可穿戴设备上的人声分离研究
2021-12-13蒋非颖张佳敏
蒋非颖 张佳敏
(1、北京儒博科技有限公司,北京 100000 2、成都大学肉类加工四川省重点实验室,四川成都 610106)
在语音识别中的多人对话场景,需要把说话人各自的语音分开才能有效加以识别,混在一起的语音识别不了。目前一个比较常用的应用场景是用于智能多人会议识别转写系统,一个麦阵设备放在参会者中间来拾取和分离、识别语音。其普遍使用的算法是基于麦阵多波束成形按说话人空间方向来分离[1],典型的如微软Azure IoT Edge 使用的“黑塔”会议系统,用12个波束,覆盖360°的方位。或者训练深度神经网络来做单通道盲分离[2-4]。将其结合的多通道神经网络语音分离架构是目前热点的研究方向[5,6]。这种主要用于多人会议场景的外置麦阵拾音设备使用场景固定,它需要有地方放置,不方便移动携带。相比而言可穿戴的小型设备更为灵活方便,广泛适用于例如服务员和顾客,医护和患者等之间的对话的拾音来分离识别。
基于设置较多固定波束的波束成形算法以及基于深度神经网络的分离算法往往需要比较大的算力和存储空间,其本地设备主要用于拾音,计算一般放在云端进行,因此用于有无线信号覆盖的在线场景。而可穿戴设备具有可移动性,有支持离线处理的需求,算法要能在本地嵌入式端进行。而且使用电池供电,也有省电、低功耗的需求。因此算力和存储都有限,需要低复杂度的分离算法。
本文研究了在一种基于增强干扰语音抑制的人声分离的算法,使用了最少一个麦阵波束和一个自适应噪声对消模块,以较小的算力消耗在一种可穿戴设备,智能胸牌上达到了较好的人声分离的效果。
1 增强干扰抑制的波束成形分离算法
1.1 胸牌ID 结构
本文研究的胸牌结构如图1 所示,胸牌使用4 个麦克风构成麦克风阵列,麦克风放置在胸牌四个角上,横向麦克间距6cm,纵向间距3cm。胸牌佩戴在说话人胸口,这种4 麦结构可以认为构成一个环形麦阵,认为4 个麦克风非均匀的分布在环麦的圆周上。

图1 胸牌结构示意图
1.2 自适应波束成形结构
胸牌佩戴在使用者身上后,可以使用麦阵型波束,一个固定指向佩戴者嘴的方向,另一个指向对话者,如图2 所示。本算法采用MVDR[7]波束成形算法,它是广泛使用的波束成形算法,能较好的抑制干扰噪声。MVDR 可以使用基于广义旁瓣对消的自适应波束成形架构来方便迭代实现[8,9]。如图3 所示,两个波束其中一个按佩戴位置以固定的方位角和抬高角指向佩戴者,另外一个以抬高角90°垂直胸牌平面指向对面的对话者。下文用服务员和顾客分别指代胸牌佩戴者和与其对话者。
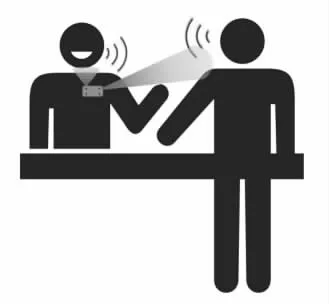
图2 胸牌使用场景
由于胸牌离服务员近很多,而且角度相对固定,而离顾客远,因此,如图3 所示,服务员这一路固定角度beamforming 输出的信号A1 中服务员语音是主要信号分量,残留的顾客语音分量小,如果能进一步抑制残留的顾客语音就能得到比较纯净的服务员信号。本文研究了一种增强干扰语音分量抑制算法来进一步抑制顾客语音在信号A1 上的残留,以此作为理想的参考信号。
相反的,由于顾客离胸牌相对较远,指向顾客的一路beamforming 输出信号A2 中有较强残留的服务员语音,并且环境噪声大。这里使用自适应噪声消除算法[10,11],把服务员一路经过干扰语音抑制后的输出作为参考信号,抑制顾客信号A2 上服务员的语音分量,以得到分离度较高的顾客语音。
在算力限制或者佩戴者和顾客之间角度较大的情况下,可以如图3 直接使用一个麦克的单麦输入语音替代顾客方向波束成形,这种方案对噪声的抑制效果小一些,但并不影响分离。两路语音再各自经过降噪/增益调整等后处理算法得到最终输出语音。

图3 增强干扰抑制波束成形算法框架
1.3 增强干扰语音抑制算法
传统自适应波束成形虽然能一定程度上抑制非指向方向的语音分量,但还是会有一定残余干扰语音成分,特别是两个指向方向角度比较靠近的情况,残留干扰语音分量会更多,需要进一步抑制才能提供较好的识别效果。具体到工牌设备,如图3,如果佩戴者一路输出信号A1 里面残留有较多顾客语音分量,则其作为噪声对消算法的参考信号就不纯净,会把顾客的语音成分给对消掉很多,影响语音分离效果。这里考虑利用广义旁瓣对消中包含的空间信息,可以进一步抑制A1 信号里残余的顾客语音分量。
如图4 所示的广义旁瓣对消原理框图里,经过block matrix之后经过平滑和EQ 处理后,是估计出来的空间噪声的频谱Ns,其在空域后滤波里面作为参考进一步抑制空间干扰分量。这个空间噪声代表波束成形算法里非beam 指向方向的空间干扰信号。包含了干扰的空间信息,越大表明干扰的能量越强,也就是干扰语音分量越强。根据它的强度,可以设定一个门限来判断当前帧的主要成分是波束指向方向的期望信号,还是非指向方向的干扰语音信号,由此可以把语音分段成期望语音段和干扰语音段,对干扰语音段进行进一步的抑制。
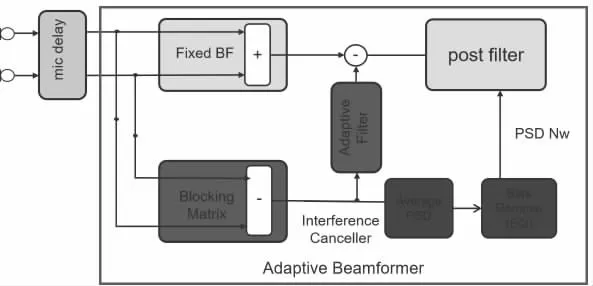
图4 空域自适应波束成型旁瓣对消原理
在广义旁瓣对消的自适应beamforming 算法结构中,麦克风输入的信号Xn经过傅里叶变换成子带信号Xn(ejΩμ,k),其中n为麦克风序号,μ 为频率点序号,Ω 为频率支撑点,k 为时间帧号。经过Blocking Matrix 去掉目标信号得到空间噪声,再经过平滑以及去偏移EQ 处理后得到用于空域后滤波的空间噪声频谱Ns(ejΩμ,k)。
空域后滤波根据估计出来的固定beamforming 处理后的语音功率谱A(ejΩμ,k),以及前述空间噪声功率谱Ns(ejΩμ,k),利用迭代维纳滤波降噪的方式计算出滤波器系数用于消除空间噪声。降噪公式为:

从式(2)可以看出,维纳滤波器系数H(ejΩμ,k)可以反映频域子带空间噪声的强弱,越小说明空间噪声越大,也就是从非beam 指向进入的干扰语音分量越大。将滤波器系数H 在频域子带上做归一化得到全频带的平均滤波器系数H(k):

式中,Hextra(ejΩμ)为额外抑制系数,用于降低去噪门限提供额外的抑制。通过设置它来基本消除干扰语音段。
2 算法实验及结果分析
2.1 服务员-顾客先后说话分离算法效果
为了评估分离算法,佩戴胸牌录音测试。两个测试人员模拟办事大厅的服务员和客户对话,两者相距两米,1.5m 外音响与两者成45°角,播放音乐作为噪声干扰,音乐声在工牌附近测得声压为70 dBSPL。录取4 路mic in,其中某一路波形如图6 第一行所示,其中加框部分波形为顾客说话,其余部分为服务员说话。
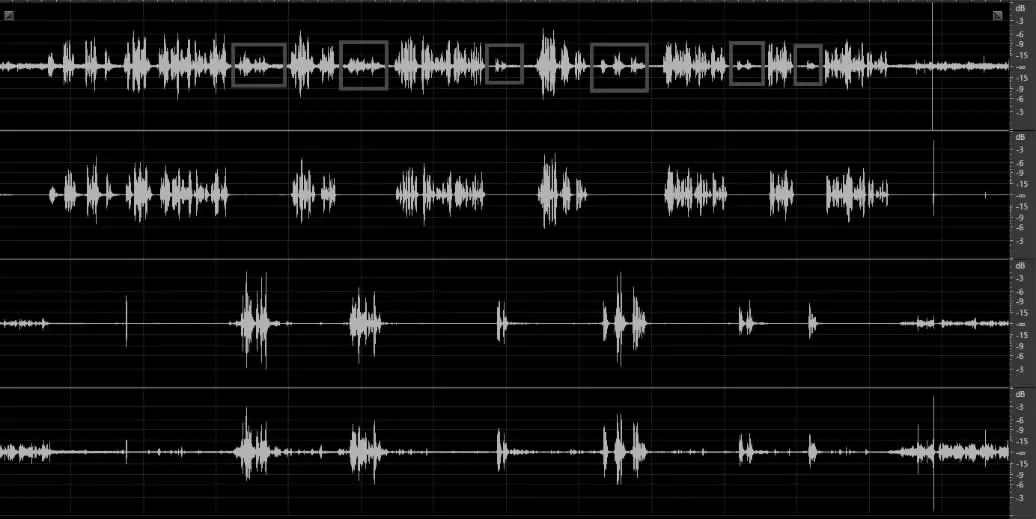
图6 分离前后波形对比
基于录音使用分离算法,录制16k 采样率16bit PCM,使用16ms 帧长,每帧做256 点FFT,使用参数:平滑系数∂=0.99,Hmin=10dB,Hextra=20dB。对服务员通路信号采用波束成形算法和干扰语音抑制算法,得到干扰语音检测标志如图5,其中蓝线为干扰语音检测标志C(k),由图5 可见,干扰语音段的C(k)值明显低于非干扰语音段,可以很好的分开。这里设门限CT 为0.05,就可以分离出干扰语音段,并使用干扰额外抑制算法。
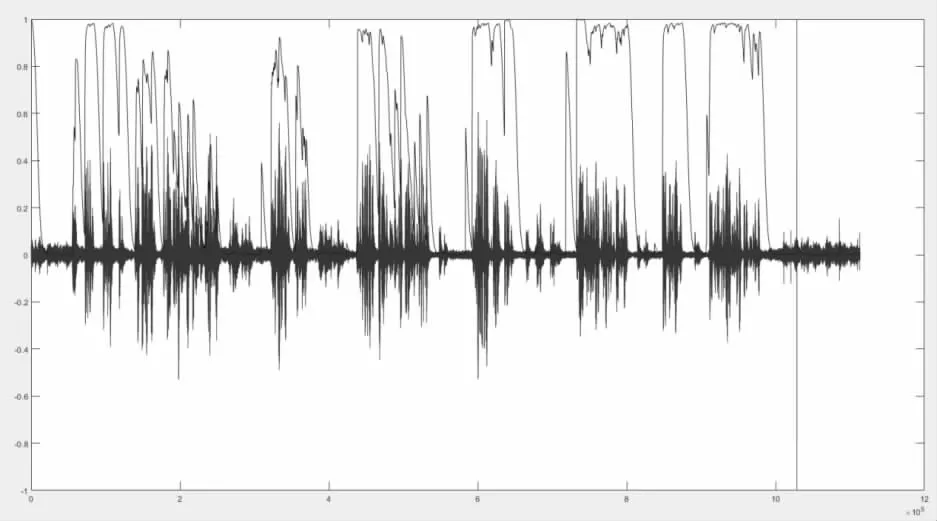
图5 干扰语音段检测
对于顾客信号通路,如图3 算法结构,对顾客信号分别使用波束成形处理后输出,或某一个输入麦克直接输出来做自适应噪声消除,处理后得到最终服务员波形和顾客波形如图6。其中第一行为麦克输入波形,第二行波形为服务员输出,第三行为使用波束成形再做自适应噪声消除的顾客输出波形,第四行为直接使用一麦克输入来做自适应噪声消除的顾客处理后输出波形。由波形可见无论顾客一路使用波束成形输出还是使用单一麦克输出来做噪声消除,服务员和顾客的语音都被完全分离开来,都具有良好的分离能力。只是使用单麦克信号的话,不具备波束成形的降噪功能,噪声抑制会差一点。但是这么节省了一个波束成形的计算,可用于算力紧张的情况。
2.2 同时说话分离效果
如2.1 所述增强干扰语音抑制算法主要针对非同时说话的场景,这是本文分离算法讨论的主要场景,在典型的对话过程中,大部分时间是对话成员先后说话。同时说话是一种暂态,但同时说话的分离能力也是重要的指标。胸牌采用由图3 所示的旁瓣对消自适应波束成形加自适应噪声消除的算法框架对同时说话也能提供较好分离能力。
由于胸牌的特点,服务员的语音能量相对顾客较大,且角度相对固定,因此图3 所示服务员一路,经波束成形输出信号A1 比较纯净,包含的顾客语音少,用它作为参考信号使用自适应滤波的噪声消除算法可以进一步消除顾客一路A2 里面的服务员语音分量,且对A2 中顾客语音成分的消除较少。在胸牌两人2m 距离说话场景,分离仿真效果如图7所示,第一,行为mic 输入波形,其中红色细线部分是顾客单讲,蓝色粗线是同时讲话部分。第二,三行分别为分离出来的服务员和顾客。经仿真计算,使用本文提出的如图3 所示的分离算法框架,同时说话的干扰语音抑制能达到18dB,同时对各自自己的语音消除较小。

图7 同时讲话的分离
3 结论
本文基于麦阵自适应波束成形算法,实现了一种用于可穿戴设备的语音分离算法框架。研究了一种加强干扰语音抑制算法,能进一步消除波束成形后的残余干扰语音分量。对于对话者的非同时说话以及同时说话的场景,本算法都可以较好的分离语音,同时节省计算量,适用于低功耗设备的需求。
