基于PSO优化博弈的区块链共识算法
2021-12-14徐晓雅赵会群
孙 晶 徐晓雅 赵会群
(北方工业大学信息学院 北京100144)(北方工业大学大规模流数据集成与分析技术北京市重点实验室 北京100144)
0 引 言
随着区块链技术的发展,共识机制作为区块链的核心技术,受到人们的广泛关注[1],典型的共识算法有以下几种。Paxos算法[2]是一种基于消息传递的分布式一致性算法,通过准备阶段和协议阶段的执行,为系统选出唯一的提案,来保证每个节点执行相同的命令序列,此算法被广泛应用在Chubby、Zookeeper分布式系统中。Raft算法[3]是另外一种共识算法,通过选举一个全局的leader生产日志,并与follower进行心跳同步达成一致,其过程是对Paxos选择提案过程的重新简化。这两种算法解决的都是非拜占庭问题,而区块链技术的原理延伸到互联网中可归纳为拜占庭将军问题,即在缺少可信任的中央节点和通道情况下,分布式网络中的各节点如何达成共识。拜占庭容错算法[4]作为经典分布式共识算法被很多区块链采用, 其过程为客户端向主节点发送调用服务操作请求,主节点广播请求给副节点,副节点执行请求并向客户端返还结果,此种情况下,若客户端收到f+1个副节点发回相同的消息,则可以作为整个操作的最终结果。这种算法无需信任单个节点,还能创建网络的共识,并且保证安全性和有效时间约束[5]。上述三种共识算法都是以“少数服从多数”的投票机制来达成共识。中本聪在设计比特币区块链网络的共识机制时提出了创新的PoW(Proof of Work)工作量证明机制[6],网络中的节点通过复杂的哈希运算来完成工作量,从而确定节点获得区块的概率,这种机制耗费大量资源,共识周期较长,并且在目前的发展来看,算力集中在几大矿池使得算力中心化违背了区块链去中心化的初衷。之后又提出了PoS(Proof of Stake)股权证明机制[7],区块链系统要求用户持有一定数量的加密货币并且具有所有权,依靠币龄来决定记账权。这种机制不再需要消耗大量能源去挖矿,虽然改善了资源浪费的缺点,但是权益容易集中在少数人的手里达成垄断,这也是此机制的弊端[8]。这类共识机制的特点是通过控制算力或是股权来达成目的,对于大多数节点来说,只是接受了共识的结果,而没有真正意义上实现系统的共识。Hyperledger Fabric项目是一个旨在推动区块链跨行业应用的开源项目,此项目提供了两种共识方式:solo模式的单点共识方式无容错性,只能在测试时使用;Kafka模式的共识是一种支持多通道分区的集群时序服务,其本质还是依赖于Zookeeper进行Paxos算法选举。此外在一些供应链金融区块链系统[9]中,由一些核心企业作为系统共识节点,很少考虑中小企业或小微企业的收益,由此可见全局的共识不一定适用于个体。
共识机制的设计着重于系统和体系的建立,其目标是让一个多样化群体在不发生冲突的情况下做出决策,使系统达成一致。然而区块链最显著的特点是去中心化,其技术是追求各节点的公平与公正,这种追求与博弈论机制最为相似,参与人具有不同的目标或利益,通过博弈制约的规则来选取对自己最为有利或最为合理的方案。对每个参与人来说,博弈公平的规则产生公正的制衡结果。受到博弈论思想的启发,共识机制的设计可以建立在系统参与各方的力量均衡上,这种均衡应该是在博弈规则制约下的一个可以量化的结果[10]。所以用博弈论原理建立均衡规则来设计区块链的共识机制是本文的一个研究主题。
最理想的共识机制是系统中的节点达成的共识是一个纳什均衡,即单方面改变自己的策略不会增大自己的效益。不仅内部状态达成稳定共识,而且对于每个节点来说都是最公正的结果。本文将寻找系统的纳什均衡点作为系统的共识节点,采用纳什均衡的共识算法能够快捷准确地为整个区块链系统推荐出几个能够作为打包交易信息的中心节点,来保持系统中节点之间的收益均衡,并使系统快速达到共识的状态。然而纳什均衡的求解一直以来都是一个难点问题,利用划线法或反应函数交叉法只能求解二人博弈或三人博弈,利用同伦算法或者全局牛顿算法求解时计算复杂且难于实现。随着智能算法的发展,依赖粒子群优化算法寻优,成为本文求解纳什均衡的一种途径。
1 相关工作
国内外学者已经展开了对共识机制的研究,Shi等[11]研究了多集群网络上的约束共识问题,提出了多聚类约束一致性算法,给出了算法的一致性分析和收敛速度分析。Wang等[12]通过设计多智能体通信系统来研究分布式最优共识问题,提出了二阶优化一致性算法,将平衡点作为此算法最优点,并且在给定条件下证明算法是渐近稳定的。张仕将等[13]提出了一种基于Gossip协议的拜占庭共识算法,提高了系统的稳定性和容错性,系统可以容忍小于一半的节点成为拜占庭节点。以上三种方法虽然达成了系统共识,但依旧没有将博弈规则的制衡作用考虑进去。
在非合作博弈中,纳什均衡是一个最重要的概念,计算纳什均衡解的方法有很多。在许多博弈的经济模型中,均衡被看成多项式方程组的解,所以纳什均衡的求解就转化成多项式的求解。Nabatova等[14]将Lemke-Howson算法用于求解双矩阵决策中的纳什均衡,找到了纯策略和混合策略纳什均衡,保证算法收敛于双矩阵博弈解,但计算量很大,不适用于多人多策略博弈。
另外一些工作主要集中于将非合作博弈纳什均衡延伸为分布式控制技术,将博弈论与多智能体系相结合起来。Xu等[15]设计了相应的分布式算法来解决纳什均衡问题,将搜索纳什均衡解与搜索梯度解联系在一起。Ye等[16]通过结合梯度和共识方案,设计了分布式纳什均衡搜索算法,对参与人行为与纳什均衡的收敛性进行了分析,并为这种算法提供了数值例子。Zhu等[17]也给出了基于梯度算法被设计用于解决纳什均衡计算的想法。Salehisadaghiani等[18]提出了一种基于gossip异步的算法和一种利用乘数的交替方向在部分决策信息下寻求分布式纳什均衡的算法[19],博弈中的参与人通过信息交换,用于在分布式多节点网络中查找游戏的纳什均衡,通过成本函数收敛减少步长来证明算法的有效性。文献[20-21]设计了一种基于次梯度的算法来计算子网零和游戏中的纳什均衡,并进一步研究多人非合作博弈中的纳什均衡计算。以上这类算法设计复杂、适应性不强。
依赖智能算法求解纳什均衡成为一种新途径。Beiranvand等[22]采用遗传算法来解决一个新的分布式优化问题,使用世代种群进化的方法来逼近求纳什均衡解,但用遗传算法求解纳什均衡的交叉、变异操作产生的解可能不满足博弈的行为特征。随后王志勇等[23]提出一种改进的蚁群寻优思想来解决有限n人非合作博弈的纳什均衡算法,提高了搜索解的能力和精确性。文献[24-25]提出了一种基于粒子群优化算法的算法,该算法能够在局部最优的博弈中找到全局纳什均衡,但未给出明确的适应度函数。
本文的目标是为系统找到可以作为共识的纳什均衡点,将求解纳什均衡转化为求解最优化问题,用改进的粒子群优化算法实现求解纳什均衡,以此作为分布式系统中共识算法所选择的主节点。
2 算法研究
本文设计并实现一个面向组合投资的区块链原型系统,商业银行是此系统的备用主节点,投资公司可以根据商业银行的货币政策计算投资回报。共识机制就是在商业银行中选择使得每个投资公司都能获得最佳效益的一个或者几个商业银行,即满足纳什均衡的商业银行作为主节点,负责区块链的打包上链管理。
2.1 Affnity Propagation聚类算法应用研究
由于在博弈中参与人的数量和决策数量很大程度地影响了博弈的复杂程度,为了解决这一问题,本文首先将数据进行聚类,把聚好的类作为博弈局势中参与方的一类,这样不但简化了博弈的过程,还保留了数据原有的结构和属性。参与人依赖聚类后的结果来观察每一簇数据的特征,对特定聚簇集合进一步分析后做出决策。
本文使用AP聚类算法(Affinity Propagation Clustering Algorithm)对投资公司聚类。与K-Means不同,AP聚类不需要预先指定簇的数量,而是将点k称为参考度的实际值S(k,k)作为输入,不同参考度将导致不同的聚类结果,具有较大参考度的点更可能被选为聚类中心[26]。初始的AP聚类将参考度默认设置为相似矩阵的中位数,但是聚类效果不佳。因此,本文采用不同的参考度值应用于AP聚类,并使用Silhouette Coefficient(SIL)轮廓系数作为有效评估函数来识别最优的分类。轮廓系数是常用的评价聚类内聚度和分离度的有效性指标之一,对于点i,定义为:
(1)
式中:a(i)表示点i与其所在类中其他点之间的平均距离,表示内聚度;b(i)表示点i与其最近的类之间的平均距离,表示分离度。由式(1)可知-1≤s(i)≤1,轮廓系数越大说明聚类效果越好,考虑不同参考度值所对应的轮廓系数来评估聚类质量。
由于商业银行对不同行业的投资业务发布的货币政策不同,因此可以将银行的货币政策作为聚类特征为投资公司进行行业聚类。本文提出AP聚类行业个数确认算法(见算法1),并用轮廓系数评估聚类效果。
算法1AP聚类行业个数确认算法
输入:投资公司的利率,涨跌幅,参考度p。
输出:行业个数和聚类图。
1 BEGIN
2 FOR每一个数据点对
3 计算s(i,k);
/*用负欧氏距离计算相似度*/
4 初始相似度矩阵S;
5 END FOR
6 FORi-1 ton
7 计算r(i,k),a(i,k);
/*吸引度矩阵,归属度矩阵*/
8 更新ri+1(i,k),ai+1(i,k);
/*引入阻尼系数δ避免震荡*/
9 计算max(r(i,k)+a(i,k));
/*最大的值对应的k为点i的聚类中心*/
10 END FOR
11 输出Exemplar
/*聚类中心对应的投资公司*/
12 确认聚类个数m;
13 FORitom
14 连接数据对[i,Exemplar];
15 构造稀疏图结构G=[I,E];
/*数据点集I,边集E*/
16 END FOR
17 用式(1)计算轮廓系数;
18 投资行业个数=m;
19 输出图结构;
20 END
2.2 改进的粒子群算法求解纳什均衡
聚类分析后,需要从算法1中得到的每类行业中选择纳什均衡解,找到最优策略。本文采用最优的思想寻求最优解,用改进的粒子群算法得到全局最优的资源分配,设计求解每一类行业中的纳什均衡解。算法中每个粒子的位置代表投资公司进行博弈的一个局势,该局势设置成投资公司与银行之间所贷款的金额和贷款时的利率,由于策略的选择为概率,算法中把所有的粒子初始位置映射到[0,1],依据式(2)确定粒子的初始位置。
(2)
式中:Nmax与Nmin分别为映射的下限1和0;Omax和Omin分别为贷款金额和贷款利率的最大值和最小值;Ox,y表示当前粒子对应投资公司的贷款金额及贷款时的利率。在博弈局势中,参与人所采取的策略都是其他参与人所采用策略的最优反应,所以具有最优适应度的粒子代表了博弈中的纳什均衡。根据纳什均衡的定义与性质,在有限n人非合作博弈的战略式表述G={s1,s2,…,sn;u1,u2,…,un}中,ui表示为:
ui=max{sregi-(E(x)-Eavg),0}
(3)
式中:sregi=|Ei-Eavg|代表每一家投资公司的收益与平均收益Eavg的差值;E(x)代表纳什均衡解下的公司收益。通过式(3)可知,当混合局势为纳什均衡解时,ui才能取得最小值0,而混合局势为非纳什均衡解时,ui取得较大值。为了使所求解接近纳什均衡得到近似纳什均衡解,本文设计投资公司博弈局势中的适应度函数:
f(x)=minuii∈(1,2,…,n)
(4)
在博弈的策略组合空间内,f(x)适应度越小,该公司的收益越接近均衡值。
在算法的迭代中,每家投资公司会根据迭代中的个体最优值Pbest和群体最优值Gbest发生移动,不断调整自己的策略,然而在群体迭代过程中,容易陷入局部最优解,导致求解的纳什均衡不准确。针对这一问题,本文提出一种基于拥挤距离的粒子群算法求解纳什均衡。拥挤距离(Deterministic crowding,DC)表示个体周围其他个体的疏密程度,拥挤距离越大,说明个体分布得稀疏,多样性越大。依据拥挤度的方法选出全局最优位置,引导粒子向处于较稀松区域进行搜索,避免陷入局部最优值,提高了解的多样性,最终趋向博弈的均衡点,并且此行为符合博弈行为。拥挤距离的计算步骤如下:
Step1对于每个个体,初始化拥挤距离为di=0。
Step2对适应度函数f(x),根据适应度函数的数值大小, 对每个个体排序;对于每个个体,计算拥挤距离:
di+1=di+(f(i+1)-f(i-1))
(5)
Step3对于边缘上的个体给予其选择优势,将其拥挤距离设置成较大值。
Step4选择时优先选择较大的拥挤距离。
PSO优化时需要时间代价,当遇到大规模数据累积或复杂程度增大的情况,就会影响算法的性能。对于单一智能算法而言,进行数据处理的能力有限、精度不足,本文利用引力搜索算法Gravitational Search Algorithm (GSA)改进粒子群算法来提高全局的寻优能力。GSA是一种新的启发式方法,粒子运动遵循动力学规律,粒子朝着质量大的粒子方向进行运动,质量最大的粒子占据着最优的位置,从而得出问题的最优解[27]。在GSA中,假设在一个系统中有N个粒子,定义粒子i的位置xi,速度为vi,通过评价粒子的适应度函数值,确定每个粒子的质量和受到的力,计算加速度,并更新速度和位置。这几个参数的计算步骤如下[28]:
Step1计算质量。粒子i的质量定义:
(6)
(7)
式中:fiti(t)和Mi(t)分别表示第t次迭代时第i个粒子的适应度值和质量;best(t)和worst(t)表示适应度的最优和最差值。
Step2计算引力。粒子j对粒子i的引力:
(8)
式中:G(t)表示万有引力常数的取值;Mpi(t)表示被作用粒子i的惯性质量;Maj(t)表示作用粒子j的惯性质量,ε是一个小常数,避免分母为0。
那么,施加给粒子i的合力:
(9)
式中:rand是一个随机数且0≤rand≤1。
Step3计算加速度。根据牛顿第二运动定律,粒子i的加速度为:
(10)
Step4更新速度和位置。
vi(t+1)=rand×vi(t)+ai(t)
(11)
xi(t+1)=xi(t)+vi(t+1)
(12)
本文在粒子群算法求解纳什均衡解中,结合计算拥挤距离的方法引导粒子的搜索过程,并且使用一种结合PSO和GSA的新型优化方法,主要思想是将PSO的寻优行为和GSA的研究定位能力结合起来,以创建功能强大的优化算法。此时PSOGSA混合算法的速度更新公式如下:
vi(t+1)=rand×vi(t)+c1r1ai(t)+
c2r2(Gbest-xi(t))
(13)
式中:c1、c2是学习因子;r1、r2为[0,1]区间内相互独立的随机数。
由拥挤距离和GSA改进的粒子群算法求解博弈问题纳什均衡解的算法如算法2所示。
算法2改进的粒子群算法求解纳什均衡算法
输入:投资公司向银行贷款数据,粒子速度上限vmax,粒子速度下限vmin,惯性因子,随机初始化粒子加速度。
输出:最优局势,近似纳什均衡解。
1 BEGIN
2 FOR每一个粒子i
3 用式(2)初始化粒子的初始位置
/*贷款金额和利率映射投资公司所对应的位置pi*/
4 用式(4)计算适应度函数,评价优化目标值;
5 用式(5)计算拥挤距离度量;
6 设置pbest=xi;
/*找到当前最优解*/
7 END FOR
8Gbest=min{pbest};
9 WHILE NOT STOP
10 FORi-1 ton
11 更新best(t)、worst(t)、Gbest;
12 用式(7)、式(9)更新粒子质量和受力;
13 用式(10)更新粒子加速度;
14 用式(13)更新粒子的速度;
15 更新粒子的位置pi=pi+vi;
16 计算拥挤度距离di重新评价博弈局势;
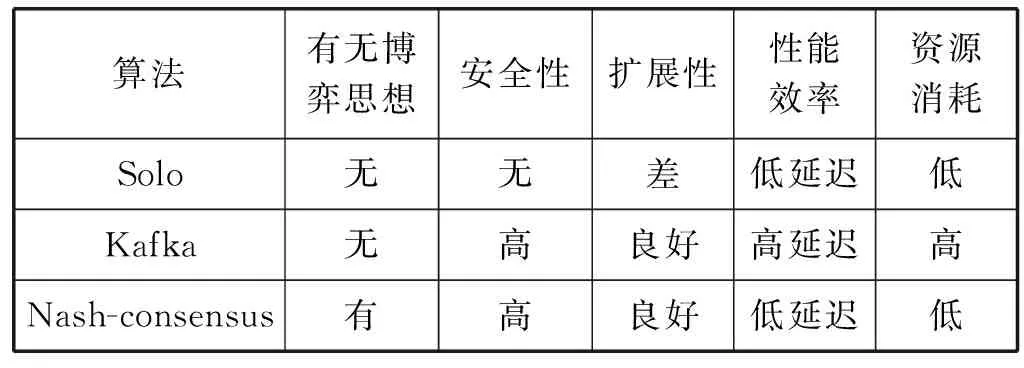
17 IFdi(xi) 18pbest=xi; /*基于DC排序更新每个粒子局部最优值*/ 19 IFdi(pbest) 20Gbest=pbest; /*基于DC排序更新粒子全局最优值Gbest*/ 21 END FOR 22 END WHILE 23 输出Gbest作为近似纳什均衡解; 24 END 基于以上两个算法可以求出纳什均衡的近似解,将其对应的商业银行作为区块链共识过程中的主节点,负责区块链的打包上链管理。Fabric项目的共识过程包括3个阶段:背书、排序和校验,本文只在排序这个部分做出改进,接受被认可的交易并且将其进行排序,确保交易顺序的一致性,并且将商业银行设置为orderer节点负责打包排序,投资公司设置为peer节点进行数据交易,结合已求得的纳什均衡近似解来设计基于博弈的区块链共识算法,如算法3所示。 算法3Nash-consensus算法 在Fabric网络刚启动时,orderer节点进入备选状态,同时创建计算时间超时定时器。 Orderer端: 输入:纳什均衡解下所对应的商业银行节点,客户端(peer节点)发送交易信息,BatchSize,BatchTimeout。 输出:数据区块。 BEGIN 1 orderer节点: 2 orderer节点进入备选状态; 3 纳什均衡解下对应的第一个商业银行orderer节点作为leader,其余解作为备份节点; 4Term=1; 5 IFtime>超时定时器时间 6 选择下一个备选节点作为leader; 7Term++; 8 其他orderer节点收到leader消息后,回到备选状态; 9 Leader通过recv接口,监听peer节点发送过来的交易信息; 10 IF 区块大小>=BatchSize 11 BlockCutter; /*切块*/ 12 IF 时间>=BatchTimeout 13 CreatNextBlock; /*创建块*/ 14 将区块写入Ledger中; 15 返回处理信息并进行广播; 16 END Peer端: 在Fabric网络刚启动时,peer节点连接orderer节点,同时创建计算时间超时定时器。 输入:获取leader排序后生成的区块。 输出:交易信息。 BEGIN 1 Peer节点: 2 IF Peer节点通过GRPC连接到leader排序节点 3 发送交易信息; 4Term=1; 5 IFtime>超时定时器时间 6 继续等待; 7Term++; 8 Peer通过deliver接口,获取leader排序后生成的区块数据; 9 检查交易是否满足背书策略; /*签名版本号等是否正确*/ 10 END 综上所述,将纳什均衡解作为共识算法的主节点分为两个部分,第一部分对于投资公司进行聚类,用AP算法将投资公司分成不同的簇,并用轮廓系数评价聚类效果,将所聚出的簇作为博弈的一类投资人,用改进的粒子群优化算法求解纳什均衡。第二部分将所求解下对应的商业银行作为超级账本中的orderer节点,按照顺序依次作为系统的共识节点。若orderer节点被选为共识主节点,其他的orderer节点则被认作备用主节点,当共识主节点出现安全和可靠性失败时,由备用主节点接管其业务。将纳什均衡解下对应的商业银行节点设置成超级账本网络中的共识节点,负责对交易信息的打包上链管理,其过程大致分成四个步骤,如图1所示。 图1 共识过程示意图 Step1peer节点通过broadcast接口将交易信息收集,提交给leader主节点。 Step2leader主节点将交易信息复制给作为备份的orderer节点,以防数据丢失。 Step3备份orderer节点返还确认接收的消息,leader主节点对交易信息进行切块处理。 Step4leader主节点将处理后的信息进行广播。 本文设计的区块链系统中,投资公司希望在银行货币政策下获得最大效益,而这些投资公司彼此之间并不了解对方的收益,所以可以认定投资公司之间的博弈是非合作的静态博弈,由于任何投资公司在特定的银行的货币政策下,不可能改变投资的效益比率,所以投资环境满足博弈论中纳什均衡的条件。其中投资环境如图2所示,商业银行在中央银行的指导下,发布自己的货币政策,投资公司与商业银行有货币业务往来,如贷款、储蓄等。 图2 投资环境示意图 本文将实验结果和分析分成三部分,分别对应第2节中提出的三个算法:用投资公司在银行购买债券的利率和涨跌幅作为聚类特征,使用AP聚类训练数据得到聚类结果;对每一类的数据,分析银行利率和收益之间的关系,用基于拥挤距离的粒子群算法求解类所在的纳什均衡的近似解,将求得的纳什均衡解所对应的贷款银行作为共识算法的主节点,应用到Hyperledger Fabric网络中,负责区块链的打包上链管理。 随着金融科技和量化投资的发展,传统的营销方法很难获得长期稳定的收益,投资公司投资某项目时已不是简单和被动地对市场需求作出反应,而是更加趋向于将自己的业务托管到金融公司来减少投资风险,金融公司为一类行业的投资公司提供高效安全、快捷周到的服务。 本文依据金融政策对投资公司的影响情况,运用聚类分析将这些投资公司进行分类,更加精准地掌握投资公司的特征,确定投资的范围。分类后的结果即为投资公司对应行业所在的金融公司。本文选择公司在银行购买债券的利率和涨跌幅这两项财务指标作为聚类的特征,对这些投资公司进行了聚类分析,为每家投资公司确定其所属的簇群。其中部分数据如表1所示,数据来源于CSMAR国泰安经济金融数据库、中国债券市场研究数据库。 表1 债券交易数据文件(部分) 3.1.1参数优化 本文使用AP聚类对上述数据进行训练,得到初始的参考度值为-1.3。根据第2节所述,参考度的值会极大影响聚类的性能,本文将参考度初始值作为参考,选择附近的一组值[-2.3,-0.5]重新聚类,依据SIL索引的最佳值,确定最佳簇数。图3说明了不同参考度对于聚类结果的影响,大于中位数值的参考度聚类后轮廓系数较小,聚类效果不佳;小于中位数值的参考度聚类后轮廓系数逐渐增大,并逐渐趋于平稳(图3(a));同时参考度的不同影响了最终聚类的簇数结果,参考度在-2附近时,聚类簇数较为稳定(图3(b))。轮廓系数越大,其相应的聚类效果越好,最终选择参考度为-2.1时,轮廓系数为0.575 5,簇数为12的结果作为本文最佳的聚类效果。 (a) 不同参考度对轮廓系数的影响 (b) 不同参考度对聚类个数的影响图3 不同参考度对聚类效果的影响 图4所示轮廓系数评估聚类质量效果图,横坐标为轮廓系数,纵坐标为簇数所含样本点的多少,虚线表示轮廓系数的均值,以此可以判断聚类模型的性能。 图4 SIL均值评估聚类质量 3.1.2聚类结果 聚类结果为12个类,即将投资公司分类成12个类,每一类都有对应行业的金融公司接管子投资公司的业务,聚类结果如图5所示,展示了AP聚类训练样本点过程的主要步骤。训练数据集包含上述数据来源的数据点,每一个数据点代表一家投资公司(图5(a));AP聚类将这些样本分配到12个子簇中,节点颜色表示公司所属的类别,用来区分公司所属的簇群,其中节点的相关性用线条来表示,线条越短,表示投资公司之间的关联性越强(图5(b));为簇群获得相应的子簇边界,每个簇群都有一个聚类中心,用公司标签显示出来(图5(c))。聚类结果如表2所示。 (a) 原始数据 (b) AP聚类结果 (c) 增加轮廓的聚类结果图5 投资公司聚类后的结果 表2 聚类结果 可以看出,使用此聚类方法可以挖掘出数据潜在的关系,所得到的结果与投资公司实际业务和经营状况基本符合。例如:Cluster1,将电子科技类的投资公司分成一类;Cluster3,将建筑材料的投资公司分成一类。聚类分析可直观显示各种投资公司的归属,为金融公司接管投资公司业务提供了一种途径和技术支持。 本节使用改进的粒子群算法求解一类投资公司在贷款政策下的纳什均衡解,即算法最终给出的最优点坐标。所用的数据为上一步聚类所得第一类金融公司向银行贷款的数据如表3所示,数据来源于CSMAR国泰安经济金融数据库。 表3 上市公司向银行贷款数据(部分) 在算法2的实现中,初始点位置根据式(1)映射生成148个点,即第一类金融公司所包含的业务数,每个粒子代表其当前局势,粒子的速度随机生成,保证在速度的上下限内,设置速度上限0.5,下限-0.5,惯性因子0.8。基于拥挤距离和GSA的粒子群算法求解纳什均衡迭代过程如图6所示,展示了不同迭代次数粒子向最优解移动的过程,每个投资公司通过迭代不断调整自己的策略,向能使整个金融公司收益效益最好的空间不断移动,最终趋向博弈的均衡点。在本文算法中,博弈问题可能有一个或者多个纳什均衡解,若有多个纳什均衡解,则其对应的贷款银行可作为共识算法的备用主节点。 (a) 第1次迭代 (b) 第20次迭代 (c) 第30次迭代 (d) 第40次迭代图6 改进的粒子群算法求解纳什均衡迭代过程 本文通过比较普通粒子群算法(PSO)、基于拥挤距离的粒子群优化算法(DC-PSO)、基于拥挤距离和GSA改进的粒子群算法(DC-GSAPSO)三种算法进行对比,如图7所示,可以看到DC-GSAPSO在求解博弈的均衡解过程中比普通粒子群算法收敛得更快,解的质量具有更小的适应度值。 图7 适应度函数随迭代次数的变化 为了进一步分析改进算法的稳定性和有效性,本文采用初始数量为300个粒子对三种算法进行验证,通过计算边缘粒子坐标的总个数与粒子总数的比值来计算覆盖率,依据覆盖率随迭代次数的变化来评价算法的有效性,如图8所示,可以明显看出,DC-GSAPSO每次迭代所产生的解均要优于其他两种算法。 图8 边缘坐标覆盖率随迭代次数的变化 第一类金融公司依据算法搜索到的纳什均衡解如表4所示,展示了解的适应度值大小、边缘坐标、所对应的投资公司和贷款银行,可以看到适应度越小越接近纳什均衡解。算法找到了三个纳什均衡解,在银行的选取上,本文选择第一个解对应的中国建设银行作为此类金融公司的主节点。 表4 第一类金融公司确定的纳什均衡解 此外的12类金融公司依据同样的方法所选择出的银行如表5所示。表5中通过众数来选择排名前三的银行为:中国建设银行、中国银行和中国工商银行。依据顺序选择中国建设银行作为此系统模型的共识主节点负责区块的排序和打包上链,中国银行和中国工商银行作为系统的备份主节点,当主节点安全性和可靠性失效时,使用容错算法替换成备份主节点。 表5 面向组合投资模型的纳什均衡解 在组合投资方面,如果合理利用组合投资的方式,不但可以把风险控制在合理范围内,而且可以获得收益。依据投资组合优化理论选取标准和得到的纳什均衡解,考虑投资者之间的影响关系,降低投资风险来提高盈利的准确性。由于聚类后得到的12类投资公司之间的相关性降低,符合投资组合优化理论,所以本文选择表5中利用基于拥挤距离的粒子群算法求出的纳什均衡解对应的12家投资公司(北方创业、长江投资、北新建材、百利电气、广博股份等)作为此次计算的组合投资方案,这样做不但减少了投资者的投资范围,而且可以让投资者重点关注处于纳什均衡解附近的稳定性公司。 为了验证算法2求解纳什均衡解的正确性和可行性,本文采用博弈中的一个经典的双矩阵对策例子Rock-Scissors-Paper,对本文理论进行验证。Rock-Scissors-Paper中两个人的支付矩阵如表6所示。 表6 Rock-Scissors-Paper支付矩阵 运用A和B的支付矩阵,用改进的粒子群算法随机生成粒子来解决此问题,如表7所示。 表7 Rock-Scissors-Paper的纳什均衡解 纳什均衡解为x=[x1,x2]T,其中x1=[0.33,0.33,0.33]T,x2=[0.33,0.33,0.33]T。这符合我们的常识,即游戏中的两个玩家随机出剪刀石头布,每种策略概率为1/3,满足每个人的最大化利益,即达到纳什均衡,且验证了算法2求解的正确性。 根据以上两节我们求得了纳什均衡近似解,并将均衡解作为共识主节点,本节将提出的共识算法应用于一个面向组合投资的区块链原型系统,基于Hyperledger Fabric 1.0来实现系统的共识机制。 3.3.1实验数据 共识节点需要将交易信息进行切块打包成区块,这里的数据主要是peer节点之间的交易信息,利用peer之间进行频繁的转账操作生成交易信息。交易依据中国上市公司关联交易数据库,此数据库包含以上两个实验中投资公司交易的基本情况和相关信息,收集了投资公司的基本信息、资金往来等数据,如表8所示。 表8 中国上市公司关联交易数据库(部分) 由于数据库包含数据量很大,而共识实验只需要验证交易信息是否达成一致,不需要全部的数据量为依靠,本文选择投资公司交易量大于100条交易的14家公司作为系统的peer节点,从数据库中为每家公司随机抽取4条交易数据作为打包上链的交易信息,这样做不仅减少了数据量,而且数据库结构合理,客观反映了关联交易的实质性内容。表9所示为选择的投资公司交易数据量的大小。 表9 公司交易数据量大小 3.3.2实验场景及过程 基于官方给出的Fabric1.0版本,在examples/e2e_cli案例基础之上进行二次开发。在e2e_cli基础上更改系统的结构:3个peer组织即14个投资公司peer节点如图9所示;3个orderer商业银行节点,指定中国建设银行作为主orderer,中国银行和中国工商银行作为备用orderer。 图9 Peer Graph 首先使用cli工具将peer节点和主orderer以及备用orderer加入同一通道,进行chaincode安装以及实例化,目的是制定peer之间正常交易的规则,模拟peer之间的正常转账场景,通过SDK或者cli工具调用两个peer之间的转账操作,为主orderer产生需要排序打包的交易数据。通过接收时间的先后生成了消息序列,之后依据提出的共识算法Nash-consensus,主orderer对消息序列打包成block,记录交易数据共识成区块的各项信息。 3.3.3实验结果 用中国建设银行作为主节点共识上链,设置最大消息计数为15,区块最大字节数为98 KB,BatchTimeout为10 s,打包上链的区块信息结果如表10所示。 表10 BLOCK信息 分别对Solo、Kafka、基于纳什均衡的共识算法Nash-consensus进行对比,分别从有无博弈思想、安全性、扩展性、性能效率、资源消耗五方面进行比较,结果如表11所示。其中:安全性指共识算法是否有容错性;扩展性指是否支持节点的扩展。 表11 三种共识算法对比 现代计算机技术中,各类共识算法都有其适用的场景,并不存在绝对优劣之分。为了保证区块链系统中各节点的利益,本文精心设计一个区块链共识算法,从博弈的角度入手,利用纳什均衡理论使系统达成一致,均衡结果作为系统的共识机制。在对纳什均衡问题的求解上,将其转化为最优问题,用聚类算法对系统中各节点进行分类,而后用粒子群优化算法求解纳什均衡近似解,将纳什均衡解下对应的节点应用于一个面向组合投资的区块链原型系统中,作为系统的共识节点,使系统达成共识。总体来说,本文为从博弈方向设计区块链共识算法提供了新的思路。2.3 基于纳什均衡的共识算法

3 实验与结果分析

3.1 亲和力传播算法聚类结果



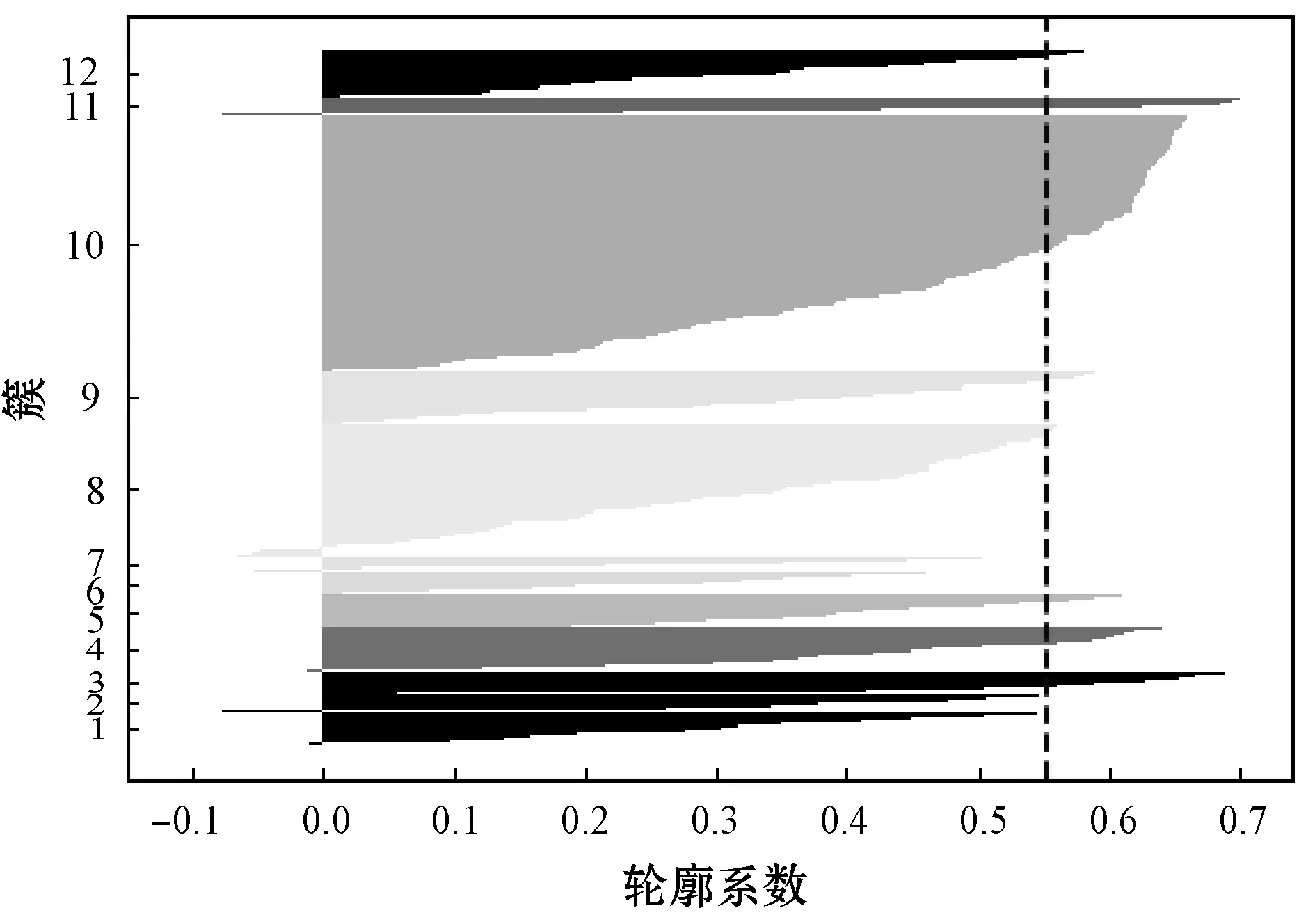



3.2 粒子群求解纳什均衡算法结果分析









3.3 系统共识实验




4 结 语
