站上收集建构154,000条评论的语料库,运用传统机器学习法和深度学习法,对其分类精确值及F测量值进行比对。大量的实证分析表明,基于深度学习架构在教师评价的情感分类任务上优于传统的机器学习分类器,其分类准确率达到98.29%。建议运用机器深度学习的模式,利用卷积神经网络和双向长短期记忆神经网络构建情感分析模型,可以学生评教为提升高校教育质量,其结果可作为衡量教学效果的指标,并给管理者提供决策依据。
深度学习;机器学习;学生评教;情感分析
教学质量的优劣是各高校核心竞争力的指标之一,因此,采用有效的手段提升高校教学质量是各高校的首要任务。目前大多数高校均采用教学质量评价这一手段,但其评价结果的科学性和有效性一直以来颇受争议。究其原因,教学评价活动是一项非常复杂的活动,其涉及的因素较多。学生评教通常既包括一些固定的问题,也包括一些开放性问题。固定问题主要是借助评教量化表,该量化表对教学活动中的教学目标、教学设计、教学内容以及课后练习等进行指标考核,通过量化表分值统计进而总结评价可以得到一些发现。然而,评教量化表日益受到教师们普遍的诟病,其所提供的指标内涵不能显示教学过程的所有方面。开放式问题却给了评价者自由表达的空间,该评价意见可以更好地给教师提供更加有用的洞见,从而帮助教师们查漏补缺,提高教学质量。其所涉及的问题可以包括教学方式、教学评估、教学资源、教学管理等方面,例如课堂内容的充实度,教师的授课能力,教师资历,课后资料等。该评教方式能够给教学教育决策部门提供基本信息来源,以达到提高教学质量的目标。高校管理部门可以把学生评教作为教学职能的测量方式。此外,该评教方式还可以用于管理层进行决策,如对教师晋升或评聘的决策。
一 情感分析方法
随着信息与通信技术的不断发展,用户的生成信息可以分享到互联网上。这些用户生成的信息文本包括对酒店、产品、电影、医生和其他事物的评价。同样地,学生们也可以在网络平台分享对教师的匿名评价,比如Ratemyprofessors.com就是全球最大的学生评教平台之一,拥有1900万条以上的评价,评价范围涵盖了多个国家,例如美国、加拿大和英国等,约7500家学校的120万位教授。在此平台上,学生们可以通过五星评价范围来评价教师,并计算教师得分。此外,学生们可以在平台的开放讨论区分享自己的观点。该平台是学生们在选取课程前,获取教师信息的一个重要渠道。从教师的角度出发,该平台也为教师们提供了关于自我效能与人际交往的有价值的信息。因此,这些信息可以作为反馈,促使教师们进一步提高自己的技能。我国绝大多数高校也采用了网上评教的方式。学生评价的内容实质就是对教师的一种情感和情绪的表达,我们可以利用计算机技术对于学生情感进行分类,以得到比较准确地教学评价反馈。
情感分析也称为观点挖掘,是计算机领域中,用于识别人们对于某一实体或学科(例如产品、服务、组织、个人、议题或事件)的个人观点、情感、态度、评价和情感的一种研究方法。情感分析方法主要是从非结构化的内容和情感分类任务中获得有条理且有深刻见解的知识,这些知识可以作为决策支持系统和决策者做决策时进行参考的重要信息来源。情感分析也可以应用于教育领域,用来提升高校的教学质量,提升学校的知名度和吸引力,还可以用于识别和调节网络学习者的情感,感知学生们的学习表现。
情感分析方法主要有两种,一种为基于词汇的方法,另一种为基于机器学习的方法。基于词汇的情感分析方法通过计算单词和短语的语义指向来识别文本文档的情感取向。这些方法需要一本与单词相对应的积极与消极情感值的字典。基于词汇的情感分析方法随着文本所处位置而有所改变,并不涉及标记数据。然而,对于不同的文本,构建一个唯一的基于词汇的字典是很难的。因此,目前情感分析的主要研究方法还是一些基于机器学习的传统算法,例如,SVM、信息熵、CRF等。这些方法归纳起来有三大类:有监督学习、无监督学习和半监督学习。
二 传统机器学习与深度学习
机器学习方法将情感分类视为监督学习任务过程,利用标记文本文档来构建学习模型。该方法利用传统的监督学习算法,例如朴素贝叶斯(NB)算法、支持向量机(SVMs)和K邻近(KNN)算法来完成情感分类。早期的情感分析研究指出,由于机器学习的方法通常能够获得更高的预测性结果,在情绪分类任务中时常有所应用。例如,Adinolfietal[1]提出一种基于情绪分析的模型,以此来测量学生们对不同学习平台,例如大量的网络公开课,学习日记和Twitter等平台的满意度。Altrabshehetal[2]的研究表明,通过机器学习方法可以来识别学生们对于文本反馈,并提取其与学习相关的情绪情感表征。目前,也有很多研究尝试用Twitter收集学生们的反馈意见和观点,例如对微积分、数据库、工程学分子、生物学、化学、物理和科学等不同课程的感受。Gutierrezetal[3]提出了一种文本挖掘方法来测量学生们对教师表现的评价。他运用SVMs与RF算法来对学生评教中的简短评论进行情感分析,重点筛选了简评中的词汇、句法、语义特征等。RaniandKumar[4]对学生们的反馈进行情绪分析,提出了以基于词汇的研究方法。在他的模型中,使用了自然语言处理技术,用于识别课程评价的情绪情感。
深度学习是机器学习研究中一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。深度学习架构是从大数据集中学习特征,而不需要任何特征抽取过程。深度学习架构包括卷积神经网络(CNN)、递归神经网络(RNN)、长短期记忆网络(LSTM)以及门控递归单元(GRU)。随着深度学习方法在图像处理和语音识别方向的成功应用,越来越多的深度学习方法也被应用于自然语言处理方向,如情绪分析任务。基于深度学习的情感分析方法将特征提取和判断文本倾向结合在一起,不需要人工提取特征,准确率较高,但是模型训练时间较长。Glorot[5]和Pang[6]等推出了一个用于情感分析任务的深度学习架构。Dos Santosand Gatti[7]提出了一个基于卷积神经网络的架构,可以用于Twitter信息的情绪分析。近年来,深度学习也运用到采集教育数据上。例如,Bustillos等[8]提出了一个以深度学习为基础的意见采集板块,用于在智能学习环境中采集意见及情感认同。在该方案中,他们研究了多种监督学习算法,如伯努利神经网络、多项式神经网络、支持向量机、线性支持向量机、随机梯度下降和邻近算法等,并将卷积神经网络和长短期记忆架构用于深度学习的意见采集。在他们的实证分析中,以深度学习为基础的架构达到了88.26%的分类准确性。Cabada等[9]提出了数个用于教育情绪分析的深度学习架构,使用长短期记忆的卷积神经网络达到了84.32%的分类准确性。
三 学生评价情感样例和评价方法
根据分类目标的不同,情感分类又可以分为主客观分类、正负情感极性分类和多情感分类等,主客观分类是情感分类的基本任务,主要负责从大规模原始数据集中识别包含主观信息的文本,构建主观文本数据集进行下一步的情感分析研究。一般而言,研究人员将主观文本的极性分为正向和负向两类,正向表示文本的情感语义为褒义,负向表示文本的情感语义为贬义。这种分类方法尽管简单,却可以满足很多现实应用的需求,例如判断学生对于教师教学是好评还是差评,他们对于教师的教学方法和态度是支持还是反对等等。
目前为止,我们从Ratemyprofessors.com成功收集到了286000份教学评价。在这个网站上,学生可以用5分制来评估老师,并从中计算出综合素质分。为了获取标注语,我们充分利用用户提供的综合素质分,综合素质分为1或2的评价被标为“负面”评价,而综合素质分为5的被标为“正面”评价。除了网站提供的综合素质分外,我们对原始评价信息也进行了标注。根据这两种主要的标注方法,我们建立了89000条正面评价和77000条负面评价的语料库。为了平衡,我们最终的语料库包含154000条评论,其中正面评价和负面评价各有77000条。
除了综合素质分外,还考虑了154000条评论的课程难度分。为了分析综合素质分数和课程难度分数之间的相互关系,本论文还采用Pearson的关联性测量方法来确定综合素质分数和课程难度分数之间是否存在显著统计关系。Pearson相关系数为-0.973,这表明教师教学综合素质分数和课程难度分数这两个变量存在极强的负相关关系。

表1 学生评教样例
为了在文本语料库中建立学习模型,我们进行了几项预处理任务。对于预处理的语料库,我们采用Bustillos等的框架。也就是说,我们执行了序列和标点符号消除、统一资源定位符移除、标记化(将文档中的句子或单词分成符号或字符)、词干提取、停用词和无关词的移除。为了评估机器学习方法和深度学习算法的预测性能,我们采用分类精度和F值度量的评估方法。
分类精度是在评估监督学习算法中最为广泛运用的一种方法之,其公式为:
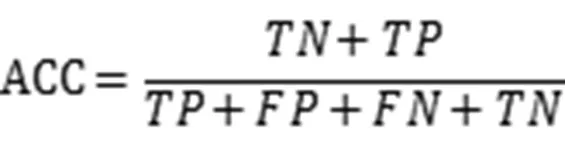
其中TN、TP、FP、和FN分别代表真负数、真正数、假正数和假负数。
F值度量是评估监督学习算法另一个常用方法,是精度(PRE)和查全率(REC)的调和平均值。PRE是真正数与真正数和假正数的和的比值。REC真正数和真正数与假负数的和的比值。基于PRE和REC,可以得出F值度量的公式,如下所示:

为了评估测试,我们根据上述算法对语料库中的学生教学评价进行了两组数据分析,包括基于传统机器学习的情感分析和基于深度学习的情感分析。在本研究的实证分析中,所建立的语料库由三种不同的N-gram模型(即unigram、bigram和trigram模型)和三种不同的权重方案(即基于TP、TF和TF-IDF的权重)表示。这样,我们可以得到9种不同的配置。为了建立基于这些配置的学习模型,本论文采用了五种传统的监督学习方法如NB、SVMs、LR (逻辑回归)、KNN和RF(随机森林)法等。
四 实验结果分析
(一)关于传统机器学习的情感分析
文本语料库通过采用三种传统的文本演示方案(即TF、TP和TF-IDF方案)及三种不同的N-gram模型(即一元模型、二元模型和三元模型)来表示。在传统的文本演示方案上,我们评估了四种机器学习方法,如NB、SVM、LR、KNN、RF和三种集成学习方法即AdaBoost(自适应提升算法)、Bagging(装袋算法)和RS(随机子空间)的预测性能。在机器学习算法的实验中,我们采用了10倍交叉验证方案,即将原始数据集随机分割成10个大小相等的数据集。在每次迭代中,其中一组数据被用作验证数据,则另外的数据集被用作训练数据。这个过程重复10次,最后得到了平均结果。我们采用了WEKA的默认参数,并利用WEKA3.9实现了监督学习算法和集成学习方法。
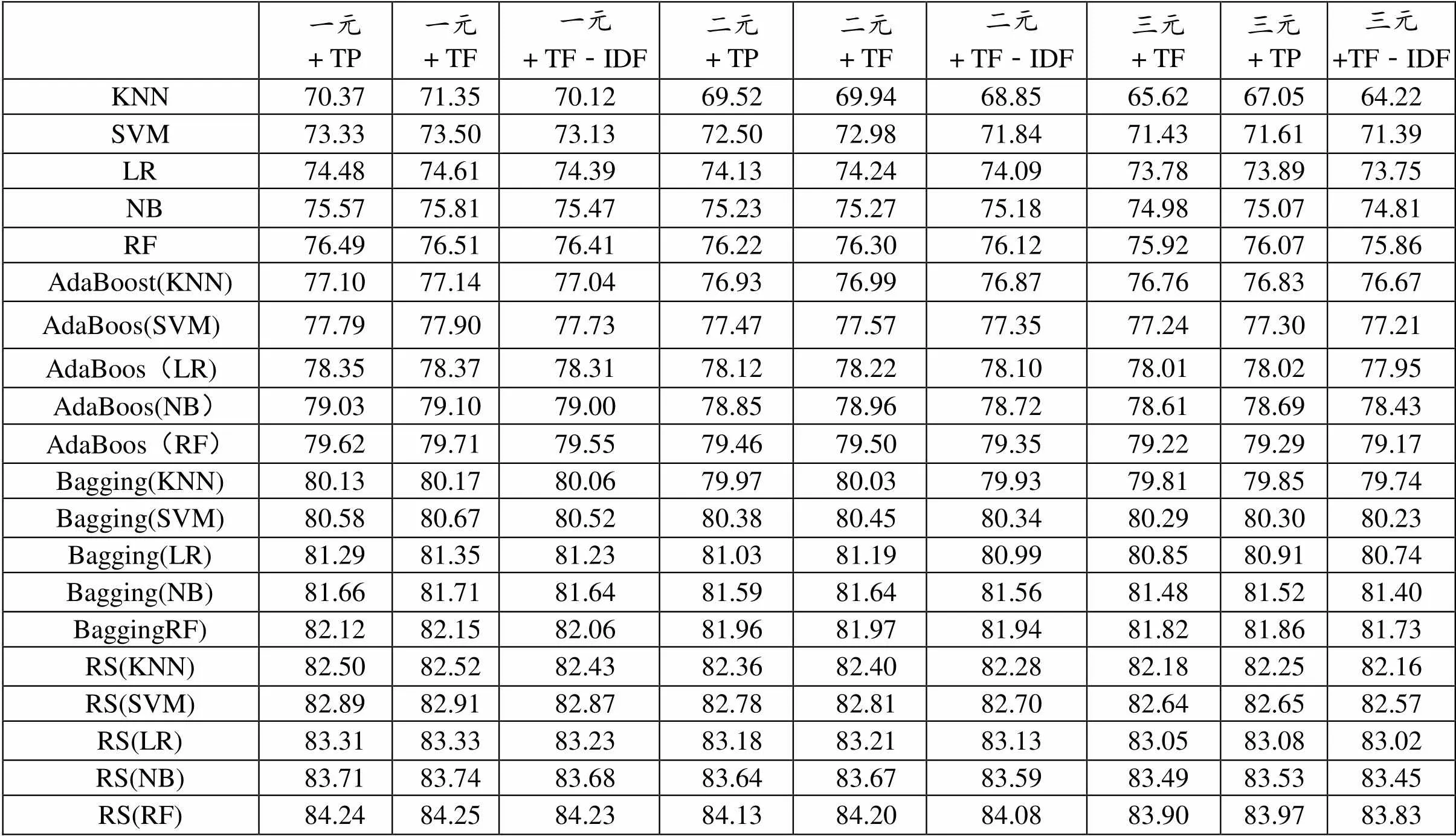
表2 传统机器学习算法分类精度值
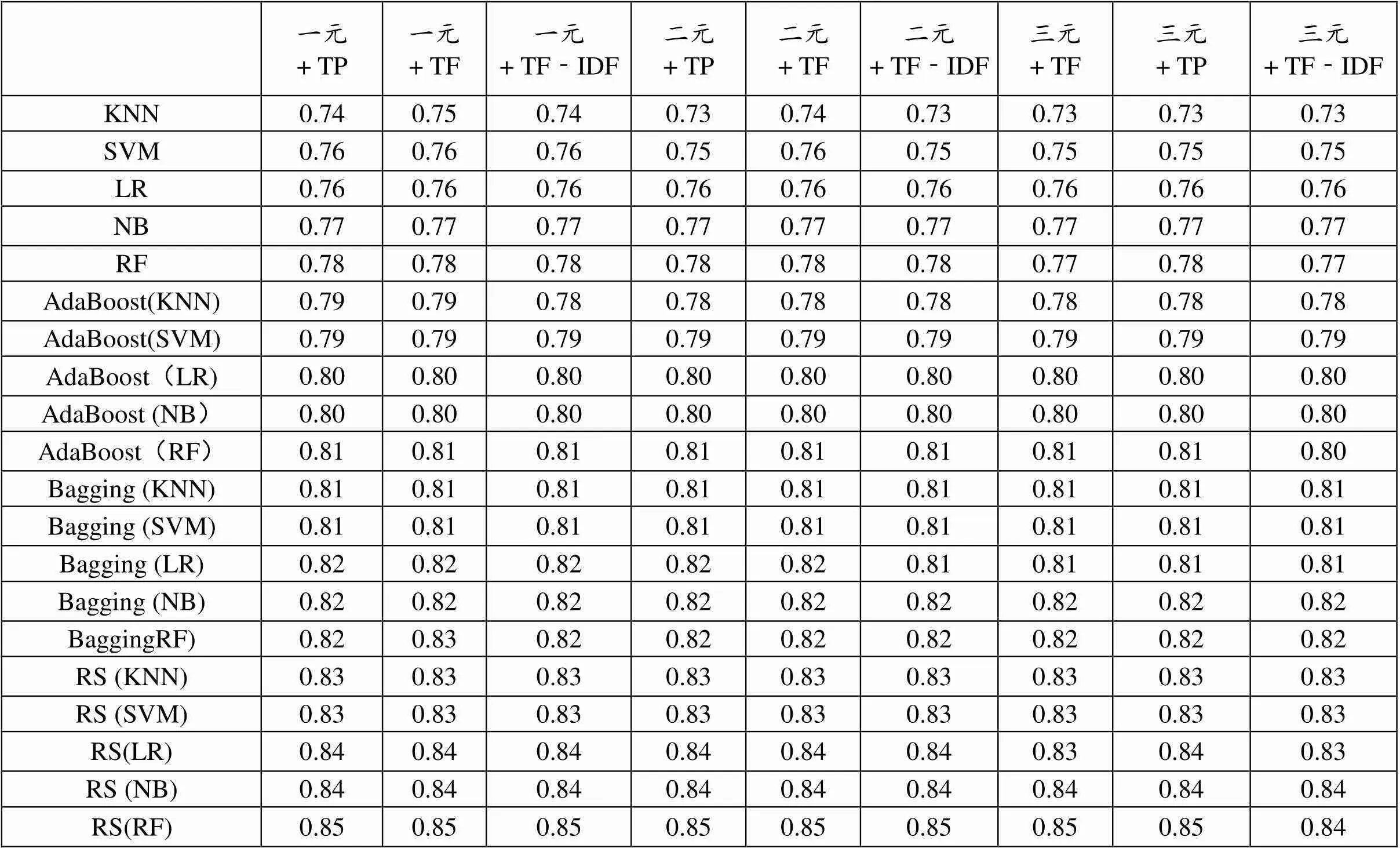
表3 传统机器学习算法F测量值
表2和表3分别给出了传统机器学习的文本语料库分类精度值和F测量值。表2给出了基于传统加权方案和N-gram模型的监督学习算法和集成学习方法。这两种方法展示了9种不同的文本语料库配置上获得的分类精度值。在实验分析中,我们考虑了上述5种监督学习算法。实验发现,在文本语料库上监督学习方法的预测性能上,随机森林算法在分类精度方面取得了最高的预测性能。朴素贝叶斯算法位居第二,支持向量机算法则次之。在传统文本演示方案的预测性能上,以词频为基础的一元模型特征具有最高的分类精度。其次是由TP方案中具有一元模型特征所取得。最后才是由具有TF-IDF权重的一元模型特征所取得。表2和表3的实证结果表明,一元模型优于其他N-gram模型,即二元模型和三元模型。此外,与基于TP的表现和基于TF-IDF的加权相比,基于TF的表现具有更高的预测性能。
如前所述,集成学习方法可与监督学习算法结合使用,可以提高预测性能。在实验分析中,我们研究了三种不同的集成学习方法(AdaBoost,Bagging,RS)。表2和表3中实证分析结果表明,使用集成学习方法可以提高监督学习方法的预测性能。对于集成方法而言,在比较的结构中,随机子空间的随机森林算法获得了最高的预测性能,分类精度为84.25%。
(二)关于深度学习的情感分析
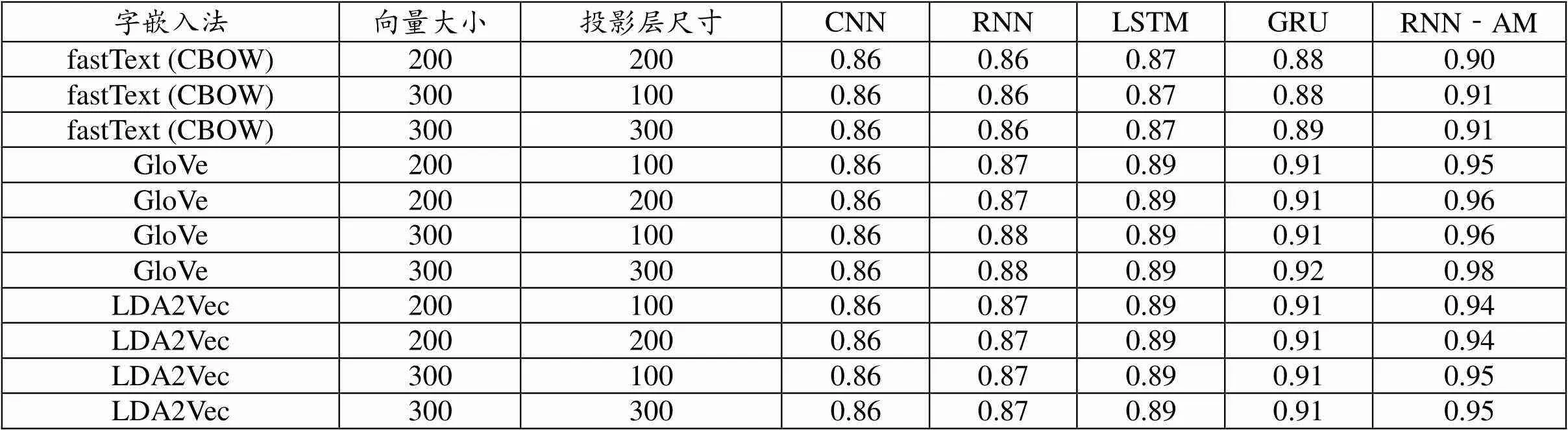
文本语料库使用了4种词汇嵌入法(即word2vec、GloVe、fastText和LDA2Vec)表示,并使用了5种深度学习架构(CNN、RNN、RNN-AM、GRU以及LSTM)来处理文本。对于每个模型,我们采用超参数搜索算法从每个深度学习模型中获得最优预测性能。为此,我们采用了基于高斯过程贝叶斯优化的超参数优化方法。在语料库中,80%的数据被用作训练集,而其余的数据被用作测试集。在word2vec和fastText方案中,我们不但考虑了连续跳格和连续词袋方案,还考虑了其矢量大小(矢量大小为200和300)和投影层的尺寸(尺寸大小为100和200)。在LDA2vec方案中,我们考虑了一系列参数(包括主题数和负采样指数)。在下列表4和表5中,分别列出了5种深度学习架构获得的分类精度值和F-测量值。

表4 深度学习算法分类准确值
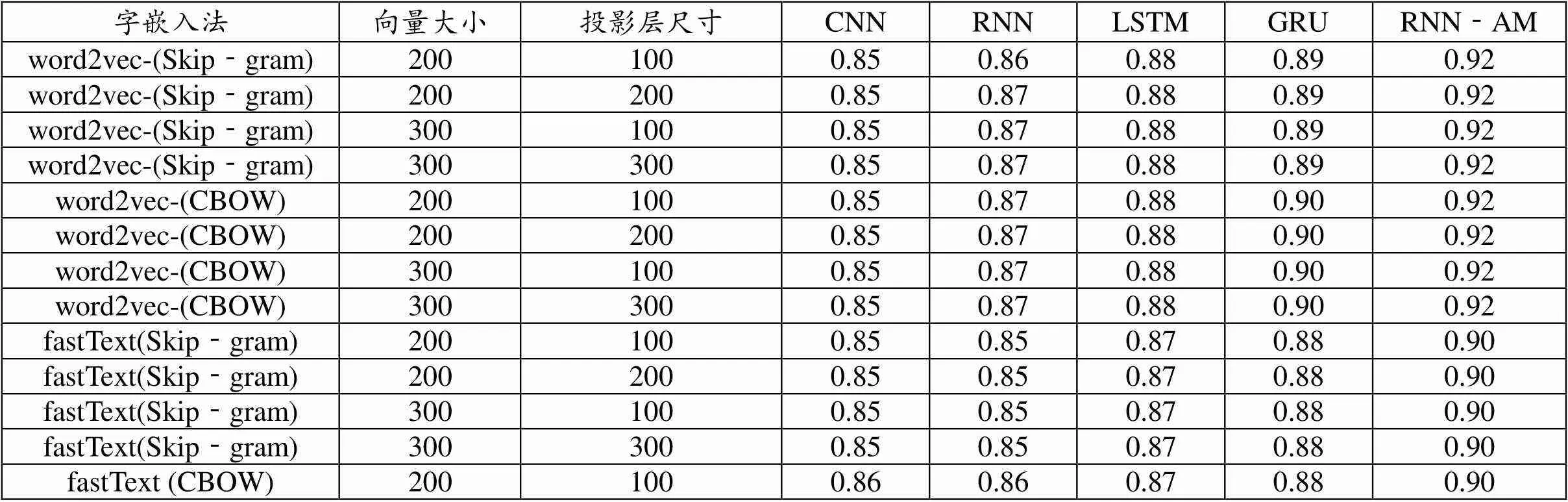
表5 深度学习算法F测量值
续前表
在表4所列的实验结果中,我们检验了6种词嵌入模型(word2vecskip-gram模型、word-2vec-CBOW模型、fastTextskip-gram模型、fastText-CBOW模型、Glove和LDA2vec)。从表4中的结果可以看出,在文本语料库中,Glove嵌入方案优于其他嵌入方案;LDA2vec嵌入方案的预测性能位居第二;紧随其后的是fastTextskip-gram模型。分类精度预测性能最低的是word2vecskip-gram模型。在词嵌入方案中,我们还考虑了不同的矢量大小和投影层的维度。实验结果表明,在矢量大小为300,投影层大小为300的情况下,词嵌入方案具有较好的预测性能。在使用深度学习架构预测性能的实证分析中,RNN-AM获得了最高的预测性能。GRU的预测性能位居第二,LSTM网络的预测性能位居第三。实证分析表明,RNN-AM、GRU和LSTM的性能优于传统的循环神经网络。
在实证分析中,CNN结构分类准确度上的预测性能最低。通过比较配置,RNN‐AM的预测性能最高,达到98.29%,它与GloVe基于词嵌入方案的表示相结合。正如表5所呈现的预测性能所示,就分类精度而言,所述方案的相同模式仍然有效。RNN-AM中的F测量值最高,GRU的F测量值居其后。单元嵌入方案中的预测性能在F测量值中,嵌入的方案GloVe单元明显优于其他单元。
以上实验表明,使用深度学习法对学生评教情感进行分类比传统学习模型效果更优。相比较于传统机器分类算法,深度学习法对情感分类的预测性能更高,尤其是使用RNN‐AM与基于词嵌入法GloVe代表的分类准确度为98.29%。可见,文本挖掘和机器学习技术能应用于教师教学评价意见反馈,从中更清晰地辨认和识别学习者的情感倾向和声音,比较科学合理的反映出教师教学的过程,也更能有效地帮助高校教学管理者做出正确的决策。
[1]P.Adinolfi et al.,Sentiment analysis to evaluate teaching performance[J].Int.J.Knowl.Soc.Res,2016(4):86–107.
[2]N.Altrabsheh,M.Cocea,and S. Fallahkhair, Predicting learning‐related emotions from students’ textual classroom feedback via Twitter[M].Proceedings of the 8th International Conference on Educational Data Mining,2015.
[3]G.Gutierrez et al.,Mining:Students comments about teacher performance assessment using machine learning algorithms[J].Int.J.Comb.Optimi.Probl,Inf,2018(3):26–40.
[4]S.Rani and P.Kumar,A sentiment analysis system to improve teaching and learning[J].Computer,2017(5):36–43.
[5]X.Glorot,A.Bordes,and Y.Bengio,Domain adaptation for large‐scale sentiment classification:A deep learning approach, proceedings of the 28th International Conference on Machine earning[M].ICML,2011.
[6]P.Pang,and L.Lee.Opinion mining and sentiment analysis[M].FoundTrends Inf.Retr,2008:1–135.
[7]C.Dos Santos and M.Gatti.Deep convolutional neural networks for sentiment analysis of short texts,Proceedings of the 25thInternational Conference on Computational Linguistics [M].Dublin City Univ.Assoc.Comput.Linguist.,2014:69–78.
[8]O.R.Bustillos et al..Opinion mining and emotion recognition inan intelligent learning environment[J].Comput.Applic.Eng.Educ,2019(1):90–101.
[9]R.Z.Cabada,M.L.B.Estrada,and R.O.Bustillos.Mining of educational opinions with deep learning[J].Univers.Comput.Sci,2018(11):1604–1626.
[10]刘华祠.基于传统机器学习与深度学习的图像分类算法对比分析[J].电脑与信息技术,2019(5):12-15.
G43
A
1673-2219(2021)02-0097-06
2020-08-21
广州市2020年度哲学社会科学发展“十三五”规划项目(项目编号2020GZGJ160)。
洪雪峰(1976-),男,广东金融学院讲师,硕士,研究方向为数据挖掘与教育教学管理。
(责任编校:周欣)
